
Setiap orang secara unik memahami teks, terlepas dari apakah orang ini membaca berita di Internet atau novel klasik yang terkenal di dunia. Ini juga berlaku untuk berbagai algoritma dan teknik pembelajaran mesin, yang memahami teks dengan cara yang lebih matematis, yaitu, menggunakan ruang vektor dimensi tinggi.
Artikel ini dikhususkan untuk memvisualisasikan Word2Vec kata-kata dimensi tinggi menggunakan t-SNE. Visualisasi dapat bermanfaat untuk memahami bagaimana Word2Vec bekerja dan bagaimana menafsirkan hubungan antara vektor yang diambil dari teks Anda sebelum menggunakannya dalam jaringan saraf atau algoritma pembelajaran mesin lainnya. Sebagai data pelatihan, kami akan menggunakan artikel dari Google News dan karya sastra klasik oleh Leo Tolstoy, penulis Rusia yang dianggap sebagai salah satu penulis terhebat sepanjang masa.
Kami pergi melalui gambaran singkat dari algoritma t-SNE, kemudian pindah ke perhitungan embeddings kata menggunakan Word2Vec, dan akhirnya, lanjutkan ke visualisasi vektor kata dengan t-SNE dalam ruang 2D dan 3D. Kami akan menulis skrip kami dalam Python menggunakan Jupyter Notebook.
Embedded Stochastic Neighbor Embedding
T-SNE adalah algoritma pembelajaran mesin untuk visualisasi data, yang didasarkan pada teknik reduksi dimensi nonlinier. Ide dasar t-SNE adalah untuk mengurangi ruang dimensi menjaga jarak berpasangan relatif antara titik. Dengan kata lain, algoritma memetakan data multi-dimensi ke dua atau lebih dimensi, di mana titik-titik yang semula jauh dari satu sama lain juga terletak jauh, dan titik dekat juga dikonversi menjadi yang dekat. Dapat dikatakan bahwa t-SNE mencari representasi data baru di mana hubungan lingkungan dipertahankan. Deskripsi terperinci dari seluruh logika t-SNE dapat ditemukan di artikel asli [1].
Model Word2Vec
Untuk memulainya, kita harus mendapatkan representasi kata-kata vektor. Untuk tujuan ini, saya memilih Word2vec [2], yaitu, model prediksi yang efisien secara komputasi untuk mempelajari penyematan kata multi-dimensi dari data tekstual mentah. Konsep utama dari Word2Vec adalah untuk menemukan kata-kata, yang berbagi konteks umum dalam corpus pelatihan, dalam jarak yang dekat dalam ruang vektor dibandingkan dengan yang lain.
Sebagai input data untuk visualisasi, kami akan menggunakan artikel dari Google News dan beberapa novel karya Leo Tolstoy. Pra-terlatih vektor dilatih pada bagian dari dataset Google News (sekitar 100 miliar kata) diterbitkan oleh Google di
halaman resmi , jadi kami akan menggunakannya.
import gensim model = gensim.models.KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
Selain model pra-terlatih, kami akan melatih model lain pada novel Tolstoy menggunakan perpustakaan Gensim [3]. Word2Vec mengambil kalimat sebagai input data dan menghasilkan vektor kata sebagai output. Pertama, perlu mengunduh Punkt Sentence Tokenizer yang telah dilatih sebelumnya, yang membagi teks menjadi daftar kalimat dengan mempertimbangkan kata singkatan, kolokasi, dan kata-kata, yang mungkin mengindikasikan awal atau akhir kalimat. Secara default, paket data NLTK tidak menyertakan tokenizer Punkt yang sudah dilatih sebelumnya untuk Rusia, jadi kami akan menggunakan model pihak ketiga dari
github.com/mhq/train_punkt .
import re import codecs def preprocess_text(text): text = re.sub('[^a-zA-Z--1-9]+', ' ', text) text = re.sub(' +', ' ', text) return text.strip() def prepare_for_w2v(filename_from, filename_to, lang): raw_text = codecs.open(filename_from, "r", encoding='windows-1251').read() with open(filename_to, 'w', encoding='utf-8') as f: for sentence in nltk.sent_tokenize(raw_text, lang): print(preprocess_text(sentence.lower()), file=f)
Pada tahap pelatihan Word2Vec hyperparameter berikut digunakan:
- Dimensi dari vektor fitur adalah 200.
- Jarak maksimum antara kata yang dianalisis dalam kalimat adalah 5.
