Bagian pertama artikel tentang dasar-dasar NLP dapat dibaca di
sini . Hari ini kita akan berbicara tentang salah satu tugas NLP paling populer - Named-Entity Recognition (NER) - dan menganalisis secara detail arsitektur solusi untuk masalah ini.
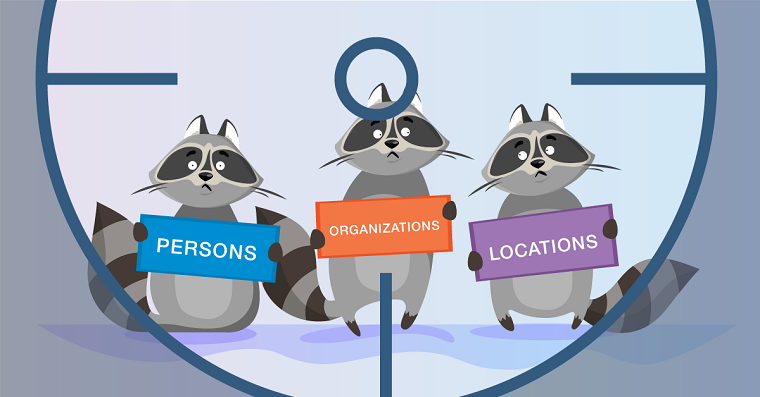
Tugas NER adalah untuk menyoroti bentang entitas dalam teks (rentang adalah fragmen teks yang berkelanjutan). Misalkan ada teks berita, dan kami ingin menyorot entitas di dalamnya (beberapa set pra-tetap - misalnya, orang, lokasi, organisasi, tanggal, dan sebagainya). Tugas NER adalah untuk memahami bahwa bagian dari teks “
1 Januari 1997 ” adalah tanggal, “
Kofi Annan ” adalah orangnya, dan “
PBB ” adalah organisasi.
Apa yang disebut entitas? Dalam pengaturan klasik pertama, yang dirumuskan pada konferensi
MUC-6 pada tahun 1995, ini adalah orang-orang, lokasi dan organisasi. Sejak itu, beberapa paket yang tersedia telah muncul, masing-masing memiliki seperangkat entitas bernama sendiri. Biasanya, tipe entitas baru ditambahkan ke orang, lokasi, dan organisasi. Yang paling umum dari mereka adalah numerik (tanggal, jumlah moneter), serta entitas Misc (dari aneka - entitas bernama lainnya; contohnya adalah iPhone 6).
Mengapa Anda perlu memecahkan masalah NER
Mudah dipahami bahwa, bahkan jika kita belajar membedakan dengan baik dalam teks orang, lokasi, dan organisasi, ini tidak mungkin menimbulkan minat yang besar di antara para pelanggan. Meskipun beberapa aplikasi praktis, tentu saja, memiliki masalah dalam pengaturan klasik.
Salah satu skenario ketika solusi untuk masalah dalam perumusan klasik mungkin masih diperlukan adalah penataan data yang tidak terstruktur. Misalkan Anda memiliki beberapa jenis teks (atau satu set teks), dan data darinya harus dimasukkan ke dalam basis data (tabel). Entitas bernama klasik dapat sesuai dengan baris tabel tersebut atau berfungsi sebagai konten beberapa sel. Oleh karena itu, untuk mengisi tabel dengan benar, Anda harus terlebih dahulu memilih dalam teks data yang akan Anda masukkan ke dalamnya (biasanya setelah ini ada langkah lain - mengidentifikasi entitas dalam teks, ketika kami memahami bahwa
PBB dan
PBB mencakup "Lihat organisasi yang sama; namun, tugas identifikasi atau menghubungkan entitas adalah tugas lain, dan kami tidak akan membicarakannya secara rinci dalam pos ini).
Namun, ada beberapa alasan mengapa NER adalah salah satu tugas NLP paling populer.
Pertama, mengekstraksi entitas bernama adalah langkah menuju "memahami" teks. Keduanya dapat memiliki nilai independen, dan membantu menyelesaikan tugas NLP lainnya dengan lebih baik.
Jadi, jika kita tahu di mana entitas disorot dalam teks, maka kita dapat menemukan fragmen teks yang penting untuk beberapa tugas. Sebagai contoh, kita dapat memilih hanya paragraf-paragraf di mana entitas dari jenis tertentu ditemukan, dan kemudian bekerja hanya dengan mereka.
Misalkan Anda menerima sepucuk surat, dan alangkah baiknya membuat cuplikan hanya dari bagian itu di mana ada sesuatu yang bermanfaat, dan bukan hanya "
Halo, Ivan Petrovich ". Jika Anda dapat membedakan entitas yang disebutkan, Anda dapat membuat cuplikan cerdas dengan menunjukkan bagian surat itu di mana entitas yang menarik bagi kami berada (dan tidak hanya menunjukkan kalimat pertama dari surat itu, seperti yang sering dilakukan). Atau Anda dapat dengan mudah menyoroti dalam teks bagian-bagian surat yang diperlukan (atau, langsung, entitas yang penting bagi kami) untuk kenyamanan analis.
