Pengujian komparatif dari cache multi-threaded diimplementasikan dalam C / C ++ dan deskripsi bagaimana cache LRU / MRU dari cache O (n) Cache ** RU diatur
Selama beberapa dekade, banyak algoritma caching telah dikembangkan: LRU, MRU, ARC, dan lainnya .... Namun, ketika cache diperlukan untuk pekerjaan multi-threaded, google pada topik ini memberikan satu setengah opsi, dan pertanyaan tentang StackOverflow umumnya tetap tidak terjawab. Saya menemukan solusi dari Facebook yang bergantung pada wadah aman dari repositori Intel TBB . Yang terakhir juga memiliki cache LRU multi-threaded yang masih dalam pengujian beta dan oleh karena itu, untuk menggunakannya, Anda harus secara eksplisit menentukan dalam proyek:
#define TBB_PREVIEW_CONCURRENT_LRU_CACHE true
Jika tidak, kompiler akan menampilkan kesalahan karena ada tanda centang pada kode Intel TBB:
#if ! TBB_PREVIEW_CONCURRENT_LRU_CACHE #error Set TBB_PREVIEW_CONCURRENT_LRU_CACHE to include concurrent_lru_cache.h #endif
Saya ingin entah bagaimana membandingkan kinerja cache - yang mana yang harus dipilih? Atau tulis sendiri? Sebelumnya, ketika saya membandingkan cache single-threaded ( tautan ), saya menerima penawaran untuk mencoba kondisi lain dengan kunci lain dan menyadari bahwa diperlukan bangku tes yang dapat diperpanjang yang lebih nyaman. Agar lebih mudah untuk menambahkan algoritma yang bersaing ke dalam tes, saya memutuskan untuk membungkusnya dalam antarmuka standar:
class IAlgorithmTester { public: IAlgorithmTester() = default; virtual ~IAlgorithmTester() { } virtual void onStart(std::shared_ptr<IConfig> &cfg) = 0; virtual void onStop() = 0; virtual void insert(void *elem) = 0; virtual bool exist(void *elem) = 0; virtual const char * get_algorithm_name() = 0; private: IAlgorithmTester(const IAlgorithmTester&) = delete; IAlgorithmTester& operator=(const IAlgorithmTester&) = delete; };
Demikian pula, antarmuka dibungkus: bekerja dengan sistem operasi, mendapatkan pengaturan, menguji kasus, dll. Sumber diletakkan dalam repositori . Ada dua test case di stand: sisipkan / cari hingga 1.000.000 elemen dengan kunci dari angka yang dihasilkan secara acak dan hingga 100.000 elemen dengan kunci string (diambil dari 10Mb garis wiki.train.tokens). Untuk mengevaluasi waktu eksekusi, setiap cache tes pertama-tama dipanaskan ke volume target tanpa pengukuran waktu, kemudian semaphore mengeluarkan aliran dari rantai untuk menambahkan dan mencari data. Jumlah utas dan pengaturan test case diatur dalam aset / settings.json . Petunjuk kompilasi langkah demi langkah dan deskripsi pengaturan JSON dijelaskan dalam repositori WiKi . Waktu dilacak sejak semafor dilepaskan hingga utas terakhir berhenti. Inilah yang terjadi:
Test case1 - kunci dalam bentuk array angka acak uint64_t keyArray [3]:
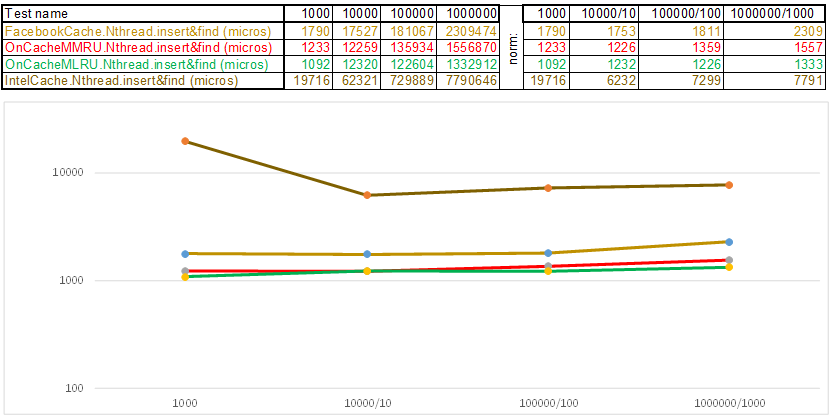
Uji case2 - kunci sebagai string:
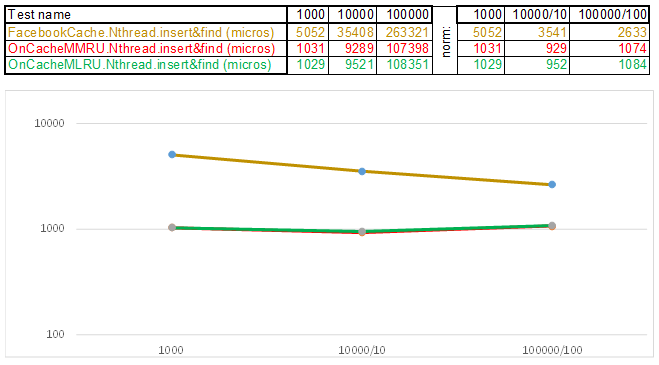
