Tautan cepat
-
Jalan Menuju Versi 12-
Pertama, Beberapa Matematika-
Kalkulus Ketidakpastian-
Matematika Klasik, SD dan Mahir-
Lebih banyak dengan Poligon-
Komputasi dengan Polyhedra-
Euclid-Style Geometry Made Computable-
Menjadi Super-Simbolik dengan Teori Aksiomatik-
Masalah n-Tubuh-
Ekstensi Bahasa & Fasilitas-
Lebih Banyak Fungsi Pembelajaran Mesin-
Yang Terbaru di Jaringan Saraf Tiruan-
Komputasi dengan Gambar-
Pengenalan Wicara & Lainnya dengan Audio-
Pemrosesan Bahasa Alami-
Kimia Komputasi-
Komputasi Geografis Diperpanjang-
Banyak Peningkatan Visualisasi Kecil-
Integrasi Pengetatan Knowledgebase-
Mengintegrasikan Big Data dari Database Eksternal-
RDF, SPARQL dan Semua Itu-
Optimalisasi Angka-
Analisis Elemen Hingga Nonlinear-
Baru, Kompiler Canggih-
Memanggil Python & Bahasa Lainnya-
Lebih untuk Wolfram "Super Shell"-
Menciptakan Browser Web-
Mikrokontroler Mandiri-
Memanggil Bahasa Wolfram dari Python & Tempat Lainnya-
Menghubungkan ke Unity Universe-
Lingkungan Simulasi untuk Pembelajaran Mesin-
Komputasi Blockchain (dan CryptoKitty)-
Dan Crypto Biasa juga-
Menghubungkan ke Umpan Data Keuangan-
Rekayasa Perangkat Lunak & Pembaruan Platform-
Dan Banyak Lagi ...
16 April 2019 - Stephen Wolfram
Hari ini kami merilis Versi 12
Bahasa Wolfram (dan
Mathematica ) pada
platform desktop , dan di
Cloud Wolfram . Kami merilis
Versi 11.0 pada bulan Agustus 2016 ,
11.1 pada bulan Maret 2017 ,
11.2 pada bulan September 2017 dan
11.3 pada bulan Maret 2018 . Ini lompatan besar dari Versi 11.3 ke Versi 12.0. Secara keseluruhan ada
278 fungsi yang sama sekali baru , di mungkin 103 area, bersama dengan ribuan pembaruan berbeda di seluruh sistem:

Dalam "
rilis integer " seperti 12, tujuan kami adalah untuk menyediakan area fungsionalitas baru yang terisi penuh. Namun dalam setiap rilis kami juga ingin memberikan hasil terbaru dari upaya R&D kami. Di 12.0, mungkin setengah dari fungsi baru kami dapat dianggap sebagai area finishing yang dimulai pada rilis ".1" sebelumnya - sementara setengah memulai area baru. Saya akan membahas kedua jenis fungsi pada bagian ini, tetapi saya akan secara khusus menekankan spesifikasi dari apa yang baru terjadi dari 11.3 menjadi 12.0.
Saya harus mengatakan bahwa sekarang setelah 12.0 selesai, saya kagum pada berapa banyak yang ada di dalamnya, dan berapa banyak yang telah kami tambahkan sejak 11.3. Dalam keynote saya di
Wolfram Technology Conference kami Oktober lalu, saya merangkum apa yang kami miliki sampai saat itu - dan bahkan itu memakan waktu hampir 4 jam. Sekarang masih ada lagi.
Apa yang dapat kami lakukan adalah bukti kekuatan upaya R&D kami, dan juga keefektifan Bahasa Wolfram sebagai lingkungan pengembangan. Kedua hal ini tentu saja telah
dibangun selama tiga dekade . Tetapi satu hal yang baru dengan 12.0 adalah bahwa kami telah membiarkan orang menonton proses desain kami di belakang layar —
menyiarkan lebih dari 300 jam pertemuan desain internal saya . Jadi selain yang lainnya, saya menduga ini menjadikan Versi 12.0 rilis perangkat lunak utama pertama dalam sejarah yang terbuka dengan cara ini.
OK, jadi apa yang baru dalam 12.0? Ada beberapa hal besar dan mengejutkan - terutama dalam
bidang kimia ,
geometri ,
ketidakpastian numerik dan
integrasi basis data . Tetapi secara keseluruhan, ada banyak hal di banyak bidang - dan bahkan ringkasan dasarnya di
Pusat Dokumentasi sudah 19 halaman:

Meskipun saat ini sebagian besar dari apa yang dilakukan oleh Bahasa Wolfram (dan Mathematica) bukanlah apa yang biasanya dianggap matematika, kami masih melakukan upaya R&D yang besar untuk mendorong batas-batas apa yang dapat dilakukan dalam matematika. Dan sebagai contoh pertama dari apa yang kami tambahkan di 12.0, inilah
ComplexPlot3D yang agak berwarna:
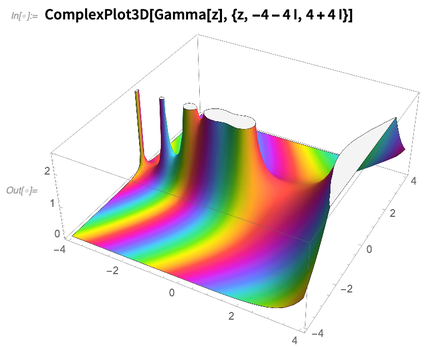
Selalu dimungkinkan untuk menulis kode Bahasa Wolfram untuk membuat plot di bidang kompleks. Tapi baru sekarang kita menyelesaikan masalah matematika dan algoritma yang diperlukan untuk mengotomatiskan proses merencanakan fungsi yang bahkan sangat patologis di bidang kompleks.
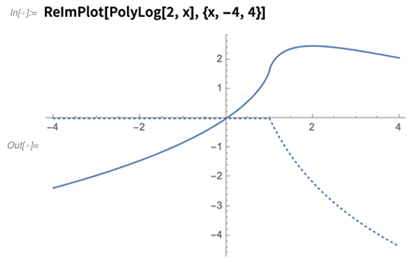
Bertahun-tahun yang lalu saya ingat dengan
susah payah merencanakan fungsi dilogaritma , dengan bagian-bagiannya yang nyata dan imajiner. Sekarang
ReImPlot lakukan saja:
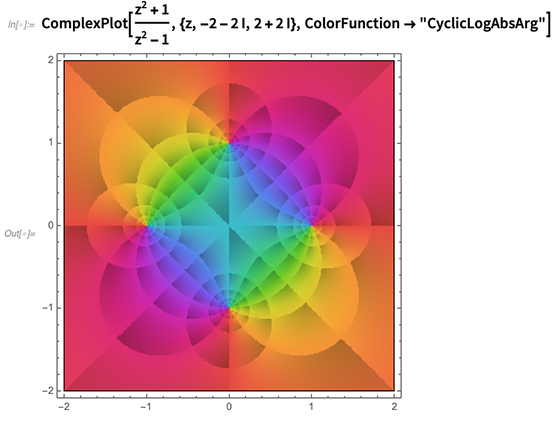
Visualisasi fungsi-fungsi kompleks adalah (menyisihkan) cerita kompleks, dengan detail membuat perbedaan besar dalam apa yang orang perhatikan tentang fungsi. Dan salah satu hal yang telah kami lakukan dalam 12.0 adalah memperkenalkan cara standar yang dipilih dengan cermat (seperti
fungsi warna yang dinamai) untuk menyoroti berbagai fitur:
Kalkulus Ketidakpastian
Pengukuran di dunia nyata seringkali memiliki ketidakpastian yang akan direpresentasikan sebagai nilai dengan ± kesalahan. Kami sudah memiliki paket tambahan untuk menangani "angka dengan kesalahan" selama berabad-abad. Namun dalam Versi 12.0 kami membangun perhitungan dengan ketidakpastian, dan kami melakukannya dengan benar.
Kuncinya adalah objek simbolis
Sekitar [
x, δ ], yang mewakili nilai "sekitar
x ", dengan ketidakpastian
δ :

Anda dapat melakukan aritmatika dengan
Sekitar , dan ada seluruh kalkulus untuk bagaimana ketidakpastian bergabung:

Jika Anda memplot angka, mereka akan ditampilkan dengan bar kesalahan:
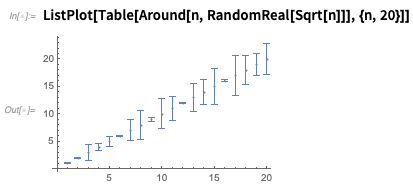
Ada banyak opsi - seperti inilah salah satu cara untuk menunjukkan ketidakpastian dalam
x dan
y :
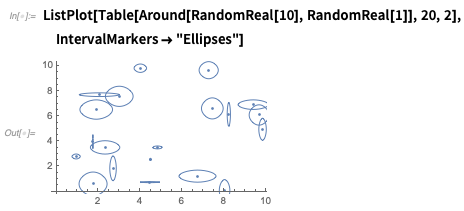
Anda dapat memiliki jumlah
sekitar :

Dan Anda juga dapat memiliki objek
Sekitar simbolis:
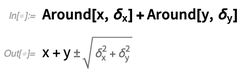
Tapi apa sebenarnya objek
Sekitar ? Itu adalah sesuatu di mana ada aturan tertentu untuk menggabungkan ketidakpastian, yang didasarkan pada distribusi normal yang tidak berkorelasi. Tetapi tidak ada pernyataan yang dibuat bahwa
Sekitar [
x, δ ] mewakili segala sesuatu yang sebenarnya secara rinci mengikuti distribusi normal - lebih dari itu
Sekitar [
x, δ ] mewakili angka khusus dalam interval yang ditentukan oleh
Interval [{
x - δ, x + δ }]. Hanya saja,
Sekitar objek menyebarkan kesalahan atau ketidakpastian mereka sesuai dengan aturan umum yang konsisten yang berhasil menangkap apa yang biasanya dilakukan dalam sains eksperimental.
OK, jadi katakanlah Anda membuat banyak pengukuran dengan nilai tertentu. Anda bisa mendapatkan estimasi nilai - bersama dengan ketidakpastiannya - menggunakan
MeanAround (dan, ya, jika pengukuran itu sendiri memiliki ketidakpastian, ini akan dipertimbangkan dalam mempertimbangkan kontribusi mereka):

Fungsi di seluruh sistem - terutama dalam
pembelajaran mesin - mulai memiliki opsi
ComputeUncaintyainty ->
True , yang membuat mereka memberikan objek
Sekitar daripada bilangan murni.
Sekitar mungkin tampak seperti konsep sederhana, tetapi penuh kehalusan - yang merupakan alasan utama sampai sekarang untuk masuk ke sistem. Banyak seluk-beluk berputar di sekitar korelasi antara ketidakpastian. Ide dasarnya adalah bahwa ketidakpastian setiap objek
Sekitar diasumsikan independen. Tetapi kadang-kadang seseorang memiliki nilai dengan ketidakpastian yang berkorelasi - dan di samping
Sekitar , ada juga
VectorAround , yang mewakili vektor nilai yang berpotensi berkorelasi dengan matriks kovarians yang ditentukan.
Bahkan ada kehalusan ketika seseorang berurusan dengan hal-hal seperti formula aljabar. Jika seseorang mengganti x di sini dengan
Sekitar , maka, mengikuti aturan
Sekitar , masing-masing contoh diasumsikan tidak berkorelasi:
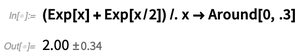
Tetapi mungkin orang ingin berasumsi di sini bahwa meskipun nilai x mungkin tidak pasti, itu akan sama untuk setiap contoh, dan orang dapat melakukan ini menggunakan fungsi
AroundReplace (perhatikan hasilnya berbeda):
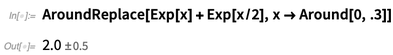
Ada banyak kehalusan dalam cara menampilkan angka yang tidak pasti. Seperti berapa banyak trailing 0s yang harus Anda masukkan:

Atau seberapa banyak ketepatan ketidakpastian yang harus Anda sertakan (ada breakpoint konvensional ketika trailing digit 35):

Dalam kasus yang jarang terjadi di mana banyak digit diketahui (pikirkan, misalnya, beberapa
konstanta fisik ), seseorang ingin pergi ke cara yang berbeda untuk menentukan ketidakpastian:

Dan itu terus berlanjut. Namun secara bertahap
Around akan mulai muncul di seluruh sistem. Omong-omong, ada banyak cara lain untuk menentukan angka
Sekitar . Ini adalah angka dengan kesalahan relatif 10%:

Ini adalah yang terbaik yang bisa dilakukan
Sekitar dalam mewakili suatu interval:

Untuk
distribusi ,
Around menghitung varian:
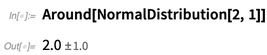
Itu juga dapat memperhitungkan asimetri dengan memberikan ketidakpastian asimetris:

Matematika Klasik, Dasar dan Mahir
Dalam membuat komputasi matematika, itu selalu menjadi tantangan untuk keduanya dapat "mendapatkan semuanya dengan benar", dan tidak membingungkan atau mengintimidasi pengguna dasar. Versi 12.0 memperkenalkan beberapa hal untuk membantu. Pertama, cobalah memecahkan
persamaan kuintik yang tak dapat direduksi:

Di masa lalu, ini akan menunjukkan banyak objek
Root eksplisit. Tapi sekarang objek
Root diformat sebagai kotak yang menunjukkan perkiraan nilai numeriknya. Komputasi bekerja persis sama, tetapi tampilan tidak langsung berhadapan dengan orang-orang yang harus tahu tentang angka aljabar.
Ketika kita mengatakan
Integrasi , yang kita maksudkan adalah “menemukan integral”, dalam arti antiderivatif. Tetapi dalam kalkulus dasar, orang ingin melihat konstanta eksplisit dari integrasi (seperti yang selalu ada di
Wolfram | Alpha ), jadi kami menambahkan
opsi untuk itu (dan C [
n ] juga memiliki bentuk output baru yang bagus):
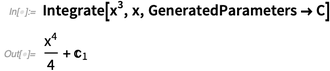
Ketika kami membandingkan kemampuan integrasi simbolis kami, kami melakukannya dengan sangat baik. Tetapi selalu ada lagi yang bisa dilakukan, khususnya dalam hal menemukan bentuk integral yang paling sederhana (dan pada tingkat teoretis ini adalah konsekuensi yang tak terhindarkan dari ketidakpastian kesetaraan ekspresi simbolik). Dalam Versi 12.0 kami terus memilih di perbatasan, menambahkan kasus seperti:

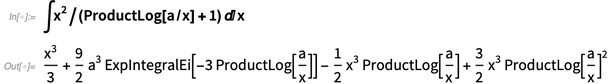
Dalam Versi 11.3 kami memperkenalkan analisis asimptotik, mampu menemukan nilai asimptotik integral dan sebagainya. Versi 12.0 menambahkan jumlah asimptotik, perulangan asimptotik dan solusi asimptotik ke persamaan:
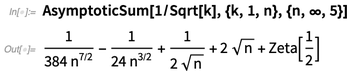
Salah satu hal hebat tentang membuat komputasi matematika adalah memberi kita cara baru untuk menjelaskan matematika itu sendiri. Dan sesuatu yang telah kami lakukan adalah meningkatkan dokumentasi kami sehingga menjelaskan matematika serta fungsinya. Misalnya, inilah awal dokumentasi tentang
Batas - dengan diagram dan contoh gagasan matematika inti:
Poligon telah menjadi bagian dari Bahasa Wolfram sejak Versi 1. Tetapi dalam Versi 12.0 mereka semakin digeneralisasi: sekarang ada cara sistematis untuk menentukan lubang di dalamnya. Kasus penggunaan geografis klasik adalah poligon untuk
Afrika Selatan — dengan lubangnya untuk negara
Lesotho .
Di Versi 12.0, seperti
Root ,
Polygon mendapatkan bentuk tampilan baru yang nyaman:
Anda dapat menghitungnya seperti sebelumnya:
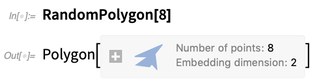
 RandomPolygon
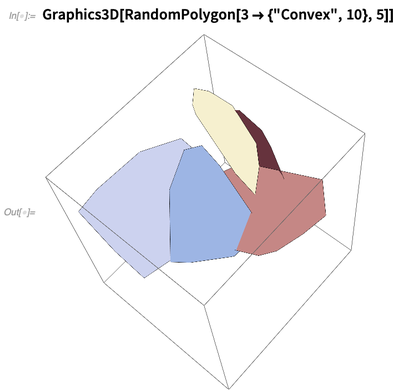
RandomPolygon juga baru. Anda dapat bertanya, katakanlah, untuk 5 poligon cembung acak, masing-masing dengan 10 simpul, dalam 3D:
Ada banyak operasi baru pada poligon. Seperti
PolygonDecomposition , yang dapat, misalnya, menguraikan poligon menjadi bagian cembung:

Poligon berlubang memperkenalkan kebutuhan untuk jenis operasi lain juga, seperti
OuterPolygon ,
SimplePolygonQ , dan
CanonicalizePolygon .
Poligon cukup mudah untuk ditentukan: Anda hanya memberikan simpulnya secara berurutan (dan jika memiliki lubang, Anda juga memberikan simpul untuk lubang tersebut). Polyhedra sedikit lebih rumit: selain memberikan simpul, Anda harus mengatakan bagaimana simpul ini terbentuk. Namun dalam Versi 12.0,
Polyhedron memungkinkan Anda melakukan ini secara umum, termasuk rongga (analog 3D lubang), dll.
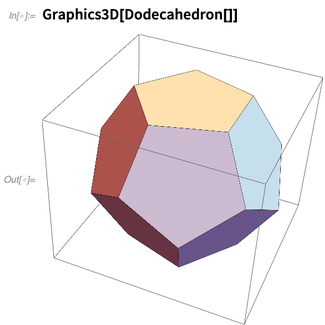
Tapi pertama-tama, dengan mengenali
sejarah 2000+ tahun mereka , Versi 12.0 memperkenalkan fungsi-fungsi untuk lima
padatan Platonis :
Dan mengingat padatan Platonis, seseorang dapat segera mulai menghitung dengan mereka:

Berikut ini sudut solid yang disurvei pada vertex 1 (karena itu Platonis, semua simpul memberikan sudut yang sama):
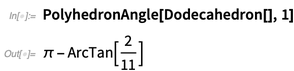
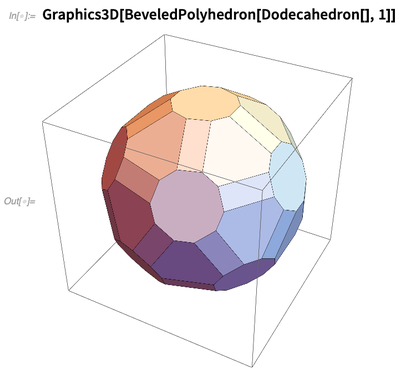
Inilah operasi yang dilakukan pada polyhedron:

Di luar padatan Platonis, Versi 12 juga membangun semua “
seragam polyhedra ” (
n tepi dan wajah bertemu di setiap titik) —dan Anda juga bisa mendapatkan versi
Polyhedron simbolis dari polyhedra yang dinamai
PolyhedronData :

Anda dapat membuat polyhedron apa saja (termasuk yang "acak", dengan
RandomPolyhedron ), lalu melakukan perhitungan apa pun yang Anda inginkan:


Mathematica dan Bahasa Wolfram sangat kuat dalam melakukan baik
geometri komputasi eksplisit dan
geometri yang diwakili dalam hal aljabar . Tetapi bagaimana dengan geometri seperti yang dilakukan dalam
Elemen Euclid — di mana seseorang membuat pernyataan geometris dan kemudian melihat apa konsekuensinya?
Nah, dalam Versi 12, dengan seluruh menara teknologi yang kami bangun, kami akhirnya dapat memberikan gaya komputasi matematika yang baru - yang pada dasarnya mengotomatiskan apa yang dilakukan Euclid 2000+ tahun yang lalu. Gagasan utama adalah untuk memperkenalkan "adegan geometris" simbolis yang memiliki simbol yang mewakili konstruksi seperti titik, dan kemudian untuk menentukan objek geometris dan hubungan dalam hal mereka.
Misalnya, inilah pemandangan geometris yang mewakili segitiga
a, b, c, dan lingkaran melalui
a, b dan
c , dengan pusat
o , dengan batasan bahwa
o berada di titik tengah garis dari
a ke
c :

Sendiri, ini hanya hal simbolis. Tapi kita bisa melakukan operasi padanya. Sebagai contoh, kita dapat meminta contoh acak darinya, di mana
a, b, c dan
o dibuat spesifik:
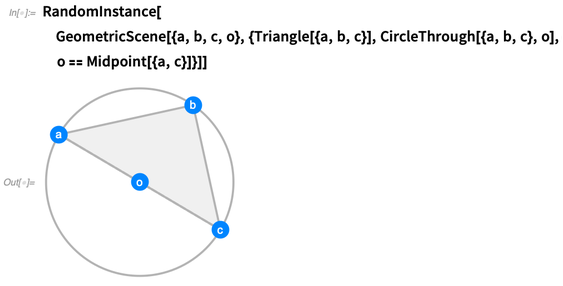
Anda dapat menghasilkan instance acak sebanyak yang Anda inginkan. Kami mencoba membuat instance menjadi generik mungkin, tanpa kebetulan yang tidak dipaksakan oleh kendala:
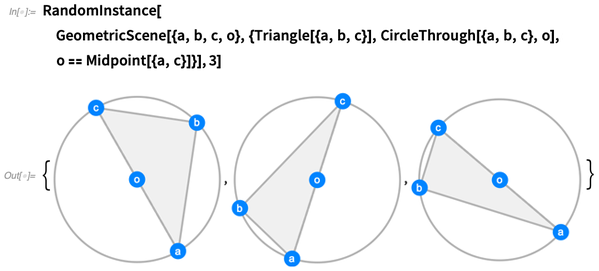
OK, tapi sekarang mari kita "mainkan Euclid", dan temukan dugaan geometris yang konsisten dengan pengaturan kami:

Untuk pemandangan geometris tertentu, mungkin ada banyak dugaan yang mungkin. Kami mencoba memilih yang menarik. Dalam hal ini kita menghasilkan dua - dan apa yang diilustrasikan adalah yang pertama: bahwa garis ba tegak lurus terhadap garis cb. Seperti yang terjadi, hasil ini sebenarnya muncul di Euclid (ada di
Buku 3, sebagai bagian dari Proposisi 31 ) - meskipun biasanya disebut
teorema Thales .
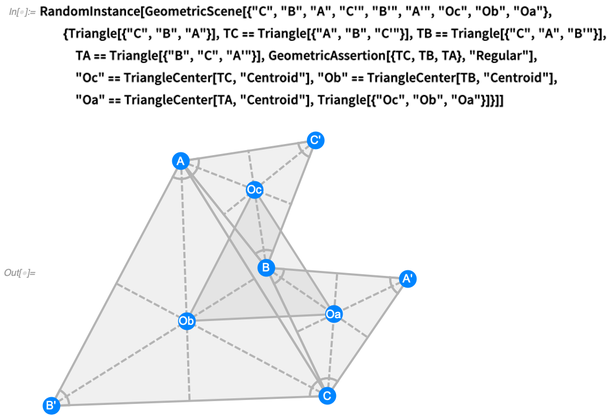
Dalam 12.0, kami sekarang memiliki seluruh bahasa simbolik untuk mewakili hal-hal khas yang muncul dalam geometri gaya Euclid. Inilah situasi yang lebih kompleks - sesuai dengan apa yang disebut
teorema Napoleon :
Di 12.0 ada banyak fungsi geometrik baru dan berguna yang bekerja pada koordinat eksplisit:
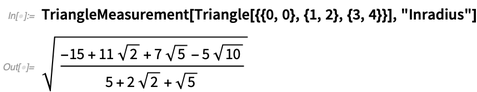
Untuk segitiga ada 12 jenis "pusat" yang didukung, dan, ya, bisa ada koordinat simbolik:

Dan untuk mendukung pengaturan pernyataan geometris kita juga perlu "
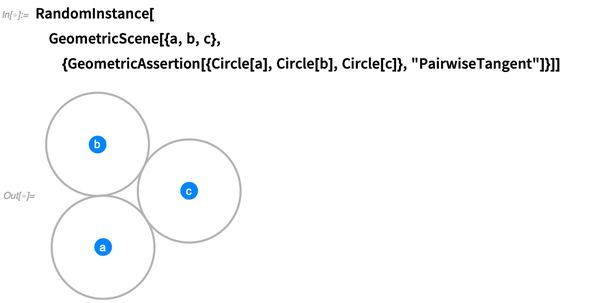
pernyataan geometris ". Dalam 12.0 ada 29 macam - seperti
"Paralel" ,
"Kongruen" ,
"Tangen" ,
"Cembung" , dll. Berikut adalah tiga lingkaran yang dinyatakan sebagai garis singgung berpasangan:
Menjadi Super-Simbolik dengan Teori Aksiomatik
Versi 11.3 memperkenalkan
FindEquationalProof untuk menghasilkan representasi simbol dari bukti. Tetapi aksioma apa yang harus digunakan untuk bukti-bukti ini? Versi 12.0 memperkenalkan
AxiomaticTheory , yang memberikan aksioma untuk berbagai
teori aksiomatik umum.
Inilah
sistem aksioma favorit pribadi saya:

Apa artinya ini? Dalam arti tertentu itu adalah ekspresi simbolik yang lebih simbolis daripada yang biasa kita lakukan. Dalam sesuatu seperti 1 +
x kami tidak mengatakan apa nilai
x , tetapi kami membayangkan bahwa itu dapat memiliki nilai. Dalam ungkapan di atas, a, b dan c adalah "simbol formal" murni yang melayani peran struktural yang esensial, dan tidak dapat dianggap memiliki nilai konkret.
Bagaimana dengan · (titik tengah)? Dalam 1 +
x kita tahu apa artinya +. Tetapi · dimaksudkan untuk menjadi operator yang sepenuhnya abstrak. Titik aksioma ini berlaku untuk
mendefinisikan kendala pada apa yang bisa · mewakili. Dalam kasus khusus ini, ternyata aksioma adalah
aksioma untuk aljabar Boolean , sehingga dapat mewakili
Nand dan
Nor . Tetapi kita dapat memperoleh konsekuensi dari aksioma sepenuhnya secara formal, misalnya dengan
FindEquationalProof :
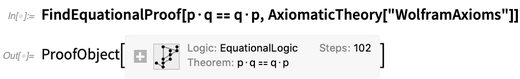
Ada sedikit kehalusan dalam semua ini. Pada contoh di atas, berguna untuk memiliki · sebagai operator, paling tidak karena tampilannya bagus. Tapi tidak ada makna
bawaan untuk itu, dan
AxiomaticTheory memungkinkan Anda memberikan sesuatu yang lain (di sini
f ) sebagai operator:

Apa yang
"Nand" lakukan di sana? Ini adalah nama untuk operator (tetapi tidak harus diartikan sebagai sesuatu yang berkaitan dengan nilai operator). Dalam
aksioma untuk teori grup , misalnya, beberapa operator muncul:
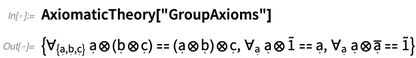
Ini memberikan representasi default dari berbagai operator di sini:
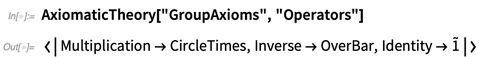 Teori aksiomatik
Teori aksiomatik tahu tentang teorema terkenal untuk sistem aksiomatik tertentu:
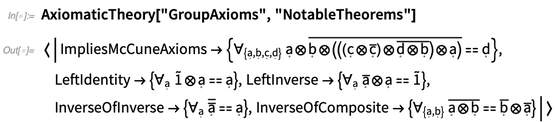
Ide dasar simbol formal diperkenalkan di Versi 7, untuk melakukan hal-hal seperti mewakili variabel dummy dalam konstruksi yang dihasilkan seperti ini:


Anda dapat memasukkan simbol formal menggunakan
\ [FormalA] atau Esc, a, Esc, dll. Tapi di Versi 7,
\ [FormalA] diterjemahkan sebagai
a . Dan itu berarti ungkapan di atas terlihat seperti:

Saya selalu berpikir ini terlihat sangat rumit. Dan untuk Versi 12 kami ingin menyederhanakannya. Kami mencoba banyak kemungkinan, tetapi akhirnya memilih satu-satunya underdots abu-abu - yang menurut saya terlihat jauh lebih baik.
Dalam
AxiomaticTheory , variabel dan operatornya "murni simbolik". Tetapi satu hal yang pasti adalah arity dari masing-masing operator, yang dapat ditanyakan
AxiomaticTheory :
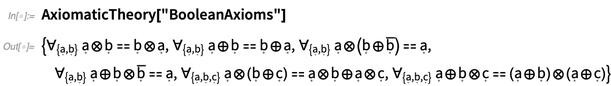

Secara mudah, representasi operator dan arities dapat segera dimasukkan ke dalam
Pengelompokan , untuk mendapatkan kemungkinan ekspresi yang melibatkan variabel-variabel tertentu:

Masalah Tubuh
Teori aksiomatik mewakili area historis klasik untuk matematika. Bidang sejarah klasik lain - lebih banyak di sisi yang diterapkan - adalah
masalah -semua orang . Versi 12.0 memperkenalkan
NBodySimulation , yang memberikan simulasi masalah n-body. Inilah masalah tiga tubuh (pikirkan
Bumi-Bulan-Matahari ) dengan kondisi awal tertentu (dan hukum gaya invers-kuadrat):

Anda dapat bertanya tentang berbagai aspek dari solusi; ini memplot posisi sebagai fungsi waktu:
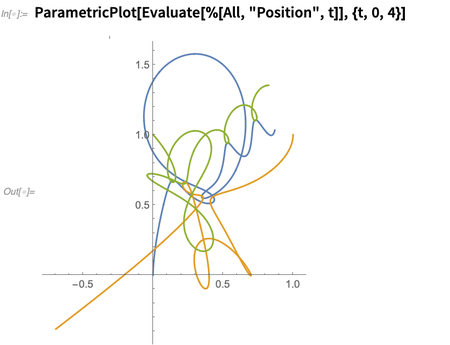
Di bawahnya, ini hanya menyelesaikan persamaan diferensial, tetapi - sedikit seperti
SystemModel -
NBodySimulation menyediakan cara yang nyaman untuk mengatur persamaan dan menangani solusi mereka. Dan, ya, hukum gaya standar sudah ada di dalamnya, tetapi Anda bisa menentukan sendiri.
Ekstensi & Kenyamanan Bahasa
Kami telah memoles inti dari Bahasa Wolfram selama lebih dari 30 tahun sekarang, dan dalam setiap versi berturut-turut kami akhirnya memperkenalkan beberapa ekstensi dan kenyamanan baru.
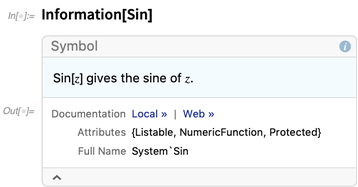
Kami telah memiliki
Informasi fungsi sejak Versi 1.0, tetapi dalam 12.0 kami telah memperluasnya. Dulu hanya memberikan informasi tentang simbol (meskipun itu sudah dimodernisasi juga):
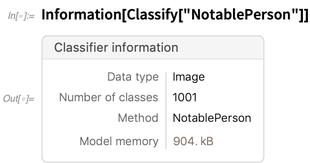
Tetapi sekarang ini juga memberikan informasi tentang banyak jenis objek. Berikut informasi tentang pengelompokan:
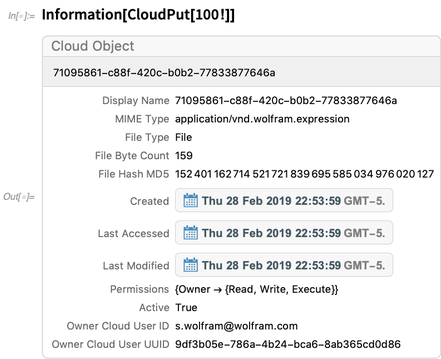
Berikut informasi tentang objek cloud:
Arahkan kursor ke label di "kotak informasi" dan Anda dapat mengetahui nama-nama properti yang sesuai:

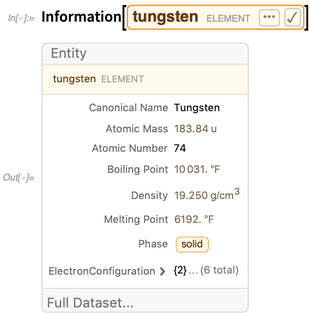
Untuk entitas,
Informasi memberikan ringkasan nilai properti yang dikenal:
Selama beberapa versi terakhir, kami telah memperkenalkan banyak bentuk tampilan ringkasan baru. Dalam Versi 11.3 kami memperkenalkan
Iconize , yang pada dasarnya adalah cara membuat bentuk tampilan ringkasan untuk apa pun. Ikonisasi telah terbukti lebih bermanfaat daripada yang kami perkirakan sebelumnya. Ini bagus untuk menyembunyikan kerumitan yang tidak perlu baik di notebook maupun dalam potongan kode Bahasa Wolfram. Dalam 12.0 kami telah mendesain ulang bagaimana tampilan Ikon, terutama untuk membuatnya "dibaca dengan baik" di dalam ekspresi dan kode.
Anda dapat secara eksplisit memberi ikon pada sesuatu:

Tekan + dan Anda akan melihat beberapa detail:
Tekan

dan Anda akan mendapatkan ekspresi asli lagi:

Jika Anda memiliki banyak data yang ingin Anda rujuk dalam perhitungan, Anda selalu dapat menyimpannya dalam file, atau di
cloud (atau bahkan dalam
repositori data ). Namun, biasanya lebih nyaman untuk meletakkannya di notebook Anda, sehingga Anda memiliki semuanya di tempat yang sama. Salah satu cara untuk menghindari data "mengambil alih notebook Anda" adalah dengan
memasukkannya ke
dalam sel yang tertutup . Tetapi Iconize menyediakan cara yang jauh lebih fleksibel dan elegan untuk melakukan ini.
Saat Anda menulis kode, sering kali mudah untuk "menjadi ikon di tempat". Menu klik kanan sekarang memungkinkan Anda melakukan itu:

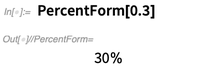
Berbicara tentang tampilan, ini adalah sesuatu yang kecil tapi nyaman yang kami tambahkan di 12.0:
Dan berikut adalah beberapa "kenyamanan nomor" lainnya yang kami tambahkan:

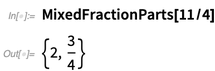
Pemrograman fungsional selalu menjadi bagian utama dari Bahasa Wolfram. Tapi kami terus mencari untuk memperpanjangnya, dan untuk memperkenalkan primitif baru yang umumnya bermanfaat. Contoh dalam Versi 12.0 adalah
SubsetMap :
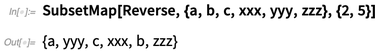

Fungsi biasanya adalah hal-hal yang dapat mengambil beberapa input, tetapi selalu memberikan hasil tunggal. Namun, dalam bidang-bidang seperti
komputasi kuantum , seseorang lebih tertarik untuk memiliki
n input dan output
n .
SubsetMap secara efektif mengimplementasikan fungsi
n-> n , mengambil input dari
n posisi yang ditentukan dalam daftar, menerapkan beberapa operasi padanya, kemudian mengembalikan hasilnya pada posisi yang sama.
Saya mulai merumuskan apa yang sekarang
SubsetMap sekitar setahun yang lalu. Dan saya segera menyadari bahwa sebenarnya saya benar-benar dapat menggunakan fungsi ini di semua tempat selama bertahun-tahun. Tapi apa sebutan “pekerjaan komputasi” ini? Nama kerja awal saya adalah
ArrayReplaceFunction (yang saya disingkat menjadi
ARF dalam catatan saya). Dalam
urutan pertemuan (streaming langsung) kami bolak-balik. Ada ide-ide seperti
ApplyAt (tapi itu tidak benar-benar
Terapkan ) dan
MutateAt (tapi itu tidak melakukan mutasi dalam arti lvalue), serta
RewriteAt ,
ReplaceAt ,
MultipartApply dan
ConstructInPlace . Ada ide-ide tentang bentuk "dekorator fungsi" kari, seperti
PartAppliedFunction ,
PartwiseFunction ,
AppliedOnto ,
AppliedAcross , dan
MultipartCurry .
Tetapi entah bagaimana ketika kami menjelaskan fungsi kami terus kembali untuk berbicara tentang bagaimana itu beroperasi pada subset daftar, dan bagaimana itu benar-benar seperti
Peta , kecuali bahwa itu beroperasi pada beberapa elemen sekaligus. Jadi akhirnya kami memilih nama
SubsetMap . Dan - dalam penguatan lain tentang pentingnya desain bahasa - sungguh luar biasa bagaimana, begitu seseorang memiliki nama untuk hal seperti ini, orang akan segera menemukan dirinya yang dapat memikirkannya, dan melihat di mana ia dapat digunakan.
Selama bertahun-tahun kami telah bekerja keras untuk menjadikan Bahasa Wolfram sistem tingkat tertinggi dan terotomasi untuk melakukan
pembelajaran mesin yang canggih . Sejak awal, kami memperkenalkan “fungsi super”
Klasifikasi dan
Prediksi yang melakukan tugas
klasifikasi dan prediksi dengan cara yang sepenuhnya otomatis, secara otomatis memilih pendekatan terbaik untuk input tertentu yang diberikan. Sepanjang jalan, kami telah memperkenalkan fungsi-fungsi lainnya - seperti
SequencePredict ,
ActiveClassification dan
FeatureExtract .
Dalam Versi 12.0 kita punya beberapa fungsi pembelajaran mesin baru yang penting. Ada
FindAnomalies , yang menemukan "elemen anomali" dalam data:
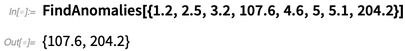
Bersamaan dengan ini, ada
DeleteAnomalies , yang menghapus elemen-elemen yang dianggapnya anomali:

Ada juga
SynthesizeMissingValues , yang mencoba menghasilkan nilai yang masuk akal untuk bagian data yang hilang:
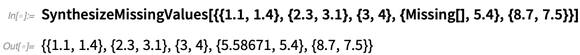
Bagaimana fungsi-fungsi ini bekerja? Semuanya didasarkan pada fungsi baru yang disebut
LearnDistribution , yang mencoba mempelajari distribusi data yang mendasarinya, dengan serangkaian contoh tertentu. Jika contohnya hanya angka, ini pada dasarnya akan menjadi masalah statistik standar, di mana kita dapat menggunakan sesuatu seperti
EstimatedDistribution . Tetapi poin tentang
LearnDistribution adalah ia bekerja dengan data dalam bentuk apa pun, bukan hanya angka. Di sini ia mempelajari distribusi yang mendasari untuk koleksi warna:

Begitu kita memiliki "distribusi yang dipelajari" ini, kita dapat melakukan segala macam hal dengannya. Misalnya, ini menghasilkan 20 sampel acak dari itu:

Tapi sekarang pikirkan tentang
FindAnomalies . Apa yang harus dilakukan adalah mencari tahu titik data mana yang anomali relatif terhadap apa yang diharapkan. Atau, dengan kata lain, mengingat distribusi data yang mendasari, ia menemukan poin data apa yang outlier, dalam arti bahwa mereka harus terjadi hanya dengan probabilitas yang sangat rendah sesuai dengan distribusi.
Dan seperti halnya distribusi numerik biasa, kita dapat menghitung
PDF untuk sepotong data tertentu. Ungu sangat mungkin diberikan distribusi warna yang kami pelajari dari contoh kami:

Tapi merah sebenarnya sangat tidak mungkin:

Untuk distribusi numerik biasa, ada konsep seperti
CDF yang memberi tahu kami probabilitas kumulatif, mengatakan bahwa kami akan mendapatkan hasil yang "lebih jauh" daripada nilai tertentu. Untuk ruang hal-hal yang sewenang-wenang, sebenarnya tidak ada gagasan "lebih jauh". Tapi kami telah datang dengan fungsi yang kami sebut
RarerProbability , yang memberi tahu kami berapa probabilitas total menghasilkan contoh dengan PDF yang lebih kecil daripada yang kami berikan:


Sekarang kita punya cara untuk menggambarkan anomali: mereka hanya titik data yang memiliki probabilitas langka yang sangat kecil. Dan sebenarnya
FindAnomalies memiliki opsi
AcceptanceThreshold (dengan nilai default 0,001) yang menentukan apa yang harus dihitung sebagai "sangat kecil".
OK, tapi mari kita lihat ini bekerja pada sesuatu yang lebih rumit daripada warna. Mari kita latih detektor anomali dengan melihat 1000 contoh digit tulisan tangan:

Sekarang
FindAnomalies dapat memberi tahu kami contoh mana yang anomali:
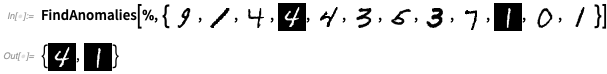
Kami pertama kali memperkenalkan kerangka simbolis kami untuk membangun, mengeksplorasi dan menggunakan jaringan saraf pada tahun 2016, sebagai bagian dari Versi 11. Dan di setiap versi sejak itu kami telah menambahkan semua jenis fitur canggih. Pada bulan Juni 2018 kami memperkenalkan
Neural Net Repository kami untuk memudahkan mengakses model neural net terbaru dari Bahasa Wolfram - dan sudah ada hampir 100 model kurasi dari berbagai jenis dalam repositori, dengan yang baru ditambahkan setiap saat.
Jadi jika Anda memerlukan
jaringan saraf "transformer" BERT terbaru (yang ditambahkan hari ini!), Anda bisa mendapatkannya dari
NetModel :

Anda dapat membuka ini dan melihat jaringan yang terlibat (dan, ya, kami telah memperbarui tampilan grafik bersih untuk Versi 12.0):
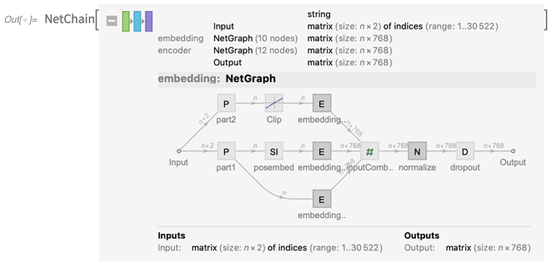
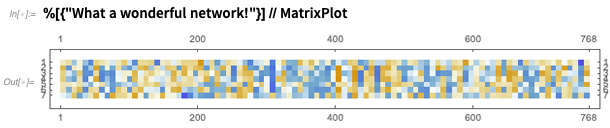
Dan Anda dapat langsung menggunakan jaringan, di sini untuk menghasilkan semacam "fitur fitur" array:
Dalam Versi 12.0 kami telah memperkenalkan beberapa jenis lapisan baru - terutama
AttentionLayer , yang memungkinkan seseorang mengatur arsitektur "transformator" terbaru - dan kami telah meningkatkan kemampuan "pemrograman fungsional neural net" kami, dengan hal-hal seperti
NetMapThreadOperator , dan beberapa urutan
NetFoldOperator . Sebagai tambahan untuk peningkatan “dalam jaring” ini, Versi 12.0 menambahkan semua jenis kasus
NetEncoder dan
NetDecoder baru , seperti
tokenization BPE untuk teks dalam ratusan bahasa, dan kemampuan untuk memasukkan fungsi-fungsi khusus untuk mendapatkan data masuk dan keluar dari jaring saraf.
Tetapi beberapa perangkat tambahan terpenting dalam Versi 12.0 lebih bersifat infrastruktur.
NetTrain sekarang mendukung
pelatihan multi-GPU , serta berurusan dengan aritmatika campuran-presisi, dan kriteria awal yang fleksibel. Kami terus menggunakan kerangka kerja neural net tingkat rendah
MXNet yang populer (yang menjadi
kontributor utama kami ) —sehingga kami dapat memanfaatkan optimasi perangkat keras terbaru. Ada beberapa
opsi baru untuk melihat apa yang terjadi selama pelatihan, dan ada juga
NetMeasurements yang memungkinkan Anda membuat 33 jenis pengukuran yang berbeda pada kinerja jaringan:

Jaring saraf bukan satu-satunya - atau bahkan selalu yang terbaik - cara untuk melakukan pembelajaran mesin. Tetapi satu hal yang baru dalam Versi 12.0 adalah bahwa kita sekarang dapat menggunakan
jaringan normalisasi sendiri secara otomatis di
Klasifikasi dan
Prediksi , sehingga mereka dapat dengan mudah
memanfaatkan jaring saraf ketika itu masuk akal.
Kami memperkenalkan
ImageIdentify , untuk mengidentifikasi gambar apa, dari Versi 10.1. Dalam Versi 12.0 kami telah berhasil menggeneralisasi ini, untuk mengetahui tidak hanya apa gambar itu, tetapi juga apa yang ada dalam gambar. Jadi, misalnya,
ImageCases akan menunjukkan kepada kita kasus jenis objek yang dikenal dalam gambar:

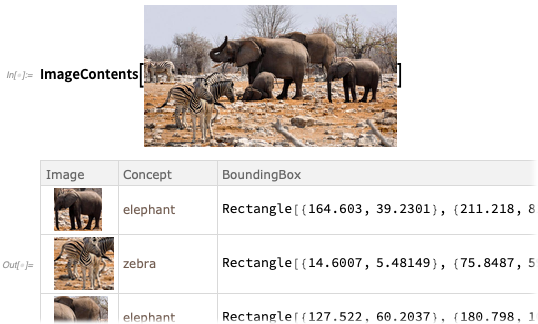
Untuk lebih jelasnya,
ImageContents memberikan dataset tentang apa yang ada dalam gambar:
Anda dapat memberi tahu
ImageCases untuk mencari hal tertentu:

Dan Anda juga bisa hanya menguji untuk melihat apakah suatu gambar mengandung hal tertentu:

Dalam arti tertentu,
ImageCases seperti versi umum
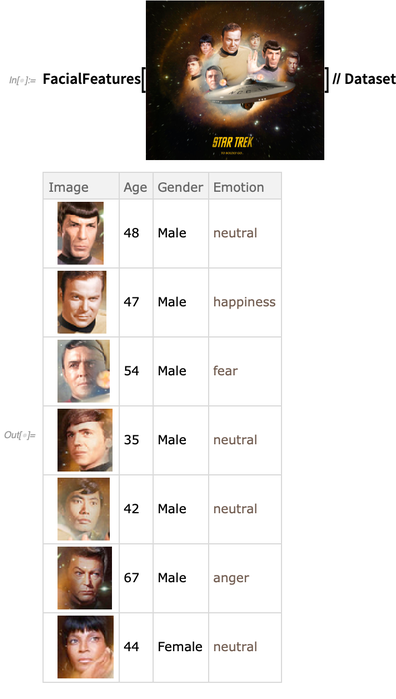
FindFaces , untuk menemukan wajah manusia dalam suatu gambar. Sesuatu yang baru dalam Versi 12.0 adalah bahwa
FindFaces dan
FacialFeatures telah menjadi
lebih efisien dan kuat - dengan
FindFaces sekarang didasarkan pada jaringan saraf daripada pemrosesan gambar klasik, dan jaringan untuk
FacialFeatures sekarang menjadi 10 MB daripada 500 MB:
Fungsi seperti
ImageCases mewakili pemrosesan gambar "gaya baru", dari jenis yang tampaknya tidak mungkin hanya beberapa tahun yang lalu. Tetapi sementara fungsi seperti itu memungkinkan seseorang melakukan segala macam hal baru, masih ada banyak nilai dalam teknik yang lebih klasik. Kami telah memiliki
pemrosesan gambar klasik yang cukup lengkap di Bahasa Wolfram untuk waktu yang lama, tetapi kami terus melakukan peningkatan tambahan.
Contoh dalam Versi 12.0 adalah kerangka kerja
ImagePyramid , untuk melakukan pemrosesan gambar
berskala banyak :

Ada beberapa fungsi baru di Versi 12.0 yang berkaitan dengan perhitungan warna. Gagasan utama adalah
ColorsNear , yang mewakili lingkungan dalam ruang warna perseptual, di sini di sekitar warna
Pink :
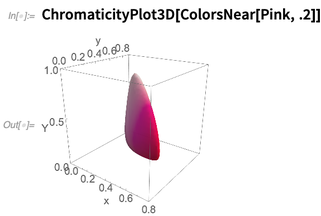
Gagasan lingkungan warna dapat digunakan, misalnya, dalam fungsi
ImageRecolor baru:

Saat saya duduk di depan komputer saya menulis ini, saya akan mengatakan sesuatu ke komputer saya, dan
menangkapnya :
Berikut adalah spektogram audio yang saya ambil:
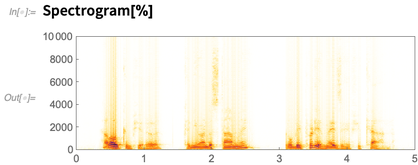
Sejauh ini kita bisa melakukan ini dalam Versi 11.3 (meskipun
Spectrogram mendapat 10 kali lebih cepat dalam 12.0). Tapi sekarang ada sesuatu yang baru:

Kami melakukan pidato-ke-teks! Kami menggunakan teknologi neural net yang canggih, tapi saya kagum pada seberapa baik kerjanya. Ini cukup ramping, dan kami sangat mampu menangani bahkan potongan audio yang sangat panjang, misalnya disimpan dalam file. Dan pada komputer tipikal transkripsi akan berjalan dengan kecepatan real-time yang sebenarnya, sehingga satu jam bicara akan memakan waktu sekitar satu jam untuk transkripsi.
Saat ini kami menganggap
Speech Recognize eksperimental, dan kami akan terus meningkatkannya. Tetapi menarik melihat tugas komputasi utama lainnya hanya menjadi fungsi tunggal dalam Bahasa Wolfram.
Di Versi 12.0, ada perangkat tambahan lain juga.
SpeechSynthesize mendukung bahasa dan suara baru (seperti yang terdaftar oleh
VoiceStyleData []).
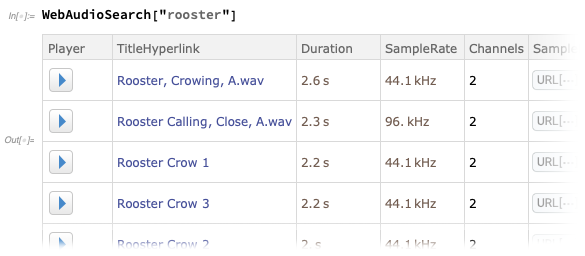
Sekarang ada
WebAudioSearch — analog dengan WebImageSearch — yang memungkinkan Anda mencari audio di web:
Anda dapat mengambil objek
Audio yang sebenarnya:
Kemudian Anda dapat membuat spektogram atau pengukuran lain:

Dan kemudian - baru dalam Versi 12.0 - Anda dapat menggunakan
AudioIdentify untuk mencoba mengidentifikasi kategori suara (apakah itu ayam jago berbicara?):

Kami masih mempertimbangkan
AudioIdentify eksperimental. Ini awal yang menarik, tetapi jelas tidak, misalnya, berfungsi sebaik
ImageIdentify .
Fungsi audio yang lebih sukses adalah
PitchRecognize , yang mencoba mengenali frekuensi dominan dalam sinyal audio (menggunakan metode “klasik” dan neural net). Itu belum bisa berurusan dengan "akord", tetapi bekerja cukup sempurna untuk "nada tunggal".
Ketika seseorang berurusan dengan audio, orang sering ingin tidak hanya mengidentifikasi apa yang ada dalam audio, tetapi juga membuat anotasi. Versi 12.0 memperkenalkan awal
kerangka audio skala besar. Sekarang
AudioAnnotate dapat menandai di mana ada keheningan, atau di mana ada sesuatu yang keras. Di masa mendatang, kami akan menambahkan identifikasi pembicara dan batasan kata, dan banyak lagi lainnya. Dan untuk mengikuti ini, kami juga memiliki fungsi seperti
AudioAnnotationLookup , untuk memilih bagian dari objek audio yang telah dijelaskan dengan cara tertentu.
Di bawah semua fungsionalitas audio tingkat tinggi ini terdapat seluruh infrastruktur pemrosesan audio tingkat rendah. Versi 12.0 sangat meningkatkan
AudioBlockMap (untuk menerapkan filter pada sinyal audio), serta memperkenalkan fungsi seperti
ShortTimeFourier .
Spektrogram dapat dilihat sedikit seperti analog berkelanjutan dari skor musik, di mana nada diplot sebagai fungsi waktu. Dalam Versi 12.0 sekarang ada
InverseSpectrogram - yang beralih dari array data spektrogram ke audio. Sejak Versi 2 pada tahun 1991, kami memiliki
Play untuk menghasilkan suara dari suatu fungsi (seperti
Sin [100 t]). Sekarang dengan
Inverse Spectrogram kita memiliki cara untuk beralih dari "bitmap waktu-frekuensi" menjadi suara. (Dan, ya, ada masalah rumit tentang tebakan terbaik untuk fase ketika seseorang hanya memiliki informasi besar.)
Dimulai dengan
Wolfram | Alpha , kami memiliki
kemampuan pemahaman bahasa alami (NLU) yang sangat kuat untuk waktu yang lama. Dan ini berarti bahwa dengan diberi sepotong bahasa alami, kita pandai memahaminya sebagai Bahasa Wolfram - yang kemudian bisa kita hitung dan hitung dari:
Tetapi bagaimana dengan pemrosesan bahasa alami (NLP) - di mana kita mengambil bagian-bagian yang berpotensi panjang dari bahasa alami, dan tidak mencoba untuk sepenuhnya memahaminya, tetapi malah menemukan atau memproses fitur-fitur tertentu dari mereka? Fungsi seperti
TextSentences ,
TextStructure ,
TextCases dan
WordCounts telah memberi kami kemampuan dasar di bidang ini untuk sementara waktu. Tetapi dalam Versi 12.0 - dengan memanfaatkan pembelajaran mesin terbaru, serta kemampuan NLU dan basis pengetahuan kami yang sudah lama - sekarang kami telah melompat untuk memiliki kemampuan NLP yang sangat kuat.
Bagian tengah adalah versi
TextCases yang ditingkatkan secara dramatis. Tujuan dasar dari
TextCases adalah untuk menemukan kasus dari berbagai jenis konten dalam sepotong teks. Contoh dari ini adalah tugas NLP klasik "pengenalan entitas" - dengan
TextCases di sini menemukan nama negara apa yang muncul di
artikel Wikipedia tentang ocelot :

Kami juga bisa bertanya pulau apa yang disebutkan, tetapi sekarang kami tidak akan meminta interpretasi Bahasa Wolfram:
 TextCases
TextCases tidak sempurna, tetapi cukup baik:

Ini mendukung banyak jenis konten yang berbeda juga:

Anda dapat memintanya untuk menemukan
kata ganti, atau mengurangi klausa relatif , atau
jumlah , atau
alamat email , atau kejadian dari 150 jenis entitas (seperti
perusahaan atau
pabrik atau
film ). Anda juga dapat memintanya untuk memilih bagian teks yang dalam bahasa
manusia atau
komputer tertentu , atau yang
membahas topik tertentu (seperti
perjalanan atau
kesehatan ), atau yang memiliki
sentimen positif atau negatif . Dan Anda dapat menggunakan konstruksi seperti
Berisi untuk meminta kombinasi dari hal-hal ini (seperti frasa kata benda yang berisi nama sungai):
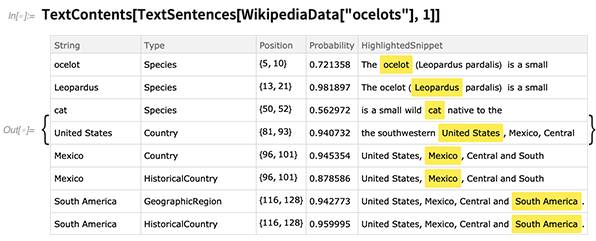
 TextContents
TextContents memungkinkan Anda melihat, misalnya, detail semua entitas yang terdeteksi di bagian teks tertentu:
Dan, ya, pada prinsipnya seseorang dapat menggunakan kemampuan ini melalui
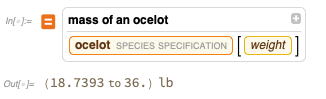
FindTextualAnswer untuk mencoba menjawab pertanyaan dari teks - tetapi dalam kasus seperti ini, hasilnya bisa sangat aneh:

Tentu saja, Anda bisa mendapatkan jawaban nyata dari basis data kurasi bawaan kami yang sebenarnya:
Omong-omong, dalam Versi 12.0 kami telah menambahkan berbagai "fungsi kenyamanan bahasa alami" kecil, seperti
Sinonim dan
Antonim :

Salah satu area "kejutan" baru dalam Versi 12.0 adalah kimia komputasi. Kami telah memiliki data tentang
bahan kimia yang dikenal secara eksplisit di basis pengetahuan kami untuk waktu yang lama. Tetapi dalam Versi 12.0 kita dapat menghitung dengan molekul yang ditentukan hanya sebagai objek simbolis murni. Inilah cara kami menentukan molekul air:

Dan inilah cara kita membuat rendering 3D:
Kita bisa berurusan dengan "bahan kimia yang dikenal":

Kita dapat menggunakan nama
IUPAC yang sewenang-wenang:
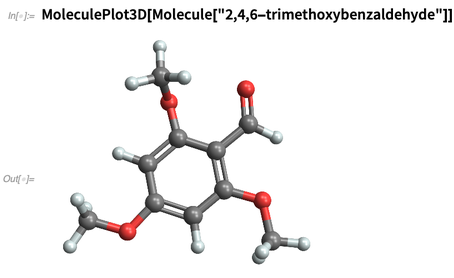
Atau kami "membuat" bahan kimia, misalnya menentukan mereka dengan string
SMILES mereka:
Tapi kami tidak hanya membuat gambar di sini. Kami juga dapat menghitung berbagai hal dari struktur - seperti simetri:
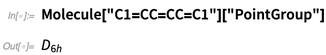
Diberikan molekul, kita dapat melakukan hal-hal seperti menyoroti ikatan karbon-oksigen:
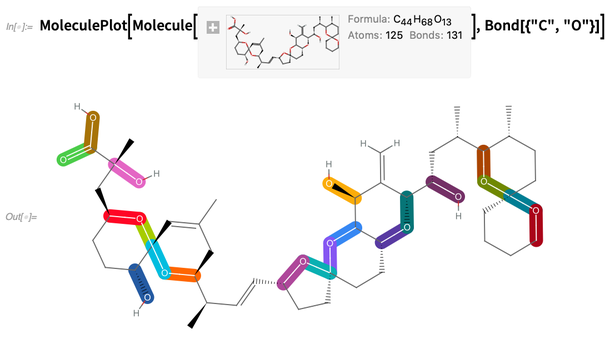
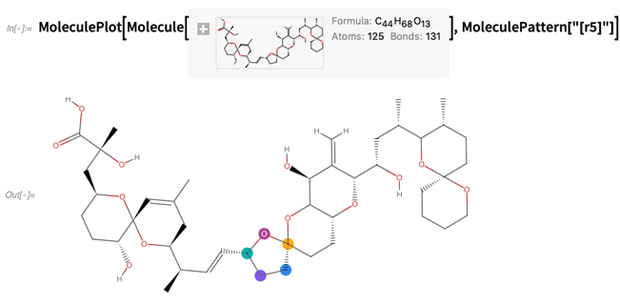
Atau sorot struktur, misalnya ditentukan oleh string
SMARTS (di sini ada 5-anggota dering):
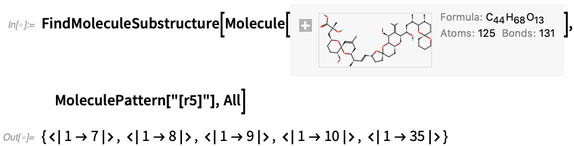
Anda juga dapat melakukan pencarian untuk "pola molekul"; hasilnya muncul dalam hal nomor atom:
Kemampuan kimia komputasi yang kami tambahkan dalam Versi 12.0 cukup umum dan cukup kuat (dengan peringatan bahwa sejauh ini mereka hanya berurusan dengan molekul organik). Pada tingkat terendah, mereka memandang molekul sebagai grafik berlabel dengan tepian yang sesuai dengan ikatan. Tetapi mereka juga tahu tentang fisika, dan dengan benar memperhitungkan valensi atom dan konfigurasi ikatan. Tak perlu dikatakan, ada banyak detail (tentang stereokimia, simetri, aromatisitas, isotop, dll). Tetapi hasil akhirnya adalah bahwa struktur molekul dan perhitungan molekul kini telah berhasil ditambahkan ke daftar area yang diintegrasikan ke dalam Bahasa Wolfram.
Bahasa Wolfram sudah memiliki kemampuan yang kuat untuk komputasi geografis, tetapi Versi 12.0 menambahkan lebih banyak fungsi, dan meningkatkan beberapa fungsi yang sudah ada.
Misalnya, sekarang ada
RandomGeoPosition , yang menghasilkan lokasi lat-panjang acak. Orang mungkin berpikir ini akan sepele, tapi tentu saja kita harus khawatir tentang transformasi koordinat - dan apa yang membuatnya jauh lebih tidak penting adalah bahwa seseorang dapat mengatakannya untuk mengambil poin hanya di dalam wilayah tertentu, di sini negara Prancis:

Tema kemampuan geografis baru dalam Versi 12.0 adalah menangani tidak hanya titik dan wilayah geografis, tetapi juga vektor geografis. Berikut vektor angin saat ini, misalnya, pada posisi Menara Eiffel, direpresentasikan sebagai
GeoVector , dengan kecepatan dan arah (ada juga
GeoVectorENU , yang memberikan komponen timur, utara dan atas, serta
GeoGridVector dan
GeoVectorXYZ ):