Selain itu, entitas merupakan lokasi yang kaku dan andal, pemilihannya dapat menjadi penting untuk banyak tugas. Misalkan Anda memiliki nama untuk entitas yang bernama dan, apa pun itu, kemungkinan besar itu adalah berkelanjutan, dan semua tindakan dengan itu perlu dilakukan seperti dengan satu blok. Misalnya, terjemahkan nama entitas ke nama entitas. Anda ingin menerjemahkan
"Toko Pyaterochka" ke dalam bahasa Prancis dalam satu potong, dan tidak terpecah menjadi beberapa fragmen yang tidak terkait satu sama lain. Kemampuan untuk mendeteksi collocations juga berguna untuk banyak tugas lain - misalnya, untuk parsing sintaksis.
Tanpa menyelesaikan masalah NER, sulit membayangkan solusi bagi banyak masalah NLP, misalnya, menyelesaikan kata ganti anafora atau membangun sistem tanya jawab. Anafora kata ganti memungkinkan kita untuk memahami elemen teks yang dirujuk oleh kata ganti tersebut. Sebagai contoh, mari kita ingin menganalisis teks “
Charming Galloped on a White Horse. Sang putri berlari untuk menemuinya dan menciumnya . " Jika kita menyoroti esensi Persona pada kata "Tampan", maka mesin itu akan jauh lebih mudah untuk memahami bahwa sang putri kemungkinan besar tidak mencium kuda, tetapi sang pangeran Tampan.
Sekarang kami memberikan contoh bagaimana alokasi entitas yang dinamai dapat membantu dalam pembangunan sistem tanya jawab. Jika Anda mengajukan pertanyaan "
Siapa yang memainkan peran Darth Vader dalam film" The Empire Strikes Back " " di mesin pencari favorit Anda, "maka dengan probabilitas tinggi Anda akan mendapatkan jawaban yang tepat. Ini dilakukan hanya dengan mengisolasi entitas bernama: kita memilih entitas (film, peran, dll.), Memahami apa yang diminta, dan kemudian mencari jawabannya di database.
Mungkin pertimbangan yang paling penting karena tugas NER sangat populer: pernyataan masalah sangat fleksibel. Dengan kata lain, tidak ada yang memaksa kita untuk memilih lokasi, orang, dan organisasi. Kita dapat memilih potongan teks berkelanjutan yang kita butuhkan yang agak berbeda dari teks lainnya. Sebagai hasilnya, Anda dapat memilih set entitas Anda sendiri untuk tugas praktis spesifik yang datang dari pelanggan, menandai badan teks dengan set ini dan melatih model. Skenario seperti itu ada di mana-mana, dan ini menjadikan NER salah satu tugas NLP yang paling sering dilakukan di industri.
Saya akan memberikan beberapa contoh kasus seperti itu dari pelanggan tertentu, dalam solusi yang saya ikuti.
Ini yang pertama: biarkan Anda memiliki satu set faktur (transfer uang). Setiap faktur memiliki deskripsi teks, yang berisi informasi yang diperlukan tentang transfer (siapa, siapa, kapan, apa, dan untuk alasan apa dikirim). Sebagai contoh, perusahaan X mentransfer $ 10 ke perusahaan Y pada tanggal ini dan itu untuk ini dan itu. Teksnya cukup formal, tetapi ditulis dalam bahasa hidup. Bank secara khusus melatih orang-orang yang membaca teks ini dan kemudian memasukkan informasi yang terkandung di dalamnya ke dalam basis data.
Kami dapat memilih satu set entitas yang sesuai dengan kolom tabel dalam database (nama perusahaan, jumlah transfer, tanggalnya, jenis transfer, dll.) Dan belajar cara memilihnya secara otomatis. Setelah ini, tetap hanya memasukkan entitas yang dipilih dalam tabel, dan orang-orang yang sebelumnya membaca teks dan memasukkan informasi ke dalam basis data akan dapat melakukan tugas yang lebih penting dan berguna.
Kasus pengguna kedua adalah ini: Anda perlu menganalisis surat dengan pesanan dari toko online. Untuk melakukan ini, Anda perlu mengetahui nomor pesanan (sehingga semua surat yang terkait dengan pesanan ini dapat ditandai atau dimasukkan ke dalam folder terpisah), serta informasi bermanfaat lainnya - nama toko, daftar barang yang dipesan, jumlah cek, dll. Semua ini - nomor pesanan, nama toko, dll. - dapat dianggap sebagai entitas, dan juga mudah untuk belajar membedakannya menggunakan metode yang sekarang akan kita analisis.
Jika NER sangat berguna, mengapa itu tidak digunakan di mana-mana?
Mengapa tugas APM tidak selalu terpecahkan dan pelanggan komersial masih bersedia membayar bukan uang terkecil untuk solusinya? Tampaknya semuanya sederhana: untuk memahami bagian teks mana yang akan disorot, dan menyorotnya.
Namun dalam hidup, semuanya tidak begitu mudah, berbagai kesulitan muncul.
Kompleksitas klasik yang mencegah kita hidup dalam menyelesaikan berbagai masalah NLP adalah segala macam ambiguitas dalam bahasa. Misalnya, kata-kata dan homonim polisemantik (lihat contoh di
bagian 1 ). Ada jenis homonim yang berbeda yang secara langsung terkait dengan tugas NER - entitas yang sama sekali berbeda dapat disebut kata yang sama. Misalnya, mari kita beri kata "
Washington ." Apa ini Orang, kota, negara bagian, nama toko, nama anjing, objek, sesuatu yang lain? Untuk menyoroti bagian teks ini sebagai entitas tertentu, orang perlu mempertimbangkan banyak hal - konteks lokal (tentang apa teks sebelumnya), konteks global (pengetahuan tentang dunia). Seseorang memperhitungkan semua ini, tetapi tidak mudah untuk mengajarkan mesin untuk melakukan ini.
