Pengantar Sistem Operasi
Halo, Habr! Saya ingin menarik perhatian Anda serangkaian artikel-terjemahan dari satu literatur yang menarik menurut saya - OSTEP. Artikel ini membahas lebih dalam karya sistem operasi mirip-unix, yaitu, bekerja dengan proses, berbagai penjadwal, memori, dan komponen serupa lainnya yang membentuk OS modern. Asli semua bahan bisa Anda lihat di
sini . Harap dicatat bahwa terjemahannya dilakukan secara tidak profesional (cukup bebas), tetapi saya harap saya tetap memiliki makna umum.
Pekerjaan laboratorium tentang hal ini dapat ditemukan di sini:
Bagian lain:
Dan Anda dapat melihat saluran saya di
telegram =)
Pengantar Penjadwal
Inti dari masalah: Bagaimana mengembangkan kebijakan perencana
Bagaimana seharusnya kerangka kebijakan penjadwal dasar dikembangkan? Apa yang seharusnya menjadi asumsi utama? Metrik apa yang penting? Apa teknik dasar yang digunakan dalam komputasi awal?Asumsi Beban Kerja
Sebelum membahas kemungkinan kebijakan, sebagai permulaan kami akan membuat beberapa penyederhanaan penyimpangan tentang proses yang berjalan dalam sistem, yang secara kolektif disebut
beban kerja . Dengan mendefinisikan beban kerja sebagai bagian penting dari kebijakan pembangunan dan semakin Anda tahu tentang beban kerja, semakin baik kebijakan yang bisa Anda tulis.
Kami membuat asumsi berikut tentang proses yang berjalan di sistem, kadang-kadang juga disebut
pekerjaan (tugas). Hampir semua asumsi ini tidak realistis, tetapi perlu untuk pengembangan pemikiran.
- Setiap tugas menjalankan jumlah waktu yang sama,
- Semua tugas diatur pada saat yang sama,
- Tugas yang ada sampai selesai,
- Semua tugas hanya menggunakan CPU,
- Waktu berjalan setiap tugas diketahui.
Metrik Penjadwal
Selain beberapa asumsi tentang beban, masih ada kebutuhan untuk beberapa alat untuk membandingkan berbagai kebijakan perencanaan: metrik penjadwal. Metrik hanyalah ukuran dari sesuatu. Ada sejumlah metrik yang dapat digunakan untuk membandingkan perencana.
Misalnya, kami akan menggunakan metrik yang disebut waktu penyelesaian. Waktu penyelesaian tugas didefinisikan sebagai perbedaan antara waktu yang dibutuhkan untuk menyelesaikan tugas dan waktu tugas memasuki sistem.
Tturnaround = Tcompletion - TarrivalKarena kami mengasumsikan bahwa semua tugas tiba pada waktu yang sama, maka Ta = 0 dan dengan demikian Tt = Tc. Nilai ini secara alami akan berubah ketika kita mengubah asumsi di atas.
Metrik lain adalah
keadilan (fairness, honesty). Produktivitas dan kejujuran seringkali berlawanan karakteristik dalam perencanaan. Misalnya, penjadwal dapat mengoptimalkan kinerja, tetapi dengan biaya menunggu tugas lain berjalan, sehingga mengurangi integritas.
PERTOLONGAN PERTAMA (FIFO)
Algoritma paling dasar yang dapat kita implementasikan disebut FIFO atau
first come (in), first served (out) . Algoritma ini memiliki beberapa keunggulan: sangat mudah diterapkan dan cocok dengan semua asumsi kami, melakukan pekerjaan dengan cukup baik.
Pertimbangkan contoh sederhana. Misalkan 3 tugas ditetapkan pada waktu bersamaan. Tapi anggaplah tugas A datang sedikit lebih awal dari yang lain, jadi itu akan ada di daftar eksekusi sebelum yang lain, seperti B relatif terhadap C. Misalkan masing-masing dari mereka membutuhkan waktu 10 detik untuk menyelesaikan. Apa yang akan menjadi waktu rata-rata untuk menyelesaikan tugas-tugas ini?
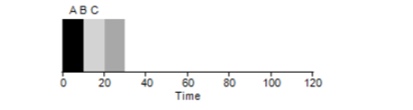
Menghitung nilai - 10 + 20 + 30 dan membaginya dengan 3, kami mendapatkan waktu eksekusi rata-rata program sama dengan 20 detik.
