Kami telah berkenalan dengan
mesin pengindeksan PostgreSQL dan antarmuka metode akses dan membahas
indeks hash ,
B-tree , serta
indeks GiST dan
SP-GiST . Dan artikel ini akan menampilkan indeks GIN.
Gin
"Gin? .. Gin sepertinya, minuman keras Amerika?"
"Aku bukan minuman, oh, bocah yang ingin tahu!" Sekali lagi lelaki tua itu berkobar, lagi-lagi dia menyadari dirinya dan kembali memegang tangannya. "Aku bukan minuman, tapi roh yang kuat dan tidak gentar, dan tidak ada keajaiban di dunia yang tidak akan bisa kulakukan."- Lazar Lagin, "Khottabych Tua."
Gin adalah singkatan dari Generalized Inverted Index dan harus dianggap sebagai jin, bukan minuman.-
READMEKonsep umum
GIN adalah Generated Inverted Index yang disingkat. Ini disebut
indeks terbalik . Itu memanipulasi tipe data yang nilainya bukan atom, tetapi terdiri dari elemen. Kami akan memanggil senyawa jenis ini. Dan ini bukan nilai-nilai yang diindeks, tetapi elemen individual; setiap elemen referensi nilai-nilai di mana itu terjadi.
Analogi yang baik untuk metode ini adalah indeks pada akhir buku, yang untuk setiap istilah, memberikan daftar halaman tempat istilah ini muncul. Metode akses harus memastikan pencarian cepat elemen yang diindeks, seperti halnya indeks dalam sebuah buku. Oleh karena itu, elemen-elemen ini disimpan sebagai
B-tree yang familiar (implementasi yang berbeda, lebih sederhana, digunakan untuk itu, tetapi tidak masalah dalam kasus ini). Rangkaian referensi yang disusun untuk baris tabel yang berisi nilai gabungan dengan elemen dihubungkan ke setiap elemen. Ketertiban tidak penting untuk pengambilan data (urutan urutan TID tidak banyak berarti), tetapi penting untuk struktur internal indeks.
Elemen tidak pernah dihapus dari indeks GIN. Diperkirakan bahwa nilai-nilai yang mengandung unsur-unsur dapat menghilang, muncul, atau bervariasi, tetapi himpunan unsur-unsur yang menyusunnya kurang lebih stabil. Solusi ini secara signifikan menyederhanakan algoritma untuk pekerjaan bersamaan dari beberapa proses dengan indeks.
Jika daftar TUT cukup kecil, itu dapat masuk ke halaman yang sama dengan elemen (dan disebut "daftar posting"). Tetapi jika daftar itu besar, struktur data yang lebih efisien diperlukan, dan kami sudah menyadarinya - itu adalah B-tree lagi. Pohon seperti ini terletak di halaman data terpisah (dan disebut "pohon posting").
Jadi, indeks GIN terdiri dari B-tree elemen, dan B-tree atau daftar datar TIDs terkait dengan baris daun B-tree itu.
Sama seperti indeks GiST dan SP-GiST, yang dibahas sebelumnya, GIN menyediakan antarmuka aplikasi kepada pengembang untuk mendukung berbagai operasi dari tipe data majemuk.
Pencarian teks lengkap
Area aplikasi utama untuk metode GIN adalah mempercepat pencarian teks lengkap, yang, oleh karena itu, masuk akal untuk digunakan sebagai contoh dalam diskusi yang lebih rinci dari indeks ini.
