Bulan lalu di NVIDIA GTC 2019, NVIDIA memperkenalkan aplikasi baru yang mengubah bola berwarna sederhana yang dibuat pengguna menjadi gambar yang realistis dan memukau foto.
Aplikasi ini dibangun di atas teknologi
jaringan generatif-kompetitif (GAN), yang didasarkan pada pembelajaran yang mendalam. NVIDIA sendiri menyebutnya GauGAN - sebuah pelesetan yang dimaksudkan untuk merujuk pada artis Paul Gauguin. Fungsionalitas GauGAN didasarkan pada algoritma SPADE baru.
Pada artikel ini, saya akan menjelaskan cara kerja mahakarya rekayasa ini. Dan untuk menarik sebanyak mungkin pembaca yang tertarik, saya akan mencoba memberikan deskripsi rinci tentang cara kerja jaringan saraf convolutional. Karena SPADE adalah jaringan kompetitif generatif, saya akan memberi tahu Anda lebih banyak tentang mereka. Tetapi jika Anda sudah terbiasa dengan istilah ini, Anda dapat langsung pergi ke bagian "Siaran gambar-ke-gambar".
Generasi gambar
Mari kita mulai memahami: dalam sebagian besar aplikasi pembelajaran dalam modern, tipe diskriminan saraf (diskriminator) digunakan, dan SPADE adalah jaringan saraf generatif (generator).
Diskriminator
Diskriminator mengklasifikasikan data input. Misalnya, penggolong gambar adalah pembeda yang mengambil gambar dan memilih satu label kelas yang sesuai, misalnya, mendefinisikan gambar sebagai "anjing", "mobil" atau "lampu lalu lintas", yaitu, memilih label yang menggambarkan seluruh gambar. Output yang diperoleh oleh classifier biasanya disajikan sebagai vektor angka
dimana
Adalah angka dari 0 hingga 1, menyatakan kepercayaan jaringan bahwa gambar itu milik orang yang dipilih
kelas.
Diskriminator juga dapat menyusun daftar klasifikasi. Itu dapat mengklasifikasikan setiap piksel dari suatu gambar sebagai milik kelas "orang" atau "mesin" (disebut "segmentasi semantik").
 Pengklasifikasi mengambil gambar dengan 3 saluran (merah, hijau dan biru) dan membandingkannya dengan vektor kepercayaan di setiap kelas yang mungkin diwakili oleh gambar tersebut.
Pengklasifikasi mengambil gambar dengan 3 saluran (merah, hijau dan biru) dan membandingkannya dengan vektor kepercayaan di setiap kelas yang mungkin diwakili oleh gambar tersebut.Karena koneksi antara gambar dan kelasnya sangat kompleks, jaringan saraf melewatkannya melalui tumpukan banyak lapisan, yang masing-masing "sedikit" memprosesnya dan mentransfer hasilnya ke tingkat interpretasi berikutnya.
Generator
Jaringan generatif seperti SPADE menerima dataset dan berupaya membuat data asli baru yang sepertinya milik kelas data ini. Pada saat yang sama, data dapat berupa apa saja: suara, bahasa atau hal lain, tetapi kami akan fokus pada gambar. Secara umum, entri data ke dalam jaringan semacam itu hanyalah sebuah vektor angka acak, dengan masing-masing set data input yang memungkinkan menciptakan gambarnya sendiri.
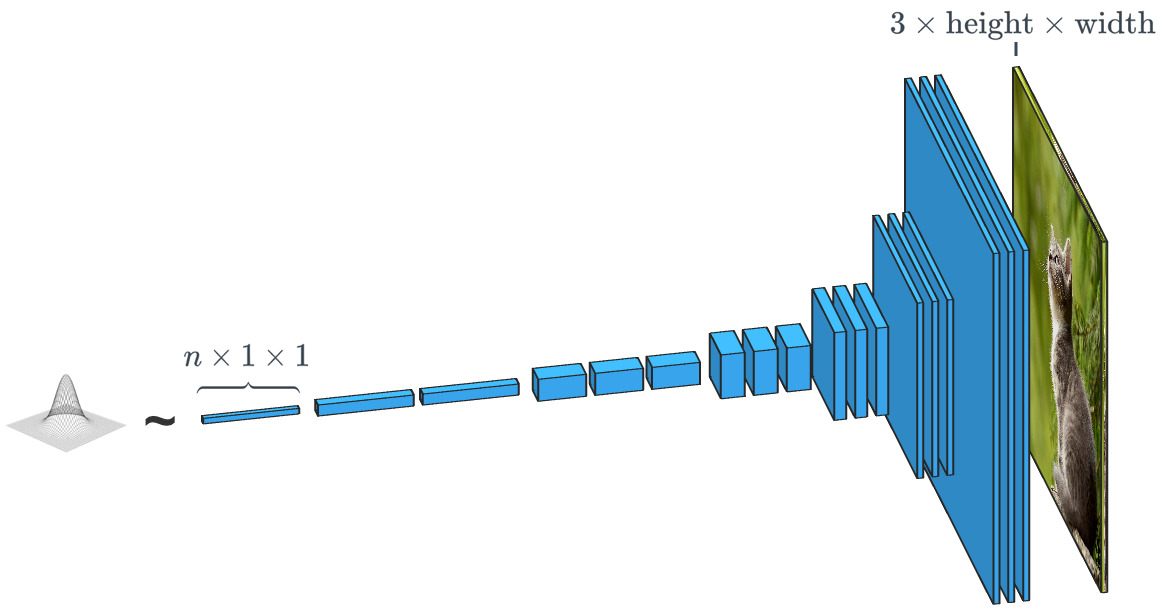 Sebuah generator yang didasarkan pada vektor input acak bekerja secara virtual berlawanan dengan classifier gambar. Dalam generator "kelas kondisional", vektor input sebenarnya adalah vektor seluruh kelas data.