Kesulitan kedua adalah teknis, tetapi jangan meremehkannya. Tidak peduli bagaimana Anda mendefinisikan esensi, kemungkinan besar akan ada beberapa batasan dan kasus-kasus sulit - ketika Anda perlu menyoroti esensi, ketika Anda tidak perlu apa yang harus dimasukkan dalam rentang entitas, dan apa yang tidak, dll. (Tentu saja, jika esensi kami adalah bukan sesuatu yang sedikit variabel, seperti email; namun, Anda biasanya dapat membedakan entitas sepele seperti itu dengan metode sepele - menulis ekspresi reguler dan tidak memikirkan pembelajaran mesin apa pun).
Misalkan, misalnya, kami ingin menyorot nama toko.
Dalam teks "
Toko Detektor Logam Profesional Menyambut Anda ", kami hampir pasti ingin memasukkan kata "toko" dalam esensi kami - ini jelas bagian dari namanya.
Contoh lain adalah "
Anda disambut oleh Volkhonka Prestige, toko merek favorit Anda dengan harga terjangkau ." Mungkin, kata "toko" tidak boleh dimasukkan dalam anotasi - ini jelas bukan bagian dari namanya, tetapi hanya deskripsinya. Selain itu, jika Anda memasukkan kata ini dalam nama, Anda juga harus memasukkan kata "- favorit Anda," dan ini, mungkin, saya tidak ingin melakukannya sama sekali.
Contoh ketiga:
"Toko hewan peliharaan Nemo menulis untuk Anda. " Tidak jelas apakah "toko hewan peliharaan" adalah bagian dari nama atau tidak. Dalam contoh ini, tampaknya setiap pilihan akan memadai. Namun, penting bahwa kita perlu membuat pilihan ini dan memperbaikinya dalam instruksi untuk spidol, sehingga dalam semua teks contoh-contoh tersebut ditandai secara sama (jika ini tidak dilakukan, pembelajaran mesin pasti akan mulai membuat kesalahan karena kontradiksi dalam markup).
Ada banyak contoh garis batas seperti itu, dan jika kita ingin penandaannya konsisten, semuanya harus dimasukkan dalam instruksi untuk penanda tersebut. Bahkan jika contoh itu sendiri sederhana, mereka perlu diperhitungkan dan dihitung, dan ini akan membuat instruksi lebih besar dan lebih rumit.
Nah, semakin rumit instruksinya, di sana Anda membutuhkan spidol yang lebih berkualitas. Ini adalah satu hal ketika juru tulis perlu menentukan apakah surat itu adalah teks dari urutan atau tidak (meskipun ada seluk-beluk dan kasus batas di sini), dan itu adalah hal lain ketika juru tulis perlu membaca instruksi 50 halaman, menemukan entitas tertentu, memahami apa yang harus dimasukkan dalam penjelasan dan apa yang tidak.
Marker yang terampil mahal, dan biasanya tidak bekerja dengan sangat cepat. Anda akan menghabiskan uang dengan pasti, tetapi sama sekali bukan fakta bahwa Anda mendapatkan markup sempurna, karena jika instruksinya kompleks, bahkan orang yang memenuhi syarat dapat membuat kesalahan dan memahami sesuatu yang salah. Untuk mengatasi hal ini, banyak markup dari teks yang sama digunakan oleh orang yang berbeda, yang selanjutnya meningkatkan harga markup dan waktu pembuatannya. Menghindari proses ini atau bahkan menguranginya secara serius tidak akan berhasil: untuk belajar, Anda perlu memiliki serangkaian pelatihan berkualitas tinggi dengan ukuran yang masuk akal.
Ini adalah dua alasan utama mengapa NER belum menaklukkan dunia dan mengapa pohon apel masih belum tumbuh di Mars.
Bagaimana memahami apakah masalah NER telah dipecahkan secara berkualitas
Saya akan memberi tahu Anda sedikit tentang metrik yang digunakan orang untuk mengevaluasi kualitas solusi mereka untuk masalah NER, dan tentang kasus standar.
Metrik utama untuk tugas kami adalah pengukuran-f yang ketat. Jelaskan apa itu.
Mari kita memiliki markup uji (hasil kerja sistem kami) dan standar (markup yang benar dari teks yang sama). Lalu kita dapat menghitung dua metrik - akurasi dan kelengkapan. Akurasi adalah fraksi dari entitas positif sejati (yaitu entitas yang dipilih oleh kami dalam teks, yang juga ada dalam standar), relatif terhadap semua entitas yang dipilih oleh sistem kami. Dan kelengkapan adalah bagian dari entitas positif sejati sehubungan dengan semua entitas yang ada dalam standar. Contoh dari classifier yang sangat akurat, tetapi tidak lengkap adalah classifier yang memilih satu objek yang benar dalam teks dan tidak ada yang lain. Contoh dari pengklasifikasi yang sangat lengkap, tetapi umumnya tidak akurat adalah pengklasifikasi yang memilih entitas pada setiap segmen teks (dengan demikian, selain semua entitas standar, classifier kami mengalokasikan sejumlah besar sampah).
