Melanjutkan topik kontes pembelajaran mesin di Habré, kami ingin memperkenalkan pembaca ke dua platform lagi. Mereka tentu tidak sebesar kaggle, tetapi mereka pasti pantas perhatian.

Secara pribadi, saya tidak terlalu suka kaggle karena beberapa alasan:
- pertama, kompetisi di sana sering berlangsung selama beberapa bulan, dan banyak upaya harus dihabiskan untuk partisipasi aktif;
- kedua, kernel publik (solusi publik). Penganut kaggle menyarankan mereka untuk tenang dengan para biarawan Tibet, tetapi pada kenyataannya sangat memalukan ketika segala sesuatu yang Anda lakukan selama satu atau dua bulan tiba-tiba ternyata diletakkan di atas piring untuk semua orang.
Untungnya, kompetisi pembelajaran mesin diadakan di platform lain, dan beberapa kompetisi seperti itu akan dibahas.
| IDAO | SNA Hackathon 2019 |
|---|
Bahasa resmi: Bahasa Inggris,
penyelenggara: Yandex, Sberbank, HSE | Bahasa resmi: Rusia,
penyelenggara: Grup Mail.ru |
Putaran Daring: 15 Jan - 11 Feb 2019;
Final Di Tempat: 4-6 April 2019 | online - mulai 7 Februari hingga 15 Maret;
offline - mulai 30 Maret hingga 1 April. |
Dari seperangkat data tertentu pada partikel dalam collider hadron besar (pada lintasan, momentum, dan parameter fisik agak rumit lainnya), tentukan apakah muon atau tidak.
Dari pernyataan ini, 2 tugas dibedakan:
- Dalam satu Anda hanya harus mengirim prediksi Anda,
- dan yang lain - kode dan model lengkap untuk prediksi, dan pembatasan yang agak ketat diberlakukan pada waktu eksekusi dan penggunaan memori | Untuk kompetisi SNA Hackathon, log untuk menunjukkan konten dari grup terbuka di feed berita pengguna untuk Februari-Maret 2018 dikumpulkan. Set tes telah disembunyikan minggu terakhir setengah Maret. Setiap entri dalam log berisi informasi tentang apa yang ditunjukkan kepada siapa dan juga tentang bagaimana pengguna bereaksi terhadap konten ini: letakkan "kelas", berkomentar, diabaikan atau disembunyikan dari umpan.
Inti dari tugas SNA Hackathon adalah untuk mengklasifikasikan umpan mereka untuk setiap pengguna jejaring sosial Odnoklassniki, menaikkan setinggi mungkin pos-pos yang akan menerima "kelas".
Pada tahap online, tugas dibagi menjadi 3 bagian:
1. untuk memberi peringkat posting pada berbagai alasan kolaboratif
2. peringkat posting berdasarkan gambar yang ada di dalamnya
3. untuk menentukan peringkat tulisan sesuai dengan teks yang terkandung di dalamnya |
| Metrik khusus yang rumit, seperti ROC-AUC | Rata-rata ROC-AUC oleh Pengguna |
Hadiah untuk tahap pertama - T-shirt untuk tempat N, perjalanan ke tahap kedua, di mana akomodasi dan makanan dibayarkan selama kompetisi
Tahap kedua - ??? (Untuk beberapa alasan, saya tidak hadir pada upacara penghargaan dan saya tidak tahu apa yang akhirnya saya dapatkan dengan hadiah). Laptop yang dijanjikan untuk semua anggota tim pemenang | Hadiah untuk tahap pertama - T-shirt untuk 100 peserta terbaik, perjalanan ke tahap kedua, di mana mereka membayar biaya perjalanan ke Moskow, akomodasi dan makanan selama kompetisi. Juga, menjelang akhir tahap pertama, hadiah diumumkan untuk yang terbaik dalam 3 tugas di tahap 1: semua orang memenangkan kartu video TI RTX 2080!
