Kadang-kadang, ketika mengembangkan produk highload, situasi muncul ketika perlu untuk memproses tidak sebanyak permintaan sebanyak mungkin, tetapi lebih untuk membatasi jumlah permintaan per satuan waktu. Dalam kasus kami, ini adalah jumlah pemberitahuan push yang dikirim ke pengguna akhir. Baca lebih lanjut tentang algoritme pembatas laju, pro dan kontra - di bawah potongan.
Pertama, sedikit tentang kita. Pushwoosh adalah layanan b2b untuk komunikasi antara pelanggan kami dan penggunanya. Kami menyediakan solusi komprehensif bagi bisnis untuk berkomunikasi dengan pengguna melalui pemberitahuan push, email, dan saluran komunikasi lainnya. Selain benar-benar mengirim pesan, kami menawarkan alat untuk mensegmentasi audiens, mengumpulkan dan memproses statistik, dan banyak lagi. Untuk melakukan ini, dari awal kami menciptakan produk highload di persimpangan banyak teknologi, hanya sebagian kecil di antaranya adalah PHP, Golang, PostgreSQL, MongoDB, Apache Kafka. Banyak solusi kami yang unik, misalnya, pemberitahuan berkecepatan tinggi. Kami memproses lebih dari 2 miliar permintaan API per hari, kami memiliki lebih dari 3 miliar perangkat di basis data kami, dan sepanjang waktu kami mengirim lebih dari 500 miliar pemberitahuan ke perangkat ini.
Dan di sini kita sampai pada situasi di mana notifikasi perlu dikirimkan ke jutaan perangkat tidak secepat mungkin (seperti pada kecepatan tinggi yang telah disebutkan), tetapi secara artifisial membatasi kecepatan sehingga server klien kami yang akan dikunjungi pengguna ketika mereka membuka notifikasi tidak jatuh di bawah waktu yang sama memuat.
Di sini, berbagai algoritme pembatas laju datang untuk membantu kami, yang memungkinkan kami membatasi jumlah permintaan per satuan waktu. Sebagai aturan, ini digunakan, misalnya, ketika merancang API, karena dengan cara ini kita dapat melindungi sistem dari permintaan yang tidak disengaja atau berbahaya, sebagai akibatnya terjadi keterlambatan atau penolakan layanan kepada klien lain. Jika pembatasan tarif diterapkan, semua klien dibatasi untuk jumlah permintaan tetap per satuan waktu. Selain itu, pembatasan kecepatan dapat digunakan ketika mengakses bagian-bagian sistem yang terkait dengan data sensitif; Jadi, jika penyerang mendapatkan akses ke mereka, maka ia tidak akan dapat dengan cepat mengakses semua data.
Ada banyak cara untuk menerapkan pembatasan tarif. Pada artikel ini, kami akan mempertimbangkan pro dan kontra dari berbagai algoritma, serta masalah yang mungkin timbul saat meningkatkan solusi ini.
Permintaan Memproses Algoritma Batas Kecepatan
Leaky Bucket (Leaking Bucket)
Leaky Bucket adalah algoritma yang menyediakan pendekatan paling sederhana, paling intuitif untuk membatasi kecepatan pemrosesan menggunakan antrian, yang dapat direpresentasikan sebagai "ember" yang berisi permintaan. Ketika permintaan diterima, itu ditambahkan ke akhir antrian. Secara berkala, elemen pertama dalam antrian diproses. Ini juga dikenal sebagai antrian FIFO . Jika antrian penuh, maka permintaan tambahan dibuang (atau "bocor").

Keuntungan dari algoritma ini adalah bahwa hal itu menghaluskan ledakan dan memproses permintaan pada kecepatan yang kira-kira sama, mudah diimplementasikan pada server tunggal atau load balancer, efisien dalam penggunaan memori, karena ukuran antrian untuk setiap pengguna terbatas.
