Jika jalan raya diajarkan di sekolah, buku pelajaran tentang hal ini akan memiliki tugas seperti itu. “Jaringan sosial N memiliki 2.000 server, di mana 150.000 file 900 MB setiap kode PHP dan staging cluster untuk 50 mesin. Kode ini digunakan 2 kali sehari ke server, kode diperbarui setiap beberapa menit pada cluster pementasan, dan ada "hotfix" tambahan - set kecil file yang diletakkan di luar giliran semua atau pada bagian yang dipilih dari server, tanpa menunggu perhitungan penuh. Pertanyaan: apakah kondisi seperti itu dianggap beban tinggi dan bagaimana cara menggunakannya? Tulis setidaknya 5 opsi penempatan. " Kita hanya bisa bermimpi tentang buku masalah hyload, tetapi sekarang kita sudah tahu bahwa
Yuri Nasretdinov (
youROCK ) pasti akan menyelesaikan masalah ini dan mendapatkan "lima".
Yuri tidak berhenti pada solusi yang sederhana, tetapi juga membuat laporan di mana ia mengungkapkan konsep konsep "menyebarkan kode", berbicara tentang solusi klasik dan alternatif untuk penyebaran PHP skala besar, menganalisis kinerja mereka dan mempresentasikan sistem penyebaran MDK.
Konsep "menyebarkan kode"
Dalam bahasa Inggris, istilah "mengerahkan" berarti menyiagakan pasukan, dan dalam bahasa Rusia kita kadang-kadang mengatakan "mengisi kode ke dalam pertempuran," yang berarti hal yang sama. Anda mengambil kode di yang sudah dikompilasi atau yang asli, jika itu PHP, unduh ke server yang melayani lalu lintas pengguna, dan kemudian, secara ajaib, entah bagaimana mengalihkan beban dari satu versi kode ke yang lain. Semua ini termasuk dalam konsep "penyebaran kode".
Proses penyebaran biasanya terdiri dari beberapa tahap.
- Mendapatkan kode dari repositori dengan cara apa pun yang Anda suka: clone, fetch, checkout.
- Majelis - bangun . Untuk kode PHP, fase pembuatan mungkin tidak ada. Dalam kasus kami, ini adalah, biasanya, pembuatan file terjemahan otomatis, mengunggah file statis ke CDN dan beberapa operasi lainnya.
- Pengiriman ke server akhir - penyebaran.
Setelah semuanya terpasang, fase penyebaran segera dimulai -
kode dituangkan ke server produksi . Tentang fase inilah
Badoo akan dibahas.
Sistem penempatan lama di Badoo
Jika Anda memiliki file dengan gambar sistem file, lalu bagaimana cara memasangnya? Di Linux, Anda perlu membuat
perangkat Loop perantara , melampirkan file ke dalamnya, dan setelah itu Anda sudah bisa memasang perangkat blok ini.
Perangkat loop adalah penopang yang dibutuhkan Linux untuk me-mount gambar sistem file. Ada OS di mana kruk ini tidak diperlukan.

Bagaimana proses penyebaran menggunakan file, yang juga kami sebut "loop" untuk kesederhanaan? Ada direktori tempat kode sumber dan konten yang dibuat secara otomatis berada. Kami mengambil gambar kosong dari sistem file - sekarang EXT2, dan sebelumnya kami menggunakan ReiserFS. Kami memasang gambar kosong dari sistem file dalam direktori sementara, menyalin semua konten di sana. Jika kami tidak perlu melakukan sesuatu untuk produksi, maka kami tidak menyalin semuanya. Setelah itu, unmount perangkat, dan dapatkan gambar dari sistem file di mana file yang diperlukan berada. Selanjutnya, kami
mengarsipkan gambar dan mengunggah ke semua server , di sana kami unzip dan memasangnya.
Solusi lain yang ada
Pertama, mari kita berterima kasih kepada
Richard Stallman - tanpa lisensi, sebagian besar utilitas yang kita gunakan tidak akan ada.

Saya secara konvensional membagi metode penempatan kode PHP ke dalam 4 kategori.
- Berdasarkan sistem kontrol versi : svn up, git pull, hg up.
- Berdasarkan utilitas rsync - ke direktori baru atau "di atas".
- Sebarkan satu file - apa pun yang terjadi: phar, hhbc, loop.
- Cara khusus yang disarankan Rasmus Lerdorf adalah rsync, 2 direktori dan realpath_root .
Setiap metode memiliki pro dan kontra, karena itu kami mengabaikannya. Pertimbangkan 4 metode ini secara lebih rinci.
Penyebaran berdasarkan sistem kontrol versi svn up
Saya memilih SVN bukan karena kebetulan - menurut pengamatan saya, dalam bentuk ini penyebaran justru ada dalam kasus SVN. Sistem ini cukup
ringan , memungkinkan Anda
untuk menggunakan
dengan cepat dan mudah - jalankan saja svn dan Anda selesai.
Tetapi metode ini memiliki satu minus besar: jika Anda melakukan svn, dan dalam proses memperbarui kode sumber, ketika permintaan baru datang dari repositori, mereka akan melihat status sistem file yang tidak ada di repositori. Anda akan memiliki sebagian file baru, dan sebagian yang lama - ini adalah
metode penyebaran non-atom yang tidak cocok untuk beban tinggi, tetapi hanya untuk proyek kecil. Meskipun demikian, saya tahu proyek yang masih dikerahkan dengan cara ini, dan sejauh ini semuanya bekerja untuk mereka.
Penerapan berdasarkan utilitas rsync
Ada dua opsi untuk melakukan hal ini: unggah file menggunakan utilitas langsung ke server dan unggah "di atas" - perbarui.