Tahap kedua adalah tim satu, tim memiliki 2 hingga 5 orang, hadiah:
Posisi Pertama - 300.000 rubel
Posisi Kedua - 200.000 rubel
Posisi Ketiga - 100.000 rubel
hadiah juri - 100.000 rubel |
| Kelompok resmi dalam telegram, ~ 190 peserta, komunikasi dalam bahasa Inggris, saya harus menunggu beberapa hari untuk menjawab pertanyaan | Kelompok resmi dalam telegram, ~ 1500 peserta, diskusi aktif tentang tugas antara peserta dan penyelenggara |
| Panitia menyediakan dua solusi dasar, sederhana dan canggih. Yang sederhana membutuhkan kurang dari 16 GB RAM, sedangkan yang canggih dari 16 tidak cocok. Pada saat yang sama, berjalan sedikit di depan, para peserta gagal secara signifikan melebihi solusi lanjutan. Tidak ada kesulitan dalam meluncurkan solusi ini. Perlu dicatat bahwa dalam contoh lanjutan ada komentar dengan petunjuk di mana harus mulai meningkatkan solusi. | Solusi dasar primitif disediakan untuk masing-masing tugas, mudah dilampaui oleh para peserta. Pada hari-hari awal kontes, para peserta menghadapi beberapa kesulitan: pertama, data diberikan dalam format Apache Parket, dan tidak semua kombinasi Python dan paket parket bekerja tanpa kesalahan. Kesulitan kedua adalah memompa gambar dari cloud email, saat ini tidak ada cara mudah untuk mengunduh sejumlah besar data sekaligus. Akibatnya, masalah ini menunda peserta selama beberapa hari. |
IDAO. Tahap pertama
Tugasnya adalah untuk mengklasifikasikan partikel muon / non-muon sesuai dengan karakteristiknya. Fitur utama dari tugas ini adalah adanya kolom bobot dalam data pelatihan, yang oleh panitia sendiri ditafsirkan sebagai kepercayaan pada jawaban untuk baris ini. Masalahnya adalah bahwa beberapa baris berisi bobot negatif.
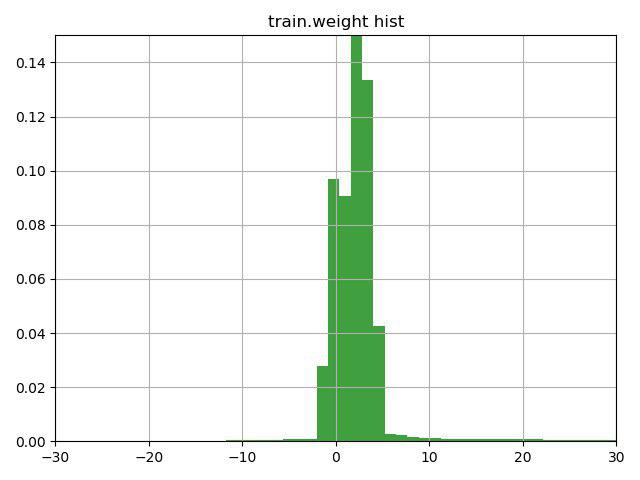
Setelah berpikir selama beberapa menit di atas garis dengan sebuah petunjuk (petunjuk itu hanya menarik perhatian pada fitur kolom bobot ini) dan membuat grafik ini, kami memutuskan untuk memeriksa 3 opsi:
1) membalikkan target untuk baris dengan bobot negatif (dan berat masing-masing)
2) geser bobot ke nilai minimum, sehingga bobotnya mulai dari 0
3) jangan gunakan bobot untuk baris
Opsi ketiga ternyata yang terburuk, tetapi dua yang pertama meningkatkan hasilnya, yang terbaik adalah opsi No. 1, yang segera membawa kami ke tempat kedua saat ini di tugas pertama dan yang pertama di yang kedua.

