Halo Nama saya Ibadov Ilkin, saya mahasiswa Universitas Federal Ural.
Dalam artikel ini saya ingin berbicara tentang pengalaman saya dengan solusi otomatis untuk captcha Google - "reCAPTCHA". Saya ingin memperingatkan pembaca sebelumnya bahwa pada saat penulisan artikel, prototipe tidak berfungsi seefisien mungkin dari judulnya, namun, hasilnya menunjukkan bahwa pendekatan yang diterapkan mampu menyelesaikan masalah.
Mungkin setiap orang dalam hidup mereka telah menemukan captcha: masukkan teks dari gambar, pecahkan persamaan sederhana atau persamaan rumit, pilih mobil, hidran, penyeberangan pejalan kaki ... Diperlukan sumber daya dari sistem otomatis dan memainkan peran penting dalam keamanan: captcha melindungi terhadap serangan DDoS , pendaftaran dan posting otomatis, penguraian, mencegah pemilihan spam dan kata sandi untuk akun.
 Formulir pendaftaran "Habré" bisa dengan captcha seperti itu.
Formulir pendaftaran "Habré" bisa dengan captcha seperti itu.Dengan perkembangan teknologi pembelajaran mesin, kinerja captcha mungkin berisiko. Pada artikel ini, saya menjelaskan poin-poin utama dari suatu program yang dapat memecahkan masalah memilih gambar secara manual di Google reCAPTCHA (untungnya, tidak selalu sejauh ini).
Untuk melewati captcha, perlu untuk memecahkan masalah seperti: menentukan kelas captcha yang diperlukan, mendeteksi dan mengklasifikasikan objek, mendeteksi sel-sel captcha, mensimulasikan aktivitas manusia dalam menyelesaikan captcha (gerakan kursor, klik).
Untuk mencari objek dalam suatu gambar, digunakan jaringan saraf terlatih yang dapat diunduh ke komputer dan mengenali objek dalam gambar atau video. Tetapi untuk menyelesaikan captcha, hanya mendeteksi objek saja tidak cukup: Anda perlu menentukan posisi sel dan mencari sel mana yang ingin Anda pilih (atau tidak memilih sel sama sekali). Untuk ini, alat visi komputer digunakan: dalam karya ini, ini adalah
perpustakaan OpenCV yang terkenal.
Untuk menemukan objek dalam gambar, pertama-tama, gambar itu sendiri diperlukan. Saya mendapatkan tangkapan layar bagian layar menggunakan modul
PyAutoGUI dengan dimensi yang cukup untuk mendeteksi objek. Di sisa layar, saya menampilkan windows untuk debugging dan memonitor proses program.
Deteksi Objek
Deteksi dan klasifikasi objek adalah apa yang dilakukan jaringan saraf. Perpustakaan yang memungkinkan kita untuk bekerja dengan jaringan saraf disebut "
Tensorflow " (dikembangkan oleh Google). Saat ini,
ada banyak model terlatih untuk pilihan Anda
pada data yang berbeda , yang berarti bahwa semuanya dapat mengembalikan hasil deteksi yang berbeda: beberapa model akan lebih baik mendeteksi objek, dan beberapa lebih buruk.
Dalam tulisan ini, saya menggunakan model ssd_mobilenet_v1_coco. Model yang dipilih dilatih pada dataset
COCO , yang menyoroti 90 kelas yang berbeda (dari orang dan mobil hingga sikat gigi dan sisir). Sekarang ada model lain yang dilatih pada data yang sama, tetapi dengan parameter berbeda. Selain itu, model ini memiliki parameter kinerja dan akurasi yang optimal, yang penting untuk komputer desktop. Sumber tersebut mengatakan bahwa waktu pemrosesan untuk satu bingkai 300 x 300 piksel adalah 30 milidetik. Pada "Nvidia GeForce GTX TITAN X".
Hasil dari jaringan saraf adalah satu set array:
- dengan daftar kelas objek yang terdeteksi (pengidentifikasi mereka);
- dengan daftar peringkat objek yang terdeteksi (dalam persen);
- dengan daftar koordinat objek yang terdeteksi ("kotak").
Indeks elemen-elemen dalam array ini bersesuaian satu sama lain, yaitu: elemen ketiga dalam array kelas objek sesuai dengan elemen ketiga dalam array "kotak" objek yang terdeteksi dan elemen ketiga dalam array peringkat objek.
 Model yang dipilih memungkinkan Anda mendeteksi objek dari 90 kelas secara real time.
