Halo, Habr!
Kami mengingatkan Anda bahwa setelah buku tentang
Kafka kami merilis karya yang sama menariknya di perpustakaan
Kafka Streams API .

Sejauh ini, masyarakat hanya memahami batas-batas alat yang ampuh ini. Jadi, sebuah artikel baru-baru ini diterbitkan, dengan terjemahan yang ingin kami perkenalkan kepada Anda. Berdasarkan pengalamannya sendiri, penulis menceritakan bagaimana cara membuat data warehouse terdistribusi dari Kafka Streams. Selamat membaca!
Perpustakaan Apache
Kafka Streams di seluruh dunia digunakan di perusahaan untuk pemrosesan streaming terdistribusi di atas Apache Kafka. Salah satu aspek yang diremehkan dari kerangka kerja ini adalah memungkinkan Anda untuk menyimpan status lokal berdasarkan pemrosesan streaming.
Dalam artikel ini, saya akan memberi tahu Anda bagaimana perusahaan kami telah berhasil menggunakan kesempatan ini untuk mengembangkan produk untuk keamanan aplikasi cloud. Menggunakan Kafka Streams, kami menciptakan layanan microser bersama, yang masing-masing berfungsi sebagai sumber informasi tepercaya yang sangat toleran dan sangat mudah diakses tentang keadaan objek dalam sistem. Bagi kami, ini adalah langkah maju baik dalam hal keandalan maupun kemudahan dukungan.
Jika Anda tertarik pada pendekatan alternatif yang memungkinkan Anda untuk menggunakan pusat data tunggal untuk mendukung keadaan formal objek Anda - baca, itu akan menarik ...
Mengapa kami pikir sudah waktunya untuk mengubah pendekatan kami untuk bekerja dengan negara bersamaKami perlu mempertahankan keadaan berbagai objek berdasarkan laporan agen (misalnya: apakah situs diserang)? Sebelum beralih ke Streaming Kafka, kami sering mengandalkan satu database pusat (+ API layanan) untuk mengelola negara kami. Pendekatan ini memiliki kelemahan: dalam
situasi intensif data, dukungan untuk konsistensi dan sinkronisasi berubah menjadi tantangan nyata. Basis data dapat menjadi hambatan, atau mungkin dalam
kondisi balapan dan tidak dapat diprediksi.
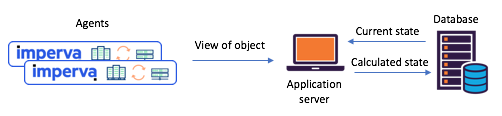 Gambar 1: Skenario split-state tipikal ditemui sebelum transisi ke
Gambar 1: Skenario split-state tipikal ditemui sebelum transisi ke
Kafka dan Kafka Streaming: agen mengkomunikasikan kiriman mereka melalui API, status yang diperbarui dihitung melalui database pusatMemenuhi Streaming Kafka - Sekarang Mudah Membuat Layanan Keadaan Mikro BersamaSekitar setahun yang lalu, kami memutuskan untuk meninjau skenario negara bagian kami secara menyeluruh untuk mengatasi masalah tersebut. Segera kami memutuskan untuk mencoba Kafka Streams - kami tahu betapa scalable, sangat mudah diakses, dan toleran terhadap kesalahannya, seberapa kaya fungsi streamingnya (transformasi, termasuk yang stateful). Apa yang kami butuhkan, belum lagi seberapa matang dan dapat diandalkan sistem pesan di Kafka.
Setiap microservices yang mempertahankan keadaan yang kami buat dibangun berdasarkan instance Kafka Streams dengan topologi yang cukup sederhana. Terdiri dari 1) sumber 2) prosesor dengan penyimpanan kunci dan nilai permanen 3) tiriskan:
 Gambar 2: Topologi default instance streaming kami untuk layanan microsoft stateful. Harap dicatat bahwa ada juga repositori yang berisi metadata perencanaan.