Langkah kami selanjutnya adalah melihat data untuk nilai yang hilang. Panitia memberi kami data yang sudah disisir, di mana ada beberapa nilai yang hilang, dan mereka digantikan oleh -9999.
Kami menemukan nilai yang hilang di kolom MatchedHit_ {X, Y, Z} [N] dan MatchedHit_D {X, Y, Z} [N], dan hanya ketika N = 2 atau 3. Seperti yang kami pahami, beberapa partikel tidak terbang melalui keempat detektor. , dan berhenti di 3 atau 4 piring. Data juga berisi kolom Lextra_ {X, Y} [N], yang tampaknya menggambarkan hal yang sama dengan MatchedHit_ {X, Y, Z} [N], tetapi menggunakan semacam ekstrapolasi. Tebakan-tebakan kecil ini menyarankan bahwa alih-alih nilai yang hilang di MatchedHit_ {X, Y, Z} [N], Anda dapat mengganti Lextra_ {X, Y} [N] (hanya untuk koordinat X dan Y). MatchedHit_Z [N] diisi dengan median. Manipulasi ini memungkinkan kami untuk pergi ke 1 tempat perantara untuk kedua tugas.

Mengingat bahwa untuk kemenangan di tahap pertama mereka tidak memberikan apa-apa, kita bisa berhenti pada ini, tetapi kami melanjutkan, menggambar beberapa gambar yang indah dan datang dengan fitur baru.

Sebagai contoh, kami menemukan bahwa jika kami membangun titik-titik perpotongan partikel dari masing-masing empat lempeng detektor, kita dapat melihat bahwa titik-titik pada masing-masing lempeng dikelompokkan menjadi 5 persegi panjang dengan rasio aspek 4 sampai 5 dan pusat pada (0,0), dan persegi panjang pertama tidak memiliki poin.
| No. Pelat / Dimensi Persegi Panjang | 1 | 2 | 3 | 4 | 5 |
|---|
| Piring 1 | 500x625 | 1000x1250 | 2000x2500 | 4000x5000 | 8000x10000 |
| Piring 2 | 520x650 | 1040x1300 | 2080x2600 | 4160x5200 | 8320x10400 |
| Piring 3 | 560x700 | 1120x1400 | 2240x2800 | 4480x5600 | 8960x11200 |
| Piring 4 | 600x750 | 1200x1500 | 2400x3000 | 4800x6000 | 9600x12000 |
Setelah menentukan ukuran ini, kami menambahkan untuk setiap partikel 4 fitur kategori baru - jumlah persegi panjang di mana ia memotong setiap lempeng.
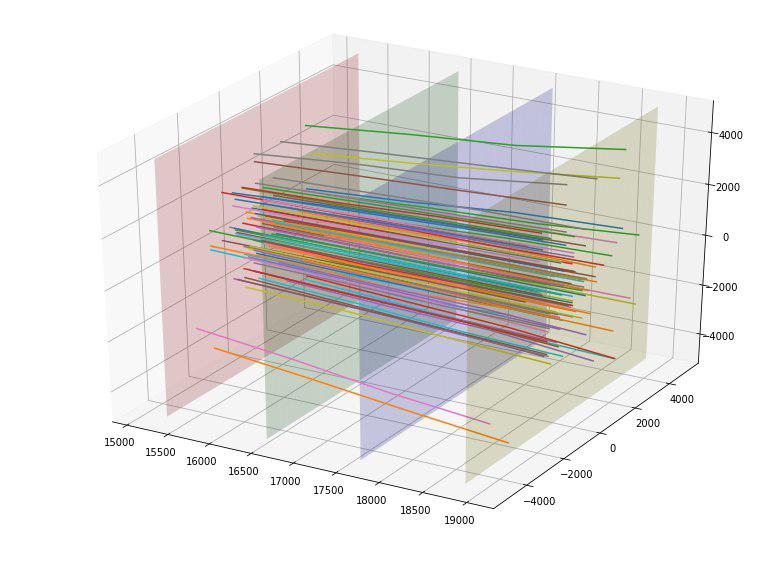
Kami juga memperhatikan bahwa partikel-partikel itu sepertinya tersebar jauh dari pusat dan muncul ide untuk mengevaluasi “kualitas” dari hamburan ini. Idealnya, mungkin, seseorang dapat membuat semacam parabola "ideal" tergantung pada titik masuk dan memperkirakan penyimpangan dari itu, tetapi kami membatasi diri pada garis "ideal". Dengan membangun garis ideal tersebut untuk setiap titik masuk, kami dapat menghitung deviasi mean-kuadrat dari lintasan setiap partikel dari garis ini. Karena rata-rata penyimpangan untuk target = 1 adalah 152, dan untuk target = 0 ternyata 390, kami tentatif menilai fitur ini sebagai baik. Memang fitur ini langsung menghantam bagian atas yang paling berguna.