Ukuran-F adalah rata-rata harmonis dari akurasi dan kelengkapan, metrik standar.
Seperti yang kami jelaskan di bagian sebelumnya, membuat markup itu mahal. Oleh karena itu, tidak banyak bangunan yang dapat diakses dengan markup.
Ada beberapa variasi untuk bahasa Inggris - ada konferensi populer di mana orang berkompetisi dalam memecahkan masalah NER (dan markup dibuat untuk kompetisi). Contoh konferensi semacam itu di mana tubuh mereka dengan entitas bernama dibuat adalah MUC, TAC, CoNLL. Semua kasus ini hampir secara eksklusif berisi teks berita.
Badan utama di mana kualitas penyelesaian masalah NER dievaluasi adalah kasus CoNLL 2003 (di sini adalah
tautan ke kasus itu sendiri , di sini adalah
artikel tentang itu ). Ada sekitar 300 ribu token dan hingga 10 ribu entitas. Sekarang sistem SOTA (canggih) - yaitu, hasil terbaik saat ini) menunjukkan pada kasus ini ukuran-f dari urutan 0,93.
Untuk bahasa Rusia, semuanya jauh lebih buruk. Ada satu badan publik (
FactRuEval 2016 , ini adalah
artikel tentang itu , ini adalah
artikel tentang Habré ), dan itu sangat kecil - hanya ada 50 ribu token. Dalam hal ini, kasusnya cukup spesifik. Secara khusus, esensi LocOrg yang agak kontroversial (lokasi dalam konteks organisasi) menonjol dalam kasus ini, yang dikacaukan dengan organisasi dan lokasi, sehingga kualitas pemilihan yang terakhir lebih rendah daripada yang seharusnya.
Bagaimana mengatasi masalah NER
Pengurangan masalah NER ke masalah klasifikasi
Terlepas dari kenyataan bahwa entitas sering bertele-tele, tugas NER biasanya turun ke masalah klasifikasi di tingkat token, yaitu, masing-masing token milik salah satu dari beberapa kelas yang mungkin. Ada beberapa cara standar untuk melakukan ini, tetapi yang paling umum disebut skema BIOES. Skema ini untuk menambahkan beberapa awalan ke label entitas (misalnya, PER untuk orang atau ORG untuk organisasi), yang menunjukkan posisi token dalam rentang entitas. Lebih detail:
B - dari kata awal - token pertama dalam rentang entitas, yang terdiri dari lebih dari 1 kata.
Saya - dari kata-kata di dalam - inilah yang ada di tengah.
E - dari kata ending, ini adalah token terakhir dari entitas, yang terdiri dari lebih dari 1 elemen.
S itu tunggal. Kami menambahkan awalan ini jika entitas terdiri dari satu kata.
Jadi, kami menambahkan satu dari 4 awalan yang mungkin untuk setiap jenis entitas. Jika token bukan milik entitas apa pun, itu ditandai dengan label khusus, biasanya diberi label OUT atau O.
Kami memberi contoh. Marilah kita memiliki teks "
Karl Friedrich Jerome von Munchausen lahir di Bodenwerder ." Di sini ada satu entitas verbose - orang "Karl Friedrich Jerome von Münhausen" dan satu kata satu - lokasi "Bodenwerder".
Dengan demikian, BIOES adalah cara untuk memetakan proyeksi bentang atau anotasi ke tingkat token.
Jelas bahwa dengan markup ini kita dapat dengan jelas menetapkan batas-batas semua penjelasan entitas. Memang, tentang masing-masing token, kita tahu apakah benar suatu entitas dimulai dengan token ini atau berakhir di atasnya, yang berarti apakah akan mengakhiri anotasi entitas pada token yang diberikan, atau memperluasnya ke token berikutnya.
Sebagian besar peneliti menggunakan metode ini (atau variasinya dengan lebih sedikit label - BIOE atau BIO), tetapi memiliki beberapa kelemahan signifikan. Yang utama adalah bahwa skema tidak memungkinkan bekerja dengan entitas bersarang atau berpotongan. Misalnya, esensi "
Universitas Negeri Moskow dinamai M.V. Lomonosov ”adalah satu organisasi. Tapi Lomonosov sendiri adalah seseorang, dan akan menyenangkan untuk bertanya di markup. Dengan menggunakan metode markup yang dijelaskan di atas, kita tidak pernah dapat menyampaikan kedua fakta ini secara bersamaan (karena kita hanya dapat membuat satu tanda pada satu token). Oleh karena itu, token "Lomonosov" dapat menjadi bagian dari anotasi organisasi, atau bagian dari anotasi orang tersebut, tetapi tidak pernah keduanya sekaligus pada saat yang bersamaan.
Contoh lain dari entitas tertanam: "
Departemen Logika Matematika dan Teori Algoritma Fakultas Mekanika dan Matematika Universitas Negeri Moskow ". Di sini, idealnya, saya ingin membedakan 3 organisasi bersarang, tetapi metode markup di atas memungkinkan Anda untuk memilih 3 entitas yang terpisah, atau satu entitas yang menjelaskan seluruh fragmen.
Selain cara standar untuk mengurangi tugas ke klasifikasi di tingkat token, ada juga format data standar yang nyaman untuk menyimpan markup untuk tugas NER (serta untuk banyak tugas NLP lainnya). Format ini disebut
CoNLL-U .