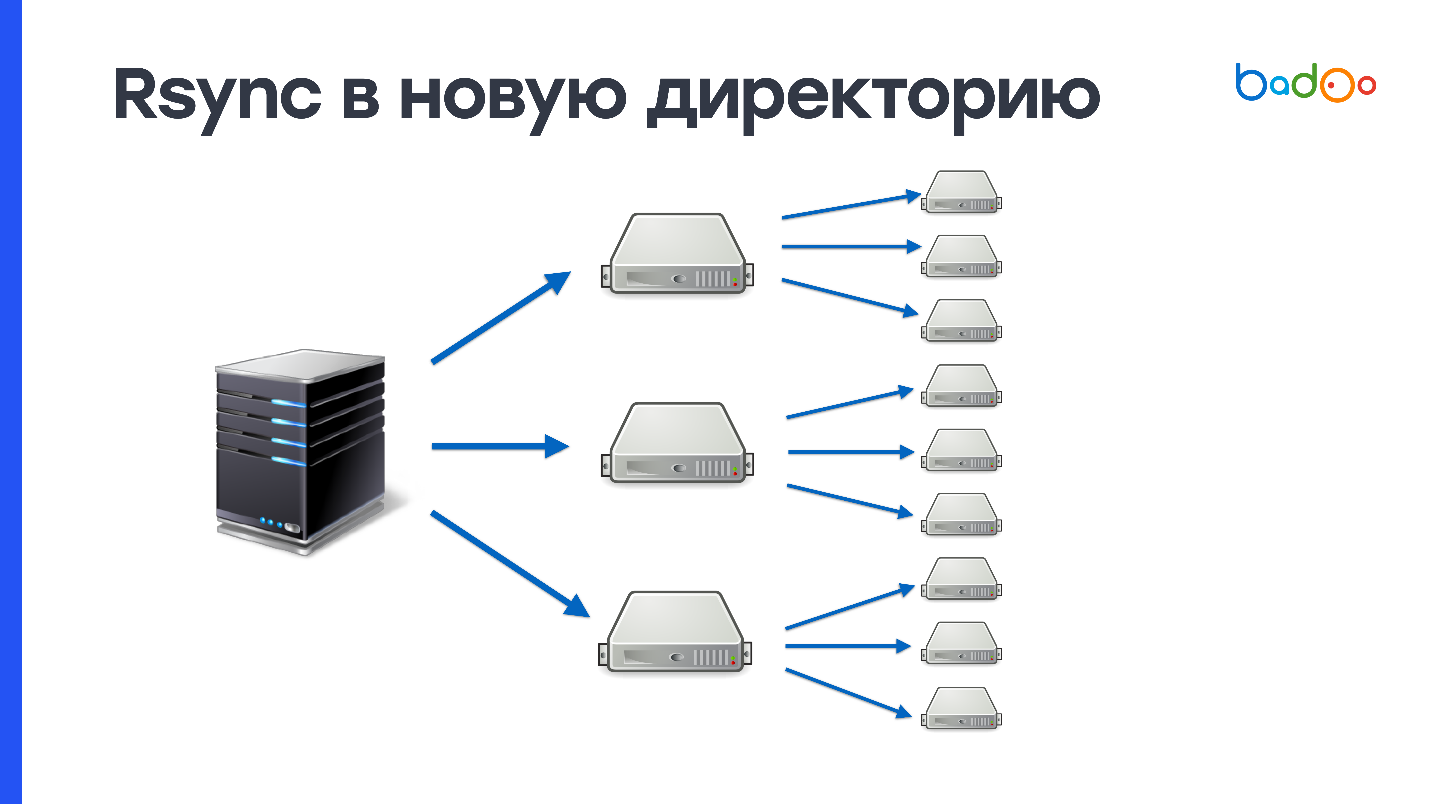
rsync ke direktori baru
Karena Anda pertama kali sepenuhnya menuangkan semua kode ke direktori yang belum ada di server, dan baru kemudian beralih lalu lintas, metode ini bersifat
atomik - tidak ada yang melihat status perantara. Dalam kasus kami, membuat 150.000 file dan menghapus direktori lama, yang juga memiliki 150.000 file, menciptakan
beban besar pada subsistem disk . Kami menggunakan hard disk sangat aktif, dan server di suatu tempat selama satu menit tidak terasa baik setelah operasi seperti itu. Karena kami memiliki 2000 server, maka diperlukan untuk mengisi 900 MB 2000 kali.
Skema ini dapat ditingkatkan jika Anda pertama kali mengunggah ke sejumlah server perantara, misalnya, 50, dan kemudian menambahkannya ke yang lain. Ini memecahkan kemungkinan masalah dengan jaringan, tetapi masalah membuat dan menghapus sejumlah besar file tidak hilang di mana pun.
rsync di atas
Jika Anda menggunakan rsync, maka Anda tahu bahwa utilitas ini tidak hanya dapat mengisi seluruh direktori, tetapi juga memperbarui yang sudah ada. Mengirim hanya perubahan adalah nilai tambah, tetapi karena kami mengunggah perubahan ke direktori yang sama tempat kami menyajikan kode pertempuran, juga akan ada semacam status perantara - ini adalah minus.
Mengirimkan perubahan berfungsi seperti ini. Rsync membuat daftar file di sisi server dari mana penyebaran dilakukan, dan di sisi penerima. Setelah itu, ia menghitung stat dari semua file dan mengirim seluruh daftar ke sisi penerima. Pada server dari mana penyebaran sedang berlangsung, perbedaan antara nilai-nilai ini dipertimbangkan, dan ditentukan file mana yang harus dikirim.
Dalam kondisi kami, proses ini membutuhkan sekitar
3 MB lalu lintas dan 1 detik waktu prosesor . Tampaknya ini tidak banyak, tetapi kami memiliki 2.000 server, dan semuanya ternyata setidaknya satu menit dari waktu prosesor. Ini bukan metode yang cepat, tetapi jelas lebih baik daripada mengirim semuanya melalui rsync. Tetap entah bagaimana menyelesaikan masalah atomicity dan akan menjadi hampir sempurna.
Menyebarkan satu file
Apa pun file tunggal yang Anda unggah, relatif mudah dilakukan menggunakan BitTorrent atau utilitas UFTP. Satu file lebih mudah di-unzip, dapat diganti secara atom pada Unix, dan mudah untuk memeriksa integritas file yang dihasilkan pada build server dan dikirim ke mesin target dengan menghitung jumlah MD5 atau SHA-1 dari file (dalam kasus rsync, Anda tidak tahu apa yang ada di server tujuan) )
Untuk hard drive, perekaman berurutan merupakan nilai tambah besar - file 900 MB akan ditulis ke hard drive yang tidak digunakan dalam waktu sekitar 10 detik. Tetapi Anda masih perlu merekam 900 MB yang sama ini dan mentransfernya melalui jaringan.
Penyimpangan liris tentang UFTP
Utilitas Open Source ini pada awalnya dibuat untuk mentransfer file melalui jaringan dengan penundaan yang lama, misalnya, melalui jaringan berbasis satelit. Tetapi UFTP ternyata cocok untuk mengunggah file ke sejumlah besar mesin, karena berfungsi menggunakan protokol UDP berdasarkan Multicast. Satu alamat Multicast dibuat, semua mesin yang ingin menerima file berlangganan padanya, dan sakelar menyediakan pengiriman salinan paket ke setiap mesin. Jadi kami mengalihkan beban pengiriman data ke jaringan. Jika jaringan Anda dapat menangani ini, maka metode ini bekerja lebih baik daripada BitTorrent.