Fungsi seperti
GeoGraphics memungkinkan Anda memvisualisasikan vektor geo diskrit.
GeoStreamPlot adalah analog geo dari
StreamPlot (atau
ListStreamPlot ) —dan menunjukkan streamline yang terbentuk dari vektor geo (di sini dari
WindDirectionData ):
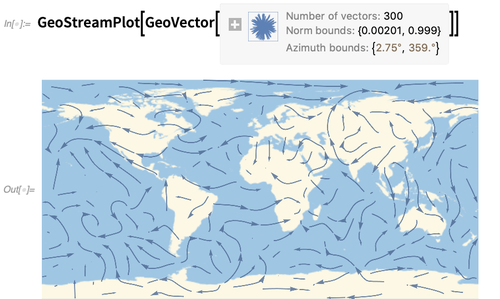
Geodesy adalah bidang yang canggih secara matematis, dan kami bangga melakukannya dengan baik dalam Bahasa Wolfram. Di Versi 12.0, kami telah menambahkan beberapa fungsi baru untuk mengisi beberapa detail. Misalnya, kami sekarang memiliki fungsi seperti
GeoGridUnitDistance dan
GeoGridUnitArea yang memberikan distorsi (pada dasarnya, nilai eigen dari Jacobian) yang terkait dengan proyeksi geo yang berbeda di setiap posisi di Bumi (atau Bulan, Mars, dll.).
Satu arah visualisasi yang terus kami kembangkan adalah apa yang bisa disebut "meta-grafis": pelabelan dan anotasi hal-hal grafis. Kami memperkenalkan
Callout di Versi 11.0; dalam Versi 12.0 itu telah diperluas ke hal-hal seperti grafik 3D:
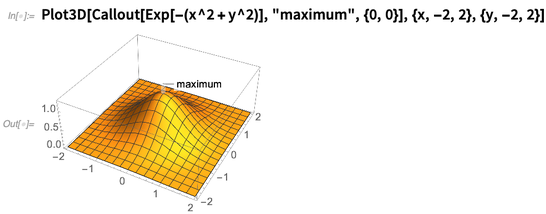
Cukup bagus untuk mencari tahu di mana harus melabeli sesuatu, bahkan ketika mereka sedikit rumit:
Ada banyak detail yang penting dalam membuat grafik benar-benar terlihat bagus. Sesuatu yang telah ditingkatkan di Versi 12.0 adalah memastikan bahwa kolom grafik berbaris pada bingkai mereka, terlepas dari panjang label centang mereka. Kami juga telah menambahkan
LabelVisibility , yang memungkinkan Anda untuk menentukan prioritas relatif yang membuat label yang berbeda terlihat.
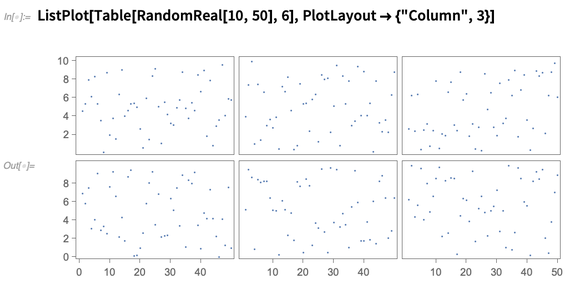
Fitur baru lain dari Versi 12.0 adalah tata letak plot multipanel, di mana dataset berbeda ditampilkan di panel yang berbeda, tetapi panel berbagi sumbu kapan pun mereka bisa:
Integrasi Pengetatan Knowledgebase
Pengetahuan kami yang dikuratori - yang misalnya memperkuat
Wolfram | Alpha - luas dan terus berkembang. Dan dengan setiap versi Bahasa Wolfram kami semakin memperketat integrasinya ke dalam inti bahasa.
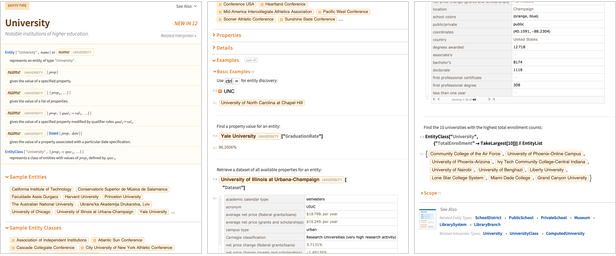
Dalam Versi 12.0 satu hal yang kami lakukan adalah mengekspos ratusan jenis entitas langsung dalam bahasa:

Sebelum Versi 12.0,
halaman Contoh Wolfram | Alpha berfungsi sebagai proksi untuk mendokumentasikan banyak jenis entitas. Tapi sekarang ada dokumentasi Bahasa Wolfram untuk semuanya:
Masih ada fungsi-fungsi seperti
SatelliteData ,
WeatherData dan
FinancialData yang menangani tipe entitas yang secara rutin membutuhkan seleksi atau perhitungan yang kompleks. Tetapi dalam Versi 12.0, setiap jenis entitas dapat diakses dengan cara yang sama, dengan input
bahasa alami ("kontrol + ="), dan entitas dan properti "kotak kuning":

Ngomong-ngomong, seseorang juga dapat menggunakan entitas secara implisit, seperti di sini meminta 5 elemen dengan titik lebur paling dikenal:

Dan seseorang dapat menggunakan
Tanggal untuk mendapatkan serangkaian nilai waktu:

Kami membuatnya sangat nyaman untuk bekerja dengan data yang ada di dalam
Wolfram Knowledgebase . Anda memiliki entitas, dan sangat mudah untuk bertanya tentang properti dan sebagainya:

Tetapi bagaimana jika Anda memiliki data sendiri? Bisakah Anda mengaturnya sehingga Anda dapat menggunakannya semudah ini?
Fitur baru utama dari Versi 11 adalah penambahan
EntityStore , di mana seseorang dapat
mendefinisikan tipe entitas sendiri , lalu menentukan entitas, properti, dan nilai.
Repositori Data Wolfram berisi
banyak contoh toko entitas . Ini satu:
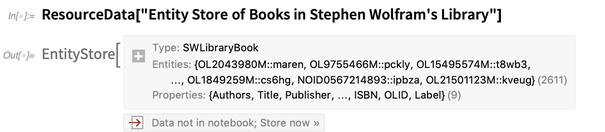
Ini menjelaskan jenis entitas tunggal:
"SWLibraryBook" . Untuk dapat menggunakan entitas jenis ini seperti entitas bawaan, kami "mendaftarkan" toko entitas:

Sekarang kita dapat melakukan hal-hal seperti meminta 10 entitas acak tipe
"SWLibraryBook" :

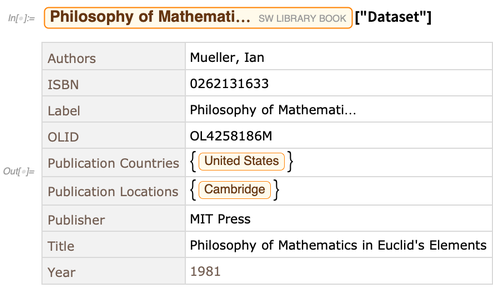
Setiap entitas di toko entitas memiliki berbagai properti. Berikut adalah dataset nilai properti untuk satu entitas tertentu:
OK, tetapi dengan pengaturan ini pada dasarnya kita membaca seluruh isi dari toko entitas ke dalam memori. Ini membuatnya sangat efisien untuk melakukan apa pun operasi Bahasa Wolfram yang diinginkannya. Tapi itu bukan solusi scalable yang baik untuk data dalam jumlah besar - misalnya, data yang terlalu besar untuk dapat disimpan dalam memori.
Tapi apa sumber data besar yang khas? Sangat sering itu adalah database, dan biasanya yang relasional yang dapat diakses menggunakan
SQL . Kami telah memiliki
paket DatabaseLink kami untuk akses baca-tulis tingkat rendah ke database SQL selama lebih dari satu dekade. Tetapi dalam Versi 12.0 kami menambahkan beberapa fitur bawaan utama yang memungkinkan basis data relasional eksternal ditangani dalam Bahasa Wolfram seperti halnya toko entitas, atau bagian bawaan dari Wolfram Knowledgebase.
Mari kita mulai dengan contoh mainan. Berikut ini adalah representasi simbolis dari database relasional kecil yang kebetulan disimpan dalam file:

Segera kami mendapatkan kotak yang merangkum apa yang ada di database, dan memberi tahu kami bahwa database ini memiliki 8 tabel. Jika kita membuka kotak itu, kita dapat mulai memeriksa struktur tabel-tabel itu:

Kami kemudian dapat mengatur basis data relasional ini sebagai entitas toko di Bahasa Wolfram. Itu terlihat sangat mirip dengan toko entitas buku perpustakaan di atas, tetapi sekarang data aktual tidak ditarik ke dalam memori; alih-alih itu masih dalam database relasional eksternal, dan kami hanya mendefinisikan pemetaan ("mirip-ORM") ke entitas dalam Bahasa Wolfram:
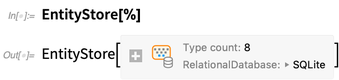
Sekarang kita dapat mendaftarkan toko entitas ini, yang mengatur sekelompok jenis entitas yang (setidaknya secara default) dinamai sesuai nama tabel di database:

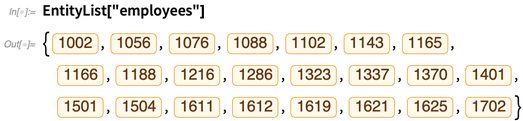
Dan sekarang kita bisa melakukan "perhitungan entitas" pada ini, sama seperti yang kita lakukan pada entitas bawaan di Wolfram Knowledgebase. Setiap entitas di sini sesuai dengan baris dalam tabel "karyawan" dalam database:
Untuk jenis entitas tertentu, kita dapat menanyakan properti apa yang dimilikinya. "Properti" ini sesuai dengan kolom dalam tabel di database yang mendasarinya:

Sekarang kita dapat meminta nilai properti tertentu dari entitas tertentu:
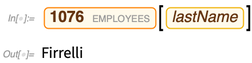
Kami juga dapat memilih entitas dengan memberikan kriteria; di sini kami meminta entitas "pembayaran" dengan 4 nilai terbesar dari properti "jumlah":

Kami dapat secara setara meminta nilai dari jumlah terbesar ini:

OK, tapi di sinilah menjadi lebih menarik: sejauh ini kita telah melihat sedikit basis data yang didukung file. Tetapi kita dapat melakukan hal yang persis sama dengan database raksasa yang dihosting di server eksternal.
Sebagai contoh, mari kita terhubung ke
database OpenStreetMap PostgreSQL berukuran terabyte yang berisi apa yang pada dasarnya peta jalan dunia:
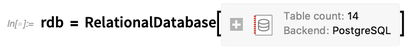
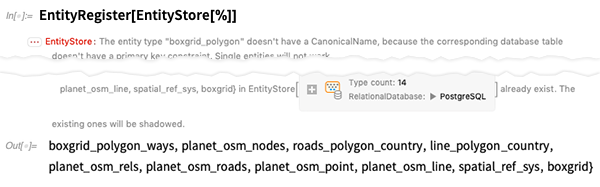
Seperti sebelumnya, mari kita daftarkan tabel dalam database ini sebagai tipe entitas. Seperti kebanyakan database di alam liar, ada sedikit gangguan dalam struktur, yang dikerjakan, tetapi menghasilkan peringatan:
Tetapi sekarang kita dapat mengajukan pertanyaan tentang basis data - seperti berapa banyak titik geografis atau "titik" yang ada di semua jalan di dunia (dan, ya, ini adalah angka yang besar, itulah sebabnya mengapa basis data itu besar):

Di sini kami meminta nama-nama objek dengan 10 area terbesar (yang diproyeksikan) di tabel (101 GB) planet_osm_polygon (dan, ya, dibutuhkan di bawah satu detik):

Jadi bagaimana cara kerjanya? Pada dasarnya apa yang terjadi adalah bahwa representasi Bahasa Wolfram kami dikompilasi ke dalam kueri SQL tingkat rendah yang kemudian dikirim untuk dieksekusi langsung pada server database.
Terkadang Anda akan meminta hasil yang hanya nilai akhir (seperti, katakanlah, "jumlah" di atas). Tetapi dalam kasus lain Anda akan menginginkan sesuatu yang sedang - seperti kumpulan entitas yang telah dipilih dengan cara tertentu. Dan tentu saja koleksi ini dapat memiliki satu miliar entri. Jadi fitur yang sangat penting dari apa yang kami perkenalkan dalam Versi 12.0 adalah bahwa kami dapat mewakili dan memanipulasi hal-hal semacam itu secara simbolis, menyelesaikannya ke sesuatu yang spesifik hanya di bagian akhir.
Kembali ke basis data mainan kami, berikut ini adalah contoh bagaimana kami menentukan kelas entitas yang diperoleh dengan mengagregasi
Batas kredit total untuk semua
pelanggan dengan nilai
negara tertentu :

Pada awalnya, ini hanya sesuatu yang simbolis. Tetapi jika kita meminta nilai tertentu, maka permintaan basis data aktual diselesaikan, dan kita mendapatkan hasil spesifik:

Ada keluarga fungsi baru untuk mengatur berbagai jenis kueri. Dan fungsi sebenarnya bekerja tidak hanya untuk database relasional, tetapi juga untuk toko entitas, dan untuk built-in Wolfram Knowledgebase. Jadi, misalnya, kita dapat meminta massa atom rata-rata untuk periode tertentu dalam
tabel periodik unsur :

Konstruk baru yang penting adalah
EntityFunction .
EntityFunction seperti
Function , kecuali variabel-variabelnya mewakili entitas (atau kelas entitas) dan menggambarkan operasi yang dapat dilakukan secara langsung pada database eksternal. Berikut adalah contoh dengan data bawaan, di mana kami mendefinisikan kelas entitas "difilter" di mana kriteria penyaringan adalah fungsi yang menguji nilai populasi.
FilteredEntityClass itu sendiri hanya diwakili secara simbolis, tetapi
EntityList benar-benar melakukan kueri, dan menyelesaikan daftar eksplisit entitas (di sini, tidak disortir):


Selain
EntityFunction ,
AggregatedEntityClass dan
SortedEntityClass , Versi 12.0 termasuk
SampledEntityClass (untuk mendapatkan beberapa entitas dari kelas),
ExtendedEntityClass (untuk menambahkan properti yang dihitung) dan
CombinedEntityClass (untuk menggabungkan properti dari kelas yang berbeda). Dengan primitif ini, seseorang dapat membangun semua operasi standar "
aljabar relasional ".
Dalam pemrograman basis data standar, seseorang biasanya berakhir dengan seluruh hutan "bergabung" dan "kunci asing" dan seterusnya. Representasi Bahasa Wolfram kami memungkinkan Anda beroperasi di tingkat yang lebih tinggi - di mana pada dasarnya bergabung menjadi komposisi fungsi dan kunci asing hanyalah jenis entitas yang berbeda. (Jika Anda ingin melakukan penggabungan eksplisit, Anda bisa - misalnya menggunakan
CombinedEntityClass .)
Apa yang terjadi di bawah tenda adalah bahwa semua konstruksi Bahasa Wolfram dikompilasi ke dalam SQL, atau, lebih tepatnya, dialek khusus
SQL yang cocok untuk basis data tertentu yang Anda gunakan (saat ini kami mendukung
SQLite ,
MySQL ,
PostgreSQL , dan
MS -SQL , dengan dukungan untuk
OracleSQL segera hadir). Ketika kami melakukan kompilasi, kami secara otomatis memeriksa jenis, untuk memastikan Anda mendapatkan permintaan yang bermakna. Bahkan spesifikasi Bahasa Wolfram yang cukup sederhana dapat berubah menjadi banyak baris SQL. Misalnya,

akan menghasilkan SQL perantara berikut (di sini untuk menanyakan basis data SQLite):

Sistem integrasi basis data yang kami miliki di Versi 12.0 cukup canggih - dan kami telah mengusahakannya selama beberapa tahun. Ini adalah langkah penting ke depan dalam memungkinkan Bahasa Wolfram untuk secara langsung menangani tingkat baru "besar" dalam data besar - dan untuk membiarkan Bahasa Wolfram secara langsung melakukan ilmu data pada dataset berukuran terabyte dan seterusnya. Seperti menemukan entitas seperti jalan mana di dunia yang memiliki "Wolfram" dalam nama mereka:

Apa cara terbaik untuk merepresentasikan pengetahuan tentang dunia? Ini adalah masalah yang telah diperdebatkan oleh para filsuf (dan lainnya) sejak jaman dahulu. Terkadang orang mengatakan logika adalah kuncinya. Terkadang matematika. Terkadang basis data relasional. Tapi sekarang kita setidaknya tahu satu dasar yang kuat (atau setidaknya, saya cukup yakin kita tahu): semuanya dapat diwakili oleh perhitungan. Ini adalah ide yang kuat - dan dalam arti itulah yang membuat semua yang kami lakukan dengan Bahasa Wolfram mungkin.
Tetapi apakah ada himpunan bagian dari perhitungan umum yang berguna untuk mewakili setidaknya jenis pengetahuan tertentu? Salah satu yang kami gunakan secara luas dalam
Wolfram Knowledgebase adalah gagasan tentang entitas ("Kota New York"), properti ("populasi") dan nilai-nilainya ("8,6 juta orang"). Tentu saja tiga kali lipat seperti itu tidak mewakili semua pengetahuan di dunia ("apa yang akan terjadi dengan posisi Mars besok?"). Tapi mereka adalah awal yang baik ketika datang ke jenis "statis" pengetahuan tentang hal-hal yang berbeda.
Jadi bagaimana kita bisa memformalkan representasi pengetahuan semacam ini? Salah satu jawabannya adalah melalui basis data grafik. Dan dalam Versi 12.0 - sejalan dengan banyak proyek
"web semantik" - kami mendukung
basis data grafik menggunakan
RDF , dan menanyakannya dengan menggunakan
SPARQL . Dalam RDF objek utama adalah
IRI ("Pengidentifikasi Sumberdaya Internasional"), yang dapat mewakili entitas atau properti. "
Triplestore " kemudian terdiri dari kumpulan tiga kali lipat ("subjek", "predikat", "objek"), dengan masing-masing elemen dalam setiap triple menjadi IRI (atau literal, seperti angka). Seluruh objek kemudian dapat dianggap sebagai basis data grafik atau toko grafik, atau, secara matematis, sebuah hypergraph. (Ini
hypergraph karena "tepi" predikat juga bisa menjadi simpul di tempat lain.)
Anda dapat membangun
RDFStore Anda sendiri seperti halnya Anda membangun
EntityStore — dan pada kenyataannya Anda dapat meminta setiap
EntriStore Bahasa Wolfram menggunakan SPARQL sama seperti Anda meminta
RDFStore . Dan karena bagian entitas-properti dari Wolfram Knowledgebase dapat diperlakukan sebagai toko entitas, Anda juga dapat menanyakan ini. Jadi di sini, akhirnya, adalah sebuah contoh. Daftar negara-kota
Entity ["
Country "],
Entity ["
City "]} yang berlaku mewakili toko RDF. Maka
SPARQLSelect adalah operator yang bertindak di toko ini. Apa yang dilakukannya adalah mencoba menemukan triple yang cocok dengan yang Anda minta, dengan nilai tertentu untuk "variabel SPARQL" x:
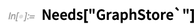

Tentu saja, ada juga cara yang lebih sederhana untuk melakukan ini dalam Bahasa Wolfram:
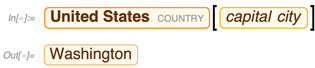
Tetapi dengan SPARQL Anda dapat melakukan banyak hal yang lebih eksotis - seperti bertanya properti apa yang menghubungkan AS dengan Meksiko:

Atau apakah ada jalur berdasarkan hubungan negara yang berbatasan dari Portugal ke Jerman:

Pada prinsipnya Anda hanya dapat menulis kueri SPARQL sebagai string (agak seperti Anda dapat menulis string SQL). Tetapi apa yang telah kami lakukan di Versi 12.0 adalah memperkenalkan representasi simbolis dari SPARQL yang memungkinkan penghitungan pada representasi itu sendiri, sehingga memudahkan, misalnya, untuk secara otomatis menghasilkan kueri SPARQL yang kompleks. (Dan ini sangat penting untuk melakukan ini karena, pada mereka sendiri, pertanyaan SPARQL praktis memiliki kebiasaan menjadi sangat panjang dan berat.)
OK, tapi apakah ada toko RDF di alam bebas? Sudah lama ada harapan bahwa sebagian besar web akan ditandai cukup untuk "menjadi semantik" dan pada dasarnya menjadi toko RDF raksasa. Akan lebih bagus jika ini terjadi, tetapi sejauh ini pasti tidak. Namun, ada beberapa toko RDF publik di luar sana, dan juga beberapa toko RDF di dalam organisasi, dan dengan kemampuan baru kami dalam Versi 12.0 kami berada dalam posisi unik untuk melakukan hal-hal menarik dengan mereka.
Bentuk masalah yang sangat umum dalam aplikasi industri matematika adalah: "Konfigurasi apa yang meminimalkan biaya (atau memaksimalkan hasil) jika kendala tertentu harus dipenuhi?" Lebih dari setengah abad yang lalu, apa yang disebut
algoritma simpleks diciptakan untuk menyelesaikan versi linear dari masalah semacam ini, di mana fungsi objektif (biaya, hasil) dan kendala adalah fungsi linier dari variabel dalam masalah. Pada 1980-an, jauh lebih efisien ("titik interior") metode telah ditemukan - dan kami memiliki ini untuk melakukan "
pemrograman linier " dalam Bahasa Wolfram untuk waktu yang lama.
Tapi bagaimana dengan masalah nonlinear? Nah, dalam kasus umum, seseorang dapat menggunakan fungsi seperti NMinimize. Dan mereka melakukan pekerjaan yang canggih. Tapi ini masalah yang sulit. Namun, beberapa tahun yang lalu, menjadi jelas bahwa bahkan di antara masalah optimasi nonlinier, ada kelas yang disebut masalah optimasi cembung yang benar-benar dapat diselesaikan hampir seefisien yang linear. ("Cembung" berarti bahwa baik tujuan dan kendala hanya melibatkan fungsi cembung - sehingga tidak ada yang bisa "bergoyang" ketika seseorang mendekati sebuah ekstrem, dan tidak ada minima lokal yang bukan minima global.)
Dalam Versi 12.0, kami sekarang memiliki implementasi yang kuat untuk semua kelas standar berbagai optimasi cembung. Inilah kasus sederhana, yang melibatkan meminimalkan bentuk kuadratik dengan beberapa kendala linier:
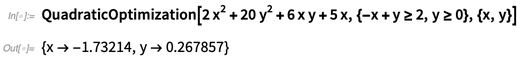 NMinimize
NMinimize sudah bisa melakukan masalah khusus ini di Versi 11.3:

Tetapi jika seseorang memiliki lebih banyak variabel,
NMinimasi lama akan dengan cepat macet. Namun, dalam Versi 12.0,
Optimasi Quadratic akan terus berfungsi dengan baik, hingga lebih dari 100.000 variabel dengan lebih dari 100.000 kendala (asalkan cukup jarang).
Dalam Versi 12.0 kita punya fungsi “raw convex optimization” seperti
SemidefiniteOptimization (yang menangani ketidaksetaraan matriks linear) dan
ConicOptimization (yang menangani ketidaksetaraan vektor linear). Tetapi fungsi seperti
NMinimize dan
FindMinimum juga akan secara otomatis mengenali kapan masalah dapat diselesaikan secara efisien dengan ditransformasikan ke bentuk optimisasi cembung.
Bagaimana cara mengatur masalah optimisasi cembung? Yang lebih besar melibatkan kendala pada seluruh vektor atau matriks variabel. Dan dalam Versi 12.0 kami sekarang memiliki fungsi seperti
VectorGreaterEqual (input ≥) yang dapat langsung mewakili ini.
Persamaan diferensial parsial sulit, dan kami telah bekerja pada cara yang lebih canggih dan umum untuk menanganinya selama 30 tahun. Kami pertama kali memperkenalkan
NDSolve (untuk
ODE ) di
Versi 2, kembali pada tahun 1991 . Kami memiliki PDE numerik pertama (1 + 1-dimensi) kami pada pertengahan 1990-an. Pada tahun 2003 kami memperkenalkan kerangka modular kami yang kuat untuk menangani persamaan diferensial numerik. Namun dalam hal PDE, kami pada dasarnya hanya berurusan dengan daerah empat persegi yang sederhana. Untuk melampaui itu diperlukan membangun seluruh
sistem geometri komputasi kami, yang kami perkenalkan di Versi 10. Dan dengan ini, kami merilis
elemen pemecah PDE elemen hingga pertama kami . Dalam Versi 11, kami kemudian digeneralisasi untuk
masalah eigen .
Sekarang, dalam Versi 12, kami memperkenalkan generalisasi besar lainnya: analisis elemen hingga nonlinier. Analisis elemen hingga melibatkan daerah penguraian menjadi segitiga diskrit kecil, tetrahedra, dll. - di mana PDE asli dapat didekati dengan sejumlah besar persamaan yang digabungkan. Ketika PDE asli linier, persamaan ini juga akan linear - dan itulah kasus khas yang dipertimbangkan orang ketika mereka berbicara tentang "analisis elemen hingga".
Tetapi ada banyak PDE yang memiliki kepentingan praktis yang tidak linier - dan untuk mengatasinya diperlukan analisis elemen hingga nonlinier, yang sekarang kita miliki dalam Versi 12.0.
Sebagai contoh, inilah yang diperlukan untuk menyelesaikan PDE nonlinear mengerikan yang menggambarkan ketinggian permukaan minimal 2D (katakanlah, film sabun ideal), di sini di atas anulus, dengan kondisi batas (Dirichlet) yang membuatnya bergoyang secara sinusoidal di tepi (seolah-olah film sabun ditangguhkan dari kabel):
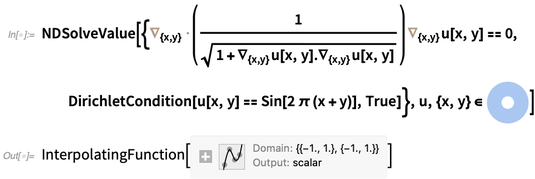
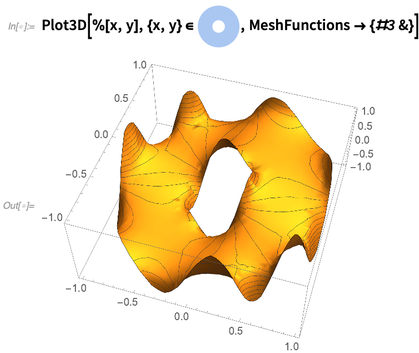
Di komputer saya hanya dibutuhkan seperempat detik untuk menyelesaikan persamaan ini, dan mendapatkan fungsi interpolasi. Berikut adalah plot fungsi interpolasi yang mewakili solusinya:
Kami telah menempatkan banyak teknik dalam mengoptimalkan pelaksanaan program Bahasa Wolfram selama bertahun-tahun. Sudah pada tahun 1989 kami mulai secara otomatis menyusun perhitungan numerik presisi mesin sederhana untuk instruksi untuk mesin virtual yang efisien (dan, seperti yang terjadi, saya menulis kode asli untuk ini). Selama bertahun-tahun, kami telah memperluas kemampuan kompiler ini, tetapi selalu terbatas pada program yang cukup sederhana.
Dalam Versi 12.0 kami mengambil langkah besar ke depan, dan kami merilis versi pertama dari kompiler baru yang jauh lebih kuat yang telah kami kerjakan selama beberapa tahun. Kompiler ini mampu menangani berbagai program yang jauh lebih luas (termasuk konstruksi fungsional yang kompleks dan aliran kontrol yang rumit), dan juga mengkompilasi bukan ke mesin virtual melainkan langsung ke kode mesin asli yang dioptimalkan.
Dalam Versi 12.0 kami masih mempertimbangkan kompiler eksperimental baru. Tapi ini berkembang pesat, dan itu akan memiliki efek dramatis pada efisiensi banyak hal dalam Bahasa Wolfram. Dalam Versi 12.0, kami hanya mengekspos "bentuk kit" dari kompiler baru, dengan fungsi kompilasi tertentu. Tapi kita akan semakin membuat kompiler beroperasi lebih dan lebih secara otomatis - mencari tahu dengan pembelajaran mesin dan metode lain ketika ada baiknya meluangkan waktu untuk melakukan apa tingkat kompilasi.
Pada tingkat teknis, kompiler Versi 12.0 baru didasarkan pada LLVM, dan bekerja dengan menghasilkan kode LLVM - menghubungkan di perpustakaan runtime tingkat rendah yang sama dengan yang digunakan oleh kernel Bahasa Wolfram sendiri, dan memanggil kembali ke kernel Bahasa Wolfram penuh untuk fungsionalitas yang tidak ada di pustaka runtime.
Inilah cara dasar seseorang mengkompilasi fungsi murni dalam versi saat ini dari kompiler baru:

Fungsi kode terkompilasi yang dihasilkan bekerja seperti fungsi aslinya, meskipun lebih cepat:
Bagian besar dari apa yang memungkinkan
FunctionCompile menghasilkan fungsi yang lebih cepat adalah Anda mengatakannya untuk membuat asumsi tentang jenis argumen yang akan didapat. Kami mendukung banyak tipe dasar (seperti "
Integer32 " dan "
Real64 "). Tetapi ketika Anda menggunakan
FunctionCompile , Anda berkomitmen untuk jenis argumen tertentu, jadi lebih banyak kode yang ramping dapat diproduksi.
Banyak kecanggihan dari kompiler baru dikaitkan dengan menyimpulkan jenis data apa yang akan dihasilkan dalam pelaksanaan suatu program. (Ada banyak teori grafik dan algoritma lain yang terlibat, dan tidak perlu dikatakan, semua pemrograman pemrograman untuk kompiler dilakukan dengan Bahasa Wolfram.)
Berikut adalah contoh yang melibatkan sedikit inferensi tipe (tipe
fib disimpulkan menjadi
"Integer64" -> "Integer64" : fungsi integer mengembalikan integer):

Di komputer saya
cf [25] berjalan sekitar 300 kali lebih cepat daripada fungsi yang tidak dikompilasi. (Tentu saja, versi yang dikompilasi gagal ketika outputnya tidak lagi bertipe "
Integer64 ", tetapi versi standar Bahasa Wolfram tetap berfungsi dengan baik.)
Kompiler dapat menangani ratusan primitif pemrograman Bahasa Wolfram, dengan tepat melacak jenis apa yang dihasilkan - dan menghasilkan kode yang secara langsung mengimplementasikan primitif ini. Namun, kadang-kadang, seseorang ingin menggunakan fungsi-fungsi canggih dalam Bahasa Wolfram yang tidak masuk akal untuk menghasilkan kode kompilasi sendiri - dan di mana yang benar-benar ingin dilakukan hanyalah memanggil ke dalam bahasa Bahasa Wolfram untuk fungsi-fungsi ini . Dalam Versi 12.0
KernelFunction memungkinkan seseorang melakukan ini:

OK, tapi katakanlah seseorang memiliki fungsi kode yang dikompilasi. Apa yang bisa dilakukan dengan itu? Yah, pertama-tama kita bisa menjalankannya di dalam Bahasa Wolfram. Seseorang dapat menyimpannya juga, dan menjalankannya nanti. Kompilasi khusus apa pun dilakukan untuk arsitektur prosesor tertentu (mis. 64-bit x86). Tetapi
CompiledCodeFunction secara otomatis menyimpan cukup informasi untuk melakukan kompilasi tambahan untuk arsitektur yang berbeda jika diperlukan.
Tetapi mengingat
CompiledCodeFunction , salah satu kemungkinan baru yang menarik adalah seseorang dapat secara langsung menghasilkan kode yang dapat dijalankan bahkan di luar lingkungan Bahasa Wolfram. (Kompiler lama kami memiliki paket
CCodeGenerate yang menyediakan kemampuan yang sedikit mirip dalam kasus-kasus sederhana - meskipun kemudian bergantung pada toolchain rumit dari kompiler C dll.)
Inilah cara seseorang dapat mengekspor kode LLVM mentah (perhatikan bahwa hal-hal seperti optimasi rekursi ekor dilakukan secara otomatis - dan perhatikan juga fungsi simbolis dan opsi kompiler di akhir):

