Log adalah bagian penting dari sistem, memungkinkan Anda untuk memahami bahwa itu berfungsi (atau tidak berfungsi), seperti yang diharapkan. Dalam kondisi arsitektur microservice, bekerja dengan log menjadi disiplin terpisah dari Olimpiade khusus. Anda harus segera memecahkan banyak pertanyaan:
- cara menulis log dari aplikasi;
- tempat menulis log;
- cara mengirim log untuk penyimpanan dan pemrosesan;
- cara memproses dan menyimpan log.
Penggunaan teknologi kontainerisasi, sekarang populer, menambahkan pasir di atas rake ke bidang pilihan untuk memecahkan masalah.
Hanya tentang ini decoding dari laporan Yuri Bushmelev "Peta menyapu di bidang pengumpulan dan pengiriman kayu bulat"
Siapa yang peduli, tolong, di bawah kucing.
Nama saya Yuri Bushmelev. Saya bekerja di Lazada. Hari ini saya akan berbicara tentang bagaimana kami membuat log, bagaimana kami mengumpulkannya, dan apa yang kami tulis di sana.

Dari mana kita berasal? Siapa kita? Lazada adalah toko online No. 1 di enam negara di Asia Tenggara. Semua negara ini didistribusikan oleh pusat data. Sekarang ada pusat data 4. Mengapa ini penting? Karena beberapa keputusan disebabkan oleh fakta bahwa ada hubungan yang sangat lemah antara pusat. Kami memiliki arsitektur microservice. Saya terkejut menemukan bahwa kami sudah memiliki 80 layanan mikro. Ketika saya memulai tugas dengan log, hanya ada 20. Plus, ada bagian yang cukup besar dari warisan PHP, yang Anda juga harus hidup dengan dan bertahan. Semua ini menghasilkan bagi kita saat ini lebih dari 6 juta pesan per menit di seluruh sistem secara keseluruhan. Selanjutnya saya akan menunjukkan bagaimana kita mencoba untuk hidup dengannya, dan mengapa demikian.

Kita perlu entah bagaimana hidup dengan 6 juta pesan ini. Apa yang harus kita lakukan dengan mereka? 6 juta pesan yang Anda butuhkan:
- kirim dari aplikasi
- terima untuk pengiriman
- mengirimkan untuk analisis dan penyimpanan.
- untuk menganalisis
- entah bagaimana menyimpan.

Ketika tiga juta pesan muncul, saya memiliki tampilan yang sama. Karena kami mulai dengan beberapa sen. Jelas bahwa log aplikasi ditulis di sana. Misalnya, saya tidak bisa terhubung ke database, saya bisa terhubung ke database, tetapi saya tidak bisa membaca sesuatu. Tapi selain itu, masing-masing layanan microser kami juga menulis log akses. Setiap permintaan yang tiba di microservice masuk ke dalam log. Kenapa kita melakukan ini? Pengembang ingin dapat melacak. Di setiap log akses ada bidang penelusuran, di mana antarmuka khusus lebih lanjut mengurai seluruh rantai dan menampilkan jejak dengan indah. Trace menunjukkan bagaimana permintaan berjalan, dan ini membantu pengembang kami untuk dengan cepat menangani sampah yang tidak dikenal.

Bagaimana cara hidup dengannya? Sekarang saya akan menjelaskan secara singkat bidang pilihan - bagaimana secara umum masalah ini diselesaikan. Cara mengatasi masalah pengumpulan, transfer, dan penyimpanan log.

Bagaimana cara menulis dari aplikasi? Jelas bahwa ada berbagai cara. Secara khusus, ada praktik terbaik, seperti yang dikatakan kawan modis. Ada sekolah tua dalam dua bentuk, seperti kata kakek. Ada beberapa cara lain.

Dengan koleksi log tentang situasi yang sama. Tidak banyak pilihan untuk menyelesaikan bagian ini. Sudah ada lebih banyak, tetapi tidak begitu banyak.

Tetapi dengan pengiriman dan analisis selanjutnya - jumlah variasi mulai meledak. Saya tidak akan menjelaskan setiap opsi sekarang. Saya pikir opsi utama didengar oleh semua orang yang tertarik pada topik.

Saya akan menunjukkan bagaimana kita melakukannya di Lazada, dan bagaimana sebenarnya semua itu dimulai.

