Kata Pengantar
Cukup sering, pengguna, pengembang dan administrator MS SQL Server DBMS menghadapi masalah kinerja database atau DBMS secara umum, oleh karena itu pemantauan MS SQL Server sangat relevan.
Artikel ini adalah tambahan untuk artikel
Menggunakan Zabbix untuk memonitor database MS SQL Server dan akan memeriksa beberapa aspek pemantauan MS SQL Server, khususnya: cara cepat menentukan sumber daya apa yang hilang, serta rekomendasi untuk mengatur jejak jejak.
Agar skrip berikut berfungsi, Anda harus membuat skema inf dalam database yang diinginkan sebagai berikut:
Membuat skema infuse <_>; go create schema inf;
Metode untuk mendeteksi kekurangan RAM
Indikator pertama dari kurangnya RAM adalah kasus ketika sebuah instance dari MS SQL Server memakan semua RAM yang dialokasikan untuk itu.
Untuk melakukan ini, buat tampilan inf.vRAM berikut:
Membuat Tampilan inf.vRAM CREATE view [inf].[vRAM] as select a.[TotalAvailOSRam_Mb]
Kemudian Anda dapat menentukan bahwa instance MS SQL Server mengkonsumsi semua memori yang dialokasikan untuk itu oleh permintaan berikut:
select SQL_server_physical_memory_in_use_Mb, SQL_server_committed_target_Mb from [inf].[vRAM];
Jika indikator SQL_server_physical_memory_in_use_Mb terus-menerus tidak kurang dari SQL_server_committed_target_Mb, maka Anda perlu memeriksa statistik ekspektasi.
Untuk menentukan kurangnya RAM melalui statistik ekspektasi, buat tampilan inf.vWaits:
Membuat Tampilan inf.vWaits CREATE view [inf].[vWaits] as WITH [Waits] AS (SELECT [wait_type],
Dalam hal ini, Anda dapat menentukan kekurangan RAM dengan kueri berikut:
SELECT [Percentage] ,[AvgWait_S] FROM [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Di sini Anda perlu memperhatikan kinerja Persentase dan AvgWait_S. Jika mereka signifikan dalam totalitasnya, maka ada kemungkinan yang sangat tinggi bahwa RAM tidak cukup untuk turunan MS SQL Server. Nilai-nilai penting ditentukan secara individual untuk setiap sistem. Namun, Anda dapat mulai dengan metrik berikut: Persentase> = 1 dan AvgWait_S> = 0,005.
Untuk mengeluarkan indikator ke sistem pemantauan (misalnya, Zabbix), Anda dapat membuat dua pertanyaan berikut:
- berapa persen dalam jenis ekspektasi untuk RAM yang ditempati (jumlah untuk semua jenis ekspektasi tersebut):
select coalesce(sum([Percentage]), 0.00) as [Percentage] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
- berapa milidetik jenis ekspektasi untuk RAM yang ditempati (nilai maksimum semua penundaan rata-rata untuk semua jenis ekspektasi semacam itu):
select coalesce(max([AvgWait_S])*1000, 0.00) as [AvgWait_MS] from [inf].[vWaits] where [WaitType] in ( 'PAGEIOLATCH_XX', 'RESOURCE_SEMAPHORE', 'RESOURCE_SEMAPHORE_QUERY_COMPILE' );
Berdasarkan dinamika nilai yang diperoleh untuk kedua indikator ini, kita dapat menyimpulkan apakah ada cukup RAM untuk instance MS SQL Server.
Metode deteksi kelebihan CPU
Untuk mengidentifikasi kurangnya waktu CPU, cukup gunakan tampilan sistem sys.dm_os_schedulers. Di sini, jika indikator runnable_tasks_count secara konstan lebih besar dari 1, maka ada kemungkinan tinggi bahwa jumlah core tidak cukup untuk turunan MS SQL Server.
Untuk menampilkan indikator dalam sistem pemantauan (misalnya, Zabbix), Anda dapat membuat kueri berikut:
select max([runnable_tasks_count]) as [runnable_tasks_count] from sys.dm_os_schedulers where scheduler_id<255;
Berdasarkan dinamika nilai yang diperoleh untuk indikator ini, kita dapat menyimpulkan apakah ada cukup waktu prosesor (jumlah inti CPU) untuk instance MS SQL Server.
Namun, penting untuk diingat bahwa permintaan itu sendiri dapat meminta banyak utas sekaligus. Dan terkadang pengoptimal tidak dapat dengan benar menilai kompleksitas permintaan itu sendiri. Kemudian permintaan tersebut dapat dialokasikan terlalu banyak utas yang pada waktu tertentu tidak dapat diproses secara bersamaan. Dan ini juga menyebabkan jenis penantian yang terkait dengan kurangnya waktu prosesor, dan pertumbuhan antrian untuk penjadwal yang menggunakan inti CPU tertentu, mis., Indikator runnable_tasks_count akan tumbuh dalam kondisi seperti itu.