Namun, dengan peningkatan lalu lintas yang tajam, antrian dapat diisi dengan permintaan lama dan menghilangkan kemampuan sistem untuk memproses permintaan yang lebih baru. Dia juga tidak menjamin bahwa permintaan akan diproses dalam waktu yang tetap. Selain itu, jika Anda memuat penyeimbang untuk memberikan toleransi kesalahan atau meningkatkan throughput, maka Anda harus menerapkan kebijakan koordinasi dan memastikan batasan global di antara mereka.
Ada variasi dari algoritma ini - Token Bucket ("ember dengan token" atau "algoritma keranjang penanda").
Dalam implementasi seperti itu, token ditambahkan ke "bucket" dengan kecepatan konstan, dan saat memproses permintaan, token dari "bucket" dihapus; jika tidak ada token yang cukup, permintaan dibuang. Anda cukup menggunakan cap waktu sebagai token.
Ada variasi menggunakan beberapa "ember", sedangkan ukuran dan tingkat penerimaan token di dalamnya dapat berbeda untuk masing-masing "ember". Jika tidak ada cukup token dalam "ember" pertama untuk memproses permintaan, maka kehadiran mereka di kotak kedua, dll., Diperiksa, tetapi prioritas pemrosesan permintaan dikurangi (sebagai aturan, ini digunakan dalam desain antarmuka jaringan ketika, misalnya, Anda dapat mengubah nilai bidang Paket yang diproses DSCP ).
Perbedaan utama dari penerapan Leaky Bucket adalah bahwa token dapat terakumulasi ketika sistem idle dan semburan dapat terjadi kemudian, sementara permintaan akan diproses (karena ada cukup token), sementara Leaky Bucket dijamin untuk memperlancar beban bahkan dalam kasus downtime.
Memperbaiki Jendela
Algoritma ini menggunakan jendela n detik untuk melacak permintaan. Biasanya, nilai-nilai seperti 60 detik (menit) atau 3600 detik (jam) digunakan. Setiap permintaan masuk meningkatkan penghitung untuk jendela ini. Jika penghitung melebihi nilai ambang tertentu, permintaan tersebut dibuang. Biasanya, jendela ditentukan oleh batas bawah dari interval waktu saat ini, yaitu, ketika jendela 60 detik lebar, permintaan yang tiba di 12:00:03 akan pergi ke jendela 12:00:00.
Keuntungan dari algoritma ini adalah bahwa ia menyediakan pemrosesan permintaan yang lebih baru, tanpa tergantung pada pemrosesan yang lama. Namun, satu ledakan lalu lintas di dekat batas jendela dapat menggandakan jumlah permintaan yang diproses, karena memungkinkan permintaan untuk jendela saat ini dan berikutnya untuk jangka waktu singkat. Selain itu, jika banyak pengguna menunggu penghitung jendela untuk mengatur ulang, misalnya, pada akhir jam, mereka dapat memprovokasi peningkatan beban pada saat ini karena fakta bahwa mereka akan mengakses API pada saat yang sama.
Sliding Log
Algoritma ini melibatkan pelacakan cap waktu dari setiap permintaan pengguna. Catatan-catatan ini disimpan, misalnya, dalam set atau tabel hash dan diurutkan berdasarkan waktu; catatan di luar interval yang dipantau dibuang. Ketika permintaan baru tiba, kami menghitung jumlah catatan untuk menentukan frekuensi permintaan. Jika permintaan di luar jumlah yang diijinkan, maka itu dibuang.
Keuntungan dari algoritma ini adalah bahwa ia tidak mengalami masalah yang muncul di perbatasan Fixed Window , yaitu batas kecepatan akan diamati dengan ketat. Selain itu, karena setiap permintaan klien dimonitor secara terpisah, tidak ada pertumbuhan beban puncak pada titik-titik tertentu, yang merupakan masalah lain dari algoritma sebelumnya.