Anda dapat mencoba utilitas Open Source ini di cluster Anda. Terlepas dari kenyataan bahwa ia bekerja di atas UDP, ia memiliki mekanisme NACK - pengakuan negatif, yang memaksa meneruskan kembali paket yang hilang pada saat pengiriman.
Ini adalah cara yang andal untuk digunakan .
Opsi penyebaran file tunggal
tar.gzOpsi yang menggabungkan kelemahan dari kedua pendekatan. Anda tidak hanya harus menulis 900 MB ke disk secara berurutan, setelah itu Anda harus menulis 900 MB yang sama lagi secara acak baca-tulis dan membuat 150.000 file. Metode ini bahkan lebih buruk dalam kinerja daripada rsync.
PharPHP mendukung arsip dalam format phar (PHP Archive), tahu bagaimana memberikan kontennya dan memasukkan file. Tetapi tidak semua proyek mudah dimasukkan ke dalam satu phar - Anda memerlukan adaptasi kode. Hanya karena kode dari arsip ini tidak berfungsi. Selain itu, Anda tidak dapat mengubah satu file di arsip (
Yuri dari masa depan: secara teori, Anda masih bisa ), Anda perlu memuat ulang seluruh arsip. Selain itu, terlepas dari kenyataan bahwa arsip phar bekerja dengan OPCache, ketika menggunakan, cache harus dibuang, karena jika tidak akan ada sampah di OPCache dari file phar lama.
hhbcMetode ini asli untuk HHVM - HipHop Virtual Machine dan digunakan oleh Facebook. Ini adalah sesuatu seperti arsip phar, tetapi tidak berisi kode sumber, tetapi kode byte yang dikompilasi dari mesin virtual HHVM - penerjemah PHP dari Facebook. Dilarang mengubah apa pun dalam file ini: Anda tidak dapat membuat kelas, fungsi, dan beberapa fitur dinamis lainnya dalam mode ini dinonaktifkan. Karena keterbatasan ini, mesin virtual dapat menggunakan optimasi tambahan. Menurut Facebook, ini dapat membawa hingga 30% ke kecepatan eksekusi kode. Ini mungkin pilihan yang bagus untuk mereka. Juga tidak mungkin untuk mengubah satu file di sini (
Yuri dari masa depan: sebenarnya itu mungkin, karena ini adalah basis sqlite ). Jika Anda ingin mengubah satu baris, Anda harus mengulang kembali seluruh arsip.
Untuk metode ini
dilarang menggunakan eval dan dynamic include. Ini memang begitu, tetapi tidak cukup. Eval dapat digunakan, tetapi jika tidak membuat kelas atau fungsi baru, dan menyertakan tidak dapat dibuat dari direktori yang berada di luar arsip ini.
lingkaranIni adalah versi lama kami, dan ini memiliki dua keuntungan besar. Pertama, sepertinya direktori biasa
. Anda memasang loop, dan untuk kode itu tidak masalah - itu bekerja dengan file, baik di lingkungan pengembangan dan lingkungan produksi. Loop kedua dapat dipasang dalam mode baca dan tulis, dan ubah satu file, jika Anda masih perlu mengubah sesuatu untuk segera diproduksi.
Tetapi loop memiliki kontra. Pertama, ini bekerja aneh dengan buruh pelabuhan. Saya akan membicarakannya nanti.
Kedua, jika Anda menggunakan symlink pada loop terakhir sebagai document_root, maka Anda akan memiliki masalah dengan OPCache. Ini tidak terlalu bagus untuk memiliki symlink di jalur, dan mulai membingungkan versi file yang akan digunakan. Karena itu, OPCache harus diatur ulang saat menggunakan.
Masalah lain adalah bahwa
hak pengguna super diperlukan untuk me-mount sistem file. Dan Anda tidak boleh lupa me-mount mereka pada awal / restart mesin, karena kalau tidak akan ada direktori kosong bukan kode.
Masalah dengan buruh pelabuhan
Jika Anda membuat wadah buruh pelabuhan dan membuang di dalamnya sebuah folder di mana "loop" atau perangkat blok lainnya dipasang, maka ada dua masalah sekaligus: titik mount baru tidak jatuh ke dalam wadah buruh pelabuhan, dan "loop" yang ada pada saat penciptaan Wadah buruh pelabuhan
tidak dapat dilepas karena diduduki oleh wadah buruh pelabuhan.
Biasanya, ini umumnya tidak sesuai dengan penyebaran, karena jumlah perangkat loop terbatas, dan tidak jelas bagaimana kode baru harus jatuh ke dalam wadah.
Kami mencoba melakukan hal-hal aneh, misalnya, meningkatkan
server NFS lokal atau memasang direktori menggunakan SSHFS, tetapi karena berbagai alasan ini tidak berakar pada kami. Akibatnya, di cron, kami mendaftarkan rsync dari "loop" terakhir ke direktori saat ini, dan menjalankan perintah sekali setiap menit:
rsync /var/loop/<N>/ /var/www/
Di sini
/var/www/ adalah direktori yang dipromosikan ke wadah. Tetapi pada mesin yang memiliki wadah buruh pelabuhan, kami tidak perlu sering menjalankan skrip PHP, jadi rsync bukan atom, yang cocok untuk kami. Tapi tetap saja, metode ini sangat buruk, tentu saja. Saya ingin membuat sistem penempatan yang berfungsi baik dengan buruh pelabuhan.
rsync, 2 direktori dan realpath_root
Metode ini diusulkan oleh Rasmus Lerdorf, penulis PHP, dan ia tahu cara menggunakan.
Bagaimana cara membuat penyebaran atom, dan dengan cara apa pun yang saya bicarakan? Ambil symlink dan daftarkan sebagai document_root. Pada setiap titik waktu, symlink menunjuk ke salah satu dari dua direktori, dan Anda membuat rsync ke direktori tetangga, yaitu ke direktori yang tidak ditunjuk oleh kode.
