Halo, Habr! Saya mempersembahkan kepada Anda sebuah posting yang merupakan adaptasi teks dari kinerja
Stella Cotton di RailsConf 2018 dan terjemahan dari artikel
“Membangun Arsitektur Berorientasi Layanan dengan Rails dan Kafka” oleh Stella Cotton.
Baru-baru ini, transisi dari arsitektur monolitik ke layanan-mikro terlihat jelas. Dalam panduan ini, kita akan mempelajari dasar-dasar Kafka dan bagaimana pendekatan berbasis peristiwa dapat meningkatkan aplikasi Rails Anda. Kami juga akan berbicara tentang masalah pemantauan dan skalabilitas layanan yang bekerja melalui pendekatan berorientasi peristiwa.
Apa itu Kafka?
Saya yakin Anda ingin memiliki informasi tentang bagaimana pengguna Anda datang ke platform Anda atau halaman apa yang mereka kunjungi, tombol mana yang mereka klik, dll. Aplikasi yang benar-benar populer dapat menghasilkan milyaran acara dan mengirimkan sejumlah besar data ke layanan analitik, yang dapat menjadi tantangan serius bagi aplikasi Anda.
Sebagai aturan, bagian integral dari aplikasi web membutuhkan apa yang disebut
aliran data waktu nyata . Kafka menyediakan koneksi toleran-kesalahan antara
produsen , mereka yang menghasilkan acara, dan
konsumen , mereka yang menerima acara ini. Bahkan mungkin ada beberapa produsen dan konsumen dalam satu aplikasi. Di Kafka, setiap acara ada untuk waktu tertentu, sehingga beberapa konsumen dapat membaca acara yang sama berulang kali. Cluster Kafka mencakup beberapa broker yang merupakan instance Kafka.
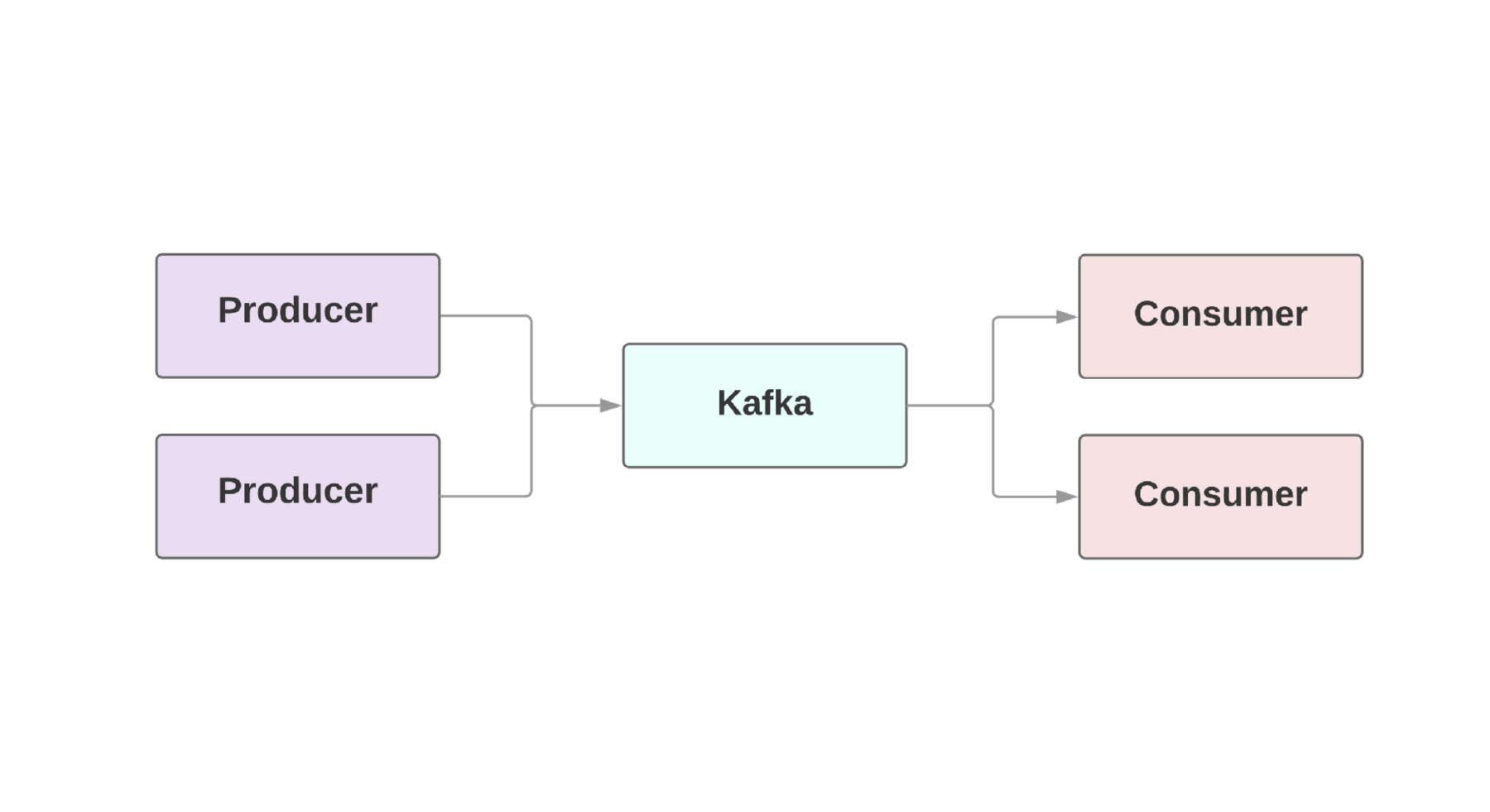
Fitur utama Kafka adalah kecepatan tinggi pemrosesan acara. Sistem antrian tradisional, seperti AMQP, memiliki infrastruktur yang memantau acara yang diproses untuk setiap konsumen. Ketika jumlah konsumen tumbuh ke tingkat yang layak, sistem hampir tidak mulai mengatasi beban, karena harus memantau peningkatan jumlah kondisi. Juga, ada masalah besar dengan konsistensi antara konsumen dan pemrosesan acara. Misalnya, apakah ada baiknya segera menandai pesan yang dikirim segera setelah diproses oleh sistem? Dan jika konsumen jatuh ke ujung tanpa menerima pesan?
