Sejarah VKontakte ada di Wikipedia, demikian diceritakan oleh Pavel sendiri. Tampaknya semua orang sudah mengenalnya. Pavel
berbicara tentang bagian dalam, arsitektur dan desain situs di HighLoad ++
kembali pada tahun 2010 . Banyak server telah bocor sejak itu, jadi kami akan memperbarui informasi: kami membedah, mengeluarkan bagian dalamnya, menimbang - kami melihat perangkat VK dari sudut pandang teknis.
 Alexey Akulovich
Alexey Akulovich (
AterCattus ) adalah pengembang backend di tim VKontakte. Transkrip dari laporan ini adalah jawaban kolektif untuk pertanyaan yang sering diajukan tentang pengoperasian platform, infrastruktur, server dan interaksi di antara mereka, tetapi bukan tentang pengembangan, yaitu
tentang perangkat keras . Secara terpisah - tentang basis data dan apa yang dimiliki VK di tempatnya, tentang pengumpulan log dan pemantauan seluruh proyek secara keseluruhan. Detail di bawah potongan.
Selama lebih dari empat tahun saya telah melakukan semua jenis tugas yang berkaitan dengan backend.
- Unduh, penyimpanan, pemrosesan, distribusi media: video, streaming langsung, audio, foto, dokumen.
- Infrastruktur, platform, pemantauan pengembang, log, cache regional, CDN, protokol RPC eksklusif.
- Integrasi dengan layanan eksternal: push mailing, parsing tautan eksternal, umpan RSS.
- Bantu kolega dalam berbagai masalah, untuk jawaban yang harus Anda masukkan ke dalam kode yang tidak dikenal.
Selama ini, saya punya banyak komponen di situs ini. Saya ingin berbagi pengalaman ini.
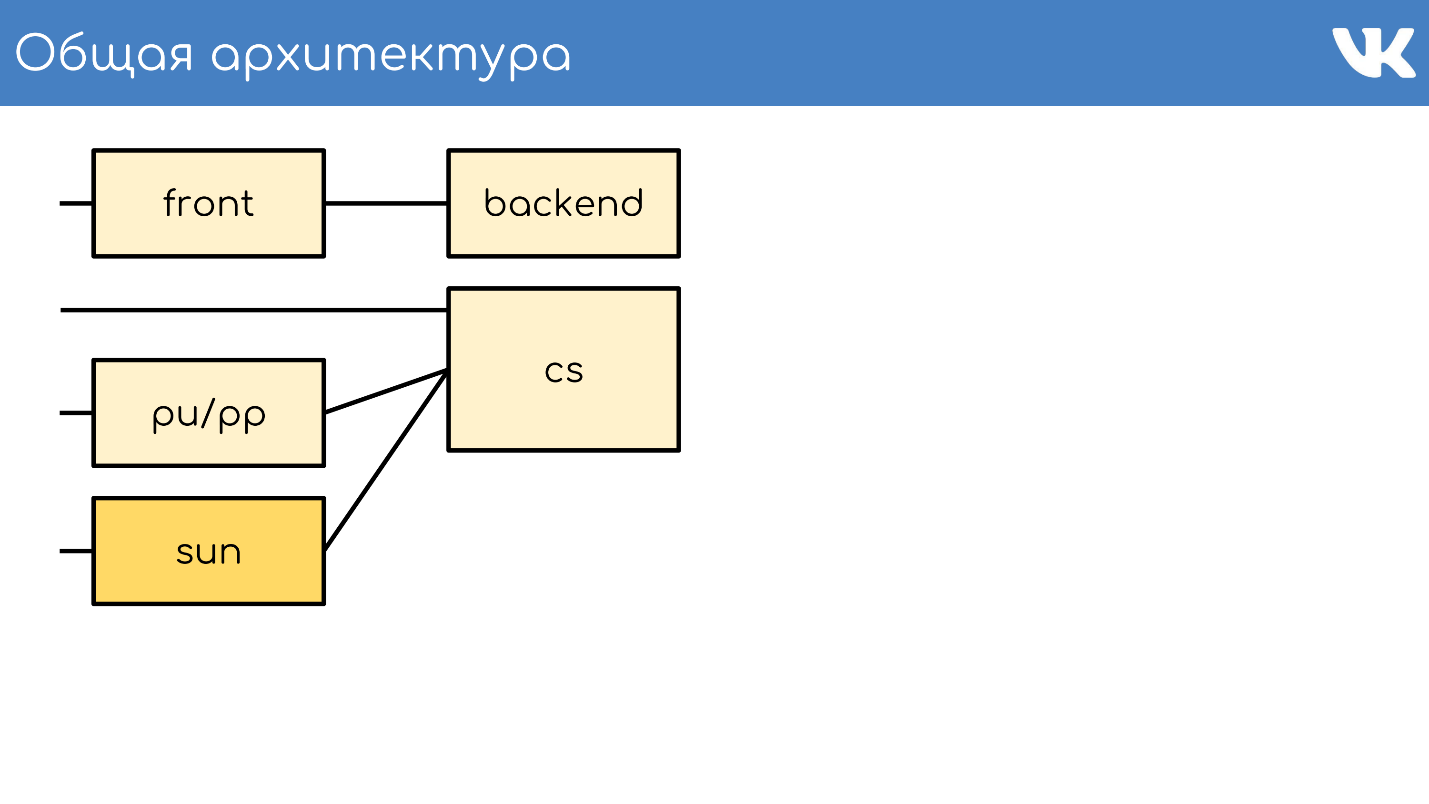
Arsitektur umum
Semuanya, seperti biasa, dimulai dengan server atau sekelompok server yang menerima permintaan.
Server depan
Server depan menerima permintaan melalui HTTPS, RTMP, dan WSS.
HTTPS adalah permintaan untuk versi web utama dan seluler dari situs: vk.com dan m.vk.com, dan klien resmi dan tidak resmi dari API kami: klien seluler, pengirim pesan instan. Kami memiliki lalu lintas
RTMP untuk siaran langsung dengan server depan yang terpisah dan koneksi
WSS untuk Streaming API.
Untuk HTTPS dan WSS,
nginx diinstal pada server. Untuk siaran RTMP, kami baru-baru ini beralih ke solusi
kive kami sendiri, tetapi itu berada di luar cakupan laporan. Untuk toleransi kesalahan, server ini mengumumkan alamat IP umum dan bertindak sebagai grup sehingga jika terjadi masalah pada salah satu server, permintaan pengguna tidak hilang. Untuk HTTPS dan WSS, server yang sama ini mengenkripsi lalu lintas untuk mengambil bagian dari beban CPU sendiri.
Lebih lanjut kami tidak akan berbicara tentang WSS dan RTMP, tetapi hanya tentang permintaan standar HTTPS, yang biasanya terkait dengan proyek web.
Backend
Di belakang bagian depan biasanya server backend. Mereka menangani permintaan yang diterima server depan dari klien.
Ini adalah
server kPHP yang menjalankan daemon HTTP karena HTTPS sudah didekripsi. kPHP adalah server yang bekerja sesuai dengan
model prefork : memulai proses master, sekelompok proses anak, melewati soket mendengarkan kepada mereka dan mereka memproses permintaan mereka. Pada saat yang sama, proses tidak dimulai ulang antara setiap permintaan dari pengguna, tetapi cukup mengatur ulang negara mereka ke keadaan nol nilai awal - permintaan dengan permintaan, alih-alih memulai kembali.
Muat pembagian
Semua backend kami bukanlah kumpulan besar mesin yang dapat menangani permintaan apa pun. Kami
membaginya menjadi beberapa kelompok : umum, seluler, api, video, pementasan ... Masalah pada kelompok mesin yang berbeda tidak akan memengaruhi orang lain. Jika ada masalah dengan video, pengguna yang mendengarkan musik bahkan tidak tahu tentang masalahnya. Backend untuk mengirim permintaan ke diselesaikan oleh nginx di bagian depan dalam konfigurasi.
Pengumpulan dan penyeimbangan metrik
Untuk memahami berapa banyak mobil yang Anda butuhkan di setiap grup, kami
tidak mengandalkan QPS . Backend berbeda, mereka memiliki permintaan yang berbeda, setiap permintaan memiliki kompleksitas penghitungan QPS yang berbeda. Oleh karena itu, kami menggunakan
konsep beban di server secara keseluruhan - pada CPU dan perf .
Kami memiliki ribuan server seperti itu. Grup kPHP berjalan pada setiap server fisik untuk memanfaatkan semua kernel (karena kPHP adalah single-threaded).
Server konten
CS atau Server Konten adalah penyimpanan . CS adalah server yang menyimpan file, dan juga memproses file yang diunggah, semua jenis tugas latar belakang sinkron yang diajukan oleh frontend web utama untuk itu.
Kami memiliki puluhan ribu server fisik yang menyimpan file. Pengguna suka mengunggah file, dan kami senang menyimpan dan membagikannya. Beberapa server ini ditutup oleh server pu / pp khusus.
pu / pp
Jika Anda membuka tab jaringan di VK, maka Anda melihat pu / pp.

