Biasanya, Nginx menggunakan produk komersial atau alternatif open-source, seperti Prometheus + Grafana, untuk memantau dan menganalisis kinerja Nginx. Ini adalah opsi yang baik untuk pemantauan atau analitik waktu nyata, tetapi tidak terlalu nyaman untuk analisis historis. Pada sumber daya populer apa pun, jumlah data dari log nginx tumbuh dengan cepat, dan logis untuk menggunakan sesuatu yang lebih khusus untuk menganalisis sejumlah besar data.
Pada artikel ini saya akan memberi tahu Anda cara menggunakan Athena untuk menganalisis log menggunakan Nginx sebagai contoh, dan menunjukkan cara mengkompilasi dashboard analitis dari data ini menggunakan kerangka cube.js open-source. Berikut adalah arsitektur solusi lengkap:

TL: DR;
Tautan ke dasbor jadi .
Kami menggunakan Fluentd untuk mengumpulkan informasi, AWS Kinesis Data Firehose dan AWS Glue untuk diproses, dan AWS S3 untuk penyimpanan. Dengan bundel ini Anda dapat menyimpan tidak hanya log nginx, tetapi juga acara lainnya, serta log layanan lainnya. Anda dapat mengganti beberapa bagian dengan bagian yang serupa untuk tumpukan Anda, misalnya, Anda dapat menulis log ke kinesis langsung dari nginx, mem-bypass fluentd, atau menggunakan logstash untuk ini.
Mengumpulkan Log Nginx
Secara default, log Nginx terlihat seperti ini:
4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-up HTTP/2.0" 200 9168 "https://example.com/sign-in" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-" 4/9/2019 12:58:17 PM1.1.1.1 - - [09/Apr/2019:09:58:17 +0000] "GET /sign-in HTTP/2.0" 200 9168 "https://example.com/sign-up" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36" "-"
Mereka dapat diuraikan, tetapi jauh lebih mudah untuk memperbaiki konfigurasi Nginx sehingga menampilkan log di JSON:
log_format json_combined escape=json '{ "created_at": "$msec", ' '"remote_addr": "$remote_addr", ' '"remote_user": "$remote_user", ' '"request": "$request", ' '"status": $status, ' '"bytes_sent": $bytes_sent, ' '"request_length": $request_length, ' '"request_time": $request_time, ' '"http_referrer": "$http_referer", ' '"http_x_forwarded_for": "$http_x_forwarded_for", ' '"http_user_agent": "$http_user_agent" }'; access_log /var/log/nginx/access.log json_combined;
S3 untuk penyimpanan
Untuk menyimpan log, kami akan menggunakan S3. Ini memungkinkan Anda untuk menyimpan dan menganalisis log di satu tempat, karena Athena dapat bekerja dengan data dalam S3 secara langsung. Nanti di artikel saya akan memberitahu Anda cara melipat dan memproses log dengan benar, tetapi pertama-tama kita perlu ember bersih dalam S3, di mana tidak ada lagi yang akan disimpan. Sebaiknya pikirkan terlebih dahulu di wilayah mana Anda akan membuat ember, karena Athena tidak tersedia di semua wilayah.
