Layanan pemesanan taksi yang baik harus aman, andal, dan cepat. Pengguna tidak akan masuk ke detail: penting baginya untuk mengklik tombol Order dan menerima mobil sesegera mungkin, yang akan mengantarkannya dari titik A ke titik B. Jika tidak ada mobil di dekatnya, layanan harus segera menginformasikan tentang hal ini sehingga klien tidak berevolusi harapan palsu. Tetapi jika plat “No cars” ditampilkan terlalu sering, adalah logis bahwa seseorang berhenti menggunakan layanan ini dan pergi ke pesaing.
Pada artikel ini saya ingin berbicara tentang bagaimana, dengan bantuan pembelajaran mesin, kami memecahkan masalah menemukan mobil di wilayah dengan kepadatan rendah (dengan kata lain, di mana, pada pandangan pertama, tidak ada mobil). Dan apa yang terjadi?
Latar belakang
Untuk memanggil taksi, pengguna mengambil beberapa langkah sederhana, dan apa yang terjadi di nyali layanan?
Tentang
ETA di pin , kami telah menulis
perhitungan harga dan
pilihan pengemudi yang paling cocok . Dan ini adalah kisah tentang menemukan driver. Ketika pesanan dibuat, pencarian terjadi dua kali: pada pin dan pada pesanan. Pencarian pada pesanan berlangsung dalam dua tahap: rekrutmen kandidat dan peringkat. Pertama, ada calon driver gratis yang datang sepanjang grafik jalan. Kemudian bonus dan penyaringan diterapkan. Kandidat yang tersisa diberi peringkat, dan pemenangnya menerima tawaran pesanan. Jika dia setuju, maka ditugaskan ke pesanan dan pergi ke titik pengiriman. Jika dia menolak, maka tawaran datang ke yang berikutnya. Jika tidak ada lagi kandidat, pencarian dimulai lagi. Ini berlangsung tidak lebih dari tiga menit, setelah itu pesanan dibatalkan - hangus.
