
Sejak 2008, perusahaan kami terutama bergerak dalam manajemen infrastruktur dan dukungan teknis 24 jam untuk proyek web: kami memiliki lebih dari 400 klien, yang merupakan sekitar 15% dari e-commerce di Rusia. Dengan demikian, arsitektur yang sangat beragam didukung. Jika sesuatu jatuh, kita harus memperbaikinya dalam 15 menit. Tetapi untuk memahami bahwa suatu kecelakaan telah terjadi, Anda perlu memonitor proyek dan menanggapi insiden. Bagaimana cara melakukannya?
Saya percaya bahwa organisasi sistem pemantauan yang tepat dalam kesulitan. Jika tidak ada masalah, maka pidato saya terdiri dari satu tesis: "Silakan instal Prometheus + Grafana dan plugin 1, 2, 3." Sayangnya, ini tidak berfungsi sekarang. Dan masalah utama adalah bahwa setiap orang terus percaya pada sesuatu yang ada pada 2008, dalam hal komponen perangkat lunak.
Mengenai organisasi sistem pemantauan, saya berisiko mengatakan bahwa ... proyek dengan pemantauan kompeten tidak ada. Dan situasinya sangat buruk jika sesuatu jatuh, ada risiko bahwa itu akan luput dari perhatian - semua orang yakin bahwa "semuanya sedang dipantau".
Mungkin semuanya sedang dipantau. Tapi bagaimana caranya?
Kita semua menemukan cerita yang mirip dengan yang berikut: devoop tertentu, admin tertentu sedang bekerja, tim pengembang mendatangi mereka dan berkata, "Kami sudah mendapatkannya, sekarang sudah dipantau." Monitor apa? Bagaimana cara kerjanya?
Ok Kami memantau cara lama. Tapi itu sudah berubah, dan ternyata Anda memonitor layanan A, yang menjadi layanan B, yang berinteraksi dengan layanan C. Tetapi tim pengembangan mengatakan kepada Anda: "Instal perangkat lunak, ia harus memantau semuanya!"
Jadi apa yang telah berubah? - Semuanya telah berubah!
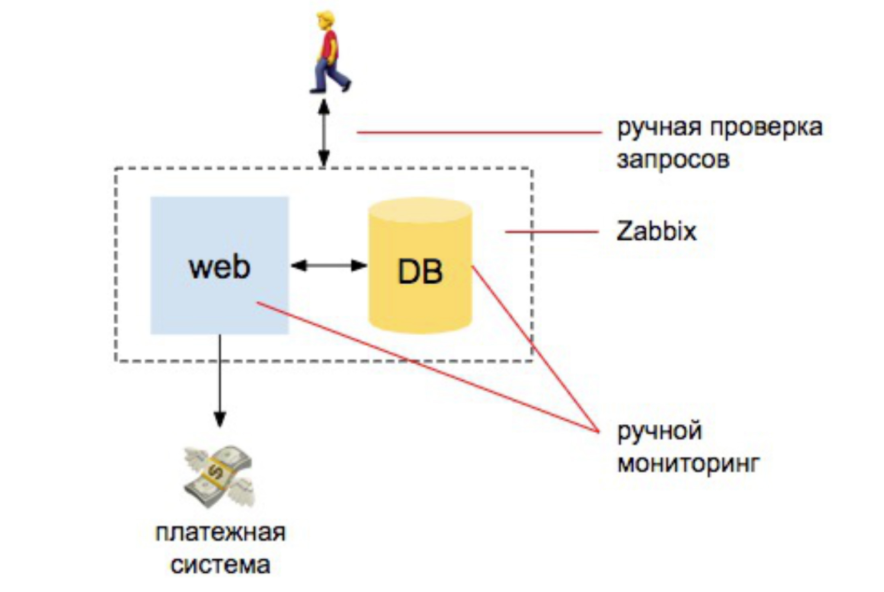
Tahun 2008 Semuanya baik-baik saja
Ada beberapa pengembang, satu server, satu server database. Dari sini semuanya berjalan. Kami memiliki beberapa INFA, kami menaruh zabbix, Nagios, cacti. Dan kemudian kita mengatur peringatan yang jelas pada CPU, pada pengoperasian disk, pada tempat di disk. Kami juga melakukan beberapa pemeriksaan manual bahwa situs menjawab bahwa pesanan datang ke database. Dan hanya itu - kita kurang lebih terlindungi.
