Kesalahan dan perangkat lunak berjalan beriringan sejak awal era pemrograman komputer. Seiring berjalannya waktu, pengembang telah mengembangkan serangkaian praktik untuk menguji dan men-debug program sebelum diterapkan, tetapi praktik ini tidak lagi sesuai untuk sistem modern dengan pembelajaran yang mendalam. Saat ini, praktik utama dalam bidang pembelajaran mesin dapat disebut pelatihan pada set data tertentu, diikuti dengan verifikasi pada set lainnya. Dengan cara ini, Anda dapat menghitung efisiensi rata-rata model, tetapi juga penting untuk menjamin keandalan, yaitu efisiensi yang dapat diterima dalam kasus terburuk. Dalam artikel ini, kami menjelaskan tiga pendekatan untuk mengidentifikasi secara akurat dan menghilangkan kesalahan dalam model prediksi terlatih: pengujian permusuhan, pembelajaran yang kuat, dan
verifikasi formal .
Sistem dengan MOs, menurut definisi, tidak stabil. Bahkan sistem yang menang melawan seseorang di area tertentu mungkin tidak dapat mengatasi solusi masalah sederhana ketika membuat perbedaan halus. Sebagai contoh, perhatikan masalah gambar yang mengganggu: jaringan saraf yang dapat mengklasifikasikan gambar lebih baik daripada orang dapat dengan mudah dibuat untuk percaya bahwa sloth adalah mobil balap, menambahkan sebagian kecil dari kebisingan yang diperhitungkan dengan cermat pada gambar.
 Input yang bersaing ketika ditimpa pada gambar biasa dapat membingungkan AI. Dua gambar ekstrim berbeda tidak lebih dari 0,0078 untuk setiap piksel. Yang pertama diklasifikasikan sebagai sloth, dengan probabilitas 99%. Yang kedua seperti mobil balap dengan probabilitas 99%.
Input yang bersaing ketika ditimpa pada gambar biasa dapat membingungkan AI. Dua gambar ekstrim berbeda tidak lebih dari 0,0078 untuk setiap piksel. Yang pertama diklasifikasikan sebagai sloth, dengan probabilitas 99%. Yang kedua seperti mobil balap dengan probabilitas 99%.Masalah ini bukan hal baru. Program selalu memiliki kesalahan. Selama beberapa dekade, programmer telah mendapatkan serangkaian teknik yang mengesankan, dari pengujian unit hingga verifikasi formal. Pada program tradisional, metode ini bekerja dengan baik, tetapi mengadaptasi pendekatan ini untuk pengujian ketat model MO sangat sulit karena skala dan kurangnya struktur dalam model yang dapat berisi ratusan juta parameter. Ini menunjukkan perlunya mengembangkan pendekatan baru untuk memastikan keandalan sistem MO.
Dari sudut pandang programmer, bug adalah perilaku apa pun yang tidak memenuhi spesifikasi, yaitu fungsionalitas sistem yang direncanakan. Sebagai bagian dari penelitian AI kami, kami mempelajari teknik untuk menilai apakah sistem MO memenuhi persyaratan tidak hanya pada set pelatihan dan tes, tetapi juga pada daftar spesifikasi yang menggambarkan sifat-sifat yang diinginkan dari sistem. Di antara sifat-sifat ini mungkin ada resistensi terhadap perubahan kecil yang cukup dalam data input, pembatasan keselamatan yang mencegah kegagalan bencana, atau kepatuhan prediksi dengan hukum fisika.
Dalam artikel ini, kita akan membahas tiga masalah teknis penting yang dihadapi komunitas MO dalam bekerja untuk membuat sistem MO kuat dan andal sesuai spesifikasi yang diinginkan:
- Verifikasi kepatuhan yang efektif terhadap spesifikasi. Kami mempelajari cara-cara efektif untuk memverifikasi bahwa sistem MO sesuai dengan propertinya (misalnya, seperti stabilitas dan invarian) yang diperlukan dari mereka oleh pengembang dan pengguna. Salah satu pendekatan untuk menemukan kasus di mana model dapat pindah dari properti ini adalah secara sistematis mencari hasil pekerjaan terburuk.
