Saya ingin memberi tahu Anda satu mekanisme menarik untuk bekerja dengan konfigurasi sistem terdistribusi. Konfigurasi disajikan langsung dalam bahasa yang dikompilasi (Scala) menggunakan tipe aman. Dalam posting ini, contoh konfigurasi seperti itu dianalisis dan berbagai aspek memperkenalkan konfigurasi yang dikompilasi ke dalam proses pengembangan secara keseluruhan dipertimbangkan.
( bahasa inggris )
Pendahuluan
Membangun sistem terdistribusi yang andal menyiratkan bahwa semua node menggunakan konfigurasi yang benar, disinkronkan dengan node lain. Biasanya, teknologi DevOps (terraform, ansible, atau sesuatu seperti itu) digunakan untuk secara otomatis menghasilkan file konfigurasi (seringkali milik mereka sendiri untuk setiap node). Kami juga ingin memastikan bahwa semua node yang berinteraksi menggunakan protokol yang identik (termasuk versi yang sama). Jika tidak, ketidakcocokan akan tertanam dalam sistem terdistribusi kami. Di dunia JVM, salah satu konsekuensi dari persyaratan ini adalah kebutuhan untuk menggunakan versi perpustakaan yang sama yang berisi pesan protokol di mana-mana.
Bagaimana dengan pengujian sistem terdistribusi? Tentu saja, kami mengasumsikan bahwa unit test disediakan untuk semua komponen sebelum kami melanjutkan ke pengujian integrasi. (Agar kami memperkirakan hasil pengujian menjadi runtime, kami juga harus menyediakan kumpulan perpustakaan yang identik pada tahap pengujian dan dalam runtime.)
Ketika bekerja dengan tes integrasi, seringkali lebih mudah di mana saja untuk menggunakan classpath tunggal pada semua node. Kami hanya perlu memastikan bahwa classpath yang sama terlibat dalam runtime. (Terlepas dari kenyataan bahwa sangat mungkin untuk menjalankan node yang berbeda dengan classpath yang berbeda, ini mengarah pada komplikasi dari seluruh konfigurasi dan kesulitan dengan tes penyebaran dan integrasi.) Sebagai bagian dari posting ini, kami mengasumsikan bahwa classpath yang sama akan digunakan pada semua node.
Konfigurasi berkembang dengan aplikasi. Untuk mengidentifikasi berbagai tahapan evolusi program, kami menggunakan versi. Tampaknya logis juga mengidentifikasi berbagai versi konfigurasi. Dan konfigurasi itu sendiri harus ditempatkan di sistem kontrol versi. Jika hanya ada satu konfigurasi dalam produksi, maka kita bisa menggunakan nomor versi. Jika banyak contoh produksi digunakan, maka kita perlu beberapa
cabang konfigurasi dan label tambahan selain versi (misalnya, nama cabang). Dengan demikian, kita dapat secara unik mengidentifikasi konfigurasi yang tepat. Setiap pengidentifikasi konfigurasi secara unik sesuai dengan kombinasi tertentu dari node terdistribusi, port, sumber daya eksternal, versi perpustakaan. Dalam kerangka posting ini, kami akan melanjutkan dari fakta bahwa hanya ada satu cabang, dan kami dapat mengidentifikasi konfigurasi dengan cara biasa menggunakan tiga angka yang dipisahkan oleh titik (1.2.3).
Dalam lingkungan modern, file konfigurasi secara manual dibuat sangat jarang. Lebih sering mereka dihasilkan selama penyebaran dan mereka tidak lagi tersentuh (agar tidak merusak apa pun ). Muncul pertanyaan logis, mengapa kita masih menggunakan format teks untuk menyimpan konfigurasi? Alternatif yang sepenuhnya layak adalah kemampuan untuk menggunakan kode reguler untuk konfigurasi dan mendapatkan manfaat dari cek pada waktu kompilasi.
Dalam posting ini, kami hanya mengeksplorasi ide mewakili konfigurasi di dalam artefak yang dikompilasi.
Konfigurasi yang dikompilasi
Bagian ini menjelaskan contoh konfigurasi terkompilasi statis. Dua layanan sederhana diterapkan - layanan gema dan layanan gema klien. Berdasarkan dua layanan ini, dua versi sistem dirakit. Dalam satu perwujudan, kedua layanan terletak pada node yang sama, dalam perwujudan lain, pada node yang berbeda.