Jika kami membandingkan jumlah pekerjaan yang admin lakukan untuk memastikan pemantauan, maka 98% otomatis: orang yang memantau harus memahami cara memasang Zabbix, cara mengonfigurasinya, dan mengonfigurasi peringatan. Dan 2% - untuk pemeriksaan eksternal: bahwa situs merespons dan membuat permintaan ke database bahwa pesanan baru telah tiba.
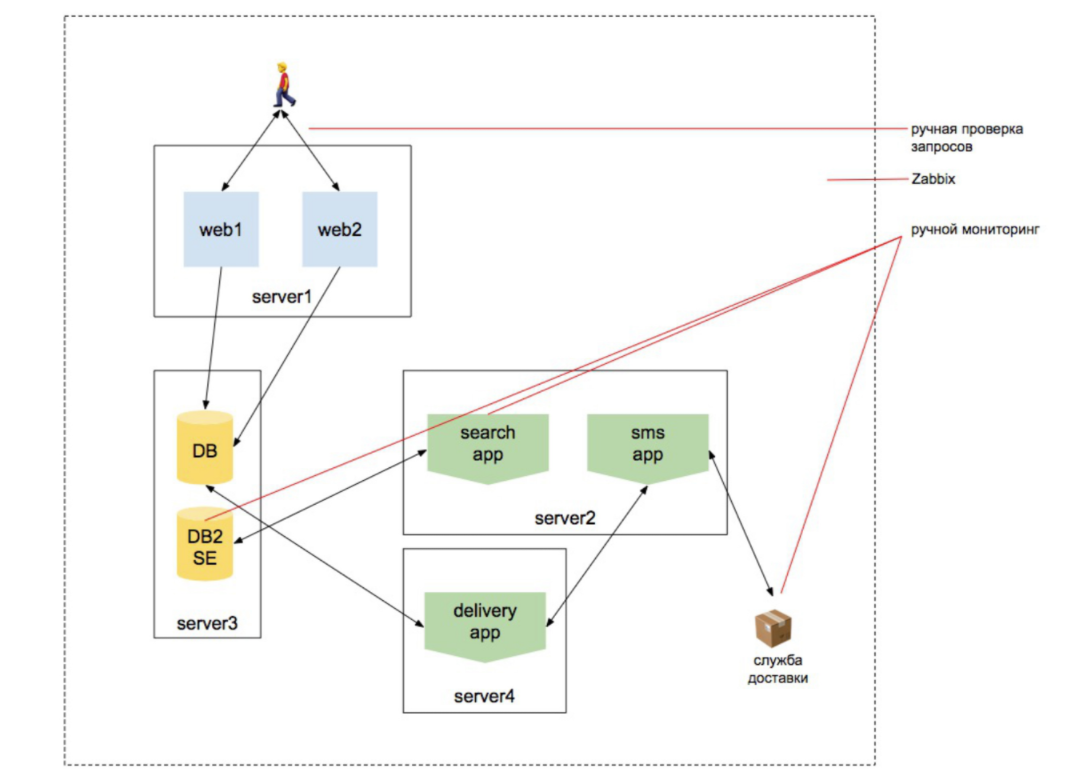
Tahun 2010 Beban bertambah
Kami mulai skala web, tambahkan mesin pencari. Kami ingin memastikan bahwa katalog produk berisi semua produk. Dan pencarian produk itu berfungsi. Basis data berfungsi, pesanan sedang dibuat, bahwa situs merespons secara eksternal dan merespons dari dua server, dan pengguna tidak diusir keluar dari situs saat ia menyeimbangkan kembali ke server lain, dll. Ada lebih banyak entitas.
Selain itu, entitas yang terkait dengan infrastruktur tetap yang terbesar di kepala manajer. Masih ada ide di kepala saya bahwa orang yang memantau adalah orang yang akan menginstal zabbix dan dapat mengonfigurasinya.