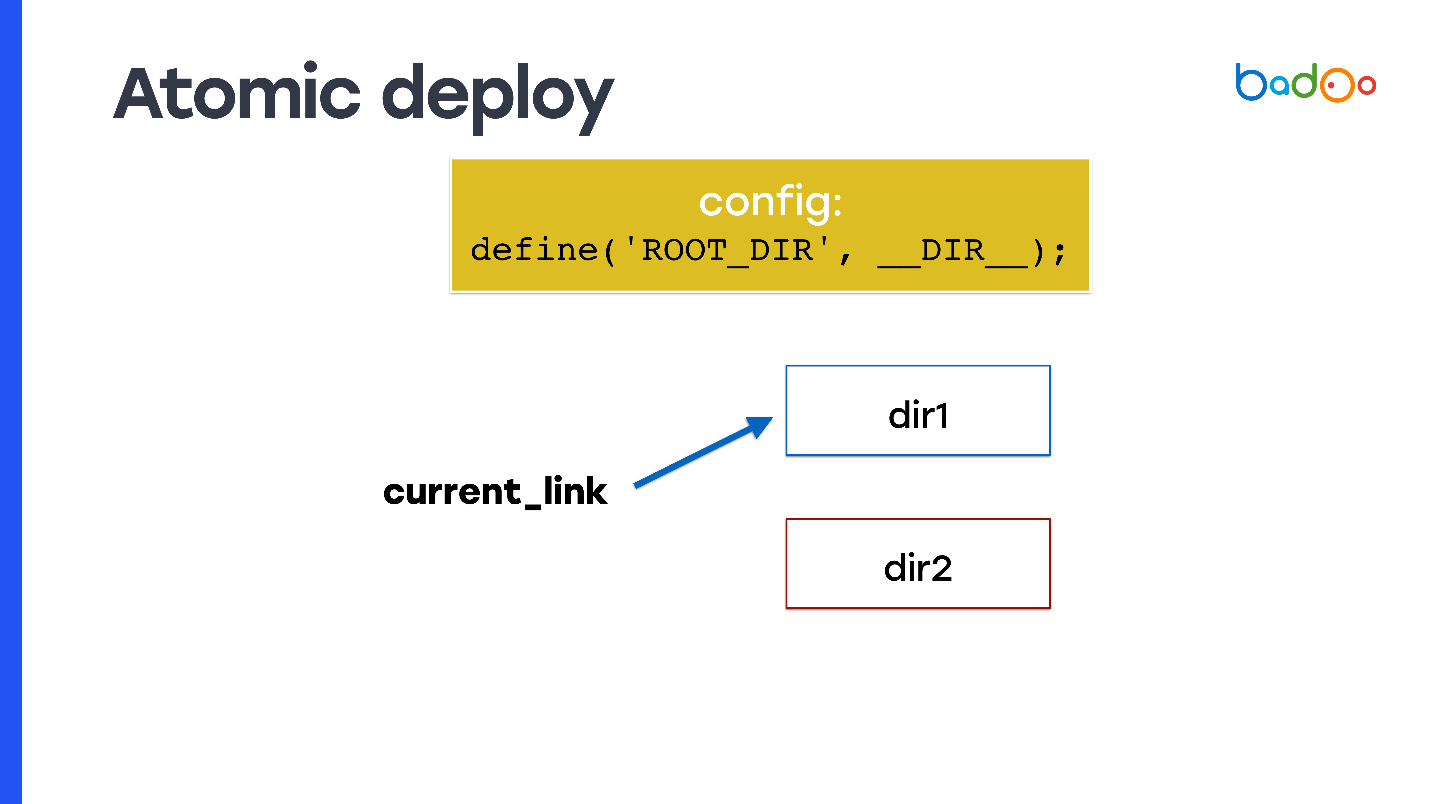
Tetapi masalah muncul: kode PHP tidak tahu direktori tempat dia menjalankan. Oleh karena itu, Anda perlu menggunakan, misalnya, variabel yang akan Anda tulis di suatu tempat di awal dalam konfigurasi - ini akan memperbaiki direktori tempat kode dijalankan dan dari mana file baru harus dimasukkan. Pada salindia, ini disebut
ROOT_DIR .
Gunakan konstanta ini ketika mengakses semua file di dalam kode yang Anda gunakan saat produksi. Jadi Anda mendapatkan properti atomicity: permintaan yang tiba sebelum Anda beralih symlink terus menyertakan file dari direktori lama di mana Anda tidak mengubah apa pun, dan permintaan baru yang datang setelah beralih symlink mulai bekerja dari direktori baru dan dilayani kode baru.

Tetapi ini perlu ditulis dalam kode. Tidak semua proyek siap untuk ini.
Gaya Rasmus
Rasmus menyarankan daripada memodifikasi kode secara manual dan membuat konstanta untuk sedikit memodifikasi Apache atau menggunakan nginx.
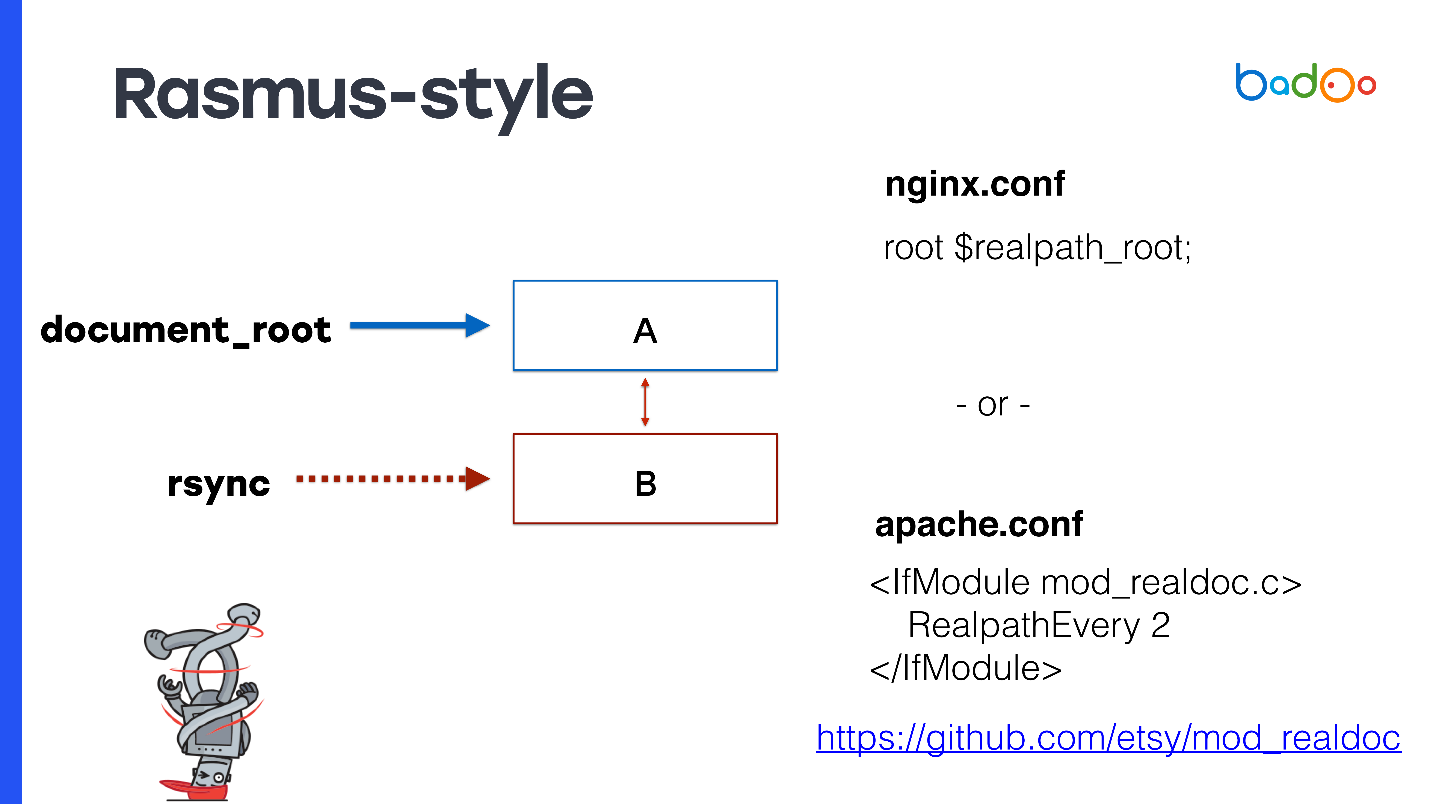
Untuk document_root, tentukan symlink ke versi terbaru. Jika Anda memiliki nginx, maka Anda dapat mendaftarkan
root $realpath_root , untuk Apache Anda akan memerlukan modul terpisah dengan pengaturan yang dapat dilihat pada slide. Ini berfungsi seperti ini - ketika sebuah permintaan tiba, nginx atau Apache sesekali mempertimbangkan realpath () dari path, menyimpannya dari symlinks, dan meneruskan path ini sebagai document_root. Dalam hal ini, document_root akan selalu menunjuk ke direktori reguler tanpa symlink, dan kode PHP Anda mungkin tidak harus memikirkan direktori tempat itu berasal.
Metode ini memiliki kelebihan yang menarik - jalur nyata datang ke OPCache PHP, mereka tidak mengandung symlink. Bahkan file pertama yang diminta sudah penuh, dan tidak akan ada masalah dengan OPCache. Karena document_root digunakan, ini berfungsi dengan proyek PHP apa pun. Anda tidak perlu menyesuaikan apa pun.
Ini tidak memerlukan pemuatan fpm, tidak perlu mengatur ulang OPCache selama penyebaran, itulah sebabnya server prosesor sangat sibuk, karena harus mengurai semua file lagi. Dalam percobaan saya, mengatur ulang OPCache sekitar setengah menit meningkatkan konsumsi prosesor dengan faktor 2–3. Akan menyenangkan untuk menggunakannya kembali dan metode ini memungkinkan Anda untuk melakukannya.
Sekarang kontra. Karena Anda tidak menggunakan kembali OPCache, dan Anda memiliki 2 direktori, Anda perlu menyimpan salinan file dalam memori untuk setiap direktori - di bawah OPCache, diperlukan 2 kali lebih banyak memori.
Ada batasan lain yang mungkin tampak aneh -