Gagasan utama dari format ini adalah ini: kami menyimpan data dalam bentuk tabel, di mana satu baris sesuai dengan satu token, dan kolom sesuai dengan jenis atribut token tertentu (termasuk kata itu sendiri, bentuk kata). Dalam arti yang sempit, format CoNLL-U mendefinisikan jenis fitur mana (yaitu kolom) yang termasuk dalam tabel - total 10 jenis fitur untuk setiap token. Tetapi para peneliti biasanya mempertimbangkan format lebih luas dan memasukkan jenis-jenis fitur yang diperlukan untuk tugas dan metode penyelesaiannya.
Di bawah ini adalah contoh data dalam format seperti CoNLL-U, di mana 6 jenis atribut dipertimbangkan: jumlah kalimat saat ini dalam teks, bentuk kata (yaitu kata itu sendiri), lemma (bentuk kata awal), tag POS (bagian dari ucapan), morfologis karakteristik kata dan, akhirnya, label entitas yang dialokasikan pada token ini.

Bagaimana Anda memecahkan masalah NER sebelumnya?
Sebenarnya, masalah dapat diselesaikan tanpa pembelajaran mesin - dengan bantuan sistem berbasis aturan (dalam versi paling sederhana - dengan bantuan ekspresi reguler). Ini tampaknya ketinggalan jaman dan tidak efektif, namun, Anda perlu memahami jika area subjek Anda terbatas dan jelas dan jika entitas, dengan sendirinya, tidak memiliki banyak variabilitas, maka masalah NER diselesaikan menggunakan metode berbasis aturan dengan cepat dan efisien.
Misalnya, jika Anda perlu menyorot email atau entitas numerik (tanggal, uang atau nomor telepon), ekspresi reguler dapat membuat Anda lebih cepat sukses daripada mencoba menyelesaikan masalah menggunakan pembelajaran mesin.Namun, begitu ambiguitas linguistik dari berbagai jenis berperan (kami menulis tentang beberapa di atas), metode sederhana seperti itu berhenti bekerja dengan baik. Oleh karena itu, masuk akal untuk menggunakannya hanya untuk domain terbatas dan pada entitas yang sederhana dan jelas dapat dipisahkan dari teks lainnya.Terlepas dari semua hal di atas, di gedung-gedung akademik hingga akhir tahun 2000-an, SOTA menunjukkan sistem yang didasarkan pada metode klasik pembelajaran mesin. Mari kita lihat bagaimana mereka bekerja.Tanda
Sebelum embedding muncul, tanda utama token biasanya berupa bentuk kata - yaitu, indeks kata dalam kamus. Dengan demikian, setiap token diberi vektor Boolean dari dimensi besar (dimensi kamus), di mana di tempat kata indeks dalam kamus adalah 1, dan di tempat-tempat lain adalah 0.Selain bentuk kata, bagian-bagian ucapan (tag-POS) sering digunakan sebagai tanda-tanda token , karakter morfologis (untuk bahasa tanpa morfologi yang kaya - misalnya, bahasa Inggris, karakter morfologis praktis tidak berpengaruh), awalan (mis., beberapa karakter pertama kata), sufiks (sama, beberapa karakter terakhir dari token), keberadaan karakter khusus dalam token dan tampilan token.Dalam pengaturan klasik, tanda token yang sangat penting adalah jenis huruf kapitalnya, misalnya:- "Huruf pertama besar, sisanya kecil",
- "Semua huruf kecil",
- "Semua huruf besar",
- atau umumnya "kapitalisasi non-standar" (diamati, khususnya, untuk token "iPhone").
Jika token memiliki kapitalisasi non-standar, sangat mungkin bahwa dapat disimpulkan bahwa token adalah semacam entitas, dan jenis entitas ini hampir tidak orang atau lokasi.Selain semua ini, surat kabar - kamus entitas secara aktif digunakan. Kita tahu bahwa Petya, Elena, Akaki adalah nama-nama, Ivanov, Rustaveli, von Goethe adalah nama-nama, dan Mytishchi, Barcelona, Sao Paulo adalah kota-kota. Penting untuk dicatat bahwa kamus entitas saja tidak menyelesaikan masalah ("Moskow" dapat menjadi bagian dari nama organisasi, dan "Elena" dapat menjadi bagian dari lokasi), tetapi mereka dapat meningkatkan solusinya. Namun, tentu saja, meskipun ambiguitasnya, token yang dimiliki oleh kamus entitas jenis tertentu adalah atribut yang sangat baik dan signifikan (begitu signifikan sehingga biasanya hasil penyelesaian masalah NER dibagi menjadi 2 kategori - dengan dan tanpa orang-orang koran).Jika Anda tertarik pada bagaimana orang memecahkan masalah NER ketika pohon-pohon besar, saya sarankan Anda untuk melihat artikel tersebutNadeau dan Sekine (2007), Sebuah survei Pengakuan dan Klasifikasi Entitas Bernama . Metode yang dijelaskan ada, tentu saja, sudah ketinggalan zaman (bahkan jika Anda tidak dapat menggunakan jaringan saraf karena keterbatasan kinerja, Anda mungkin tidak akan menggunakan HMM, seperti yang dijelaskan dalam artikel, tetapi, katakanlah, peningkatan gradien), tetapi lihat deskripsi gejala mungkin masuk akal.Fitur menarik termasuk pola kapitalisasi (pola ringkasan dalam artikel di atas). Mereka masih dapat membantu dengan beberapa tugas NLP. Jadi, pada tahun 2018, ada upaya yang berhasil untuk menerapkan pola kapitalisasi (bentuk kata) ke metode jaringan saraf untuk menyelesaikan masalah.Bagaimana mengatasi masalah NER menggunakan jaringan saraf?