Biasanya, sistem terdistribusi berisi beberapa node. Node dapat diidentifikasi menggunakan nilai dari beberapa tipe NodeId :
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
atau
case class NodeId(hostName: String)
atau bahkan
object Singleton type NodeId = Singleton.type
Node memainkan berbagai peran, layanan diluncurkan pada mereka dan komunikasi TCP / HTTP dapat dibuat di antara mereka.
Untuk menggambarkan komunikasi TCP, kita memerlukan setidaknya nomor port. Kami juga ingin merefleksikan protokol yang didukung pada port ini untuk memastikan bahwa klien dan server menggunakan protokol yang sama. Kami akan menggambarkan koneksi menggunakan kelas ini:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
di mana Port hanyalah Int integer dengan rentang nilai yang valid:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Jenis HalusLihat perpustakaan yang disempurnakan dan laporan saya . Singkatnya, perpustakaan memungkinkan Anda untuk menambahkan kendala yang diperiksa pada waktu kompilasi untuk mengetik. Dalam hal ini, nilai nomor port yang valid adalah bilangan bulat 16-bit. Untuk konfigurasi yang dikompilasi, menggunakan perpustakaan yang disempurnakan adalah opsional, tetapi dapat meningkatkan kemampuan kompiler untuk memverifikasi konfigurasi.
Untuk protokol HTTP (REST), selain nomor port, kami juga mungkin memerlukan jalur ke layanan:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
Jenis hantuUntuk mengidentifikasi protokol pada tahap kompilasi, kami menggunakan parameter tipe yang tidak digunakan di dalam kelas. Keputusan ini disebabkan oleh kenyataan bahwa dalam runtime kami tidak menggunakan contoh protokol, tetapi kami ingin kompiler memeriksa kompatibilitas protokol. Berkat protokol, kami tidak akan dapat mentransfer layanan yang tidak sesuai sebagai ketergantungan.
Salah satu protokol yang umum adalah REST API dengan serialisasi Json:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
di mana RequestMessage adalah jenis permintaan, ResponseMessage adalah jenis respons.
Tentu saja, Anda dapat menggunakan deskripsi protokol lain yang memberikan akurasi yang kami butuhkan.
Untuk keperluan posting ini, kami akan menggunakan versi protokol yang disederhanakan:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Di sini, permintaan adalah string yang ditambahkan ke url, dan responsnya adalah string yang dikembalikan di badan respons HTTP.
Konfigurasi layanan dijelaskan oleh nama layanan, port, dan dependensi. Elemen-elemen ini dapat direpresentasikan dalam Scala dalam beberapa cara (misalnya, HList , tipe data aljabar). Untuk keperluan posting ini, kita akan menggunakan Pola Kue dan mewakili modul menggunakan trait . (Pola Kue bukan elemen yang diperlukan dari pendekatan yang dijelaskan. Ini hanya salah satu implementasi yang mungkin.)
Ketergantungan antara layanan dapat direpresentasikan sebagai metode yang mengembalikan port EndPoint dari node lain:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Untuk membuat layanan gema, hanya nomor port dan indikasi bahwa port ini mendukung protokol gema sudah cukup. Kami tidak dapat menunjukkan port tertentu, karena sifat memungkinkan Anda untuk mendeklarasikan metode tanpa implementasi (metode abstrak). Dalam hal ini, ketika membuat konfigurasi tertentu, kompiler akan meminta kami untuk menyediakan implementasi metode abstrak dan memberikan nomor port. Karena kami menerapkan metode ini, saat membuat konfigurasi tertentu, kami tidak dapat menentukan port lain. Nilai default akan digunakan.
Dalam konfigurasi klien, kami menyatakan ketergantungan pada layanan gema:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
Ketergantungan dari jenis yang sama dengan layanan yang diekspor echoService . Secara khusus, di klien gema kami memerlukan protokol yang sama. Karena itu, ketika menghubungkan kedua layanan, kita dapat yakin bahwa semuanya akan bekerja dengan benar.