- Melatih model MO untuk spesifikasi. Bahkan jika ada sejumlah besar data pelatihan, algoritma MO standar dapat menghasilkan model prediksi yang operasinya tidak memenuhi spesifikasi yang diinginkan. Kami harus merevisi algoritma pelatihan sehingga tidak hanya berfungsi dengan baik pada data pelatihan, tetapi juga memenuhi spesifikasi yang diinginkan.
- Bukti formal kesesuaian model MO dengan spesifikasi yang diinginkan. Algoritma harus dikembangkan untuk mengkonfirmasi bahwa model memenuhi spesifikasi yang diinginkan untuk semua data input yang mungkin. Meskipun bidang verifikasi formal telah mempelajari algoritma tersebut selama beberapa dekade, meskipun ada kemajuan yang mengesankan, pendekatan ini tidak mudah untuk skala ke sistem MO modern.
Verifikasi Kepatuhan Model dengan Spesifikasi yang Diinginkan
Perlawanan terhadap contoh-contoh kompetitif adalah masalah pertahanan sipil yang cukup banyak dipelajari. Salah satu kesimpulan utama yang dibuat adalah pentingnya mengevaluasi tindakan jaringan sebagai akibat dari serangan yang kuat, dan pengembangan model transparan yang dapat dianalisis dengan cukup efektif. Kami, bersama dengan peneliti lain, telah menemukan bahwa banyak model terbukti tahan terhadap contoh yang lemah dan kompetitif. Namun, mereka memberikan akurasi hampir 0% untuk contoh kompetitif yang lebih kuat (
Athalye et al., 2018 ,
Uesato et al., 2018 ,
Carlini dan Wagner, 2017 ).
Meskipun sebagian besar pekerjaan berfokus pada kegagalan langka dalam konteks mengajar dengan seorang guru (dan ini terutama klasifikasi gambar), ada kebutuhan untuk memperluas penerapan ide-ide ini ke bidang lain. Dalam karya terbaru dengan pendekatan kompetitif untuk menemukan kegagalan katastropik, kami menerapkan ide-ide ini untuk menguji jaringan yang dilatih dengan penguatan dan dirancang untuk digunakan di tempat-tempat dengan persyaratan keamanan tinggi. Salah satu tantangan mengembangkan sistem otonom adalah bahwa, karena satu kesalahan dapat memiliki konsekuensi serius, bahkan kemungkinan kecil kegagalan tidak dapat diterima.
Tujuan kami adalah merancang "saingan" yang akan membantu untuk mengenali kesalahan seperti itu sebelumnya (dalam lingkungan yang terkendali). Jika musuh dapat secara efektif menentukan data input terburuk untuk model yang diberikan, ini akan memungkinkan kita untuk menangkap kasus kegagalan yang jarang terjadi sebelum menempatkannya. Seperti halnya penggolong gambar, mengevaluasi cara bekerja dengan lawan yang lemah memberi Anda rasa aman yang salah selama penerapan. Pendekatan ini mirip dengan pengembangan perangkat lunak dengan bantuan "tim merah" [tim merah - melibatkan tim pengembang pihak ketiga yang berperan sebagai penyerang untuk mendeteksi kerentanan / perkiraan. terjemahan.], namun, melampaui pencarian kegagalan yang disebabkan oleh penyusup, dan juga termasuk kesalahan yang terjadi secara alami, misalnya, karena generalisasi yang tidak memadai.