Kafka juga memiliki arsitektur gagal-aman. Sistem berjalan sebagai cluster di satu atau lebih server, yang dapat diskalakan secara horizontal dengan menambahkan mesin baru. Semua data ditulis ke disk dan disalin ke beberapa broker. Untuk memahami kemungkinan skalabilitas, ada baiknya melihat perusahaan seperti Netflix, LinkedIn, Microsoft. Semuanya mengirim triliunan pesan per hari melalui kelompok Kafka mereka!
Menyiapkan Kafka di Rails
Heroku menyediakan
add-on cluster Kafka yang dapat digunakan untuk lingkungan apa pun. Untuk aplikasi ruby, kami sarankan menggunakan
permata ruby-kafka . Implementasi minimal terlihat seperti ini:
Setelah mengkonfigurasi konfigurasi, Anda dapat menggunakan permata untuk mengirim pesan. Berkat pengiriman acara yang tidak sinkron, kami dapat mengirim pesan dari mana saja:
class OrdersController < ApplicationController def create @comment = Order.create!(params) $kafka_producer.produce(order.to_json, topic: "user_event", partition_key: user.id) end end
Kami akan berbicara tentang format serialisasi di bawah ini, tetapi untuk sekarang kami akan menggunakan JSON lama yang bagus. Argumen
topic merujuk pada log tempat Kafka menulis acara ini. Topik tersebar di bagian yang berbeda, yang memungkinkan Anda untuk membagi data untuk topik tertentu menjadi broker yang berbeda untuk skalabilitas dan keandalan yang lebih baik. Dan itu benar-benar ide yang baik untuk memiliki dua bagian atau lebih untuk setiap topik, karena jika salah satu bagian jatuh, acara Anda akan direkam dan diproses. Kafka memastikan bahwa acara dikirimkan sesuai urutan antrian di dalam bagian, tetapi tidak dalam keseluruhan topik. Jika urutan peristiwa penting, maka mengirim partisi_key memastikan bahwa semua peristiwa dari jenis tertentu disimpan di partisi yang sama.
Kafka untuk layanan Anda
Beberapa fitur yang menjadikan Kafka alat yang berguna juga menjadikannya RPC failover antar layanan. Lihatlah contoh aplikasi e-commerce:
def create_order create_order_record charge_credit_card
Ketika pengguna melakukan pemesanan, fungsi
create_order . Ini menciptakan pesanan dalam sistem, mengurangi uang dari kartu dan mengirim email dengan konfirmasi. Seperti yang Anda lihat, dua langkah terakhir diambil dalam layanan terpisah.