Pencarian pada pin mirip dengan pencarian pada urutan, hanya urutan tidak dibuat dan pencarian itu sendiri dilakukan hanya sekali. Juga, pengaturan yang disederhanakan untuk jumlah kandidat dan radius pencarian digunakan. Penyederhanaan seperti itu diperlukan, karena ada urutan besarnya lebih banyak pin daripada pesanan, dan pencarian adalah operasi yang agak sulit.
Momen kunci untuk kisah kami: jika selama pencarian awal pada pin tidak ada kandidat yang cocok, maka kami tidak mengizinkan melakukan pemesanan. Setidaknya dulu.
Inilah yang dilihat pengguna dalam aplikasi:
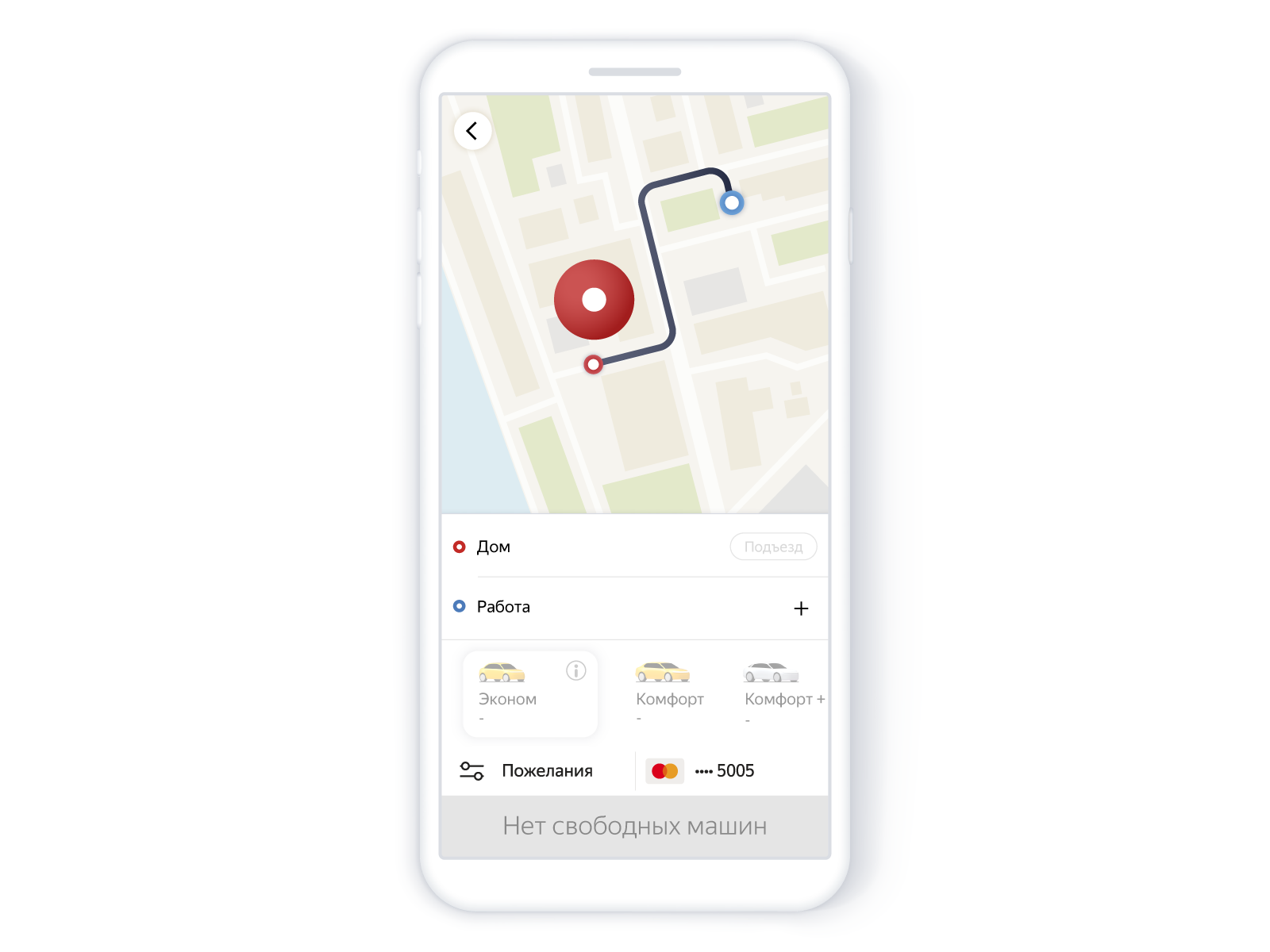
Cari mobil tanpa mobil
Setelah kami memiliki hipotesis: mungkin, dalam beberapa kasus, pesanan masih dapat diselesaikan, bahkan jika tidak ada mobil di pin. Memang, beberapa waktu berlalu antara pin dan urutan, dan pencarian pada urutan lebih lengkap dan kadang-kadang diulang beberapa kali: selama waktu ini driver gratis mungkin muncul. Kami juga tahu yang sebaliknya: jika driver ditemukan pada pin, maka itu bukan fakta bahwa mereka akan ditemukan ketika memesan. Terkadang mereka menghilang atau semuanya menolak perintah.
Untuk menguji hipotesis ini, kami meluncurkan percobaan: kami berhenti memeriksa keberadaan mesin selama pencarian pin untuk kelompok uji pengguna, yaitu, mereka memiliki kesempatan untuk membuat "pesanan tanpa mobil". Hasilnya cukup tak terduga:
jika mobil tidak di pin, maka dalam 29% kasus itu nanti - ketika mencari pesanan! Selain itu, pesanan tanpa mobil tidak berbeda jauh dari yang biasa dalam hal tingkat pembatalan, peringkat, dan indikator kualitas lainnya. Jumlah pesanan tanpa mobil adalah 5% dari semua pesanan, tetapi hanya lebih dari 1% dari semua perjalanan yang berhasil.
