Bagaimana cara bekerja secara efektif dengan json di R?
Ini adalah kelanjutan dari publikasi sebelumnya .
Pernyataan masalah
Sebagai aturan, sumber utama data dalam format json adalah API REST. Penggunaan json, di samping platform kemerdekaan dan kenyamanan persepsi data manusia, memungkinkan pertukaran sistem data yang tidak terstruktur dengan struktur pohon yang kompleks.
Dalam tugas membangun API, ini sangat nyaman. Sangat mudah untuk memastikan versi protokol komunikasi, mudah untuk memberikan fleksibilitas pertukaran informasi. Pada saat yang sama, kompleksitas struktur data (level bersarang bisa 5, 6, 10 atau bahkan lebih) tidak menakutkan, karena menulis parser yang fleksibel untuk satu catatan tunggal yang memperhitungkan segala sesuatu dan semuanya tidak terlalu sulit.
Tugas pemrosesan data juga termasuk mendapatkan data dari sumber eksternal, termasuk dalam format json. R memiliki seperangkat paket yang bagus, khususnya jsonlite , yang dirancang untuk mengubah objek json ke R ( list atau, data.frame , jika struktur data memungkinkan).
Namun, dalam praktiknya, dua kelas masalah sering muncul ketika menggunakan jsonlite dan sejenisnya menjadi sangat tidak efisien. Tugas terlihat seperti ini:
- memproses sejumlah besar data (satuan ukuran - gigabita) yang diperoleh selama pengoperasian berbagai sistem informasi;
- menggabungkan sejumlah besar tanggapan terstruktur variabel yang diterima selama paket permintaan API REST yang diparameterisasi menjadi representasi persegi panjang yang seragam (
data.frame ).
Contoh struktur serupa dalam ilustrasi:
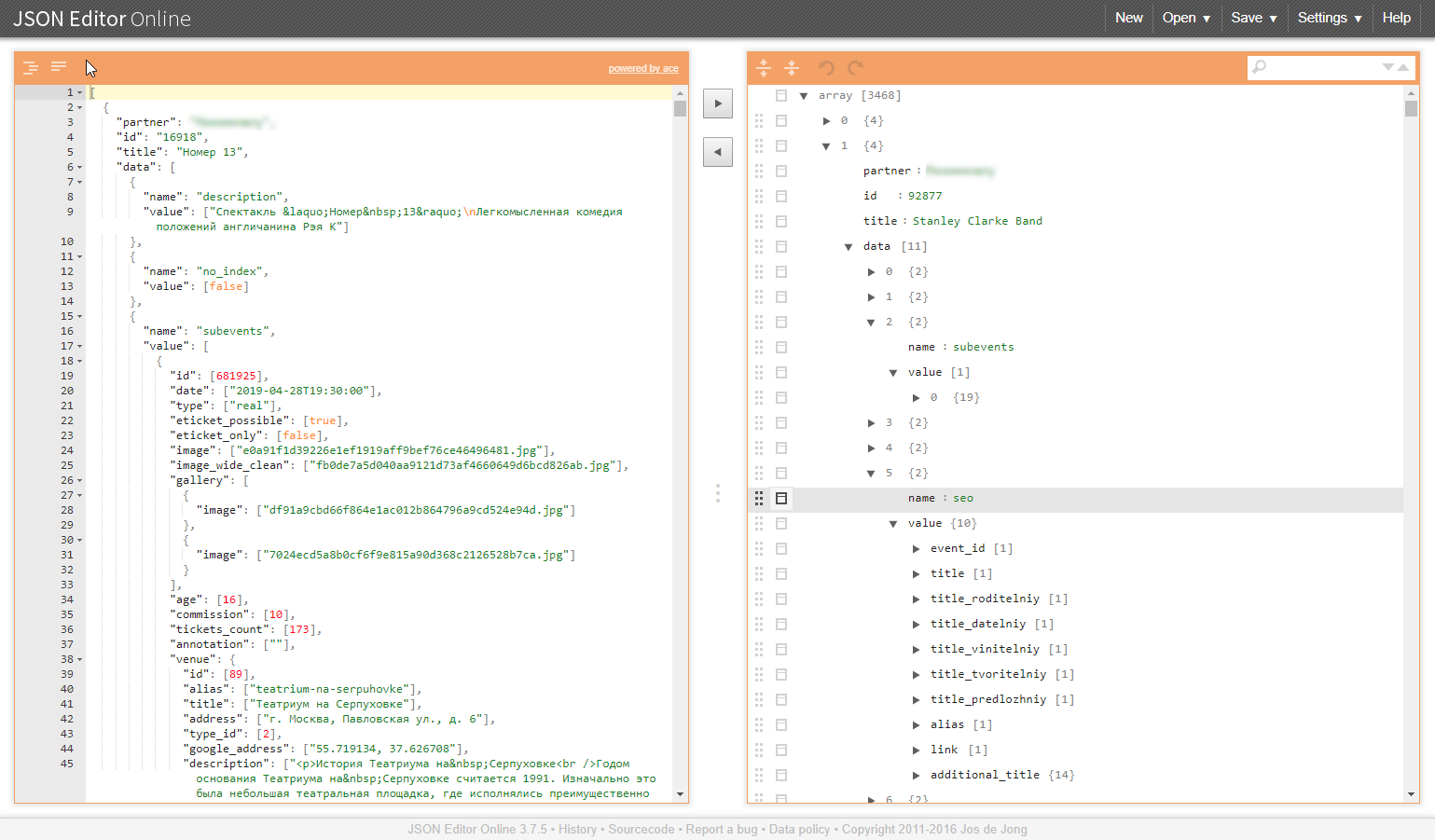
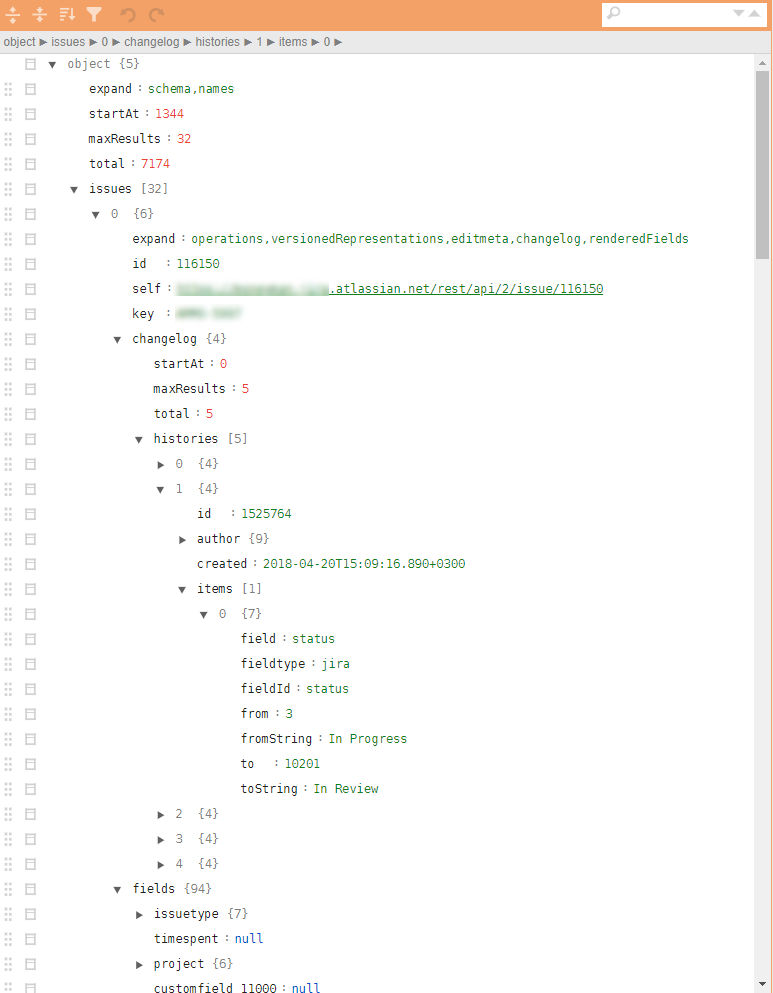
Mengapa kelas tugas ini bermasalah?
Sejumlah besar data
Sebagai aturan, pembongkaran dari sistem informasi dalam format json adalah blok data yang tidak dapat dibagi. Untuk menguraikannya dengan benar, Anda harus membaca semuanya dan membaca seluruh volumenya.