Dalam hal ini, sebelum menambah jumlah core CPU, Anda harus mengkonfigurasi dengan benar properti paralelisme dari instance MS SQL Server, dan dari versi 2016, mengkonfigurasi dengan benar properti paralelisme dari database yang diperlukan:

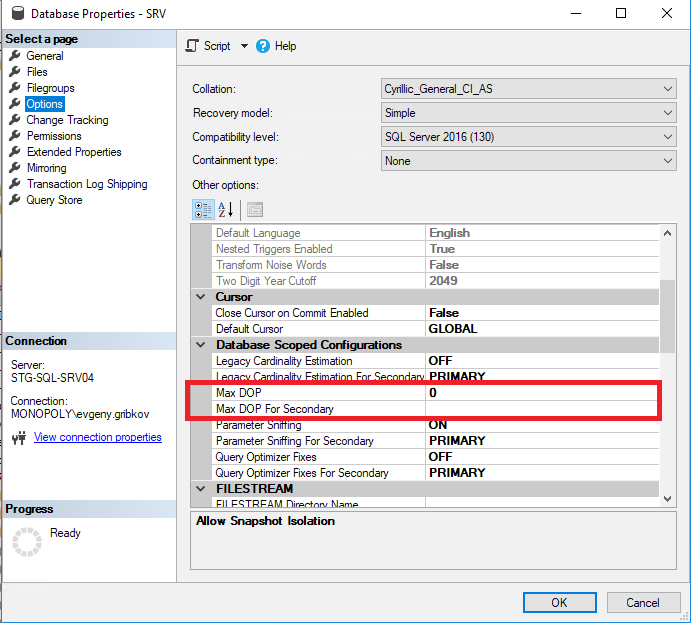
Ini ada baiknya memperhatikan parameter berikut:
- Derajat Paralelisme Maks - menetapkan jumlah utas maksimum yang dapat dialokasikan untuk setiap permintaan (standarnya adalah 0-batasan hanya oleh sistem operasi dan edisi MS SQL Server)
- Ambang Biaya untuk Paralelisme - perkiraan biaya paralelisme (standarnya adalah 5)
- Max DOP-menetapkan jumlah maksimum utas yang dapat dialokasikan untuk setiap kueri di tingkat basis data (tetapi tidak lebih dari nilai properti "Derajat Paralelisme") (standarnya adalah pembatasan 0 hanya oleh sistem operasi dan edisi MS SQL Server, serta pembatasan pada properti "Max Degree of Parallelism" dari seluruh instance MS SQL Server)
Tidak mungkin untuk memberikan resep yang sama baiknya untuk semua kasus, yaitu, Anda perlu menganalisis permintaan yang sulit.
Dari pengalaman saya sendiri, saya merekomendasikan algoritma tindakan berikut untuk sistem OLTP untuk mengkonfigurasi properti paralelisme:
- pertama melarang konkurensi dengan menetapkan level seluruh instance Max Degree of Parallelism ke 1
- menganalisis permintaan yang paling sulit dan memilih jumlah utas yang optimal untuknya
- atur Max Degree of Parallelism ke jumlah optimal utas yang diperoleh dari item 2, dan untuk database spesifik setel nilai DOP Max yang diperoleh dari item 2 untuk setiap database
- menganalisis permintaan yang paling sulit dan mengidentifikasi efek negatif dari multithreading. Jika ya, maka tambahkan Ambang Biaya untuk Paralelisme.
Untuk sistem seperti 1C, Microsoft CRM dan Microsoft NAV, dalam banyak kasus, larangan multithreading cocok.
Juga, jika edisi Standar diinstal, maka dalam banyak kasus larangan multithreading cocok mengingat fakta bahwa edisi ini dibatasi oleh jumlah inti CPU.
Untuk sistem OLAP, algoritma yang dijelaskan di atas tidak cocok.
Dari pengalaman saya sendiri, saya merekomendasikan algoritma tindakan berikut untuk sistem OLAP untuk mengatur properti paralelisme:
- menganalisis permintaan yang paling sulit dan memilih jumlah utas yang optimal untuknya
- atur Max Degree of Parallelism ke jumlah optimal utas yang diperoleh dari item 1, dan juga untuk database spesifik atur nilai Max DOP yang diperoleh dari item 1 untuk setiap database
- menganalisis permintaan yang paling sulit dan mengidentifikasi efek negatif dari batas concurrency. Jika ya, turunkan Nilai Ambang Batas untuk nilai Paralelisme, atau ulangi langkah 1-2 dari algoritme ini
Yaitu, untuk sistem OLTP kita beralih dari single-threaded ke multithreading, dan untuk sistem OLAP, sebaliknya, kita beralih dari multithreading ke single-threaded. Dengan demikian, dimungkinkan untuk memilih pengaturan konkurensi optimal untuk database tertentu dan seluruh instance MS SQL Server.
Penting juga untuk memahami bahwa pengaturan properti konkurensi perlu diubah dari waktu ke waktu berdasarkan hasil pemantauan kinerja MS SQL Server.
