
Pengembang tergila-gila pada hal-hal aneh. Kita semua lebih suka menganggap diri kita makhluk super rasional, tetapi ketika harus memilih teknologi tertentu, kita jatuh ke dalam semacam kegilaan, melompat dari komentar di HackerNews ke posting di blog, dan sekarang, seolah-olah terlupakan, kita tidak berdaya. kita berlayar menuju sumber cahaya yang paling terang dan tunduk dengan patuh padanya, setelah sepenuhnya melupakan apa yang semula kita cari.
Ini sama sekali bukan bagaimana orang rasional mengambil keputusan. Tetapi justru para pengembang memutuskan untuk menggunakan, misalnya, MapReduce.
Seperti yang dicatat Joe Hellerstein dalam ceramahnya tentang database untuk mahasiswa sarjana (pada menit ke-54):
Faktanya adalah ada sekitar 5 perusahaan di dunia yang melakukan tugas ambisius tersebut. Adapun orang lain ... mereka menghabiskan sumber daya yang luar biasa untuk menyediakan sistem toleransi kesalahan yang mereka benar-benar tidak butuhkan. Orang-orang memiliki semacam "google" di tahun 2000-an: "kami akan melakukan segalanya persis seperti yang dilakukan Google, karena kami juga mengelola layanan pemrosesan data terbesar di dunia ..." [ironisnya menggelengkan kepalanya dan menunggu tawa dari hadirin]

Berapa lantai di gedung pusat data Anda? Google memutuskan untuk tetap pada jam empat, setidaknya di pusat data khusus ini yang berlokasi di Mays County, Oklahoma.
Ya, sistem Anda lebih tangguh dari yang Anda butuhkan, tetapi pikirkan berapa biayanya. Intinya bukan hanya kebutuhan untuk memproses data dalam jumlah besar. Anda kemungkinan bertukar sistem lengkap - dengan transaksi, indeks, dan optimisasi kueri - untuk sesuatu yang relatif lemah. Ini adalah langkah mundur yang signifikan. Berapa banyak pengguna Hadoop melakukan ini secara sadar? Berapa banyak dari mereka yang membuat keputusan yang benar-benar seimbang?
MapReduce / Hadoop adalah contoh yang sangat sederhana. Bahkan pengikut Cargo Cult sudah menyadari bahwa pesawat tidak akan menyelesaikan semua masalah mereka. Namun demikian, penggunaan MapReduce memungkinkan Anda untuk membuat generalisasi yang penting: jika Anda menggunakan teknologi yang dibuat untuk perusahaan besar, tetapi pada saat yang sama menyelesaikan masalah kecil, Anda mungkin bertindak tanpa berpikir. Meski begitu, kemungkinan besar Anda dipandu oleh ide-ide mistis yang meniru raksasa seperti Google dan Amazon, Anda akan mencapai ketinggian yang sama.

Ya, artikel ini adalah lawan kultus kargo. Tetapi tunggu, saya memiliki daftar periksa yang berguna untuk Anda, yang dapat Anda gunakan untuk membuat keputusan yang lebih tepat.
Kerangka keren: UNPHAT
Lain kali Anda google beberapa teknik keren baru untuk (kembali) membentuk sistem Anda, saya mendorong Anda untuk berhenti dan hanya menggunakan kerangka UNPHAT :
- Jangan pernah mencoba memikirkan solusi yang mungkin sebelum memahami masalah (Memahami) . Tujuan utama Anda adalah untuk "memecahkan" masalah dalam hal masalah, bukan dalam hal solusi.
- Daftar (eNumerate) beberapa solusi yang mungkin. Tidak perlu langsung mengarahkan jari Anda ke opsi favorit Anda.
- Pertimbangkan solusi terpisah, dan kemudian baca dokumentasi (Kertas) , jika ada.
- Tentukan konteks historis di mana solusi ini dibuat.
- Cocokkan Keunggulan dengan Cacat. Analisis apa yang harus dikorbankan oleh pembuat keputusan untuk mencapai tujuan mereka.
- Pikirkan (Pikirkan) ! Dengan tenang dan tenang pertimbangkan seberapa baik solusi ini cocok untuk memenuhi kebutuhan Anda. Apa yang sebenarnya perlu diubah agar Anda berubah pikiran? Misalnya, seberapa sedikit data yang seharusnya, sehingga Anda memilih untuk tidak menggunakan Hadoop?
Anda bukan amazon
Menggunakan UNPHAT itu mudah. Ingat percakapan saya baru-baru ini dengan perusahaan yang buru-buru memutuskan untuk menggunakan Cassandra untuk proses intensif membaca data yang diunduh pada malam hari.
Karena saya sudah terbiasa dengan dokumentasi Dynamo dan tahu bahwa Cassandra adalah sistem turunan, saya mengerti bahwa dalam basis data ini fokus utamanya adalah pada kemampuan untuk merekam (Amazon perlu membuat tindakan “menambah kereta” tidak pernah tidak gagal). Saya juga menghargai bahwa para pengembang mengorbankan integritas data - dan memang, setiap fitur yang melekat dalam RDBMS tradisional. Tetapi bagaimanapun juga, perusahaan tempat saya berbicara, kemampuan untuk merekam bukanlah prioritas. Sejujurnya, proyek itu berarti menciptakan satu rekor besar sehari.