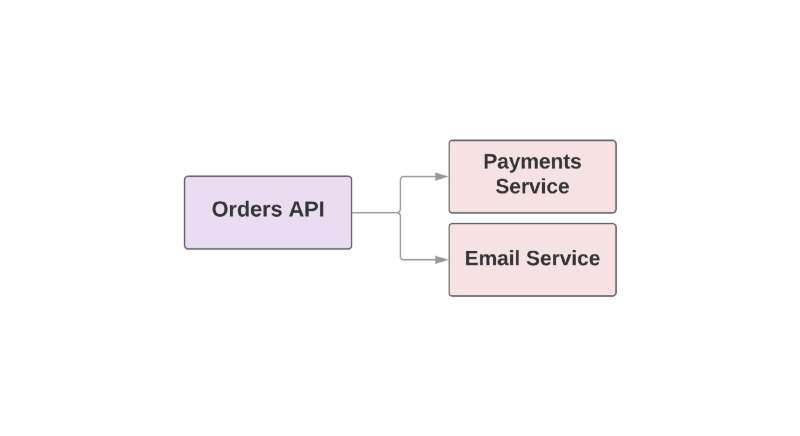
Salah satu masalah dengan pendekatan ini adalah bahwa layanan unggul dalam hierarki bertanggung jawab untuk memantau ketersediaan layanan hilir. Jika layanan untuk mengirim surat ternyata hari yang buruk, layanan yang lebih tinggi perlu mengetahuinya. Dan jika layanan pengiriman tidak tersedia, maka Anda perlu mengulang serangkaian tindakan tertentu. Bagaimana Kafka dapat membantu dalam situasi ini?
Sebagai contoh:
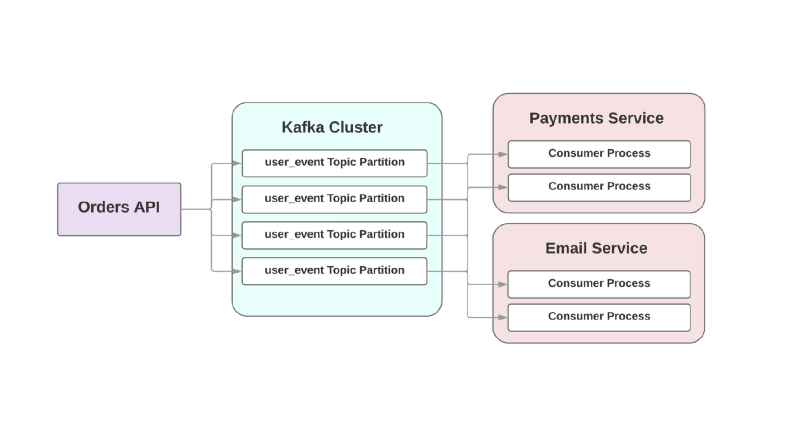
Dalam pendekatan yang didorong oleh peristiwa ini, layanan yang unggul dapat merekam acara di Kafka yang telah dibuat pesanan. Karena apa yang disebut pendekatan
setidaknya satu kali , acara ini akan direkam di Kafka setidaknya sekali dan akan tersedia bagi konsumen hilir untuk membaca. Jika layanan pengiriman surat berbohong, acara akan menunggu di disk hingga konsumen naik dan membacanya.
Masalah lain dengan arsitektur berorientasi RPC adalah dalam sistem yang tumbuh cepat: menambahkan layanan hilir baru memerlukan perubahan di hulu. Misalnya, Anda ingin menambahkan satu langkah lagi setelah membuat pesanan. Di dunia yang didorong oleh peristiwa, Anda perlu menambahkan konsumen lain untuk menangani jenis acara baru.

Mengintegrasikan Acara ke dalam Arsitektur Berorientasi Layanan
Sebuah posting berjudul "
Apa yang Anda maksud dengan" Event-Driven "oleh Martin Fowler membahas kebingungan seputar aplikasi yang dikendalikan oleh peristiwa. Ketika pengembang membahas sistem seperti itu, mereka sebenarnya berbicara tentang sejumlah besar aplikasi yang berbeda. Untuk memberikan pemahaman umum tentang sifat sistem tersebut, Fowler mendefinisikan beberapa pola arsitektur.
Mari kita lihat apa saja pola-pola ini. Jika Anda ingin tahu lebih banyak, saya sarankan Anda membaca
laporannya di GOTO Chicago 2017.