Apa itu pu / pp? Jika kami menutup satu server demi satu, maka ada dua opsi untuk mengunggah dan mengunduh file ke server yang ditutup:
langsung melalui
http://cs100500.userapi.com/path atau
melalui server perantara -
http://pu.vk.com/c100500/path .
Pu adalah nama historis untuk unggahan foto, dan pp adalah proxy foto . Yaitu, satu server untuk mengunggah foto, dan lainnya - untuk diberikan. Sekarang tidak hanya foto yang dimuat, tetapi nama telah disimpan.
Server-server ini
menghentikan sesi HTTPS untuk menghapus beban prosesor dari penyimpanan. Juga, karena file pengguna diproses pada server ini, informasi yang kurang sensitif disimpan pada mesin ini, semakin baik. Misalnya, kunci enkripsi HTTPS.
Karena mesin ditutup oleh mesin kami yang lain, kami tidak dapat memberi mereka IP eksternal "putih", dan
memberikan yang "abu-abu" . Jadi kami menyimpan di kolam IP dan dijamin untuk melindungi mesin dari akses dari luar - tidak ada IP untuk sampai ke sana.
Toleransi kesalahan melalui IP bersama . Dalam hal toleransi kesalahan, skema bekerja dengan cara yang sama - beberapa server fisik memiliki IP fisik yang sama, dan sepotong besi di depannya memilih di mana untuk mengirim permintaan. Nanti saya akan berbicara tentang opsi lain.
Poin kontroversialnya adalah bahwa dalam kasus ini,
klien memiliki lebih sedikit koneksi . Jika ada IP yang sama pada beberapa mesin - dengan host yang sama: pu.vk.com atau pp.vk.com, browser klien memiliki batasan jumlah permintaan simultan ke satu host. Tetapi selama HTTP / 2 di mana-mana, saya percaya bahwa ini tidak lagi terjadi.
Yang minus dari skema ini adalah Anda harus
memompa semua lalu lintas yang masuk ke penyimpanan melalui server lain. Karena kita memompa lalu lintas melalui mobil, kita belum dapat memompa lalu lintas yang padat dengan cara yang sama, misalnya, video. Kami mentransfernya langsung - koneksi langsung terpisah untuk repositori individual khusus untuk video. Kami mengirimkan konten yang lebih ringan melalui proxy.
Belum lama ini, kami memiliki versi proksi yang ditingkatkan. Sekarang saya akan memberitahu Anda bagaimana mereka berbeda dari yang biasa dan mengapa ini perlu.
Sun
Pada bulan September 2017, Oracle, yang sebelumnya membeli Sun,
memberhentikan sejumlah besar karyawan Sun. Kita dapat mengatakan bahwa saat ini perusahaan tidak ada lagi. Memilih nama untuk sistem baru, admin kami memutuskan untuk membayar upeti dan rasa hormat kepada perusahaan ini, dan menamai sistem Sun yang baru. Di antara kita sendiri, kita menyebutnya "sinar matahari".
Pp punya beberapa masalah.
Satu IP per grup adalah cache yang tidak efisien . Beberapa server fisik memiliki alamat IP yang sama, dan tidak ada cara untuk mengontrol server mana permintaan akan datang. Oleh karena itu, jika pengguna yang berbeda datang untuk file yang sama, maka jika ada cache pada server ini, file mengendap di cache masing-masing server. Ini adalah skema yang sangat tidak efisien, tetapi tidak ada yang bisa dilakukan.
Akibatnya,
kami tidak dapat membagikan konten , karena kami tidak dapat memilih server tertentu untuk grup ini - mereka memiliki IP yang sama. Juga, untuk beberapa alasan internal, kami
tidak memiliki kesempatan untuk menempatkan server seperti itu di wilayah . Mereka hanya berdiri di St. Petersburg.
Dengan matahari, kami mengubah sistem seleksi. Sekarang kami memiliki
routing anycast : routing dinamis, anycast, daemon self-check. Setiap server memiliki IP individualnya masing-masing, tetapi pada saat yang sama merupakan subnet yang umum. Semuanya dikonfigurasi sedemikian rupa sehingga dalam hal hilangnya satu server, lalu lintas menyebar ke server lain dari grup yang sama secara otomatis. Sekarang dimungkinkan untuk memilih server tertentu,
tidak ada caching yang berlebihan , dan keandalan tidak terpengaruh.
Dukungan berat badan . Sekarang kita dapat menempatkan mobil dengan kapasitas berbeda sesuai kebutuhan, dan juga jika terjadi masalah sementara, ubah bobot “matahari” yang bekerja untuk mengurangi beban pada mobil sehingga mereka “beristirahat” dan bekerja kembali.
Sharding oleh id konten . Hal yang lucu tentang sharding adalah bahwa kita biasanya membagikan konten sehingga pengguna yang berbeda mengikuti file yang sama melalui "sun" yang sama sehingga mereka memiliki cache yang sama.
Kami baru-baru ini meluncurkan aplikasi Clover. Ini adalah kuis siaran langsung online tempat presenter mengajukan pertanyaan dan pengguna merespons secara real time dengan memilih opsi. Aplikasi ini memiliki obrolan tempat pengguna dapat membanjiri.
Lebih dari 100 ribu orang dapat secara bersamaan terhubung ke siaran. Mereka semua menulis pesan yang dikirim ke semua peserta, bersama dengan pesan datang avatar lain. Jika 100 ribu orang datang untuk satu avatar dalam satu "matahari", maka itu kadang-kadang dapat bergulir di atas awan.
Untuk menahan semburan permintaan dari file yang sama, itu untuk beberapa jenis konten yang kami sertakan skema bodoh yang menyebar file di semua "matahari" yang tersedia di wilayah tersebut.
Berjemur di dalam
Membalikkan proxy ke nginx, cache di RAM atau disk cepat Optane / NVMe. Contoh:
http://sun4-2.userapi.com/c100500/path - tautan ke "matahari", yang berada di wilayah keempat, grup server kedua. Itu menutup file path, yang secara fisik terletak di server 100500.
Cache
Kami menambahkan satu simpul lagi ke skema arsitektur kami - lingkungan caching.

