Baru-baru ini, di grup pengenalan ABBYY, kami semakin menggunakan jaringan saraf dalam berbagai tugas. Sangat baik mereka telah membuktikan diri mereka terutama untuk jenis tulisan yang kompleks. Dalam posting sebelumnya, kami berbicara tentang bagaimana kami menggunakan jaringan saraf untuk mengenali skrip Jepang, Cina, dan Korea.
 Posting tentang pengenalan karakter Jepang dan Cina Pos pengenalan karakter Korea
Posting tentang pengenalan karakter Jepang dan Cina Pos pengenalan karakter KoreaDalam kedua kasus, kami menggunakan jaringan saraf untuk sepenuhnya menggantikan metode klasifikasi untuk simbol tunggal. Semua pendekatan mencakup banyak jaringan yang berbeda, dan beberapa tugas termasuk kebutuhan untuk bekerja secara memadai pada gambar yang bukan simbol. Model dalam situasi ini harus entah bagaimana memberi sinyal bahwa kita bukan simbol. Hari ini kita hanya akan berbicara tentang mengapa hal ini mungkin diperlukan secara prinsip, dan tentang pendekatan yang dapat digunakan untuk mencapai efek yang diinginkan.
Motivasi
Apa masalahnya? Mengapa bekerja pada gambar yang bukan karakter yang terpisah? Tampaknya Anda dapat membagi fragmen string menjadi karakter, mengklasifikasikannya semua dan mengumpulkan hasilnya dari ini, seperti, misalnya, pada gambar di bawah ini.
Ya, khususnya dalam hal ini, ini benar-benar dapat dilakukan. Tetapi, sayangnya, dunia nyata jauh lebih rumit, dan dalam praktiknya, ketika mengenali, Anda harus berurusan dengan distorsi geometris, blur, noda kopi dan kesulitan lainnya.
Akibatnya, Anda sering harus bekerja dengan fragmen seperti:
Saya pikir jelas bagi semua orang apa masalahnya. Menurut gambar fragmen semacam itu, tidaklah mudah untuk membaginya secara jelas menjadi simbol-simbol terpisah untuk mengenalinya secara terpisah. Kita harus mengajukan serangkaian hipotesis tentang di mana batas-batas antara karakter, dan di mana karakter itu sendiri. Untuk ini, kami menggunakan apa yang disebut grafik pembagian linier (GLD). Dalam gambar di atas, grafik ini ditunjukkan di bagian bawah: segmen hijau adalah busur dari GLD yang dibangun, yaitu, hipotesis tentang di mana simbol individu berada.
Dengan demikian, beberapa gambar yang meluncurkan modul pengenalan karakter individu, pada kenyataannya, bukan karakter individu, tetapi kesalahan segmentasi. Dan modul yang sama ini harus memberi sinyal bahwa di depannya, kemungkinan besar, bukan simbol, mengembalikan kepercayaan rendah untuk semua opsi pengenalan. Dan jika ini tidak terjadi, maka pada akhirnya, opsi yang salah untuk segmentasi fragmen ini dengan simbol dapat dipilih, yang akan sangat meningkatkan jumlah kesalahan pembagian linier.
Selain kesalahan segmentasi, model juga harus tahan terhadap sampah apriori dari halaman. Misalnya, di sini gambar seperti itu juga dapat dikirim untuk mengenali satu karakter:
Jika Anda hanya mengklasifikasikan gambar tersebut ke karakter yang terpisah, maka hasil klasifikasi akan jatuh ke dalam hasil pengenalan. Selain itu, pada kenyataannya, gambar-gambar ini hanyalah artefak dari algoritma binarisasi, tidak ada yang sesuai dengan mereka dalam hasil akhir. Jadi bagi mereka juga, Anda harus dapat mengembalikan kepercayaan yang rendah pada klasifikasi.
Semua gambar serupa: kesalahan segmentasi, sampah apriori, dll. kita selanjutnya akan disebut contoh negatif. Gambar simbol nyata akan disebut contoh positif.
Masalah pendekatan jaringan saraf
Sekarang mari kita ingat bagaimana jaringan saraf normal bekerja untuk mengenali karakter individu. Biasanya ini adalah semacam lapisan konvolusional dan terhubung sepenuhnya, dengan bantuan yang vektor probabilitas milik masing-masing kelas tertentu dibentuk dari gambar input.
Selain itu, jumlah kelas bertepatan dengan ukuran alfabet. Selama pelatihan jaringan saraf, gambar simbol nyata disajikan dan diajarkan untuk mengembalikan probabilitas tinggi untuk kelas simbol yang benar.
Dan apa yang akan terjadi jika jaringan saraf dimasukkan dengan kesalahan segmentasi dan sampah apriori? Bahkan, secara teoritis murni, apa pun bisa terjadi, karena jaringan tidak melihat gambar seperti itu sama sekali dalam proses pembelajaran. Untuk beberapa gambar, mungkin beruntung, dan jaringan akan mengembalikan probabilitas rendah untuk semua kelas. Tetapi dalam beberapa kasus, jaringan mungkin mulai mencari di antara sampah di pintu masuk untuk garis akrab simbol tertentu, misalnya, simbol "A" dan mengenalinya dengan probabilitas 0,99.
