
Pada tanggal 1 April, SNA Hackathon 2019 final berakhir, para peserta yang bersaing dalam menyortir umpan jaringan sosial menggunakan teknologi pembelajaran mesin modern, visi komputer, pemrosesan tes dan sistem rekomendasi. Seleksi online yang keras dan dua hari kerja keras pada 160 gigabyte data tidak sia-sia :). Kami berbicara tentang apa yang membantu para peserta mencapai kesuksesan dan tentang pengamatan menarik lainnya.
Tentang data dan tugas
Kompetisi menyajikan data dari mekanisme untuk menyiapkan umpan untuk pengguna jejaring sosial OK , yang terdiri dari tiga bagian:
- log tampilan konten dalam umpan pengguna dengan sejumlah besar atribut yang menggambarkan pengguna, konten, penulis, dan properti lainnya;
- teks yang terkait dengan konten yang ditampilkan;
- badan gambar yang digunakan dalam konten.
Jumlah total data melebihi 160 gigabytes, lebih dari 3 akun untuk log, 3 lebih untuk teks dan sisanya untuk gambar. Jumlah besar data tidak membuat takut para peserta: menurut statistik ML Bootcamp , hampir 200 orang ambil bagian dalam kompetisi, yang mengirim lebih dari 3.000 pengiriman, dan yang paling aktif berhasil menembus batas 100 solusi yang dikirim. Mungkin mereka termotivasi oleh kumpulan hadiah 700.000 rubel + 3 kartu grafis GTX 2080 Ti.