Anda tidak dapat menggunakan lebih dari sekali setiap max_execution_time . Kalau tidak, masalah yang sama akan terjadi, karena ketika rsync pergi ke salah satu direktori, permintaan darinya masih dapat diproses.
Jika Anda menggunakan Apache karena suatu alasan, maka Anda memerlukan
modul pihak ketiga yang juga ditulis oleh Rasmus.
Rasmus mengatakan sistemnya baik dan saya merekomendasikannya untuk Anda juga. Untuk 99% proyek, sangat cocok, baik untuk proyek baru maupun yang sudah ada. Tetapi, tentu saja, kita tidak seperti itu dan memutuskan untuk menulis keputusan kita sendiri.
Sistem baru - MDK
Pada dasarnya, persyaratan kami tidak berbeda dengan persyaratan untuk sebagian besar proyek web. Kami hanya ingin
penyebaran cepat pada pementasan dan produksi,
konsumsi sumber daya yang rendah , penggunaan kembali OPCache dan rollback cepat.
Tetapi ada dua persyaratan lagi yang mungkin berbeda dari yang lain. Pertama-tama, itu adalah kemampuan untuk
menerapkan tambalan secara atom . Kami merujuk ke tambalan sebagai perubahan dalam satu atau beberapa file yang mengatur sesuatu pada produksi. Kami ingin melakukannya dengan cepat. Pada prinsipnya, sistem yang ditawarkan Rasmus mengatasi tugas tambalan.
Kami juga memiliki
skrip CLI yang dapat berjalan selama beberapa jam , dan
skrip tersebut harus tetap bekerja dengan versi kode yang konsisten. Dalam hal ini, solusi di atas, sayangnya, tidak cocok untuk kita, atau kita harus memiliki banyak direktori.
Kemungkinan solusi:
- loop xN (-staging, -docker, -opcache);
- rsync xN (-produksi, -opcache xN);
- SVN xN (-produksi, -opcache xN).
Di sini N adalah jumlah perhitungan yang terjadi dalam beberapa jam. Kita dapat memiliki lusinan di antaranya, yang berarti kebutuhan untuk menghabiskan ruang yang sangat besar untuk salinan kode tambahan.
Karena itu, kami membuat sistem baru dan menyebutnya
MDK. Itu adalah singkatan dari
Multiversion Deployment Kit , alat penyebaran multi-versi. Kami melakukannya berdasarkan asumsi berikut.
Kami mengambil arsitektur penyimpanan pohon dari Git. Kita perlu memiliki versi kode yang konsisten di mana skrip bekerja, yaitu, kita memerlukan snapshot. Snapshots didukung oleh LVM, tetapi di sana mereka diimplementasikan secara tidak efisien oleh sistem file eksperimental seperti Btrfs dan Git. Kami mengambil implementasi snapshots dari Git.
Mengganti nama semua file dari file.php ke file.php. <version>. Karena semua file yang kita miliki hanya disimpan di disk, maka jika kita ingin menyimpan beberapa versi file yang sama, kita harus menambahkan akhiran dengan versi tersebut.