- Abaikan semua kata dengan frekuensi total lebih rendah dari 5 per korpus.
import multiprocessing from gensim.models import Word2Vec def train_word2vec(filename): data = gensim.models.word2vec.LineSentence(filename) return Word2Vec(data, size=200, window=5, min_count=5, workers=multiprocessing.cpu_count())
Visualisasi Word Embeddings menggunakan t-SNE
T-SNE cukup berguna jika perlu untuk memvisualisasikan kesamaan antara objek yang terletak di ruang multidimensi. Dengan set data yang besar, semakin sulit untuk membuat plot t-SNE yang mudah dibaca, jadi itu adalah praktik umum untuk memvisualisasikan kelompok kata yang paling mirip.
Mari kita pilih beberapa kata dari kosa kata model Google News yang sudah dilatih sebelumnya dan menyiapkan vektor kata untuk visualisasi.
keys = ['Paris', 'Python', 'Sunday', 'Tolstoy', 'Twitter', 'bachelor', 'delivery', 'election', 'expensive', 'experience', 'financial', 'food', 'iOS', 'peace', 'release', 'war'] embedding_clusters = [] word_clusters = [] for word in keys: embeddings = [] words = [] for similar_word, _ in model.most_similar(word, topn=30): words.append(similar_word) embeddings.append(model[similar_word]) embedding_clusters.append(embeddings) word_clusters.append(words)
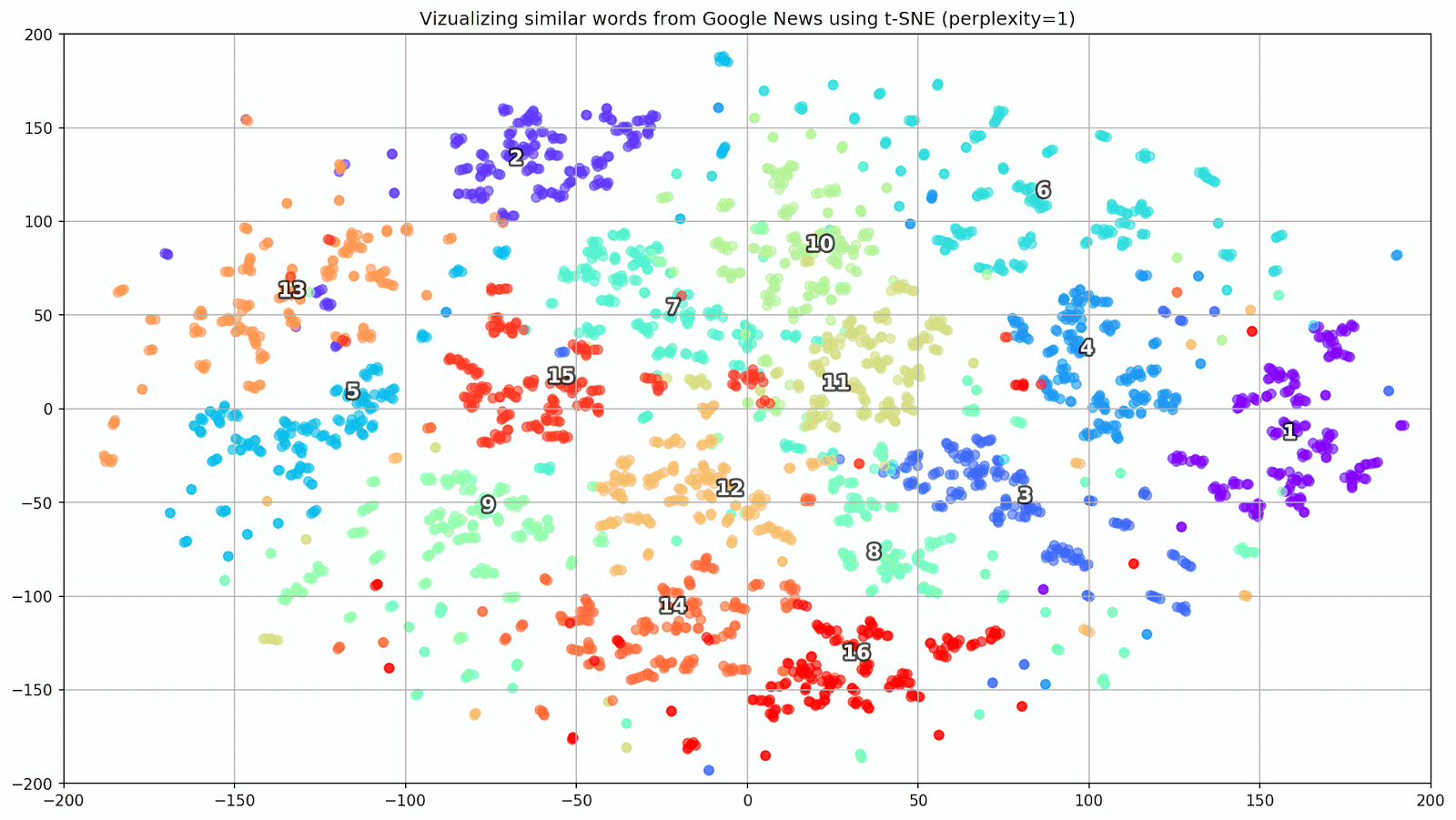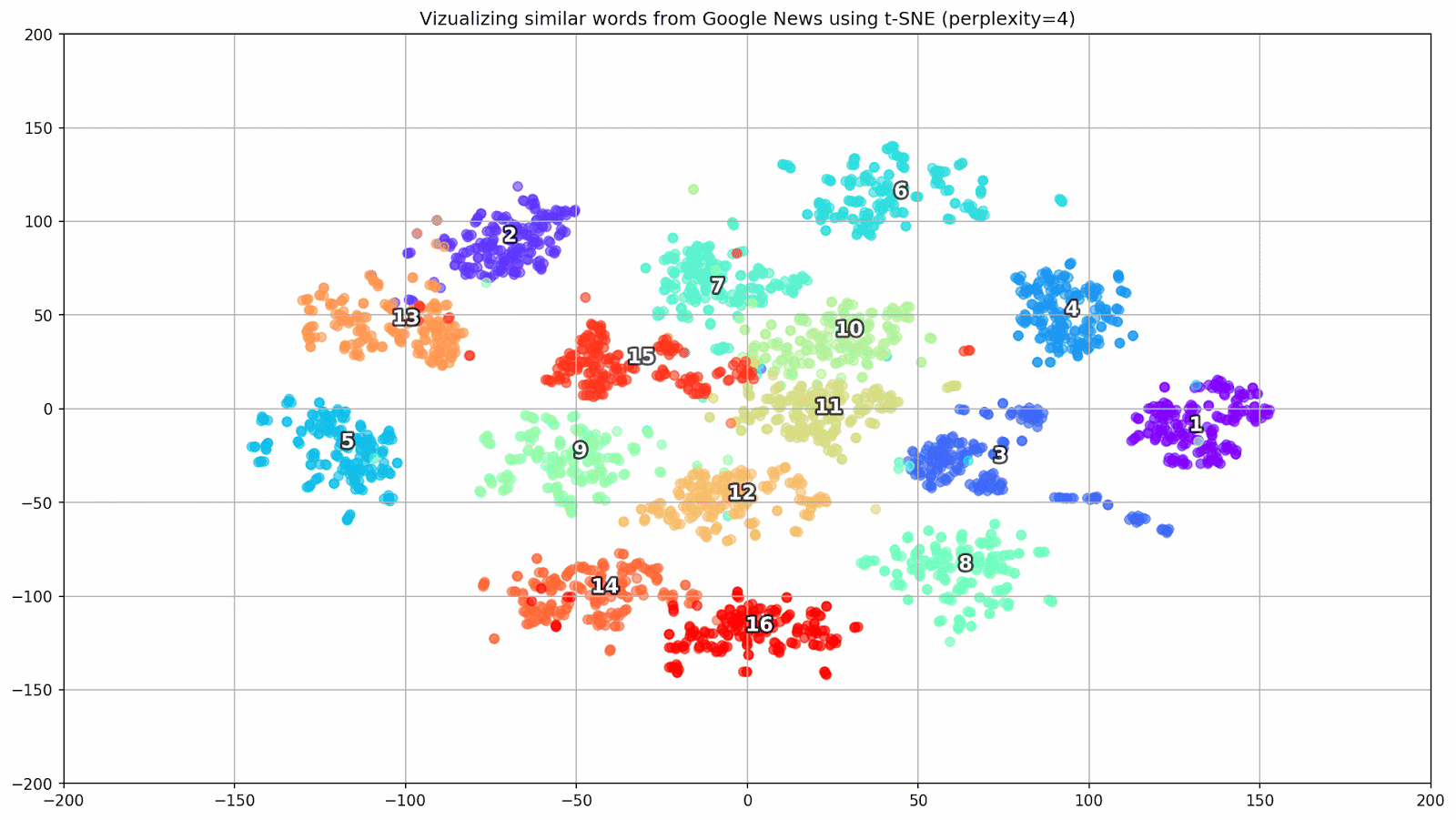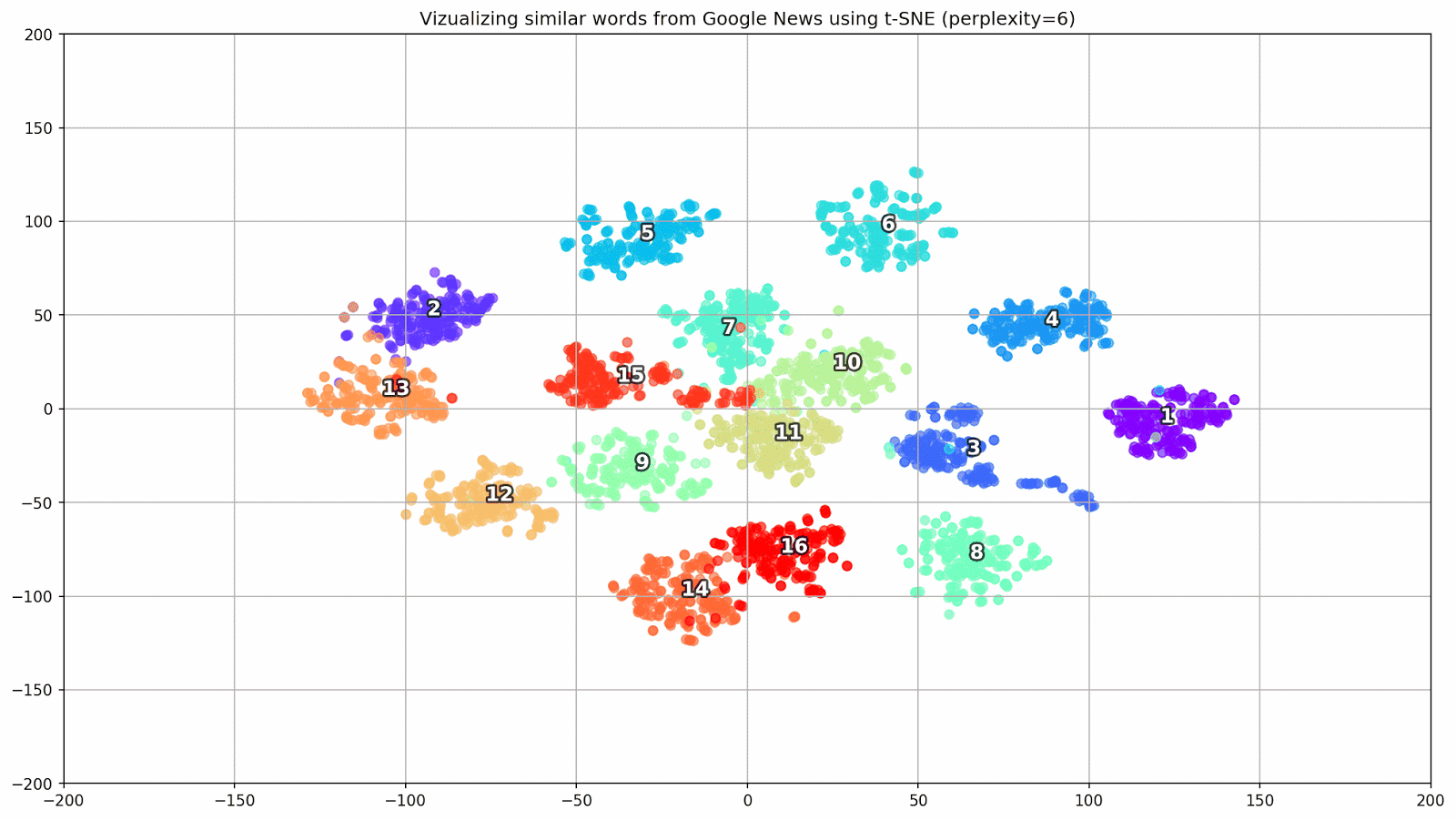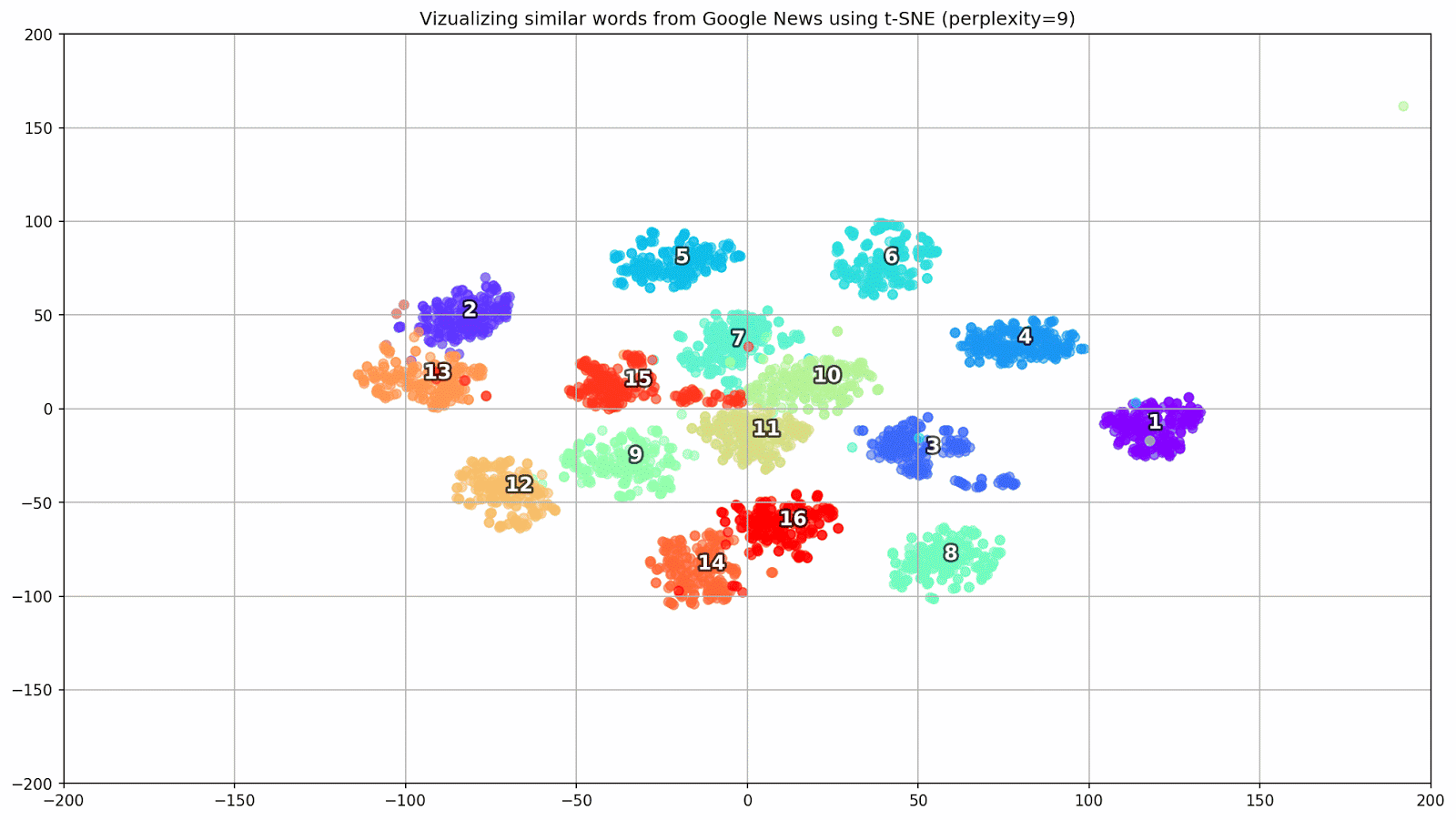 Fig. 1. Pengaruh berbagai nilai kebingungan pada bentuk kata cluster.
Fig. 1. Pengaruh berbagai nilai kebingungan pada bentuk kata cluster.Selanjutnya, kita lanjutkan ke bagian yang menarik dari makalah ini, konfigurasi t-SNE. Pada bagian ini, kita harus memperhatikan hyperparameter berikut.
- Jumlah komponen , yaitu dimensi ruang keluaran.
- Nilai keruwetan , yang dalam konteks t-SNE, dapat dipandang sebagai ukuran mulus dari jumlah tetangga yang efektif. Ini terkait dengan jumlah tetangga terdekat yang dipekerjakan di banyak pelajar berjenis lain (lihat gambar di atas). Menurut [1], disarankan untuk memilih nilai antara 5 dan 50.
