Industri ini telah fokus pada percepatan perkalian matriks, tetapi meningkatkan algoritma pencarian dapat menyebabkan peningkatan kinerja yang lebih serius

Dalam beberapa tahun terakhir, industri komputer sibuk mencoba mempercepat perhitungan yang diperlukan untuk jaringan saraf tiruan - baik untuk pelatihan maupun untuk menarik kesimpulan dari pekerjaannya. Secara khusus, cukup banyak upaya dimasukkan ke dalam pengembangan besi khusus di mana perhitungan ini dapat dilakukan. Google mengembangkan
Tensor Processing Unit , atau TPU, pertama kali
diperkenalkan kepada publik pada tahun 2016. Nvidia kemudian memperkenalkan
V100 Graphics Processing Unit, menggambarkannya sebagai chip yang dirancang khusus untuk pelatihan dan penggunaan AI, serta untuk kebutuhan komputasi berperforma tinggi lainnya. Penuh dengan startup lain, berkonsentrasi pada jenis
akselerator perangkat keras lainnya .
Mungkin mereka semua membuat kesalahan besar.
Gagasan ini disuarakan dalam
karya , yang muncul pada pertengahan Maret di situs arXiv. Di dalamnya, penulisnya,
Beidi Chen ,
Tarun Medini dan
Anshumali Srivastava dari Rice University, berpendapat bahwa mungkin peralatan khusus yang dikembangkan untuk pengoperasian jaringan saraf sedang dioptimalkan untuk algoritma yang salah.
Masalahnya adalah bahwa pekerjaan jaringan saraf biasanya tergantung pada seberapa cepat peralatan dapat melakukan penggandaan matriks yang digunakan untuk menentukan parameter output dari masing-masing neutron buatan - "aktivasi" - untuk satu set nilai input yang diberikan. Matriks digunakan karena setiap nilai input untuk neuron dikalikan dengan parameter bobot yang sesuai, dan kemudian semuanya dijumlahkan - dan perkalian ini dengan penambahan adalah operasi dasar dari perkalian matriks.
Para peneliti di Rice University, seperti beberapa ilmuwan lain, menyadari bahwa aktivasi banyak neuron dalam lapisan tertentu dari jaringan saraf terlalu kecil, dan tidak mempengaruhi nilai output yang dihitung oleh lapisan berikutnya. Karena itu, jika Anda tahu apa itu neuron, Anda bisa mengabaikannya.
Tampaknya satu-satunya cara untuk mengetahui neuron dalam suatu lapisan yang tidak diaktifkan adalah dengan terlebih dahulu melakukan semua operasi penggandaan matriks untuk lapisan ini. Tetapi para peneliti menyadari bahwa Anda benar-benar dapat memutuskan cara yang lebih efisien ini jika Anda melihat masalah dari sudut yang berbeda. "Kami mendekati masalah ini sebagai solusi untuk masalah pencarian," kata Srivastava.
Artinya, alih-alih menghitung perkalian matriks dan melihat neuron mana yang diaktifkan untuk input yang diberikan, Anda bisa melihat jenis neuron apa yang ada dalam database. Keuntungan dari pendekatan ini dalam masalah adalah bahwa Anda dapat menggunakan strategi umum yang telah lama ditingkatkan oleh para ilmuwan komputer untuk mempercepat pencarian data dalam database: hashing.
Hashing memungkinkan Anda untuk dengan cepat memeriksa apakah ada nilai dalam tabel database, tanpa harus melalui setiap baris dalam satu baris. Anda menggunakan hash, mudah dihitung dengan menerapkan fungsi hash ke nilai yang diinginkan, yang menunjukkan di mana nilai ini harus disimpan dalam database. Kemudian Anda dapat memeriksa hanya satu tempat untuk mengetahui apakah nilai ini disimpan di sana.
Para peneliti melakukan sesuatu yang serupa untuk perhitungan yang berkaitan dengan jaringan saraf. Contoh berikut akan membantu menggambarkan pendekatan mereka:
Misalkan kita telah membuat jaringan saraf yang mengenali input angka tulisan tangan. Misalkan input adalah piksel abu-abu dalam array 16x16, yaitu total 256 angka. Kami mengumpankan data ini ke satu lapisan tersembunyi dari 512 neuron, hasil aktivasi yang diumpankan oleh lapisan output 10 neuron, satu untuk masing-masing angka yang mungkin.