Kami telah mengembangkan dua pendekatan pelengkap untuk pengujian kompetitif jaringan pembelajaran yang diperkuat. Yang pertama, kami menggunakan optimisasi bebas derivatif untuk secara langsung meminimalkan hadiah yang diharapkan. Dalam yang kedua, kita belajar fungsi nilai permusuhan, yang dalam pengalaman memprediksi di mana situasi jaringan mungkin gagal. Kemudian kami menggunakan fungsi yang dipelajari ini untuk optimasi, berkonsentrasi pada evaluasi data input yang paling bermasalah. Pendekatan-pendekatan ini hanya membentuk sebagian kecil dari ruang yang kaya dan berkembang dari algoritma potensial, dan kami sangat tertarik dengan pengembangan masa depan dari area ini.
Kedua pendekatan sudah menunjukkan peningkatan yang signifikan dibandingkan pengujian acak. Dengan menggunakan metode kami, dalam beberapa menit dimungkinkan untuk mendeteksi kekurangan yang sebelumnya harus dicari sepanjang hari, atau bahkan mungkin tidak dapat ditemukan (
Uesato et al., 2018b ). Kami juga menemukan bahwa pengujian kompetitif dapat mengungkapkan perilaku jaringan yang berbeda secara kualitatif dibandingkan dengan apa yang mungkin diharapkan dari evaluasi pada set uji acak. Secara khusus, menggunakan metode kami, kami menemukan bahwa jaringan yang melakukan tugas orientasi pada peta tiga dimensi, dan biasanya mengatasinya di tingkat manusia, tidak dapat menemukan target dalam labirin sederhana yang tidak terduga (
Ruderman et al., 2018 ). Pekerjaan kami juga menekankan perlunya merancang sistem yang aman terhadap kegagalan alami, dan bukan hanya saingan.
 Melakukan tes pada sampel acak, kita hampir tidak pernah melihat kartu dengan probabilitas kegagalan yang tinggi, tetapi pengujian kompetitif menunjukkan adanya kartu tersebut. Probabilitas kegagalan tetap tinggi bahkan setelah penghapusan banyak dinding, yaitu penyederhanaan peta dibandingkan dengan yang asli.
Melakukan tes pada sampel acak, kita hampir tidak pernah melihat kartu dengan probabilitas kegagalan yang tinggi, tetapi pengujian kompetitif menunjukkan adanya kartu tersebut. Probabilitas kegagalan tetap tinggi bahkan setelah penghapusan banyak dinding, yaitu penyederhanaan peta dibandingkan dengan yang asli.Pelatihan Model Spec
Pengujian kompetitif berupaya menemukan contoh tandingan yang melanggar spesifikasi. Seringkali, itu melebih-lebihkan konsistensi model dengan spesifikasi ini. Dari sudut pandang matematika, spesifikasi adalah jenis hubungan yang harus dipertahankan antara input dan output data jaringan. Ini dapat berbentuk batas atas dan bawah atau beberapa parameter input dan output utama.
Terinspirasi oleh pengamatan ini, beberapa peneliti (
Raghunathan et al., 2018 ;
Wong et al., 2018 ;
Mirman et al., 2018 ;
Wang et al., 2018 ), termasuk tim kami dari DeepMind (
Dvijotham et al., 2018 ;
Gowal et al., 2018 ), bekerja pada algoritma invarian untuk pengujian kompetitif. Ini dapat dijelaskan secara geometris - kita dapat membatasi (
Ehlers 2017 ,
Katz et al. 2017 ,
Mirman et al., 2018 ) pelanggaran spesifikasi terburuk, membatasi ruang data output berdasarkan pada set input. Jika batas ini dapat dibedakan berdasarkan parameter jaringan dan dapat dihitung dengan cepat, dapat digunakan selama pelatihan. Kemudian, batas asli dapat menyebar melalui setiap lapisan jaringan.