Sebuah generator yang didasarkan pada vektor input acak bekerja secara virtual berlawanan dengan classifier gambar. Dalam generator "kelas kondisional", vektor input sebenarnya adalah vektor seluruh kelas data.Seperti yang telah kita lihat, SPADE menggunakan lebih dari sekedar "vektor acak". Sistem dipandu oleh semacam gambar yang disebut "peta segmentasi". Yang terakhir menunjukkan apa dan di mana memposting. SPADE melakukan proses yang berlawanan dengan segmentasi semantik yang kami sebutkan di atas. Secara umum, tugas diskriminatif yang mengubah satu tipe data ke yang lain memiliki tugas yang serupa, tetapi membutuhkan jalur yang berbeda dan tidak biasa.
Generator dan diskriminator modern biasanya menggunakan jaringan konvolusional untuk memproses data mereka. Untuk pengantar yang lebih lengkap tentang jaringan saraf convolutional (CNN), lihat posting
Chew tentang Karna atau
karya Andrei Karpati .
Ada satu perbedaan penting antara classifier dan generator gambar, dan terletak pada bagaimana tepatnya mereka mengubah ukuran gambar selama pemrosesan. Penggolong gambar harus menguranginya sampai gambar kehilangan semua informasi spasial dan hanya kelas yang tersisa. Ini dapat dicapai dengan menggabungkan lapisan, atau melalui penggunaan jaringan konvolusional melalui mana piksel individu dilewatkan. Generator, di sisi lain, menciptakan gambar menggunakan proses "konvolusi" terbalik, yang disebut transposisi konvolusional. Dia sering bingung dengan "dekonvolusi" atau
"konvolusi terbalik" .
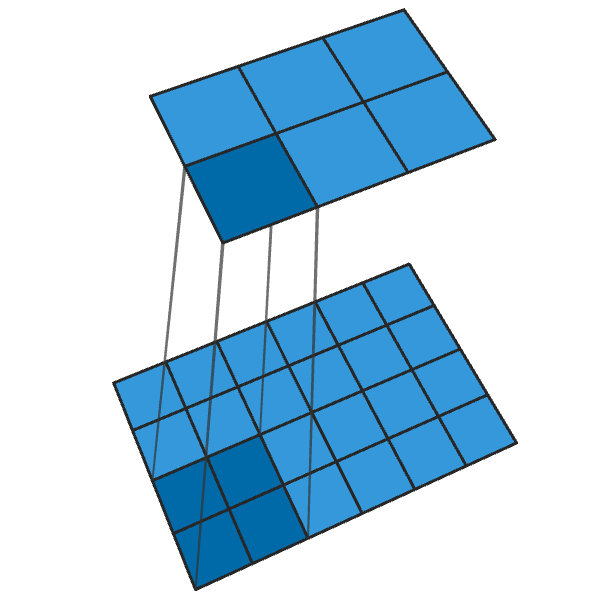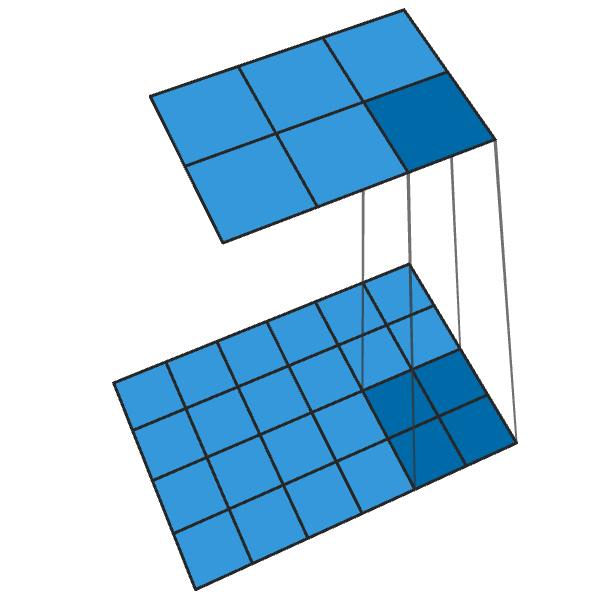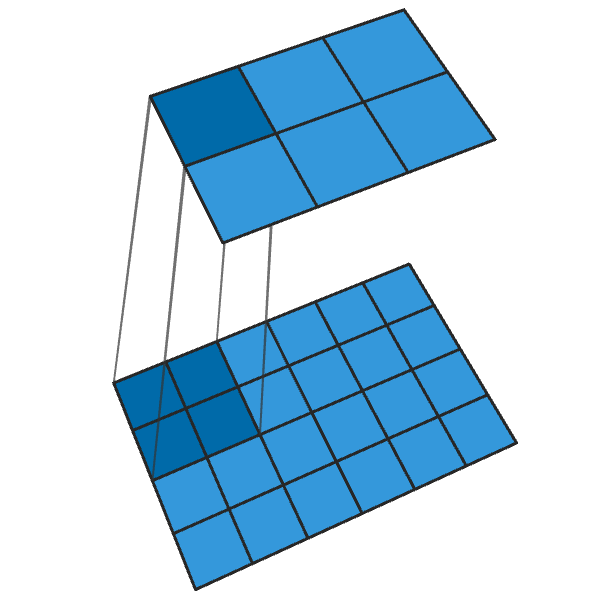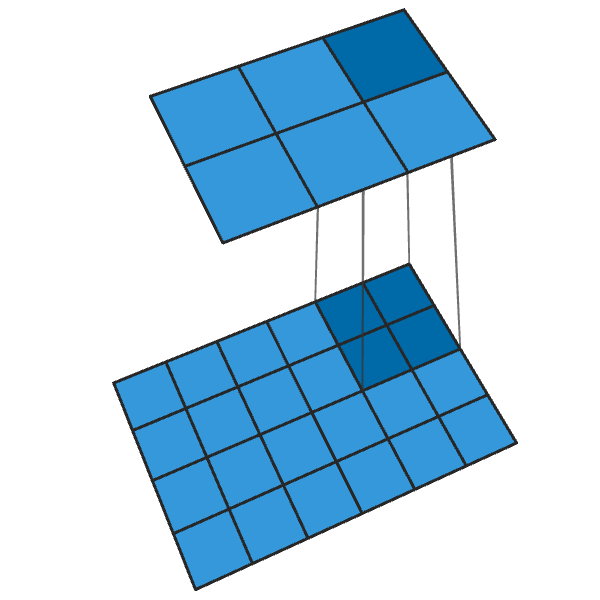
Konvolusi 2x2 konvensional dengan langkah "2" mengubah setiap blok 2x2 menjadi satu titik, mengurangi ukuran output sebesar 1/2.

Konvolusi 2x2 dengan langkah “2” menghasilkan blok 2x2 dari setiap titik, meningkatkan ukuran output sebanyak 2 kali.