Untuk memahami dari mana datangnya pesanan ini, mari kita lihat status mereka selama pencarian di pin:
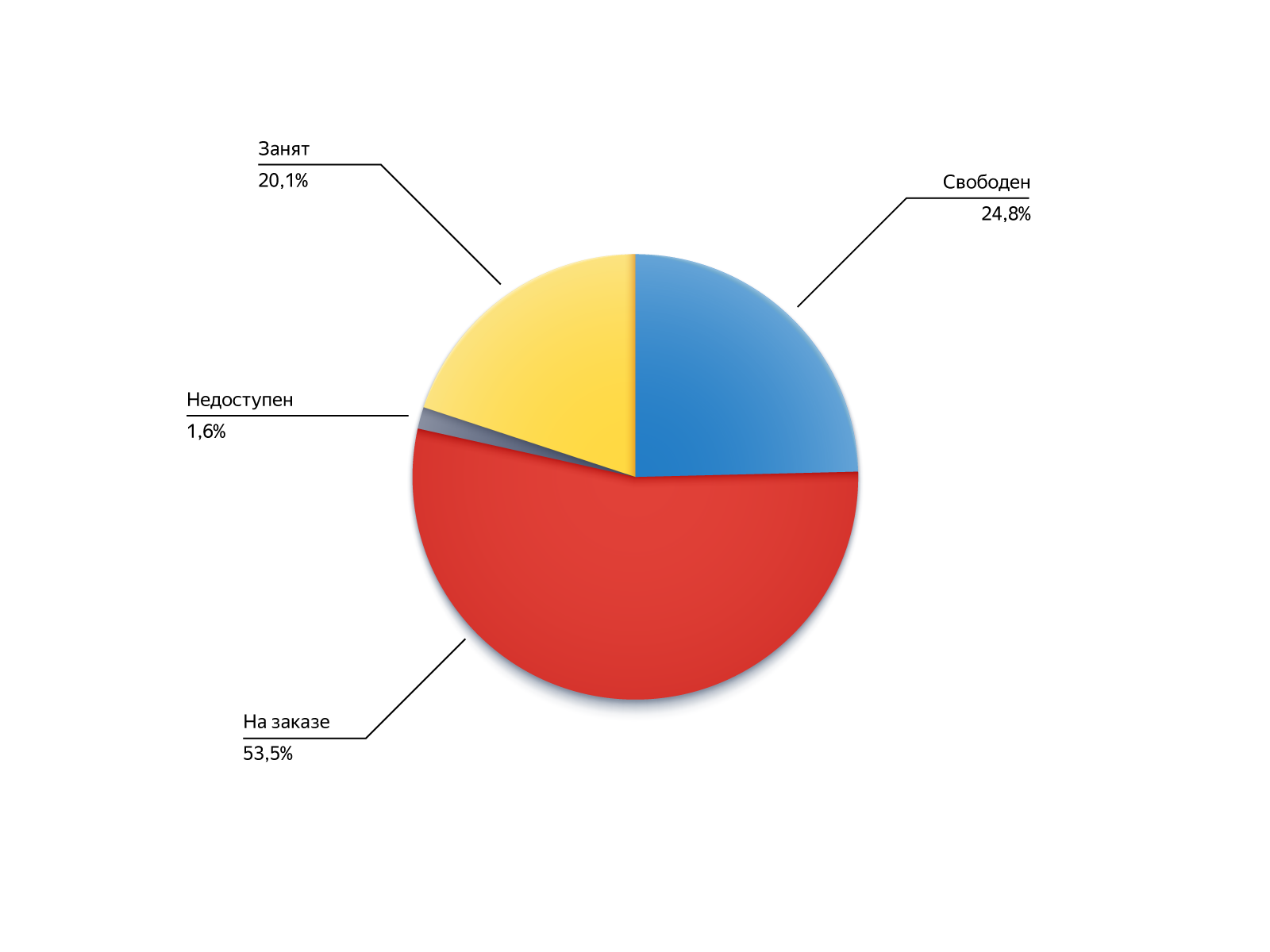
- Gratis: tersedia, tetapi untuk beberapa alasan tidak masuk ke kandidat, misalnya, terlalu jauh;
- Sesuai pesanan: dia sibuk, tetapi berhasil membebaskan diri atau menjadi tersedia untuk memesan di sepanjang rantai ;
- Sibuk: kemampuan untuk menerima pesanan dinonaktifkan, tetapi kemudian pengemudi kembali ke jalur;
- Tidak tersedia: pengemudi tidak online, tetapi dia muncul.