Setahun yang lalu, saya datang ke Lazada, dan mereka mengirim saya ke sebuah proyek tentang kayu. Seperti ini. Log dari aplikasi ditulis ke stdout dan stderr. Mereka melakukan segalanya dengan cara yang modis. Tapi kemudian para pengembang membuangnya keluar dari aliran standar, dan kemudian ada spesialis infrastruktur akan mengatasinya entah bagaimana. Antara spesialis infrastruktur dan pengembang ada juga rilis yang mengatakan: "eh ... yah, mari kita bungkus mereka dalam file dengan shell, itu saja." Dan karena semua ini ada di dalam wadah, mereka membungkusnya di dalam wadah itu sendiri, mengunduh katalog di dalam dan meletakkannya di sana. Saya pikir kira-kira sudah jelas bagi semua orang apa yang terjadi.

Mari kita lihat sedikit lebih jauh. Bagaimana cara kami mengirimkan log ini. Seseorang memilih agen-td, yang sebenarnya fluentd, tetapi tidak cukup lancar. Saya masih tidak mengerti hubungan kedua proyek ini, tetapi mereka tampaknya tentang hal yang sama. Dan fluentd ini, ditulis dalam Ruby, membaca file log, menguraikannya dalam JSON untuk beberapa periode reguler. Kemudian dia mengirim mereka ke Kafka. Dan di Kafka untuk setiap API kami memiliki 4 topik terpisah. Mengapa 4? Karena ada hidup, ada pementasan, dan karena ada stdout dan stderr. Pengembang melahirkan mereka, dan insinyur infrastruktur harus membuatnya di Kafka. Apalagi, Kafka dikendalikan oleh departemen lain. Karena itu, perlu membuat tiket sehingga mereka membuat 4 topik untuk masing-masing api di sana. Semua orang lupa tentang itu. Secara umum, ada sampah dan asap.
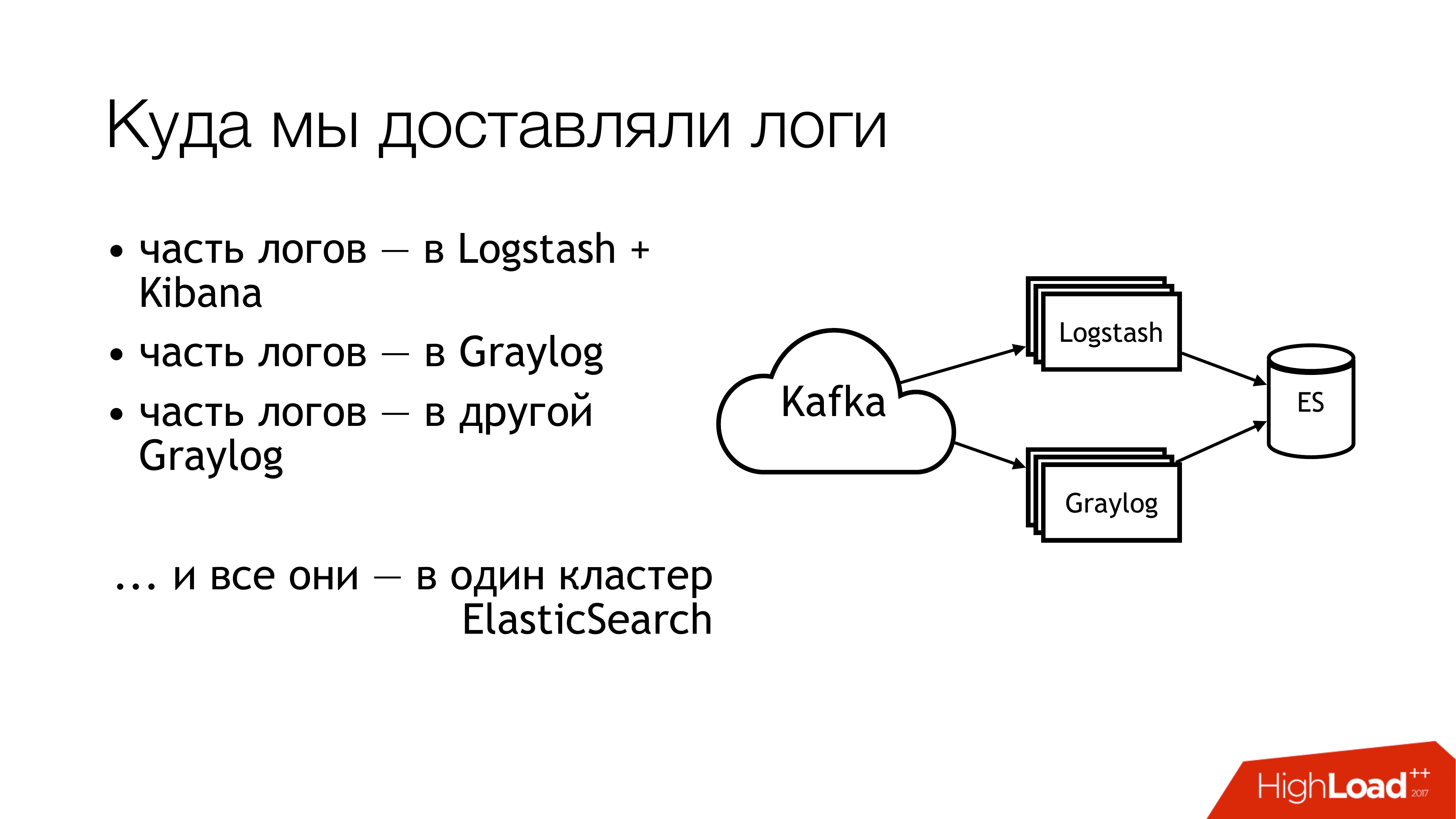
Apa yang kita lakukan selanjutnya dengan ini? Kami mengirimnya ke kafka. Lebih jauh dari Kafka, setengah dari log terbang ke Logstash. Setengah lainnya dari log dibagikan. Sebagian terbang menjadi satu Graylog, sebagian - ke Graylog lainnya. Akibatnya, semua ini terbang menjadi satu cluster Elasticsearch. Artinya, seluruh kekacauan ini akhirnya jatuh di sana. Anda tidak harus melakukan ini!