Artikel yang terkait dengan GiST telah memberikan pengantar kecil untuk pencarian teks lengkap, jadi mari kita langsung ke titik tanpa pengulangan. Jelas bahwa nilai majemuk dalam hal ini adalah
dokumen , dan elemen dari dokumen ini adalah
leksem .
Mari kita perhatikan contoh dari artikel terkait GiST:
postgres=# create table ts(doc text, doc_tsv tsvector); postgres=# insert into ts(doc) values ('Can a sheet slitter slit sheets?'), ('How many sheets could a sheet slitter slit?'), ('I slit a sheet, a sheet I slit.'), ('Upon a slitted sheet I sit.'), ('Whoever slit the sheets is a good sheet slitter.'), ('I am a sheet slitter.'), ('I slit sheets.'), ('I am the sleekest sheet slitter that ever slit sheets.'), ('She slits the sheet she sits on.'); postgres=# update ts set doc_tsv = to_tsvector(doc); postgres=# create index on ts using gin(doc_tsv);
Struktur yang mungkin dari indeks ini ditunjukkan pada gambar:
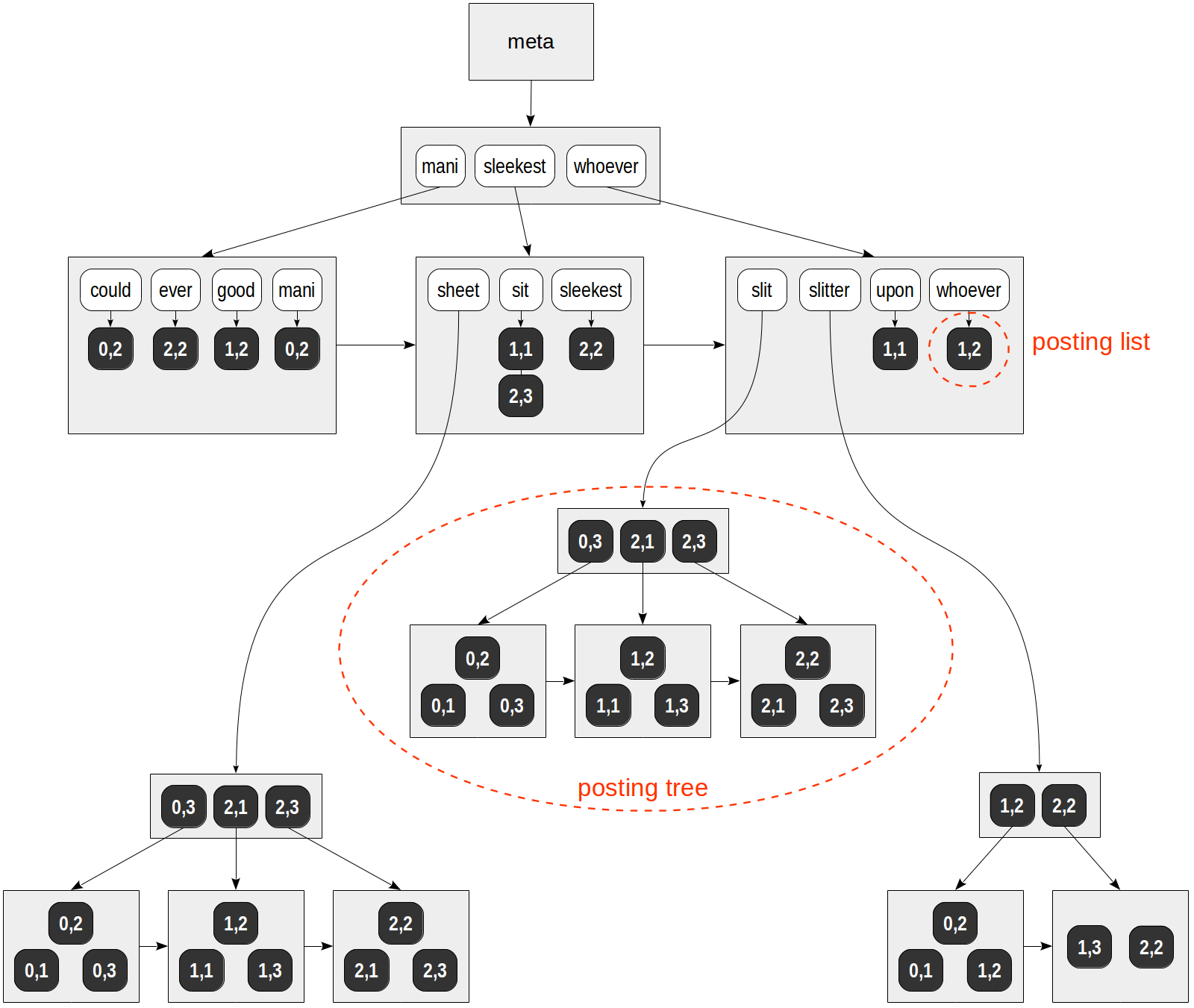
Tidak seperti di semua gambar sebelumnya, referensi ke baris tabel (TIDs) dilambangkan dengan nilai numerik pada latar belakang gelap (nomor halaman dan posisi pada halaman) daripada dengan panah.
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
Dalam contoh spekulatif ini, daftar TIDs masuk ke dalam halaman reguler untuk semua leksem kecuali "sheet", "slit", dan "slitter". Leksem ini muncul di banyak dokumen, dan daftar TUT untuk mereka telah ditempatkan di pohon-B individu.
Ngomong-ngomong, bagaimana kita bisa mengetahui berapa banyak dokumen yang mengandung leksem? Untuk sebuah meja kecil, teknik "langsung", ditunjukkan di bawah, akan berhasil, tetapi kita akan belajar lebih lanjut apa yang harus dilakukan dengan yang lebih besar.
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count ----------+------- sheet | 9 slit | 8 slitter | 5 sit | 2 upon | 1 mani | 1 whoever | 1 sleekest | 1 good | 1 could | 1 ever | 1 (11 rows)
Perhatikan juga bahwa tidak seperti B-tree biasa, halaman indeks GIN dihubungkan oleh daftar searah dan bukan dari dua arah. Ini cukup karena melintasi pohon hanya dilakukan satu arah.
Contoh kueri
Bagaimana pertanyaan berikut akan dilakukan untuk contoh kita?
postgres=# explain(costs off) select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('many & slitter'::text)) (4 rows)
Leksem individual (kunci pencarian) diekstraksi dari kueri terlebih dahulu: "mani" dan "slitter". Ini dilakukan oleh fungsi API khusus yang memperhitungkan tipe data dan strategi yang ditentukan oleh kelas operator:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'tsvector_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- @@(tsvector,tsquery) | 1 matching search query @@@(tsvector,tsquery) | 2 synonym for @@ (for backward compatibility) (2 rows)
Dalam B-tree of lexemes, kita selanjutnya menemukan kedua kunci dan pergi melalui daftar siap TUT. Kami mendapatkan:
untuk "mani" - (0,2).
untuk "slitter" - (0,1), (0,2), (1,2), (1,3), (2,2).