Rekomendasi untuk mengatur tanda jejak
Dari pengalaman saya sendiri dan pengalaman rekan-rekan saya, saya sarankan mengatur tanda jejak berikut di tingkat startup dari layanan MS SQL Server untuk versi 2008-2016 untuk kinerja yang optimal:
- 610 - Mengurangi penebangan sisipan dalam tabel yang diindeks. Ini dapat membantu dengan memasukkan ke dalam tabel dengan sejumlah besar catatan dan banyak transaksi, dengan harapan panjang yang sering dari WRITELOG untuk perubahan indeks
- 1117 - Jika file dalam filegroup memenuhi ambang pertumbuhan otomatis, semua file dalam filegroup diperluas
- 1118 - Memaksa semua objek berada di luasan yang berbeda (melarang luasan campuran), yang meminimalkan kebutuhan untuk memindai halaman SGAM, yang digunakan untuk melacak luasan campuran
- 1224 - Menonaktifkan eskalasi kunci berdasarkan jumlah kunci. Penggunaan memori yang berlebihan dapat mencakup eskalasi kunci.
- 2371 - Mengubah ambang batas untuk pembaruan statistik otomatis tetap ke ambang batas untuk pembaruan statistik otomatis dinamis. Penting untuk memperbarui rencana kueri untuk tabel besar di mana salah menentukan jumlah catatan mengarah ke rencana eksekusi yang salah
- 3226 - Menekan pesan cadangan yang berhasil di log kesalahan
- 4199 - Termasuk perubahan pengoptimal kueri yang dirilis dalam pembaruan kumulatif dan paket layanan SQL Server
- 6532-6534 - Termasuk peningkatan kinerja kueri untuk tipe data spasial
- 8048 - Mengonversi NUMA objek memori yang dipartisi menjadi CPU yang dipartisi
- 8780 - Mengaktifkan alokasi waktu tambahan untuk menjadwalkan permintaan. Beberapa permintaan tanpa tanda ini mungkin ditolak karena tidak memiliki rencana permintaan (kesalahan yang sangat jarang terjadi)
- 9389 - Termasuk dinamis tambahan yang disediakan sementara buffer memori untuk operator mode batch, yang memungkinkan operator mode batch untuk meminta memori tambahan dan menghindari transfer data ke tempdb jika memori tambahan tersedia
Sebelum versi 2016, penting untuk menyertakan jejak bendera 2301, yang mencakup optimalisasi dukungan keputusan yang diperluas dan dengan demikian membantu dalam memilih rencana kueri yang lebih benar. Namun, dimulai dengan versi 2016, seringkali memiliki efek negatif dalam waktu eksekusi kueri keseluruhan yang cukup panjang.
Juga untuk sistem di mana ada banyak indeks (misalnya, untuk database 1C), saya sarankan Anda mengaktifkan jejak flag 2330, yang menonaktifkan pengumpulan penggunaan indeks, yang umumnya memiliki efek positif pada sistem.
Pelajari lebih lanjut tentang tanda jejak di
sini .
Menggunakan tautan di atas, penting juga untuk mempertimbangkan versi dan rakitan MS SQL Server, karena untuk versi yang lebih baru, beberapa flag trace diaktifkan secara default atau tidak berpengaruh. Misalnya, dalam versi 2017, relevan untuk hanya menetapkan 5 tanda jejak berikut: 1224, 3226, 6534, 8780 dan 9389.
Anda dapat mengaktifkan atau menonaktifkan tanda jejak menggunakan masing-masing perintah DBCC TRACEON dan DBCC TRACEOFF. Lihat di
sini untuk detail lebih lanjut.
Anda bisa mendapatkan status tanda jejak menggunakan perintah DBCC TRACESTATUS:
selengkapnya .
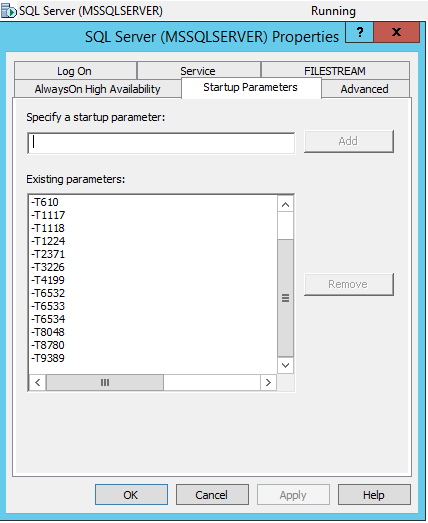
Agar tanda jejak disertakan dalam autorun layanan MS SQL Server, Anda harus masuk ke SQL Server Configuration Manager dan menambahkan tanda jejak ini di properti layanan melalui -T:
Ringkasan
Pada artikel ini, beberapa aspek pemantauan MS SQL Server diperiksa, dengan bantuan yang Anda dapat dengan cepat mengidentifikasi kurangnya waktu luang RAM dan CPU, serta sejumlah masalah lain yang kurang jelas. Bendera jejak yang paling umum digunakan dipertimbangkan.
Sumber
»
Statistik Siaga SQL Server»
Statistik ekspektasi SQL Server atau tolong beri tahu saya di tempat yang menyakitkan»
Tampilan Sistem sys.dm_os_schedulers»
Menggunakan Zabbix untuk melacak basis data MS SQL Server»
Gaya Hidup SQL»
Lacak bendera»
Sql.ru