Buat diagram di konsol Athena
Buat tabel di Athena untuk log. Ini diperlukan untuk menulis dan membaca, jika Anda berencana menggunakan Kinesis Firehose. Buka konsol Athena dan buat tabel:
Pembuatan tabel SQL CREATE EXTERNAL TABLE `kinesis_logs_nginx`( `created_at` double, `remote_addr` string, `remote_user` string, `request` string, `status` int, `bytes_sent` int, `request_length` int, `request_time` double, `http_referrer` string, `http_x_forwarded_for` string, `http_user_agent` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 's3://<YOUR-S3-BUCKET>' TBLPROPERTIES ('has_encrypted_data'='false');
Buat Kinesis Firehose Stream
Kinesis Firehose akan menulis data yang diterima dari Nginx ke S3 dalam format yang dipilih, dibagi menjadi direktori dalam format YYYY / MM / DD / HH. Ini berguna saat membaca data. Anda tentu saja dapat menulis langsung ke S3 dari fluentd, tetapi dalam hal ini Anda harus menulis JSON, yang tidak efisien karena ukuran file yang besar. Selain itu, saat menggunakan PrestoDB atau Athena, JSON adalah format data paling lambat. Jadi buka konsol Firehose Kinesis, klik "Buat aliran pengiriman", pilih "PUT langsung" di bidang "pengiriman":
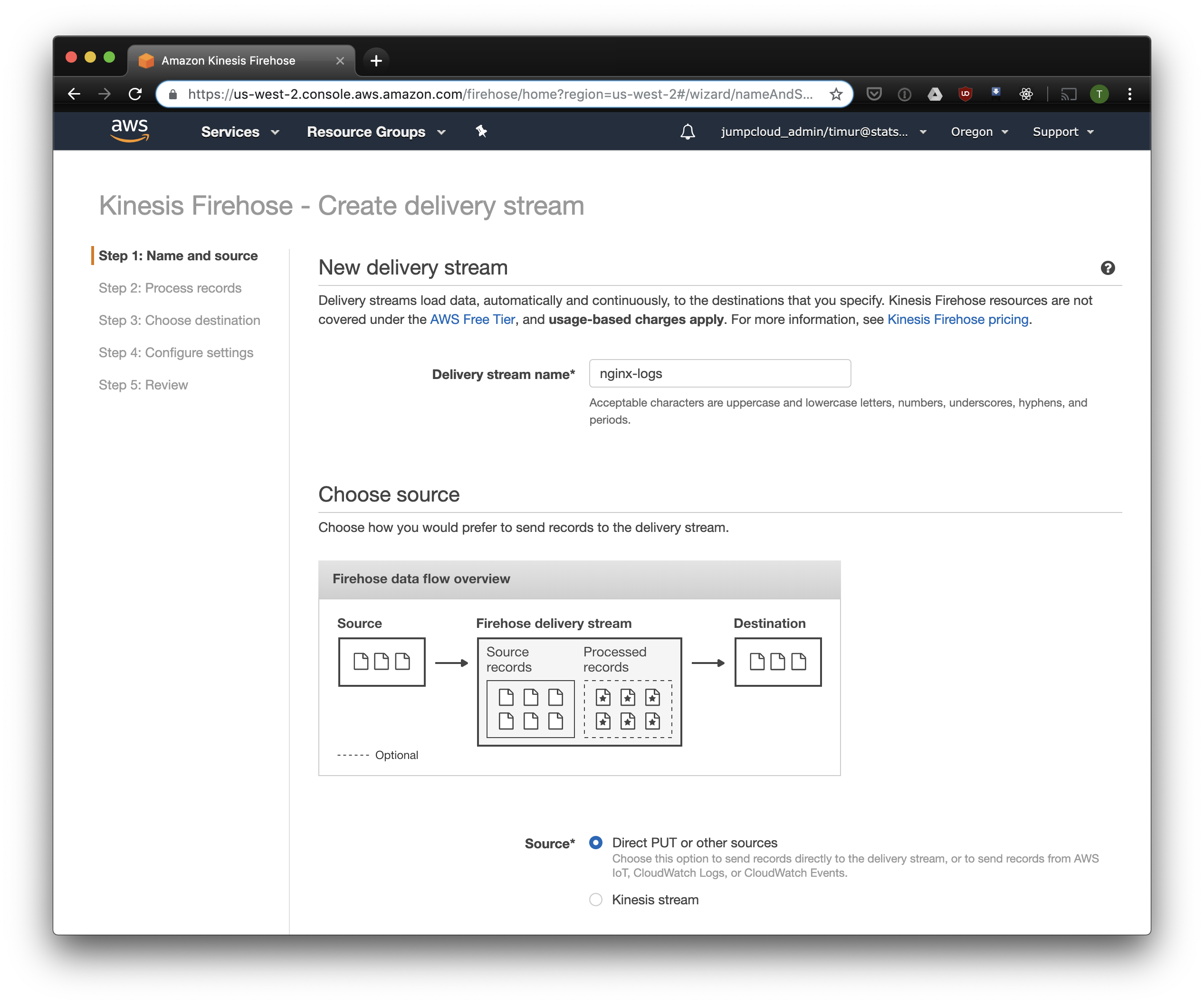
Pada tab berikutnya, pilih "Rekam konversi format" - "Diaktifkan" dan pilih "Apache ORC" sebagai format untuk perekaman. Menurut beberapa Owen O'Malley , ini adalah format optimal untuk PrestoDB dan Athena. Sebagai diagram, kami menunjukkan tabel yang kami buat di atas. Harap dicatat bahwa Anda dapat menentukan lokasi S3 di kinesis, hanya skema yang digunakan dari tabel. Tetapi jika Anda menentukan lokasi S3 lain, maka membaca catatan ini dari tabel ini tidak akan berfungsi.