NLP hampir dari awal
Upaya sukses pertama untuk memecahkan masalah NER menggunakan jaringan saraf dilakukan pada tahun 2011 .Pada saat publikasi artikel ini, ia menunjukkan hasil SOTA pada paket CoNLL 2003. Tetapi Anda perlu memahami bahwa keunggulan model dibandingkan dengan sistem yang didasarkan pada algoritma pembelajaran mesin klasik cukup tidak signifikan. Dalam beberapa tahun ke depan, metode berdasarkan ML klasik menunjukkan hasil yang sebanding dengan metode jaringan saraf.Selain menggambarkan upaya sukses pertama untuk memecahkan masalah NER dengan bantuan jaringan saraf, artikel ini menjelaskan secara rinci banyak poin bahwa sebagian besar karya pada topik NLP tidak disertakan. Oleh karena itu, terlepas dari kenyataan bahwa arsitektur jaringan saraf yang dijelaskan dalam artikel sudah usang, masuk akal untuk membaca artikel tersebut. Ini akan membantu untuk memahami pendekatan dasar untuk jaringan saraf yang digunakan dalam menyelesaikan masalah NER (dan lebih luas, banyak tugas NLP lainnya).Kami akan memberi tahu Anda lebih banyak tentang arsitektur jaringan saraf yang dijelaskan dalam artikel.Para penulis memperkenalkan dua jenis arsitektur yang sesuai dengan dua cara yang berbeda untuk memperhitungkan konteks token:- baik menggunakan "jendela" dari lebar yang diberikan (pendekatan berbasis jendela),
- atau menganggap pendekatan berbasis kalimat sebagai konteks.
Dalam kedua kasus, tanda yang digunakan adalah embeddings dari bentuk kata, serta beberapa tanda manual - huruf besar, bagian dari ucapan, dll. Kami akan memberi tahu Anda lebih banyak tentang bagaimana mereka dihitungKami mendapat daftar masukan kata-kata dari kalimat kami: misalnya, " Kucing duduk di atas matras ".Anggaplah ada tanda K yang berbeda untuk satu token (misalnya, bentuk kata, bagian ucapan, huruf besar, apakah token kita adalah yang pertama atau terakhir dalam kalimat, dll., Dapat bertindak sebagai tanda-tanda seperti itu). Kita dapat mempertimbangkan semua tanda-tanda ini kategorikal (misalnya, bentuk kata sesuai dengan vektor Boolean panjang dimensi kamus, di mana 1 hanya pada koordinat indeks kata yang sesuai dalam kamus). Biarkan
 Apakah vektor Boolean sesuai dengan nilai atribut ke-i token j dalam kalimat.Penting untuk dicatat bahwa dalam pendekatan berbasis kalimat, di samping fitur kategorikal yang ditentukan oleh kata-kata, fitur tersebut digunakan - pergeseran relatif terhadap token, label yang coba kita tentukan. Nilai atribut ini untuk nomor token i akan menjadi i-core, di mana core adalah jumlah token yang labelnya sedang kami coba tentukan saat ini (atribut ini juga dianggap kategorikal, dan vektor untuknya dihitung dengan cara yang sama seperti yang lain).Langkah selanjutnya dalam menemukan tanda-tanda token adalah mengalikan masing-masing dengan matriks yang
Apakah vektor Boolean sesuai dengan nilai atribut ke-i token j dalam kalimat.Penting untuk dicatat bahwa dalam pendekatan berbasis kalimat, di samping fitur kategorikal yang ditentukan oleh kata-kata, fitur tersebut digunakan - pergeseran relatif terhadap token, label yang coba kita tentukan. Nilai atribut ini untuk nomor token i akan menjadi i-core, di mana core adalah jumlah token yang labelnya sedang kami coba tentukan saat ini (atribut ini juga dianggap kategorikal, dan vektor untuknya dihitung dengan cara yang sama seperti yang lain).Langkah selanjutnya dalam menemukan tanda-tanda token adalah mengalikan masing-masing dengan matriks yang 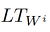 disebut Tabel Pencarian (dengan cara ini vektor Boolean "berubah" menjadi yang berkelanjutan). Ingat bahwa masing-masingAdalah vektor Boolean di mana di satu tempat harganya 1, dan di tempat lain itu 0. Dengan demikian, ketika mengalikan
disebut Tabel Pencarian (dengan cara ini vektor Boolean "berubah" menjadi yang berkelanjutan). Ingat bahwa masing-masingAdalah vektor Boolean di mana di satu tempat harganya 1, dan di tempat lain itu 0. Dengan demikian, ketika mengalikan pada
, salah satu baris dalam matriks kami dipilih. Baris ini adalah penyematan fitur token yang sesuai. Matriks (di mana saya dapat mengambil nilai dari 1 hingga K) adalah parameter dari jaringan kami, yang kami latih bersama dengan sisa lapisan jaringan saraf.Perbedaan antara metode bekerja dengan fitur-fitur kategorikal yang dijelaskan dalam artikel ini dan word2vec yang muncul kemudian (kami berbicara tentang bagaimana word2vec embeddings bentuk pra-dilatih di bagian sebelumnya dari posting kami) adalah bahwa matriks diinisialisasi secara acak di sini, dan dalam matriks word2vec yang pra-dilatih pada kasus besar pada tugas menentukan kata berdasarkan konteks (atau konteks dengan kata).Dengan demikian, untuk setiap token, vektor fitur kontinu diperoleh, yang merupakan gabungan dari hasil mengalikan semua jenis pada
.