Implementasi layananUntuk memulai dan menghentikan layanan, diperlukan suatu fungsi. (Kemampuan untuk menghentikan layanan sangat penting untuk pengujian.) Sekali lagi, ada beberapa opsi untuk mengimplementasikan fungsi ini (misalnya, kita bisa menggunakan kelas tipe berdasarkan tipe konfigurasi). Untuk keperluan posting ini, kami akan menggunakan Pola Kue. Kami akan mewakili layanan menggunakan kelas cats.Resource , karena Di kelas ini, sarana pelepasan sumber daya yang dijamin aman jika terjadi masalah sudah disediakan. Untuk mendapatkan sumber daya kita perlu menyediakan konfigurasi dan konteks runtime yang siap. Fungsi untuk memulai layanan mungkin terlihat seperti ini:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
dimana
Config - jenis konfigurasi untuk layanan iniAddressResolver - objek runtime yang memungkinkan Anda mengetahui alamat node lain (lihat di bawah)
dan jenis lain dari perpustakaan cats :
F[_] - jenis efek (dalam kasus paling sederhana, F[A] hanya bisa menjadi fungsi () => A Dalam posting ini kita akan menggunakan cats.IO )Reader[A,B] - kurang lebih identik dengan fungsi A => Bcats.Resource - sumber daya yang dapat diperoleh dan dirilisTimer - timer (memungkinkan Anda tertidur sebentar dan mengukur interval waktu)ContextShift - analog dari ExecutionContextApplicative - kelas jenis efek yang memungkinkan Anda untuk menggabungkan efek individual (hampir monad). Dalam aplikasi yang lebih kompleks, tampaknya lebih baik menggunakan Monad / ConcurrentEffect .
Dengan menggunakan tanda tangan fungsi ini, kita dapat mengimplementasikan beberapa layanan. Misalnya, layanan yang tidak melakukan apa pun:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Lihat kode sumber untuk layanan lain - layanan gema , klien gema
dan pengontrol seumur hidup .)
Node adalah objek yang dapat memulai beberapa layanan (peluncuran rantai sumber daya dipastikan oleh Pola Kue):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Harap perhatikan bahwa kami menunjukkan jenis konfigurasi persis yang diperlukan untuk simpul ini. Jika kita lupa menentukan salah satu tipe konfigurasi yang diperlukan oleh layanan terpisah, akan ada kesalahan kompilasi. Selain itu, kami tidak akan dapat memulai node jika kami tidak menyediakan beberapa objek dari tipe yang sesuai dengan semua data yang diperlukan.
Resolusi Nama HostUntuk terhubung ke host jarak jauh, kami membutuhkan alamat IP asli. Ada kemungkinan bahwa alamat tersebut akan diketahui setelah konfigurasi lainnya. Oleh karena itu, kita memerlukan fungsi yang memetakan pengidentifikasi simpul ke alamat:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Anda dapat menawarkan beberapa cara untuk mengimplementasikan fungsi tersebut:
- Jika alamat diketahui oleh kami sebelum penerapan, maka kami dapat membuat kode Scala
alamat dan kemudian mulai majelis. Ini akan mengkompilasi dan menjalankan tes.
Dalam hal ini, fungsinya akan diketahui secara statis dan dapat direpresentasikan dalam kode sebagai tampilan peta Map[NodeId, NodeAddress] . - Dalam beberapa kasus, alamat yang valid hanya diketahui setelah node dimulai.
Dalam hal ini, kita dapat mengimplementasikan "layanan penemuan" (discovery), yang berjalan sebelum node lain dan semua node akan mendaftar dalam layanan ini dan meminta alamat node lain. - Jika kita dapat memodifikasi
/etc/hosts , maka kita dapat menggunakan nama host yang telah ditentukan (seperti my-project-main-node dan echo-backend ) dan hanya mengikat nama-nama ini
dengan alamat IP selama penyebaran.
Dalam kerangka posting ini, kami tidak akan mempertimbangkan kasus ini secara lebih rinci. Untuk kita
Dalam contoh mainan, semua node akan memiliki satu alamat IP - 127.0.0.1 .
Berikutnya, kami mempertimbangkan dua opsi untuk sistem terdistribusi:
- Penempatan semua layanan pada satu node.
- Dan penempatan layanan gema dan klien gema pada node yang berbeda.
Konfigurasi untuk satu simpul :
Konfigurasi simpul tunggal object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
Objek mengimplementasikan konfigurasi klien dan server. Konfigurasi seumur hidup juga digunakan untuk mengakhiri program setelah lifetime . (Ctrl-C juga berfungsi dan membebaskan semua sumber daya dengan benar.)
Rangkaian sifat dan implementasi konfigurasi yang sama dapat digunakan untuk membuat sistem yang terdiri dari dua node terpisah :
Konfigurasi untuk dua node object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Penting! Perhatikan bagaimana pengikatan layanan dilakukan. Kami menunjukkan layanan yang diterapkan oleh satu node sebagai implementasi dari metode dependensi dari node lain. Jenis ketergantungan diperiksa oleh kompiler, karena berisi jenis protokol. Ketika diluncurkan, dependensi akan berisi pengidentifikasi yang benar dari node target. Berkat skema ini, kami menunjukkan nomor port tepat sekali dan selalu dijamin untuk merujuk ke port yang benar.