- Jenis inisialisasi awal untuk embeddings.
tsne_model_en_2d = TSNE(perplexity=15, n_components=2, init='pca', n_iter=3500, random_state=32) embedding_clusters = np.array(embedding_clusters) n, m, k = embedding_clusters.shape embeddings_en_2d = np.array(tsne_model_en_2d.fit_transform(embedding_clusters.reshape(n * m, k))).reshape(n, m, 2)
Harus disebutkan bahwa t-SNE memiliki fungsi objektif non-cembung, yang diminimalkan dengan menggunakan optimasi gradient descent dengan inisiasi acak, sehingga proses yang berbeda menghasilkan hasil yang sedikit berbeda.
Di bawah ini Anda dapat menemukan skrip untuk membuat plot sebar 2D menggunakan Matplotlib, salah satu perpustakaan paling populer untuk visualisasi data dalam Python.
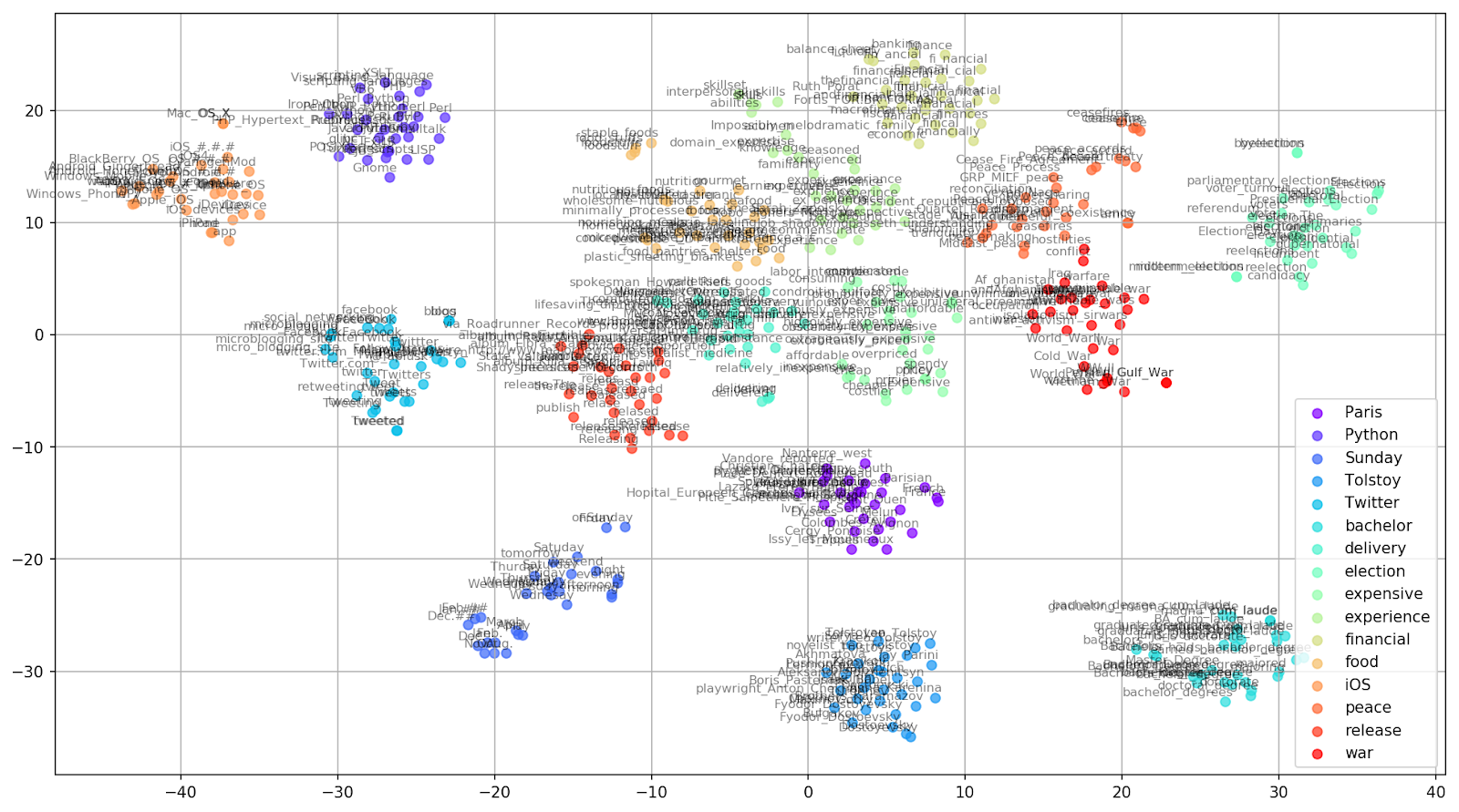 Fig. 2. Cluster kata-kata serupa dari Google News (preplexity = 15).