Model yang dipilih memungkinkan Anda mendeteksi objek dari 90 kelas secara real time.Deteksi sel
"OpenCV" memberi kita kemampuan untuk beroperasi dengan entitas yang disebut "
sirkuit ": Mereka hanya dapat dideteksi oleh fungsi "findContours ()" dari perpustakaan "OpenCV". Adalah perlu untuk mengirimkan gambar biner ke input dari fungsi seperti itu, yang dapat diperoleh
oleh fungsi transformasi ambang batas :
_retval, binImage = cv2.threshold(image,254,255,cv2.THRESH_BINARY) contours = cv2.findContours(binImage, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)[0]
Setelah menetapkan nilai ekstrim dari parameter fungsi transformasi ambang, kami juga menyingkirkan berbagai jenis kebisingan. Juga, untuk meminimalkan jumlah elemen kecil dan kebisingan yang tidak perlu,
transformasi morfologis dapat diterapkan: fungsi erosi (kompresi) dan penumpukan (ekspansi). Fungsi-fungsi ini juga merupakan bagian dari OpenCV. Setelah transformasi, kontur dipilih dengan jumlah simpul empat (setelah sebelumnya melakukan fungsi
perkiraan pada kontur).
 Di jendela pertama, hasil transformasi ambang batas. Yang kedua adalah contoh transformasi morfologis. Di jendela ketiga, sel dan tutup captcha sudah dipilih: disorot dalam warna secara terprogram.
Di jendela pertama, hasil transformasi ambang batas. Yang kedua adalah contoh transformasi morfologis. Di jendela ketiga, sel dan tutup captcha sudah dipilih: disorot dalam warna secara terprogram.Setelah semua transformasi, kontur yang bukan sel masih termasuk dalam array terakhir dengan sel. Untuk menyaring suara yang tidak perlu, saya memilih sesuai dengan nilai panjang (perimeter) dan luas kontur.
Secara eksperimental terungkap bahwa nilai-nilai sirkuit yang menarik berada di kisaran 360 hingga 900 unit. Nilai ini dipilih pada layar dengan diagonal 15,6 inci dan resolusi 1366 x 768 piksel. Selanjutnya, nilai yang ditunjukkan dari kontur dapat dihitung tergantung pada ukuran layar pengguna, tetapi tidak ada tautan seperti itu dalam prototipe yang dibuat.
Keuntungan utama dari pendekatan yang dipilih untuk mendeteksi sel adalah bahwa kami tidak peduli seperti apa tampilan grid dan berapa banyak sel yang akan ditampilkan pada halaman captcha: 8, 9 atau 16.
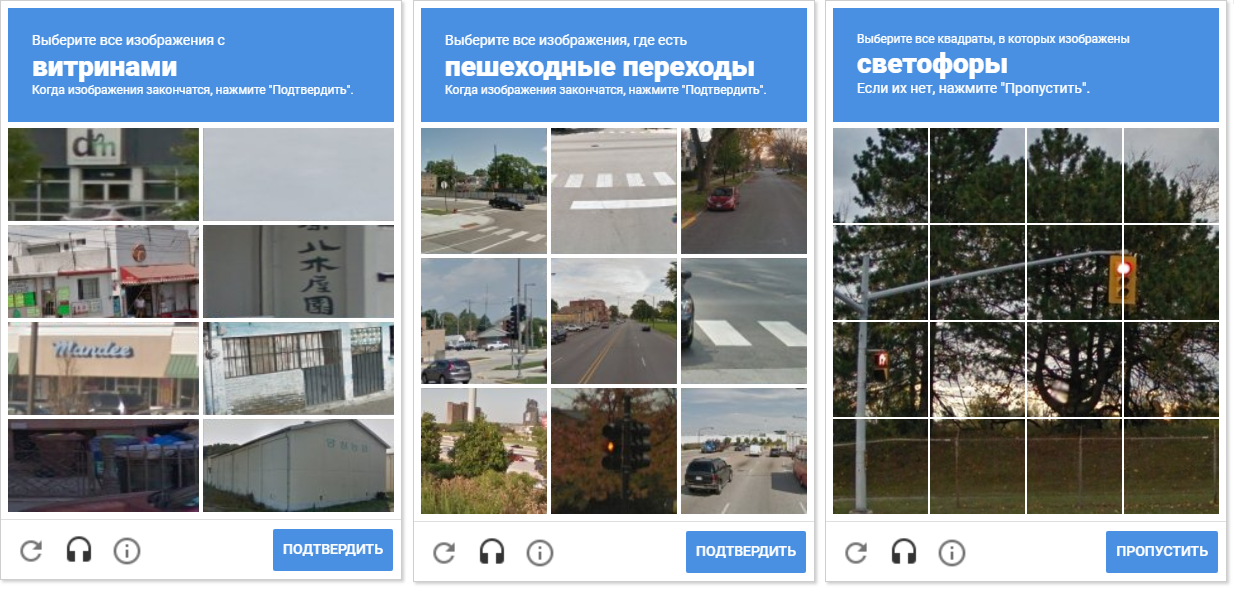 Gambar menunjukkan berbagai jaring captcha. Harap perhatikan bahwa jarak antar sel berbeda. Untuk memisahkan sel dari satu sama lain memungkinkan kompresi morfologis.