Tetapi pada saat yang sama, ada pekerjaan untuk melakukan pemeriksaan eksternal, membuat sekumpulan skrip untuk mencari pengindeks pencarian, sekumpulan skrip untuk memverifikasi bahwa pencarian berubah selama proses pengindeksan, sekumpulan skrip yang memverifikasi bahwa barang-barang ditransfer ke layanan pengiriman, dll. dll.

Catatan: Saya menulis "kumpulan naskah" 3 kali. Artinya, orang yang bertanggung jawab untuk memantau bukan lagi orang yang baru saja menginstal zabbix. Ini adalah orang yang mulai kode. Tetapi belum ada yang berubah dalam pikiran tim.
Tetapi dunia berubah, menjadi semakin rumit. Lapisan virtualisasi, beberapa sistem baru ditambahkan. Mereka mulai berinteraksi satu sama lain. Siapa bilang "pukulan microservices?" Tetapi setiap layanan masih secara individual terlihat seperti sebuah situs. Kita dapat menoleh kepadanya dan memahami bahwa dia memberikan informasi yang diperlukan dan bekerja dengan sendirinya. Dan jika Anda adalah admin yang terus-menerus terlibat dalam proyek yang telah berkembang selama 5-7-10 tahun, Anda memiliki akumulasi pengetahuan ini: tingkat baru muncul - Anda menyadarinya, tingkat lain muncul - Anda menyadarinya ...
Tapi jarang ada yang menemani proyek selama 10 tahun.
Ringkasan Pemantauan Pria
Misalkan Anda datang ke startup baru yang langsung mencetak 20 pengembang, menulis 15 layanan microser, dan Anda adalah admin yang diberi tahu: “Bangun CI / CD. Tolong. " Anda membuat CI / CD dan tiba-tiba Anda mendengar: "Sulit bagi kami untuk bekerja dengan produksi di" kubus "tanpa memahami bagaimana aplikasi akan bekerja di dalamnya. Jadikan kami kotak pasir di "kubus" yang sama.
Anda membuat kotak pasir di kubus ini. Mereka segera memberi tahu Anda: "Kami ingin database tahap, yang diperbarui setiap hari dari produksi, untuk memahami bahwa itu bekerja pada database, tetapi tidak merusak database produksi."
Anda hidup dalam semua itu. Ada 2 minggu tersisa sampai rilis, mereka berkata kepada Anda: "Sekarang semuanya akan dipantau ..." Ya memantau infrastruktur cluster, memantau arsitektur layanan mikro, memantau pekerjaan dengan layanan eksternal ...
Dan kolega mengambil skema yang begitu akrab dari kepala mereka dan berkata: “Jadi di sini semuanya jelas! Instal program yang memonitor semuanya. " Ya: Prometheus + Grafana + plugins.
Dan mereka menambahkan pada saat yang sama: "Anda memiliki dua minggu, pastikan semuanya dapat diandalkan."
Di tumpukan proyek yang kita lihat, satu orang dialokasikan untuk pemantauan. Bayangkan kita ingin merekrut seseorang selama 2 minggu untuk memantau, dan kita akan menulis resume kepadanya. Keterampilan apa yang harus dimiliki orang ini - mengingat semua yang telah kita katakan sebelumnya?
- Dia harus memahami pengawasan dan kekhasan pekerjaan infrastruktur besi.
- Dia harus memahami spesifikasi pemantauan Kubernetes (dan semua orang menginginkan "kubus", karena Anda dapat mengabaikan segalanya, bersembunyi, karena admin akan mengetahuinya) - dengan sendirinya, infrastrukturnya, dan memahami cara memantau aplikasi di dalamnya.
- Dia harus memahami bahwa layanan berkomunikasi satu sama lain dengan cara khusus, dan mengetahui secara spesifik interaksi layanan di antara mereka sendiri. Cukup realistis untuk melihat proyek tempat beberapa layanan berkomunikasi secara serempak, karena tidak ada cara lain. Misalnya, backend berjalan pada REST, pada gRPC ke layanan katalog, menerima daftar barang dan kembali. Anda tidak bisa menunggu di sini. Dan dengan layanan lain, ia bekerja secara tidak sinkron. Transfer pesanan ke layanan pengiriman, kirim surat, dll.