Peserta kompetisi diperlukan untuk menyelesaikan masalah pengurutan rekaman: untuk setiap pengguna individu, urutkan objek yang ditampilkan sedemikian rupa sehingga yang mendapat "Kelas!" Mark lebih dekat ke kepala daftar.
ROC-AUC digunakan sebagai metrik penilaian kualitas. Pada saat yang sama, metrik tidak dipertimbangkan untuk semua data secara keseluruhan, tetapi secara terpisah untuk setiap pengguna dan kemudian dirata-ratakan. Opsi perhitungan ini patut diperhatikan karena algoritma yang telah belajar untuk membedakan pengguna yang ditempatkan di banyak kelas tidak menerima keuntungan. Di sisi lain, tidak ada opsi seperti itu dalam paket Python standar, yang mengungkapkan beberapa poin menarik, yang dibahas di bawah ini.
Tentang teknologi
Secara tradisional, SNA Hackathon tidak hanya algoritma, tetapi juga teknologi - volume data yang dikirim melebihi 160 gigabytes, yang menempatkan peserta di depan tugas teknis yang menarik.
Parket vs. Csv
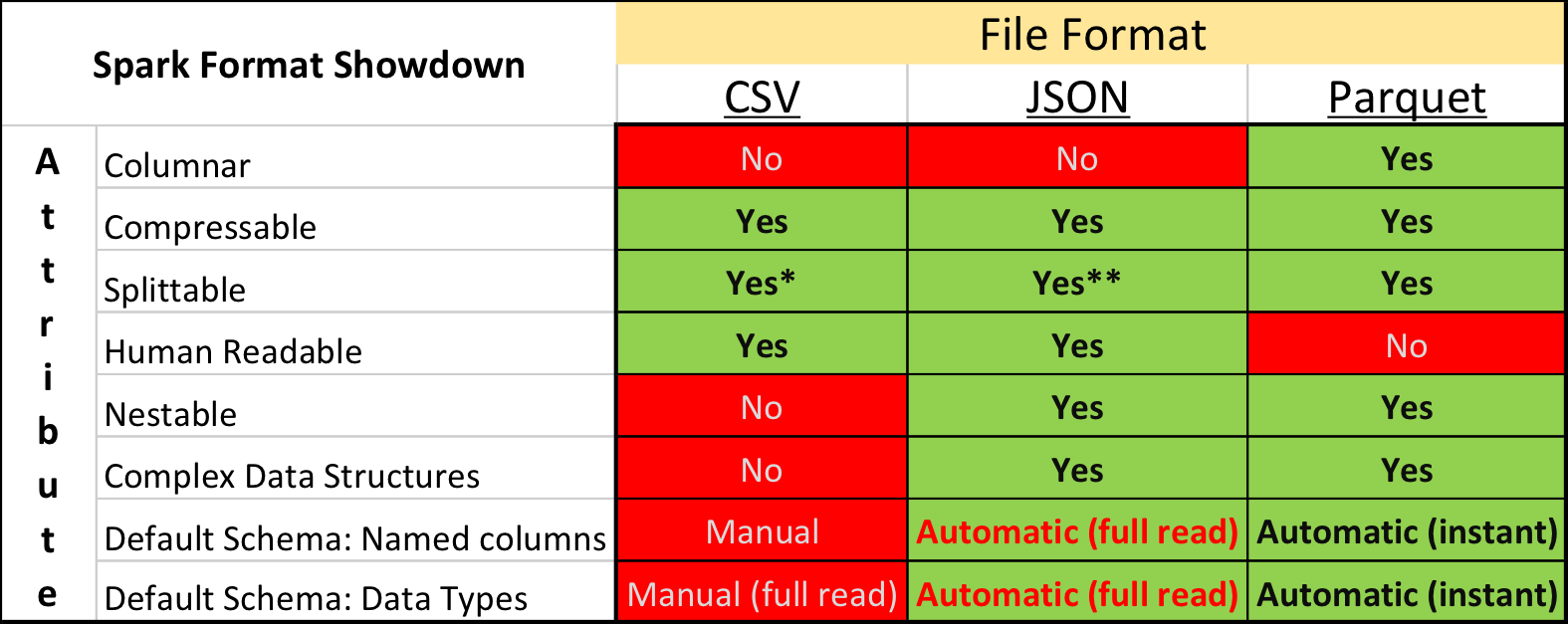
Dalam penelitian akademik dan tentang Kaggle, format data yang dominan adalah CSV , serta format teks biasa lainnya. Namun, situasi di industri agak berbeda - kecepatan yang jauh lebih padat dan pemrosesan dapat dicapai dengan menggunakan format penyimpanan "biner".
Secara khusus, dalam ekosistem yang dibangun berdasarkan Apache Spark , Apache Parquet adalah yang paling populer - format penyimpanan data kolom dengan dukungan untuk banyak fitur operasional penting:
- sirkuit yang ditentukan secara eksplisit dengan dukungan evolusi;
- hanya membaca kolom yang diperlukan dari disk;
- dukungan dasar untuk indeks dan filter saat membaca;
- kompresi string.
Namun terlepas dari keuntungan yang jelas, mengirimkan data untuk kompetisi dalam format Apache Parket bertemu dengan kritik keras dari beberapa peserta. Selain konservatisme dan keengganan untuk menghabiskan waktu mengembangkan sesuatu yang baru, ada beberapa momen yang benar-benar tidak menyenangkan.
Pertama, dukungan untuk format di perpustakaan Apache Arrow , alat utama untuk bekerja dengan Parket dari Python, jauh dari sempurna. Saat menyiapkan data, semua bidang struktural harus diperluas ke rata, dan masih, ketika membaca teks, banyak peserta menemukan bug dan dipaksa untuk menginstal versi lama perpustakaan 0.11.1 bukannya versi saat ini 0.12 pada waktu itu. Kedua, Anda tidak akan melihat file Parket menggunakan utilitas konsol sederhana: cat, less, dll. Namun, kelemahan ini relatif mudah dikompensasi dengan menggunakan paket alat parket .
Namun demikian, mereka yang awalnya mencoba mengubah semua data menjadi CSV, kemudian bekerja di lingkungan yang akrab, akhirnya meninggalkan ide ini - lagipula, Parket bekerja lebih cepat secara signifikan.
Meningkatkan dan GPU

Pada konferensi SmartData di St. Petersburg, "dikenal luas di kalangan sempit," Alexey Natekin membandingkan kinerja beberapa alat pendongkrak yang populer saat bekerja pada CPU / GPU dan sampai pada kesimpulan bahwa GPU tidak memberikan keuntungan yang nyata. Namun demikian, kesimpulan ini menghasilkan polemik aktif, terutama dengan pengembang alat CatBoost domestik.
Selama dua tahun terakhir, kemajuan dalam pengembangan GPU dan adaptasi algoritma tidak berhenti dan final SNA Hackathon dapat dianggap sebagai kemenangan pasangan GPU CatBoost + - semua pemenang menggunakannya dan menarik metrik terutama karena kemampuan untuk menumbuhkan lebih banyak pohon per unit waktu.
Implementasi terintegrasi dari target target encoding juga berkontribusi pada hasil tinggi solusi berdasarkan CatBoost, tetapi jumlah dan kedalaman pohon memberikan peningkatan yang lebih signifikan.
Alat pendongkrak lainnya bergerak ke arah yang sama, menambah dan meningkatkan dukungan GPU. Jadi tumbuhkan lebih banyak pohon!
Spark vs. Pyspark