Gambar menunjukkan berbagai jaring captcha. Harap perhatikan bahwa jarak antar sel berbeda. Untuk memisahkan sel dari satu sama lain memungkinkan kompresi morfologis.Keuntungan tambahan mendeteksi kontur adalah bahwa OpenCV memungkinkan kita untuk mendeteksi pusatnya (kita perlu mereka menentukan koordinat pergerakan dan klik mouse).
Memilih sel untuk dipilih
Memiliki array dengan kontur yang bersih dari sel CAPTCHA tanpa sirkuit noise yang tidak perlu, kita dapat menggilir setiap sel CAPTCHA ("sirkuit" dalam terminologi "OpenCV") dan memeriksa apakah itu berpotongan dengan "kotak" yang terdeteksi dari objek yang diterima dari jaringan saraf.
Untuk menetapkan fakta ini, transfer "kotak" yang terdeteksi ke sirkuit yang mirip dengan sel digunakan. Tetapi pendekatan ini ternyata salah, karena kasus ketika objek berada di dalam sel tidak dianggap persimpangan. Secara alami, sel-sel tersebut tidak menonjol dalam captcha.
Masalahnya dipecahkan dengan menggambar ulang garis besar setiap sel (dengan isian putih) ke lembaran hitam. Dengan cara yang sama, gambar biner dari sebuah bingkai dengan objek diperoleh. Timbul pertanyaan - bagaimana sekarang untuk menetapkan fakta dari persimpangan sel dengan bingkai objek yang diarsir? Dalam setiap iterasi array dengan sel, operasi disjungsi (logis atau) dilakukan pada dua gambar biner. Sebagai hasilnya, kami mendapatkan gambar biner baru di mana area berpotongan akan disorot. Artinya, jika ada area seperti itu, maka sel dan bingkai objek bersinggungan. Secara pemrograman, pemeriksaan semacam itu dapat dilakukan dengan menggunakan metode "