Anda mungkin sudah berlayar dari semua ini? Dan admin, yang perlu memonitor ini, berenang lebih banyak lagi. - Dia harus dapat merencanakan dan merencanakan dengan benar - ketika pekerjaan menjadi semakin dan semakin banyak.
- Karena itu, ia harus membuat strategi dari layanan yang dibuat untuk memahami cara memantaunya secara spesifik. Dia membutuhkan pemahaman tentang arsitektur proyek dan pengembangan + pemahaman tentang teknologi yang digunakan dalam pengembangan.
Mari kita ingat kasus yang benar-benar normal: bagian dari layanan di php, bagian dari layanan di Go, bagian dari layanan di JS. Mereka entah bagaimana bekerja di antara mereka sendiri. Di sinilah istilah "layanan mikro" berasal: ada begitu banyak sistem terpisah yang pengembang tidak dapat memahami proyek secara keseluruhan. Salah satu bagian dari tim menulis layanan di JS yang bekerja sendiri dan tidak tahu cara kerja sistem lainnya. Bagian lain menulis layanan dengan Python dan tidak masuk ke cara layanan lain bekerja, mereka terisolasi di bidangnya. Ketiga - menulis layanan di php atau yang lainnya.
Semua 20 orang ini dibagi menjadi 15 layanan, dan hanya ada satu admin yang harus memahami semua ini. Hentikan itu! kami hanya membagi sistem menjadi 15 layanan mikro, karena 20 orang tidak dapat memahami keseluruhan sistem.
Tetapi perlu dipantau entah bagaimana ...
Apa hasilnya? Akibatnya, ada satu orang yang memikirkan segala sesuatu yang tidak dapat dipahami oleh seluruh tim pengembang, namun ia juga harus tahu dan mampu melakukan apa yang telah kami sebutkan di atas - infrastruktur besi, infrastruktur Kubernet, dll.
Apa yang bisa saya katakan ... Houston, kita punya masalah.
Pemantauan proyek perangkat lunak modern adalah proyek perangkat lunak itu sendiri
Dari keyakinan keliru bahwa pemantauan adalah perangkat lunak, kami memiliki keyakinan pada keajaiban. Tetapi keajaiban, sayangnya, tidak terjadi. Anda tidak dapat menginstal zabbix dan menunggu semuanya berfungsi. Tidak masuk akal untuk menempatkan Grafana dan berharap semuanya akan beres. Sebagian besar waktu akan dihabiskan untuk mengatur pemeriksaan pada operasi layanan dan interaksinya satu sama lain, memeriksa bagaimana sistem eksternal bekerja. Bahkan, 90% dari waktu akan dihabiskan bukan untuk menulis skrip, tetapi untuk pengembangan perangkat lunak. Dan itu harus tim yang memahami pekerjaan proyek.
Jika dalam situasi ini satu orang dilemparkan untuk pemantauan, maka masalah akan terjadi. Yang terjadi di mana-mana.
Misalnya, ada beberapa layanan yang berkomunikasi satu sama lain melalui Kafka. Pesanan datang, kami mengirim pesan tentang pesanan ke Kafka. Ada layanan yang mendengarkan informasi tentang pesanan dan melakukan pengiriman barang. Ada layanan yang mendengarkan informasi tentang pesanan dan mengirim surat kepada pengguna. Dan kemudian masih ada banyak layanan, dan kami mulai bingung.
Dan jika Anda masih memberikannya kepada administrator dan pengembang pada tahap ketika ada waktu singkat sebelum rilis, seseorang harus memahami seluruh protokol ini. Yaitu proyek skala ini membutuhkan waktu yang lama, dan ini harus dimasukkan ke dalam pengembangan sistem.
Tetapi sangat sering, terutama dalam pembakaran, di startup, kita melihat bagaimana pemantauan ditunda sampai nanti. “Sekarang kita akan membuat Bukti Konsep, kita akan mulai dengan itu, biarkan jatuh - kita siap berkorban. Dan kemudian kita akan memonitor semuanya. " Ketika (atau jika) proyek mulai menghasilkan uang, bisnis ingin memotong lebih banyak fitur - karena mulai bekerja, jadi Anda perlu melangkah lebih jauh! Dan Anda berada pada titik di mana pada awalnya Anda perlu memantau semua yang sebelumnya, yang tidak membutuhkan 1% dari waktu, tetapi lebih dari itu. Dan omong-omong, pengembang akan membutuhkan pemantauan, dan lebih mudah untuk memasukkannya ke dalam fitur baru. Akibatnya, fitur baru ditulis, semuanya terbungkus, dan Anda berada di jalan buntu tanpa akhir.