Ini adalah tampilannya jika Anda terlihat jauh dari atas. Jangan lakukan ini! Di sini, angka-angka segera menunjukkan area masalah. Sebenarnya ada lebih banyak dari mereka, tetapi 6 benar-benar cukup bermasalah, yang dengannya Anda perlu melakukan sesuatu. Saya akan membicarakannya secara terpisah sekarang.

Di sini (1,2,3) kami menulis file dan, karenanya, inilah tiga rake sekaligus.
Yang pertama (1) adalah bahwa kita perlu menuliskannya di suatu tempat. Saya tidak selalu ingin memberi API kemampuan untuk menulis langsung ke file. Sangat diharapkan bahwa API diisolasi dalam wadah, dan bahkan lebih baik, bahwa itu hanya baca. Saya seorang sysadmin, jadi saya memiliki pandangan sedikit alternatif tentang hal-hal ini.
Poin kedua (2,3) - kami memiliki banyak permintaan yang datang ke API. API menulis banyak data ke file. File tumbuh. Kita perlu memutarnya. Karena kalau tidak, tidak ada cara untuk mendapatkan disk. Memutarnya buruk karena dialihkan melalui shell ke direktori. Kami tidak bisa memindahkannya dengan cara apa pun. Aplikasi tidak dapat diberitahu untuk menemukan kembali deskriptor. Karena pengembang akan melihat Anda seperti orang bodoh: "Apa deskriptornya? Kami biasanya menulis ke stdout. " Insinyur infrastruktur membuat copytruncate dalam logrotate, yang hanya membuat salinan file dan trankeytit yang asli. Dengan demikian, antara proses penyalinan ini, ruang disk biasanya berakhir.
(4) Kami memiliki format yang berbeda dan berada di API yang berbeda. Mereka sedikit berbeda, tetapi regexp harus ditulis berbeda. Karena semua ini dikendalikan oleh Wayang, ada banyak kelas dengan kecoak mereka. Plus, agen td sebagian besar waktu bisa memakan memori, bodoh, itu bisa saja berpura-pura bekerja, dan tidak melakukan apa pun. Di luar, tidak mungkin untuk memahami bahwa dia tidak melakukan apa-apa. Paling-paling, dia akan jatuh, dan seseorang akan menjemputnya nanti. Lebih tepatnya, peringatan akan tiba, dan seseorang akan pergi dengan tangan mereka.

(6) Dan yang paling banyak sampah dan limbah - itu adalah elasticsearch. Karena itu versi lama. Karena, kami tidak memiliki master yang berdedikasi pada saat itu. Kami memiliki log heterogen di mana bidang bisa bersilangan. Log yang berbeda dari aplikasi yang berbeda dapat ditulis dengan nama bidang yang sama, tetapi pada saat yang sama mungkin ada data yang berbeda di dalamnya. Artinya, satu log dilengkapi dengan Integer di lapangan, misalnya level. Log lain datang dengan String di bidang level. Dengan tidak adanya pemetaan statis, hal yang luar biasa diperoleh. Jika, setelah rotasi indeks dalam elasticsearch, pesan pertama dengan sebuah string tiba, maka kita hidup secara normal. Dan jika itu datang lebih dulu dengan Integer, maka semua pesan berikutnya yang datang dengan String dibuang begitu saja. Karena jenis bidangnya tidak cocok.