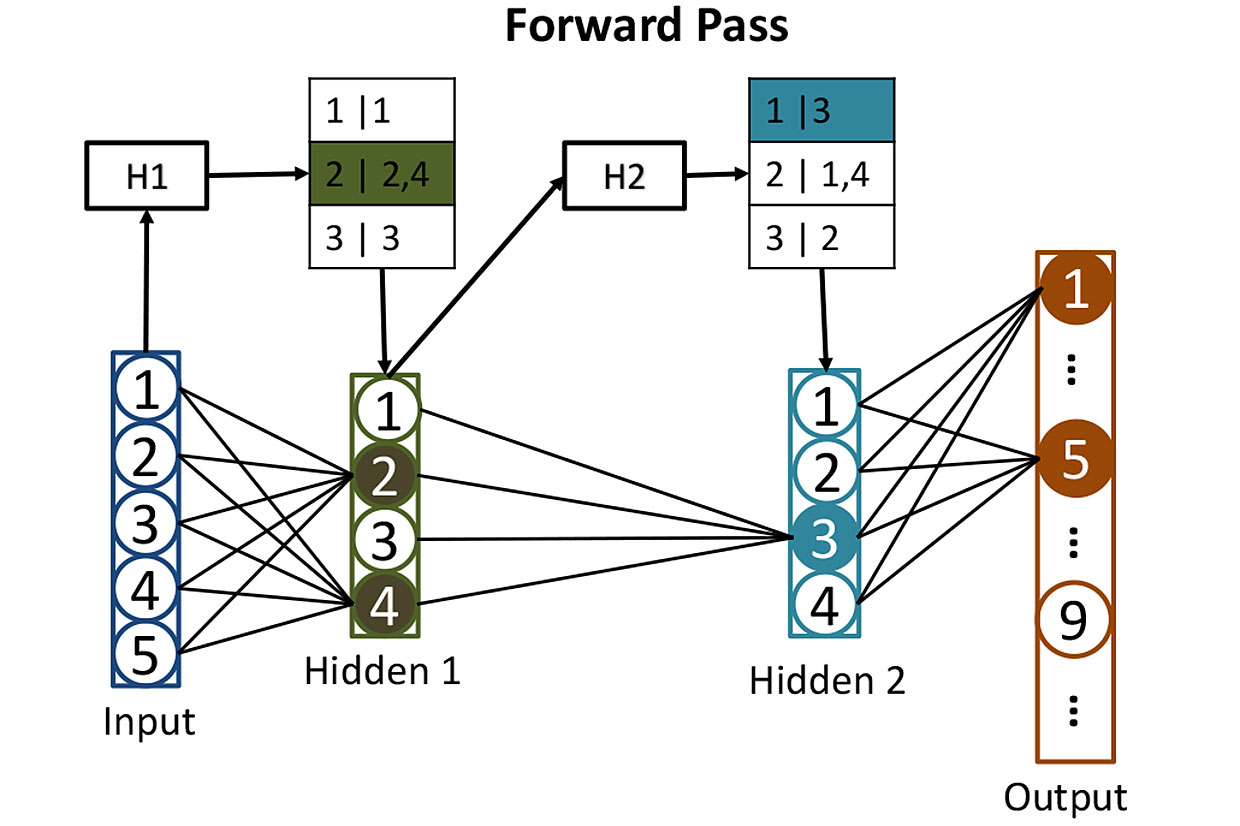 Tabel dari jaringan: sebelum menghitung aktivasi neuron di lapisan tersembunyi, kami menggunakan hash untuk membantu kami menentukan neuron mana yang akan diaktifkan. Di sini, hash dari nilai input H1 digunakan untuk mencari neuron yang sesuai di lapisan tersembunyi pertama - dalam hal ini mereka akan menjadi neuron 2 dan 4. Hash kedua H2 menunjukkan neuron mana dari lapisan tersembunyi kedua yang akan berkontribusi. Strategi seperti itu mengurangi jumlah aktivasi yang perlu dihitung.