Pelatihan Generator
Secara teoritis, jaringan saraf convolutional dapat menghasilkan gambar seperti yang dijelaskan di atas. Tapi bagaimana kita melatihnya? Artinya, jika kita mempertimbangkan set data input gambar, bagaimana kita bisa menyesuaikan parameter generator (dalam kasus kami, SPADE) sehingga menciptakan gambar baru yang tampak seolah-olah mereka sesuai dengan set data yang diusulkan?
Untuk melakukan ini, Anda perlu membandingkannya dengan pengklasifikasi gambar, di mana masing-masing memiliki label kelas yang benar. Mengetahui vektor prediksi jaringan dan kelas yang benar, kita dapat menggunakan algoritma backpropagation untuk menentukan parameter pembaruan jaringan. Hal ini diperlukan untuk meningkatkan akurasinya dalam menentukan kelas yang diinginkan dan mengurangi pengaruh kelas lain.
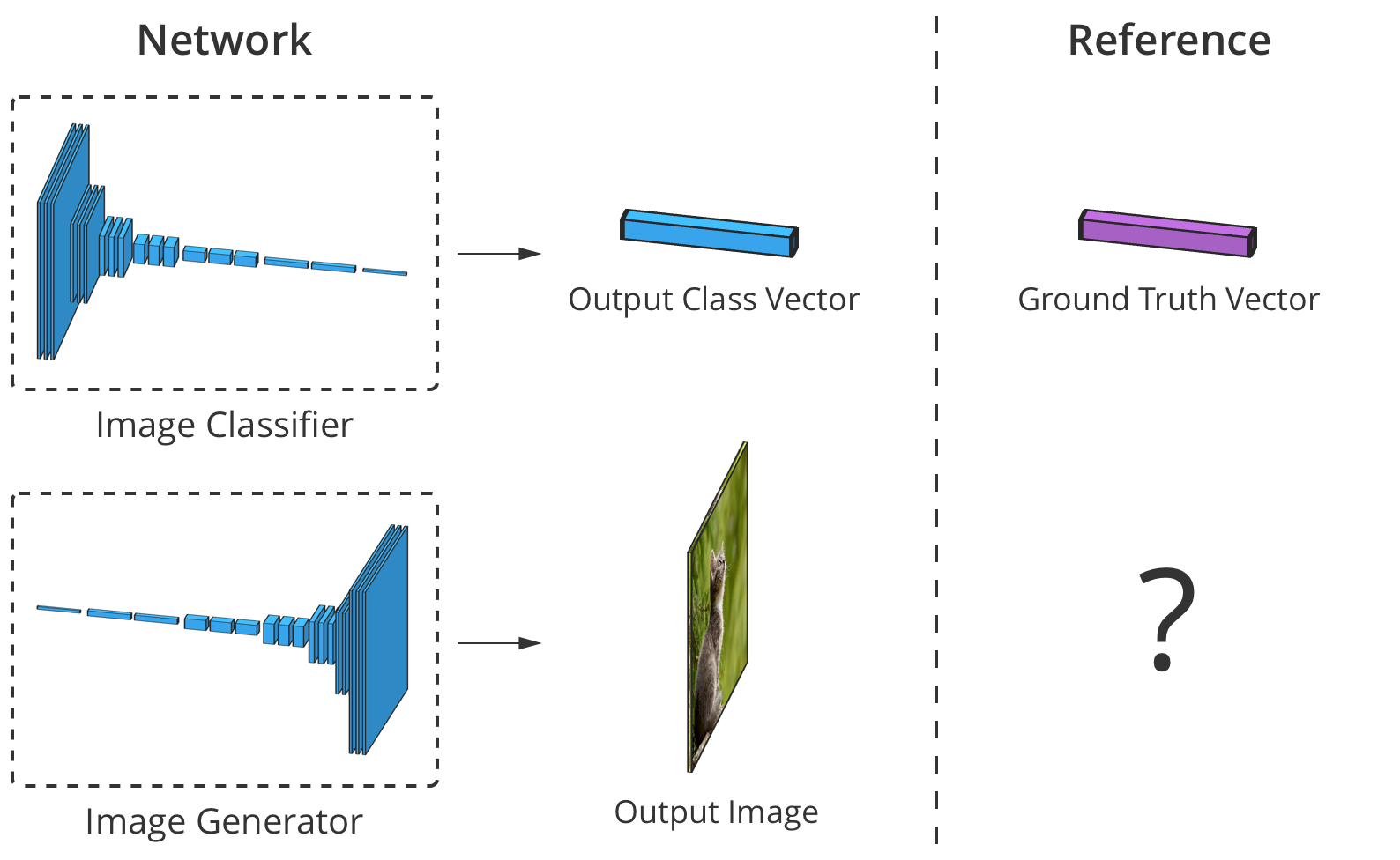 Keakuratan penggolong gambar dapat diperkirakan dengan membandingkan elemen keluarannya dengan elemen dengan vektor kelas yang benar. Tetapi untuk generator, tidak ada gambar output "benar".
Keakuratan penggolong gambar dapat diperkirakan dengan membandingkan elemen keluarannya dengan elemen dengan vektor kelas yang benar. Tetapi untuk generator, tidak ada gambar output "benar".Masalahnya adalah ketika generator membuat gambar, tidak ada nilai "benar" untuk setiap piksel (kami tidak dapat membandingkan hasilnya, seperti dalam kasus penggolong berdasarkan basis yang disiapkan sebelumnya, kira-kira Trans.). Secara teoritis, gambar apa pun yang terlihat dapat dipercaya dan mirip dengan data target adalah valid, bahkan jika nilai pikselnya sangat berbeda dari gambar sebenarnya.
