Halo semuanya. Pustaka jaringan saraf dijelaskan dalam
artikel terakhir saya. Di sini saya memutuskan untuk menunjukkan bagaimana Anda dapat menggunakan jaringan terlatih dari TF (Tensorflow) dalam keputusan Anda, dan apakah itu layak dilakukan.
Di bawah potongan, perbandingan dengan implementasi asli TF, aplikasi demo untuk mengenali gambar, juga ... kesimpulan. Tolong, siapa yang peduli.
Anda dapat mengetahui cara kerja ResNet, misalnya, di
sini .
Berikut adalah struktur jaringan dalam angka:
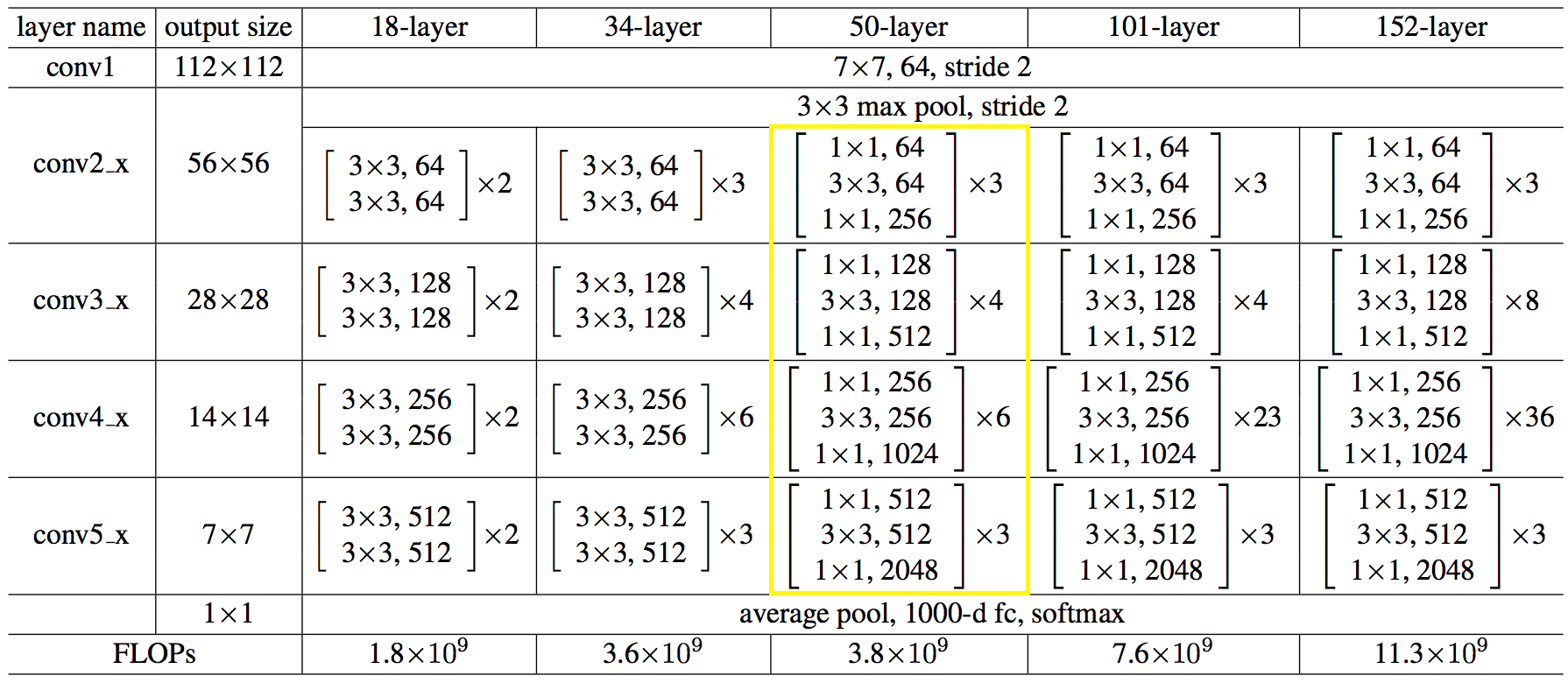
Kode tersebut ternyata tidak lebih sederhana dan tidak lebih rumit dari python.