Jadi bagaimana Anda memantau proyek dari awal, dan bagaimana jika Anda punya proyek yang perlu Anda pantau, tetapi Anda tidak tahu harus mulai dari mana?
Pertama, Anda perlu merencanakan.
Penyimpangan liris: sangat sering dimulai dengan pemantauan infrastruktur. Sebagai contoh, kami memiliki Kubernet. Untuk mulai dengan, kami menempatkan Prometheus dengan Grafana, meletakkan plugin di bawah pengawasan "kubus". Tidak hanya pengembang, tetapi juga admin memiliki praktik yang tidak menguntungkan: "Kami akan menginstal plug-in ini, dan plug-in mungkin tahu cara melakukan ini." Orang suka memulai dengan tindakan yang sederhana dan mudah dipahami, daripada penting. Dan memantau infrastruktur itu mudah.Pertama, putuskan apa dan bagaimana Anda ingin memantau, dan kemudian mengambil instrumen, karena orang lain tidak dapat berpikir untuk Anda. Ya, dan haruskah mereka? Orang lain berpikir sendiri, tentang sistem universal - atau tidak berpikir sama sekali ketika plugin ini ditulis. Dan fakta bahwa plugin ini memiliki 5 ribu pengguna tidak berarti itu membawa manfaat apa pun. Mungkin Anda akan menjadi yang 5001 hanya karena sudah ada 5.000 orang di sana sebelumnya.
Jika Anda mulai memantau infrastruktur dan bagian belakang aplikasi Anda berhenti merespons, semua pengguna akan kehilangan kontak dengan aplikasi seluler. Kesalahan akan terbang keluar. Mereka akan datang kepada Anda dan berkata, "Aplikasi tidak bekerja, apa yang Anda lakukan di sini?" "Kami sedang memantau." - "Bagaimana Anda memonitor jika Anda tidak melihat bahwa aplikasi tidak berfungsi?!"
- Saya percaya bahwa perlu untuk mulai memantau dari titik masuk pengguna. Jika pengguna tidak melihat bahwa aplikasi berfungsi - itu saja, itu gagal. Dan sistem pemantauan harus memperingatkan tentang hal ini sejak awal.
- Dan hanya dengan begitu kita dapat memonitor infrastruktur. Atau melakukannya secara paralel. Infrastrukturnya lebih sederhana - di sini kita akhirnya dapat menginstal zabbix.
- Dan sekarang Anda harus pergi ke akar aplikasi untuk memahami di mana itu tidak berfungsi.
Pikiran utama saya adalah bahwa pemantauan harus sejalan dengan proses pengembangan. Jika Anda merobek tim pemantauan untuk tugas-tugas lain (membuat CI / CD, kotak pasir, menata kembali infrastruktur), pemantauan akan mulai terlambat dan Anda mungkin tidak akan pernah ketinggalan dengan pengembangan (atau cepat atau lambat itu harus dihentikan).
Semua berdasarkan level
Ini adalah bagaimana saya melihat organisasi dari sistem pemantauan.
1) Tingkat Aplikasi:
- memantau logika bisnis aplikasi;
- memantau metrik layanan kesehatan;
- pemantauan integrasi.
2) Tingkat infrastruktur:
- memantau tingkat orkestrasi;
- perangkat lunak sistem pemantauan;
- memonitor level "besi".
3) Sekali lagi, level aplikasi - tetapi sebagai produk teknik:
- mengumpulkan dan memantau log aplikasi;
- APM
- melacak.
4) Peringatan:
- pengorganisasian sistem peringatan;
- organisasi sistem arloji;
- organisasi "basis pengetahuan" dan pemrosesan insiden alur kerja.