Di bawah ini adalah tata letak
cache regional , ada sekitar 20 di antaranya. Ini adalah tempat di mana tepatnya cache dan "suns" berada, yang dapat men-cache lalu lintas melalui diri mereka sendiri.

Ini adalah caching konten multimedia, data pengguna tidak disimpan di sini - hanya musik, video, foto.
Untuk menentukan wilayah pengguna, kami
mengumpulkan awalan jaringan BGP yang diumumkan di wilayah tersebut . Dalam kasus fallback, kami masih memiliki parsing pangkalan geoip, jika kami tidak dapat menemukan IP dengan awalan.
Berdasarkan IP pengguna, kami menentukan wilayah . Dalam kode, kita dapat melihat satu atau lebih wilayah pengguna - titik-titik yang paling dekat secara geografis dengan dia.
Bagaimana cara kerjanya?
Kami mempertimbangkan popularitas file berdasarkan wilayah . Ada nomor cache regional tempat pengguna berada, dan pengidentifikasi file - kami mengambil pasangan ini dan menambah peringkat untuk setiap unduhan.
Pada saat yang sama, iblis - layanan di wilayah - dari waktu ke waktu datang ke API dan berkata: "Saya memiliki cache ini dan itu, beri saya daftar file paling populer di wilayah saya yang belum saya miliki." API memberikan banyak file yang diurutkan berdasarkan peringkat, daemon memompanya, membawanya ke daerah dan memberi mereka file dari sana. Ini adalah perbedaan mendasar antara pu / pp dan Sun dari cache: mereka memberikan file melalui diri mereka sendiri segera, bahkan jika file tersebut tidak ada dalam cache, dan cache pertama memompa file ke dirinya sendiri, dan kemudian mulai memberikannya.
Pada saat yang sama, kami mendapatkan
konten lebih dekat dengan pengguna dan mengolesi beban jaringan. Misalnya, hanya dari cache Moskow kami mendistribusikan lebih dari 1 Tbit / s selama jam sibuk.
Tapi ada masalah -
server cache bukan karet . Untuk konten yang sangat populer, terkadang tidak ada cukup jaringan di server yang terpisah. Kami memiliki server cache 40-50 Gbit / s, tetapi ada konten yang sepenuhnya menyumbat saluran tersebut. Kami berupaya mewujudkan penyimpanan lebih dari satu salinan file populer di kawasan ini. Saya berharap bahwa kita akan menyadarinya pada akhir tahun ini.
Kami memeriksa arsitektur umum.
- Server depan yang menerima permintaan.
- Backends yang menangani permintaan.
- Vault yang ditutup oleh dua jenis proxy.
- Cache regional.
Apa yang hilang dari skema ini? Tentu saja, basis data tempat kita menyimpan data.
Database atau mesin
Kami menyebutnya bukan basis data, tetapi mesin Engine, karena dalam pengertian yang berlaku umum, kami praktis tidak memiliki basis data.
 Ini adalah langkah yang perlu
Ini adalah langkah yang perlu . Itu terjadi karena pada 2008-2009, ketika VK memiliki pertumbuhan popularitas yang eksplosif, proyek ini sepenuhnya bekerja pada MySQL dan Memcache, dan ada masalah. MySQL suka jatuh dan merusak file, setelah itu tidak naik, dan Memcache secara bertahap menurunkan kinerjanya, dan harus dimulai kembali.
Ternyata dalam proyek yang mendapatkan popularitas ada penyimpanan gigih yang merusak data, dan cache yang melambat. Dalam kondisi seperti itu, sulit untuk mengembangkan proyek yang sedang tumbuh. Diputuskan untuk mencoba menulis ulang hal-hal penting yang menjadi sandaran proyek dengan sepeda motor mereka sendiri.
Solusinya berhasil . Kemampuan untuk melakukan ini adalah, sebagaimana kebutuhan mendesak, karena metode penskalaan lain tidak ada pada waktu itu. Tidak ada tumpukan basis, NoSQL belum ada, hanya ada MySQL, Memcache, PostrgreSQL - dan itu saja.
Operasi universal . Pengembangan ini dipimpin oleh tim pengembang-C kami, dan semuanya dilakukan dengan cara yang sama. Terlepas dari mesin, di mana-mana ada kira-kira format yang sama dari file yang ditulis ke disk, parameter startup yang sama, sinyal diproses sama dan berperilaku sama jika terjadi situasi dan masalah tepi. Dengan pertumbuhan mesin, akan lebih mudah bagi administrator untuk mengoperasikan sistem - tidak ada kebun binatang yang perlu dipelihara, dan belajar untuk mengoperasikan setiap pangkalan pihak ketiga yang baru lagi, yang memungkinkan peningkatan jumlah mereka dengan cepat dan mudah.
Jenis mesin
Tim telah menulis beberapa mesin. Berikut adalah beberapa di antaranya: teman, petunjuk, gambar, ipdb, surat, daftar, log, memcached, meowdb, berita, nostradamus, foto, daftar putar, pmemcached, kotak pasir, pencarian, penyimpanan, suka, tugas, ...
Untuk setiap tugas yang membutuhkan struktur data spesifik atau proses permintaan yang tidak lazim, tim-C menulis mesin baru. Kenapa tidak
Kami memiliki mesin
memcached terpisah, yang mirip dengan yang biasa, tetapi dengan banyak roti, dan yang tidak melambat. Bukan ClickHouse, tetapi berfungsi juga. Ada
pmemcached secara terpisah - ini adalah
memcached persisten yang dapat menyimpan data juga pada disk, dan lebih dari itu masuk ke dalam RAM agar tidak kehilangan data saat memulai ulang. Ada berbagai mesin untuk tugas individu: antrian, daftar, set - semua yang diperlukan oleh proyek kami.
Cluster
Dari sudut pandang kode, tidak perlu membayangkan mesin atau database sebagai proses, entitas, atau instance tertentu. Kode ini bekerja secara khusus dengan kluster, dengan grup mesin -
satu jenis per kluster . Katakanlah ada cluster memcached - itu hanya sekelompok mesin.
Kode tidak perlu mengetahui lokasi fisik, ukuran dan jumlah server. Dia pergi ke cluster oleh beberapa pengenal.
Agar ini berfungsi, Anda perlu menambahkan entitas lain, yang terletak di antara kode dan mesin -
proxy .
Proxy RPC
Proxy -
bus penghubung , yang menjalankan hampir seluruh situs. Pada saat yang sama, kami
tidak memiliki penemuan layanan - sebagai gantinya ada konfigurasi proxy ini, yang mengetahui lokasi semua cluster dan semua pecahan dari cluster ini. Ini dilakukan oleh admin.
Pemrogram umumnya tidak peduli berapa banyak, di mana dan berapa biayanya - mereka hanya pergi ke cluster. Ini memungkinkan kita banyak. Setelah menerima permintaan, proksi mengalihkan permintaan, mengetahui di mana - itu menentukan ini.