Namun, menyimpan informasi tentang setiap permintaan bisa mahal, di samping itu, setiap permintaan memerlukan penghitungan jumlah permintaan sebelumnya, yang berpotensi pada seluruh kluster, sebagai akibatnya pendekatan ini tidak skala dengan baik untuk menangani ledakan lalu lintas besar dan penolakan serangan layanan.
Jendela Geser
Ini adalah pendekatan hybrid yang menggabungkan biaya rendah pemrosesan Window Tetap dan penanganan canggih situasi batas Sliding Log . Seperti pada Jendela Tetap yang sederhana, kami melacak penghitung untuk setiap jendela, dan kemudian memperhitungkan nilai bobot frekuensi permintaan jendela sebelumnya berdasarkan cap waktu saat ini untuk memuluskan ledakan lalu lintas. Misalnya, jika 25% dari waktu jendela saat ini berlalu, maka kami memperhitungkan 75% dari permintaan sebelumnya. Jumlah data yang relatif kecil yang diperlukan untuk melacak setiap kunci memungkinkan kami untuk mengukur dan bekerja dalam kelompok besar.
Algoritma ini memungkinkan Anda untuk mengukur pembatasan tingkat, sambil mempertahankan kinerja yang baik. Selain itu, ini adalah cara yang dapat dimengerti untuk menyampaikan informasi kepada pelanggan tentang pembatasan jumlah permintaan, dan juga menghindari masalah yang muncul saat menerapkan algoritma pembatasan tarif lainnya.
Pembatasan Nilai dalam Sistem Terdistribusi
Kebijakan Sinkronisasi
Jika Anda ingin menetapkan batasan laju global saat mengakses kluster yang terdiri dari beberapa node, maka Anda perlu menerapkan kebijakan pembatasan. Jika setiap node hanya melacak batasannya sendiri, maka pengguna dapat mem-bypassnya dengan hanya mengirimkan permintaan ke node yang berbeda. Bahkan, semakin besar jumlah node, semakin besar kemungkinan pengguna akan dapat melampaui batas global.
Cara termudah untuk menetapkan batas adalah dengan mengkonfigurasi "sesi lengket" pada penyeimbang sehingga pengguna diarahkan ke simpul yang sama. Kerugian dari metode ini adalah kurangnya toleransi kesalahan dan masalah penskalaan ketika node cluster kelebihan beban.
Solusi terbaik, yang memungkinkan aturan yang lebih fleksibel untuk load balancing, adalah dengan menggunakan gudang data terpusat (pilihan Anda). Ini dapat menyimpan penghitung jumlah permintaan untuk setiap jendela dan pengguna. Masalah utama dari pendekatan ini adalah peningkatan waktu respons karena permintaan penyimpanan dan kondisi ras.
Kondisi balapan
Salah satu masalah terbesar dengan data warehouse terpusat adalah kemungkinan kondisi balapan saat bersaing. Ini terjadi ketika Anda menggunakan pendekatan get-then-set alami, di mana Anda mengekstrak penghitung saat ini, menambahkannya, dan kemudian mengirim nilai yang dihasilkan kembali ke toko. Masalah dengan model ini adalah bahwa selama waktu yang diperlukan untuk menyelesaikan siklus penuh dari operasi ini (yaitu, membaca, menambah dan menulis), permintaan lain dapat masuk, di mana masing-masing penghitung akan disimpan dengan nilai yang tidak valid (lebih rendah). Ini memungkinkan pengguna untuk mengirim lebih banyak permintaan daripada yang disediakan oleh algoritma pembatasan kecepatan.
Salah satu cara untuk menghindari masalah ini adalah dengan mengatur kunci di sekitar kunci yang dimaksud, mencegah akses untuk membaca atau menulis proses lain ke penghitung. Namun, ini dapat dengan cepat menjadi hambatan kinerja dan tidak skala dengan baik, terutama ketika menggunakan server jauh, seperti Redis, sebagai penyimpan data tambahan.