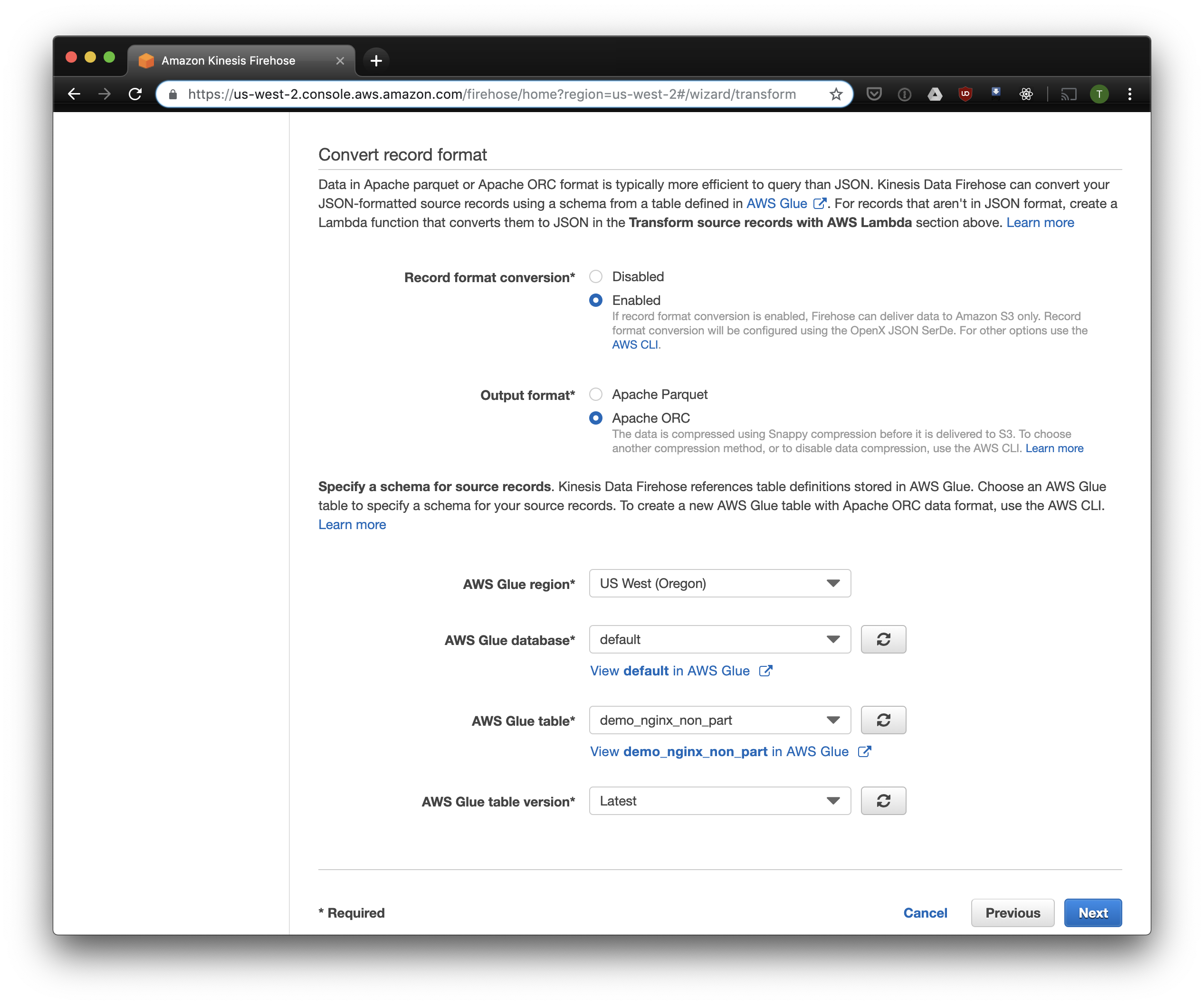
Kami memilih S3 untuk penyimpanan dan ember yang kami buat sebelumnya. Aws Glue Crawler, yang akan saya bicarakan nanti, tidak tahu cara bekerja dengan awalan di bucket S3, jadi penting untuk membiarkannya kosong.