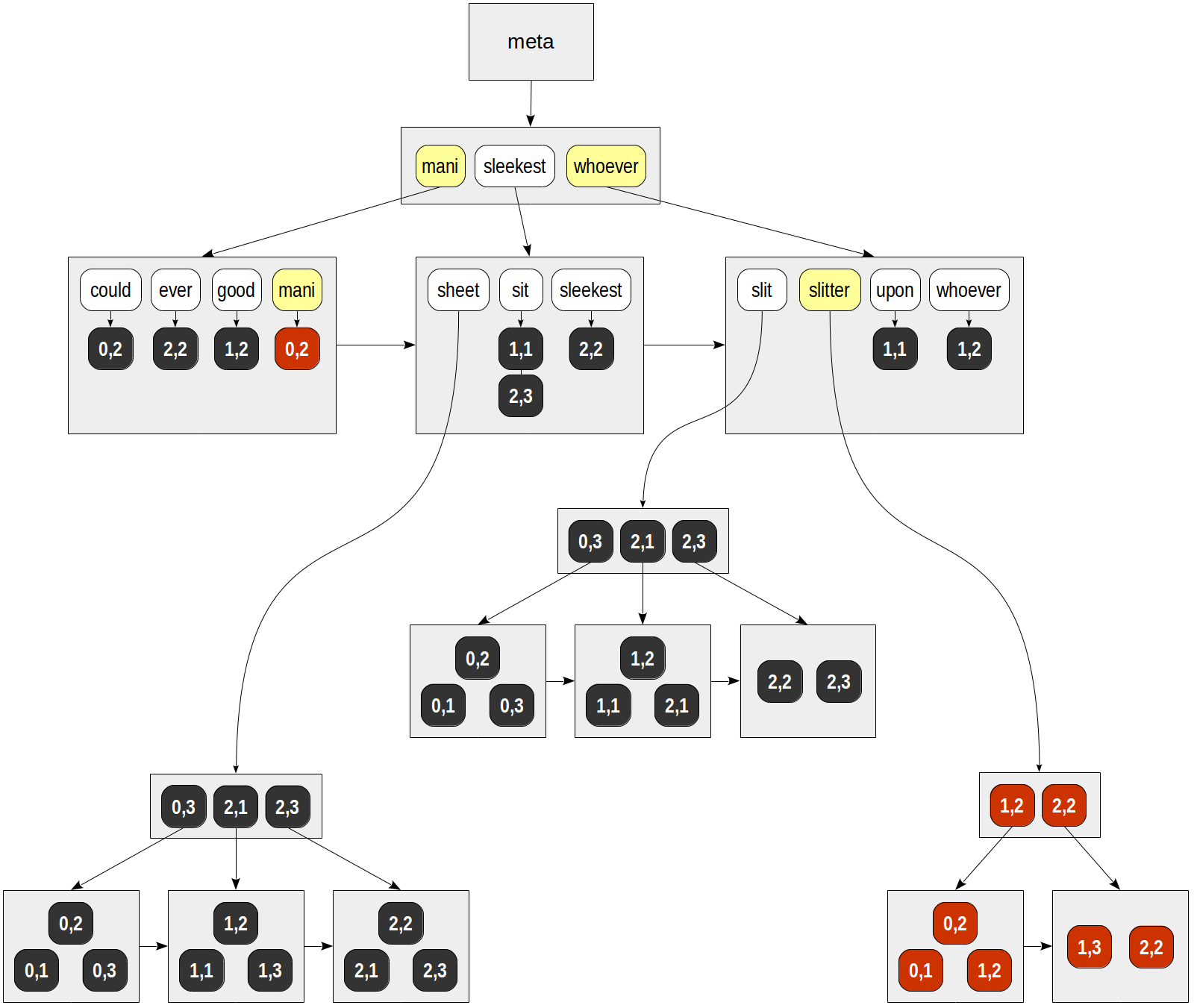
Akhirnya, untuk setiap TID yang ditemukan, fungsi konsistensi API dipanggil, yang harus menentukan baris mana yang ditemukan cocok dengan permintaan pencarian. Karena leksem dalam kueri kami bergabung dengan Boolean "dan", satu-satunya baris yang dikembalikan adalah (0,2):
| | | consistency | | | function TID | mani | slitter | slit & slitter -------+------+---------+---------------- (0,1) | f | T | f (0,2) | T | T | T (1,2) | f | T | f (1,3) | f | T | f (2,2) | f | T | f
Dan hasilnya adalah:
postgres=# select doc from ts where doc_tsv @@ to_tsquery('many & slitter');
doc --------------------------------------------- How many sheets could a sheet slitter slit? (1 row)
Jika kita membandingkan pendekatan ini dengan yang sudah dibahas untuk GiST, keuntungan dari GIN untuk pencarian teks lengkap tampak jelas. Tetapi ada lebih dari ini dalam memenuhi mata.
Masalah pembaruan lambat
Masalahnya adalah bahwa penyisipan atau pembaruan data dalam indeks GIN cukup lambat. Setiap dokumen biasanya berisi banyak leksem untuk diindeks. Oleh karena itu, ketika hanya satu dokumen yang ditambahkan atau diperbarui, kami harus memperbarui pohon indeks secara besar-besaran.
Di sisi lain, jika beberapa dokumen diperbarui secara bersamaan, beberapa leksemya mungkin sama, dan jumlah total pekerjaan akan lebih kecil daripada saat memperbarui dokumen satu per satu.