Gambar 2: Topologi default instance streaming kami untuk layanan microsoft stateful. Harap dicatat bahwa ada juga repositori yang berisi metadata perencanaan.Dengan pendekatan baru ini, agen menyusun pesan yang dikirim ke topik asli, dan konsumen - katakanlah, layanan pemberitahuan surat - menerima keadaan bersama yang dihitung melalui stok (topik keluaran).
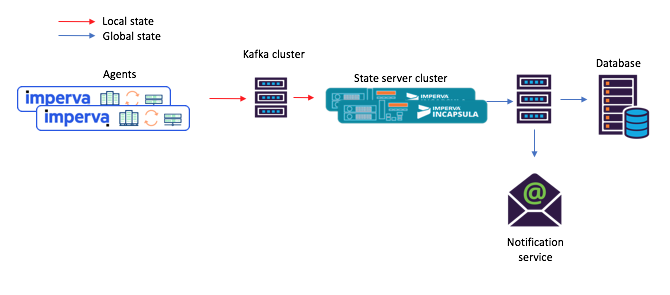 Gambar 3: contoh baru alur tugas untuk skenario dengan layanan microser bersama: 1) agen menghasilkan pesan yang tiba di topik Kafka asli; 2) layanan microser dengan status bersama (menggunakan Streaming Kafka) memprosesnya dan menulis status terhitung ke topik Kafka akhir; setelah itu 3) konsumen menerima negara baruHei, repositori kunci dan nilai bawaan ini sebenarnya sangat berguna!
Gambar 3: contoh baru alur tugas untuk skenario dengan layanan microser bersama: 1) agen menghasilkan pesan yang tiba di topik Kafka asli; 2) layanan microser dengan status bersama (menggunakan Streaming Kafka) memprosesnya dan menulis status terhitung ke topik Kafka akhir; setelah itu 3) konsumen menerima negara baruHei, repositori kunci dan nilai bawaan ini sebenarnya sangat berguna!Seperti yang disebutkan di atas, topologi keadaan bersama kami berisi penyimpanan kunci dan nilai. Kami menemukan beberapa opsi untuk penggunaannya, dan dua di antaranya dijelaskan di bawah ini.
Opsi # 1: menggunakan keystore dan value store untuk perhitunganPenyimpanan kunci dan nilai pertama kami berisi data tambahan yang kami butuhkan untuk perhitungan. Misalnya, dalam beberapa kasus, negara bersama ditentukan berdasarkan prinsip "suara terbanyak". Dalam repositori dimungkinkan untuk menyimpan semua laporan agen terbaru tentang keadaan objek tertentu. Kemudian, menerima laporan baru dari agen, kita bisa menyimpannya, mengekstrak laporan dari semua agen lain tentang keadaan objek yang sama dari repositori, dan ulangi perhitungan.
Gambar 4 di bawah ini menunjukkan bagaimana kami membuka akses ke penyimpanan kunci dan nilai ke metode pemrosesan prosesor, sehingga kami dapat memproses pesan baru.
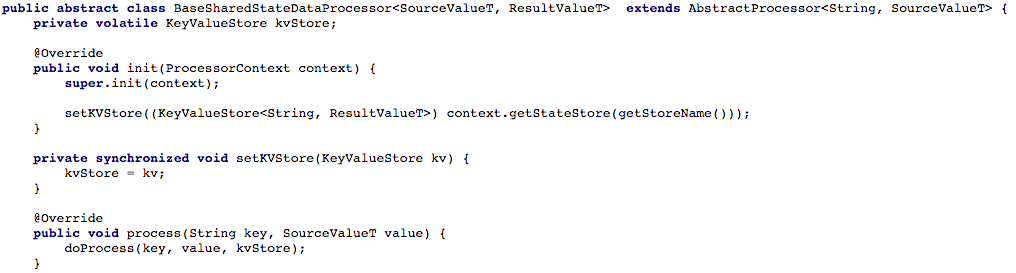 Gambar 4: kita membuka akses ke penyimpanan kunci dan nilai-nilai untuk metode pemrosesan prosesor (setelah itu, dalam setiap skrip yang bekerja dengan keadaan bersama, Anda harus menerapkan metode
Gambar 4: kita membuka akses ke penyimpanan kunci dan nilai-nilai untuk metode pemrosesan prosesor (setelah itu, dalam setiap skrip yang bekerja dengan keadaan bersama, Anda harus menerapkan metode doProcess )Opsi # 2: membuat API CRUD di atas Aliran KafkaSetelah menyesuaikan aliran tugas dasar kami, kami mulai mencoba menulis API CRESTful RESTful untuk layanan microser-shared kami. Kami ingin dapat mengambil status beberapa atau semua objek, serta mengatur atau menghapus status objek (ini berguna dengan dukungan sisi server).