Opsi yang tersisa dapat diubah tergantung pada beban Anda, saya biasanya menggunakan yang standar. Perhatikan bahwa kompresi S3 tidak tersedia, tetapi ORC menggunakan kompresi asli secara default.
Fluentd
Sekarang kami telah mengkonfigurasi penyimpanan dan penerimaan log, Anda perlu mengkonfigurasi pengiriman. Kami akan menggunakan Fluentd karena saya suka Ruby, tetapi Anda dapat menggunakan Logstash atau mengirim log ke kinesis secara langsung. Anda dapat memulai server Fluentd dengan beberapa cara, saya akan berbicara tentang buruh pelabuhan, karena sederhana dan nyaman.
Pertama, kita memerlukan file konfigurasi fluent.conf. Buat dan tambahkan sumber:
ketik maju
port 24224
ikat 0.0.0.0
Sekarang Anda dapat memulai server Fluentd. Jika Anda memerlukan konfigurasi lebih lanjut, Docker Hub memiliki panduan terperinci, termasuk cara merakit gambar Anda.
$ docker run \ -d \ -p 24224:24224 \ -p 24224:24224/udp \ -v /data:/fluentd/log \ -v <PATH-TO-FLUENT-CONF>:/fluentd/etc fluentd \ -c /fluentd/etc/fluent.conf fluent/fluentd:stable
Konfigurasi ini menggunakan jalur /fluentd/log ke cache log sebelum mengirim. Anda dapat melakukannya tanpa ini, tetapi kemudian ketika Anda me-restart, Anda bisa kehilangan semua yang di-cache oleh kerja yang berlebihan. Port apa pun juga dapat digunakan, 24224 adalah port Fluentd default.
Sekarang kami telah menjalankan Fluentd, kami dapat mengirim log Nginx di sana. Kami biasanya menjalankan Nginx dalam wadah Docker, dalam hal ini Docker memiliki driver log asli untuk Fluentd:
$ docker run \ --log-driver=fluentd \ --log-opt fluentd-address=<FLUENTD-SERVER-ADDRESS>\ --log-opt tag=\"{{.Name}}\" \ -v /some/content:/usr/share/nginx/html:ro \ -d \ nginx
Jika Anda menjalankan Nginx secara berbeda, Anda dapat menggunakan file log, Fluentd memiliki plugin file tail .
Tambahkan parsing log yang dikonfigurasi di atas ke konfigurasi Fasih:
<filter YOUR-NGINX-TAG.*> @type parser key_name log emit_invalid_record_to_error false <parse> @type json </parse> </filter>
Dan mengirim log ke Kinesis menggunakan plugin firehose kinesis :
<match YOUR-NGINX-TAG.*> @type kinesis_firehose region region delivery_stream_name <YOUR-KINESIS-STREAM-NAME> aws_key_id <YOUR-AWS-KEY-ID> aws_sec_key <YOUR_AWS-SEC_KEY> </match>
Athena
Jika Anda mengonfigurasi semuanya dengan benar, maka setelah beberapa saat (secara default, Kinesis menulis data yang diterima setiap 10 menit) Anda akan melihat file log dalam S3. Di menu "monitoring" Kinesis Firehose, Anda dapat melihat berapa banyak data yang ditulis ke S3, serta kesalahan. Jangan lupa untuk memberikan akses tulis ke Bucket S3 untuk peran Kinesis. Jika Kinesis tidak dapat menguraikan sesuatu, ia akan menambahkan kesalahan dalam keranjang yang sama.