Kami senang, dan menambahkan penyimpangan semua 4 titik persimpangan untuk setiap partikel dari garis ideal sebagai tambahan 4 fitur (dan mereka juga bekerja dengan baik).
Tautan ke artikel ilmiah tentang topik kompetisi, yang diberikan kepada kami oleh penyelenggara, menyarankan bahwa kami jauh dari yang pertama untuk menyelesaikan masalah ini dan, mungkin, ada beberapa perangkat lunak khusus. Setelah menemukan repositori di github di mana metode IsMuonSimple, IsMuon, IsMuonLoose diterapkan, kami memindahkannya ke diri kami sendiri dengan sedikit modifikasi. Metodenya sendiri sangat sederhana: misalnya, jika energinya kurang dari ambang, maka ini bukan muon, atau muon. Tanda-tanda sederhana seperti itu jelas tidak bisa memberikan peningkatan dalam hal menggunakan peningkatan gradien, jadi kami menambahkan tanda lain "jarak" ke ambang batas. Fitur-fitur ini juga sedikit meningkat. Mungkin, setelah menganalisis metode yang ada lebih menyeluruh, orang bisa menemukan metode yang lebih kuat dan menambahkannya ke atribut.
Menjelang akhir kontes, kami menarik sedikit solusi "cepat" untuk tugas kedua, sebagai hasilnya, itu berbeda dari baseline dalam poin-poin berikut:
- Dalam baris dengan bobot negatif, target dibalik
- Diisi nilai-nilai yang hilang di MatchedHit_ {X, Y, Z} [N]
- Mengurangi kedalaman hingga 7
- Mengurangi tingkat belajar menjadi 0,1 (0,19)
Sebagai hasilnya, kami mencoba beberapa fitur lainnya (tidak terlalu berhasil), mengambil parameter dan melatih catboost, lightgbm dan xgboost, mencoba campuran prediksi yang berbeda dan dengan percaya diri memenangkan tugas kedua sebelum membuka privat, dan berada di antara para pemimpin di yang pertama.
Setelah privat dibuka, kami berada di posisi 10 untuk 1 tugas dan 3 untuk yang kedua. Semua pemimpin berbaur, dan kecepatan di privat lebih tinggi daripada di papan tulis. Tampaknya data itu bertingkat buruk (atau misalnya, tidak ada garis dengan bobot negatif di pribadi) dan ini sedikit membuat frustrasi.
SNA Hackathon 2019 - Teks. Tahap pertama
Tugasnya adalah menentukan peringkat posting pengguna di jejaring sosial Odnoklassniki sesuai dengan teks yang terkandung di dalamnya, selain teks, ada beberapa karakteristik posting (bahasa, pemilik, tanggal dan waktu pembuatan, tanggal dan waktu menonton).