Dalam praktiknya, ketika kami bekerja, misalnya, pada model jaringan saraf untuk penulisan Jepang dan Cina, penggunaan probabilitas kasar dari output jaringan menyebabkan munculnya sejumlah besar kesalahan segmentasi. Dan, terlepas dari kenyataan bahwa model simbolis bekerja sangat baik berdasarkan gambar, itu tidak mungkin untuk mengintegrasikannya ke dalam algoritma pengenalan penuh.
Seseorang mungkin bertanya: mengapa dengan jaringan saraf timbul masalah seperti itu? Mengapa atribut classifier tidak bekerja dengan cara yang sama, karena mereka juga belajar berdasarkan gambar, yang berarti bahwa tidak ada contoh negatif dalam proses pembelajaran?
Perbedaan mendasar, menurut saya, adalah bagaimana tepatnya tanda dibedakan dari gambar simbol. Dalam kasus penggolong biasa, seseorang sendiri menentukan cara mengekstraknya, dipandu oleh beberapa pengetahuan tentang perangkat mereka. Dalam kasus jaringan saraf, ekstraksi fitur juga merupakan bagian yang terlatih dari model: mereka dikonfigurasi sehingga dimungkinkan untuk membedakan karakter dari kelas yang berbeda dengan cara terbaik. Dan dalam praktiknya, ternyata karakteristik yang dijelaskan oleh seseorang lebih tahan terhadap gambar yang bukan simbol: mereka cenderung tidak sama dengan gambar simbol nyata, yang berarti bahwa nilai kepercayaan yang lebih rendah dapat dikembalikan kepada mereka.
Meningkatkan Stabilitas Model dengan Kehilangan Center
Karena masalahnya, menurut kecurigaan kami, adalah bagaimana jaringan saraf memilih tanda-tanda, kami memutuskan untuk mencoba memperbaiki bagian khusus ini, yaitu, untuk belajar bagaimana menyoroti beberapa tanda "baik". Dalam pembelajaran yang mendalam, ada bagian terpisah yang dikhususkan untuk topik ini, dan itu disebut "Representasi Pembelajaran". Kami memutuskan untuk mencoba berbagai pendekatan yang berhasil di bidang ini. Sebagian besar solusi diusulkan untuk pelatihan representasi dalam masalah pengenalan wajah.
Pendekatan yang dijelaskan dalam artikel "
Pendekatan Pembelajaran Fitur Diskriminatif untuk Pengenalan Wajah Dalam " tampak cukup baik. Gagasan utama penulis: untuk menambahkan istilah tambahan ke fungsi kerugian, yang akan mengurangi jarak Euclidean di ruang fitur antara elemen-elemen dari kelas yang sama.
Untuk berbagai nilai bobot istilah ini dalam fungsi kerugian umum, orang dapat memperoleh berbagai gambar di ruang atribut:
Gambar ini menunjukkan distribusi elemen sampel uji dalam ruang atribut dua dimensi. Masalah mengklasifikasikan angka tulisan tangan dipertimbangkan (sampel MNIST).
Salah satu sifat penting yang dinyatakan oleh penulis: peningkatan kemampuan generalisasi dari karakteristik yang diperoleh untuk orang-orang yang tidak dalam pelatihan. Wajah-wajah beberapa orang masih berada di dekatnya, dan wajah-wajah orang yang berbeda berjauhan.
Kami memutuskan untuk memeriksa apakah properti serupa untuk pemilihan karakter dipertahankan. Pada saat yang sama, mereka dipandu oleh logika berikut: jika dalam ruang fitur semua elemen dari kelas yang sama dikelompokkan secara kompak di dekat satu titik, maka tanda-tanda untuk contoh negatif akan lebih kecil kemungkinannya berada di dekat titik yang sama. Oleh karena itu, sebagai kriteria utama untuk penyaringan, kami menggunakan jarak Euclidean ke pusat statistik kelas tertentu.
Untuk menguji hipotesis, kami melakukan percobaan berikut: kami melatih model untuk mengenali subset kecil karakter Jepang dari huruf suku kata (yang disebut kana). Selain sampel pelatihan, kami juga memeriksa 3 basis buatan dari contoh negatif:
- Pasangan - satu set pasangan karakter Eropa
- Potongan - potongan garis Jepang memotong celah, bukan karakter
- Bukan kana - karakter lain dari alfabet Jepang yang tidak terkait dengan subset yang dianggap
Kami ingin membandingkan pendekatan klasik dengan fungsi Cross Entropy loss dan pendekatan dengan Center Loss dalam kemampuan mereka untuk menyaring contoh negatif. Kriteria penyaringan untuk contoh negatif berbeda. Dalam kasus Cross Entropy Loss, kami menggunakan respon jaringan dari lapisan terakhir, dan dalam kasus Center Loss, kami menggunakan jarak Euclidean ke pusat statistik kelas di ruang atribut. Dalam kedua kasus, kami memilih ambang statistik yang sesuai, di mana tidak lebih dari 3% contoh positif dari sampel uji dihilangkan dan melihat proporsi contoh negatif dari setiap basis data yang dihilangkan pada ambang ini.