Sekarang Anda dapat melihat data di Athena. Mari temukan beberapa pertanyaan baru yang kami berikan kesalahan:
SELECT * FROM "db_name"."table_name" WHERE status > 499 ORDER BY created_at DESC limit 10;
Pindai semua catatan untuk setiap permintaan
Sekarang log kami diproses dan ditumpuk dalam S3 dalam ORC, dikompresi dan siap untuk dianalisis. Kinesis Firehose bahkan menempatkannya di direktori setiap jam. Namun, sementara tabel tidak dipartisi, Athena akan memuat data sepanjang waktu untuk setiap kueri, dengan pengecualian langka. Ini adalah masalah besar karena dua alasan:
- Jumlah data terus bertambah, memperlambat permintaan;
- Athena ditagih berdasarkan jumlah data yang dipindai, dengan minimum 10 MB untuk setiap permintaan.
Untuk memperbaikinya, kami menggunakan AWS Glue Crawler, yang akan memindai data dalam S3 dan merekam informasi partisi di Glue Metastore. Ini akan memungkinkan kami untuk menggunakan partisi sebagai filter untuk permintaan di Athena, dan itu hanya akan memindai direktori yang ditentukan dalam permintaan.
Kustomisasi Amazon Glue Crawler
Amazon Glue Crawler memindai semua data dalam bucket S3 dan membuat tabel partisi. Buat Glue Crawler dari konsol AWS Glue dan tambahkan bucket tempat Anda menyimpan data. Anda dapat menggunakan satu perayap untuk beberapa kotak, dalam