Pemberitahuan acara
Pola Fowler pertama disebut
Pemberitahuan Acara . Dalam skenario ini, layanan produsen memberi tahu konsumen tentang acara tersebut dengan informasi minimum:
{ "event": "order_created", "published_at": "2016-03-15T16:35:04Z" }
Jika konsumen membutuhkan lebih banyak informasi tentang acara tersebut, mereka meminta kepada produsen dan mendapatkan lebih banyak data.
Transfer status berdasarkan peristiwa
Templat kedua disebut
Transfer Keadaan Acara-Carried . Dalam skenario ini, produsen memberikan informasi tambahan tentang acara dan konsumen dapat menyimpan salinan data ini tanpa membuat panggilan tambahan:
{ "event": "order_created", "order": { "order_id": 98765, "size": "medium", "color": "blue" }, "published_at": "2016-03-15T16:35:04Z" }
Sumber acara
Fowler menyebut templat ketiga
Event-Sourced dan lebih bersifat arsitektur. Pelepasan templat tidak hanya melibatkan komunikasi antara layanan Anda, tetapi juga pelestarian presentasi acara. Ini memastikan bahwa bahkan jika Anda kehilangan database, Anda masih dapat mengembalikan keadaan aplikasi dengan hanya menjalankan aliran acara yang disimpan. Dengan kata lain, setiap peristiwa menyimpan keadaan tertentu dari aplikasi pada saat tertentu.
Masalah besar dengan pendekatan ini adalah bahwa kode aplikasi selalu berubah, dan dengan itu format atau jumlah data yang diberikan produsen dapat berubah. Ini membuat mengembalikan status aplikasi bermasalah.
Segregasi Tanggung Jawab Permintaan Perintah
Dan templat terakhir adalah
Segregasi Command Query Responsibility , atau CQRS. Idenya adalah bahwa tindakan yang Anda terapkan ke objek, misalnya: membuat, membaca, memperbarui, harus dibagi ke dalam berbagai domain. Ini berarti bahwa satu layanan harus bertanggung jawab atas pembuatan, yang lain untuk pembaruan, dll. Dalam sistem berorientasi objek, semuanya sering disimpan dalam satu layanan.
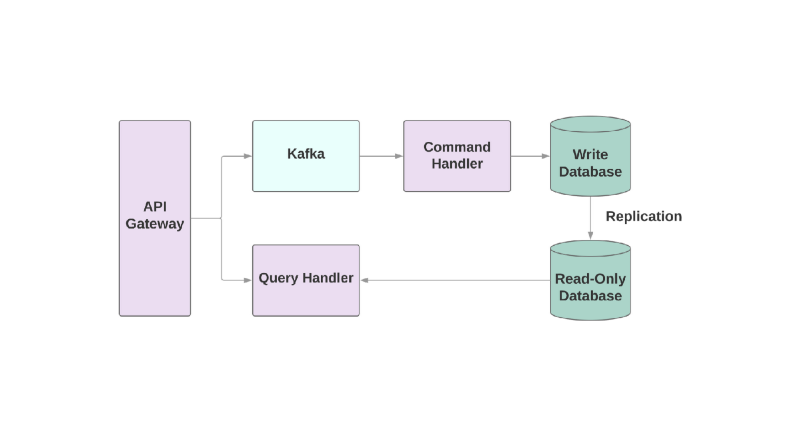
Layanan yang menulis ke basis data akan membaca aliran acara dan memproses perintah. Tetapi setiap permintaan hanya terjadi di database read-only. Membagi logika baca dan tulis menjadi dua layanan yang berbeda meningkatkan kompleksitas, tetapi memungkinkan Anda untuk mengoptimalkan kinerja secara terpisah untuk sistem ini.
Masalahnya
Mari kita bicara tentang beberapa masalah yang mungkin Anda temui ketika mengintegrasikan Kafka ke aplikasi berorientasi layanan Anda.
Masalah pertama mungkin lambat konsumen. Dalam sistem yang berorientasi pada peristiwa, layanan Anda harus dapat memproses acara secara instan saat diterima dari layanan yang unggul. Jika tidak, mereka hanya akan hang tanpa pemberitahuan tentang masalah atau batas waktu. Satu-satunya tempat di mana Anda dapat menentukan batas waktu adalah koneksi soket dengan broker Kafka. Jika layanan tidak menangani acara dengan cukup cepat, koneksi dapat terputus oleh batas waktu, tetapi memulihkan layanan memerlukan waktu tambahan, karena membuat soket seperti itu mahal.