.any () ": ia akan mengembalikan "True" jika array memiliki setidaknya satu elemen sama dengan satu atau "False" jika tidak ada unit.
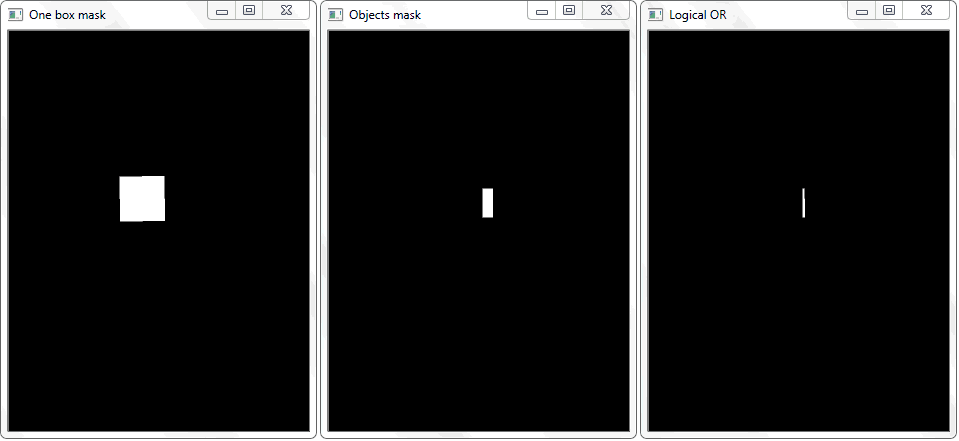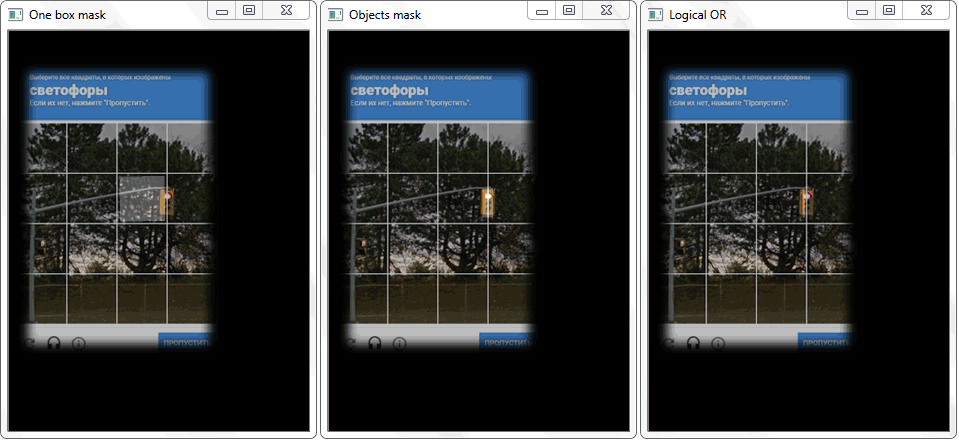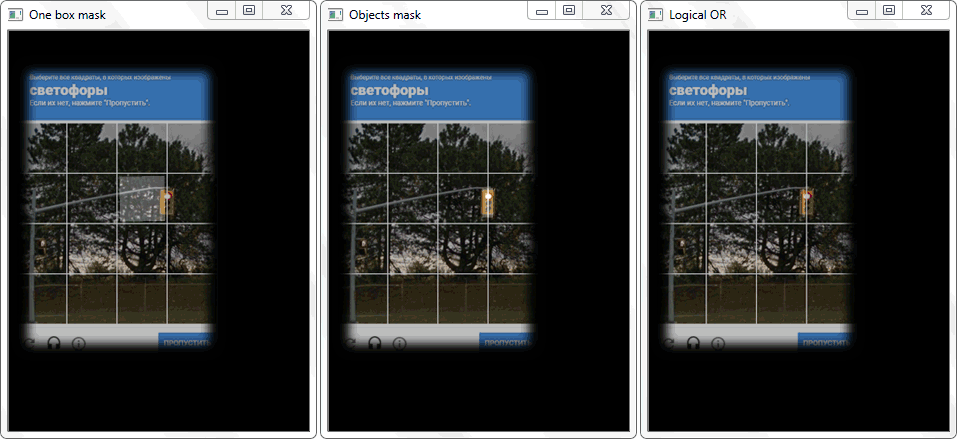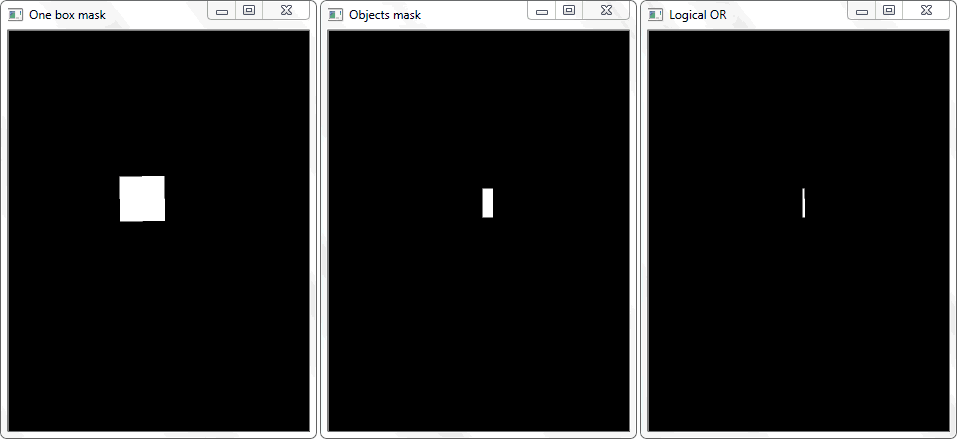 Fungsi "any ()" untuk gambar "Logical OR" dalam kasus ini akan kembali benar dan dengan demikian menetapkan fakta persimpangan sel dengan area bingkai objek yang terdeteksi.
Fungsi "any ()" untuk gambar "Logical OR" dalam kasus ini akan kembali benar dan dengan demikian menetapkan fakta persimpangan sel dengan area bingkai objek yang terdeteksi.Manajemen
Kontrol kursor dalam "Python" tersedia berkat modul "win32api" (namun, ternyata "PyAutoGUI" yang sudah diimpor ke proyek juga tahu bagaimana melakukan ini). Menekan dan melepaskan tombol kiri mouse, serta menggerakkan kursor ke koordinat yang diinginkan, dilakukan oleh fungsi yang sesuai dari modul win32api. Tetapi dalam prototipe, mereka dibungkus dengan fungsi yang ditentukan pengguna untuk memberikan pengamatan visual dari pergerakan kursor. Ini berdampak negatif pada kinerja dan hanya diterapkan untuk demonstrasi.
Selama proses pengembangan, muncul ide untuk memilih sel secara acak. Ada kemungkinan bahwa ini tidak masuk akal secara praktis (untuk alasan yang jelas, Google tidak memberi kami komentar dan deskripsi tentang mekanisme operasi captcha), tetapi memindahkan kursor melalui sel-sel dalam cara yang kacau terlihat lebih menyenangkan.