Penting : kami mendapatkan lansiran bukan setelahnya, tetapi segera! Tidak perlu memulai pemantauan dan "entah bagaimana nanti" pikirkan siapa yang akan menerima peringatan. Lagi pula, apa tugas pemantauan: untuk memahami di mana sesuatu tidak bekerja dalam sistem, dan biarkan orang yang tepat mengetahuinya. Jika ini dibiarkan sampai akhir, maka orang yang tepat akan mengetahui bahwa ada sesuatu yang salah, hanya dengan memanggil "tidak ada yang berhasil untuk kita."
Lapisan Aplikasi - Pemantauan Logika Bisnis
Di sini kita berbicara tentang memeriksa fakta bahwa aplikasi berfungsi untuk pengguna.
Level ini harus dilakukan pada tahap desain. Sebagai contoh, kami memiliki Prometheus bersyarat: ia merayapi ke server yang terlibat dalam pemeriksaan, menarik titik akhir, dan titik akhir pergi dan memeriksa API.
Ketika sering diminta memantau halaman utama untuk memastikan situsnya berfungsi, programmer memberikan pena yang dapat ditarik setiap kali Anda perlu memastikan bahwa API berfungsi. Dan programmer saat ini masih mengambil dan menulis / api / test / helloworld
Satu-satunya cara untuk memastikan semuanya berfungsi? - Tidak!
- Membuat cek semacam itu pada dasarnya adalah tugas pengembang. Tes unit harus ditulis oleh programmer yang menulis kode. Karena jika Anda menggabungkan ini ke admin “Bung, berikut adalah daftar protokol API untuk semua 25 fungsi, harap pantau semuanya!” - tidak akan ada yang berhasil.
- Jika Anda mencetak "hello world", tidak ada yang akan tahu bahwa API harus dan benar-benar berfungsi. Setiap perubahan pada API harus mengarah pada perubahan dalam pemeriksaan.
- Jika Anda sudah memiliki bencana seperti itu, hentikan fitur-fiturnya dan pilih pengembang yang akan menulis cek ini, atau rekonsiliasi dengan kerugiannya, rekonsiliasi bahwa tidak ada yang diperiksa dan akan jatuh.
Kiat Teknis:
- Pastikan untuk mengatur server eksternal untuk mengatur inspeksi - Anda harus yakin bahwa proyek Anda dapat diakses oleh dunia luar.
- Atur validasi di seluruh protokol API, bukan hanya titik akhir individual.
- Buat prometheus-endpoint dengan hasil tes.
Level Aplikasi - Pemantauan Metrik Kesehatan
Sekarang kita berbicara tentang metrik layanan kesehatan eksternal.
Kami memutuskan bahwa kami memantau semua "pena" aplikasi menggunakan pemeriksaan eksternal yang kami sebut dari sistem pemantauan eksternal. Tapi ini justru "pena" yang "dilihat" pengguna. Kami ingin memastikan bahwa layanan itu sendiri berfungsi untuk kami. Ini cerita yang lebih baik: K8 memiliki pemeriksaan kesehatan sehingga setidaknya kubus memastikan bahwa layanan tersebut berfungsi. Tapi setengah dari cek yang saya lihat adalah cetakan yang sama "hello world". Yaitu di sini dia menarik sekali setelah penyebaran, dia menjawab bahwa semuanya baik-baik saja - dan hanya itu. Dan layanan ini, jika menggunakan API sendiri, memiliki sejumlah besar titik masuk untuk API yang sama, yang juga perlu dipantau, karena kami ingin tahu bahwa itu berfungsi. Dan kami sedang memantau di dalam.
Cara menerapkannya dengan benar secara teknis: setiap layanan menetapkan titik akhir tentang kinerjanya saat ini, dan dalam grafik Grafana (atau aplikasi lain), kami melihat status semua layanan.
- Setiap perubahan pada API harus mengarah pada perubahan dalam pemeriksaan.
- Buat layanan baru segera dengan metrik kesehatan.
- Admin dapat datang ke pengembang dan bertanya "tambahkan saya beberapa fitur sehingga saya mengerti segalanya dan menambahkan informasi tentang ini ke sistem pemantauan saya." Tetapi pengembang biasanya menjawab, "Kami tidak akan menambahkan apa pun dua minggu sebelum rilis."