Tambahkan keandalan
Pesanan tambahan bagus, tetapi 29% dari pencarian yang berhasil berarti bahwa dalam 71% kasus pengguna telah menunggu lama dan sebagai hasilnya tidak pergi ke mana pun. Meskipun dari sudut pandang efisiensi sistem ini tidak mengerikan, tetapi pada kenyataannya, pengguna menerima harapan palsu dan menghabiskan waktu, setelah itu dia kesal dan (mungkin) berhenti menggunakan layanan. Untuk mengatasi masalah ini, kami belajar memprediksi kemungkinan bahwa sebuah mesin akan ditemukan pada pesanan.
Skemanya adalah sebagai berikut:
- Pengguna menaruh pin.
- Mencari di pin.
- Jika tidak ada mobil, kami memperkirakan: mungkin mereka akan muncul.
- Dan tergantung pada probabilitas, kami memberi atau tidak memberi pesanan, tetapi kami memperingatkan bahwa kepadatan mobil di daerah ini kecil saat ini.
Dalam aplikasi, itu terlihat seperti ini:
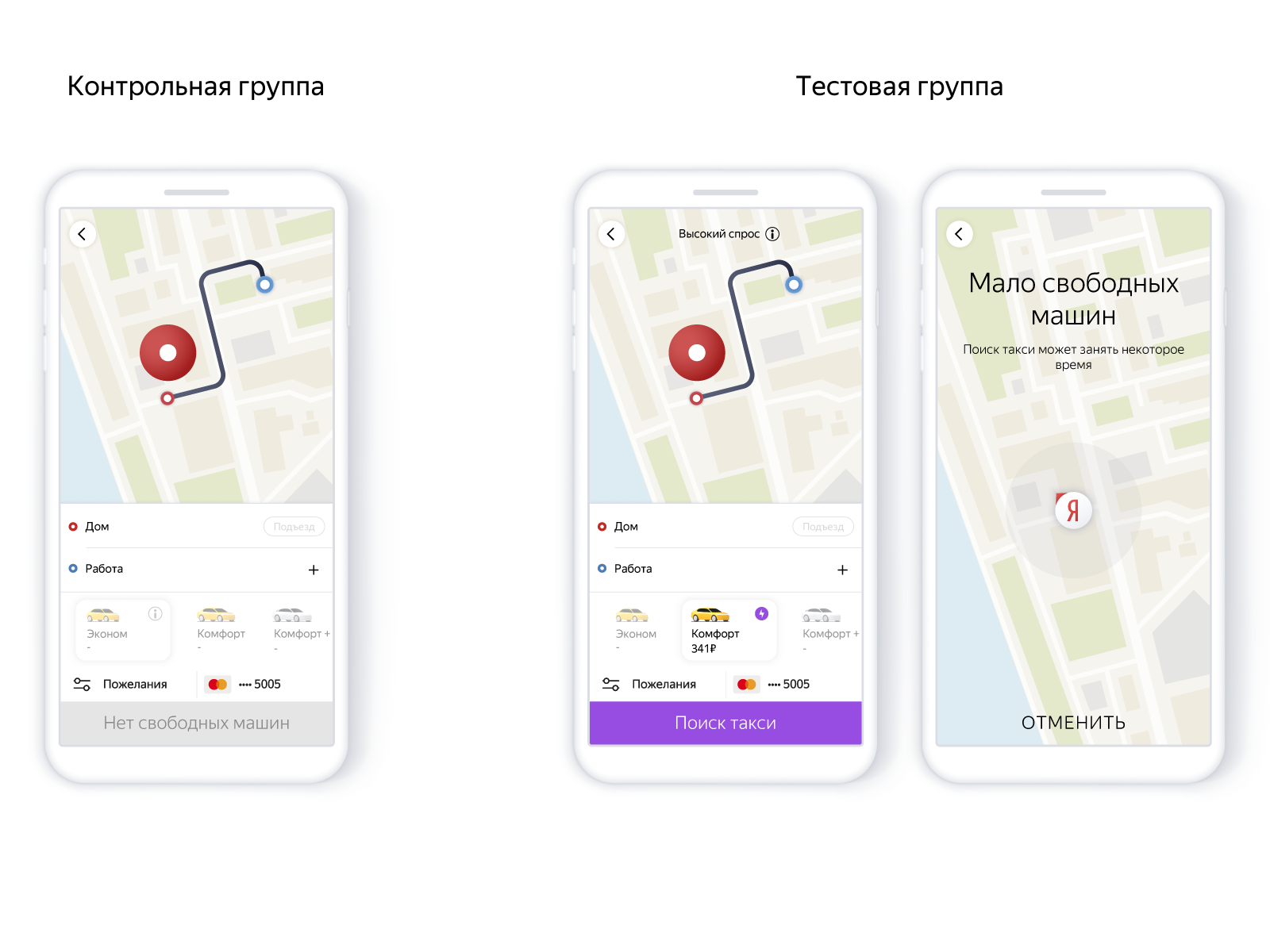
Menggunakan model memungkinkan Anda untuk membuat pesanan baru dengan hati-hati, bukan untuk meyakinkan seseorang dengan sia-sia. Yaitu, untuk menyesuaikan rasio keandalan dan jumlah pesanan tanpa mesin menggunakan model presisi-recall. Keandalan layanan memengaruhi keinginan untuk terus menggunakan produk, mis., Pada akhirnya, semua tergantung pada jumlah perjalanan.