Sebagai pendekatan klasik untuk bekerja dengan teks, saya akan memilih dua opsi:
- Pemetaan setiap kata ke dalam ruang vektor n-dimensi, sehingga kata-kata yang mirip memiliki vektor yang sama (lebih detail dapat ditemukan dalam artikel kami ), kemudian menemukan kata tengah untuk teks atau menggunakan mekanisme yang memperhitungkan posisi relatif kata-kata (CNN, LSTM / GRU) .
- Menggunakan model yang segera dapat bekerja dengan seluruh kalimat. Misalnya, Bert. Secara teori, pendekatan ini harus bekerja lebih baik.
Karena ini adalah pengalaman pertama saya dengan teks, akan salah untuk mengajar seseorang, jadi saya akan mengajar diri sendiri. Ini adalah tips yang akan saya berikan pada awal kontes:
- Sebelum Anda berlari untuk mempelajari sesuatu, lihat datanya! Selain teks-teks itu sendiri, ada beberapa kolom dalam data, dan lebih banyak yang bisa diperas dari mereka daripada saya. Hal paling sederhana adalah melakukan pengkodean target berarti untuk bagian dari kolom.
- Jangan belajar dari semua data! Ada banyak data (sekitar 17 juta baris) dan itu sepenuhnya opsional untuk menggunakan semuanya untuk menguji hipotesis. Pelatihan dan praproses sangat lambat, dan saya jelas akan punya waktu untuk menguji hipotesis yang lebih menarik.
- < Saran kontroversial > Tidak perlu mencari model pembunuh. Saya berurusan dengan Elmo dan Bert untuk waktu yang lama, berharap bahwa mereka akan segera membawa saya ke tempat yang tinggi, dan sebagai hasilnya saya menggunakan embeddings pra-latih FastText untuk bahasa Rusia. Dengan Elmo, itu tidak mungkin untuk mencapai kecepatan yang lebih baik, tetapi dengan Bert aku tidak berhasil mengetahuinya.
- < Saran kontroversial > Jangan mencari satu fitur pembunuh. Melihat data, saya perhatikan bahwa di wilayah 1 persen dari teks tidak mengandung, pada kenyataannya, teks! Tapi kemudian ada tautan ke beberapa sumber, dan saya menulis parser sederhana yang membuka situs dan mengeluarkan nama dan deskripsi. Sepertinya ide yang bagus, tetapi kemudian saya terbawa suasana, memutuskan untuk mengurai semua tautan untuk semua teks, dan sekali lagi kehilangan banyak waktu. Semua ini tidak memberikan peningkatan yang signifikan dalam hasil akhir (meskipun saya menemukan cara untuk membendung, misalnya).
- Fitur klasik berfungsi. Google, misalnya, "fitur teks kaggle", membaca dan menambahkan semuanya. TF-IDF memberikan peningkatan, fitur statistik, seperti panjang teks, kata, jumlah tanda baca, juga.