Pendekatan yang jauh lebih baik adalah "set - kemudian - get", berdasarkan pada operator atom, yang memungkinkan Anda untuk dengan cepat meningkatkan dan memeriksa nilai penghitung tanpa mengganggu operasi atom.
Optimalisasi kinerja
Kerugian lain dari menggunakan gudang data terpusat adalah peningkatan waktu respons karena keterlambatan dalam memeriksa penghitung yang digunakan untuk menerapkan pembatasan tarif (waktu pulang-pergi , atau “penundaan pulang-pergi ”). Sayangnya, bahkan memeriksa penyimpanan cepat seperti Redis akan menghasilkan penundaan tambahan beberapa milidetik per permintaan.
Untuk membuat definisi kendala dengan penundaan minimum, perlu dilakukan pemeriksaan di memori lokal. Ini dapat dilakukan dengan mengendurkan kondisi untuk memeriksa kecepatan dan akhirnya menggunakan model yang konsisten.
Misalnya, setiap node dapat membuat siklus sinkronisasi data yang akan disinkronkan dengan repositori. Setiap node secara berkala mentransmisikan nilai penghitung untuk setiap pengguna dan jendela yang terpengaruh, ke toko, yang akan memperbarui nilai-nilai secara atom. Kemudian node dapat menerima nilai baru dan memperbarui data dalam memori lokal. Siklus ini pada akhirnya akan memungkinkan semua node dalam klaster menjadi terbaru.
Periode di mana node disinkronkan harus disesuaikan. Interval sinkronisasi yang lebih pendek akan menyebabkan perbedaan data yang lebih sedikit ketika beban didistribusikan secara merata di beberapa node cluster (misalnya, dalam kasus ketika balancer menentukan node sesuai dengan prinsip "round-robin"), sementara interval yang lebih lama membuat lebih sedikit beban baca / tulis untuk penyimpanan. dan mengurangi biaya di setiap node untuk menerima data yang disinkronkan.
Perbandingan Algoritma Pembatas Rate
Khususnya, dalam kasus kami, kami tidak boleh menolak permintaan klien untuk API, tetapi atas dasar data, sebaliknya, jangan membuatnya; namun, kami tidak berhak untuk “kehilangan” permintaan. Untuk melakukan ini, saat mengirim pemberitahuan, kami menggunakan parameter send_rate, yang menunjukkan jumlah maksimum pemberitahuan yang akan kami kirim per detik saat mengirim.
Jadi, kami memiliki Pekerja tertentu yang melakukan pekerjaan dalam waktu yang ditentukan (dalam contoh saya, membaca dari file), yang menerima antarmuka RateLimitingInterface sebagai input, memberi tahu apakah mungkin untuk mengeksekusi permintaan pada waktu tertentu dan berapa lama akan berjalan.
interface RateLimitingInterface { public function __construct(int $rate); public function canDoWork(float $currentTime): bool; }
Semua contoh kode dapat ditemukan di GitHub di sini .
Saya akan segera menjelaskan mengapa Anda perlu mentransfer waktu ke Worker. Faktanya adalah bahwa terlalu mahal untuk menjalankan daemon terpisah untuk memproses pengiriman satu pesan dengan batas kecepatan, jadi send_rate sebenarnya digunakan sebagai parameter “jumlah pemberitahuan per unit waktu”, yaitu 0,01 - 1 detik tergantung pada beban.
Bahkan, kami memproses hingga 100 permintaan berbeda dengan send_rate per detik, mengalokasikan 1 / N detik untuk setiap kuantum waktu, di mana N adalah jumlah dorongan yang diproses oleh daemon ini. Parameter yang paling kami minati selama pemrosesan adalah apakah send_rate akan dihormati (kesalahan kecil diizinkan dalam satu arah atau yang lain) dan beban pada perangkat keras kami (jumlah minimum akses ke penyimpanan, CPU dan konsumsi memori).