Alat Apache Spark adalah pemimpin yang kuat dalam Ilmu Data industri, sebagian berkat API Python. Namun, menggunakan Python dilengkapi dengan overhead tambahan untuk mengintegrasikan antara runtime yang berbeda dan pekerjaan juru bahasa.
Ini dengan sendirinya bukan masalah jika pengguna menyadari sejauh mana jumlah biaya tambahan mengarah ke tindakan tertentu. Namun, ternyata begitu banyak yang tidak menyadari besarnya masalah - terlepas dari kenyataan bahwa para peserta tidak menggunakan Apache Spark, diskusi tentang Python vs Scala muncul secara teratur dalam obrolan hackathon, yang menyebabkan munculnya pos yang diuraikan .
Singkatnya, perlambatan menggunakan Spark melalui Python dibandingkan dengan menggunakan Spark via Scala / Java dapat dipecah menjadi tingkat berikut:
- hanya Spark SQL API yang digunakan tanpa Fungsi yang Ditentukan Pengguna (UDF) - dalam hal ini praktis tidak ada overhead, karena seluruh rencana pelaksanaan kueri dihitung dalam kerangka kerja JVM;
- UDF digunakan dalam Python tanpa memanggil paket dengan kode C ++ - dalam hal ini, kinerja tahap di mana UDF dihitung turun 7-10 kali ;
- UDF digunakan dalam Python dengan akses ke paket C ++ (numpy, sklearn, dll.) - dalam hal ini, kinerja turun 10-50 kali .
Sebagian, efek negatif dapat dikompensasikan dengan menggunakan PyPy (JIT for Python) dan UDF yang di- vectorisasi , namun dalam kasus ini perbedaan dalam kinerja berlipat ganda, dan kompleksitas implementasi dan penyebaran disertai dengan "bonus" tambahan.
Tentang Algoritma
Tetapi hal yang paling menarik tentang hackathons Ilmu Data, tentu saja, bukan teknologi, tetapi algoritma baru yang terbukti modis dan lama. CatBoost mendominasi SNA Hackathon tahun ini, tetapi ada beberapa pendekatan alternatif. Kami akan membicarakannya :).
Grafik yang dapat dibedakan

Salah satu publikasi keputusan pertama berdasarkan hasil babak kualifikasi didedikasikan bukan untuk pohon, tetapi grafik yang dapat dibedakan (juga disebut jaringan saraf tiruan). Penulis adalah karyawan OK, sehingga ia tidak mampu mengejar hadiah, tetapi lebih suka membangun solusi yang menjanjikan berdasarkan dasar matematika yang kuat.
Gagasan utama dari solusi yang diusulkan adalah untuk membangun satu grafik terdiferensiasi komputasi tunggal yang menerjemahkan fitur yang tersedia ke dalam ramalan yang mempertimbangkan berbagai aspek dari data input:
- objek dan serikat pengguna memungkinkan Anda untuk menambahkan elemen rekomendasi kolaboratif klasik;
- transisi dari skalar embedding ke agregasi melalui MLP memungkinkan Anda untuk menambahkan karakteristik sewenang-wenang;
- perhatian-kunci-nilai memungkinkan model untuk secara dinamis beradaptasi dengan perilaku bahkan pengguna yang sebelumnya tidak terbiasa melihat sejarahnya baru-baru ini.
Model ini terbukti sangat bagus dalam pemilihan online dalam menyelesaikan masalah merekomendasikan konten teks, sehingga beberapa tim mencoba memainkannya di final sekaligus, namun, mereka tidak berhasil. Ini sebagian disebabkan oleh fakta bahwa ini membutuhkan waktu dan pengalaman, dan sebagian lagi karena fakta bahwa jumlah atribut di final jauh lebih besar dan metode berdasarkan pohon menerima keuntungan yang signifikan karena mereka.
Dominasi kolaboratif

Tentu saja, ketika mengatur kontes, kami tahu bahwa ada sinyal yang cukup kuat di log, karena tanda-tanda yang dikumpulkan di sana mencerminkan bagian penting dari pekerjaan yang dilakukan di OK untuk memberi peringkat feed. Namun demikian, sampai akhir mereka berharap bahwa para peserta akan berhasil mengatasi "kutukan karakter ketiga" - situasi di mana sumber daya manusia dan mesin yang besar diinvestasikan dalam mengembangkan model untuk mengekstraksi atribut dari konten (teks dan foto) menghasilkan peningkatan kualitas yang sangat kecil dibandingkan dengan yang sudah ada. siap, terutama sifat kolaboratif.
Mengetahui masalah ini, kami awalnya membagi tugas menjadi tiga trek di babak kualifikasi dan membentuk gabungan data yang ditetapkan hanya di final, tetapi dalam format hackathon dengan metrik tetap, tim yang berinvestasi dalam pengembangan model konten menemukan diri mereka dalam situasi kehilangan sengaja dibandingkan dengan tim yang mengembangkan kolaboratif bagian.
Hadiah juri membantu mengkompensasi ketidakadilan ini ...
Cluster yang dalam