Seperti yang Anda lihat, pendekatan Center Loss benar-benar melakukan pekerjaan yang lebih baik untuk menyaring contoh negatif. Selain itu, dalam kedua kasus, kami tidak memiliki gambar contoh negatif dalam proses pembelajaran. Ini sebenarnya sangat bagus, karena dalam kasus umum, mendapatkan basis perwakilan dari semua contoh negatif dalam masalah OCR bukanlah tugas yang mudah.
Kami menerapkan pendekatan ini pada masalah mengenali karakter Jepang (pada tingkat kedua dari model dua tingkat), dan hasilnya memuaskan kami: jumlah kesalahan pembagian linier berkurang secara signifikan. Meskipun kesalahan tetap ada, mereka sudah bisa diklasifikasikan menurut jenis tertentu: apakah itu pasang angka atau hieroglif dengan simbol tanda baca yang macet. Untuk kesalahan ini, sudah dimungkinkan untuk membentuk beberapa basis sintetis dari contoh negatif dan menggunakannya dalam proses pembelajaran. Tentang bagaimana ini bisa dilakukan, dan akan dibahas lebih lanjut.
Menggunakan dasar contoh negatif dalam pelatihan
Jika Anda memiliki beberapa koleksi contoh negatif, maka bodoh untuk tidak menggunakannya dalam proses pembelajaran. Tapi mari kita pikirkan bagaimana ini bisa dilakukan.
Pertama, pertimbangkan skema paling sederhana: kami mengelompokkan semua contoh negatif ke dalam kelas yang terpisah dan menambahkan neuron lain ke lapisan output yang sesuai dengan kelas ini. Sekarang pada output kami memiliki distribusi probabilitas untuk kelas
N + 1 . Dan kami mengajarkan ini Kehilangan Lintas Entropi yang biasa.
Kriteria bahwa contohnya negatif dapat dianggap sebagai nilai respons jaringan baru yang sesuai. Tetapi terkadang karakter nyata dengan kualitas yang tidak terlalu tinggi dapat diklasifikasikan sebagai contoh negatif. Apakah mungkin untuk membuat transisi antara contoh positif dan negatif lebih lancar?
Bahkan, Anda dapat mencoba untuk tidak menambah jumlah output, tetapi cukup membuat model, ketika belajar, mengembalikan respons rendah untuk semua kelas ketika menerapkan contoh negatif ke input. Untuk melakukan ini, kita tidak bisa secara eksplisit menambahkan output
N + 1 ke model, tetapi cukup menambahkan nilai
–max dari respons untuk semua kelas lainnya ke elemen
N + 1st . Kemudian, ketika menerapkan contoh negatif ke input, jaringan akan mencoba melakukan sebanyak mungkin, yang berarti bahwa respons maksimum akan mencoba membuat sesedikit mungkin.
Skema yang tepat seperti itu kami terapkan pada tingkat pertama dari model dua tingkat untuk Jepang dikombinasikan dengan pendekatan Center Loss di tingkat kedua. Dengan demikian, beberapa contoh negatif disaring di tingkat pertama, dan beberapa di tingkat kedua. Dalam kombinasi, kami telah berhasil mendapatkan solusi yang siap untuk dimasukkan ke dalam algoritma pengenalan umum.
Secara umum, orang mungkin juga bertanya: bagaimana menggunakan basis contoh negatif dalam pendekatan dengan Center Loss? Ternyata entah bagaimana kita perlu menunda contoh negatif yang terletak dekat dengan pusat statistik kelas di ruang atribut. Bagaimana cara menempatkan logika ini ke dalam fungsi kerugian?
Biarkan
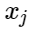
- tanda-tanda contoh negatif, dan
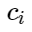
- pusat kelas. Kemudian kita dapat mempertimbangkan tambahan berikut untuk fungsi kerugian:
Di sini
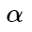
- celah tertentu yang diijinkan antara pusat dan contoh negatif, di mana hukuman dikenakan pada contoh negatif.
Kombinasi Center Loss dengan aditif yang dijelaskan di atas, kami telah berhasil menerapkan, misalnya, untuk beberapa pengklasifikasi individu dalam tugas mengenali karakter Korea.
Kesimpulan
Secara umum, semua pendekatan untuk menyaring apa yang disebut "contoh negatif" yang dijelaskan di atas dapat diterapkan dalam masalah klasifikasi ketika Anda memiliki beberapa kelas yang secara implisit sangat tidak seimbang relatif terhadap yang lain tanpa basis perwakilan yang baik, yang bagaimanapun perlu diperhitungkan bagaimanapun juga. . OCR hanyalah beberapa tugas khusus di mana masalah ini paling akut.
Secara alami, semua masalah ini muncul hanya ketika menggunakan jaringan saraf sebagai model utama untuk mengenali karakter individu. Saat menggunakan pengenalan garis ujung ke ujung sebagai model terpisah secara keseluruhan, masalah seperti itu tidak muncul.
Grup Teknologi Baru OCR