Pada saat yang sama, proksi adalah titik perlindungan terhadap kegagalan layanan. Jika ada mesin yang melambat atau mogok, maka proksi memahami ini dan karenanya menanggapi sisi klien. Ini memungkinkan Anda untuk menghapus batas waktu - kode tidak menunggu mesin merespons, tetapi memahami bahwa itu tidak berfungsi dan Anda perlu berperilaku berbeda. Kode harus disiapkan untuk fakta bahwa database tidak selalu berfungsi.
Implementasi spesifik
Terkadang kami masih ingin memiliki semacam solusi khusus sebagai mesin. Pada saat yang sama, diputuskan untuk tidak menggunakan rpc-proxy kami yang sudah jadi, yang dibuat khusus untuk mesin kami, tetapi untuk membuat proksi terpisah untuk tugas tersebut.
Untuk MySQL, yang masih kami miliki di beberapa tempat, kami menggunakan db-proxy, dan untuk ClickHouse -
Kittenhouse .
Ini berfungsi secara keseluruhan seperti itu. Ada server, kPHP, Go, Python berjalan di atasnya - secara umum, kode apa pun yang dapat mengikuti protokol RPC kami. Kode berjalan secara lokal ke RPC-proxy - pada setiap server di mana ada kode, proksi lokalnya sendiri diluncurkan. Atas permintaan, proksi mengerti ke mana harus pergi.
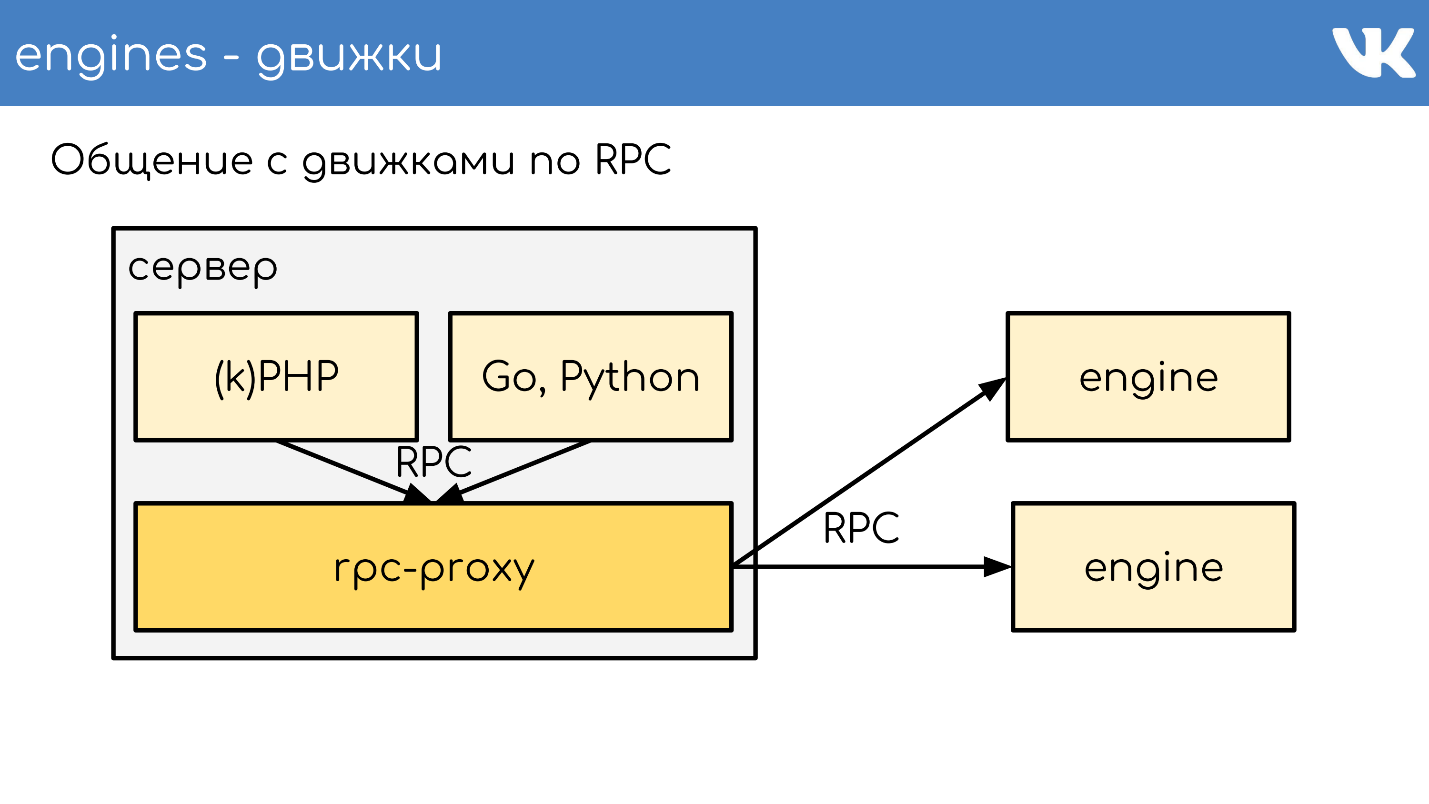
Jika satu mesin ingin pergi ke yang lain, bahkan jika itu adalah tetangga, itu melalui proxy, karena tetangga itu bisa berada di pusat data yang berbeda. Mesin tidak harus dikaitkan dengan mengetahui lokasi selain dari dirinya sendiri - kami memiliki solusi standar ini. Tapi tentu saja ada pengecualian :)
Contoh skema TL yang sesuai dengan semua mesin bekerja.
memcache.not_found = memcache.Value; memcache.strvalue value:string flags:int = memcache.Value; memcache.addOrIncr key:string flags:int delay:int value:long = memcache.Value; tasks.task fields_mask:# flags:int tag:%(Vector int) data:string id:fields_mask.0?long retries:fields_mask.1?int scheduled_time:fields_mask.2?int deadline:fields_mask.3?int = tasks.Task; tasks.addTask type_name:string queue_id:%(Vector int) task:%tasks.Task = Long;
Ini adalah protokol biner, analog terdekat yang merupakan
protobuf. Skema ini menjelaskan bidang opsional di muka, tipe kompleks - ekstensi skalars bawaan, dan kueri. Semuanya berfungsi sesuai dengan protokol ini.
RPC over TL over TCP / UDP ... UDP?
Kami memiliki protokol RPC untuk menanyakan mesin, yang berjalan di atas skema TL. Ini semua berfungsi di atas koneksi TCP / UDP. TCP - sudah jelas mengapa kita sering ditanya tentang UDP.