Kami mulai mengajukan pertanyaan-pertanyaan ini. Kami memutuskan untuk tidak mencari yang bersalah.

Tetapi sesuatu harus dilakukan! Yang jelas adalah menetapkan standar. Kami sudah memiliki beberapa standar. Beberapa kita dapatkan nanti. Untungnya, format log yang seragam untuk semua API sudah disetujui pada waktu itu. Ini ditulis langsung ke dalam standar untuk interaksi layanan. Karenanya, mereka yang ingin menerima log harus menuliskannya dalam format ini. Jika seseorang tidak menulis log dalam format ini, maka kami tidak menjamin apa pun.
Lebih lanjut, saya ingin menetapkan satu standar untuk metode pencatatan, pengiriman dan pengumpulan log. Sebenarnya, di mana harus menulisnya, dan bagaimana mengirimkannya. Situasi yang ideal adalah ketika proyek menggunakan perpustakaan yang sama. Berikut adalah pustaka logging terpisah untuk Go, ada pustaka terpisah untuk PHP. Setiap orang yang kita miliki - semua orang harus menggunakannya. Saat ini, saya akan mengatakan bahwa kami mendapatkannya 80 persen. Tetapi beberapa terus makan kaktus.
Dan di sana (pada slide) nyaris tidak muncul "SLA untuk pengiriman log". Dia belum ada di sana, tetapi kami sedang mengusahakannya. Karena itu sangat nyaman ketika infra mengatakan bahwa jika Anda menulis dalam format ini-dan-itu ke tempat ini-dan-itu dan tidak lebih dari N pesan per detik, maka kami kemungkinan akan mengirim ini-dan-itu di sana. Ini mengurangi banyak sakit kepala. Jika ada SLA, maka ini luar biasa!

Bagaimana kita mulai menyelesaikan masalah? Penggaruk utama adalah dengan agen td. Tidak jelas ke mana log-log itu pergi. Apakah sudah terkirim? Apakah mereka akan pergi? Di mana mereka? Oleh karena itu, item pertama diputuskan untuk menggantikan td-agent. Saya secara singkat membuat sketsa opsi untuk menggantikannya.
Fluentd Pertama, saya menemukan dia di pekerjaan sebelumnya, dan dia juga secara berkala jatuh di sana. Kedua, ini sama, hanya di profil.
Filebeat. Bagaimana nyamannya bagi kita? Fakta bahwa dia sedang on Go, dan kami memiliki banyak keahlian di Go. Dengan demikian, jika itu, kita bisa menambahkannya untuk diri kita sendiri. Karena itu, kami tidak mengambilnya. Sehingga bahkan tidak ada godaan untuk mulai menulis ulang untuk Anda sendiri.
Solusi yang jelas untuk sysadmin adalah semua syslog dalam jumlah ini (syslog-ng / rsyslog / nxlog).
Atau menulis sesuatu dari kita sendiri, tetapi kita menjatuhkannya, seperti halnya filebeat. Jika Anda menulis sesuatu, lebih baik menulis sesuatu yang bermanfaat untuk bisnis. Untuk pengiriman log, lebih baik mengambil sesuatu yang sudah siap.
Oleh karena itu, pilihan sebenarnya datang ke pilihan antara syslog-ng dan rsyslog. Dia condong ke rsyslog hanya karena kami sudah memiliki kelas untuk rsyslog di Puppet, dan saya tidak menemukan perbedaan yang jelas di antara mereka. Apa itu syslog, apa itu syslog. Ya, seseorang memiliki dokumentasi yang lebih buruk, seseorang memiliki yang lebih baik. Dia tahu caranya, dan dia - dengan cara yang berbeda.

Dan sedikit tentang rsyslog. Pertama, itu keren karena memiliki banyak modul. Ini memiliki RainerScript yang dapat dibaca manusia (bahasa konfigurasi modern). Bonus luar biasa adalah bahwa kita dapat meniru perilaku td-agent menggunakan cara biasa, dan tidak ada yang berubah untuk aplikasi. Artinya, kami mengubah td-agent ke rsyslog, tetapi kami tidak menyentuh yang lainnya. Dan segera kami mendapatkan pengiriman yang berfungsi. Selanjutnya, mmnormalisasi adalah hal yang luar biasa di rsyslog. Ini memungkinkan Anda untuk mengurai log, tetapi tidak menggunakan Grok dan regexp. Dia membuat pohon sintaksis abstrak. Ini mem-parsing log, seperti kompiler mem-parsing kode sumber. Ini memungkinkan Anda untuk bekerja sangat cepat, makan sedikit CPU, dan, secara umum, ini adalah hal yang sangat keren. Ada banyak bonus lainnya. Saya tidak akan berhenti tentang mereka.