Indeks GIN memiliki parameter penyimpanan "perbaruan cepat", yang dapat kita tentukan selama pembuatan indeks dan perbarui nanti:
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
Dengan diaktifkannya parameter ini, pembaruan akan diakumulasikan dalam daftar terpisah yang tidak disusun (pada setiap halaman yang terhubung). Ketika daftar ini menjadi cukup besar atau selama vakum, semua pembaruan yang terakumulasi secara instan dibuat ke indeks. Daftar apa yang dianggap "cukup besar" ditentukan oleh parameter konfigurasi "gin_pending_list_limit" atau oleh parameter penyimpanan nama-sama dari indeks.
Tetapi pendekatan ini memiliki kelemahan: pertama, pencarian diperlambat (karena daftar yang tidak berurutan perlu diperiksa selain dari pohon), dan kedua, pembaruan berikutnya secara tak terduga dapat memakan banyak waktu jika daftar yang tidak berurutan telah diluap.
Cari kecocokan parsial
Kami dapat menggunakan kecocokan sebagian dalam pencarian teks lengkap. Misalnya, pertimbangkan permintaan berikut:
gin=# select doc from ts where doc_tsv @@ to_tsquery('slit:*');
doc -------------------------------------------------------- Can a sheet slitter slit sheets? How many sheets could a sheet slitter slit? I slit a sheet, a sheet I slit. Upon a slitted sheet I sit. Whoever slit the sheets is a good sheet slitter. I am a sheet slitter. I slit sheets. I am the sleekest sheet slitter that ever slit sheets. She slits the sheet she sits on. (9 rows)
Kueri ini akan menemukan dokumen yang berisi leksem dimulai dengan "celah". Dalam contoh ini, leksem semacam itu "slit" dan "slitter".
Bagaimanapun, sebuah kueri pasti akan berfungsi, bahkan tanpa indeks, tetapi GIN juga mengizinkan untuk mempercepat pencarian berikut:
postgres=# explain (costs off) select doc from ts where doc_tsv @@ to_tsquery('slit:*');
QUERY PLAN ------------------------------------------------------------- Bitmap Heap Scan on ts Recheck Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) -> Bitmap Index Scan on ts_doc_tsv_idx Index Cond: (doc_tsv @@ to_tsquery('slit:*'::text)) (4 rows)
Di sini semua leksem yang memiliki awalan yang ditentukan dalam permintaan pencarian dilihat di pohon dan bergabung dengan Boolean "atau".
Leksem yang sering dan jarang
Untuk melihat bagaimana pengindeksan bekerja pada data langsung, mari kita ambil arsip email "pgsql-hacker", yang telah kita gunakan saat membahas GiST.
Versi arsip ini berisi 356125 pesan dengan tanggal kirim, subjek, penulis, dan teks.
fts=# alter table mail_messages add column tsv tsvector; fts=# update mail_messages set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed DETAIL: Words longer than 2047 characters are ignored. ... UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
Mari kita pertimbangkan leksem yang muncul di banyak dokumen. Kueri yang menggunakan "undest" akan gagal berfungsi pada ukuran data sebesar itu, dan teknik yang benar adalah dengan menggunakan fungsi "ts_stat", yang menyediakan informasi tentang leksem, jumlah dokumen di mana mereka terjadi, dan jumlah total kejadian.
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') order by ndoc desc limit 3;
word | ndoc -------+-------- re | 322141 wrote | 231174 use | 176917 (3 rows)
Mari kita pilih "menulis".
Dan kami akan mengambil beberapa kata yang jarang untuk email pengembang, katakanlah, "tato":
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc --------+------ tattoo | 2 (1 row)
Apakah ada dokumen di mana kedua leksem ini muncul? Tampaknya ada:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row)
Muncul pertanyaan bagaimana melakukan kueri ini. Jika kita mendapatkan daftar TUT untuk kedua leksem, seperti dijelaskan di atas, pencarian jelas akan tidak efisien: kita harus melewati lebih dari 200 ribu nilai, hanya satu yang tersisa. Untungnya, menggunakan statistik perencana, algoritma memahami bahwa "menulis" leksem sering terjadi, sementara "tato" jarang terjadi. Oleh karena itu, pencarian leksem yang jarang dilakukan, dan dua dokumen yang diambil kemudian diperiksa untuk terjadinya leksem "tulis". Dan ini jelas dari kueri, yang dilakukan dengan cepat:
fts=# \timing on fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count ------- 1 (1 row) Time: 0,959 ms
Pencarian "wrote" saja memakan waktu lebih lama:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count -------- 231174 (1 row) Time: 2875,543 ms (00:02,876)
Optimalisasi ini tentu saja berfungsi tidak hanya untuk dua leksem, tetapi dalam kasus yang lebih kompleks juga.
Membatasi hasil kueri
Fitur metode akses GIN adalah bahwa hasilnya selalu dikembalikan sebagai bitmap: metode ini tidak dapat mengembalikan hasil TID oleh TID. Karena hal ini, semua paket kueri dalam artikel ini menggunakan pemindaian bitmap.
Oleh karena itu, keterbatasan hasil pemindaian indeks menggunakan klausa LIMIT tidak cukup efisien. Perhatikan perkiraan biaya operasi (bidang "biaya" pada simpul "Batas"):
fts=# explain (costs off) select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN ----------------------------------------------------------------------------------------- Limit (cost=1283.61..1285.13 rows=1) -> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207) Recheck Cond: (tsv @@ to_tsquery('wrote'::text)) -> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207) Index Cond: (tsv @@ to_tsquery('wrote'::text)) (5 rows)
Biaya diperkirakan 1285.13, yang sedikit lebih besar dari biaya membangun seluruh bitmap 1249.30 (bidang "biaya" dari node Bitmap Index Scan).