Harap dicatat bahwa volume data yang dimasukkan / dicari pada setiap langkah dari test case meningkat 10 kali lipat. Kemudian, waktu yang dihabiskan untuk memproses volume berikutnya, saya bagi dengan 10, 100, 1000, masing-masing ... Jika algoritma berperilaku seperti O (n) dalam kompleksitas waktu, maka timeline akan tetap kira-kira sejajar dengan sumbu X. Selanjutnya, saya akan mengungkapkan pengetahuan suci, seperti yang saya kelola dapatkan 3-5 kali keunggulan dari cache Facebook di algoritme O (n) Cache ** RU saat bekerja dengan kunci string:
- Fungsi hash, alih-alih membaca setiap huruf dari string, cukup melemparkan pointer ke data string ke uint64_t keyArray [3] dan menghitung jumlah bilangan bulat. Yaitu, ini berfungsi seperti program "Tebak melodi" - dan saya kira melodi dengan 3 catatan ... 3 * 8 = 24 huruf jika itu bahasa Latin, dan ini sudah memungkinkan Anda untuk menyebarkan garis dengan cukup baik di keranjang hash. Ya, banyak baris dapat dikumpulkan dalam keranjang hash, dan di sini algoritme mulai dipercepat:
- Daftar Lewati di setiap keranjang memungkinkan Anda untuk melompat dengan cepat terlebih dahulu dalam hash yang berbeda (id keranjang = hash% jumlah keranjang, sehingga hash yang berbeda dapat muncul dalam satu keranjang), lalu dalam hash yang sama di sepanjang simpul:
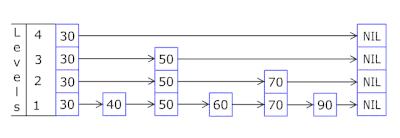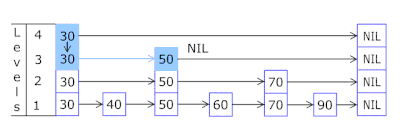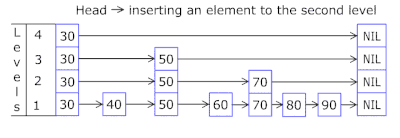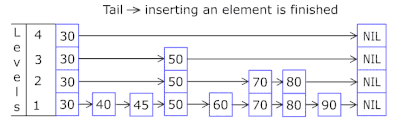
- Node di mana kunci dan data disimpan diambil dari array node yang sebelumnya dialokasikan, jumlah node bertepatan dengan kapasitas cache. Pengidentifikasi Atom menunjukkan simpul mana yang akan diambil berikutnya - jika mencapai akhir kumpulan simpul, dimulai dengan 0 = sehingga pengalokasi berjalan dalam lingkaran menimpa node lama ( cache LRU di OnCacheMLRU ).
Untuk kasus ketika perlu bahwa elemen paling populer dalam permintaan pencarian disimpan dalam cache, kelas OnCacheMMRU kedua dibuat , algoritma adalah sebagai berikut: selain kapasitas cache, konstruktor kelas juga melewati parameter kedua uint32_t kegunaan, batas popularitas adalah jika jumlah permintaan pencarian yang ingin simpul saat ini dari cyclic pool berkurang Jika batas-batasnya tidak berguna, maka simpul tersebut digunakan kembali untuk operasi penyisipan berikutnya (akan digusur). Jika pada lingkaran ini popularitas node (std :: atomic <uint32_t> yang digunakan {0}) tinggi, maka pada saat meminta pengalokasi dari kumpulan siklus, node akan dapat bertahan, tetapi penghitung popularitas akan diatur ulang ke 0. Jadi akan ada lingkaran lain dari pengalokasi pengalokasian pada kumpulan node dan akan mendapatkan kesempatan untuk mendapatkan kembali popularitas agar terus eksis. Yaitu, itu adalah campuran dari algoritma MRU (di mana yang paling populer bertahan dalam cache selamanya) dan MQ (di mana seumur hidup dilacak). Cache terus diperbarui dan pada saat yang sama berfungsi dengan sangat cepat - alih-alih 10 server Anda dapat menempatkan 1 ..
Secara umum, algoritma caching menghabiskan waktu untuk hal-hal berikut:
- Memelihara infrastruktur cache (wadah, pengalokasi, pelacakan masa pakai dan popularitas elemen)
- Perhitungan hash dan operasi perbandingan utama saat menambahkan / mencari data
- Algoritma Pencarian: Pohon Merah-Hitam, Tabel Hash, Daftar Lewati, ...