Rsyslog masih memiliki banyak kekurangan. Mereka hampir sama dengan bonus. Masalah utama - Anda harus bisa memasaknya, dan Anda harus memilih versi.
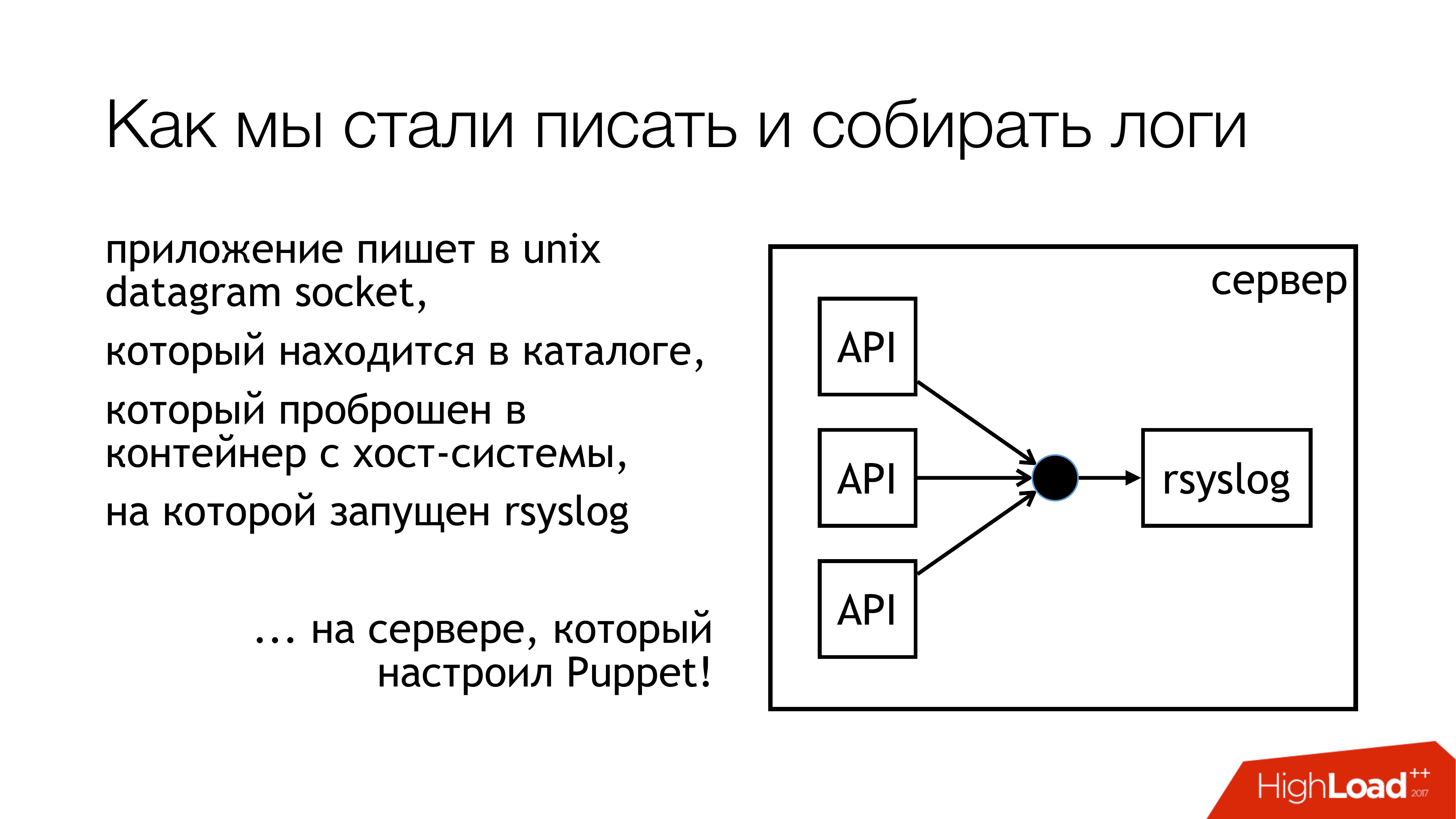
Kami memutuskan bahwa kami akan menulis log ke soket unix. Dan tidak di / dev / log, karena di sana kami memiliki bubur dari log sistem, ada journald di dalam pipa ini. Jadi mari kita menulis ke soket kustom. Kami lampirkan ke aturan terpisah. Kami tidak akan ikut campur. Semuanya akan transparan dan jelas. Jadi kami benar-benar melakukannya. Direktori dengan soket ini distandarisasi dan diteruskan ke semua wadah. Kontainer dapat melihat soket yang mereka butuhkan, buka dan tulis.
Kenapa bukan file? Karena semua orang membaca artikel tentang Badushechka yang mencoba meneruskan file ke buruh pelabuhan, dan ternyata setelah rsyslog me-restart perubahan deskriptor file, dan buruh pelabuhan kehilangan file ini. Dia terus membuka sesuatu yang lain, tetapi bukan soket yang sama di mana mereka menulis. Kami memutuskan bahwa kami akan mem-bypass masalah ini, dan pada saat yang sama, kami akan mem-bypass masalah pemblokiran.