Implementasi dua node sistemUntuk konfigurasi ini, kami menggunakan implementasi layanan yang sama tanpa perubahan. Satu-satunya perbedaan adalah bahwa sekarang kami memiliki dua objek yang mengimplementasikan set layanan yang berbeda:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Node pertama mengimplementasikan server dan hanya membutuhkan konfigurasi server. Node kedua diimplementasikan oleh klien dan menggunakan bagian lain dari konfigurasi. Kedua node juga perlu mengatur waktu hidup. Node server berjalan tanpa batas hingga dihentikan oleh SIGTERM , dan node klien berakhir setelah beberapa waktu. Lihat aplikasi peluncuran .
Proses pengembangan umum
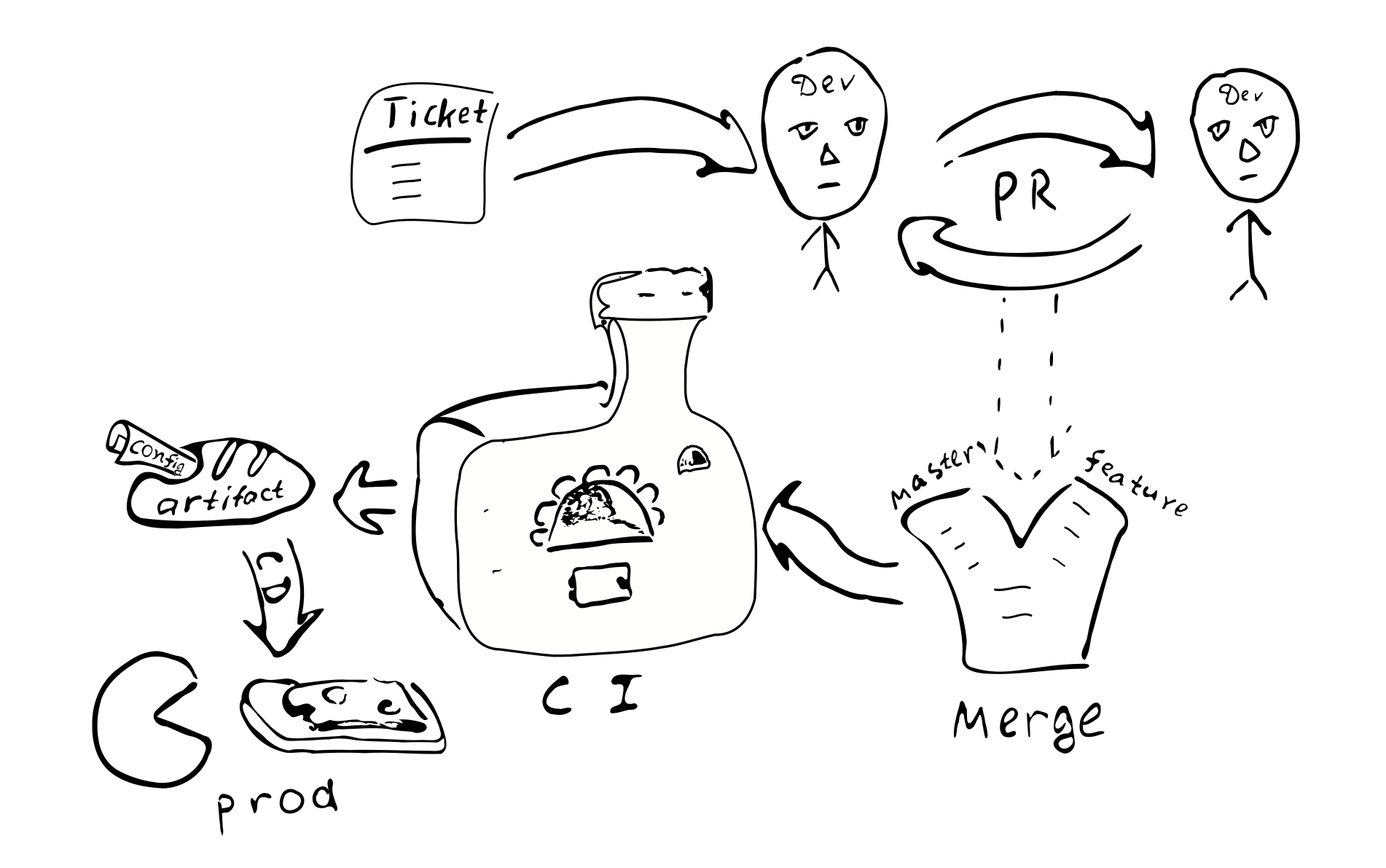
Mari kita lihat bagaimana pendekatan konfigurasi ini mempengaruhi keseluruhan proses pengembangan.