Jadi, bagaimana kita bisa memberi tahu generator di mana piksel itu harus mengubah outputnya dan bagaimana ia dapat membuat gambar yang lebih realistis (yaitu bagaimana memberikan "sinyal kesalahan")? Para peneliti banyak merenungkan pertanyaan ini, dan sebenarnya itu cukup sulit. Sebagian besar ide, seperti menghitung "jarak" rata-rata ke gambar nyata, menghasilkan gambar yang buram dan berkualitas buruk.
Idealnya, kita dapat "mengukur" seberapa realistis gambar yang dihasilkan terlihat melalui penggunaan konsep "tingkat tinggi", seperti "Seberapa sulitkah untuk membedakan gambar ini dari yang asli?" ...
Jaringan permusuhan generatif
Inilah yang diterapkan sebagai bagian dari
Goodfellow et al., 2014 . Idenya adalah untuk menghasilkan gambar menggunakan dua jaringan saraf, bukan satu: satu jaringan -
generator, yang kedua adalah penggolong gambar (diskriminator). Tugas pembeda adalah untuk membedakan gambar output generator dari gambar nyata dari kumpulan data primer (kelas-gambar gambar ini ditetapkan sebagai "palsu" dan "nyata"). Tugas generator adalah untuk menipu pembeda dengan membuat gambar yang semirip mungkin dengan gambar dalam kumpulan data. Kita dapat mengatakan bahwa generator dan pembeda adalah lawan dalam proses ini. Maka dari itu namanya:
jaringan generatif-permusuhan .
Bagaimana ini membantu kita? Sekarang kita dapat menggunakan pesan kesalahan hanya berdasarkan prediksi pembeda: nilai dari 0 ("salah") ke 1 ("nyata"). Karena diskriminator adalah jaringan saraf, kita dapat membagikan kesimpulannya tentang kesalahan dengan pembuat gambar. Artinya, diskriminator dapat memberi tahu generator di mana dan bagaimana ia harus menyesuaikan gambar-gambarnya agar lebih “menipu” sang diskriminator (yaitu, bagaimana meningkatkan realisme gambar-gambarnya).
Dalam proses belajar bagaimana menemukan gambar palsu, pembeda memberi generator lebih baik dan umpan balik yang lebih baik tentang bagaimana yang terakhir dapat meningkatkan kerjanya. Dengan demikian, diskriminator melakukan fungsi
"belajar rugi" untuk generator.