Rsyslog melakukan tindakan yang ditunjukkan pada slide dan mengirimkan log ke relay atau ke Kafka. Kafka cocok dengan cara lama. Relay - Saya mencoba menggunakan rsyslog murni untuk mengirimkan log. Tanpa Antrian Pesan, alat rsyslog standar. Pada dasarnya, ini berhasil.

Tetapi ada nuansa dengan cara menjejalkannya nanti ke bagian ini (Logstash / Graylog / ES). Bagian ini (rsyslog-rsyslog) digunakan antara pusat data. Berikut ini adalah tautan tcp terkompresi, yang memungkinkan Anda menghemat bandwidth dan, karenanya, entah bagaimana meningkatkan kemungkinan kami akan menerima beberapa jenis log dari pusat data lain dalam kondisi ketika saluran penuh. Karena, kita memiliki Indonesia, di mana semuanya buruk. Di sinilah masalah konstan ini.

Kami berpikir tentang bagaimana kami benar-benar memantau, dengan probabilitas apa log yang kami catat dari aplikasi mencapai tujuan itu? Kami memutuskan untuk mendapatkan metrik. Rsyslog memiliki modul pengumpulan statistik sendiri, yang memiliki beberapa jenis penghitung. Misalnya, ini dapat menunjukkan ukuran antrian, atau berapa banyak pesan yang masuk dalam tindakan tersebut. Sesuatu sudah bisa diambil dari mereka. Plus, ia memiliki penghitung khusus yang dapat dikonfigurasi, dan itu akan menunjukkan kepada Anda, misalnya, jumlah pesan yang ditulis beberapa API. Selanjutnya, saya menulis rsyslog_exporter dengan Python, dan kami mengirim semuanya ke Prometheus dan merencanakannya. Metrik Graylog benar-benar ingin, tetapi sejauh ini kami belum punya waktu untuk mengonfigurasinya.

Apa masalahnya? Masalah muncul dengan fakta yang kami temukan (TERTINGGAL!) Bahwa API Langsung kami menulis pesan 50k per detik. Ini hanya API langsung tanpa pementasan. Dan Graylog menunjukkan kepada kita hanya 12 ribu pesan per detik. Dan pertanyaan yang masuk akal muncul, tetapi di mana sisanya? Dari mana kami menyimpulkan bahwa Graylog tidak bisa mengatasinya. Mereka melihat, dan, memang, Graylog dengan Elasticsearch tidak menguasai aliran ini.
Selanjutnya, penemuan lain yang kami buat dalam proses.
Tulis ke soket diblokir. Bagaimana ini bisa terjadi? Ketika saya menggunakan rsyslog untuk pengiriman, di beberapa titik saluran kami antara pusat data terputus. Pengiriman naik di satu tempat, pengiriman naik di tempat lain. Semua ini telah sampai pada mesin dengan API yang menulis ke soket rsyslog. Ada antrian. Kemudian antrian untuk menulis ke soket unix terisi, yang standarnya adalah 128 paket. Dan tulis berikutnya () dalam aplikasi diblokir. Ketika kami melihat perpustakaan yang kami gunakan di aplikasi on Go, tertulis di sana bahwa penulisan ke soket terjadi dalam mode non-blocking. Kami yakin tidak ada yang menghalangi. Karena kami membaca artikel tentang Badushechka yang menulisnya. Tapi ada saatnya. Di sekitar panggilan ini, masih ada siklus tanpa akhir di mana upaya terus-menerus dilakukan untuk mendorong pesan ke dalam soket. Kami tidak menyadarinya. Saya harus menulis ulang perpustakaan. Sejak itu, telah berubah beberapa kali, tetapi sekarang kami telah menyingkirkan kunci di semua subsistem. Oleh karena itu, Anda dapat menghentikan rsyslog dan tidak ada yang akan jatuh.
Penting untuk memantau ukuran antrian, yang membantu untuk tidak menginjak menyapu ini. Pertama, kita bisa memonitor ketika kita mulai kehilangan pesan. Kedua, kita dapat memonitor bahwa pada prinsipnya kita memiliki masalah pengiriman.
Dan momen tidak menyenangkan lainnya - amplifikasi 10 kali dalam arsitektur microservice - sangat mudah. Kami tidak memiliki banyak permintaan masuk, tetapi karena grafik di mana pesan-pesan ini berjalan, karena akses log, kami benar-benar menambah beban pada log sekitar sepuluh kali. Sayangnya saya tidak punya waktu untuk menghitung angka yang tepat, tetapi layanan microser - mereka. Ini harus diingat. Ternyata saat ini subsistem pengumpulan log adalah yang paling dimuat di Lazada.