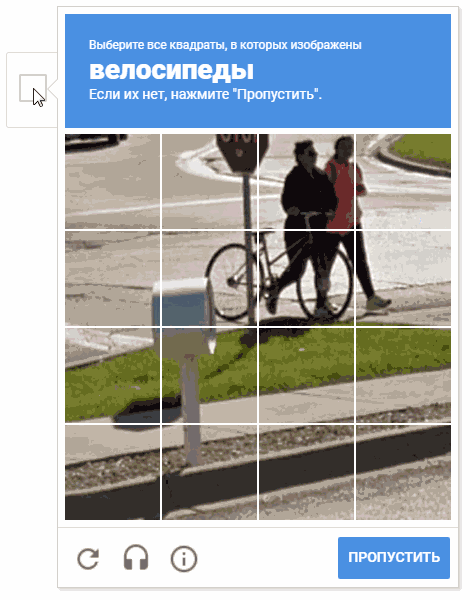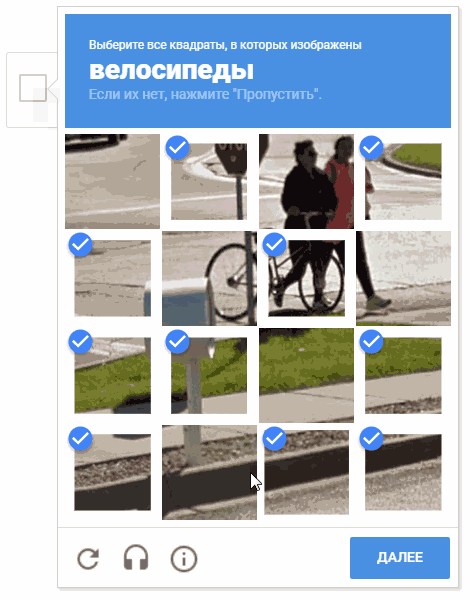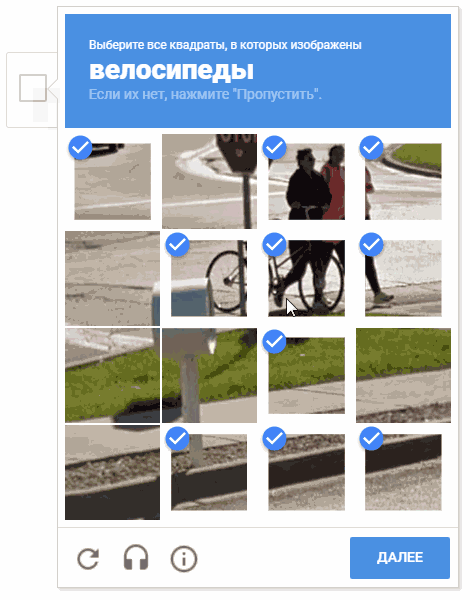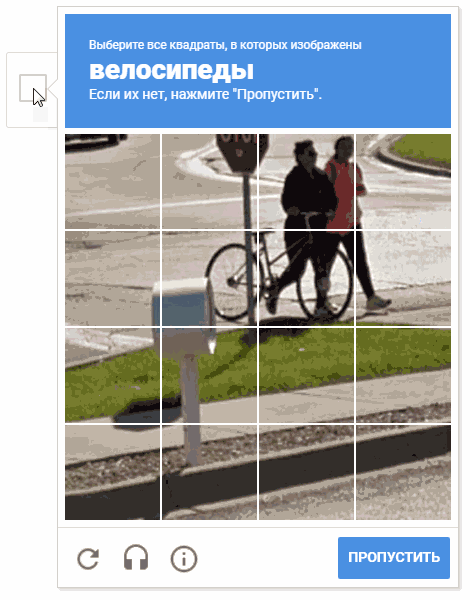 Pada animasi, hasilnya adalah "random.shuffle (boxesForSelect)".
Pada animasi, hasilnya adalah "random.shuffle (boxesForSelect)".Pengenalan teks
Untuk menggabungkan semua perkembangan yang tersedia menjadi satu keseluruhan, diperlukan satu tautan lagi: unit pengenalan untuk kelas yang diperlukan dari captcha. Kami sudah tahu cara mengenali dan membedakan berbagai objek dalam gambar, kami dapat mengeklik sel captcha yang sewenang-wenang, tetapi kami tidak tahu sel mana yang harus diklik. Salah satu cara untuk mengatasi masalah ini adalah mengenali teks dari heading captcha. Pertama-tama, saya mencoba menerapkan pengenalan teks menggunakan alat pengenalan karakter optik "
Tesseract-OCR ".
Dalam versi terbaru, adalah mungkin untuk menginstal paket bahasa langsung di jendela installer (sebelumnya ini dilakukan secara manual). Setelah menginstal dan mengimpor Tesseract-OCR ke proyek saya, saya mencoba mengenali teks dari header captcha.
Hasilnya, sayangnya, tidak membuat saya terkesan sama sekali. Saya memutuskan bahwa teks di header disorot dalam huruf tebal dan digabung karena suatu alasan, jadi saya mencoba menerapkan berbagai transformasi pada gambar: binarisasi, penyempitan, ekspansi, pengaburan, distorsi, dan operasi pengubahan ukuran. Sayangnya, ini tidak memberikan hasil yang baik: dalam kasus terbaik, hanya sebagian dari surat kelas ditentukan, dan ketika hasilnya memuaskan, saya menerapkan transformasi yang sama, tetapi untuk penutup lainnya (dengan teks berbeda), dan hasilnya ternyata buruk lagi.