Amazon menjual banyak segalanya. Jika fungsi "tambahkan ke keranjang" tiba-tiba berhenti bekerja, mereka akan kehilangan BANYAK uang. Apakah Anda memiliki masalah dengan urutan yang sama?
Perusahaan ini memutuskan untuk menggunakan Cassandra karena butuh beberapa menit untuk menyelesaikan permintaan PostgreSQL yang bersangkutan, dan mereka memutuskan bahwa ini adalah keterbatasan teknis pada bagian dari perangkat keras mereka. Setelah mengklarifikasi beberapa poin, kami menyadari bahwa tabel tersebut terdiri dari sekitar 50 juta baris masing-masing 80 byte. Dibutuhkan sekitar 5 detik untuk membacanya dari SSD jika Anda harus menjalaninya sepenuhnya. Ini lambat, tetapi masih dua urutan besarnya lebih cepat dari kecepatan eksekusi permintaan pada waktu itu.
Pada tahap ini, saya punya banyak pertanyaan (U = pahami, pahami masalahnya!) Dan saya mulai menimbang sekitar 5 strategi berbeda yang dapat menyelesaikan masalah asli (N = eNumerate, daftarkan beberapa solusi yang mungkin!), Tetapi bagaimanapun juga sudah jelas hingga saat itu bahwa menggunakan Cassandra pada dasarnya adalah keputusan yang salah. Yang mereka butuhkan adalah sedikit kesabaran untuk mengatur, mungkin desain baru untuk database dan, mungkin (meskipun tidak mungkin), pilihan teknologi yang berbeda ... Tapi jelas bukan penyimpanan data bernilai kunci dengan rekaman intensif bahwa Amazon dibuat untuk keranjang mereka!
Anda bukan LinkedIn
Saya sangat terkejut menemukan bahwa salah satu startup mahasiswa memutuskan untuk membangun arsitekturnya di sekitar Kafka. Itu luar biasa. Sejauh yang saya tahu, bisnis mereka hanya menjalankan beberapa lusin operasi yang sangat besar per hari. Mungkin beberapa ratus pada hari-hari paling sukses. Dengan bandwidth ini, gudang data utama bisa menjadi entri tulisan tangan di buku biasa.
Sebagai perbandingan, ingat bahwa Kafka diciptakan untuk menangani semua peristiwa analitik di LinkedIn. Ini hanya sejumlah besar data. Bahkan beberapa tahun yang lalu, itu sekitar 1 triliun peristiwa setiap hari , dengan beban puncak 10 juta pesan per detik. Tentu saja, saya mengerti bahwa Kafka dapat digunakan untuk bekerja dengan muatan yang lebih rendah, tetapi untuk 10 pesanan lebih sedikit?

Matahari, menjadi objek yang sangat masif, dan itu hanya 6 kali lipat lebih berat dari Bumi.
Mungkin para pengembang bahkan membuat keputusan yang disengaja, berdasarkan kebutuhan yang diharapkan dan pemahaman yang baik tentang tujuan Kafka. Tapi saya pikir mereka agak didorong oleh antusiasme masyarakat (biasanya dibenarkan) untuk Kafka dan hampir tidak pernah bertanya-tanya apakah ini benar-benar alat yang mereka butuhkan. Bayangkan saja ... 10 pesanan!
Apakah saya sudah mengatakan itu? Anda bukan amazon
Bahkan lebih populer daripada gudang data terdistribusi Amazon, adalah pendekatan desain arsitektur yang memberi mereka skalabilitas: arsitektur berorientasi layanan. Seperti yang dicatat oleh Werner Vogels dalam wawancara tahun 2006 dengan Jim Gray, Amazon menyadari pada tahun 2001 bahwa mereka mengalami kesulitan meningkatkan antarmuka (front-end) dan bahwa arsitektur berorientasi layanan dapat membantu mereka. Gagasan ini menginfeksi satu demi satu pengembang, sementara startup, yang hanya terdiri dari beberapa pengembang dan hampir tidak ada klien, tidak mulai membagi perangkat lunak mereka menjadi layanan nano.
Pada saat Amazon memutuskan untuk beralih ke SOA (arsitektur berorientasi layanan), mereka memiliki sekitar 7.800 karyawan dan penjualan mereka melebihi $ 3 miliar .