Sekarang mari kita coba mengubah asumsi kita. Khususnya, asumsi 1, dan dengan demikian kita tidak akan lagi menganggap bahwa setiap tugas membutuhkan jumlah waktu yang sama. Bagaimana FIFO akan tampil sendiri kali ini?
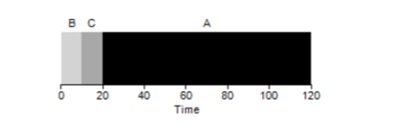
Ternyata, waktu pelaksanaan tugas yang berbeda memiliki dampak yang sangat negatif pada produktivitas algoritma FIFO. Asumsikan bahwa tugas A akan dieksekusi selama 100 detik, sedangkan B dan C masing-masing akan tetap 10.

Seperti dapat dilihat dari gambar, waktu rata-rata untuk sistem adalah (100 + 110 + 120) / 3 = 110. Efek ini disebut
efek konvoi , ketika beberapa konsumen jangka pendek dari suatu sumber daya akan sejalan setelah konsumen yang berat. Itu terlihat seperti garis toko kelontong ketika pelanggan dengan troli penuh ada di depan Anda. Solusi terbaik untuk masalah ini adalah mencoba mengganti kasir atau bersantai dan bernapas dalam-dalam.
Pekerjaan terpendek pertama
Apakah mungkin untuk menyelesaikan situasi yang serupa dengan proses yang berat? Tentu saja Tipe lain dari penjadwalan disebut
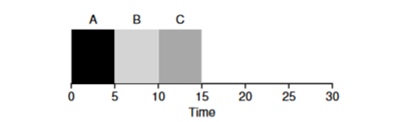
Shortest Job First (SJF). Algoritma ini juga cukup primitif - seperti namanya, tugas terpendek akan diluncurkan satu demi satu.
Dalam contoh ini, hasil dari memulai proses yang sama akan menjadi peningkatan dalam waktu penyelesaian rata-rata dari program dan itu akan menjadi
50 bukannya 110 , yang hampir 2 kali lebih baik.
Dengan demikian, untuk asumsi yang diberikan bahwa semua tugas tiba pada saat yang sama, algoritma SJF tampaknya merupakan algoritma yang paling optimal. Namun, asumsi kami masih tampak tidak realistis. Kali ini, kami mengubah asumsi 2 dan kali ini membayangkan bahwa tugas dapat tetap setiap saat, dan tidak semua pada waktu yang bersamaan. Masalah apa yang bisa menyebabkan ini?

Bayangkan bahwa tugas A (100-an) datang pertama dan mulai dieksekusi. Pada waktu t = 10, tugas B, C tiba, yang masing-masing akan memakan waktu 10 detik. Dengan demikian, waktu eksekusi rata-rata adalah (100+ (110-10) + (120-10)) \ 3 = 103. Apa yang dapat dilakukan perencana untuk memperbaiki situasi?
STCF (Waktu-ke-Penyelesaian) Terpendek Pertama
Untuk memperbaiki situasi, kami menghilangkan asumsi 3 bahwa program sudah berjalan dan berjalan sampai selesai. Selain itu, kami akan memerlukan dukungan perangkat keras, dan seperti yang Anda duga, kami akan menggunakan
timer untuk mengganggu tugas kerja dan
mengubah konteks . Dengan demikian, penjadwal dapat melakukan sesuatu pada saat tugas B dan C tiba - hentikan pelaksanaan tugas A dan letakkan tugas B dan C dalam pemrosesan dan, setelah selesai, lanjutkan proses A. Penjadwal ini disebut
STCF atau
Preemptive Job First .
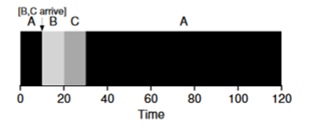
Hasil dari penjadwal ini adalah hasil ini: ((120-0) + (20-10) + (30-10)) / 3 = 50. Dengan demikian, penjadwal seperti itu menjadi lebih optimal untuk tugas kita.