Sedikit tentang presisi-recallSalah satu tugas dasar dalam pembelajaran mesin adalah masalah klasifikasi: menetapkan objek ke salah satu dari dua kelas. Dalam hal ini, hasil operasi algoritma pembelajaran mesin sering menjadi estimasi numerik milik salah satu kelas, misalnya, estimasi probabilitas. Namun, tindakan yang dilakukan biasanya biner: jika kita memiliki mobil, maka kita memberikannya sesuai pesanan, dan jika tidak, maka tidak. Untuk kepastian, kami menyebut model algoritma yang memberikan peringkat numerik, dan classifier - aturan yang mengacu pada salah satu dari dua kelas (1 atau –1). Untuk membuat klasifikasi berdasarkan penilaian model, Anda harus memilih ambang penilaian. Bagaimana tepatnya - sangat tergantung pada tugas.
Misalkan kita melakukan tes (pengklasifikasi) untuk beberapa penyakit langka dan berbahaya. Berdasarkan hasil tes, kami mengirim pasien untuk pemeriksaan yang lebih rinci, atau mengatakan: "Sehat, pulanglah." Bagi kami, mengirim orang sakit ke rumah jauh lebih buruk daripada memeriksa orang sehat dengan sia-sia. Yaitu, kami ingin tes ini berhasil untuk sebanyak mungkin orang yang benar-benar sakit. Nilai ini disebut recall =
. Penarikan classifier yang ideal adalah 100%. Situasi yang merosot adalah mengirim semua orang untuk ujian, maka penarikan kembali juga akan 100%.