Yang hampir dengan suara bulat diberikan untuk pekerjaan mereproduksi dan menguji algoritma Deep Cluster dari facebook. Metode markup awal yang sederhana dan tidak memerlukan untuk membuat cluster dan embeddings gambar terkesan dengan ide-ide baru dan hasil yang menjanjikan.
Inti dari metode ini sangat sederhana:
- menghitung vektor embedding untuk gambar dengan jaringan saraf yang berarti;
- klaster vektor di ruang yang dihasilkan dengan k-means;
- melatih pengklasifikasi jaringan saraf untuk memprediksi sekelompok gambar;
- ulangi langkah 2-3 hingga konvergensi (jika Anda memiliki 800 GPU) atau saat ada cukup waktu.
Dengan upaya minimal, kami berhasil memperoleh pengelompokan gambar OK berkualitas tinggi, embedding yang baik, dan peningkatan metrik pada digit ketiga.
Lihatlah ke masa depan

Dalam data apa pun Anda dapat menemukan "celah" untuk meningkatkan perkiraan. Ini sendiri tidak begitu buruk, jauh lebih buruk jika celah ditemukan sendiri dan untuk waktu yang lama hanya muncul dalam bentuk perbedaan yang tidak dapat dipahami antara hasil validasi pada data historis dan tes A / B.
Salah satu celah paling luas dari jenis ini adalah penggunaan informasi dari masa depan. Informasi seperti itu seringkali merupakan sinyal yang sangat kuat dan algoritma pembelajaran mesin, jika diaktifkan, akan mulai menggunakannya dengan percaya diri. Ketika Anda membuat model untuk produk Anda, Anda berusaha dengan segala cara yang mungkin untuk menghindari kebocoran informasi dari masa depan, tetapi di hackathon ini adalah kesempatan yang baik untuk meningkatkan metrik, yang digunakan oleh para peserta.
Celah yang paling jelas adalah kehadiran numLike dan num. Disukai di bidang ini dengan jumlah reaksi pada objek pada saat pertunjukan. Dengan membandingkan dua peristiwa terdekat dalam waktu yang terkait dengan objek yang sama, dimungkinkan untuk menentukan dengan akurasi tinggi apa reaksi terhadap objek pada awalnya. Ada beberapa penghitung serupa dalam data, dan penggunaannya memberikan keuntungan nyata. Secara alami, dalam penggunaan aktual, informasi tersebut tidak akan tersedia.
Dalam hidup, masalah yang sama dapat ditemukan tanpa menyadarinya, biasanya dengan hasil negatif. Misalnya, menghitung statistik pada jumlah tanda "Kelas!" untuk objek sesuai dengan semua data dan menganggapnya sebagai atribut terpisah. Atau, seperti yang mereka lakukan di salah satu tim yang berpartisipasi, menambahkan pengenal objek ke model sebagai atribut kategorikal. Pada set pelatihan, model dengan fitur seperti itu berfungsi dengan baik, tetapi tidak dapat digeneralisasi ke set tes.
Alih-alih sebuah kesimpulan

Semua bahan kontes, termasuk data dan presentasi keputusan peserta tersedia di Cloud Mail.ru. Data tersedia untuk digunakan oleh proyek penelitian tanpa batasan, kecuali untuk ketersediaan tautan. Untuk ceritanya, mari kita tinggalkan tabel terakhir di sini dengan metrik tim final:
- Crouching Scala, menyembunyikan Python - 0.7422, solusi parsing tersedia di sini , dan kode ada di sini dan di sini .
- Kota Ajaib - 0.7256
- Kefir - 0.7226
- Tim 6 - 0,7205
- Tiga di atas kapal - 0.7188
- Hall # 14 - 0,7167 dan hadiah juri
- BezSNA - 0.7147
- PONGA - 0.7117
- Tim 5 - 0,7112
SNA Hackathon 2019, seperti acara seri sebelumnya, merupakan keberhasilan dalam segala hal. Kami berhasil mengumpulkan para profesional keren di berbagai bidang di bawah satu atap dan memiliki waktu yang bermanfaat, yang banyak terima kasih kepada para peserta sendiri dan kepada semua orang yang membantu organisasi.
Mungkinkah sesuatu dilakukan lebih baik? Tentu saja ya! Setiap kompetisi yang diadakan memperkaya kami dengan pengalaman baru, yang kami perhitungkan saat mempersiapkan yang berikutnya dan tidak akan berhenti di situ. Jadi, sampai ketemu lagi di SNA Hackathon!