 Pengakuan topi Tesseract-OCR biasanya menyebabkan hasil yang tidak memuaskan.
Pengakuan topi Tesseract-OCR biasanya menyebabkan hasil yang tidak memuaskan.Tidak mungkin untuk mengatakan dengan tegas bahwa "Tesseract-OCR" tidak mengenali teks dengan baik, ini tidak begitu: alat mengatasi dengan gambar lain (bukan topi captcha) jauh lebih baik.
Saya memutuskan untuk menggunakan layanan pihak ketiga yang menawarkan API untuk bekerja dengannya secara gratis (diperlukan pendaftaran dan penerimaan kunci ke alamat email). Layanan ini memiliki batas 500 pengakuan per hari, tetapi untuk seluruh periode pengembangan saya tidak mengalami masalah dengan keterbatasan. Sebaliknya: saya mengirimkan gambar asli dari header ke layanan (tanpa menerapkan transformasi apa pun) dan hasilnya membuat saya terkesan.
Kata-kata dari layanan dikembalikan praktis tanpa kesalahan (biasanya bahkan yang ditulis dalam cetakan kecil). Selain itu, mereka kembali dalam format yang sangat mudah - dipecah oleh garis dengan karakter pemecah baris. Dalam semua gambar, saya hanya tertarik pada baris kedua, jadi saya langsung mengaksesnya. Ini tidak bisa tidak bersukacita, karena format seperti itu membebaskan saya dari kebutuhan untuk mempersiapkan sebuah baris: Saya tidak harus memotong awal atau akhir dari keseluruhan teks, melakukan "trim", penggantian, bekerja dengan ekspresi reguler dan melakukan operasi lain pada baris, yang bertujuan menyoroti satu kata (dan terkadang dua!) - bonus bagus!
text = serviceResponse['ParsedResults'][0]['ParsedText']
Layanan yang mengenali teks hampir tidak pernah membuat kesalahan dengan nama kelas, tetapi saya masih memutuskan untuk meninggalkan sebagian nama kelas untuk kemungkinan kesalahan. Ini opsional, tetapi saya perhatikan bahwa “Tesseract-OCR” dalam beberapa kasus salah mengenali ujung kata yang dimulai dari tengah. Selain itu, pendekatan ini menghilangkan kesalahan aplikasi dalam kasus nama kelas panjang atau nama dua kata (dalam hal ini, layanan akan mengembalikan bukan 3, tetapi 4 baris, dan saya tidak dapat menemukan nama lengkap kelas di baris kedua).
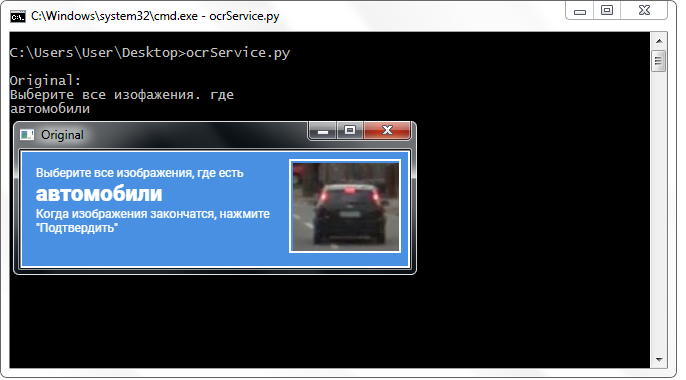 Layanan pihak ketiga mengenali nama kelas dengan baik tanpa ada transformasi atas gambar.
Layanan pihak ketiga mengenali nama kelas dengan baik tanpa ada transformasi atas gambar.Penggabungan
Mendapatkan teks dari header tidak cukup. Ini perlu dibandingkan dengan pengidentifikasi kelas model yang tersedia, karena dalam array kelas jaringan saraf mengembalikan persis pengenal kelas, dan bukan namanya, seperti yang terlihat. Ketika melatih model, sebagai aturan, file dibuat di mana nama kelas dan pengidentifikasi mereka dibandingkan (alias "label peta"). Saya memutuskan untuk melakukannya dengan lebih mudah dan menentukan pengidentifikasi kelas secara manual, karena captcha masih membutuhkan kelas dalam bahasa Rusia (omong-omong, ini dapat diubah):
if "" in query:
Semua yang dijelaskan di atas direproduksi dalam siklus utama program: bingkai objek, sel, persimpangan ditentukan, kursor bergerak dan klik. Saat header terdeteksi, pengenalan teks dilakukan. Jika jaringan saraf tidak dapat mendeteksi kelas yang diperlukan, maka pergeseran sewenang-wenang dari gambar dilakukan hingga 5 kali (yaitu, input ke jaringan saraf diubah), dan jika deteksi masih tidak terjadi, maka tombol "Lewati / Konfirmasi" diklik (posisinya dideteksi dengan cara yang sama mendeteksi sel dan tutup).