Oleh karena itu, indeks memiliki kemampuan khusus untuk membatasi jumlah hasil. Nilai ambang ditentukan dalam parameter konfigurasi "gin_fuzzy_search_limit" dan sama dengan nol secara default (tidak ada batasan yang terjadi). Tetapi kita dapat mengatur nilai ambang:
fts=# set gin_fuzzy_search_limit = 1000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 5746 (1 row)
fts=# set gin_fuzzy_search_limit = 10000; fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count ------- 14726 (1 row)
Seperti yang bisa kita lihat, jumlah baris yang dikembalikan oleh query berbeda untuk nilai parameter yang berbeda (jika akses indeks digunakan). Batasannya tidak ketat: lebih banyak baris dari yang ditentukan dapat dikembalikan, yang membenarkan bagian "fuzzy" dari nama parameter.
Representasi yang kompak
Di antara yang lainnya, indeks GIN bagus berkat kekompakannya. Pertama, jika satu dan leksem yang sama muncul di beberapa dokumen (dan biasanya ini masalahnya), ia disimpan dalam indeks hanya sekali. Kedua, TUT disimpan dalam indeks dengan cara yang teratur, dan ini memungkinkan kita untuk menggunakan kompresi sederhana: masing-masing TUT berikutnya dalam daftar sebenarnya disimpan sebagai perbedaan dari yang sebelumnya; ini biasanya sejumlah kecil, yang membutuhkan bit lebih sedikit daripada TID 6-byte yang lengkap.
Untuk mengetahui ukurannya, mari kita bangun B-tree dari teks pesan. Tetapi perbandingan yang adil belum tentu akan terjadi:
- GIN dibangun di atas tipe data yang berbeda ("tsvector" daripada "text"), yang lebih kecil,
- pada saat yang sama, ukuran pesan untuk B-tree harus dipersingkat menjadi sekitar dua kilobyte.
Namun demikian, kami terus:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
Kami akan membangun indeks GiST juga:
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
Ukuran indeks pada "vakum penuh":
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin, pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist, pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree --------+--------+-------- 179 MB | 125 MB | 546 MB (1 row)
Karena kekompakan representasi, kita dapat mencoba menggunakan indeks GIN selama migrasi dari Oracle sebagai pengganti indeks bitmap (tanpa merinci, saya memberikan
referensi ke posting Lewis untuk pikiran ingin tahu). Sebagai aturan, indeks bitmap digunakan untuk bidang yang memiliki beberapa nilai unik, yang sangat baik juga untuk GIN. Dan, seperti yang ditunjukkan
pada artikel pertama , PostgreSQL dapat membangun bitmap berdasarkan indeks apa pun, termasuk GIN, dengan cepat.
GiST atau GIN?
Untuk banyak tipe data, kelas operator tersedia untuk GiST dan GIN, yang menimbulkan pertanyaan indeks mana yang akan digunakan. Mungkin, kita sudah bisa membuat beberapa kesimpulan.
Sebagai aturan, GIN mengalahkan GiST dalam akurasi dan kecepatan pencarian. Jika data diperbarui tidak sering dan pencarian cepat diperlukan, kemungkinan besar GIN akan menjadi pilihan.
Di sisi lain, jika data diperbarui secara intensif, biaya overhead untuk memperbarui GIN mungkin tampak terlalu besar. Dalam hal ini, kita harus membandingkan kedua opsi dan memilih salah satu yang karakteristiknya lebih seimbang.
Array
Contoh lain menggunakan GIN adalah pengindeksan array. Dalam hal ini, elemen array masuk ke dalam indeks, yang memungkinkan untuk mempercepat sejumlah operasi melalui array:
postgres=# select amop.amopopr::regoperator, amop.amopstrategy from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname = 'array_ops' and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy -----------------------+-------------- &&(anyarray,anyarray) | 1 intersection @>(anyarray,anyarray) | 2 contains array <@(anyarray,anyarray) | 3 contained in array =(anyarray,anyarray) | 4 equality (4 rows)
Database demo kami memiliki tampilan "rute" dengan informasi tentang penerbangan. Di antara yang lain, tampilan ini berisi kolom "days_of_week" - array hari kerja ketika penerbangan dilakukan. Misalnya, penerbangan dari Vnukovo ke Gelendzhik berangkat pada hari Selasa, Kamis, dan Minggu:
demo=# select departure_airport_name, arrival_airport_name, days_of_week from routes where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week ------------------------+----------------------+-------------- Vnukovo | Gelendzhik | {2,4,7} (1 row)
Untuk membangun indeks, mari "wujudkan" tampilan menjadi tabel:
demo=# create table routes_t as select * from routes; demo=# create index on routes_t using gin(days_of_week);
Sekarang kita dapat menggunakan indeks untuk mengetahui semua penerbangan yang berangkat pada hari Selasa, Kamis, dan Minggu:
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (4 rows)
Tampaknya ada enam di antaranya:
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week -----------+------------------------+----------------------+-------------- PG0005 | Domodedovo | Pskov | {2,4,7} PG0049 | Vnukovo | Gelendzhik | {2,4,7} PG0113 | Naryan-Mar | Domodedovo | {2,4,7} PG0249 | Domodedovo | Gelendzhik | {2,4,7} PG0449 | Stavropol | Vnukovo | {2,4,7} PG0540 | Barnaul | Vnukovo | {2,4,7} (6 rows)
Bagaimana cara kueri ini dilakukan? Cara yang persis sama seperti yang dijelaskan di atas:
- Dari array {2,4,7}, yang memainkan peran permintaan pencarian di sini, elemen (kata kunci pencarian) diekstraksi. Jelas, ini adalah nilai-nilai "2", "4", dan "7".