Itu terjadi dan sebaliknya. Sebagai contoh, kami membuat sistem pengujian untuk siswa, dan memiliki detektor kecurangan. Jika tiba-tiba sebuah cek tidak berfungsi untuk beberapa kasus kecurangan, maka ini tidak menyenangkan, tetapi tidak kritis. Di sisi lain, sangat buruk menyalahkan siswa secara tidak adil atas apa yang tidak mereka lakukan. Artinya, penting bagi kita bahwa di antara jawaban positif penggolong harus ada sebanyak mungkin yang benar, mungkin merugikan jumlah mereka. Jadi, Anda perlu memaksimalkan presisi =
\ frac {number \ true \ positif \} {jumlah \ semua \ positif} . Jika operasi mulai terjadi pada semua objek, maka presisi akan sama dengan frekuensi kelas yang ditentukan dalam sampel.
Jika algoritma memberikan nilai numerik probabilitas, maka, dengan memilih ambang yang berbeda, Anda dapat mencapai nilai yang berbeda dari presisi-recall.
Dalam tugas kami, situasinya adalah sebagai berikut. Ingat adalah jumlah pesanan yang dapat kami tawarkan, presisi adalah keandalan pesanan ini. Berikut adalah kurva presisi-recall model kami:
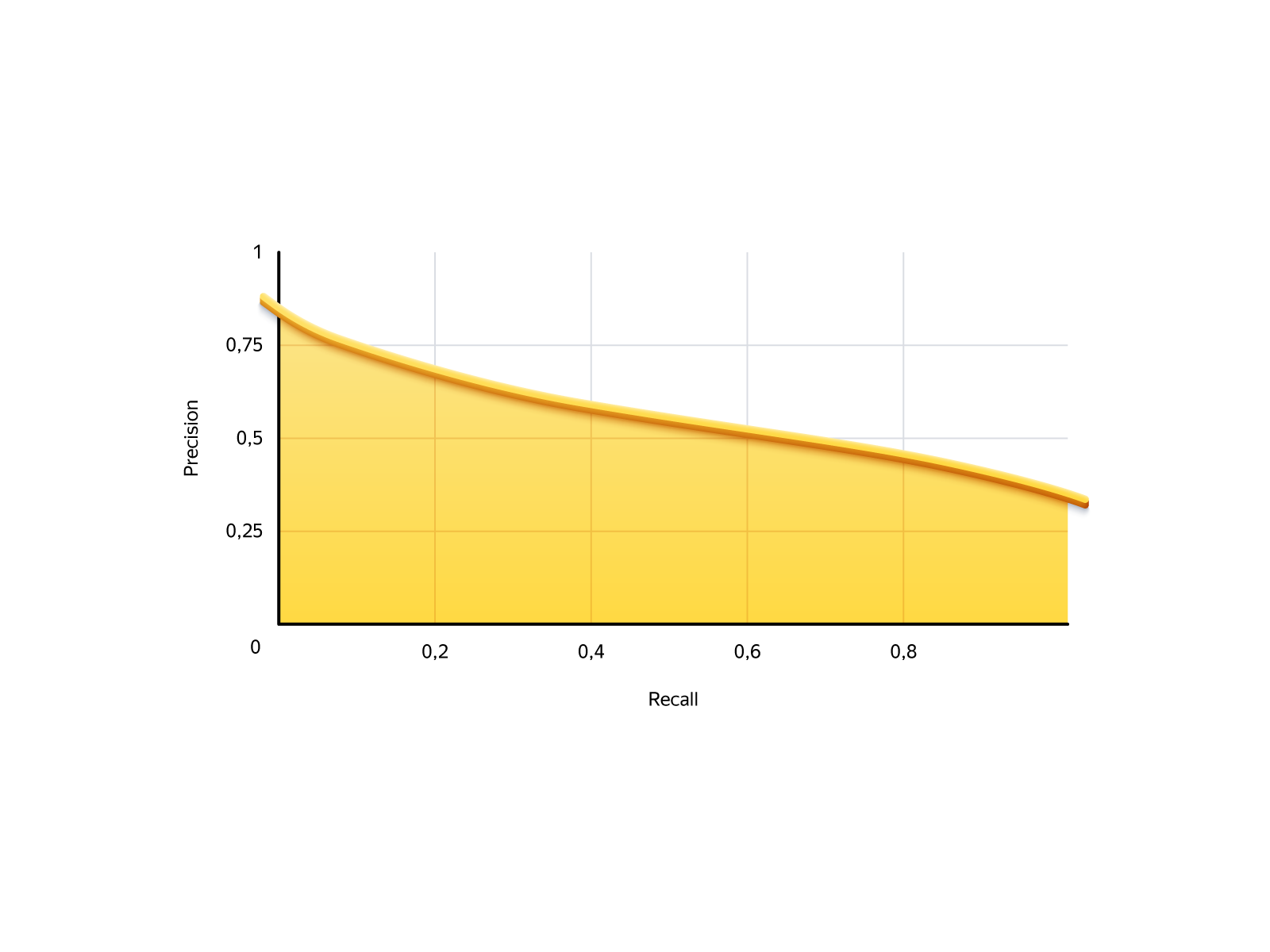
Ada dua kasus ekstrem: jangan izinkan siapa pun memesan dan mengizinkan semua orang memesan. Jika Anda tidak mengizinkan siapa pun, maka penarikan akan menjadi 0: kami tidak membuat pesanan, tetapi tidak ada yang akan gagal. Jika Anda mengizinkan semua orang, maka penarikan akan menjadi 100% (kami akan menerima semua pesanan yang mungkin), dan presisi - 29%, mis. 71% dari pesanan akan berubah menjadi buruk.
Sebagai tanda, kami menggunakan berbagai parameter dari titik keberangkatan:
- Waktu / tempat.
- Status sistem (jumlah mobil yang ditempati dari semua tarif dan pin di sekitarnya).
- Parameter pencarian (jari-jari, jumlah kandidat, batasan).
Detail tentang gejala
Secara konseptual, kami ingin membedakan antara dua situasi:
- "Hutan Mati" - tidak ada mobil di sini saat ini.