Sekarang kita akan mengerti bagaimana tanda-tanda ini digunakan dalam pendekatan berbasis kalimat (berbasis jendela secara ideologis lebih sederhana). Adalah penting bahwa kami akan meluncurkan arsitektur kami secara terpisah untuk setiap token (yaitu, untuk kalimat "Kucing duduk di atas tikar" kami akan meluncurkan jaringan kami 6 kali). Tanda-tanda di setiap run dikumpulkan sama, dengan pengecualian tanda yang bertanggung jawab untuk posisi token, label yang kami coba tentukan - token inti.Kami mengambil vektor kontinu yang dihasilkan dari masing-masing token dan melewati mereka melalui konvolusi satu dimensi dengan filter dimensi tidak terlalu besar: 3-5. Dimensi filter sesuai dengan ukuran konteks yang diperhitungkan jaringan secara bersamaan, dan jumlah saluran sesuai dengan dimensi vektor kontinu sumber (jumlah dimensi embedding semua atribut). Setelah menerapkan konvolusi, kami mendapatkan matriks dimensi m oleh f, di mana m adalah sejumlah cara filter dapat diterapkan ke data kami (mis., Panjang kalimat dikurangi panjang filter ditambah satu), dan f adalah jumlah filter yang digunakan.Seperti hampir selalu ketika bekerja dengan konvolusi, setelah konvolusi kita menggunakan pooling - dalam hal ini max pooling (mis., Untuk setiap filter kita mengambil nilai maksimumnya pada seluruh kalimat), setelah itu kita mendapatkan vektor dimensi f. Dengan demikian, semua informasi yang terkandung dalam kalimat, yang mungkin kita perlukan ketika menentukan label token inti, dikompresi menjadi satu vektor (max pooling dipilih karena bukan rata-rata informasi pada kalimat yang penting bagi kita, tetapi nilai atribut di area terpentingnya) . "Konteks rata" ini memungkinkan kami untuk mengumpulkan tanda-tanda token kami di seluruh kalimat dan menggunakan informasi ini untuk menentukan label mana yang harus diterima oleh token inti.Selanjutnya, kita melewati vektor melalui perceptron multilayer dengan beberapa fungsi aktivasi (dalam artikel - HardTanh), dan sebagai lapisan terakhir kita menggunakan softmax yang sepenuhnya terhubung dari dimensi d, di mana d adalah jumlah label token yang mungkin.Dengan demikian, lapisan convolutional memungkinkan kita untuk mengumpulkan informasi yang terkandung dalam jendela dimensi filter, menyatukan - memilih informasi yang paling khas dalam kalimat (mengompresnya menjadi satu vektor), dan lapisan softmax - memungkinkan kita untuk menentukan label mana yang memiliki token nomor inti.CharCNN-BLSTM-CRF
Sekarang mari kita bicara tentang arsitektur CharCNN-BLSTM-CRF, yaitu, tentang apa yang SOTA pada periode 2016-2018 (pada tahun 2018 ada arsitektur berdasarkan embeddings pada model bahasa, setelah itu dunia NLP tidak akan pernah sama; tetapi saga ini bukan tentang ini). Sebagaimana diterapkan pada tugas NER, arsitektur pertama kali dijelaskan dalam artikel oleh Lample et al (2016) dan Ma & Hovy (2016) .Lapisan pertama dari jaringan sama dengan di dalam pipa NLP yang diuraikan dalam bagian sebelumnya dari posting kami .Pertama, atribut konteks-independen dari setiap token dalam kalimat dihitung. Gejala biasanya dikumpulkan dari tiga sumber. Yang pertama adalah embedding bentuk kata dari token, yang kedua adalah tanda simbolik, yang ketiga adalah tanda-tanda tambahan: informasi tentang kapitalisasi, bagian dari pidato, dll. Penggabungan semua tanda-tanda ini membentuk tanda tanda yang bebas konteks.Kami berbicara tentang embeddings bentuk kata secara rinci di bagian sebelumnya. Kami mencantumkan fitur tambahan, tetapi kami tidak mengatakan secara pasti bagaimana fitur tersebut tertanam di jaringan saraf. Jawabannya sederhana - untuk setiap kategori fitur tambahan, kita belajar dari awal tidak terlalu besar. Ini persis tabel pencarian dari paragraf sebelumnya, dan kami mengajari mereka persis seperti yang dijelaskan di sana.Sekarang kita akan tahu bagaimana tanda simbolik diatur.Pertama jawab pertanyaannya, apa itu. Sederhana - kami ingin setiap token mendapatkan vektor tanda ukuran konstan, yang hanya bergantung pada simbol yang membentuk token (dan tidak tergantung pada makna token dan atribut tambahan, seperti bagian dari ucapan).Kita sekarang beralih ke deskripsi arsitektur CharCNN (serta arsitektur CharRNN yang terkait dengannya). Kami diberi token, yang terdiri dari beberapa karakter. Untuk setiap simbol kita akan mengeluarkan vektor dari beberapa dimensi yang tidak terlalu besar (misalnya, 20) - simbol embedding. Embedded simbolik dapat dilakukan sebelum pelatihan, tetapi paling sering mereka belajar dari awal - ada banyak simbol bahkan dalam kasus yang tidak terlalu besar, dan emblem simbolik harus dilatih secara memadai.Jadi, kami memiliki embeddings dari semua simbol token kami, serta simbol tambahan yang menunjukkan batas token - paddings (biasanya embeddings paddings diinisialisasi dengan nol). Kami ingin mendapatkan dari vektor-vektor ini satu vektor dari beberapa dimensi konstan, yang merupakan tanda simbolis dari seluruh token dan mencerminkan interaksi antara simbol-simbol ini.Ada 2 metode standar.Yang sedikit lebih populer adalah menggunakan konvolusi satu dimensi (oleh karena itu bagian arsitektur ini disebut CharCNN). Kami melakukan ini dengan cara yang sama seperti yang kami lakukan dengan kata-kata dalam pendekatan berbasis kalimat dalam arsitektur sebelumnya.Jadi, kami melewatkan hiasan semua karakter melalui konvolusi dengan filter dengan dimensi yang tidak terlalu besar (misalnya, 3), kami mendapatkan vektor dimensi dari jumlah filter. Kami memproduksi penyatuan maksimum di atas vektor-vektor ini, kami mendapatkan 1 vektor dimensi dari jumlah filter. Ini berisi informasi tentang simbol kata dan interaksinya dan akan menjadi vektor tanda simbolik token.Cara kedua untuk mengubah embeddings simbolis menjadi satu vektor adalah untuk memberi mereka menjadi jaringan saraf berulang bilateral (BLSTM atau BiGRU; apa itu, kami dijelaskan di bagian pertama dari posting kami ). Biasanya tanda simbolis dari token hanyalah gabungan dari kondisi terakhir maju dan mundur RNN.Jadi, mari kita diberi vektor fitur token konteks-independen. Menurutnya, kami ingin mendapatkan atribut konteks-sensitif.Ini dilakukan dengan menggunakan BLSTM atau BiGRU. Pada saat ini, layer menghasilkan vektor, yang merupakan gabungan dari output yang sesuai dari forward dan reverse RNN. Vektor ini berisi informasi baik tentang token sebelumnya dalam penawaran (itu ada di RNN langsung), dan tentang yang berikut (itu dalam RNN terbalik). Oleh karena itu, vektor ini adalah tanda token yang peka konteks.Arsitektur ini dapat digunakan dalam berbagai tugas NLP, dan karenanya dianggap sebagai bagian penting dari pipa NLP.Namun, kami kembali ke masalah NER. Setelah menerima tanda-tanda konteks-sensitif dari semua token, kami ingin mendapatkan label yang benar untuk setiap token. Ini bisa dilakukan dengan banyak cara.Cara yang lebih sederhana dan lebih jelas adalah menggunakan, sebagai lapisan terakhir, dimensi d, sepenuhnya terhubung dengan softmax, di mana d adalah jumlah label token yang mungkin. Dengan demikian, kita mendapatkan probabilitas token untuk memiliki masing-masing label yang mungkin (dan kita dapat memilih yang paling memungkinkan dari mereka).Metode ini berfungsi, namun, memiliki kelemahan yang signifikan - label token dihitung secara independen dari label token lain. Kami menganggap token tetangga sendiri karena BiRNN, tetapi label token tidak hanya bergantung pada token tetangga, tetapi juga pada label mereka. Misalnya, terlepas dari token, label I-PER terjadi hanya setelah B-PER atau I-PER.Cara standar untuk menjelaskan interaksi antara jenis label adalah dengan menggunakan CRF (bidang acak bersyarat). Kami tidak akan menjelaskan secara detail apa itu ( di sinideskripsi yang baik diberikan), tetapi kami menyebutkan bahwa CRF mengoptimalkan seluruh rantai label secara keseluruhan, dan tidak setiap elemen dalam rantai ini.Jadi, kami menggambarkan arsitektur CharCNN-BLSTM-CRF, yang merupakan SOTA dalam tugas NER sampai munculnya embeddings pada model bahasa pada tahun 2018.Sebagai kesimpulan, mari kita bicara sedikit tentang pentingnya setiap elemen arsitektur. Untuk bahasa Inggris, CharCNN memberikan peningkatan ukuran-f sekitar 1%, CRF - sebesar 1-1,5%, dan tanda-tanda tambahan token tidak mengarah pada peningkatan kualitas (kecuali jika Anda menggunakan teknik yang lebih kompleks seperti pembelajaran multi-tugas, seperti dalam Wu et al. (2018) ). BiRNN adalah dasar arsitektur, yang, bagaimanapun, dapat digantikan oleh transformator .
Kami berharap bahwa kami dapat memberi pembaca beberapa gagasan tentang masalah APM. Meskipun ini adalah tugas yang penting, itu cukup sederhana, yang memungkinkan kami untuk menggambarkan solusinya dalam satu posting.Ivan Smurov,
Kepala Kelompok Penelitian Lanjutan NLP