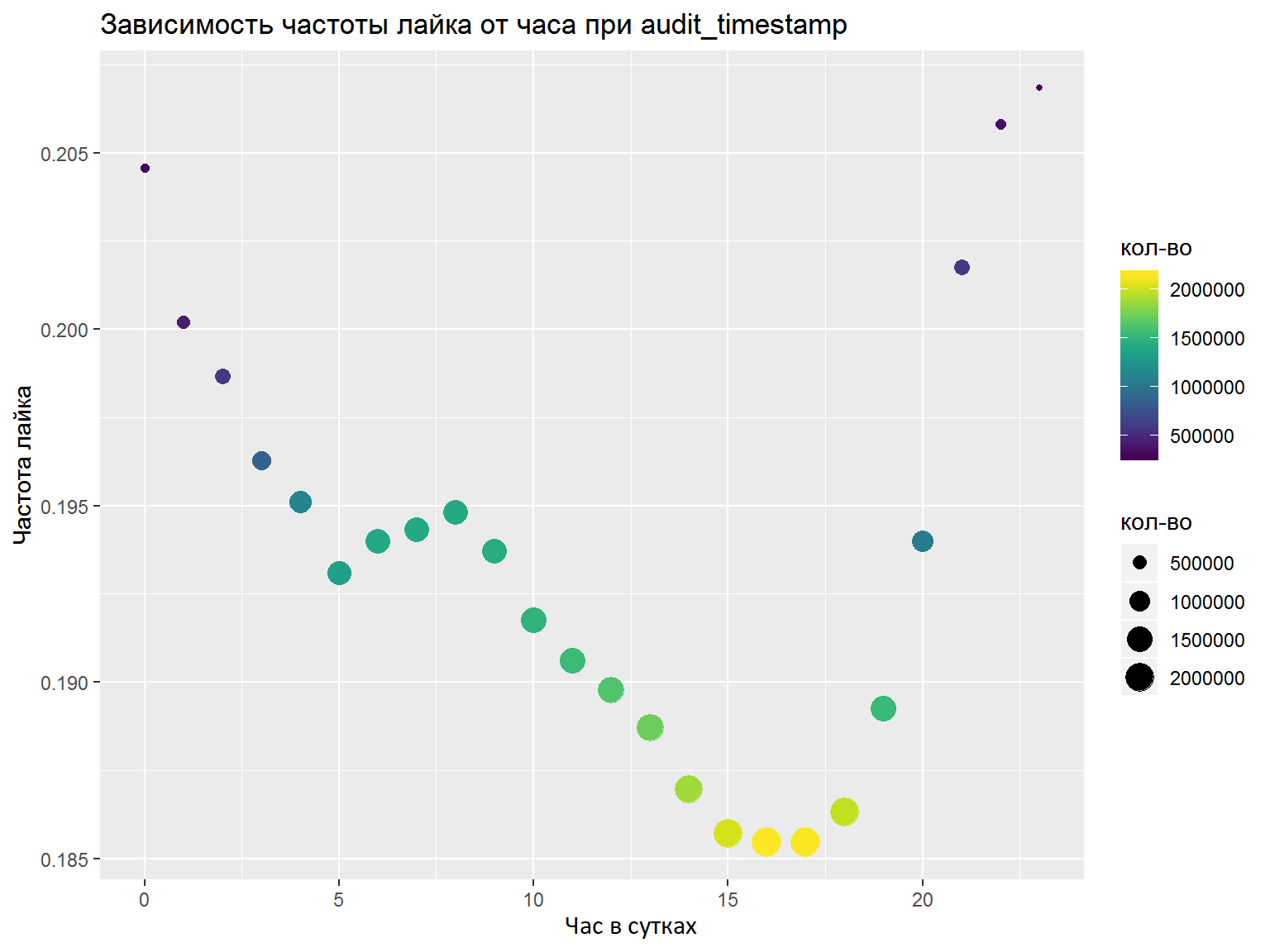
- Jika ada kolom DateTime, Anda harus menguraikannya ke dalam beberapa fitur terpisah (jam, hari dalam seminggu, dll.). Fitur mana yang akan disorot harus dianalisis dengan grafik / beberapa metrik. Di sini saya melakukan semuanya dengan benar pada firasat dan memilih fitur yang diperlukan, tetapi analisis normal tidak akan merugikan (misalnya, seperti yang kami lakukan di final).
Sebagai hasil dari kompetisi, saya melatih satu model keras dengan konvolusi sesuai kata-kata, dan satu lagi berdasarkan LSTM dan GRU. Baik di sana maupun di sana digunakan embeddings FastText pra-dilatih untuk bahasa Rusia (saya mencoba sejumlah embeddings lainnya, tetapi yang ini bekerja paling baik). Setelah rata-rata prediksi, saya mengambil tempat 7 dari 76 peserta.
Sudah setelah tahap pertama, sebuah artikel diterbitkan oleh Nikolai Anokhin , yang menempati posisi kedua (ia ikut serta dalam kompetisi), dan keputusannya diulangi sampai tahap tertentu, tetapi ia melangkah lebih jauh karena mekanisme perhatian nilai kunci kueri.