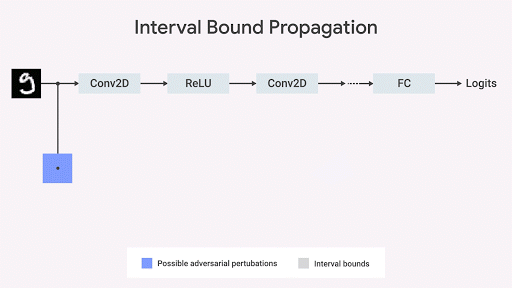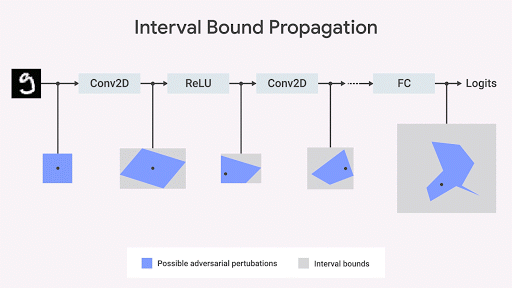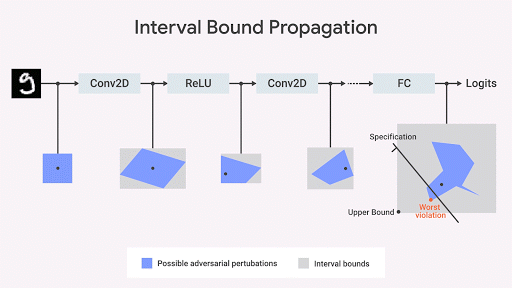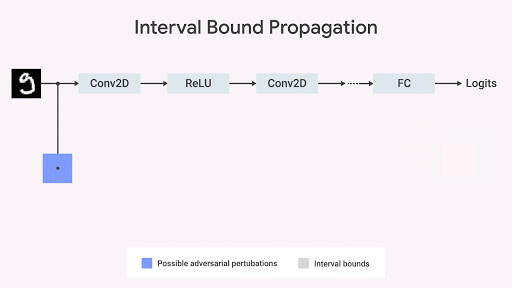
Kami menunjukkan bahwa penyebaran batas interval cepat, efisien, dan - tidak seperti apa yang dipikirkan sebelumnya - memberikan hasil yang baik (
Gowal et al., 2018 ). Secara khusus, kami menunjukkan bahwa hal itu dapat mengurangi jumlah kesalahan (mis., Jumlah kesalahan maksimum yang dapat ditimbulkan oleh lawan mana pun) secara provokatif dibandingkan dengan pengklasifikasi gambar paling canggih pada set dari database MNIST dan CIFAR-10.
Tujuan selanjutnya adalah mempelajari abstraksi geometrik yang benar untuk menghitung perkiraan ruang keluaran yang berlebihan. Kami juga ingin melatih jaringan sehingga mereka dapat bekerja dengan baik dengan spesifikasi yang lebih kompleks yang menggambarkan perilaku yang diinginkan, seperti invarian yang disebutkan sebelumnya dan kepatuhan terhadap hukum fisik.
Verifikasi formal
Pengujian dan pelatihan menyeluruh dapat sangat membantu dalam menciptakan sistem MO yang andal. Namun, pengujian voluminous resmi sewenang-wenang tidak dapat menjamin bahwa perilaku sistem sesuai dengan keinginan kami. Dalam model skala besar, menghitung semua opsi output yang mungkin untuk satu set input yang diberikan (misalnya, perubahan gambar kecil) tampaknya sulit untuk diterapkan karena jumlah astronomi yang memungkinkan perubahan gambar. Namun, seperti dalam kasus pelatihan, orang dapat menemukan pendekatan yang lebih efektif untuk menetapkan batasan geometrik pada set data output. Verifikasi formal adalah subjek penelitian yang sedang berlangsung di DeepMind.