hal ini ini akan membuat tabel dalam database yang ditentukan dengan nama yang cocok dengan nama kotak. Jika Anda berencana untuk menggunakan data ini sepanjang waktu, pastikan untuk menyesuaikan jadwal peluncuran Crawler sesuai dengan kebutuhan Anda. Kami menggunakan satu Crawler untuk semua tabel, yang berjalan setiap jam.
Tabel dipartisi
Setelah mulai pertama perayap, tabel untuk setiap ember yang dipindai harus muncul dalam database yang ditentukan dalam pengaturan. Buka konsol Athena dan temukan tabel dengan log Nginx. Mari kita coba membaca sesuatu:
SELECT * FROM "default"."part_demo_kinesis_bucket" WHERE( partition_0 = '2019' AND partition_1 = '04' AND partition_2 = '08' AND partition_3 = '06' );
Kueri ini akan memilih semua catatan yang diterima dari 6 pagi hingga 7 pagi pada 8 April 2019. Tetapi seberapa jauh lebih efektif daripada hanya membaca dari tabel yang tidak dipartisi? Mari cari tahu dan pilih catatan yang sama dengan memfilternya dengan stempel waktu:
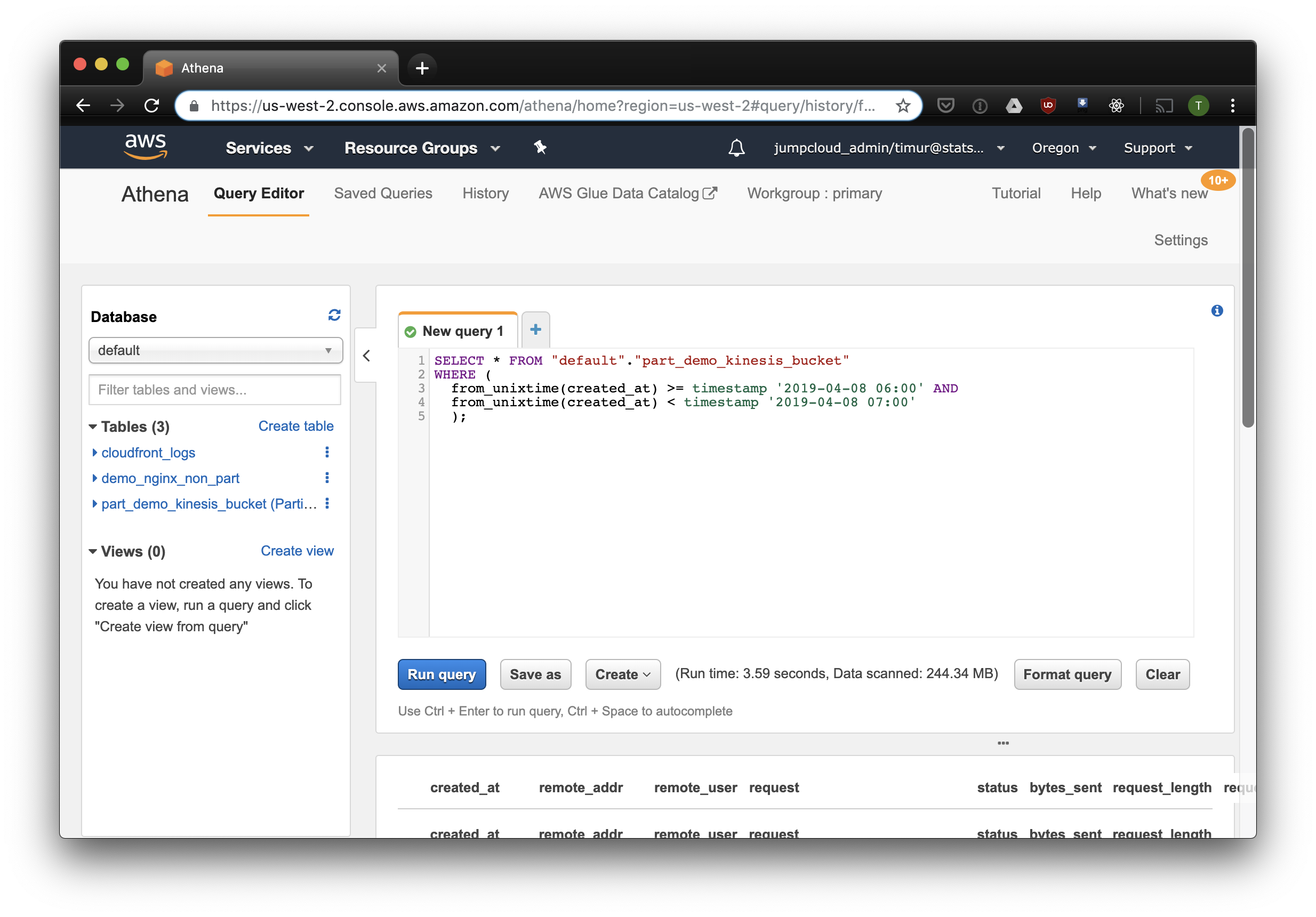
3,59 detik dan 244,34 megabita data pada dataset, di mana hanya ada satu minggu log. Mari kita coba filter berdasarkan partisi:
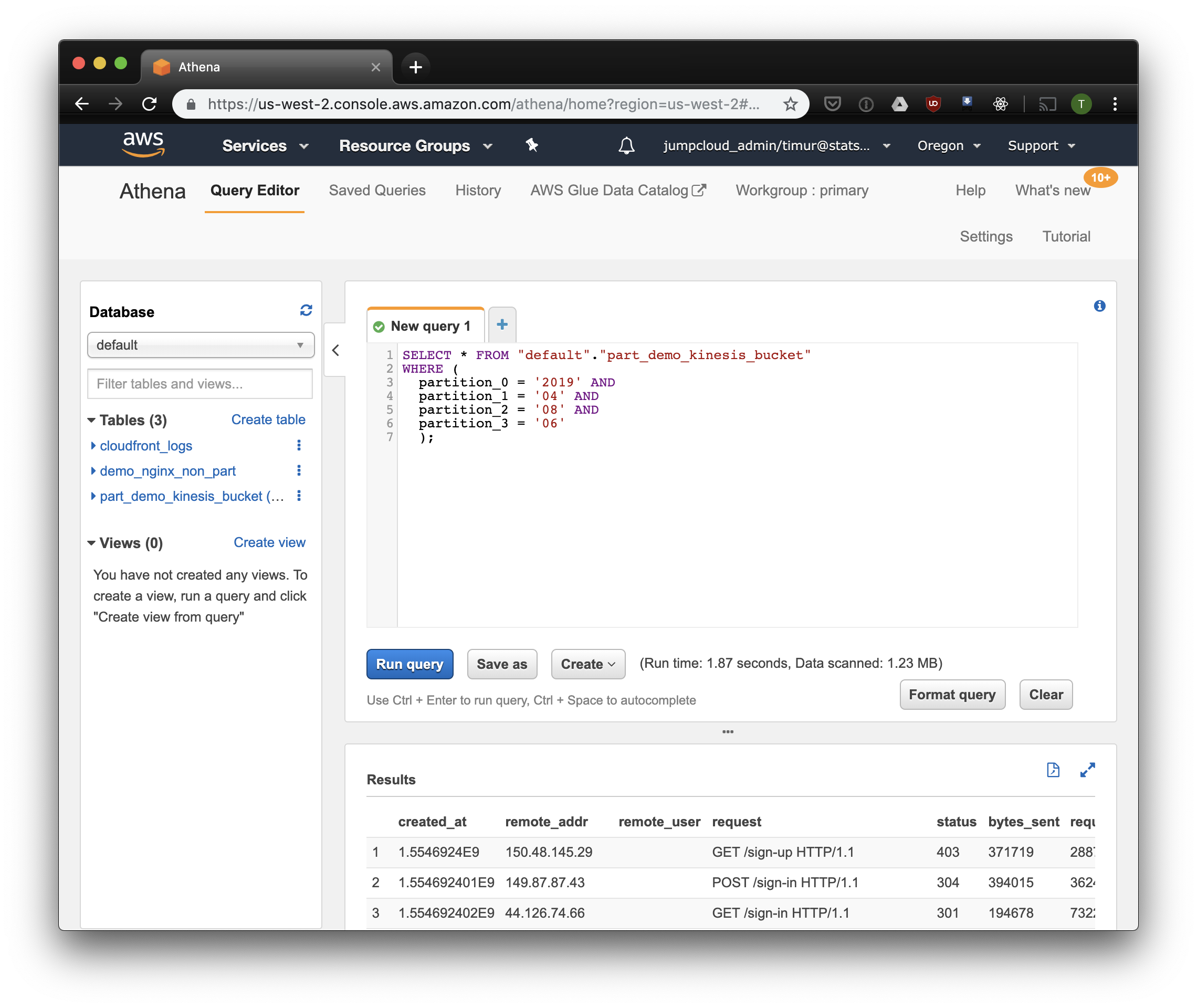