GAN Kecil Yang Mulia
GAN yang kami pertimbangkan dalam kerjanya mengikuti logika yang dijelaskan di atas. Diskriminatornya
menganalisis gambar
dan mendapat nilai
dari 0 hingga 1, yang mencerminkan tingkat kepercayaannya bahwa gambar itu asli atau palsu oleh generator. Generatornya
mendapat vektor acak dari angka-angka yang terdistribusi normal
dan menampilkan gambar
yang bisa diakali oleh pembeda (pada kenyataannya, gambar ini
)
Salah satu masalah yang tidak kami diskusikan adalah bagaimana melatih GAN dan apa
fungsi kerugian yang digunakan pengembang untuk mengukur kinerja jaringan. Secara umum, fungsi kerugian harus meningkat ketika diskriminator dilatih dan berkurang saat generator dilatih. Fungsi kehilangan dari sumber GAN menggunakan dua parameter berikut. Yang pertama adalah
mewakili sejauh mana diskriminator dengan benar mengklasifikasikan gambar nyata sebagai nyata. Yang kedua adalah seberapa baik diskriminator mendeteksi gambar palsu:
$ sebaris $ \ mulai {persamaan *} \ mathcal {L} _ \ teks {GAN} (D, G) = \ underbrace {E _ {\ vec {x} \ sim p_ \ teks {data}} [\ log D ( \ vec {x})]} _ {\ text {akurasi gambar nyata}} + \ underbrace {E _ {\ vec {z} \ sim \ mathcal {N}} [\ log (1 - D (G (\ vec {z}))]} _ {\ text {akurasi on fakes}} \ end {persamaan *} $ inline $
Diskriminator
mendapatkan klaimnya bahwa gambar itu nyata. Masuk akal sejak itu
meningkat ketika diskriminator menganggap x nyata. Ketika diskriminator mendeteksi gambar palsu dengan lebih baik, nilai ekspresi juga meningkat.
(Mulai berjuang untuk 1), sejak
akan cenderung ke 0.
Dalam praktiknya, kami mengevaluasi akurasi menggunakan seluruh kumpulan gambar. Kami mengambil banyak (tetapi tidak berarti semua) gambar nyata
dan banyak vektor acak
untuk mendapatkan rata-rata sesuai dengan rumus di atas. Lalu kami memilih kesalahan umum dan satu set data.
Seiring waktu, ini mengarah ke hasil yang menarik:
 Goodfellow GAN mensimulasikan set data MNIST, TFD dan CIFAR-10. Gambar kontur adalah yang paling dekat dalam dataset ke pemalsuan yang berdekatan.
Goodfellow GAN mensimulasikan set data MNIST, TFD dan CIFAR-10. Gambar kontur adalah yang paling dekat dalam dataset ke pemalsuan yang berdekatan.Semua ini fantastis hanya 4,5 tahun yang lalu. Untungnya, seperti yang ditunjukkan SPADE dan jaringan lain, pembelajaran mesin terus berkembang dengan cepat.
Masalah pelatihan
Jaringan kompetitif generatif terkenal karena kompleksitasnya dalam persiapan dan ketidakstabilan kerja. Salah satu masalah adalah bahwa jika generator terlalu jauh mendahului pembeda dalam langkah pelatihan, maka pemilihan gambar dipersempit menjadi yang membantu menipu pembeda. Bahkan, sebagai hasilnya, melatih generator turun untuk menciptakan gambar tunggal universal untuk menipu pembeda. Masalah ini disebut "mode runtuh".

Mode runtuh GAN mirip dengan Goodfellow. Harap dicatat bahwa banyak gambar kamar tidur ini terlihat sangat mirip satu sama lain.
SumberMasalah lain adalah ketika generator secara efektif menipu pembeda
, karena itu beroperasi dengan gradien yang sangat kecil
tidak bisa mendapatkan cukup data untuk menemukan jawaban yang benar, di mana gambar ini akan terlihat lebih realistis.
Upaya para peneliti untuk memecahkan masalah ini terutama ditujukan untuk mengubah struktur fungsi kerugian. Salah satu perubahan sederhana yang diusulkan oleh
Xudong Mao et al., 2016 adalah penggantian fungsi kerugian
untuk beberapa fungsi sederhana
, yang didasarkan pada kuadrat area yang lebih kecil. Ini mengarah pada stabilisasi proses pelatihan, memperoleh gambar yang lebih baik dan lebih sedikit kemungkinan runtuh menggunakan gradien yang tidak tercampuri.
Masalah lain yang dihadapi para peneliti adalah sulitnya mendapatkan gambar beresolusi tinggi, sebagian karena gambar yang lebih detail memberikan informasi lebih banyak kepada diskriminator untuk mendeteksi gambar palsu. GAN modern mulai melatih jaringan dengan gambar beresolusi rendah dan secara bertahap menambahkan lebih banyak dan lebih banyak lapisan hingga ukuran gambar yang diinginkan tercapai.
 Penambahan lapisan secara bertahap dengan resolusi yang lebih tinggi selama pelatihan GAN secara signifikan meningkatkan stabilitas seluruh proses, serta kecepatan dan kualitas gambar yang dihasilkan.