Masalah yang ditimbulkan:
- diperlukan sejumlah RAM dan sumber daya komputasi yang sesuai;
- kecepatan parsing sangat tergantung pada kualitas perpustakaan yang digunakan, dan bahkan jika ada sumber daya yang memadai, waktu konversi dapat puluhan atau bahkan ratusan menit;
- dalam hal terjadi kegagalan penguraian, tidak ada hasil yang diperoleh pada output, dan tidak ada alasan untuk berharap bahwa semuanya akan selalu berjalan lancar, tidak ada alasan, melainkan sebaliknya;
- Ini akan sangat berhasil jika data yang diuraikan dapat dikonversi ke
data.frame .
Menggabungkan Struktur Pohon
Tugas serupa muncul, misalnya, ketika perlu untuk mengumpulkan direktori yang diperlukan oleh proses bisnis untuk bekerja dengan paket permintaan melalui API. Selain itu, direktori menyiratkan penyatuan dan kesiapan untuk menanamkan ke dalam pipa analitik dan potensi pengunggahan ke database. Dan ini lagi membuatnya perlu untuk mengubah data ringkasan tersebut menjadi data.frame .
Masalah yang ditimbulkan:
- struktur pohon itu sendiri tidak akan berubah menjadi datar. json parser mengubah data input menjadi satu set daftar bersarang, yang kemudian secara manual perlu digunakan untuk waktu yang lama dan menyakitkan;
- kebebasan dalam atribut data keluaran (yang tidak ada mungkin tidak ditampilkan) mengarah ke penampilan objek
NULL yang relevan dalam daftar, tetapi tidak dapat "sesuai" dalam data.frame , yang menyulitkan pasca proses dan menyulitkan bahkan proses dasar menggabungkan setiap baris-lembar ke dalam data.frame (tidak masalah rbindlist , bind_rows , 'map_dfr' atau rbind ).
JQ - jalan keluar
Dalam situasi yang sangat sulit, penggunaan pendekatan yang sangat mudah dari paket jsonlite "convert all to R objek" karena alasan di atas memberikan kerusakan serius. Nah, jika Anda berhasil sampai ke akhir pemrosesan. Lebih buruk lagi, jika di tengah Anda harus merentangkan tangan dan menyerah.
Alternatif untuk pendekatan ini adalah dengan menggunakan prepson json, yang beroperasi langsung pada data json. Pustaka jq dan pembungkus jqr . Praktek menunjukkan bahwa itu tidak hanya digunakan sedikit, tetapi sedikit yang pernah mendengarnya sama sekali, dan sia-sia.
Manfaat perpustakaan jq .
- perpustakaan dapat digunakan dalam R, dalam Python dan pada baris perintah;
- semua transformasi dilakukan pada tingkat json, tanpa transformasi menjadi representasi dari objek R / Python;
- pemrosesan dapat dibagi menjadi operasi atom dan menggunakan prinsip rantai (pipa);
- siklus untuk memproses vektor objek disembunyikan di dalam parser, sintaks iterasi disederhanakan secara maksimal;
- kemampuan untuk melakukan semua prosedur untuk penyatuan struktur json, penyebaran dan pemilihan elemen yang diperlukan untuk membuat format json yang dikonversi secara batch ke
data.frame menggunakan jsonlite ; - beberapa pengurangan kode R yang bertanggung jawab untuk memproses data json;
- kecepatan pemrosesan yang besar, tergantung pada volume dan kompleksitas struktur data, keuntungannya bisa 1-3 urutan besarnya;
- persyaratan RAM jauh lebih sedikit.
Kode pemrosesan dikompresi agar sesuai dengan layar dan mungkin terlihat seperti ini:
cont <- httr::content(r3, as = "text", encoding = "UTF-8") m <- cont %>% # jqr::jq('del(.[].movie.rating, .[].movie.genres, .[].movie.trailers)') %>% jqr::jq('del(.[].movie.countries, .[].movie.images)') %>% # jqr::jq('del(.[].schedules[].hall, .[].schedules[].language, .[].schedules[].subtitle)') %>% # jqr::jq('del(.[].cinema.location, .[].cinema.photo, .[].cinema.phones)') %>% jqr::jq('del(.[].cinema.goodies, .[].cinema.subway_stations)') # m2 <- m %>% jqr::jq('[.[] | {date, movie, schedule: .schedules[], cinema}]') df <- fromJSON(m2) %>% as_tibble()
jq sangat elegan dan cepat! Bagi mereka yang relevan: unduh, atur, pahami. Kami mempercepat pemrosesan, kami menyederhanakan hidup untuk diri sendiri dan kolega kami.
Posting sebelumnya - “Bagaimana cara mulai menerapkan R di Enterprise. Contoh pendekatan praktis . "