Jika seseorang menggunakan
FunctionCompileExportLibrary , maka seseorang akan mendapatkan file library - .dylib di Mac, .dll di Windows dan .so di Linux. Satu dapat menggunakan ini di Bahasa Wolfram dengan melakukan
LibraryFunctionLoad . Tetapi orang juga dapat menggunakannya dalam program eksternal.
Salah satu hal utama yang menentukan generalisasi dari kompiler baru adalah kekayaan sistem tipenya. Saat ini kompiler mendukung
14 jenis atom (seperti "
Boolean ", "
Integer8 ", "
Complex64 ", dll.). Ini juga mendukung konstruktor tipe seperti "
PackedArray " —sehingga, misalnya,
TypeSpecifier ["
PackedArray "] [
"Real64", 2 ] sesuai dengan array paket-2 yang dikemas dari real-bit 64-bit.
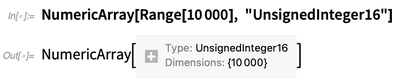
Dalam implementasi internal Bahasa Wolfram (yang, omong-omong, sebagian besar sendiri dalam Bahasa Wolfram) kami telah memiliki cara yang dioptimalkan untuk menyimpan array untuk waktu yang lama. Dalam Versi 12.0 kami mengeksposnya sebagai
NumericArray . Tidak seperti konstruksi Bahasa Wolfram biasa, Anda harus memberi tahu
NumericArray secara terperinci bagaimana seharusnya menyimpan data. Tapi kemudian bekerja dengan cara yang bagus dan dioptimalkan:

Dalam Versi 11.2 kami memperkenalkan
ExternalEvaluate , yang memungkinkan Anda melakukan perhitungan dalam bahasa seperti
Python dan
JavaScript dari dalam Bahasa Wolfram (dalam
Python , “^” berarti
BitXor ):

Dalam Versi 11.3, kami memperkenalkan sel-sel bahasa eksternal, untuk membuatnya mudah untuk memasukkan program-program bahasa eksternal atau input lainnya langsung di notebook:

Di Versi 12.0, kami memperketat integrasi. Misalnya, di dalam string bahasa eksternal, Anda dapat menggunakan <* ... *> untuk memberikan kode Bahasa Wolfram untuk mengevaluasi:

Ini juga berfungsi dalam sel bahasa eksternal:

Tentu saja, Python bukan Bahasa Wolfram, jadi banyak hal yang tidak berfungsi:

Tapi
ExternalEvaluate setidaknya dapat mengembalikan banyak jenis data dari Python, termasuk daftar (sebagai
Daftar ), kamus (sebagai
Asosiasi ), gambar (sebagai
Gambar ), tanggal (sebagai
DateObject ),
array NumPy (sebagai
NumericArray ) dan
dataset panda (seperti
TimeSeries) ,
DataSet , dll.). (
ExternalEvaluate juga dapat mengembalikan
ExternalObject yang pada dasarnya adalah pegangan ke objek yang dapat Anda kirim kembali ke Python.)
Anda juga dapat langsung menggunakan fungsi eksternal (ord yang sedikit aneh pada dasarnya adalah analog Python dari
ToCharacterCode ):

Dan inilah fungsi murni Python, diwakili secara simbolis dalam Bahasa Wolfram:


Memanggil Bahasa Wolfram dari Python & Tempat Lainnya
Bagaimana seharusnya seseorang mengakses Bahasa Wolfram? Ada banyak cara. Seseorang dapat menggunakannya langsung di notebook. Orang dapat
memanggil API yang menjalankannya di cloud. Atau seseorang dapat menggunakan
WolframScript di
shell baris perintah . WolframScript dapat berjalan melawan
Mesin Wolfram lokal, atau melawan
Mesin Wolfram di cloud . Ini memungkinkan Anda langsung memberikan kode untuk dieksekusi:

Dan itu memungkinkan Anda melakukan hal-hal seperti mendefinisikan fungsi, misalnya dengan kode dalam file:


Bersamaan dengan rilis Versi 12.0, kami juga merilis
Perpustakaan Klien Bahasa Wolfram baru pertama kami - untuk Python. Ide dasar dari perpustakaan ini adalah untuk membuatnya mudah bagi program Python untuk memanggil Bahasa Wolfram. (Perlu menunjukkan bahwa kami telah secara efektif memiliki Perpustakaan Klien Bahasa C selama tidak kurang dari 30 tahun - melalui apa yang sekarang disebut
WSTP .)
Cara kerja Perpustakaan Klien Bahasa berbeda untuk berbagai bahasa. For Python—as an interpreted language (that was actually historically informed by early Wolfram Language)—it's particularly simple. After you
set up the library , and start a session (locally or in the cloud), you can then just evaluate Wolfram Language code and get the results back in Python:

You can also directly access Wolfram Language functions (as a kind of inverse of
ExternalFunction ):

And you can directly interact with things like pandas structures, NumPy arrays, etc. In fact, you can in effect just treat the whole of the Wolfram Language like a giant library that can be accessed from Python. Or, of course, you can just use the nice, integrated Wolfram Language directly, perhaps creating external APIs if you need them.
More for the Wolfram “Super Shell”
One feature of using the Wolfram Language is that it lets you get away from having to think about the details of your computer system, and about things like files and processes. But sometimes one wants to work at a systems level. And for fairly simple operations, one can just use an operating system GUI. But what about for more complicated things? In the past I usually found myself using the
Unix shell . But for a long time now, I've instead used Wolfram Language.
It's certainly very convenient to have everything in a notebook, and it's been great to be able to programmatically use functions like
FileNames (ls),
FindList (grep),
SystemProcessData (ps),
RemoteRunProcess (ssh) and
FileSystemScan . Tetapi dalam Versi 12.0 kami menambahkan banyak fungsi tambahan untuk mendukung menggunakan Bahasa Wolfram sebagai "super shell".Ada RemoteFile untuk secara simbolis mewakili file jarak jauh (dengan otentikasi jika diperlukan) - yang dapat segera Anda gunakan dalam fungsi seperti CopyFile . Ada FileConvert untuk secara langsung mengkonversi file antara format yang berbeda.Dan jika Anda benar-benar ingin menyelam lebih dalam, inilah cara Anda melacak semua paket di port 80 dan 443 yang digunakan dalam membaca dari wolfram.com :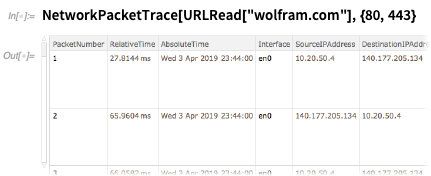
Membodohi peramban web
Di dalam Bahasa Wolfram, mudah untuk waktu yang lama berinteraksi dengan server web, menggunakan fungsi seperti
URLExecute dan
HTTPRequest , serta $
Cookies , dll. Tetapi dalam Versi 12.0 kami menambahkan sesuatu yang baru: kemampuan Bahasa Wolfram untuk
mengontrol browser web , dan secara terprogram membuatnya melakukan apa yang kita inginkan. Hal paling langsung yang dapat kita lakukan adalah hanya untuk mendapatkan gambaran seperti apa sebuah situs web dengan browser web:

Hasilnya adalah gambar yang dapat kita hitung:
Untuk melakukan sesuatu yang lebih rinci, kami harus memulai sesi browser (saat ini kami mendukung Firefox dan Chrome):

Segera jendela browser kosong muncul di layar kami. Sekarang kita bisa menggunakan WebExecute untuk membuka halaman web:

Sekarang kita telah membuka halaman, ada banyak perintah yang bisa kita jalankan. Ini mengklik hyperlink pertama yang berisi teks "Lab Pemrograman":
Ini mengembalikan judul halaman yang telah kami jangkau:
Anda dapat mengetik ke dalam bidang, menjalankan JavaScript, dan pada dasarnya melakukan apa pun yang dapat Anda lakukan secara program dengan browser web. Tidak perlu dikatakan, kami telah menggunakan versi teknologi ini selama bertahun-tahun di dalam perusahaan kami untuk menguji semua berbagai situs web dan layanan web kami. Tapi sekarang, di Versi 12.0, kami membuat versi efisien tersedia secara umum.
Untuk setiap komputer serba guna di dunia saat ini, mungkin ada 10 kali lebih banyak
mikrokontroler - menjalankan perhitungan spesifik tanpa sistem operasi umum. Sebuah mikrokontroler mungkin berharga beberapa sen hingga beberapa dolar, dan dalam sesuatu seperti mobil kelas menengah, mungkin ada 30 di antaranya.
Dalam Versi 12.0 kami memperkenalkan
Kit Mikrokontroler untuk Bahasa Wolfram, yang memungkinkan Anda memberikan spesifikasi simbolis dari mana ia secara otomatis menghasilkan dan menyebarkan kode untuk dijalankan secara mandiri dalam mikrokontroler. Dalam pengaturan tipikal, mikrokontroler terus melakukan perhitungan data yang masuk dari sensor, dan secara real time mengeluarkan sinyal ke aktuator. Jenis komputasi yang paling umum adalah yang efektif dalam teori kontrol dan pemrosesan sinyal.
Kami telah mendapat dukungan luas untuk melakukan
teori kontrol dan
pemrosesan sinyal secara langsung dalam Bahasa Wolfram untuk waktu yang lama. Tapi sekarang yang mungkin dilakukan dengan Microcontroller Kit adalah mengambil apa yang ditentukan dalam bahasa dan mengunduhnya sebagai kode tertanam dalam mikrokontroler mandiri yang dapat
digunakan di mana saja (di perangkat, IoT, peralatan, dll.).
Sebagai contoh, inilah cara seseorang dapat menghasilkan representasi simbolis dari filter pemrosesan sinyal analog:

Kita dapat menggunakan filter ini secara langsung dalam Bahasa Wolfram - katakanlah menggunakan
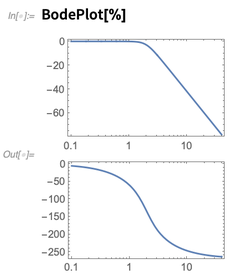
RecurrenceFilter untuk menerapkannya pada sinyal audio. Kami juga dapat melakukan hal-hal seperti merencanakan respons frekuensinya:
Untuk menggunakan filter dalam mikrokontroler, pertama-tama kita harus mengambil dari representasi waktu kontinu ini pendekatan waktu diskrit yang dapat dijalankan dalam loop ketat (di sini, setiap 0,1 detik) dalam mikrokontroler:
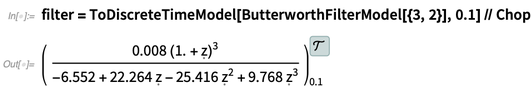
Sekarang kita siap menggunakan Mikrokontroler Kit untuk benar-benar menyebarkan ini ke mikrokontroler. Kit ini mendukung lebih dari seratus jenis mikrokontroler. Inilah cara kami dapat menyebarkan filter ke
Arduino Uno yang telah kami sambungkan ke port serial di komputer kami:

 Mikrokontroler EmbedCode
Mikrokontroler EmbedCode bekerja dengan menghasilkan kode sumber mirip-C yang sesuai, mengompilasinya untuk arsitektur mikrokontroler yang Anda inginkan, kemudian benar-benar menyebarkannya ke mikrokontroler melalui pemrogramnya. Berikut kode sumber aktual yang dihasilkan dalam kasus khusus ini:
Jadi sekarang kita memiliki hal seperti ini yang menjalankan
filter Butterworth kita, yang dapat kita gunakan di mana saja:
Jika kita ingin memeriksa apa yang dilakukannya, kita selalu dapat menghubungkannya kembali ke Bahasa Wolfram menggunakan
DeviceOpen untuk membuka
port serialnya , dan membaca dan menulis darinya.
Apa hubungan antara Bahasa Wolfram dan permainan video? Selama bertahun-tahun, Bahasa Wolfram telah digunakan di belakang layar dalam
banyak aspek pengembangan game (simulasi strategi, membuat geometri, menganalisis hasil, dll.). Tetapi untuk beberapa waktu sekarang kami telah mengerjakan tautan yang lebih dekat antara Wolfram Language dan
lingkungan game Unity , dan dalam Versi 12.0 kami merilis versi pertama dari tautan ini.
Skema dasarnya adalah membuat Unity berjalan di samping Bahasa Wolfram, kemudian mengatur komunikasi dua arah, memungkinkan kedua objek dan perintah untuk dipertukarkan. Pipa di bawah tenda cukup rumit, tetapi hasilnya adalah penggabungan yang bagus dari kekuatan Bahasa dan Persatuan Wolfram.
Ini mengatur tautan, lalu memulai proyek baru di Unity:

Sekarang buat beberapa bentuk kompleks:
Maka hanya perlu satu perintah untuk memasukkan ini ke dalam permainan Unity sebagai objek yang disebut "
thingoid ":

Di dalam Bahasa Wolfram ada representasi simbolik dari objek, dan UnityLink sekarang menyediakan ratusan fungsi untuk memanipulasi objek seperti itu, selalu mempertahankan versi baik dalam Unity maupun dalam Bahasa Wolfram.
Sangat kuat bahwa seseorang dapat mengambil sesuatu dari Bahasa Wolfram dan segera memasukkannya ke dalam Unity - apakah itu
geometri ,
gambar ,
audio ,
medan geografis ,
struktur molekul ,
anatomi 3D , atau apa pun. Ini juga sangat kuat bahwa hal-hal seperti itu kemudian dapat dimanipulasi dalam game Unity, baik melalui hal-hal seperti fisika game, atau dengan aksi pengguna. (Pada akhirnya, orang bisa berharap memiliki fungsi mirip-
Memanipulasi , di mana kontrol bukan hanya bilah geser dan benda-benda, tetapi juga gameplay yang kompleks.)
Kami telah melakukan percobaan dengan memasukkan konten yang dibuat Wolfram Language ke dalam realitas virtual sejak awal 1990-an. Tetapi di zaman modern, Unity telah menjadi semacam standar de facto untuk mengatur lingkungan VR / AR - dan dengan UnityLink sekarang dengan mudah untuk secara rutin memasukkan berbagai hal dari Bahasa Wolfram ke dalam lingkungan XR modern mana pun.
Seseorang dapat menggunakan Bahasa Wolfram untuk menyiapkan materi untuk game Unity, tetapi di dalam game Unity UnityLink pada dasarnya juga memungkinkan seseorang cukup memasukkan kode Bahasa Wolfram yang dapat dieksekusi selama pertandingan baik di mesin lokal atau melalui API di
Wolfram Cloud . Dan, di antara hal-hal lain, ini memudahkan untuk memasukkan kait ke dalam permainan sehingga permainan dapat mengirim "telemetri" (katakan kepada
Drop Data Wolfram ) untuk dianalisis dalam Bahasa Wolfram. (Dimungkinkan juga untuk menulis skrip permainan - yang, misalnya, sangat berguna untuk pengujian game.)
Menulis game adalah masalah yang kompleks. Tetapi UnityLink menyediakan pendekatan baru yang menarik yang seharusnya membuatnya lebih mudah untuk membuat prototipe semua jenis game, dan untuk mempelajari ide-ide pengembangan game. Salah satu alasannya adalah karena secara efektif memungkinkan satu skrip permainan pada tingkat yang lebih tinggi dengan menggunakan konstruksi simbolik dalam Bahasa Wolfram. Tetapi alasan lain adalah bahwa hal itu memungkinkan proses pengembangan dilakukan secara bertahap dalam buku catatan, dan menjelaskan dan mendokumentasikan setiap langkah. Misalnya, inilah yang menjadi
esai komputasi yang menggambarkan pengembangan "
permainan piano ":