Penambahan lapisan secara bertahap dengan resolusi yang lebih tinggi selama pelatihan GAN secara signifikan meningkatkan stabilitas seluruh proses, serta kecepatan dan kualitas gambar yang dihasilkan.Siaran gambar-ke-gambar
Sejauh ini, kita telah berbicara tentang cara menghasilkan gambar dari set input data acak. Tetapi SPADE tidak hanya menggunakan data acak. Jaringan ini menggunakan gambar yang disebut peta segmentasi: ia menetapkan kelas materi untuk setiap piksel (misalnya, rumput, kayu, air, batu, langit). Dari gambar ini, kartu SPADE dan menghasilkan apa yang tampak seperti foto. Ini disebut "Siaran gambar-ke-gambar."
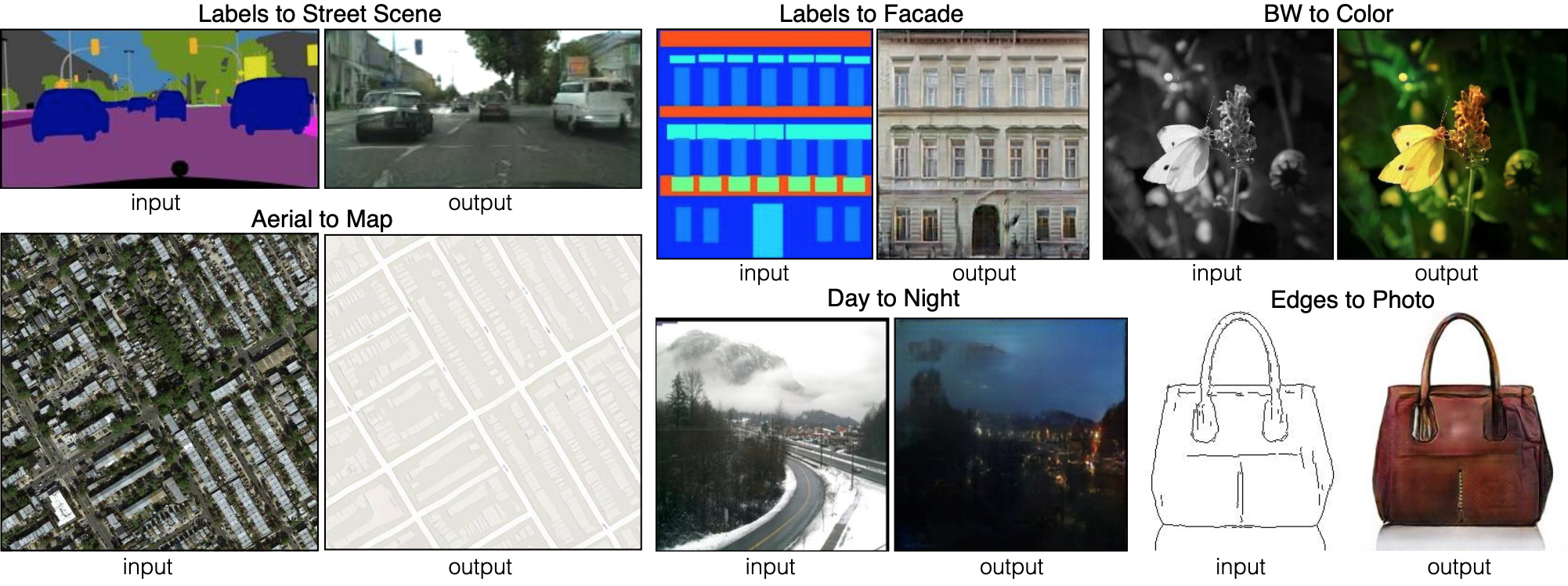 Enam jenis siaran Image-to-image yang ditunjukkan oleh pix2pix. Pix2pix adalah pendahulu dari dua jaringan, yang akan kita bahas lebih lanjut: pix2pixHD dan SPADE.
Enam jenis siaran Image-to-image yang ditunjukkan oleh pix2pix. Pix2pix adalah pendahulu dari dua jaringan, yang akan kita bahas lebih lanjut: pix2pixHD dan SPADE.Agar generator mempelajari pendekatan ini, diperlukan seperangkat peta segmentasi dan foto yang sesuai. Kami memodifikasi arsitektur GAN sehingga generator dan diskriminator menerima peta segmentasi. Generator, tentu saja, membutuhkan peta untuk mengetahui "cara menggambar". Diskriminator juga membutuhkannya untuk memastikan bahwa generator menempatkan hal yang benar di tempat yang tepat.
Selama pelatihan, generator belajar untuk tidak meletakkan rumput di mana "langit" ditunjukkan pada peta segmentasi, karena jika tidak, pembeda dapat dengan mudah mendeteksi gambar palsu, dan sebagainya.