Bagaimana mengatasi masalah elasticsearch? Jika Anda perlu dengan cepat mendapatkan log di satu tempat, agar tidak berjalan di semua mesin, dan tidak mengumpulkannya di sana, gunakan penyimpanan file. Ini dijamin berfungsi. Itu dibuat dari server apa pun. Anda hanya perlu menempelkan disk di sana dan meletakkan syslog. Setelah itu, Anda dijamin memiliki semua log di satu tempat. Selanjutnya akan mungkin untuk secara perlahan menyesuaikan elasticsearch, graylog, sesuatu yang lain. Tetapi Anda sudah memiliki semua log, dan, lebih lagi, Anda dapat menyimpannya sejauh cukup banyak disk array.

Pada saat laporan saya, sirkuit mulai terlihat seperti ini. Kami praktis berhenti menulis ke file. Sekarang, kemungkinan besar, kita akan mematikan sisa makanan. Pada mesin lokal yang menjalankan API, kami akan berhenti menulis ke file. Pertama, ada penyimpanan file yang berfungsi dengan sangat baik. Kedua, tempat di mesin ini terus-menerus habis, perlu untuk terus memantaunya.
Bagian ini dengan Logstash dan Graylog, sangat melambung. Karena itu, kita harus menyingkirkannya. Anda harus memilih satu hal.

Kami memutuskan untuk melempar Logstash dan Kibana. Karena kami memiliki departemen keamanan. Apa hubungannya? Koneksi adalah bahwa Kibana tanpa X-Pack dan tanpa Shield tidak memungkinkan untuk membedakan hak akses ke log. Karena itu, mereka mengambil Graylog. Dia memiliki semuanya. Saya tidak suka dia, tetapi berhasil. Kami membeli besi baru, meletakkan Graylog baru di sana dan memindahkan semua log dengan format ketat ke Graylog terpisah. Kami memecahkan masalah dengan berbagai jenis bidang identik secara organisasi.

Apa sebenarnya yang termasuk dalam Graylog baru. Kami baru saja merekam semua yang ada di buruh pelabuhan. Kami mengambil banyak server, meluncurkan tiga contoh Kafka, 7 server Graylog versi 2.3 (karena saya ingin Elasticsearch versi 5). Semua ini pada penggerebekan dari HDD dinaikkan. Kami melihat tingkat pengindeksan hingga 100 ribu pesan per detik. Kami melihat angka itu 140 terabyte data per minggu.

Dan lagi menyapu! Dua penjualan akan datang. Kami telah pindah untuk 6 juta pesan. Di kami, Graylog tidak punya waktu untuk mengunyah. Entah bagaimana kita harus selamat lagi.

Kami selamat seperti ini. Kami menambahkan beberapa server dan SSD lagi. Saat ini, kita hidup dengan cara ini. Sekarang kami sudah mengunyah 160rb pesan per detik. Kami belum mencapai batas, jadi belum jelas seberapa besar kita bisa keluar dari ini.

Ini adalah rencana kami untuk masa depan. Dari jumlah tersebut, sungguh, yang paling penting mungkin ketersediaan tinggi. Kami belum memilikinya. Beberapa mobil dikonfigurasi sama, tetapi sejauh ini semuanya berjalan melalui satu mobil. , failover .
Graylog.
rate limit , API, bandwidth .
, - SLA c , . , .
.