Tabel dari jaringan: sebelum menghitung aktivasi neuron di lapisan tersembunyi, kami menggunakan hash untuk membantu kami menentukan neuron mana yang akan diaktifkan. Di sini, hash dari nilai input H1 digunakan untuk mencari neuron yang sesuai di lapisan tersembunyi pertama - dalam hal ini mereka akan menjadi neuron 2 dan 4. Hash kedua H2 menunjukkan neuron mana dari lapisan tersembunyi kedua yang akan berkontribusi. Strategi seperti itu mengurangi jumlah aktivasi yang perlu dihitung.Sangat sulit untuk melatih jaringan seperti itu, tetapi untuk sekarang mari kita hilangkan momen ini dan bayangkan bahwa kita telah menyesuaikan semua bobot masing-masing neuron sehingga jaringan saraf mengenali angka tulisan tangan dengan sempurna. Ketika angka yang ditulis dengan jelas tiba di inputnya, aktivasi salah satu neuron output (sesuai dengan nomor ini) akan mendekati 1. Aktivasi sembilan lainnya akan mendekati 0. Secara klasik, operasi jaringan semacam itu membutuhkan satu penggandaan matriks untuk masing-masing 512 neuron yang tersembunyi, dan satu lagi untuk setiap akhir pekan - yang memberi kami banyak multiplikasi.
Peneliti mengambil pendekatan yang berbeda. Langkah pertama adalah untuk hash bobot masing-masing dari 512 neuron di lapisan tersembunyi menggunakan "hashing sensitifitas lokalitas", salah satu sifatnya adalah bahwa data input yang sama memberikan nilai hash yang serupa. Anda kemudian dapat mengelompokkan neuron dengan hash yang serupa, yang berarti neuron ini memiliki bobot yang serupa. Setiap kelompok dapat disimpan dalam database, dan ditentukan oleh hash dari nilai input yang akan mengarah pada aktivasi kelompok neuron ini.
Setelah semua hashing ini, ternyata mudah untuk menentukan neuron tersembunyi mana yang akan diaktifkan oleh beberapa input baru. Anda perlu menjalankan 256 nilai input melalui fungsi hash yang mudah dihitung, dan gunakan hasilnya untuk mencari di database untuk neuron yang akan diaktifkan. Dengan cara ini, Anda harus menghitung nilai aktivasi hanya untuk beberapa neuron yang penting. Tidak perlu menghitung aktivasi semua neuron lain dalam lapisan hanya untuk mengetahui bahwa mereka tidak berkontribusi pada hasilnya.
Input dari jaringan data saraf seperti itu dapat direpresentasikan sebagai pelaksanaan permintaan pencarian ke database yang meminta untuk menemukan semua neuron yang akan diaktifkan dengan penghitungan langsung. Anda mendapatkan jawabannya dengan cepat karena Anda menggunakan hash untuk mencari. Dan kemudian Anda bisa menghitung aktivasi sejumlah kecil neuron yang sangat penting.
Para peneliti telah menggunakan teknik ini, yang mereka sebut SLIDE (Sub-Learear Deep Learning Engine), untuk melatih jaringan saraf - untuk proses yang memiliki lebih banyak permintaan komputasi daripada yang dilakukannya untuk tujuan yang dimaksudkan. Mereka kemudian membandingkan kinerja algoritma pembelajaran dengan pendekatan yang lebih tradisional menggunakan GPU yang kuat - khususnya, GPU Nvidia V100. Hasilnya, mereka mendapatkan sesuatu yang luar biasa: "Hasil kami menunjukkan bahwa rata-rata teknologi CPU SLIDE dapat bekerja lebih cepat daripada alternatif terbaik yang mungkin, diimplementasikan pada peralatan terbaik dan dengan akurasi apa pun."
Masih terlalu dini untuk menarik kesimpulan tentang apakah hasil ini (yang belum dievaluasi oleh para ahli) akan tahan terhadap tes dan apakah mereka akan memaksa produsen chip untuk melihat secara berbeda pada pengembangan peralatan khusus untuk pembelajaran mendalam. Tetapi pekerjaan tersebut secara jelas menekankan bahaya entrainment dari jenis besi tertentu dalam kasus-kasus di mana ada kemungkinan algoritma baru dan lebih baik untuk pengoperasian jaringan saraf.