- Di pohon elemen, kunci yang diekstraksi ditemukan, dan untuk masing-masingnya daftar TUT dipilih.
- Dari semua TIDs yang ditemukan, fungsi konsistensi memilih yang cocok dengan operator dari kueri. Untuk
= operator, hanya TIDs yang cocok dengan itu yang terjadi di ketiga daftar (dengan kata lain, array awal harus berisi semua elemen). Tetapi ini tidak cukup: array juga tidak perlu mengandung nilai lain, dan kami tidak dapat memeriksa kondisi ini dengan indeks. Oleh karena itu, dalam hal ini, metode akses meminta mesin pengindeksan untuk memeriksa kembali semua TID yang dikembalikan dengan tabel.
Menariknya, ada strategi (misalnya, "terkandung dalam array") yang tidak dapat memeriksa apa pun dan harus memeriksa ulang semua TUT yang ditemukan dengan tabel.
Tetapi apa yang harus dilakukan jika kita perlu mengetahui penerbangan yang berangkat dari Moskow pada hari Selasa, Kamis, dan Minggu? Indeks tidak akan mendukung kondisi tambahan, yang akan masuk ke kolom "Filter".
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN ----------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: (days_of_week = '{2,4,7}'::integer[]) Filter: (departure_city = 'Moscow'::text) -> Bitmap Index Scan on routes_t_days_of_week_idx Index Cond: (days_of_week = '{2,4,7}'::integer[]) (5 rows)
Di sini ini OK (indeks hanya memilih enam baris saja), tetapi dalam kasus di mana kondisi tambahan meningkatkan kemampuan selektif, diinginkan untuk memiliki dukungan seperti itu. Namun, kami tidak bisa hanya membuat indeks:
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin" HINT: You must specify an operator class for the index or define a default operator class for the data type.
Tapi ekstensi "
btree_gin " akan membantu, yang menambahkan kelas operator GIN yang mensimulasikan pekerjaan B-tree biasa.
demo=# create extension btree_gin; demo=# create index on routes_t using gin(days_of_week,departure_city); demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = 'Moscow';
QUERY PLAN --------------------------------------------------------------------- Bitmap Heap Scan on routes_t Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) -> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND (departure_city = 'Moscow'::text)) (4 rows)
Jsonb
Satu lagi contoh tipe data majemuk yang memiliki dukungan GIN bawaan adalah JSON. Untuk bekerja dengan nilai JSON, sejumlah operator dan fungsi didefinisikan saat ini, beberapa di antaranya dapat dipercepat menggunakan indeks:
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop where opc.opcname in ('jsonb_ops','jsonb_path_ops') and opf.oid = opc.opcfamily and am.oid = opf.opfmethod and amop.amopfamily = opc.opcfamily and am.amname = 'gin' and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str ----------------+------------------+----- jsonb_ops | ?(jsonb,text) | 9 top-level key exists jsonb_ops | ?|(jsonb,text[]) | 10 some top-level key exists jsonb_ops | ?&(jsonb,text[]) | 11 all top-level keys exist jsonb_ops | @>(jsonb,jsonb) | 7 JSON value is at top level jsonb_path_ops | @>(jsonb,jsonb) | 7 (5 rows)
Seperti yang dapat kita lihat, dua kelas operator tersedia: "jsonb_ops" dan "jsonb_path_ops".
Kelas operator pertama "jsonb_ops" digunakan secara default. Semua kunci, nilai, dan elemen array sampai ke indeks sebagai elemen dari dokumen JSON awal. Atribut ditambahkan ke masing-masing elemen ini, yang menunjukkan apakah elemen ini adalah kunci (ini diperlukan untuk strategi "ada", yang membedakan antara kunci dan nilai).