Untuk memulai, mari kita cari tahu pada titik mana waktu pekerja benar-benar bekerja. Untuk mempermudah, contoh ini memproses file 10.000-baris dengan send_rate = 1000 (artinya, kita membaca 1000 baris per detik dari file).
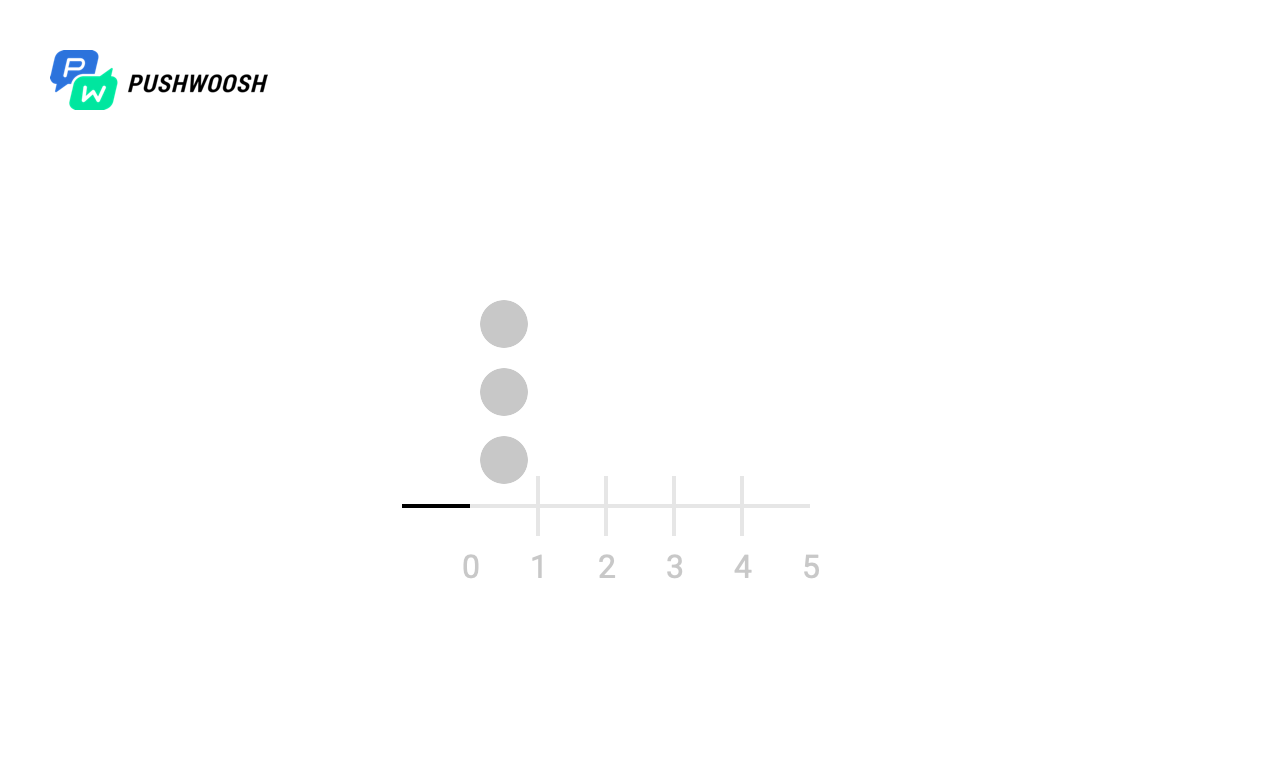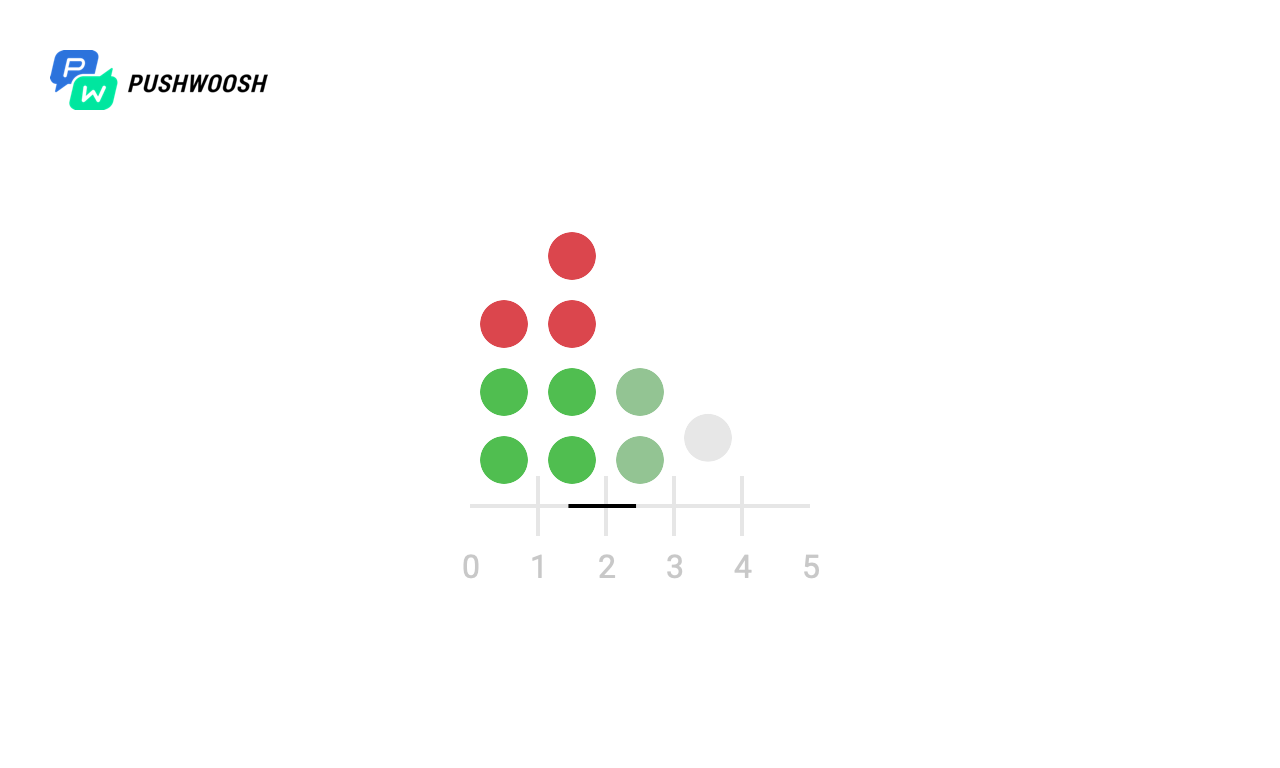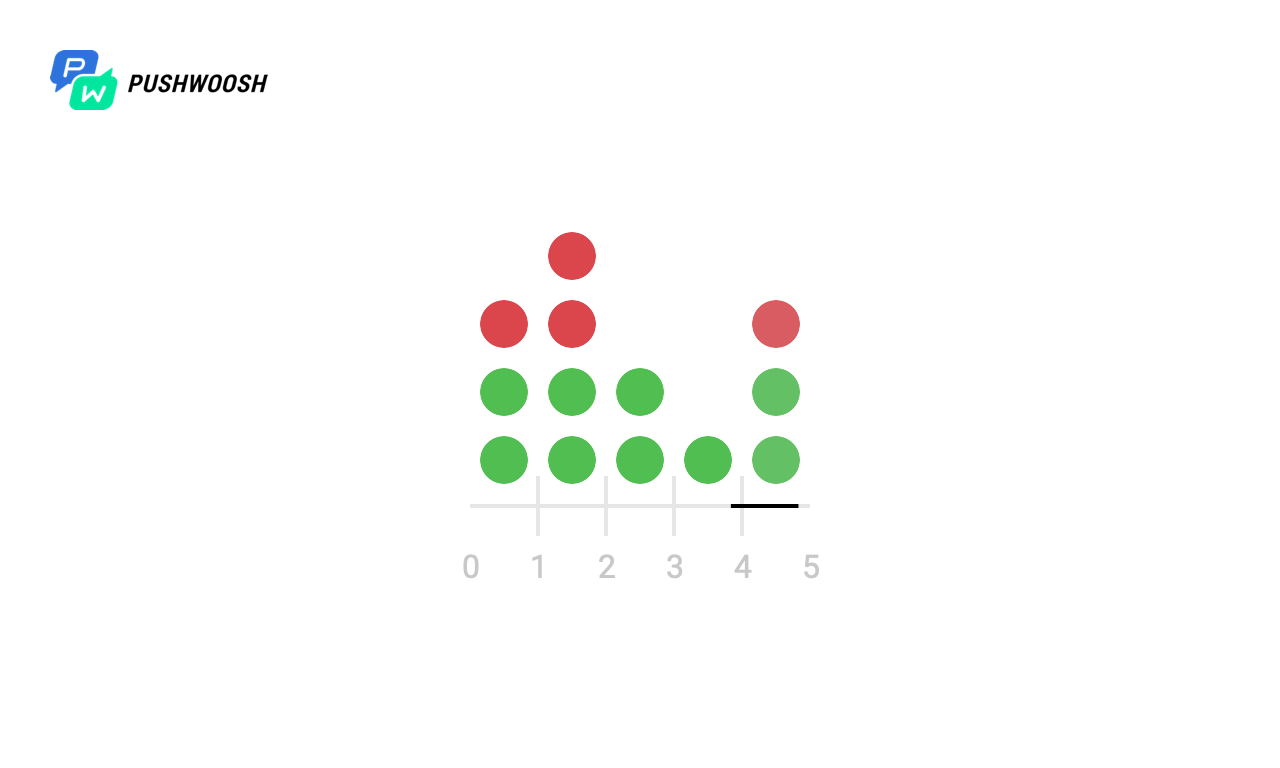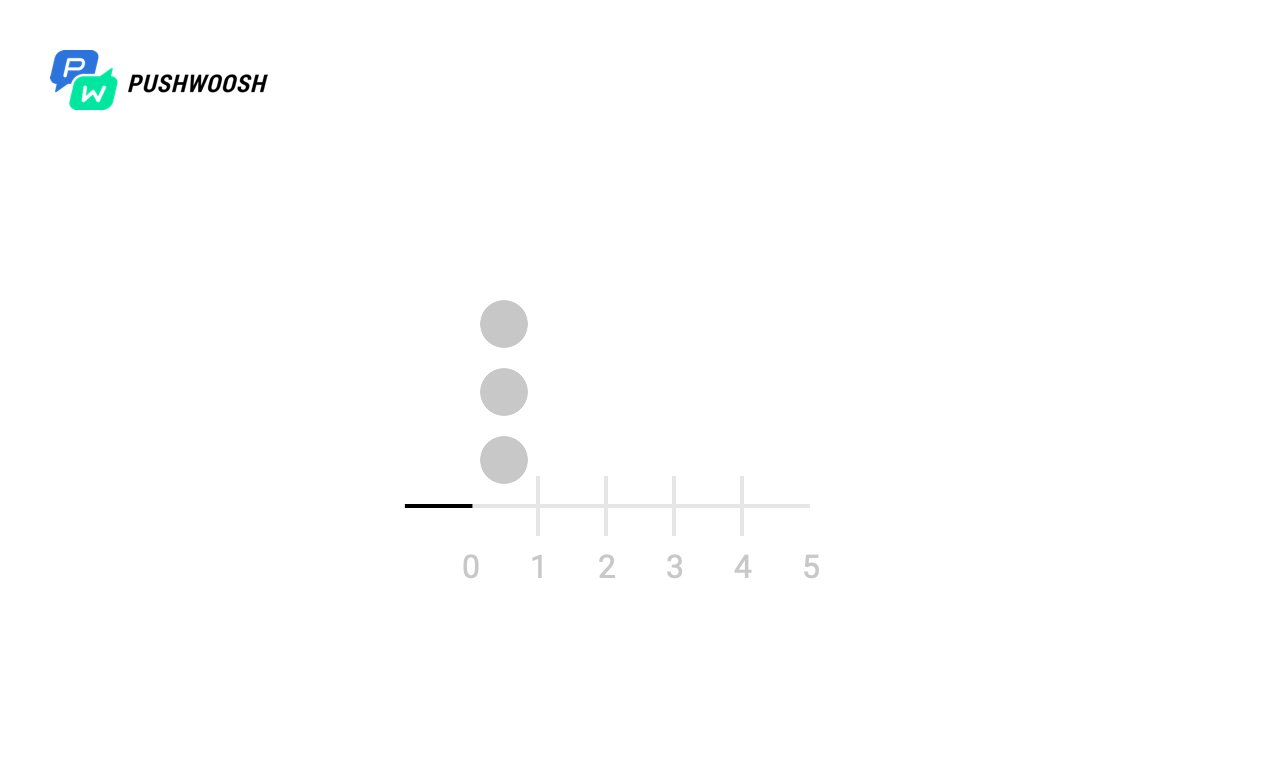
Dalam tangkapan layar, spidol menandai momen dan jumlah panggilan gadget untuk semua algoritma. Pada kenyataannya, ini bisa menjadi banding ke database, sumber daya pihak ketiga, atau pertanyaan lain, jumlah yang ingin kita batasi per unit waktu.