Sedikit lebih cepat, tetapi yang paling penting - hanya 1,23 megabita data! Akan jauh lebih murah jika bukan untuk harga minimum 10 megabyte per permintaan. Namun itu jauh lebih baik, dan pada dataset besar perbedaannya akan jauh lebih mengesankan.
Buat dasbor menggunakan Cube.js
Untuk membangun dasbor, kami menggunakan kerangka analitik Cube.js. Ini memiliki beberapa fungsi, tetapi kami tertarik pada dua: kemampuan untuk secara otomatis menggunakan filter pada partisi dan pra-agregasi data. Ini menggunakan skema data yang ditulis dalam Javascript untuk menghasilkan SQL dan mengeksekusi query database. Semua yang diperlukan dari kami adalah untuk menunjukkan cara menggunakan filter partisi dalam skema data.
Ayo buat aplikasi baru Cube.js. Karena kita sudah menggunakan AWS-stack, logis untuk menggunakan Lambda untuk penyebaran. Anda bisa menggunakan templat ekspres untuk pembuatan jika Anda berencana untuk meng-host backend Cube.js di Heroku atau Docker. Dokumentasi menjelaskan metode hosting lainnya.
$ npm install -g cubejs-cli $ cubejs create nginx-log-analytics -t serverless -d athena
Variabel lingkungan digunakan untuk mengonfigurasi akses ke database di cube.js. Generator akan membuat file .env di mana Anda dapat menentukan kunci untuk Athena .
Sekarang kita membutuhkan skema data di mana kita menunjukkan bagaimana log kita disimpan. Di sana Anda dapat menentukan cara membaca metrik untuk dasbor.