Jika konsumen lambat, bagaimana Anda bisa meningkatkan kecepatan pemrosesan acara? Di Kafka, Anda dapat meningkatkan jumlah konsumen dalam grup, sehingga lebih banyak acara dapat diproses secara paralel. Tetapi setidaknya 2 konsumen akan diminta untuk satu layanan: jika salah satu jatuh, bagian yang rusak dapat dipindahkan.
Juga sangat penting untuk memiliki metrik dan peringatan untuk memantau kecepatan pemrosesan acara.
ruby-kafka dapat bekerja dengan peringatan ActiveSupport, ia juga memiliki modul StatsD dan Datadog, yang diaktifkan secara default. Selain itu, permata memberikan
daftar metrik yang disarankan untuk pemantauan.
Aspek penting lain dari membangun sistem dengan Kafka adalah desain konsumen dengan kemampuan untuk menangani kegagalan. Kafka dijamin mengirim acara setidaknya satu kali; mengecualikan kasing ketika pesan tidak dikirim sama sekali. Tetapi penting bahwa konsumen siap untuk menangani acara yang berulang. Salah satu cara untuk melakukan ini adalah dengan selalu menggunakan
UPSERT untuk menambahkan catatan baru ke database. Jika catatan sudah ada dengan atribut yang sama, panggilan pada dasarnya tidak aktif. Selain itu, Anda dapat menambahkan pengidentifikasi unik untuk setiap peristiwa dan hanya melewati acara yang sudah diproses sebelumnya.
Format data
Salah satu kejutan ketika bekerja dengan Kafka mungkin adalah sikapnya yang sederhana terhadap format data. Anda dapat mengirim apa pun dalam byte dan data akan dikirim ke konsumen tanpa verifikasi apa pun. Di satu sisi, ini memberikan fleksibilitas dan memungkinkan Anda untuk tidak peduli dengan format data. Di sisi lain, jika produsen memutuskan untuk mengubah data yang dikirim, ada kemungkinan beberapa konsumen pada akhirnya akan rusak.
Sebelum membangun arsitektur berorientasi acara, pilih format data dan analisis bagaimana itu akan membantu di masa depan untuk mendaftar dan mengembangkan skema.
Salah satu format yang direkomendasikan untuk digunakan, tentu saja, adalah JSON. Format ini dapat dibaca oleh manusia dan didukung oleh semua bahasa pemrograman yang dikenal. Tapi ada jebakan. Misalnya, ukuran data akhir di JSON bisa menjadi sangat besar. Format ini diperlukan untuk menyimpan pasangan nilai kunci, yang cukup fleksibel, tetapi data digandakan di setiap peristiwa. Mengubah skema juga merupakan tugas yang sulit karena tidak ada dukungan bawaan untuk overlay satu kunci pada yang lain jika Anda perlu mengganti nama bidang.
Tim yang menciptakan Kafka menyarankan
Avro sebagai sistem serialisasi. Data dikirim dalam bentuk biner, dan ini bukan format yang paling dapat dibaca manusia, tetapi di dalamnya ada dukungan yang lebih dapat diandalkan untuk sirkuit. Entitas terakhir di Avro mencakup skema dan data. Avro juga mendukung kedua tipe sederhana, seperti angka, dan yang kompleks: tanggal, array, dll. Selain itu, Avro juga memungkinkan Anda untuk memasukkan dokumentasi di dalam skema, yang memungkinkan Anda untuk memahami tujuan bidang tertentu dalam sistem dan berisi banyak alat bawaan lainnya untuk bekerja dengan skema tersebut.
avro-builder adalah permata yang dibuat oleh Salsify yang menawarkan DSL seperti ruby untuk membuat skema. Anda dapat membaca lebih lanjut tentang Avro di
artikel ini .
Informasi tambahan
Jika Anda tertarik untuk meng-host Kafka atau bagaimana menggunakannya di Heroku, ada beberapa laporan yang mungkin menarik bagi Anda.
Jeff Chao di DataEngConf SF '17 “
Melampaui 50.000 Partisi: Bagaimana Heroku Mengoperasikan dan Mendorong Batas Kafka pada Skala ”
Pavel Pravosud di Dreamforce '16 “
Dogfooding Kafka: Bagaimana Kami Membangun Streaming Platform Platform Real-Time Heroku ”
Selamat menikmati!