Biarkan manajer pengembangan tahu bahwa akan ada kerugian seperti itu, biarkan bos dari manajer pengembangan juga tahu. Karena ketika semuanya jatuh, seseorang masih akan menelepon dan meminta untuk memantau "layanan yang terus jatuh" (c) - By the way, pilih pengembang untuk menulis plugin untuk Grafana - ini akan menjadi bantuan yang baik untuk admin.
Lapisan Aplikasi - Pemantauan Integrasi
Pemantauan integrasi berfokus pada pemantauan komunikasi antara sistem kritis bisnis.
Misalnya, ada 15 layanan yang saling berkomunikasi. Ini bukan lagi situs individual. Yaitu kami tidak dapat menarik layanan sendiri, dapatkan / helloworld dan memahami bahwa layanan ini berfungsi. Karena layanan web untuk menempatkan pesanan harus mengirim informasi tentang pesanan ke bus - layanan gudang harus menerima pesan ini dari bus dan bekerja dengannya lebih lanjut. Dan layanan distribusi e-mail harus menangani ini lebih jauh, dll.
Karena itu, kita tidak dapat mengerti, mengaduk-aduk di setiap layanan individu, bahwa ini semua bekerja. Karena kami memiliki bus tertentu yang digunakan untuk berkomunikasi dan berinteraksi.
Oleh karena itu, tahap ini harus menunjukkan tahap layanan pengujian untuk berinteraksi dengan layanan lain. Setelah memantau pialang pesan, Anda tidak dapat mengatur pemantauan komunikasi. Jika ada layanan yang mengeluarkan data dan layanan yang menerimanya, saat memantau broker, kami hanya akan melihat data yang terbang dari sisi ke sisi. Sekalipun kami entah bagaimana berhasil memantau interaksi data ini di dalam - bahwa beberapa produser memposting data, seseorang membacanya, aliran ini berlanjut ke Kafka - tetap tidak akan memberi kami informasi jika satu layanan memberikan pesan dalam satu versi, tetapi layanan lain tidak mengharapkan versi ini dan melewatkannya. Kami tidak akan mencari tahu tentang ini, karena layanan akan memberi tahu kami bahwa semuanya berfungsi.
Seperti yang saya sarankan lakukan:
- Untuk komunikasi sinkron: titik akhir mengeksekusi permintaan untuk layanan terkait. Yaitu kita ambil titik akhir ini, tarik skrip ke dalam layanan, yang menuju ke semua titik dan berkata "Saya bisa menarik ke sana, dan menarik ke sana, saya bisa menarik ..."
- Untuk komunikasi asinkron: pesan masuk - titik akhir memeriksa bus untuk pesan pengujian dan menampilkan status pemrosesan.
- Untuk komunikasi asinkron: pesan keluar - titik akhir mengirim pesan percobaan ke bus.
Seperti yang biasanya terjadi: kami memiliki layanan yang membuang data di bus. Kami datang ke layanan ini dan meminta Anda untuk berbicara tentang kesehatan integrasinya. Dan jika layanan perlu menjual beberapa pesan lebih lanjut (WebApp), maka itu akan menghasilkan pesan pengujian ini. Dan jika kita menarik layanan di sisi OrderProcessing, itu pertama posting sesuatu yang dapat memposting independen, dan jika ada hal-hal tergantung, kemudian membaca satu set pesan pengujian dari bus, mengerti bahwa ia dapat memprosesnya, melaporkannya dan , jika perlu, poskan lebih jauh, dan tentang ini katanya - semuanya baik-baik saja, aku hidup.
Sangat sering kita mendengar pertanyaan "bagaimana kita bisa menguji ini pada data pertempuran?" Sebagai contoh, kita berbicara tentang layanan pesanan yang sama. Pesanan mengirim pesan ke gudang tempat barang dihapus: kita tidak dapat menguji ini pada data pertempuran, karena "barang saya akan dihapus!" Keluar: pada tahap awal, rencanakan seluruh tes ini. Anda memiliki tes unit yang mengejek. Jadi, lakukan di tingkat yang lebih dalam, di mana Anda akan memiliki saluran komunikasi yang tidak akan membahayakan bisnis.
Tingkat infrastruktur
Pemantauan infrastruktur adalah apa yang telah lama dianggap pemantauan itu sendiri.