Waktu Respons Metrik
Jadi, jika kita tahu waktu menjalankan tugas dan bahwa tugas-tugas ini hanya menggunakan CPU, STCF akan menjadi solusi terbaik. Dan sekali di hari-hari awal, algoritma ini bekerja dengan cukup baik. Namun, sekarang pengguna menghabiskan sebagian besar waktu di terminal dan mengharapkan interaksi interaktif yang produktif darinya. Maka lahirlah sebuah metrik baru -
waktu respons (response).
Waktu respons dihitung sebagai berikut:
Tresponse = Tfirstrun - TarrivalJadi, untuk contoh sebelumnya, waktu respons adalah sebagai berikut: A = 0, B = 0, B = 10 (abg = 3,33).
Dan ternyata algoritma STCF tidak begitu baik dalam situasi ketika 3 tugas tiba pada saat yang sama - itu harus menunggu sampai tugas-tugas kecil selesai sepenuhnya. Dengan demikian, algoritma ini baik untuk metrik waktu penyelesaian, tetapi buruk untuk metrik interaktivitas. Bayangkan duduk di terminal dalam upaya mengetikkan karakter di editor, Anda harus menunggu lebih dari 10 detik, karena beberapa tugas lain ditempati oleh prosesor. Ini tidak terlalu menyenangkan.
Jadi kita dihadapkan dengan masalah lain - bagaimana kita bisa membuat scheduler yang sensitif terhadap waktu respons?
Round robin
Untuk mengatasi masalah ini, algoritma
Round Robin (RR) dikembangkan. Gagasan dasarnya cukup sederhana: alih-alih memulai tugas hingga selesai, kami akan memulai tugas untuk periode waktu tertentu (disebut kuantum waktu) dan kemudian beralih ke tugas lain dari antrian. Algoritme mengulangi kerjanya sampai semua tugas selesai. Dalam hal ini, waktu menjalankan program harus kelipatan dari waktu setelah timer menghentikan proses. Misalnya, jika timer menghentikan proses setiap x = 10ms, maka ukuran jendela eksekusi proses harus kelipatan 10 dan menjadi 10,20 atau x * 10.
Mari kita lihat sebuah contoh: Tugas ABV tiba secara bersamaan dalam sistem dan masing-masing ingin bekerja selama 5 detik. Algoritma SJF akan menyelesaikan setiap tugas sampai akhir sebelum memulai yang lain. Sebaliknya, algoritma RR dengan jendela peluncuran = 1s akan melalui tugas-tugas sebagai berikut (Gbr. 4.3):
(SJF Lagi (Buruk untuk Waktu Respons)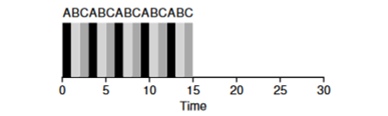 (Round Robin (Baik Untuk Waktu Respons)
(Round Robin (Baik Untuk Waktu Respons)Rata-rata waktu respons untuk algoritma adalah RR (0 + 1 + 2) / 3 = 1, sedangkan untuk SJF (0 + 5 + 10) / 3 = 5.
Adalah logis untuk mengasumsikan bahwa jendela waktu adalah parameter yang sangat penting untuk RR, semakin kecil, semakin tinggi waktu respons. Namun, Anda tidak dapat membuatnya terlalu kecil, karena waktu untuk beralih konteks juga akan memainkan peran dalam kinerja keseluruhan. Dengan demikian, waktu dari jendela eksekusi diatur oleh arsitek OS dan tergantung pada tugas-tugas yang direncanakan untuk dieksekusi di dalamnya. Berpindah konteks bukan satu-satunya operasi layanan yang menghabiskan waktu - program yang berjalan beroperasi dengan lebih banyak, misalnya, berbagai cache, dan setiap kali diperlukan untuk menyimpan dan memulihkan lingkungan ini, yang juga dapat memakan banyak waktu.
RR adalah perencana hebat jika hanya metrik waktu respons. Tetapi bagaimana metrik waktu penyelesaian tugas akan berperilaku dengan algoritma ini? Perhatikan contoh di atas, ketika waktu operasi A, B, C = 5d dan tiba pada waktu yang sama. Tugas A akan berakhir pada 13, B pada 14, C pada 15-an dan waktu penyelesaian rata-rata adalah 14-an. Dengan demikian, RR adalah algoritma terburuk untuk metrik omset.