UDP membantu
menghindari masalah sejumlah besar koneksi antar server . Jika ada RPC-proxy di setiap server dan secara umum dapat masuk ke mesin apa pun, maka Anda mendapatkan puluhan ribu koneksi TCP ke server. Ada beban, tetapi tidak berguna. Dalam kasus UDP, ini bukan masalah.
Tidak ada jabat tangan TCP yang berlebihan . Ini adalah masalah khas: ketika mesin baru atau server baru muncul, banyak koneksi TCP dibuat sekaligus. Untuk permintaan ringan kecil, misalnya, muatan UDP, semua komunikasi antara kode dan mesin adalah
dua paket UDP: satu terbang di satu arah, yang lain terbang di yang lain. Satu perjalanan pulang pergi - dan kode menerima respons dari mesin tanpa jabat tangan.
Ya, itu semua hanya berfungsi
dengan persentase paket yang sangat kecil . Protokol memiliki dukungan untuk transmisi ulang, batas waktu, tetapi jika kita kehilangan banyak, kita mendapatkan TCP praktis, yang tidak menguntungkan. Di seberang lautan, jangan mengemudi UDP.
Kami memiliki ribuan server seperti itu, dan skema yang sama ada di sana: satu paket mesin ditempatkan pada setiap server fisik. Pada dasarnya, mereka single-threaded untuk bekerja secepat mungkin tanpa pemblokiran, dan diparut sebagai solusi single-threaded. Pada saat yang sama, kami tidak memiliki yang lebih andal daripada mesin ini, dan banyak perhatian diberikan pada penyimpanan data yang persisten.
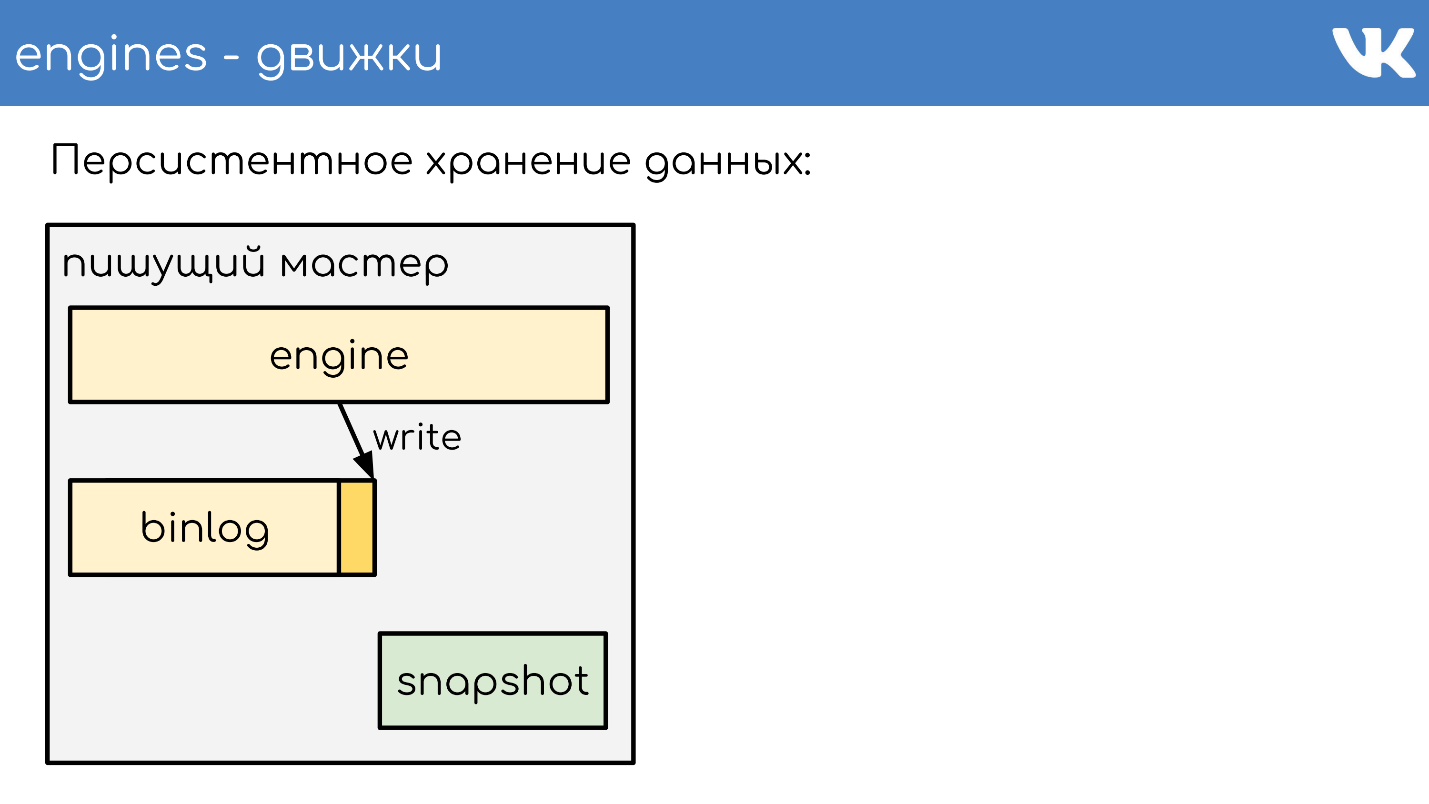
Penyimpanan data yang persisten
Mesin menulis binlog . Binlog adalah file di mana suatu peristiwa ditambahkan untuk mengubah keadaan atau data. Dalam solusi yang berbeda itu disebut berbeda: log biner,
WAL ,
AOF , tetapi prinsipnya satu.
Agar mesin tidak membaca ulang seluruh binlog selama restart selama bertahun-tahun, mesin menulis
snapshots - status saat ini . Jika perlu, mereka pertama membaca dari itu, dan kemudian membaca dari binlog. Semua binlog ditulis dalam format biner yang sama - sesuai dengan skema-TL, sehingga admin dapat mengadministrasikannya secara merata dengan alat mereka. Tidak perlu snapshot seperti itu. Ada tajuk umum yang menunjukkan foto siapa yang int, keajaiban mesin, dan bodi mana yang tidak penting bagi siapa pun. Ini adalah masalah mesin yang merekam snapshot.
Saya akan menjelaskan secara singkat prinsip kerja. Ada server tempat mesin berjalan. Dia membuka binlog kosong baru untuk merekam, menulis perubahan acara ke dalamnya.