Kode C ++ untuk membuat jaringan:auto net = sn::Net(); net.addNode("In", sn::Input(), "conv1") .addNode("conv1", sn::Convolution(64, 7, 3, 2, sn::batchNormType::beforeActive, sn::active::none, mode), "pool1_pad") .addNode("pool1_pad", sn::Pooling(3, 2, sn::poolType::max, mode), "res2a_branch1 res2a_branch2a"); convBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, 1, "res2a_branch", "res2b_branch2a res2b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256 }, 3, "res2b_branch", "res2c_branch2a res2c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 64, 64, 256}, 3, "res2c_branch", "res3a_branch1 res3a_branch2a", mode); convBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, 2, "res3a_branch", "res3b_branch2a res3b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3b_branch", "res3c_branch2a res3c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3c_branch", "res3d_branch2a res3d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 128, 128, 512 }, 3, "res3d_branch", "res4a_branch1 res4a_branch2a", mode); convBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, 2, "res4a_branch", "res4b_branch2a res4b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4b_branch", "res4c_branch2a res4c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4c_branch", "res4d_branch2a res4d_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4d_branch", "res4e_branch2a res4e_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4e_branch", "res4f_branch2a res4f_branchSum", mode); idntBlock(net, vector<uint32_t>{ 256, 256, 1024 }, 3, "res4f_branch", "res5a_branch1 res5a_branch2a", mode); convBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, 2, "res5a_branch", "res5b_branch2a res5b_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5b_branch", "res5c_branch2a res5c_branchSum", mode); idntBlock(net, vector<uint32_t>{ 512, 512, 2048 }, 3, "res5c_branch", "avg_pool", mode); net.addNode("avg_pool", sn::Pooling(7, 7, sn::poolType::avg, mode), "fc1000") .addNode("fc1000", sn::FullyConnected(1000, sn::active::none, mode), "LS") .addNode("LS", sn::LossFunction(sn::lossType::softMaxToCrossEntropy), "Output");
→ Kode lengkap tersedia
di siniAnda dapat melakukannya dengan lebih mudah, memuat arsitektur jaringan dan bobot dari file,
seperti ini: string archPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Struct.json", weightPath = "c:/cpp/other/skyNet/example/resnet50/resNet50Weights.dat"; std::ifstream ifs; ifs.open(archPath, std::ifstream::in); if (!ifs.good()){ cout << "error open file : " + archPath << endl; system("pause"); return false; } ifs.seekg(0, ifs.end); size_t length = ifs.tellg(); ifs.seekg(0, ifs.beg); string jnArch; jnArch.resize(length); ifs.read((char*)jnArch.data(), length);
Membuat aplikasi untuk menarik. Anda dapat mengunduh
dari sini . Volume besar karena bobot jaringan. Sumber ada di sana, bisa Anda gunakan sebagai contoh.
Aplikasi ini dibuat hanya untuk artikel, itu tidak akan didukung, oleh karena itu tidak termasuk dalam repositori proyek.

Sekarang, apa yang terjadi dibandingkan dengan TF.
Indikasi setelah menjalankan 100 gambar, rata-rata. Mesin: i5-2400, GF1050, Win7, MSVC12.
Nilai hasil pengenalan cocok dengan karakter ke-3.
→
Uji kodePadahal, semuanya menyedihkan tentu saja.
Untuk CPU, saya memutuskan untuk tidak menggunakan MKL-DNN, saya sendiri berpikir untuk menyelesaikannya: mendistribusikan kembali memori untuk pembacaan berurutan, memuat register vektor secara maksimal. Mungkin perlu untuk menghasilkan perkalian matriks, dan / atau beberapa peretasan lainnya. Beristirahat di sini, pada awalnya itu lebih buruk, akan lebih tepat untuk menggunakan MKL sama saja.
Pada GPU, waktu dihabiskan untuk menyalin memori dari / ke memori kartu video, dan tidak semua operasi dilakukan pada GPU.
Kesimpulan apa yang bisa diambil dari semua keributan ini:
- tidak untuk pamer, tetapi untuk menggunakan solusi terbukti yang terkenal, mereka datang ke pikiran sudah kurang lebih seperti. Dia duduk di mxnet sendiri sekali, dan bekerja keras dengan penggunaan asli, lebih pada yang di bawah ini;
- Jangan mencoba menggunakan antarmuka C asli kerangka kerja ML. Dan gunakan dalam bahasa yang menjadi fokus pengembang, yaitu python.
Cara mudah untuk menggunakan fungsionalitas ML dari bahasa Anda adalah dengan membuat proses layanan pada python dan mengirim gambar ke soket, Anda mendapatkan pembagian tanggung jawab dan tidak adanya kode yang berat.
Mungkin semuanya. Artikel itu singkat, tetapi kesimpulannya, saya pikir, sangat berharga, dan tidak hanya berlaku untuk ML.
Terima kasih
PS:
jika ada yang punya keinginan dan kekuatan untuk mencoba tetap mengejar TF,
selamat datang !)
PS2:
menurunkan tangannya lebih awal. Dia berhenti merokok, mengambilnya lagi dan semuanya beres.
Untuk CPU, casting ke perkalian matriks membantu, seperti yang saya pikir.
Untuk GPU, saya memilih semua operasi dalam lib yang terpisah, sehingga tanpa menyalin ke CPU dan sebaliknya, satu-satunya minus dari pendekatan ini adalah bahwa saya harus menulis ulang (menduplikasi) semua operator, meskipun beberapa hal bertepatan, tetapi saya tidak menghubungkan mereka.
Secara umum, begini caranya sekarang:
Artinya, setidaknya kesimpulannya ternyata lebih cepat dari pada TF.
Kode tes tidak berubah.