Misalnya, mari kita wakili beberapa baris dari "rute" sebagai JSON sebagai berikut:
demo=# create table routes_jsonb as select to_jsonb(t) route from ( select departure_airport_name, arrival_airport_name, days_of_week from routes order by flight_no limit 4 ) t; demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty -------+------------------------------------------------- (0,1) | { + | "days_of_week": [ + | 1 + | ], + | "arrival_airport_name": "Surgut", + | "departure_airport_name": "Ust-Ilimsk" + | } (0,2) | { + | "days_of_week": [ + | 2 + | ], + | "arrival_airport_name": "Ust-Ilimsk", + | "departure_airport_name": "Surgut" + | } (0,3) | { + | "days_of_week": [ + | 1, + | 4 + | ], + | "arrival_airport_name": "Sochi", + | "departure_airport_name": "Ivanovo-Yuzhnyi"+ | } (0,4) | { + | "days_of_week": [ + | 2, + | 5 + | ], + | "arrival_airport_name": "Ivanovo-Yuzhnyi", + | "departure_airport_name": "Sochi" + | } (4 rows)
demo=# create index on routes_jsonb using gin(route);
Indeks mungkin terlihat sebagai berikut:
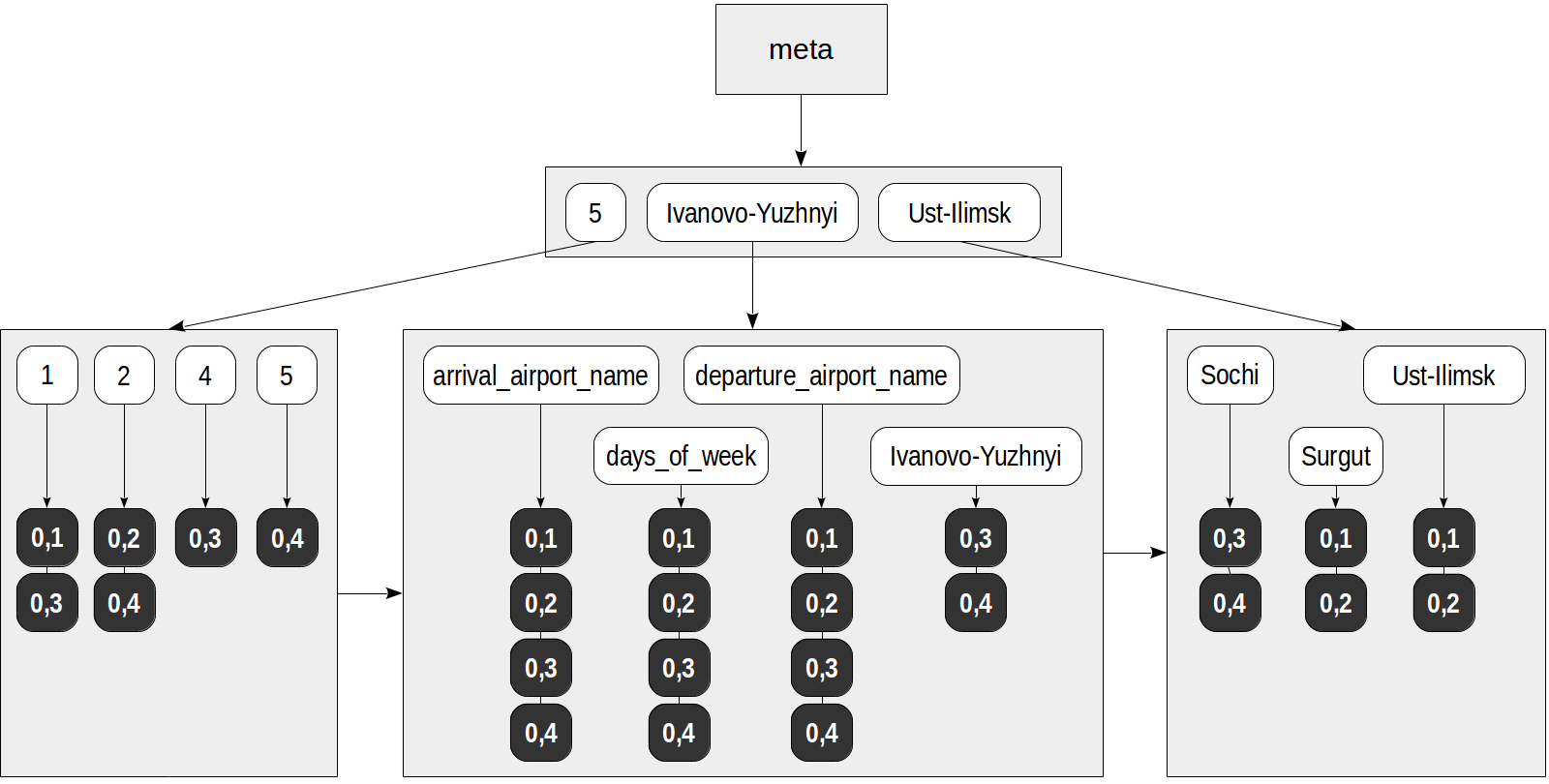
Sekarang, kueri seperti ini, misalnya, dapat dilakukan menggunakan indeks:
demo=# explain (costs off) select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
QUERY PLAN --------------------------------------------------------------- Bitmap Heap Scan on routes_jsonb Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb) -> Bitmap Index Scan on routes_jsonb_route_idx Index Cond: (route @> '{"days_of_week": [5]}'::jsonb) (4 rows)
Dimulai dengan akar dokumen JSON,
@> operator memeriksa apakah rute yang ditentukan (
"days_of_week": [5] ) terjadi. Di sini kueri akan mengembalikan satu baris:
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty ------------------------------------------------ { + "days_of_week": [ + 2, + 5 + ], + "arrival_airport_name": "Ivanovo-Yuzhnyi",+ "departure_airport_name": "Sochi" + } (1 row)
Permintaan dilakukan sebagai berikut:
- Dalam kueri pencarian (
"days_of_week": [5] ) elemen (kunci pencarian) diekstraksi: "days_of_week" dan "5".
- Di pohon elemen kunci yang diekstraksi ditemukan, dan untuk masing-masing daftar TIDs dipilih: untuk "5" - (0,4), dan untuk "days_of_week" - (0,1), (0,2) ), (0,3), (0,4).
- Dari semua TIDs yang ditemukan, fungsi konsistensi memilih yang cocok dengan operator dari kueri. Untuk operator
@> , dokumen yang mengandung tidak semua elemen dari permintaan pencarian tidak akan memastikan, sehingga hanya (0,4) yang tersisa. Tetapi kita masih perlu memeriksa kembali TID yang tersisa dengan tabel karena tidak jelas dari indeks dalam urutan apa elemen yang ditemukan terjadi dalam dokumen JSON.