Pada titik tertentu, ia memutuskan untuk mengambil snapshot, atau ia menerima sinyal. Server membuat file baru, benar-benar menulis statusnya ke dalamnya, menambahkan ukuran saat ini dari binlog - offset ke akhir file, dan terus menulis lebih lanjut Binlog baru tidak dibuat.
Pada titik tertentu, ketika mesin dinyalakan kembali, akan ada binlog dan snapshot pada disk. Mesin membaca dalam snapshot penuh, menaikkan statusnya pada titik tertentu.

Kurangi posisi yang pada saat snapshot dibuat, dan ukuran binlog.
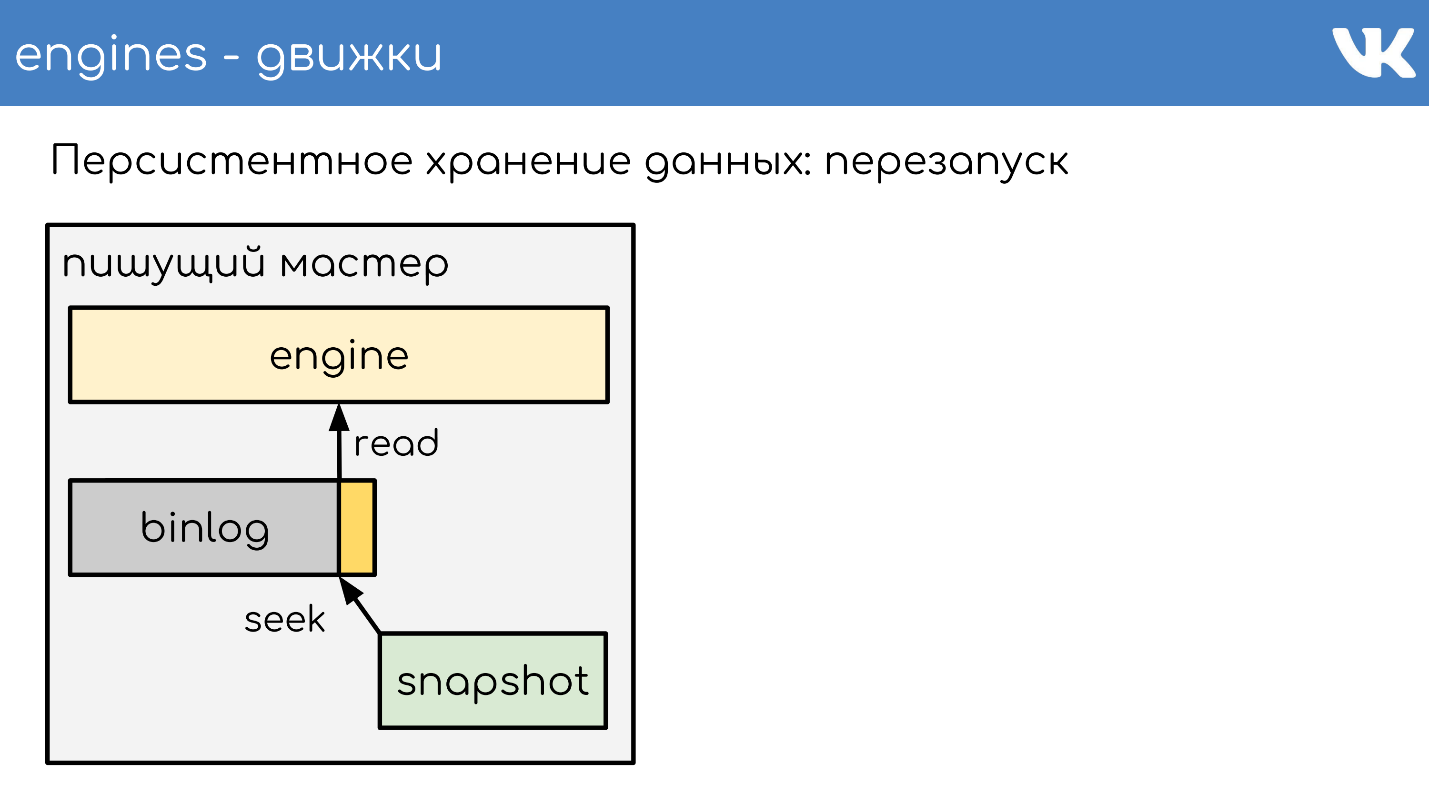
Membaca akhir binlog untuk mendapatkan status saat ini dan terus menulis acara lebih lanjut. Ini adalah skema sederhana, semua mesin kami bekerja di atasnya.
Replikasi data
Akibatnya, replikasi data
berbasis pernyataan - kami tidak menulis perubahan halaman apa pun pada binlog, melainkan
meminta perubahan . Sangat mirip dengan apa yang datang melalui jaringan, hanya sedikit yang berubah.
Skema yang sama digunakan tidak hanya untuk replikasi, tetapi juga
untuk membuat cadangan . Kami memiliki mesin - master penulisan yang menulis dalam binlog. Di tempat lain di mana admin mengatur, menyalin binlog ini naik, dan itu saja - kami memiliki cadangan.

Jika Anda memerlukan
replika bacaan untuk mengurangi beban bacaan pada CPU, mesin bacaan hanya naik, yang membaca akhir binlog dan menjalankan perintah ini secara lokal.
Jeda di sini sangat kecil, dan ada peluang untuk mengetahui berapa banyak replika di belakang master.
Sharding data dalam RPC-proxy
Bagaimana cara kerja sharding? Bagaimana proksi memahami pecahan mana yang akan dikirim? Kode tidak mengatakan: "Kirim ke 15 shard!" - tidak, itu proxy.
Skema paling sederhana adalah firstint , angka pertama dalam permintaan.
get(photo100_500) => 100 % N.Ini adalah contoh untuk protokol teks memcached sederhana, tetapi, tentu saja, permintaan kompleks, terstruktur. Contoh mengambil nomor pertama dalam kueri dan sisanya dari divisi dengan ukuran cluster.
Ini berguna ketika kita ingin memiliki lokalitas data dari satu entitas. Katakanlah 100 adalah ID pengguna atau grup, dan kami ingin semua data dari satu entitas berada di beling yang sama untuk permintaan kompleks.
Jika kami tidak peduli bagaimana permintaan tersebar di seluruh kluster, ada opsi lain -
membuat seluruh halaman .
hash(photo100_500) => 3539886280 % NKami juga mendapatkan hash, sisa divisi dan jumlah pecahan.
Kedua opsi ini hanya berfungsi jika kita siap untuk fakta bahwa ketika kita menambah ukuran cluster, kita akan membagi atau menambahnya beberapa kali. Misalnya, kami memiliki 16 pecahan, kami hilang, kami ingin lebih - Anda bisa mendapatkan 32 dengan aman tanpa downtime. Jika kita ingin membangun berulang kali, akan ada downtime, karena tidak mungkin untuk menghancurkan semuanya dengan hati-hati tanpa kehilangan. Opsi ini bermanfaat, tetapi tidak selalu.
Jika kita perlu menambah atau menghapus jumlah server yang arbitrer,
hashing yang konsisten pada cincin a la Ketama digunakan . Tetapi pada saat yang sama, kami benar-benar kehilangan lokasi data, kami harus membuat permintaan penggabungan ke cluster sehingga masing-masing bagian mengembalikan jawaban kecilnya, dan sudah menggabungkan tanggapan ke proxy.
- . : RPC-proxy , , . , , , . proxy.

. —
memcache .
ring-buffer: prefix.idx = line— , , — . 0 1. memcache — . .
,
Multi Get , , . , - , , , .
logs-engine . , . 600 .
, , 6–7 . , , , ClickHouse .
ClickHouse
, .

, RPC RPC-proxy, , . ClickHouse, :
- - ClickHouse;
- RPC-proxy, ClickHouse, - , , RPC.
— ClickHouse.
ClickHouse,
KittenHouse . KittenHouse ClickHouse — . , HTTP- . , ClickHouse
reverse proxy , , . .

RPC- , , nginx. KittenHouse UDP.

, UDP- . RPC , UDP. .
Pemantauan
: , , . :
.
Netdata ,
Graphite Carbon . ClickHouse, Whisper, . ClickHouse,
Grafana , . , Netdata Grafana .
. , , Counts, UniqueCounts , - .
statlogsCountEvent ( 'stat_name', $key1, $key2, …) statlogsUniqueCount ( 'stat_name', $uid, $key1, $key2, …) statlogsValuetEvent ( 'stat_name', $value, $key1, $key2, …) $stats = statlogsStatData($params)
, , — , Wathdogs.
, 600 1 .
, . — , . , .
,
memcache , .
stats-daemon .
logs-collectors , , .