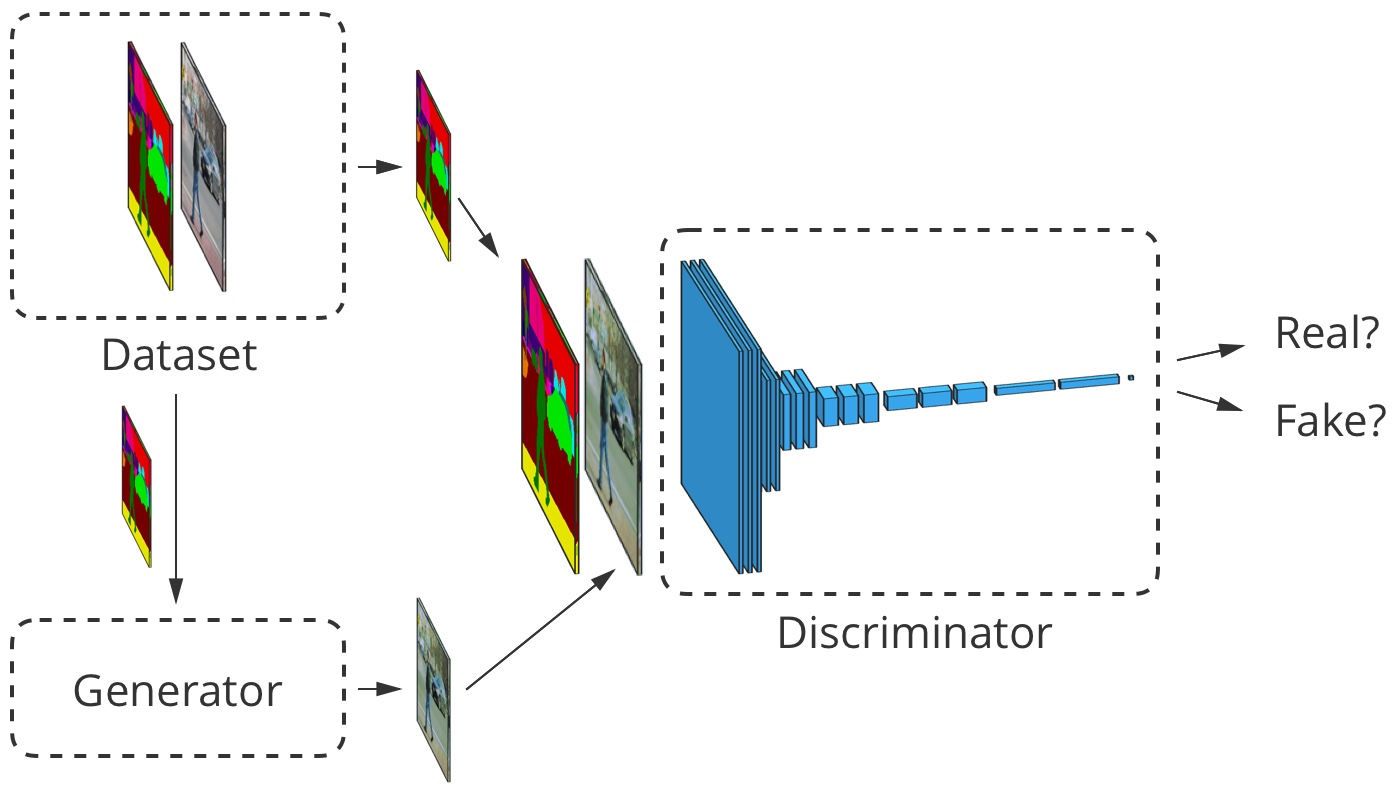 Untuk terjemahan gambar-ke-gambar, gambar input diterima oleh generator dan pembeda. Selain itu, diskriminator menerima output generator atau output sebenarnya dari set data pelatihan. Contoh
Untuk terjemahan gambar-ke-gambar, gambar input diterima oleh generator dan pembeda. Selain itu, diskriminator menerima output generator atau output sebenarnya dari set data pelatihan. ContohPengembangan penerjemah gambar-ke-gambar
Mari kita lihat penerjemah gambar-ke-gambar yang nyata:
pix2pixHD . Omong-omong, SPADE dirancang untuk sebagian besar dalam gambar dan kemiripan pix2pixHD.
Untuk penerjemah gambar-ke-gambar, generator kami membuat gambar dan menerimanya sebagai input. Kita hanya bisa menggunakan peta lapisan convolutional, tetapi karena lapisan convolutional menggabungkan nilai hanya di area kecil, kita membutuhkan terlalu banyak layer untuk mengirimkan informasi gambar resolusi tinggi.
pix2pixHD memecahkan masalah ini lebih efisien dengan bantuan "Encoder", yang mengurangi skala gambar input, diikuti oleh "Decoder", yang meningkatkan skala untuk mendapatkan gambar output. Seperti yang akan segera kita lihat, SPADE memiliki solusi yang lebih elegan yang tidak memerlukan encoder.
 Diagram jaringan Pix2pixHD pada level "tinggi". Blok "residual" dan "+ operasi" merujuk pada teknologi "lewati koneksi" dari jaringan saraf residual . Ada lewati blok dalam jaringan, yang saling berhubungan dalam encoder dan decoder.
Diagram jaringan Pix2pixHD pada level "tinggi". Blok "residual" dan "+ operasi" merujuk pada teknologi "lewati koneksi" dari jaringan saraf residual . Ada lewati blok dalam jaringan, yang saling berhubungan dalam encoder dan decoder.Normalisasi batch adalah masalah
Hampir semua jaringan saraf convolutional modern menggunakan normalisasi batch atau salah satu analognya untuk mempercepat dan menstabilkan proses pelatihan. Aktivasi setiap saluran menggeser rata-rata ke 0 dan standar deviasi ke 1 sebelum sepasang parameter saluran
dan
biarkan mereka mendenormalisasi lagi.
Sayangnya, normalisasi batch membahayakan generator, sehingga sulit bagi jaringan untuk mengimplementasikan beberapa jenis pemrosesan gambar. Alih-alih menormalkan sejumlah gambar, pix2pixHD menggunakan
standar normalisasi , yang menormalkan setiap gambar secara individual.