Untuk menemukan rincian lebih lanjut dari operator lain, Anda dapat membaca
dokumentasi .
Selain operasi konvensional untuk berurusan dengan JSON, ekstensi "jsquery" telah lama tersedia, yang mendefinisikan bahasa permintaan dengan kemampuan yang lebih kaya (dan tentu saja, dengan dukungan indeks GIN). Selain itu, pada tahun 2016, standar SQL baru dikeluarkan, yang mendefinisikan set operasi sendiri dan bahasa query "SQL / JSON path". Implementasi standar ini telah selesai, dan kami yakin ini akan muncul di PostgreSQL 11.
Patch path SQL / JSON akhirnya berkomitmen untuk PostgreSQL 12, sementara bagian lainnya masih dalam perjalanan. Semoga kita akan melihat fitur yang sepenuhnya diimplementasikan di PostgreSQL 13.
Internal
Kita dapat melihat ke dalam indeks GIN menggunakan ekstensi "
pageinspect ".
fts=# create extension pageinspect;
Informasi dari halaman meta menunjukkan statistik umum:
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+----------- pending_head | 4294967295 pending_tail | 4294967295 tail_free_size | 0 n_pending_pages | 0 n_pending_tuples | 0 n_total_pages | 22968 n_entry_pages | 13751 n_data_pages | 9216 n_entries | 1423598 version | 2
Struktur halaman menyediakan area khusus tempat metode akses menyimpan informasinya; area ini "buram" untuk program biasa seperti ruang hampa udara. Fungsi "Gin_page_opaque_info" menunjukkan data ini untuk GIN. Sebagai contoh, kita bisa mengetahui kumpulan halaman indeks:
fts=# select flags, count(*) from generate_series(1,22967) as g(id),
flags | count ------------------------+------- {meta} | 1 meta page {} | 133 internal page of element B-tree {leaf} | 13618 leaf page of element B-tree {data} | 1497 internal page of TID B-tree {data,leaf,compressed} | 7719 leaf page of TID B-tree (5 rows)
Fungsi "Gin_leafpage_items" memberikan informasi tentang TUT yang disimpan di halaman {data, leaf, compressed}:
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]--------------------------------------------------------------------- first_tid | (239,44) nbytes | 248 tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",... -[ RECORD 2 ]--------------------------------------------------------------------- first_tid | (247,40) nbytes | 248 tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",... ...
Perhatikan di sini bahwa meninggalkan halaman-halaman pohon TIDs sebenarnya mengandung daftar kecil dari pointer ke baris tabel daripada pointer individual.
Properti
Mari kita lihat sifat-sifat metode akses GIN (pertanyaan
telah disediakan ).
amname | name | pg_indexam_has_property --------+---------------+------------------------- gin | can_order | f gin | can_unique | f gin | can_multi_col | t gin | can_exclude | f
Menariknya, GIN mendukung pembuatan indeks multikolom. Namun, tidak seperti untuk B-tree biasa, alih-alih kunci majemuk, indeks multikolom masih akan menyimpan elemen individu, dan nomor kolom akan diindikasikan untuk setiap elemen.
Properti lapisan indeks berikut tersedia:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Perhatikan bahwa mengembalikan hasil TID dengan TID (pemindaian indeks) tidak didukung; hanya pemindaian bitmap yang dimungkinkan.
Pemindaian mundur juga tidak didukung: fitur ini penting untuk pemindaian indeks saja, tetapi tidak untuk pemindaian bitmap.
Dan berikut ini adalah properti layer-layer:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | f
Tidak ada yang tersedia di sini: tidak ada penyortiran (yang jelas), tidak ada penggunaan indeks sebagai penutup (karena dokumen itu sendiri tidak disimpan dalam indeks), tidak ada manipulasi NULLs (karena tidak masuk akal untuk elemen tipe senyawa) .
Tipe data lainnya
Beberapa ekstensi lagi tersedia yang menambahkan dukungan GIN untuk beberapa tipe data.
- " pg_trgm " memungkinkan kita untuk menentukan "persamaan" kata-kata dengan membandingkan berapa banyak urutan tiga huruf (trigram) yang tersedia. Dua kelas operator ditambahkan, "gist_trgm_ops" dan "gin_trgm_ops", yang mendukung berbagai operator, termasuk perbandingan melalui LIKE dan ekspresi reguler. Kita dapat menggunakan ekstensi ini bersama dengan pencarian teks lengkap untuk menyarankan opsi kata untuk memperbaiki kesalahan ketik.
- " hstore " mengimplementasikan penyimpanan "nilai kunci". Untuk tipe data ini, kelas operator untuk berbagai metode akses tersedia, termasuk GIN. Namun, dengan diperkenalkannya tipe data "jsonb", tidak ada alasan khusus untuk menggunakan "hstore".
- " intarray " memperluas fungsi array integer. Dukungan indeks termasuk GiST, dan juga GIN ("gin__int_ops" kelas operator).
Dan dua ekstensi ini telah disebutkan di atas:
- " btree_gin " menambahkan dukungan GIN untuk tipe data reguler agar dapat digunakan dalam indeks multikolom bersama dengan tipe majemuk.
- " jsquery " mendefinisikan bahasa untuk kueri JSON dan kelas operator untuk dukungan indeks bahasa ini. Ekstensi ini tidak termasuk dalam pengiriman PostgreSQL standar.
Baca terus .