Lebih umum, algoritma apa pun seperti RR jujur, itu membagi waktu yang dihabiskan untuk CPU secara merata di antara semua proses. Dan dengan demikian, metrik ini terus-menerus bertentangan satu sama lain.
Dengan demikian, kami memiliki beberapa algoritma yang berlawanan dan pada saat yang sama beberapa asumsi tetap - bahwa waktu tugas diketahui dan bahwa tugas hanya menggunakan CPU.
Bercampur dengan I / O
Pertama-tama, kami menghapus asumsi 4 bahwa proses hanya menggunakan CPU, tentu saja tidak demikian, dan proses dapat beralih ke peralatan lain.
Saat proses meminta operasi I / O, proses masuk ke status diblokir, menunggu I / O selesai. Jika I / O dikirim ke hard disk, maka operasi seperti itu dapat memakan waktu hingga beberapa ms atau lebih lama, dan prosesor akan idle pada saat itu. Pada saat ini, penjadwal dapat mengambil alih prosesor dengan proses lainnya. Keputusan berikutnya yang harus dibuat oleh penjadwal adalah ketika proses menyelesaikan I / O-nya. Ketika ini terjadi, interupsi akan terjadi dan OS akan menempatkan proses I / O-calling dalam status siap.
Pertimbangkan contoh beberapa tugas. Masing-masing dari mereka membutuhkan 50ms waktu prosesor. Namun, yang pertama akan mengakses I / O setiap 10 ms (yang juga akan dieksekusi untuk 10 ms). Dan proses B hanya menggunakan prosesor 50ms tanpa I / O.
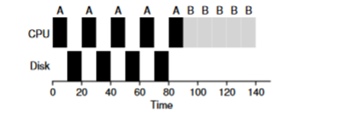
Dalam contoh ini, kita akan menggunakan penjadwal STCF. Bagaimana penjadwal berperilaku jika Anda menjalankan proses seperti A di atasnya? Dia akan melanjutkan sebagai berikut - proses sepenuhnya pertama A, dan kemudian proses B.

Pendekatan tradisional untuk memecahkan masalah ini adalah untuk menafsirkan setiap 10-ms sub-tugas dari proses A sebagai tugas yang terpisah. Jadi, ketika memulai dengan algoritma STJF, pilihan antara tugas 50 ms dan 10 ms jelas. Kemudian, ketika subtugas A selesai, proses B dan I / O akan dimulai. Setelah I / O selesai, akan menjadi kebiasaan untuk memulai proses 10-ms lagi alih-alih proses B. Dengan demikian, dimungkinkan untuk mewujudkan tumpang tindih ketika CPU digunakan oleh proses lain sementara yang pertama sedang menunggu I / O. Dan sebagai hasilnya, sistem lebih baik digunakan - pada saat proses interaktif menunggu I / O, proses lain dapat dijalankan pada prosesor.
Oracle tidak ada lagi
Sekarang mari kita coba untuk menyingkirkan anggapan bahwa waktu tugas diketahui. Ini umumnya asumsi terburuk dan paling tidak realistis dari seluruh daftar. Bahkan, dalam OS standar rata-rata, OS itu sendiri biasanya tahu sedikit tentang waktu yang dibutuhkan untuk menyelesaikan tugas, jadi bagaimana Anda bisa membuat penjadwal tanpa mengetahui berapa lama tugas itu akan berlangsung? Mungkin kita bisa menggunakan beberapa prinsip RR untuk menyelesaikan masalah ini?
Ringkasan
Kami memeriksa ide-ide dasar perencanaan tugas dan meninjau 2 keluarga perencana. Yang pertama memulai tugas terpendek di awal dan dengan demikian meningkatkan waktu penyelesaian, yang kedua terpecah antara semua tugas secara sama, meningkatkan waktu respons. Kedua algoritma buruk di mana algoritma keluarga lainnya baik. Kami juga melihat bagaimana penggunaan paralel CPU dan I / O dapat meningkatkan kinerja, tetapi tidak memecahkan masalah dengan clairvoyance dari OS. Dan dalam pelajaran berikutnya, kita akan mempertimbangkan seorang perencana yang melihat ke masa lalu dekat dan mencoba untuk memprediksi masa depan. Dan itu disebut antrian umpan balik multi-level.