Tahap kedua OK & IDAO
Tahap kedua kompetisi diadakan hampir berturut-turut, jadi saya memutuskan untuk mempertimbangkannya bersama.
Pertama, dengan tim yang baru diakuisisi, saya berakhir di kantor Mail.ru yang mengesankan, di mana tugas kami adalah menggabungkan model tiga trek dari tahap pertama - teks, gambar, dan collab. Sedikit lebih dari 2 hari dialokasikan untuk ini, yang ternyata sangat kecil. Bahkan, kami hanya bisa mengulangi hasil tahap pertama kami, tanpa menerima keuntungan dari asosiasi. Akibatnya, kami mengambil tempat ke-5, tetapi model teks tidak dapat digunakan. Melihat keputusan peserta lain, tampaknya ada baiknya mencoba mengelompokkan teks dan menambahkannya ke model collab. Efek samping dari tahap ini adalah kesan baru, kenalan dan komunikasi dengan peserta dan organisator yang keren, serta kurang tidur, yang mungkin mempengaruhi hasil tahap akhir IDAO.
Tugas pada tahap tatap muka IDAO 2019 Final adalah memprediksi waktu tunggu untuk pesanan pengemudi taksi Yandex di bandara. Pada tahap 2, 3 tugas = 3 bandara dialokasikan. Untuk setiap bandara, data per menit pada jumlah pesanan taksi selama enam bulan diberikan. Dan bulan berikutnya dan data pesanan per menit selama 2 minggu terakhir diberikan sebagai data uji. Tidak ada cukup waktu (1,5 hari), tugasnya cukup spesifik, hanya satu orang yang datang dari tim ke kontes - dan sebagai hasilnya, tempat yang menyedihkan lebih dekat ke akhir. Dari ide-ide menarik, ada upaya untuk menggunakan data eksternal: cuaca, kemacetan lalu lintas dan statistik pesanan taksi Yandex. Meskipun panitia tidak mengatakan apa bandara itu, banyak peserta menyarankan bahwa mereka adalah Sheremetyevo, Domodedovo dan Vnukovo. Meskipun asumsi ini ditolak setelah kompetisi, fitur, misalnya, dari data cuaca Moskow meningkatkan hasil baik pada validasi dan di papan peringkat.
Kesimpulan
- Kontes ML itu keren dan menarik! Ada aplikasi untuk keterampilan dalam analisis data, dan dalam model dan teknik yang licik, dan hanya akal sehat saja.
- ML sudah merupakan lapisan besar pengetahuan yang tampaknya tumbuh secara eksponensial. Saya menetapkan diri saya untuk mengenal area yang berbeda (sinyal, gambar, tabel, teks) dan sudah menyadari betapa banyak yang harus dipelajari. Sebagai contoh, setelah kompetisi ini, saya memutuskan untuk belajar: algoritma pengelompokan, teknik-teknik canggih untuk bekerja dengan perpustakaan meningkatkan gradien (khususnya, bekerja dengan CatBoost pada GPU), jaringan kapsul, dan mekanisme perhatian nilai kunci permintaan.
- Tidak sedikit pun! Ada banyak kontes lain di mana bahkan lebih mudah untuk mendapatkan T-shirt, dan hadiah lainnya lebih mungkin.
- Mengobrol! Di bidang pembelajaran mesin dan analisis data sudah ada komunitas besar, ada kelompok tematik di telegram, kendur, dan orang-orang serius dari Mail.ru, Yandex dan perusahaan lain menjawab pertanyaan dan membantu pemula dan melanjutkan perjalanan mereka di bidang pengetahuan ini.
- Saya menyarankan semua orang yang dijiwai dengan paragraf sebelumnya untuk mengunjungi datafest - sebuah konferensi gratis besar di Moskow, yang akan diadakan pada 10-11 Mei.