Saya suka Go, jadi untuk kecepatan saya menulis sebuah sistem di Go.Bagaimana Kit Penerapan Multiversion Bekerja
Kami mengambil ide snapshot dari Git. Saya sedikit menyederhanakannya dan memberi tahu Anda cara penerapannya di MDK.
Ada dua jenis file di MDK. Yang pertama adalah
kartu. Gambar-gambar di bawah ini ditandai dengan warna hijau dan sesuai dengan direktori di repositori. Tipe kedua adalah
file secara langsung, yang terletak di tempat yang sama seperti biasanya, tetapi dengan akhiran dalam bentuk versi file. File dan peta diversi berdasarkan isinya, dalam kasus kami hanya MD5.
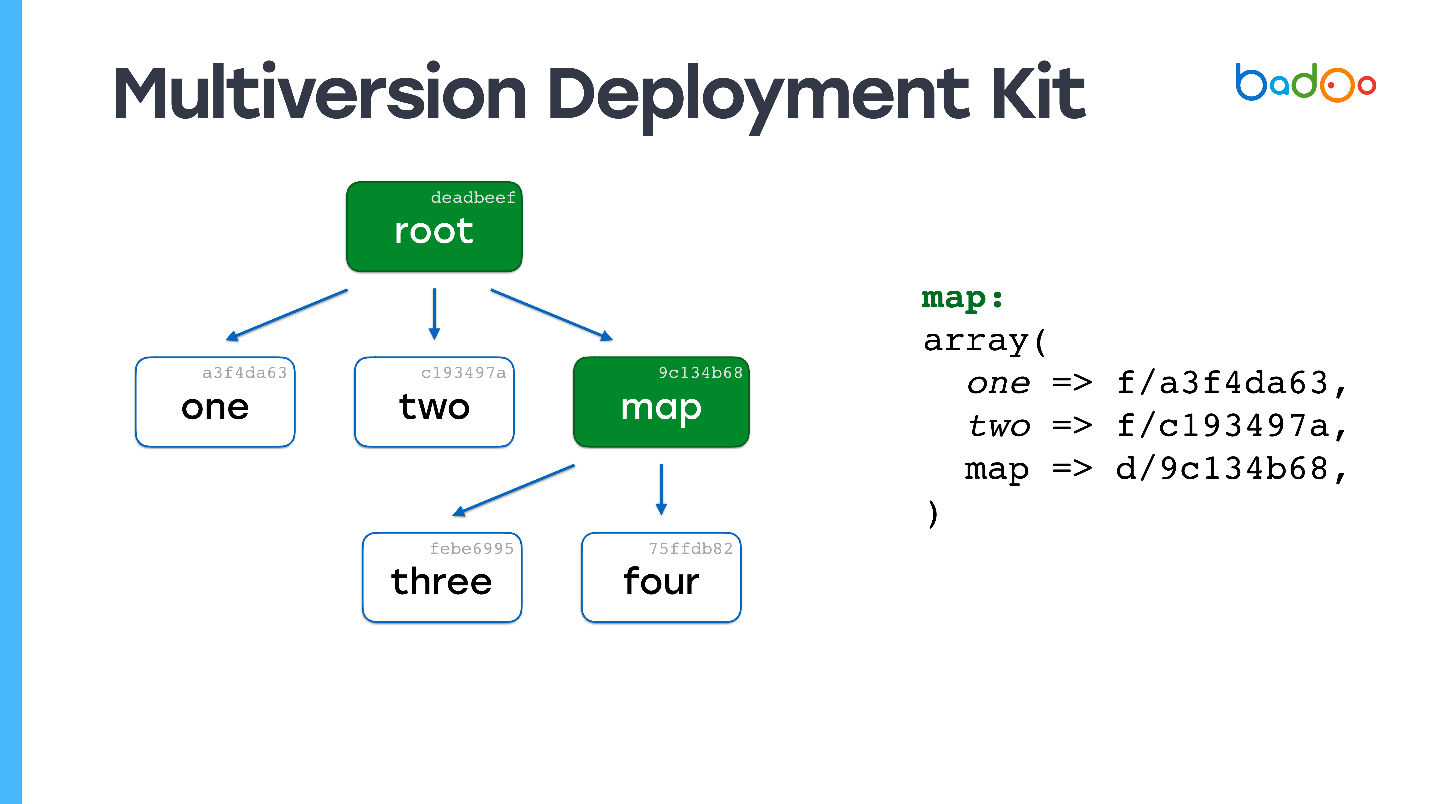
Misalkan kita memiliki beberapa hierarki file di mana
peta root merujuk ke versi file tertentu dari peta lain , dan mereka, pada gilirannya, merujuk ke file dan peta lain, dan memperbaiki versi tertentu. Kami ingin mengubah beberapa jenis file.

Mungkin Anda telah melihat gambar yang sama: kami mengubah file di tingkat bersarang kedua, dan di peta yang sesuai - peta *, versi dari tiga file * diperbarui, isinya dimodifikasi, versinya diubah - dan versinya juga berubah di root map. Jika kami mengubah sesuatu, kami selalu mendapatkan peta root baru, tetapi semua file yang tidak kami ubah digunakan kembali.
Tautan tetap ke file yang sama seperti sebelumnya. Ini adalah ide utama untuk membuat snapshot dengan cara apa pun, misalnya, di
ZFS diterapkan dengan cara yang hampir sama.
Bagaimana MDK terletak pada disk

Kami memiliki pada disk:
symlink ke peta root terbaru - kode yang akan dilayani dari web, beberapa versi peta root, beberapa file, mungkin dengan versi yang berbeda, dan di subdirektori ada peta untuk direktori yang sesuai.
Saya memperkirakan pertanyaan: "
Dan bagaimana ini memproses permintaan web? File apa yang akan digunakan oleh kode pengguna? "
Ya, saya menipu Anda - ada juga file tanpa versi, karena jika Anda menerima permintaan untuk index.php, dan Anda tidak memilikinya di direktori, situs tidak akan berfungsi.

Semua file PHP memiliki file, yang kami sebut
bertopik , karena mengandung dua baris: wajibkan dari file di mana fungsi yang tahu cara bekerja dengan kartu-kartu ini dideklarasikan, dan diperlukan dari versi file yang diinginkan.
<?php require_once "mdk.inc"; require mdk_resolve_path("a.php");
Hal ini dilakukan, dan tidak dikaitkan dengan versi terbaru, karena jika Anda mengecualikan
b.php dari file
a.php tanpa versi, maka sejak require_once ditulis, sistem akan mengingat kartu root yang memulai, akan menggunakannya, dan Dapatkan versi file yang konsisten.