logs-collectors.
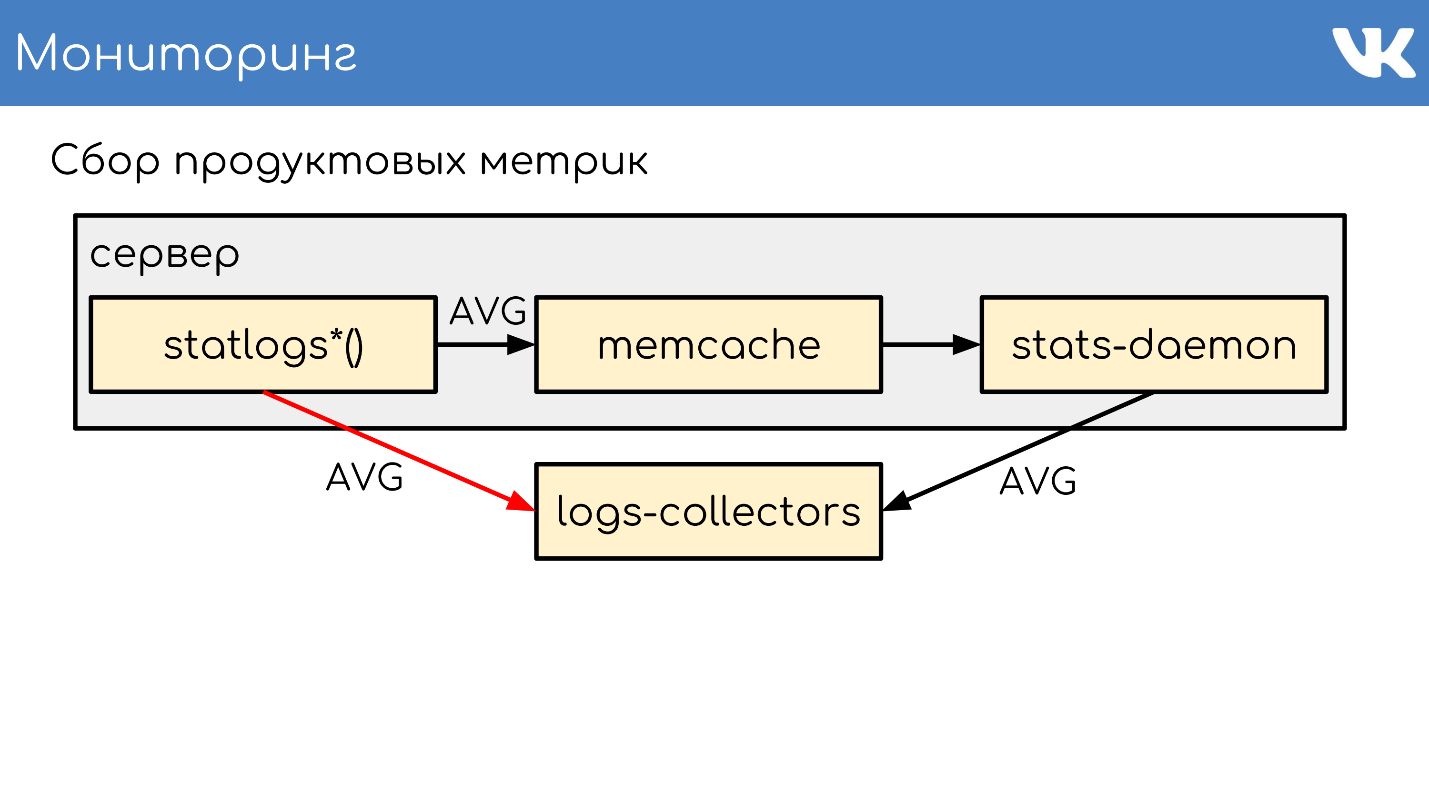
stas-daemom — , collector. , - memcache stats-daemon, , .
logs-collectors
meowDB — , .
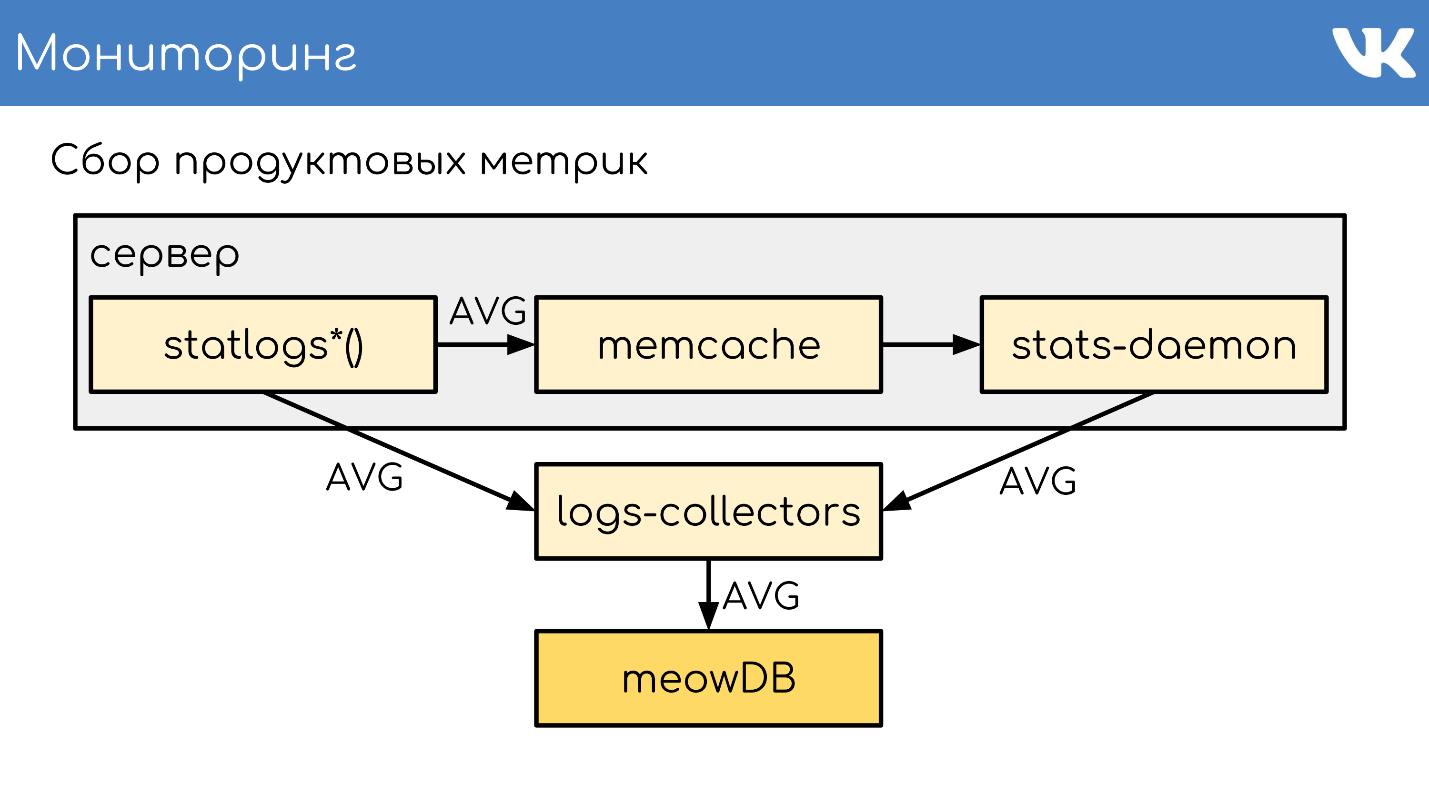
«-SQL» .

2018 , -, ClickHouse. ClickHouse — ?