Untuk mendukung semua Get State APIs, setiap kali kami perlu menghitung ulang status selama pemrosesan, kami memasukkannya ke dalam repositori kunci dan nilai bawaan untuk waktu yang lama. Dalam hal ini, menjadi sangat sederhana untuk mengimplementasikan API seperti itu menggunakan satu instance Kafka Streams, seperti yang ditunjukkan dalam daftar di bawah ini:
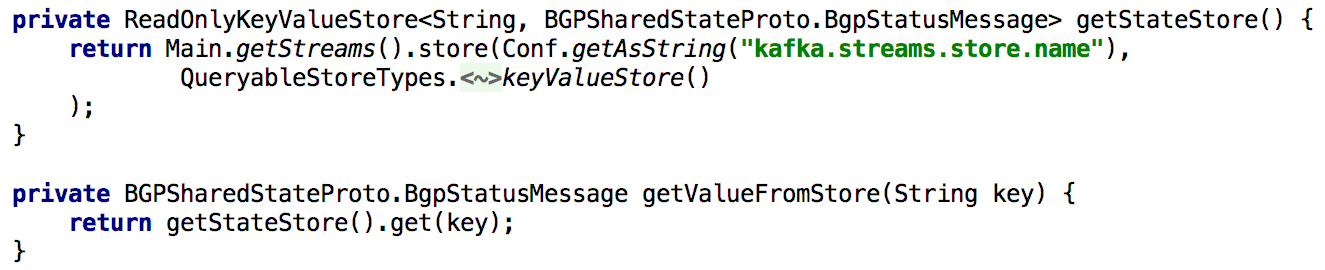 Gambar 5: menggunakan penyimpanan kunci dan nilai bawaan untuk mendapatkan keadaan objek yang telah dihitung sebelumnya
Gambar 5: menggunakan penyimpanan kunci dan nilai bawaan untuk mendapatkan keadaan objek yang telah dihitung sebelumnyaMemperbarui status suatu objek melalui API juga mudah diimplementasikan. Pada prinsipnya, untuk ini Anda hanya perlu membuat Kafka produser, dan dengan bantuannya membuat catatan di mana negara baru dibuat. Ini memastikan bahwa semua pesan yang dihasilkan melalui API akan diproses dengan cara yang sama seperti yang diterima dari produsen lain (mis. Agen).
 Gambar 6: Anda dapat mengatur keadaan objek menggunakan produsen KafkaKomplikasi kecil: Kafka memiliki banyak partisi.
Gambar 6: Anda dapat mengatur keadaan objek menggunakan produsen KafkaKomplikasi kecil: Kafka memiliki banyak partisi.Selanjutnya, kami ingin mendistribusikan beban pemrosesan dan meningkatkan ketersediaan dengan menyediakan klaster layanan-layanan bersama untuk setiap skenario. Pengaturan diberikan kepada kami sesederhana mungkin: setelah kami mengkonfigurasi semua instance sehingga mereka bekerja dengan ID aplikasi yang sama (dan dengan server boot yang sama), hampir semua hal lain dilakukan secara otomatis. Kami juga menetapkan bahwa setiap topik sumber akan terdiri dari beberapa partisi, sehingga setiap instance dapat diberi subset dari partisi tersebut.