Untuk sisa file, kami hanya memiliki symlink ke versi terbaru.
Cara menggunakan MDK
Modelnya sangat mirip dengan git push.
- Kirim isi peta root.
- Di sisi penerima, kami melihat file apa yang hilang. Karena versi file ditentukan oleh konten, kita tidak perlu mengunduhnya untuk kedua kalinya ( Yuri dari masa depan: kecuali untuk kasus ketika MD5 yang diperpendek bertabrakan, yang masih terjadi satu kali dalam produksi ).
- Minta file yang hilang.
- Kami melewati titik kedua dan selanjutnya dalam lingkaran.
Contoh
Misalkan ada file bernama "satu" di server. Kirim peta root ke sana.

Di root map, panah putus-putus menunjukkan tautan ke file yang tidak kita miliki. Kami tahu nama dan versinya karena mereka ada di peta. Kami meminta mereka dari server. Server mengirim, dan ternyata salah satu file juga kartu.
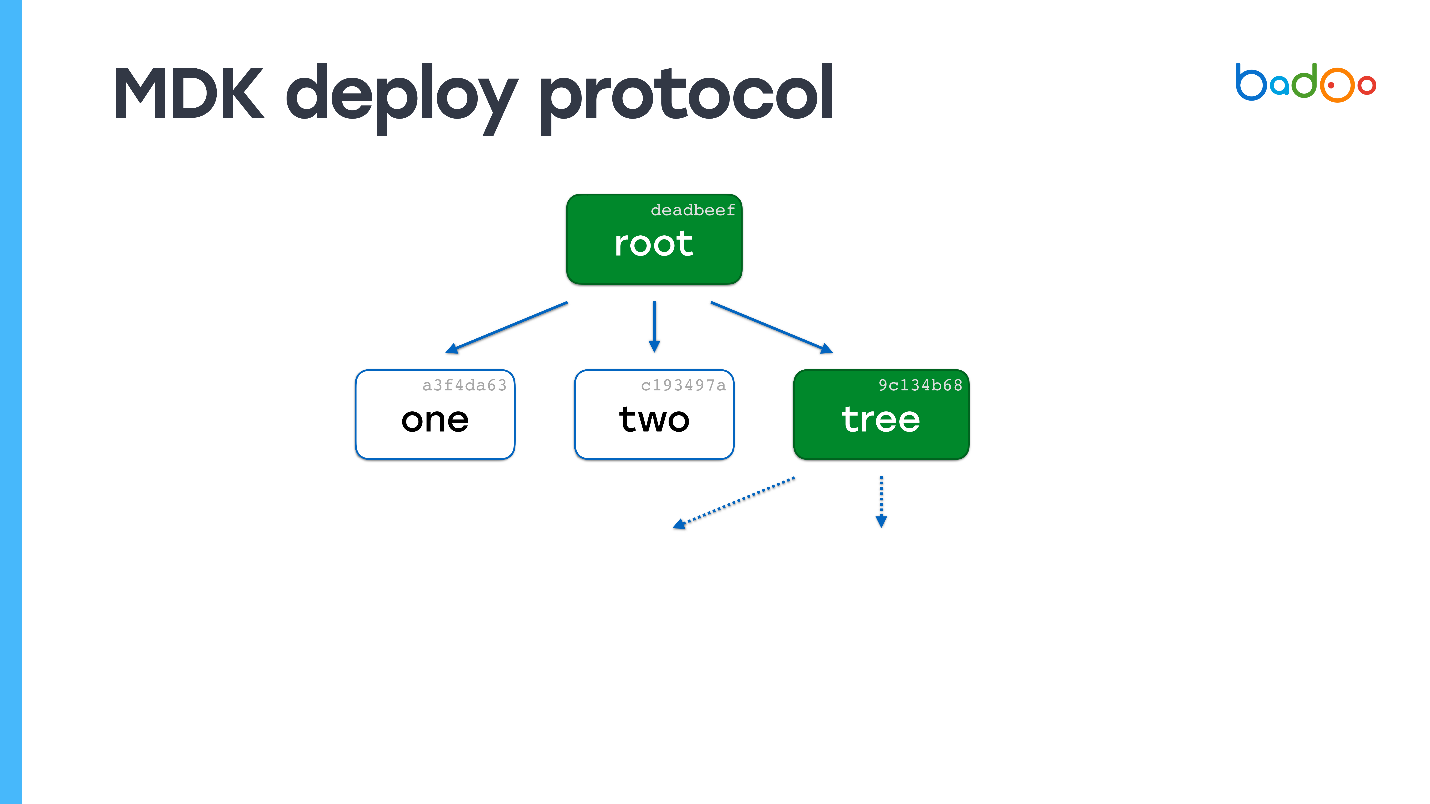
Kami melihat - kami tidak memiliki satu file sama sekali. Sekali lagi kami meminta file yang hilang. Server mengirimkannya. Tidak ada lagi kartu yang tersisa - proses penyebaran selesai.