, KittenHouse.
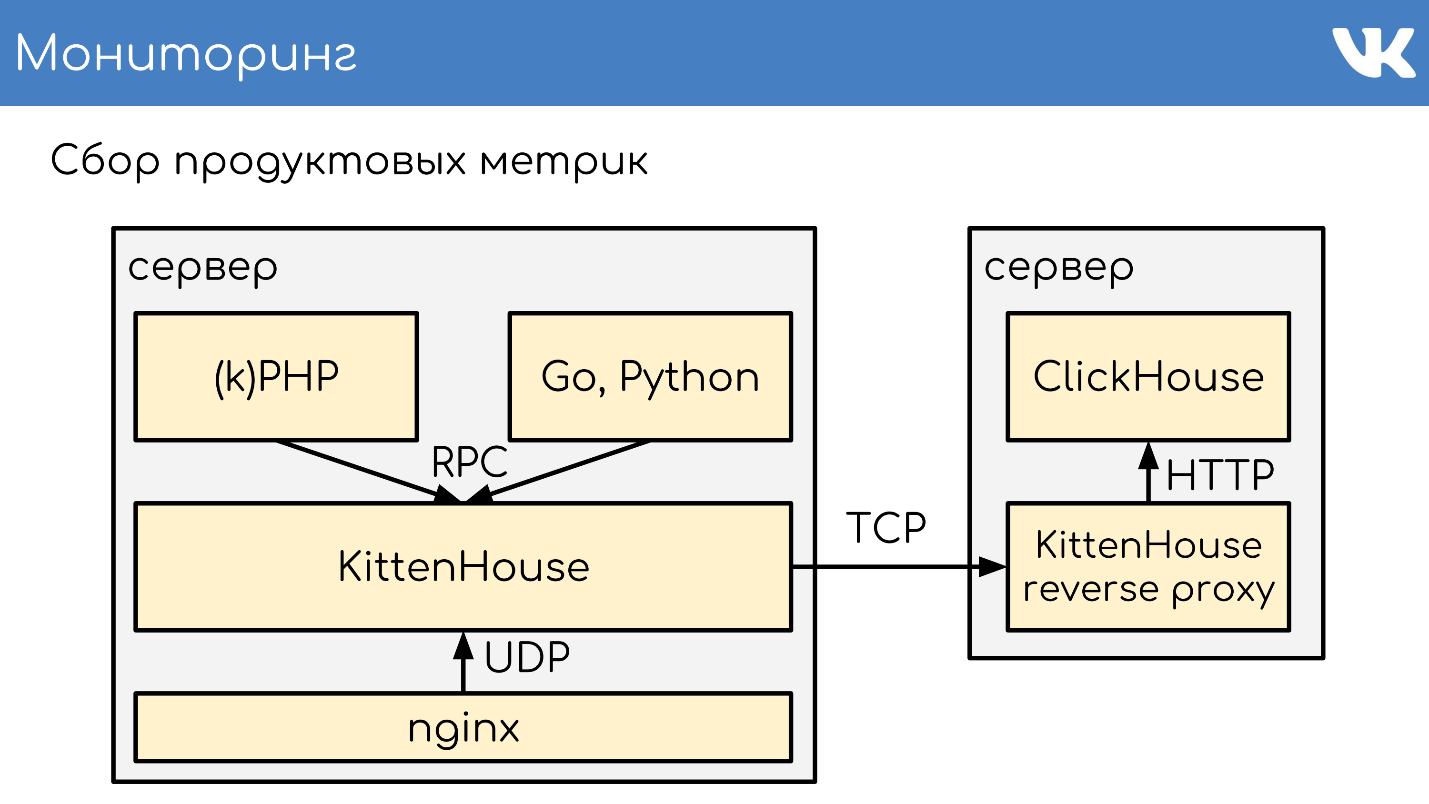 «*House»
«*House» , , UDP. *House inserts, , KittenHouse. ClickHouse, .
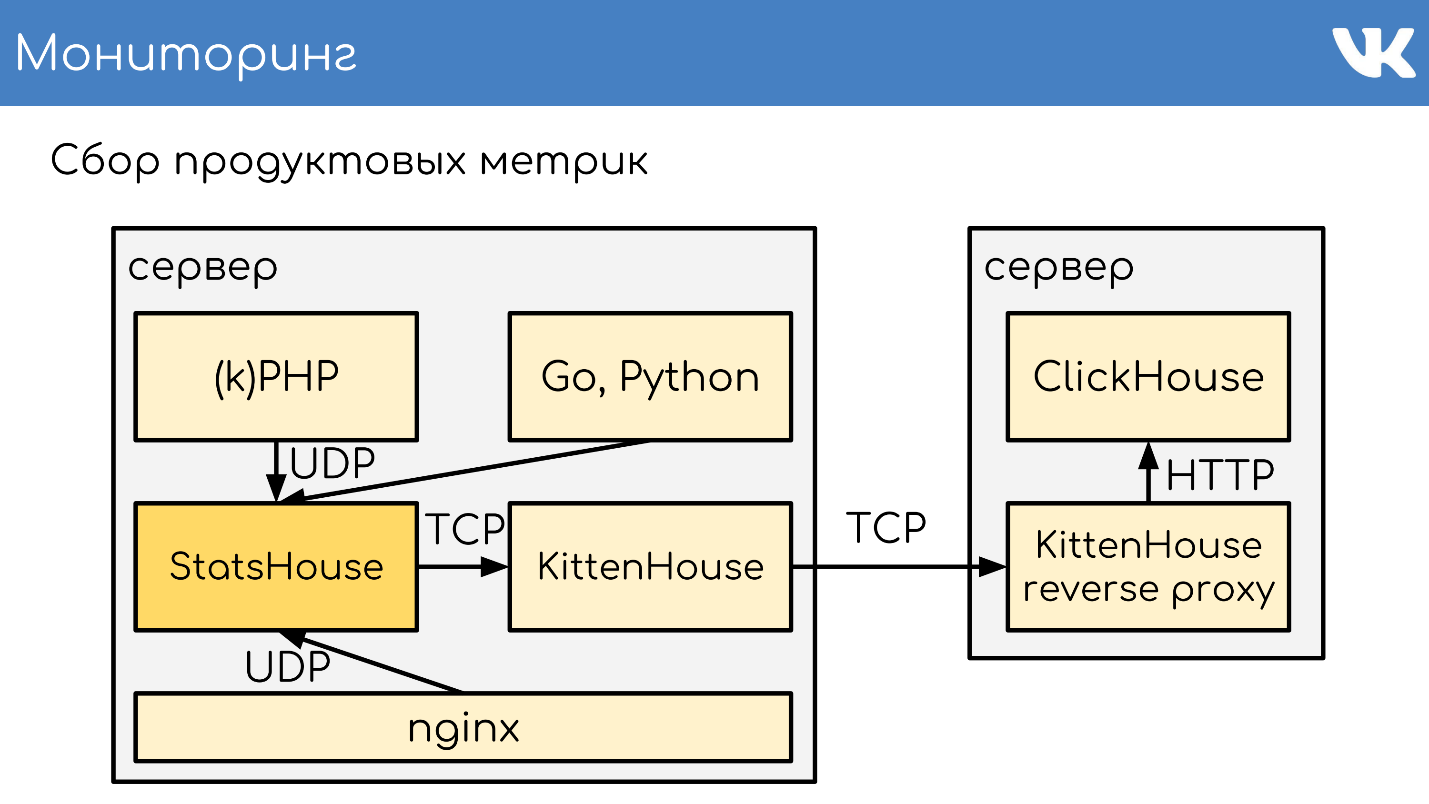
memcache, stats-daemon logs-collectors .

memcache, stats-daemon logs-collectors .
- , StatsHouse.
- StatsHouse KittenHouse UDP-, SQL-inserts, .
- KittenHouse ClickHouse.
- , StatsHouse — ClickHouse SQL.
, , . , , , . .
. , stats-daemons logs-collectors, ClickHouse , , .
, .
PHP.
git :
GitLab TeamCity . -, , — .
, diff — : , , . binlog copyfast, . ,
gossip replication , , — , . . ,
. .
kPHP
git .
HTTP- , diff — . —
binlog copyfast . , .
. copyfast' , binlog , gossip replication , -, .
graceful .
, , :
- git master branch;
- .deb ;
- binlog copyfast;
- ;
- .dep;
- dpkg -i ;
- graceful .
,
.deb ,
dpkg -i . kPHP , — dpkg? . — .
:, PHP Russia 17 PHP-. , , ( PHP!) — , PHP, .