UnityLink bukan hal yang sederhana: ia mengandung lebih dari 600 fungsi. Tetapi dengan fungsi-fungsi itu dimungkinkan untuk mengakses hampir semua kemampuan Unity, dan untuk mengatur hampir semua permainan yang bisa dibayangkan.
Untuk sesuatu seperti pembelajaran penguatan, sangat penting untuk memiliki lingkungan eksternal yang dapat dimanipulasi dalam loop ketika seseorang melakukan pembelajaran mesin. Nah,
ServiceExecute memungkinkan Anda menjalankan perangkat yang sebenarnya (putar robot ke kiri) dan mendapatkan data dari sensor (apakah robot terjatuh?) Dan
DeviceExecute memungkinkan Anda memanggil API yang sebenarnya (apa efek dari memposting tweet itu, atau membuat perdagangan itu?).
Tetapi untuk banyak tujuan yang diinginkan seseorang adalah memiliki lingkungan eksternal yang disimulasikan. Dan sedikit banyak, bahasa Wolfram murni sudah sampai batas tertentu melakukan itu, misalnya menyediakan akses ke "alam semesta komputasi" yang kaya penuh dengan program dan persamaan yang dapat dimodifikasi (
automata seluler ,
persamaan diferensial , ...). Dan, ya, hal-hal di jagat komputasi dapat diinformasikan oleh dunia nyata - katakan dengan sifat realistis dari
lautan , atau
bahan kimia atau
gunung .
Tapi bagaimana dengan lingkungan yang lebih seperti yang kita pelajari manusia modern - penuh dengan struktur teknik yang dibangun dan sebagainya? Cukup nyaman,
SystemModel memberikan akses ke banyak sistem rekayasa realistis. Dan melalui UnityLink kita dapat mengharapkan untuk memiliki akses ke simulasi dunia berbasis game yang kaya.
Tetapi sebagai langkah pertama, dalam Versi 12.0 kami membuat koneksi ke beberapa game sederhana - khususnya dari
"gym" OpenAI . Antarmuka sangat banyak untuk berinteraksi dengan dunia nyata, dengan game diakses seperti "perangkat" (setelah instalasi kadang-kadang "open-source-menyakitkan"):

Kita bisa membaca keadaan permainan:

Dan kita bisa menampilkannya sebagai gambar:
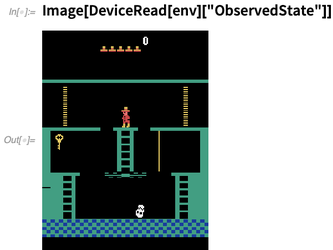
Dengan sedikit usaha, kita dapat mengambil 100 tindakan acak dalam game (selalu memeriksa bahwa kita tidak "mati"), kemudian menunjukkan plot fitur ruang dari keadaan yang diamati dari game:

Dalam Versi 11.3 kami memulai
koneksi pertama kami ke blockchain . Versi 12.0 menambahkan banyak fitur dan kemampuan baru, mungkin yang paling menonjol adalah kemampuan untuk menulis ke blockchain publik, serta membaca dari mereka. (Kami juga memiliki
Wolfram Blockchain kami sendiri untuk pengguna Wolfram Cloud.) Kami saat ini mendukung blockchain
Bitcoin ,
Ethereum dan
ARK , baik mainnets dan testnets mereka (dan, ya, kami memiliki node kami sendiri yang terhubung langsung ke blockchain ini).
Dalam Versi 11.3 kami mengizinkan
pembacaan mentah transaksi dari blockchains. Dalam Versi 12.0 kami telah menambahkan lapisan analisis, sehingga, misalnya, Anda dapat meminta ringkasan token "CK" (AKA
CryptoKitties ) pada blockchain
Ethereum :

Cepat untuk melihat semua transaksi token dalam riwayat, dan buat cloud kata seberapa aktif token yang berbeda:

Tetapi bagaimana dengan melakukan transaksi kita sendiri? Katakanlah kita ingin menggunakan
ATM Bitcoin (seperti yang, anehnya,
ada di toko bagel di dekat saya ) untuk mentransfer uang tunai ke alamat Bitcoin. Pertama, kita buat kunci kripto kita (dan kita perlu memastikan bahwa kita mengingat kunci pribadi kita!):

Selanjutnya, kita harus mengambil kunci publik dan menghasilkan alamat Bitcoin darinya:

Buat kode QR dari sana dan Anda siap pergi ke ATM:

Tetapi bagaimana jika kita ingin menulis sendiri ke blockchain? Di sini kita akan menggunakan testnet Bitcoin (jadi kita tidak menghabiskan uang nyata). Ini menunjukkan output dari transaksi yang kami lakukan sebelumnya - itu termasuk 0,0002 bitcoin (mis. 20,000 satoshi):
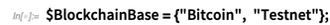

Sekarang kita dapat mengatur transaksi yang mengambil output ini, dan, misalnya, mengirimkan 8000 satoshi ke masing-masing dari dua alamat (yang kami definisikan seperti untuk transaksi ATM):
OK, jadi sekarang kita punya objek transaksi blockchain - yang akan menawarkan biaya (ditunjukkan dengan warna merah karena itu "uang aktual" yang akan Anda habiskan) dari semua cryptocurrency yang tersisa (di sini 4000 satoshi) untuk seorang penambang yang bersedia untuk menempatkan transaksi di blockchain. Tetapi sebelum kita dapat mengirimkan transaksi ini (dan "menghabiskan uang") kita harus menandatanganinya dengan kunci pribadi kita:
Akhirnya, kami hanya menerapkan
BlockchainTransactionSubmit dan kami telah mengirimkan transaksi kami untuk dimasukkan ke blockchain:

Inilah ID transaksinya:

Jika kami segera bertanya tentang transaksi ini, kami akan mendapatkan pesan yang mengatakan itu tidak ada di blockchain:

Tetapi setelah kita menunggu beberapa menit, itu dia - dan itu akan segera menyebar ke setiap salinan dari blockchain testnet Bitcoin:
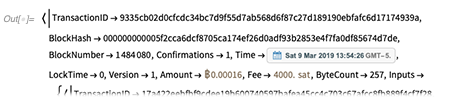
Jika Anda siap untuk menghabiskan uang nyata, Anda dapat menggunakan fungsi yang persis sama untuk melakukan transaksi di internet utama. Anda juga dapat melakukan hal-hal seperti membeli CryptoKitties. Fungsi seperti
BlockchainContractValue dapat digunakan untuk kontrak pintar apa pun (untuk saat ini, hanya Ethereum), dan diatur untuk segera memahami hal-hal seperti token
ERC-20 dan
ERC-721 .
Berurusan dengan blockchain melibatkan banyak kriptografi, beberapa di antaranya baru dalam Versi 12.0 (terutama, menangani kurva elips). Namun dalam Versi 12.0 kami juga memperluas fungsi kriptografis non-blockchain kami. Misalnya, kami sekarang memiliki fungsi untuk berurusan langsung dengan
tanda tangan digital . Ini menciptakan tanda tangan digital menggunakan kunci pribadi dari atas:


Sekarang siapa pun dapat memverifikasi pesan menggunakan kunci publik yang sesuai:

Dalam Versi 12.0, kami menambahkan beberapa jenis hash baru untuk fungsi
Hash , terutama untuk mendukung berbagai cryptocurrency. Kami juga menambahkan cara untuk membuat dan memverifikasi
kunci turunan . Mulai dari kata sandi apa pun, dan
GenerateDerivedKey akan "membusungkannya" menjadi sesuatu yang lebih lama (agar lebih aman Anda harus menambahkan "
garam "):

Berikut adalah versi kunci yang diturunkan, cocok untuk digunakan dalam berbagai skema otentikasi:

Menghubungkan ke Umpan Data Keuangan
Wolfram Knowledgebase berisi semua jenis
data keuangan . Biasanya ada
entitas finansial (seperti saham), lalu ada properti (seperti harga). Inilah sejarah harian lengkap dari harga saham Apple (sangat mengesankan bahwa itu terlihat terbaik pada skala log):
Tetapi sementara data keuangan dalam Wolfram Knowledgebase, dan tersedia secara standar dalam Bahasa Wolfram, terus diperbarui, itu bukan waktu nyata (kebanyakan 15 menit tertunda), dan tidak memiliki semua detail yang digunakan banyak pedagang keuangan. Namun, untuk penggunaan keuangan yang serius, kami telah mengembangkan
Platform Wolfram Finance . Dan sekarang, dalam Versi 12.0, ia memiliki akses langsung ke umpan data keuangan Bloomberg dan Reuters.
Cara kami merancang Bahasa Wolfram, kerangka kerja untuk koneksi ke Bloomberg dan Reuters selalu tersedia dalam bahasa - tetapi itu hanya diaktifkan jika Anda memiliki Platform Wolfram Finance, serta langganan Bloomberg atau Reuters yang sesuai. Tetapi dengan asumsi Anda memiliki ini, inilah yang tampaknya terhubung ke layanan
Terminal Bloomberg :

Semua instrumen keuangan yang ditangani oleh Terminal Bloomberg sekarang tersedia sebagai entitas dalam Bahasa Wolfram:

Sekarang kita dapat meminta properti entitas ini:

Secara keseluruhan, ada lebih dari 60.000 properti yang dapat diakses dari Terminal Bloomberg:

Berikut adalah 5 contoh acak (ya, mereka cukup rinci; itu adalah nama Bloomberg, bukan milik kami):

Kami mendukung layanan Terminal Bloomberg, layanan
Lisensi Data Bloomberg , dan layanan
Reuters Elektron . Satu hal canggih yang sekarang dapat dilakukan adalah mengatur tugas terus-menerus untuk menerima data secara tidak sinkron, dan memanggil "
fungsi penangan " setiap kali ada data baru yang masuk:
Rekayasa Perangkat Lunak & Pembaruan Platform
Saya sudah bicara tentang banyak fungsi baru dan fungsionalitas baru di Bahasa Wolfram. Tetapi bagaimana dengan infrastruktur yang mendasari Bahasa Wolfram? Yah, kami sudah bekerja keras untuk itu juga. Misalnya, antara Versi 11.3 dan Versi 12.0 kami telah berhasil memperbaiki hampir 8000 bug yang dilaporkan. Kami juga telah membuat banyak hal lebih cepat dan lebih kuat. Dan secara umum kami telah memperketat rekayasa perangkat lunak sistem, misalnya mengurangi ukuran unduhan awal hampir 10% (terlepas dari semua fungsi yang ditambahkan). (Kami juga telah melakukan hal-hal seperti meningkatkan
prefetch prediktif
elemen berbasis pengetahuan dari cloud - jadi ketika Anda membutuhkan data yang serupa, itu kemungkinan besar sudah di-cache di komputer Anda.)
Ini adalah fitur lama dari lanskap komputasi yang sistem operasinya terus diperbarui - dan untuk memanfaatkan fitur terbaru mereka, aplikasi juga harus diperbarui. Kami telah bekerja selama beberapa tahun pada pembaruan utama untuk antarmuka notebook Mac kami - yang akhirnya siap dalam Versi 12.0. Sebagai bagian dari pembaruan, kami telah menulis ulang dan merestrukturisasi sejumlah besar kode yang telah dikembangkan dan dipoles selama lebih dari 20 tahun, tetapi hasilnya adalah dalam Versi 12.0, segala sesuatu tentang sistem kami pada Mac sepenuhnya 64-bit, dan memanfaatkan
API Kakao terbaru. Ini berarti ujung depan notebook secara signifikan lebih cepat - dan juga dapat melampaui batas memori 2 GB sebelumnya.
Ada juga pembaruan platform di Linux, di mana sekarang antarmuka notebook sepenuhnya mendukung
Qt 5 , yang memungkinkan semua operasi rendering berlangsung "tanpa kepala", tanpa server X - sangat merampingkan penyebaran
Mesin Wolfram di awan. (Versi 12.0 belum memiliki dukungan dpi tinggi untuk Windows, tetapi akan segera hadir.)
Pengembangan
Cloud Wolfram dalam beberapa hal terpisah dari pengembangan Bahasa Wolfram, dan aplikasi
Wolfram Desktop (meskipun untuk kompatibilitas internal kami merilis Versi 12.0 pada saat yang sama di kedua lingkungan). Tetapi dalam setahun terakhir sejak Versi 11.3 dirilis, ada kemajuan dramatis di Wolfram Cloud.
Yang paling menonjol adalah kemajuan di notebook cloud - mendukung lebih banyak elemen antarmuka (termasuk beberapa, seperti situs web dan video tertanam, yang bahkan belum tersedia di notebook desktop), serta ketahanan dan kecepatan yang meningkat pesat. (Menjadikan seluruh antarmuka notebook kami berfungsi di peramban web bukan fitur kecil dalam rekayasa perangkat lunak, dan dalam Versi 12.0 ada beberapa strategi yang cukup canggih untuk hal-hal seperti mempertahankan cache yang cepat untuk dimuat secara konsisten, bersama dengan representasi DOM simbolis penuh.)
Di Versi 12.0 sekarang hanya ada item menu sederhana (File> Publish to Cloud ...) untuk menerbitkan notebook apa pun ke cloud. Dan begitu buku catatan diterbitkan, siapa pun di dunia dapat berinteraksi dengannya - serta membuat salinannya sendiri sehingga mereka dapat mengeditnya.
Sangat menarik untuk melihat
seberapa luas cloud telah memasuki apa yang dapat dilakukan dalam Bahasa Wolfram. Selain semua integrasi basis pengetahuan cloud yang mulus, dan kemampuan untuk menjangkau hal-hal seperti blockchain, ada juga kemudahan seperti
Kirim Ke ... mengirim buku catatan melalui email, menggunakan cloud jika tidak ada koneksi server email langsung yang tersedia.
Dan Banyak Lagi ...
Meskipun ini adalah bagian yang panjang, itu bahkan tidak dekat dengan menceritakan seluruh kisah tentang apa yang baru di Versi 12.0. Seiring dengan sisa tim kami, saya telah bekerja sangat keras pada Versi 12.0 untuk waktu yang lama sekarang - tetapi masih menarik untuk melihat seberapa banyak sebenarnya di dalamnya.
Tapi apa yang penting (dan banyak pekerjaan untuk dicapai!) Adalah bahwa semua yang kami tambahkan dirancang dengan hati-hati agar sesuai dengan apa yang sudah ada. Dari versi pertama lebih dari 30 tahun yang lalu dari apa yang sekarang Bahasa Wolfram, kami telah mengikuti prinsip-prinsip inti yang sama - dan ini adalah bagian dari apa yang memungkinkan kami untuk secara dramatis menumbuhkan sistem sambil mempertahankan kompatibilitas jangka panjang.
Selalu sulit untuk memutuskan dengan tepat apa yang harus diprioritaskan dikembangkan untuk setiap versi baru, tetapi saya sangat senang dengan pilihan yang kami buat untuk Versi 12.0. Saya telah memberikan banyak ceramah selama setahun terakhir, dan saya sangat terkejut dengan seberapa sering saya dapat mengatakan tentang hal-hal yang muncul: “Ya, kebetulan bahwa itu akan menjadi bagian dari Versi 12.0! ”
Saya secara pribadi telah menggunakan versi awal versi 12.0 selama hampir setahun, dan saya telah menerima begitu banyak kemampuan baru - dan untuk menggunakan dan menikmatinya banyak. Jadi, sangat menyenangkan bahwa hari ini kita memiliki Versi final 12.0 - dengan semua kemampuan baru ini secara resmi, siap digunakan oleh siapa saja dan semua orang ...