, , . -, . -, syslog — . -, rsyslog , . .
.
: - … (filebeat?)
: . . API , , . pipe. : « , , »? , , : « , ».
: HDFS?
: . , , , , long term solution.
: .
: . "" .
: rsyslog. TCP, UDP. UDP, ?
: . , , . , : « , - , - », «! , , , .» . , ? , ? best effort. , 100% . . .
: API - , , ? - .
: , . . , . , API . rsyslog . API , , timestamp . Graylog, timestamp. .
: Timestamp .
: Timestamp API. , , . NTP. API timestamp . rsyslog .
: . , . ? ?
: . - . , . . Log Relay. Rsyslog . . . . . . , (), Graylog. storage. , , . . .
: ?
: ( ) .
: , ?
: , . . , Go API, . , socket. . . socket. , . . , . prometheus, Grafana . . , .
: elasticsearch . ?
: .
: ?
: . .
: rsyslog - ?
: unix socket. 128 . . . , 128 . , , , , . , . .
c : JSON?
: JSON relay, . Graylog, JSON . , , rsyslog. issue, .
c : Kafka? RabbitMQ? Graylog ?
: Graylog . Graylog . . . , , . rsyslog elasticsearch Kibana. . , Graylog Kibana. Logstash . , rsyslog. elasticsearch. Graylog - . . .
Kafka. . , , . . , , . RabbitMQ… c RabbitMQ. RabbitMQ . , . , . . . Graylog AMQP 0.9, rsyslog AMQP 1.0. , , . . Kafka. . omkafka rsyslog, , , rsyslog. .
Pertanyaan : Apakah Anda menggunakan Kafka karena Anda memilikinya? Tidak digunakan untuk tujuan lain?
Jawaban : Kafka, yang digunakan oleh tim Data SCience. Ini adalah proyek yang sepenuhnya terpisah, yang, sayangnya, saya tidak bisa mengatakan apa-apa. Saya tidak tahu Dia dijalankan oleh tim Ilmu Data. Ketika log dimulai, mereka memutuskan untuk menggunakannya, agar tidak menempatkannya sendiri. Sekarang kami telah memperbarui Graylog, dan kami telah kehilangan kompatibilitas, karena ada versi lama Kafka. Kami harus mendapatkan milik kami sendiri. Pada saat yang sama, kami menyingkirkan empat topik ini untuk setiap API. Kami membuat satu topik yang luas untuk semua siaran langsung, satu topik yang sangat luas untuk semua pementasan dan hanya menjelaskan semuanya di sana. Graylog menyapu semua ini secara paralel.
Pertanyaan : Mengapa perdukunan dengan soket ini diperlukan? Sudahkah Anda mencoba menggunakan driver log syslog untuk kontainer?
Jawaban : Pada saat kami menanyakan pertanyaan ini, kami memiliki hubungan yang tegang dengan buruh pelabuhan. Itu buruh pelabuhan 1.0 atau 0.9. Docker sendiri aneh. Kedua, jika Anda juga mendorong log ke dalamnya ... Saya memiliki kecurigaan yang tidak terverifikasi bahwa ia melewati semua log melalui dirinya sendiri, melalui daemon buruh pelabuhan. Jika kita memiliki satu API yang menjadi gila, maka sisa API terjebak pada kenyataan bahwa mereka tidak dapat mengirim stdout dan stderr. Saya tidak tahu ke mana ini akan mengarah. Saya memiliki kecurigaan pada tingkat perasaan bahwa Anda tidak perlu menggunakan driver syslog buruh pelabuhan di tempat ini. Departemen pengujian fungsional kami memiliki cluster Graylog sendiri dengan log. Mereka menggunakan buruh pelabuhan log-driver dan semuanya tampaknya baik-baik saja di sana. Tetapi mereka segera menulis GELF ke Graylog. Kami pada saat itu ketika semua ini sampai, kami membutuhkannya hanya untuk bekerja. Mungkin nanti, ketika seseorang datang dan mengatakan bahwa itu telah bekerja secara normal selama seratus tahun, kami akan mencoba.
Pertanyaan : Anda melakukan pengiriman antar pusat data di rsyslog. Kenapa tidak di Kafka?
Jawaban : Kami melakukan keduanya, dan dalam kenyataannya. Karena dua alasan. Jika saluran benar-benar mati, maka kami memiliki semua log, bahkan dalam bentuk terkompresi, tidak akan merangkak melaluinya. Dan kafka memungkinkan mereka hilang begitu saja dalam proses. Dengan cara ini kita menyingkirkan menempelkan log ini. Kami hanya menggunakan Kafka dalam kasus ini secara langsung. Jika kami memiliki saluran yang bagus dan ingin membebaskannya, maka kami menggunakan rsyslog mereka. Tetapi pada kenyataannya, Anda dapat mengkonfigurasinya sehingga ia sendiri menjatuhkan apa yang tidak merangkak. Saat ini, kami hanya di suatu tempat menggunakan pengiriman rsyslog secara langsung, di suatu tempat Kafka.