Konfigurasi akan dikompilasi bersama dengan sisa kode dan artefak (.jar) akan dihasilkan. Tampaknya, masuk akal untuk meletakkan konfigurasi dalam artefak terpisah. Ini disebabkan oleh kenyataan bahwa kita dapat memiliki banyak konfigurasi berdasarkan kode yang sama. Sekali lagi, Anda dapat membuat artefak yang sesuai dengan cabang konfigurasi yang berbeda. Bersama dengan konfigurasi, dependensi pada versi perpustakaan tertentu dipertahankan dan versi ini dipertahankan selamanya, setiap kali kami memutuskan untuk menggunakan versi konfigurasi ini.
Perubahan konfigurasi apa pun berubah menjadi perubahan kode. Dan oleh karena itu, masing-masing
Perubahan akan ditanggung oleh proses penjaminan kualitas yang biasa:
Tiket di bugtracker -> PR -> ulasan -> bergabung dengan cabang terkait ->
integrasi -> penyebaran
Konsekuensi utama dari penerapan konfigurasi yang dikompilasi:
Konfigurasi akan dikoordinasikan pada semua node dari sistem terdistribusi. Karena semua node menerima konfigurasi yang sama dari satu sumber.
Bermasalah untuk mengubah konfigurasi hanya di salah satu node. Oleh karena itu, "konfigurasi drift" tidak mungkin.
Menjadi lebih sulit untuk membuat perubahan konfigurasi kecil.
Sebagian besar perubahan konfigurasi akan terjadi sebagai bagian dari keseluruhan proses pengembangan dan akan ditinjau.
Apakah saya memerlukan repositori terpisah untuk menyimpan konfigurasi produksi? Konfigurasi seperti itu mungkin berisi kata sandi dan informasi rahasia lainnya, akses yang ingin kami batasi. Berdasarkan hal ini, tampaknya masuk akal untuk menyimpan konfigurasi final dalam repositori terpisah. Anda dapat membagi konfigurasi menjadi dua bagian - satu berisi pengaturan konfigurasi publik, dan yang lainnya berisi pengaturan akses terbatas. Ini akan memungkinkan sebagian besar pengembang memiliki akses ke parameter umum. Pemisahan ini mudah dicapai dengan menggunakan sifat-sifat peralihan yang mengandung nilai-nilai default.
Kemungkinan variasi
Mari kita coba membandingkan konfigurasi yang dikompilasi dengan beberapa alternatif umum:
- File teks pada mesin target.
- Penyimpanan terpusat nilai kunci (
etcd / zookeeper ). - Komponen proses yang dapat dikonfigurasi ulang / dihidupkan ulang tanpa memulai kembali proses.
- Penyimpanan konfigurasi di luar artefak dan kontrol versi.
File teks memberikan fleksibilitas signifikan dalam hal perubahan kecil. Administrator sistem dapat pergi ke node jarak jauh, membuat perubahan pada file yang sesuai dan memulai kembali layanan. Namun, untuk sistem yang besar, fleksibilitas semacam itu mungkin tidak diinginkan. Dari perubahan yang dilakukan tidak ada jejak di sistem lain. Tidak ada yang mengulas perubahan. Sulit menentukan siapa yang melakukan perubahan dan untuk alasan apa. Perubahan tidak diuji. Jika sistem didistribusikan, maka administrator mungkin lupa untuk membuat perubahan yang sesuai pada node lain.
(Perlu juga dicatat bahwa penggunaan konfigurasi yang dikompilasi tidak memblokir kemungkinan menggunakan file teks di masa depan. Ini akan cukup untuk menambahkan parser dan validator yang memberikan jenis Config sama sebagai output, dan Anda dapat menggunakan file teks. Segera mengikuti kompleksitas sistem dengan konfigurasi yang dikompilasi agak kurang dari kompleksitas sistem yang menggunakan file teks, karena file teks memerlukan kode tambahan.)