Fig. 2. Cluster kata-kata serupa dari Google News (preplexity = 15). from sklearn.manifold import TSNE import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np % matplotlib inline def tsne_plot_similar_words(labels, embedding_clusters, word_clusters, a=0.7): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, len(labels))) for label, embeddings, words, color in zip(labels, embedding_clusters, word_clusters, colors): x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=color, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.5, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=8) plt.legend(loc=4) plt.grid(True) plt.savefig("f/.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_similar_words(keys, embeddings_en_2d, word_clusters)
Dalam beberapa kasus, akan berguna untuk memplot semua vektor kata sekaligus untuk melihat keseluruhan gambar. Mari kita menganalisis Anna Karenina, sebuah novel epik tentang hasrat, intrik, tragedi, dan penebusan.
prepare_for_w2v('data/Anna Karenina by Leo Tolstoy (ru).txt', 'train_anna_karenina_ru.txt', 'russian') model_ak = train_word2vec('train_anna_karenina_ru.txt') words = [] embeddings = [] for word in list(model_ak.wv.vocab): embeddings.append(model_ak.wv[word]) words.append(word) tsne_ak_2d = TSNE(n_components=2, init='pca', n_iter=3500, random_state=32) embeddings_ak_2d = tsne_ak_2d.fit_transform(embeddings)
def tsne_plot_2d(label, embeddings, words=[], a=1): plt.figure(figsize=(16, 9)) colors = cm.rainbow(np.linspace(0, 1, 1)) x = embeddings[:,0] y = embeddings[:,1] plt.scatter(x, y, c=colors, alpha=a, label=label) for i, word in enumerate(words): plt.annotate(word, alpha=0.3, xy=(x[i], y[i]), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom', size=10) plt.legend(loc=4) plt.grid(True) plt.savefig("hhh.png", format='png', dpi=150, bbox_inches='tight') plt.show() tsne_plot_2d('Anna Karenina by Leo Tolstoy', embeddings_ak_2d, a=0.1)
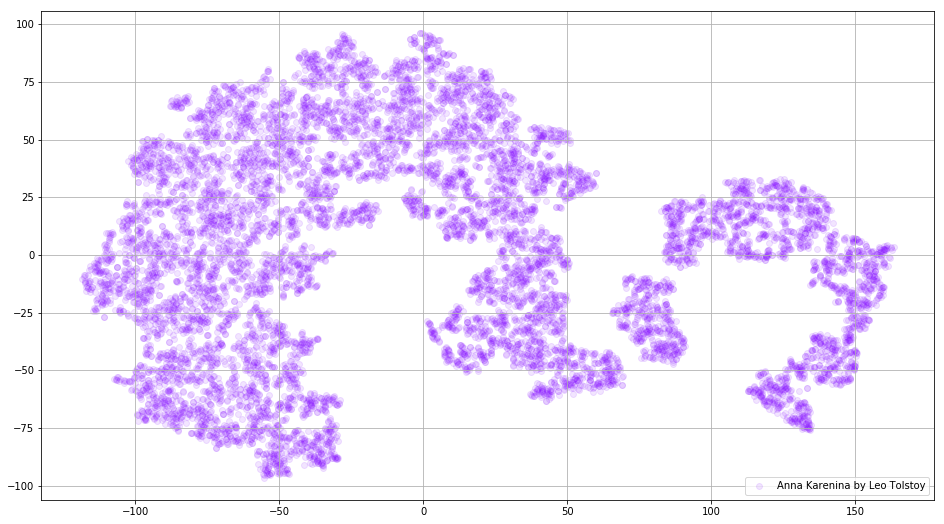
 Fig. 3. Visualisasi model Word2Vec yang dilatih tentang Anna Karenina.