Itu hanya perlu untuk mengurangi waktu operasi dari masing-masing item ini, mengingat fakta bahwa algoritma paling sederhana adalah kompleks untuk sementara dan seringkali paling efisien, karena logika apa pun membutuhkan siklus CPU. Yaitu, apa pun yang Anda tulis, ini adalah operasi yang harus terbayar tepat waktu dibandingkan dengan metode enumerasi sederhana: sementara fungsi selanjutnya disebut, enumerasi harus melalui ratusan atau dua node lainnya. Dalam hal ini, cache multi-threaded akan selalu hilang dalam mode single-threaded, karena melindungi keranjang melalui std :: shared_mutex dan node melalui std :: atomic_flag in_use tidak gratis. Oleh karena itu, untuk mengeluarkan di server, saya menggunakan cache single-threaded OnCacheSMRU di utas server Epoll utama (hanya operasi panjang pada bekerja dengan DBMS, disk, kriptografi diambil dalam alur kerja paralel). Untuk penilaian komparatif, versi kasus uji single-threaded digunakan:
Test case1 - kunci dalam bentuk array angka acak uint64_t keyArray [3]:

Uji case2 - kunci sebagai string:
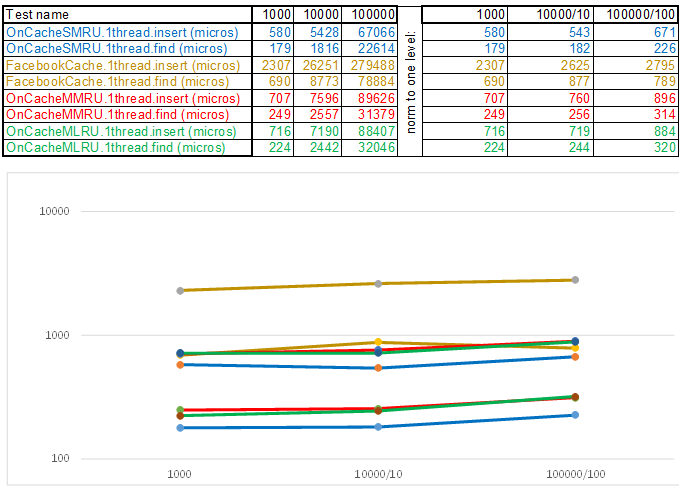
Sebagai kesimpulan, saya ingin memberi tahu Anda hal lain yang menarik yang dapat diekstraksi dari sumber bangku tes:
- Parsing pustaka JSON, yang terdiri dari satu file specjson.h, adalah algoritma cepat kecil yang sederhana untuk mereka yang tidak ingin menyeret beberapa megabyte kode orang lain ke dalam proyek mereka untuk mengurai file pengaturan atau JSON masuk dari format yang dikenal.
- Suatu pendekatan dengan menyuntikkan implementasi operasi platform spesifik dalam bentuk (kelas LinuxSystem: public ISystem {...}) alih-alih tradisional (#ifdef _WIN32). Lebih mudah untuk membungkus, misalnya, semaphore, bekerja dengan perpustakaan yang terhubung secara dinamis, layanan - di kelas hanya ada kode dan header dari sistem operasi tertentu. Jika Anda membutuhkan sistem operasi lain, Anda menyuntikkan implementasi lain (kelas WindowsSystem: public ISystem {...}).
- Stand akan menuju CMake - akan lebih mudah untuk membuka proyek CMakeLists.txt di Qt Creator atau Microsoft Visual Studio 2017. Bekerja dengan proyek melalui CmakeLists.txt memungkinkan Anda untuk mengotomatiskan beberapa operasi persiapan - misalnya, menyalin file kasus uji dan file konfigurasi ke direktori instalasi:
- Bagi mereka yang menguasai fitur-fitur baru C ++ 17, ini adalah contoh bekerja dengan std :: shared_mutex, std :: pengalokasi <std :: shared_mutex>, static thread_local di templat (ada nuansa - di mana mengalokasikan?), Meluncurkan sejumlah besar tes di utas dalam berbagai cara dengan mengukur waktu eksekusi:
- Petunjuk langkah demi langkah tentang cara mengompilasi, mengkonfigurasi dan menjalankan bangku tes ini - WiKi .
Jika Anda belum memiliki petunjuk langkah demi langkah untuk sistem operasi yang nyaman, saya akan berterima kasih atas kontribusi ke repositori untuk menerapkan ISystem dan instruksi kompilasi langkah demi langkah (untuk WiKi) ... Atau cukup tulis saya - Saya akan mencoba mencari waktu untuk meningkatkan mesin virtual dan menjelaskan langkah-langkah untuk perakitan.