Jika Anda sering memecahkan captcha, Anda bisa mengamati gambar ketika sel yang dipilih menghilang, dan yang baru perlahan-lahan muncul di tempatnya. Karena prototipe diprogram untuk langsung pergi ke halaman berikutnya setelah memilih semua sel, saya memutuskan untuk membuat jeda 3 detik untuk mengecualikan mengklik tombol "Next" tanpa mendeteksi objek pada sel yang muncul perlahan.
Artikel tidak akan lengkap jika tidak mengandung deskripsi hal yang paling penting - tanda centang untuk berhasil melewati captcha. Saya memutuskan bahwa
perbandingan templat sederhana dapat melakukan ini. Perlu dicatat bahwa pencocokan pola jauh dari cara terbaik untuk mendeteksi objek. Sebagai contoh, saya harus mengatur sensitivitas deteksi ke "0,01" sehingga fungsi berhenti melihat kutu dalam segala hal, tetapi melihatnya ketika benar-benar ada kutu. Demikian pula, saya bertindak dengan kotak centang kosong yang memenuhi pengguna dan dari mana captcha dimulai (tidak ada masalah dengan sensitivitas).
Hasil
Hasil dari semua tindakan yang dijelaskan adalah aplikasi, kinerja yang saya uji pada "
Pemanggang Roti ":
Perlu diakui bahwa video tidak direkam pada percobaan pertama, karena saya sering dihadapkan dengan kebutuhan untuk memilih kelas yang tidak ada dalam model (misalnya, penyeberangan pejalan kaki, tangga atau jendela toko).
“Google reCAPTCHA” mengembalikan nilai tertentu ke situs, menunjukkan bagaimana “Anda adalah robot”, dan administrator situs, pada gilirannya, dapat menetapkan ambang batas untuk meneruskan nilai ini. Ada kemungkinan bahwa ambang captcha yang relatif rendah ditetapkan pada Pemanggang. Ini menjelaskan jalan yang agak mudah dari captcha oleh program, meskipun faktanya salah dua kali, tidak melihat lampu lalu lintas dari halaman pertama dan hidran dari halaman keempat captcha.
Selain pemanggang roti, percobaan dilakukan pada
halaman demo resmi
reCAPTCHA . Akibatnya, diketahui bahwa setelah beberapa deteksi salah (dan non-deteksi), mendapatkan captcha menjadi sangat sulit bahkan untuk seseorang: kelas baru diperlukan (seperti traktor dan pohon palem), sel tanpa objek muncul dalam sampel (warna hampir monoton) dan jumlah halaman meningkat secara dramatis, untuk melewati.
Ini terutama terlihat ketika saya memutuskan untuk mencoba mengklik pada sel-sel acak dalam kasus non-deteksi objek (karena mereka tidak ada dalam model). Karena itu, kami dapat mengatakan dengan pasti bahwa klik acak tidak akan mengarah ke solusi untuk masalah tersebut. Untuk menghilangkan "penyumbatan" semacam itu oleh pemeriksa, kami menghubungkan kembali koneksi Internet dan membersihkan data peramban, karena menjadi tidak mungkin untuk lulus tes semacam itu - hampir tidak ada habisnya!
 Jika Anda meragukan kemanusiaan Anda, hasil seperti itu mungkin terjadi.
Jika Anda meragukan kemanusiaan Anda, hasil seperti itu mungkin terjadi.Pengembangan
Jika artikel dan aplikasi tersebut membangkitkan minat pembaca, saya dengan senang hati akan melanjutkan penerapannya, pengujian dan uraian lebih lanjut dalam bentuk yang lebih terperinci.
Ini adalah tentang menemukan kelas yang bukan bagian dari jaringan saat ini, ini akan sangat meningkatkan efisiensi aplikasi. Saat ini, ada kebutuhan mendesak untuk mengenali setidaknya kelas-kelas seperti: perlintasan pejalan kaki, jendela toko, dan cerobong asap - saya akan memberi tahu Anda cara melatih ulang model. Selama pengembangan, saya membuat daftar pendek dari kelas yang paling umum:
- penyeberangan pejalan kaki;
- hidran api;
- jendela toko
- cerobong asap;
- mobil;
- Bus
- lampu lalu lintas;
- sepeda
- sarana transportasi;
- tangga
- tanda-tanda.
Meningkatkan kualitas deteksi objek dapat dicapai dengan menggunakan beberapa model secara bersamaan: ini dapat menurunkan kinerja, tetapi meningkatkan akurasi.