Fig. 3. Visualisasi model Word2Vec yang dilatih tentang Anna Karenina.Seluruh gambar bisa lebih informatif jika kita memetakan embeddings awal dalam ruang 3D. Pada saat ini mari kita melihat Perang dan Perdamaian, salah satu novel vital sastra dunia dan salah satu prestasi sastra terbesar Tolstoy.
prepare_for_w2v('data/War and Peace by Leo Tolstoy (ru).txt', 'train_war_and_peace_ru.txt', 'russian') model_wp = train_word2vec('train_war_and_peace_ru.txt') words_wp = [] embeddings_wp = [] for word in list(model_wp.wv.vocab): embeddings_wp.append(model_wp.wv[word]) words_wp.append(word) tsne_wp_3d = TSNE(perplexity=30, n_components=3, init='pca', n_iter=3500, random_state=12) embeddings_wp_3d = tsne_wp_3d.fit_transform(embeddings_wp)
from mpl_toolkits.mplot3d import Axes3D def tsne_plot_3d(title, label, embeddings, a=1): fig = plt.figure() ax = Axes3D(fig) colors = cm.rainbow(np.linspace(0, 1, 1)) plt.scatter(embeddings[:, 0], embeddings[:, 1], embeddings[:, 2], c=colors, alpha=a, label=label) plt.legend(loc=4) plt.title(title) plt.show() tsne_plot_3d('Visualizing Embeddings using t-SNE', 'War and Peace', embeddings_wp_3d, a=0.1)
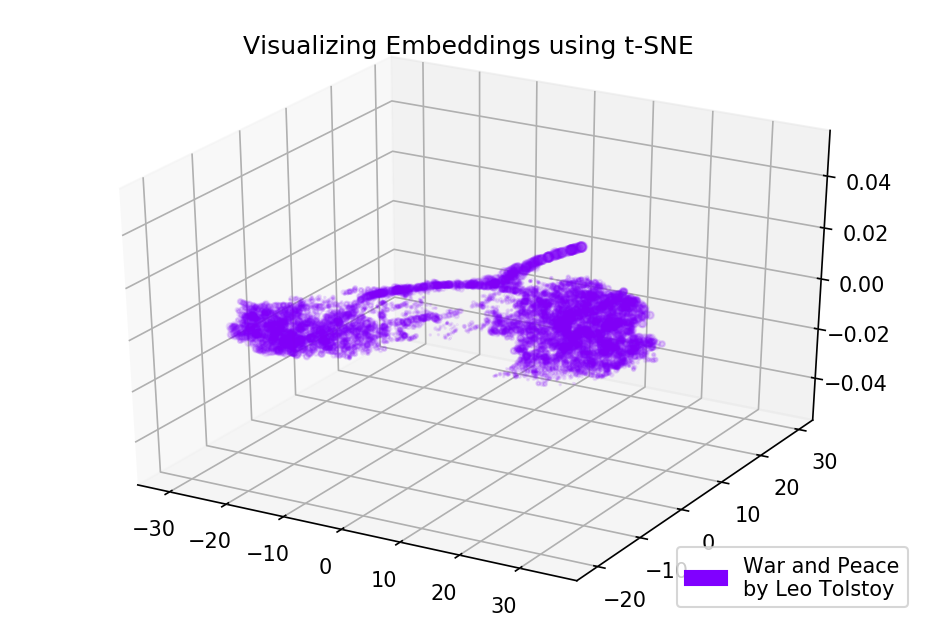 Fig. 4. Visualisasi model Word2Vec yang dilatih tentang Perang dan Perdamaian.
Fig. 4. Visualisasi model Word2Vec yang dilatih tentang Perang dan Perdamaian.Hasilnya
Seperti inilah bentuk teks dari prospektif Word2Vec dan t-SNE. Kami merencanakan bagan yang cukup informatif untuk kata-kata serupa dari Google News dan dua diagram untuk novel Tolstoy. Juga, satu hal lagi, GIF! GIF mengagumkan, tetapi memplot GIF hampir sama dengan memplot grafik biasa. Jadi, saya memutuskan untuk tidak menyebutkannya di artikel, tetapi Anda dapat menemukan kode untuk generasi animasi di sumbernya.
Kode sumber tersedia di
Github .
Artikel ini awalnya diterbitkan di
Menuju Ilmu Data .
Referensi
- L. Maate dan G. Hinton, "Visualisasi data menggunakan t-SNE", Journal of Machine Learning Research, vol. 9, hlm. 2579-2605, 2008.
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado dan J. Dean, "Perwakilan Kata dan Frasa Terdistribusi dan Komposisionalitasnya", Kemajuan dalam Sistem Pemrosesan Informasi Saraf Tiruan, hal. 3111-3119, 2013.
- R. Rehurek dan P. Sojka, "Kerangka Perangkat Lunak untuk Pemodelan Topik dengan Perusahaan Besar," Prosiding Lokakarya LREC 2010 tentang Tantangan Baru untuk Kerangka NLP, 2010.