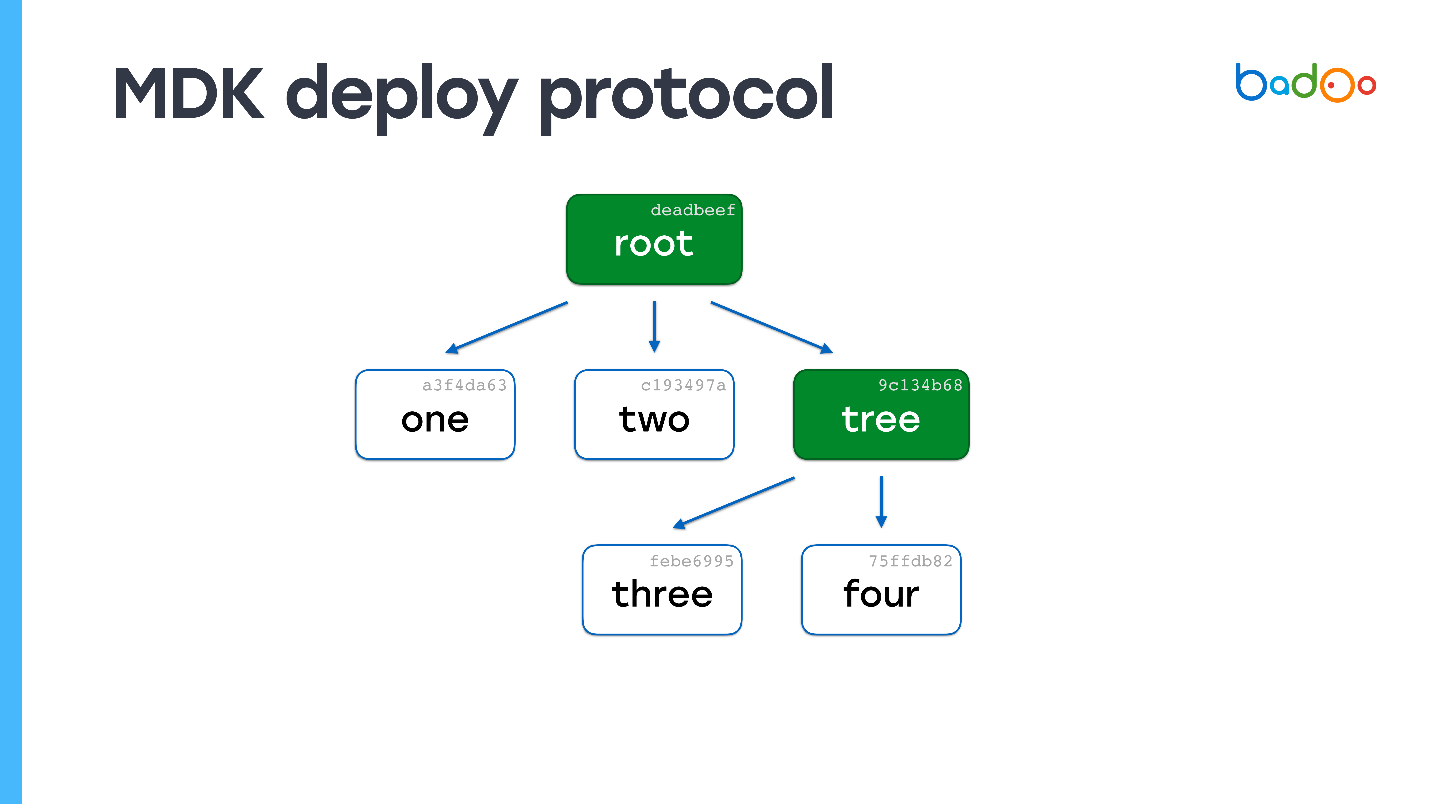
Anda dapat dengan mudah menebak apa yang akan terjadi jika file 150.000, tetapi satu telah berubah. Kita akan melihat di peta dasar bahwa ada satu peta yang hilang, mari kita lanjutkan dengan tingkat sarang dan dapatkan file. Dalam hal kompleksitas komputasi, prosesnya hampir tidak berbeda dengan menyalin file secara langsung, tetapi pada saat yang sama, konsistensi dan snapshot dari kode tersebut dipertahankan.
MDK tidak memiliki kekurangan :) Ini memungkinkan Anda untuk secara
cepat dan atomis melakukan perubahan kecil , dan
skrip bekerja selama berhari-hari , karena kami dapat meninggalkan semua file yang digunakan dalam waktu seminggu. Mereka akan menempati ruang yang cukup memadai. Anda juga dapat menggunakan kembali OPCache, dan CPU hampir tidak makan apa-apa.
Pemantauan cukup sulit, tetapi memungkinkan . Semua file diversi versi oleh konten, dan Anda dapat menulis cron, yang akan melewati semua file dan memverifikasi nama dan konten. Anda juga dapat memeriksa bahwa peta root merujuk ke semua file, bahwa tidak ada tautan yang rusak di dalamnya. Selain itu, selama integritas penyebaran diperiksa.
Anda dapat
dengan mudah mengembalikan perubahan , karena semua kartu lama ada di tempatnya. Kita bisa melempar kartunya, semuanya akan segera ada di sana.
Bagi saya, ditambah fakta bahwa
MDK ditulis dalam Go berarti bekerja dengan cepat.
Saya menipu Anda lagi, masih ada kontra. Agar proyek dapat bekerja dengan sistem,
diperlukan modifikasi kode yang signifikan, tetapi lebih sederhana daripada yang terlihat pada pandangan pertama.
Sistem ini sangat kompleks , saya tidak akan merekomendasikan menerapkannya jika Anda tidak memiliki persyaratan seperti Badoo. Lagipula, cepat atau lambat tempat itu berakhir, jadi
Pengumpul Sampah diperlukan .
Kami menulis utilitas khusus untuk mengedit file - yang asli, bukan bertopik, misalnya, mdk-vim. Anda menentukan file, menemukan versi yang diinginkan dan mengeditnya.
MDK dalam angka
Kami memiliki 50 server untuk pementasan, yang kami gunakan selama 3-5 detik
. Dibandingkan dengan semuanya kecuali rsync, ini sangat cepat. Pada
produksi kami menyebarkan sekitar
2 menit , tambalan kecil -
5-10 s .
Jika karena alasan tertentu Anda telah kehilangan seluruh folder dengan kode pada semua server (yang seharusnya tidak pernah terjadi :)), maka
proses pengunggahan penuh membutuhkan waktu sekitar 40 menit . Itu pernah terjadi pada kami, meskipun pada malam hari dengan lalu lintas minimum. Karena itu, tidak ada yang terluka. File kedua adalah sepasang server selama 5 menit, jadi ini tidak layak disebutkan.
Sistem ini tidak di Open Source, tetapi jika Anda tertarik, tulis di komentar - itu mungkin ditata (
Yuri dari masa depan: sistem masih belum di Open Source pada saat penulisan ini ).
Kesimpulan
Dengarkan Rasmus, dia tidak berbohong . Menurut pendapat saya, metode rsync-nya bersama dengan realpath_root adalah yang terbaik, meskipun loop juga bekerja dengan baik.
Pikirkan dengan kepala Anda : lihat apa yang dibutuhkan proyek Anda, dan jangan mencoba membuat pesawat ruang angkasa di mana ada cukup "jagung". Tetapi jika Anda masih memiliki persyaratan yang serupa, maka sistem yang mirip dengan MDK akan cocok untuk Anda.
Kami memutuskan untuk kembali ke topik ini, yang dibahas pada HighLoad ++ dan, mungkin, tidak mendapat perhatian, karena itu hanya satu dari banyak batu bata untuk mencapai kinerja tinggi. Tetapi sekarang kami memiliki konferensi PHP Rusia profesional terpisah yang didedikasikan sepenuhnya untuk PHP. Dan di sini kita benar-benar datang sepenuhnya. Kami akan berbicara secara menyeluruh tentang kinerja , dan tentang standar , dan tentang alat - banyak tentang itu, termasuk refactoring .
Berlangganan saluran Telegram dengan pembaruan program konferensi dan sampai jumpa pada 17 Mei.