- "Sial" - ada mobil, tetapi tidak ada yang cocok ketika mencari.
Salah satu contoh "Sial" adalah jika ada permintaan tinggi di pusat pada Jumat malam. Ada banyak pesanan, ada banyak yang ingin banyak, tidak ada cukup driver sama sekali. Mungkin terjadi seperti ini: tidak ada driver yang sesuai di pin. Tapi secara harfiah dalam hitungan detik mereka muncul, karena saat ini di tempat ini ada banyak driver dan status mereka terus berubah.
Oleh karena itu, berbagai fitur sistem di sekitar titik A ternyata merupakan fitur yang baik:
- Jumlah total mobil.
- Jumlah mobil yang dipesan.
- Jumlah mesin yang tidak tersedia untuk pesanan dalam status "Sibuk".
- Jumlah pengguna.
Setelah semua, semakin banyak mobil di sekitar, semakin besar kemungkinan salah satu dari mereka akan tersedia.
Faktanya, penting bagi kita untuk tidak hanya memiliki mobil, tetapi juga membuat perjalanan yang sukses. Oleh karena itu, adalah mungkin untuk memprediksi kemungkinan perjalanan yang sukses. Tetapi kami memutuskan untuk tidak melakukan ini, karena nilai ini sangat tergantung pada pengguna dan driver.
CatBoost digunakan sebagai algoritma pembelajaran model. Untuk pelatihan kami menggunakan data yang diperoleh dari percobaan. Setelah implementasi, perlu untuk mengumpulkan data pelatihan, kadang-kadang memungkinkan sejumlah kecil pengguna untuk melakukan pemesanan yang bertentangan dengan keputusan model.
Ringkasan
Hasil percobaan ternyata diharapkan: penggunaan model memungkinkan untuk secara signifikan meningkatkan jumlah perjalanan yang berhasil karena pesanan tanpa mobil, tetapi pada saat yang sama tidak menurunkan keandalan.
Saat ini, mekanisme diluncurkan di semua kota dan negara, dan dengan itu sekitar 1% dari perjalanan yang sukses terjadi. Selain itu, di beberapa kota dengan kepadatan mobil yang rendah, pangsa perjalanan tersebut mencapai 15%.
Posting Teknologi Taksi Lainnya