Pada skala X - waktu dari awal pemrosesan, dari 0 hingga 10 detik, setiap detik dibagi menjadi sepersepuluh, jadi jadwalnya adalah 0 hingga 100).
Kita melihat bahwa terlepas dari kenyataan bahwa semua algoritma mengatasi send_rate (untuk ini mereka dirancang), Fixed Window dan Sliding Log “memberikan” seluruh beban hampir secara bersamaan, yang tidak cocok dengan kita, sementara Token Bucket dan Sliding Windows mendistribusikannya secara merata per unit waktu (dengan pengecualian beban puncak pada saat mulai, karena kurangnya data tentang beban pada waktu sebelumnya).
Karena kenyataan bahwa kode biasanya tidak bekerja dengan sistem file lokal, tetapi dengan penyimpanan pihak ketiga, jawabannya mungkin tertunda, mungkin ada masalah jaringan dan banyak masalah lainnya, kami akan mencoba memeriksa bagaimana ini atau itu akan berperilaku ketika permintaan membutuhkan waktu. tidak. Misalnya, setelah 4 dan 6 detik.
Di sini, sepertinya Window Tetap tidak bekerja dengan benar dan diproses 2 kali lebih banyak dari permintaan yang diharapkan pada pertama dan dari 7 hingga 8 detik, tetapi kenyataannya tidak demikian, karena waktu dihitung dari saat peluncuran pada grafik, dan algoritma menggunakan cap waktu unix saat ini .
Secara umum, tidak ada yang berubah secara mendasar, tetapi kami melihat bahwa Token Bucket menghaluskan beban lebih lancar dan tidak pernah melebihi batas tarif yang ditentukan, tetapi Sliding Log jika terjadi downtime dapat melebihi nilai yang diizinkan.
Kesimpulan
Kami memeriksa semua algoritma dasar untuk menerapkan pembatasan tingkat, yang masing-masing memiliki pro dan kontra dan cocok untuk berbagai tugas. Kami berharap setelah membaca artikel ini, Anda akan memilih algoritma yang paling cocok untuk menyelesaikan masalah Anda.