Di direktori schema , buat file Logs.js Berikut adalah contoh model data untuk nginx:
Kode model const partitionFilter = (from, to) => ` date(from_iso8601_timestamp(${from})) <= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') AND date(from_iso8601_timestamp(${to})) >= date_parse(partition_0 || partition_1 || partition_2, '%Y%m%d') ` cube(`Logs`, { sql: ` select * from part_demo_kinesis_bucket WHERE ${FILTER_PARAMS.Logs.createdAt.filter(partitionFilter)} `, measures: { count: { type: `count`, }, errorCount: { type: `count`, filters: [ { sql: `${CUBE.isError} = 'Yes'` } ] }, errorRate: { type: `number`, sql: `100.0 * ${errorCount} / ${count}`, format: `percent` } }, dimensions: { status: { sql: `status`, type: `number` }, isError: { type: `string`, case: { when: [{ sql: `${CUBE}.status >= 400`, label: `Yes` }], else: { label: `No` } } }, createdAt: { sql: `from_unixtime(created_at)`, type: `time` } } });
Di sini kita menggunakan variabel FILTER_PARAMS untuk menghasilkan kueri SQL dengan filter partisi.
Kami juga menentukan metrik dan parameter yang ingin kami tampilkan di dasbor, dan menentukan pra-agregasi. Cube.js akan membuat tabel tambahan dengan data pra-agregat dan secara otomatis memperbarui data begitu tersedia. Ini tidak hanya mempercepat permintaan, tetapi juga mengurangi biaya menggunakan Athena.
Tambahkan informasi ini ke file skema data:
preAggregations: { main: { type: `rollup`, measureReferences: [count, errorCount], dimensionReferences: [isError, status], timeDimensionReference: createdAt, granularity: `day`, partitionGranularity: `month`, refreshKey: { sql: FILTER_PARAMS.Logs.createdAt.filter((from, to) => `select CASE WHEN from_iso8601_timestamp(${to}) + interval '3' day > now() THEN date_trunc('hour', now()) END` ) } } }
Dalam model ini, kami menunjukkan bahwa perlu untuk melakukan agregat data untuk semua metrik yang digunakan, dan untuk menggunakan partisi bulanan. Mempartisi pra-agregasi dapat secara signifikan mempercepat pengumpulan dan pembaruan data.
Sekarang kita bisa membuat dashboard!
Backend Cube.js menyediakan REST API dan satu set perpustakaan klien untuk kerangka kerja front-end yang populer. Kami akan menggunakan versi Bereaksi klien untuk membangun dasbor. Cube.js hanya menyediakan data, jadi kami membutuhkan pustaka untuk visualisasi - Saya suka restart , tetapi Anda bisa menggunakan apa saja.
Server Cube.js menerima permintaan dalam format JSON , yang menunjukkan metrik yang diperlukan. Misalnya, untuk menghitung berapa banyak kesalahan yang diberikan Nginx per hari, Anda perlu mengirim permintaan berikut:
{ "measures": ["Logs.errorCount"], "timeDimensions": [ { "dimension": "Logs.createdAt", "dateRange": ["2019-01-01", "2019-01-07"], "granularity": "day" } ] }
Instal klien Cube.js dan React library komponen melalui NPM:
$ npm i --save @cubejs-client/core @cubejs-client/react
Kami mengimpor komponen cubejs dan QueryRenderer untuk membongkar data, dan mengumpulkan dasbor:
Kode dasbor import React from 'react'; import { LineChart, Line, XAxis, YAxis } from 'recharts'; import cubejs from '@cubejs-client/core'; import { QueryRenderer } from '@cubejs-client/react'; const cubejsApi = cubejs( 'YOUR-CUBEJS-API-TOKEN', { apiUrl: 'http://localhost:4000/cubejs-api/v1' }, ); export default () => { return ( <QueryRenderer query={{ measures: ['Logs.errorCount'], timeDimensions: [{ dimension: 'Logs.createdAt', dateRange: ['2019-01-01', '2019-01-07'], granularity: 'day' }] }} cubejsApi={cubejsApi} render={({ resultSet }) => { if (!resultSet) { return 'Loading...'; } return ( <LineChart data={resultSet.rawData()}> <XAxis dataKey="Logs.createdAt"/> <YAxis/> <Line type="monotone" dataKey="Logs.errorCount" stroke="#8884d8"/> </LineChart> ); }} /> ) }
Sumber dasbor tersedia di CodeSandbox .