Cara lain untuk meningkatkan kualitas deteksi objek adalah dengan mengubah input gambar ke jaringan saraf: dalam video, Anda dapat melihat bahwa ketika objek tidak terdeteksi, saya melakukan perpindahan gambar acak beberapa kali (dalam 10 piksel secara horizontal dan vertikal), dan seringkali operasi ini memungkinkan Anda melihat objek yang sebelumnya tidak terdeteksi.
Peningkatan gambar dari kotak kecil ke kotak besar (hingga 300 x 300 piksel) juga mengarah pada deteksi objek yang tidak terdeteksi.
 Tidak ada benda yang ditemukan di sebelah kiri: kotak asli dengan sisi 100 piksel. Di sebelah kanan, bus terdeteksi: kotak yang diperbesar hingga 300 x 300 piksel.
Tidak ada benda yang ditemukan di sebelah kiri: kotak asli dengan sisi 100 piksel. Di sebelah kanan, bus terdeteksi: kotak yang diperbesar hingga 300 x 300 piksel.Transformasi lain yang menarik adalah penghapusan grid putih di atas gambar menggunakan alat OpenCV: ada kemungkinan hidran tidak terdeteksi dalam video karena alasan ini (kelas ini hadir dalam jaringan saraf).
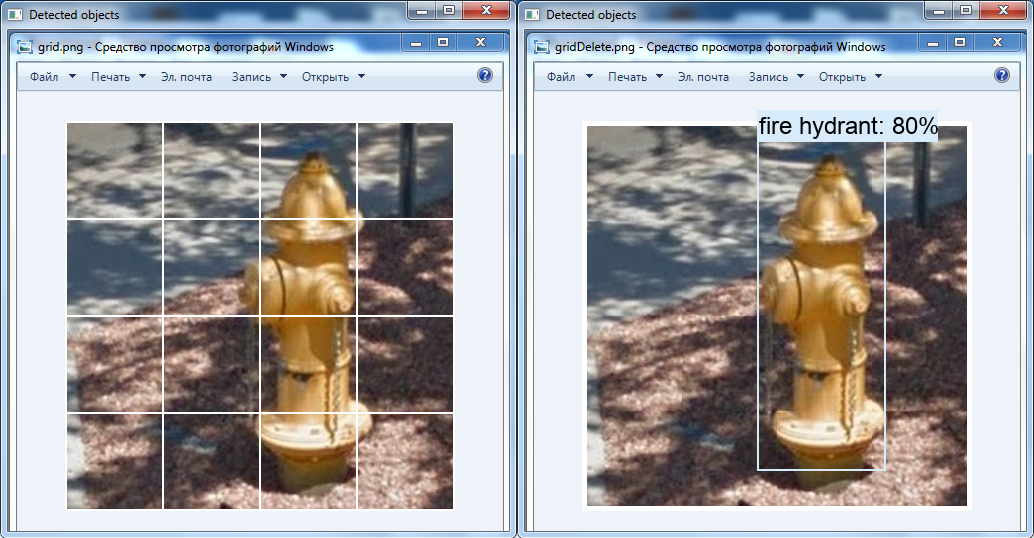 Di sebelah kiri adalah gambar asli, dan di sebelah kanan adalah gambar yang diubah dalam editor grafik: kisi dihapus, sel-sel dipindahkan satu sama lain.
Di sebelah kiri adalah gambar asli, dan di sebelah kanan adalah gambar yang diubah dalam editor grafik: kisi dihapus, sel-sel dipindahkan satu sama lain.Ringkasan
Dengan artikel ini, saya ingin memberi tahu Anda bahwa captcha mungkin bukan perlindungan terbaik terhadap bot, dan sangat mungkin bahwa dalam waktu dekat akan ada kebutuhan akan sarana perlindungan baru terhadap sistem otomatis.
Prototipe yang dikembangkan, bahkan dalam keadaan belum selesai, menunjukkan bahwa dengan kelas yang diperlukan dalam model jaringan saraf dan menerapkan transformasi pada gambar, dimungkinkan untuk mencapai otomatisasi proses yang tidak boleh otomatis.
Juga, saya ingin menarik perhatian Google pada fakta bahwa selain metode untuk menghindari captcha yang dijelaskan dalam artikel ini, ada juga
cara lain di mana sampel audio
ditranskripsikan . Menurut pendapat saya, sekarang perlu untuk mengambil langkah-langkah yang berkaitan dengan peningkatan kualitas produk perangkat lunak dan algoritma terhadap robot.
Dari isi dan esensi materi, sepertinya saya tidak suka Google dan, khususnya, reCAPTCHA, tetapi ini jauh dari kasus, dan jika ada implementasi berikutnya, saya akan memberi tahu Anda alasannya.
Dikembangkan dan diperagakan untuk meningkatkan pendidikan dan meningkatkan metode yang bertujuan untuk memastikan keamanan informasi.
Terima kasih atas perhatian anda