Aula Konser Bill Graham Auditorium di San Francisco menampung 7.000 orang. Amazon memiliki sekitar 7.800 karyawan ketika mereka beralih ke SOA.
Ini tidak berarti bahwa Anda harus menunda transisi ke SOA sampai perusahaan Anda mencapai level 7800 karyawan ... selalu berpikir dengan kepala Anda sendiri . Apakah ini benar-benar solusi terbaik untuk tugas Anda? Apa sebenarnya tugas di depan Anda dan apakah ada cara lain untuk menyelesaikannya?
Jika Anda memberi tahu saya bahwa pekerjaan organisasi Anda, yang terdiri dari 50 pengembang, hanya akan berakhir tanpa SOA, maka saya bertanya-tanya mengapa begitu banyak perusahaan besar hanya bekerja luar biasa menggunakan satu aplikasi, tetapi terorganisir dengan baik.
Bahkan Google bukan Google.
Contoh penggunaan sistem untuk memproses aliran data yang sangat banyak (Hadoop atau Spark) benar-benar dapat membingungkan. Sangat sering, DBMS tradisional lebih cocok untuk memuat, dan kadang-kadang jumlah data sangat kecil sehingga bahkan memori yang tersedia akan cukup untuk mereka. Tahukah Anda bahwa Anda dapat membeli 1TB RAM di suatu tempat seharga $ 10.000? Bahkan jika Anda memiliki satu miliar pengguna, Anda masih dapat memberikan masing-masing dari mereka dengan 1 KB RAM.
Mungkin ini tidak akan cukup untuk memuat Anda, karena Anda perlu membaca dan menulis ke disk. Tetapi apakah Anda benar-benar membutuhkan beberapa ribu disk untuk membaca dan menulis? Berikut ini berapa banyak data yang Anda miliki? GFS dan MapReduce dibuat untuk memecahkan masalah komputasi di Internet ... misalnya, untuk menghitung ulang indeks pencarian di seluruh Internet .
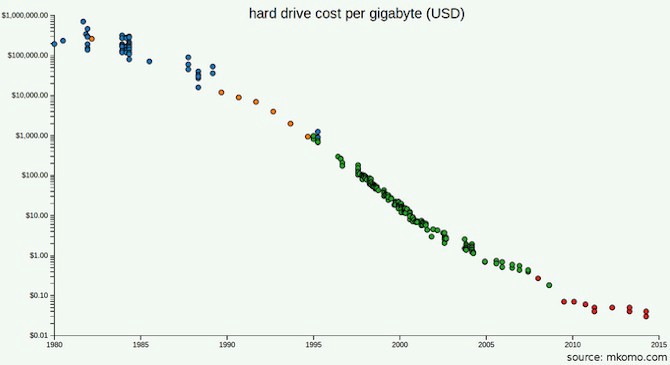
Harga untuk hard drive sekarang jauh lebih rendah daripada tahun 2003 ketika dokumentasi GFS diterbitkan.
Mungkin Anda membaca dokumentasi GFS dan MapReduce dan memperhatikan bahwa salah satu masalah bagi Google bukanlah jumlah data, tetapi bandwidth (kecepatan pemrosesan): mereka menggunakan penyimpanan terdistribusi karena butuh terlalu banyak waktu untuk mentransfer byte dari disk. Tapi berapa bandwidth perangkat yang akan Anda gunakan tahun ini? Mengingat Anda bahkan tidak membutuhkan perangkat sebanyak yang dibutuhkan Google, apakah lebih baik membeli lebih banyak drive modern? Berapa biaya untuk menggunakan SSD?
Mungkin Anda ingin mempertimbangkan skalabilitas terlebih dahulu. Sudahkah Anda melakukan semua perhitungan yang diperlukan? Apakah Anda mengumpulkan data lebih cepat daripada harga SSD turun? Berapa kali bisnis Anda harus tumbuh sehingga semua data yang tersedia tidak lagi cocok pada satu perangkat? Pada 2016, Stack Exchange memproses 200 juta kueri per hari dengan dukungan hanya 4 server SQL : yang utama untuk Stack Overflow, satu lagi untuk yang lainnya, dan dua salinan.
Sekali lagi, Anda dapat menggunakan UNPHAT dan masih memutuskan untuk menggunakan Hadoop atau Spark. Dan keputusannya mungkin benar. Yang utama adalah Anda benar-benar menggunakan teknologi yang tepat untuk menyelesaikan masalah Anda . Omong-omong, ini terkenal di Google: ketika mereka memutuskan bahwa MapReduce tidak cocok untuk pengindeksan, mereka berhenti menggunakannya.
Hal pertama yang pertama, pahami masalahnya
Pesan saya mungkin bukan sesuatu yang baru, tetapi mungkin dalam bentuk yang akan menanggapi Anda atau mungkin mudah bagi Anda untuk mengingat UNPHAT dan menerapkannya dalam kehidupan. Jika tidak, Anda dapat menonton Rich Hickey berbicara di Hammock Driven Development , atau buku Paul , How to Solve it , atau Hamming 's Art of Doing Science and Engineering . Karena hal utama yang kita semua tanyakan adalah berpikir!
Dan sangat memahami masalah yang Anda coba selesaikan. Dalam kata-kata inspirasional Paulus:
“ Adalah bodoh untuk menjawab pertanyaan yang tidak Anda mengerti. Sangat menyedihkan untuk berjuang untuk tujuan yang tidak ingin Anda capai. "
Terjemahan Rusia
Terjemahan: Alexander Tregubov
Diedit oleh Alexey Ivanov (@ponchiknews)
Komunitas: @ponchiknews
Gambar: Tim Konten LucidChart