Saya juga akan menyebutkan bahwa membuat salinan cadangan toko negara adalah hal yang normal, sehingga, misalnya, jika terjadi pemulihan setelah kegagalan, transfer salinan ini ke contoh lain. Untuk setiap toko negara di Kafka Streaming, topik direplikasi dibuat dengan log perubahan (di mana pembaruan lokal dilacak). Dengan demikian, Kafka terus-menerus mengamankan toko negara. Oleh karena itu, dalam hal terjadi kegagalan satu atau lain contoh aliran Kafka, toko negara dapat dengan cepat dikembalikan ke contoh lain, di mana partisi yang sesuai akan pergi. Pengujian kami menunjukkan bahwa ini dapat dilakukan dalam hitungan detik bahkan jika ada jutaan catatan dalam repositori.
Pindah dari satu microservice layanan bersama ke sekelompok layanan microser, menjadi kurang sepele untuk mengimplementasikan Get State API. Dalam situasi baru, repositori keadaan masing-masing microservice hanya berisi bagian dari keseluruhan gambar (objek-objek yang kuncinya dipetakan ke partisi tertentu). Kami harus menentukan di mana keadaan objek yang kami butuhkan terkandung, dan kami melakukan ini berdasarkan aliran metadata, seperti yang ditunjukkan di bawah ini:
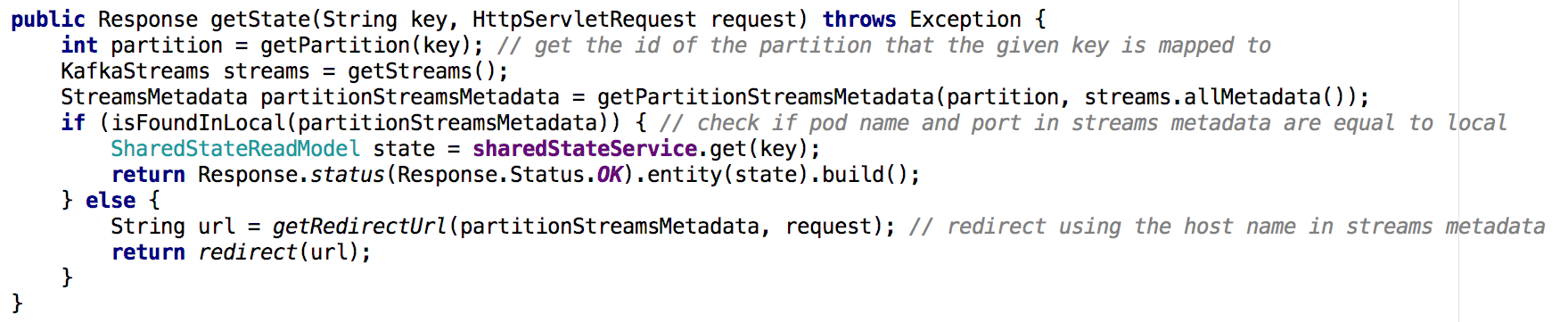 Gambar 7: menggunakan metadata aliran kita menentukan dari instance mana untuk meminta keadaan objek yang diinginkan; pendekatan serupa digunakan dengan GET ALL APITemuan Kunci
Gambar 7: menggunakan metadata aliran kita menentukan dari instance mana untuk meminta keadaan objek yang diinginkan; pendekatan serupa digunakan dengan GET ALL APITemuan KunciToko-toko negara di Kafka Streaming dapat, secara de facto, berfungsi sebagai basis data terdistribusi,
- terus menerus direplikasi dalam kafka
- Di atas sistem seperti ini mudah dibangun API CRUD
- Memproses banyak partisi sedikit lebih rumit
- Dimungkinkan juga untuk menambahkan satu atau lebih state store ke topologi aliran untuk menyimpan data tambahan. Opsi ini dapat digunakan untuk:
- Penyimpanan data jangka panjang diperlukan untuk perhitungan dalam pemrosesan streaming
- Penyimpanan data jangka panjang yang mungkin berguna pada saat berikutnya aliran contoh diinisialisasi
- lebih banyak ...
Berkat keunggulan ini dan lainnya, Kafka Streaming sangat bagus untuk mendukung status global dalam sistem terdistribusi seperti milik kami. Kafka Streaming terbukti sangat andal dalam produksi (dari saat penempatannya, kami praktis tidak kehilangan pesan), dan kami yakin ini tidak terbatas pada kemampuannya!