Pelatihan Pix2pixHD
GAN modern, seperti pix2pixHD dan SPADE, mengukur realisme gambar output mereka sedikit berbeda dari apa yang dijelaskan untuk desain asli jaringan pertikaian generatif.
Untuk memecahkan masalah menghasilkan gambar resolusi tinggi, pix2pixHD menggunakan tiga pembeda dari struktur yang sama, masing-masing menerima gambar output pada skala yang berbeda (ukuran normal, dikurangi 2 kali dan berkurang 4 kali).
Pix2pixHD menggunakan
, dan juga termasuk elemen lain yang dirancang untuk membuat kesimpulan generator lebih realistis (terlepas dari apakah ini membantu menipu pembeda). Item ini
disebut "pencocokan fitur" - ini mendorong generator untuk membuat distribusi lapisan yang sama ketika mensimulasikan diskriminasi antara data nyata dan output dari generator, meminimalkan
di antara mereka.
Jadi, pengoptimalan turun sebagai berikut:
$$ menampilkan $$ \ mulai {persamaan *} \ min_G \ bigg (\ lambda \ sum_ {k = 1,2,3} V_ \ teks {LSGAN} (G, D_k) + \ besar (\ max_ {D_1, D_2 , D_3} \ sum_ {k = 1,2,3} \ mathcal {L} _ \ text {FM} (G, D_k) \ besar) \ bigg) \ end {persamaan *}, $$ menampilkan $$
di mana kerugian dirangkum oleh tiga faktor diskriminatif dan koefisien
, yang mengontrol prioritas kedua elemen.
 pix2pixHD menggunakan peta segmentasi yang terdiri dari kamar tidur nyata (di sebelah kiri dalam setiap contoh) untuk membuat kamar tidur palsu (di sebelah kanan).
pix2pixHD menggunakan peta segmentasi yang terdiri dari kamar tidur nyata (di sebelah kiri dalam setiap contoh) untuk membuat kamar tidur palsu (di sebelah kanan).Meskipun diskriminator mengurangi skala gambar sampai mereka membongkar seluruh gambar, mereka berhenti di "bintik-bintik" ukuran 70 × 70 (pada skala yang sesuai). Kemudian mereka hanya merangkum semua nilai dari "titik-titik" ini untuk seluruh gambar.
Dan pendekatan ini berfungsi dengan baik, karena fungsinya
, ,
. , .
 pix2pixHD . CelebA , .
pix2pixHD . CelebA , .pix2pixHD?
, . , pix2pixHD .
, pix2pixHD , , , . , . «» ()
. β- , : , «», «», «» - .
pix2pixHD . , , .— SPADE.
: SPADE
- : - () (SPADE).
SPADE , , γ, β, , . , 2 .
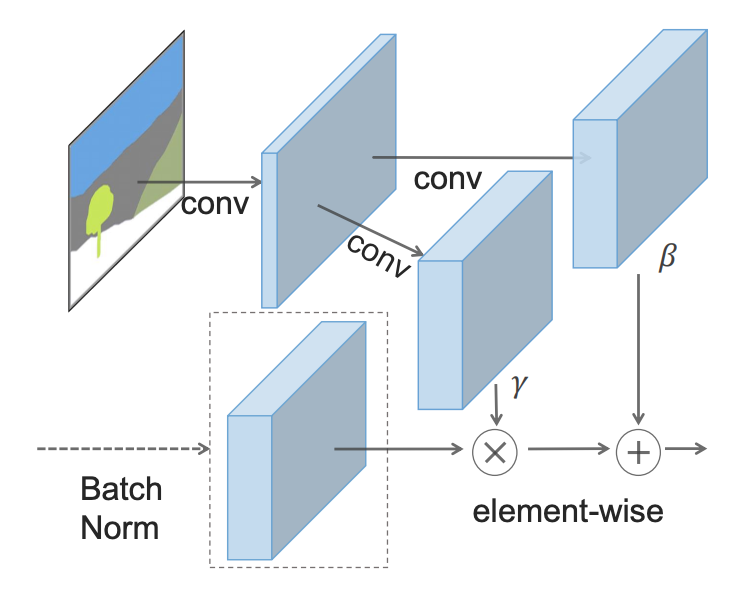 , SPADE .
, SPADE .SPADE « », ( ):
 SPADE pix2pixHD
SPADE pix2pixHD, «» , . GAN, . (« »). «» pix2pixHD, .
SPADE , pix2pixHD, :
hinge loss .
:
 SPADE pix2pixHD
SPADE pix2pixHD, SPADE . . GauGAN «» , . , - SPADE , «» , .
, SPADE , «» .
, , «». SPADE , , ? 55, «».
, , 5x5 . , .
SPADE , , , , pix2pixHD. , .
SPADE — (, , , ).
 SPADE , .
SPADE , .: ,
, . , , SPADE , , .
, . , ,
.
Beginilah fungsi SPADE / GAIGAN. Saya harap artikel ini memuaskan rasa ingin tahu Anda tentang cara kerja sistem NVIDIA yang baru. Anda dapat menghubungi saya melalui Twitter @AdamDanielKin atau email adam@AdamDKing.com.