Penyimpanan nilai kunci terpusat adalah mekanisme yang baik untuk mendistribusikan meta-parameter aplikasi terdistribusi. Kita harus memutuskan parameter konfigurasi apa dan apa itu data. Misalkan kita memiliki fungsi C => A => B , dengan parameter C jarang berubah, dan data A sering. Dalam hal ini, kita dapat mengatakan bahwa C adalah parameter konfigurasi, dan A adalah datanya. Tampaknya parameter konfigurasi berbeda dari data di mana mereka umumnya berubah lebih jarang daripada data. Selain itu, data biasanya berasal dari satu sumber (dari pengguna), dan parameter konfigurasi dari yang lain (dari administrator sistem).
Jika jarang mengubah parameter perlu diperbarui tanpa me-restart program, maka ini sering dapat menyebabkan komplikasi program, karena kita perlu entah bagaimana memberikan parameter, menyimpan, mengurai dan memeriksa, memproses nilai-nilai yang salah. Oleh karena itu, dari sudut pandang mengurangi kompleksitas program, masuk akal untuk mengurangi jumlah parameter yang dapat berubah selama program (atau tidak mendukung parameter tersebut sama sekali).
Dari sudut pandang pos ini, kita akan membedakan antara parameter statis dan dinamis. Jika logika layanan memerlukan perubahan parameter selama program, maka kami akan memanggil parameter tersebut dinamis. Jika tidak, parameternya statis dan dapat dikonfigurasi menggunakan konfigurasi yang dikompilasi. Untuk konfigurasi ulang dinamis, kita mungkin memerlukan mekanisme untuk memulai kembali bagian program dengan parameter baru, mirip dengan bagaimana proses sistem operasi dihidupkan ulang. (Menurut pendapat kami, disarankan untuk menghindari konfigurasi ulang waktu-nyata, karena kompleksitas sistem meningkat. Jika memungkinkan, lebih baik menggunakan kemampuan OS standar untuk memulai kembali proses.)
Salah satu aspek penting dari menggunakan konfigurasi statis yang memaksa orang untuk mempertimbangkan konfigurasi ulang dinamis adalah waktu yang diperlukan sistem untuk reboot setelah pembaruan konfigurasi (downtime). Bahkan, jika kita perlu membuat perubahan pada konfigurasi statis, kita harus me-restart sistem agar nilai-nilai baru berlaku. Masalah downtime memiliki tingkat keparahan yang berbeda untuk sistem yang berbeda. Dalam beberapa kasus, Anda dapat menjadwalkan reboot pada saat beban minimal. Jika Anda ingin memberikan layanan terus menerus, Anda dapat menerapkan "koneksi drainase" (AWS ELB draining) . Pada saat yang sama, ketika kita perlu me-reboot sistem, kita meluncurkan instance paralel dari sistem ini, alihkan balancer ke sana, dan tunggu sampai koneksi lama selesai. Setelah semua koneksi lama selesai, kami mematikan instance sistem yang lama.
Sekarang mari kita pertimbangkan masalah menyimpan konfigurasi di dalam atau di luar artefak. Jika kita menyimpan konfigurasi di dalam artefak, maka setidaknya kita memiliki kesempatan selama perakitan artefak untuk memastikan konfigurasi itu benar. Jika konfigurasi di luar artefak yang dikontrol, sulit untuk melacak siapa dan mengapa membuat perubahan pada file ini. Seberapa pentingkah ini? Menurut pendapat kami, untuk banyak sistem produksi, penting untuk memiliki konfigurasi yang stabil dan berkualitas tinggi.
Versi artifact memungkinkan Anda untuk menentukan kapan itu dibuat, nilai-nilai apa yang dikandungnya, fungsi apa yang diaktifkan / dinonaktifkan, siapa yang bertanggung jawab atas setiap perubahan dalam konfigurasi. Tentu saja, menyimpan konfigurasi di dalam artefak memerlukan beberapa upaya, jadi Anda perlu membuat keputusan.
Pro dan kontra
Saya ingin membahas pro dan kontra dari teknologi yang diusulkan.
Manfaatnya
Berikut ini adalah daftar fitur utama dari konfigurasi sistem terdistribusi yang dikompilasi:
- Pemeriksaan konfigurasi statis. Memungkinkan Anda untuk memastikannya
. - . . Scala , . ,
trait' , , val', (DRY) . ( Seq , Map , ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- . , . , , — . production- .
- Pengujian. mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList (case class') . - , : (
package , import , ; override def ' , ). , DSL. , (, XML), . - .
Kesimpulan
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
, .