- Pemantauan infrastruktur dapat dan harus diluncurkan sebagai proses terpisah.
- Anda tidak boleh memulai dengan memonitor infrastruktur pada proyek yang berfungsi, bahkan jika Anda benar-benar menginginkannya. Ini sakit untuk semua devops. “Pertama saya memonitor cluster, saya memonitor infrastruktur” - yaitu Pertama, ia akan memantau apa yang ada di bawah, tetapi tidak akan masuk ke dalam aplikasi. Karena aplikasi itu adalah hal yang tidak dapat dipahami oleh para devopa. Mereka membocorkannya kepadanya, dan dia tidak mengerti cara kerjanya. Dan dia mengerti infrastruktur dan mulai dengan itu. Tapi tidak - Anda selalu perlu memonitor aplikasi terlebih dahulu.
- . , , - . on-call, , « ». .
-
:
- ELK. . - , .
- APM. APM (NewRelic, BlackFire, Datadog). , - , .
- Tracing. , . , tracing — . – ! . Jaeger/Zipkin
- : . Grafana. PagerDuty. (, …). ,
- : ( , ). Oncall : , , , — ( — , : , ). , — (« — »), .
- « » workflow : , , . , — ; .
, :
- — Prometheus + Grafana;
- — ELK;
- APM Tracing — Jaeger (Zipkin).
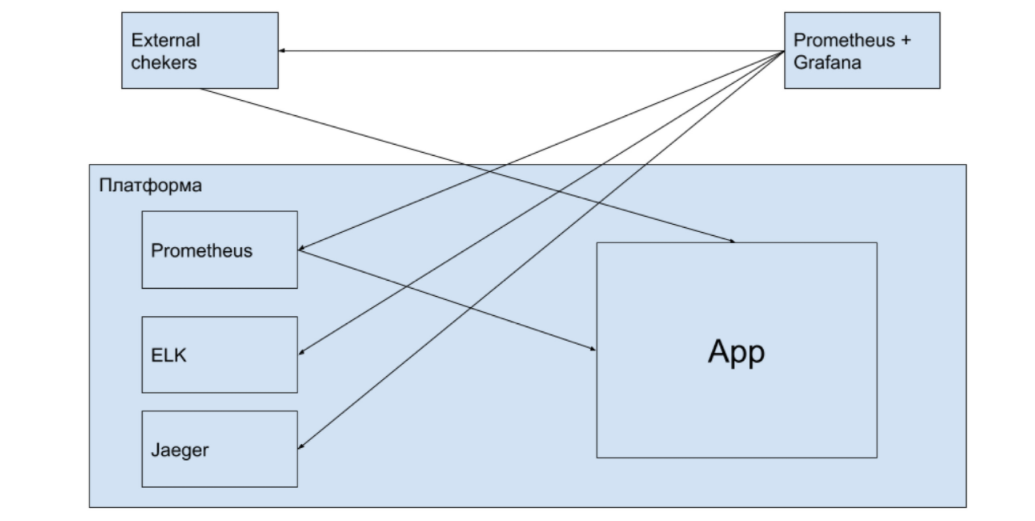
. , , , . , . , , , — .
, :
Prometheus Kubernetes — ?! , ? , , — , .
. . , Promtheus, , , . ? , , .
Kesimpulan
- — , . 98% — . , , , --.
- : 30% , .
- , , - , — . , — .
- ( ) — .
- , , « » — , .
Saint Highload++.UPD ( ):
1. , , , «, , , ». , : DevOps , — , , , .
2. Saya tidak mencoba memberi isyarat, kata mereka, "semuanya buruk di mana-mana, tetapi di sini kami dapat melakukan pemantauan - datanglah ke ITSumma." Tidak, jika proyek diluncurkan, pemantauan tidak dapat dilakukan oleh perusahaan pihak ketiga. Tentu saja, kami juga memiliki tujuan bisnis, dan apa yang benar-benar kami pikirkan adalah memperkenalkan konsultasi untuk mendukung proyek dalam proses pengembangannya untuk menyampaikan cara melakukan pemantauan bagian pengembangan secara tepat.Jika Anda tertarik dengan ide dan pemikiran saya tentang itu dan sebagainya, maka Anda dapat
membaca saluran :-)