Komunitas MO telah mengembangkan beberapa ide menarik untuk menghitung batas geometris yang tepat dari ruang output jaringan (Katz et al. 2017,
Weng et al., 2018 ;
Singh et al., 2018 ). Pendekatan kami (
Dvijotham et al., 2018 ), berdasarkan optimasi dan dualitas, terdiri dari perumusan masalah verifikasi dalam hal optimasi, yang mencoba untuk menemukan pelanggaran terbesar dari properti yang diuji. Tugas menjadi computable jika ide dari dualitas digunakan dalam optimisasi. Sebagai hasilnya, kami mendapatkan batasan tambahan yang menentukan batas yang dihitung ketika memindahkan batas interval [interval terikat propagasi] menggunakan apa yang disebut bidang pemotongan. Ini adalah pendekatan yang dapat diandalkan tetapi tidak lengkap: mungkin ada kasus ketika properti yang menarik bagi kami puas, tetapi batas yang dihitung oleh algoritma ini tidak cukup ketat sehingga keberadaan properti ini dapat dibuktikan secara formal. Namun, setelah menerima perbatasan, kami mendapatkan jaminan resmi tentang tidak adanya pelanggaran terhadap properti ini. Dalam gbr. Di bawah pendekatan ini diilustrasikan secara grafis.

Pendekatan ini memungkinkan kami untuk memperluas penerapan algoritma verifikasi pada jaringan yang lebih umum (fungsi aktivator, arsitektur), spesifikasi umum dan model GO yang lebih kompleks (model generatif, proses saraf, dll.) Dan spesifikasi yang melampaui keandalan kompetitif (
Qin , 2018 ).
Prospek
Menyebarkan MO dalam situasi berisiko tinggi memiliki tantangan dan kesulitan tersendiri, dan ini membutuhkan pengembangan teknologi penilaian yang dijamin untuk mendeteksi kesalahan yang tidak mungkin terjadi. Kami percaya bahwa pelatihan yang konsisten mengenai spesifikasi dapat secara signifikan meningkatkan kinerja dibandingkan dengan kasus-kasus di mana spesifikasi muncul secara implisit dari data pelatihan. Kami menantikan hasil studi penilaian kompetitif yang sedang berlangsung, model pelatihan yang kuat dan verifikasi spesifikasi formal.
Jauh lebih banyak pekerjaan akan diperlukan bagi kita untuk dapat membuat alat otomatis yang menjamin bahwa sistem AI di dunia nyata akan "melakukan segalanya dengan benar." Secara khusus, kami sangat senang untuk maju dalam bidang-bidang berikut:
- Pelatihan untuk penilaian dan verifikasi kompetitif. Dengan penskalaan dan kecanggihan sistem AI, semakin sulit untuk merancang penilaian kompetitif dan algoritma verifikasi yang cukup disesuaikan dengan model AI. Jika kita dapat menggunakan kekuatan penuh AI untuk evaluasi dan verifikasi, proses ini dapat ditingkatkan.
- Pengembangan alat yang tersedia untuk umum untuk penilaian dan verifikasi kompetitif: penting untuk memberi insinyur dan orang yang menggunakan AI lainnya alat yang mudah digunakan yang menjelaskan kemungkinan mode kegagalan sistem AI sebelum kegagalan ini mengarah pada konsekuensi negatif yang luas. Ini akan memerlukan beberapa standardisasi penilaian kompetitif dan algoritma verifikasi.
- Memperluas spektrum contoh kompetitif. Sejauh ini, sebagian besar pekerjaan pada contoh kompetitif telah difokuskan pada stabilitas model untuk perubahan kecil, biasanya di area gambar. Ini telah menjadi ajang pengujian yang sangat baik untuk mengembangkan pendekatan penilaian kompetitif, pelatihan yang andal, dan verifikasi. Kami mulai mempelajari berbagai spesifikasi untuk properti yang berhubungan langsung dengan dunia nyata, dan kami menantikan hasil penelitian masa depan dalam arah ini.
- Spesifikasi pelatihan. Spesifikasi yang menggambarkan perilaku "benar" sistem AI seringkali sulit untuk dirumuskan secara akurat. Ketika kita menciptakan lebih banyak dan lebih banyak sistem cerdas yang mampu berperilaku kompleks dan bekerja dalam lingkungan yang tidak terstruktur, kita perlu belajar bagaimana membuat sistem yang dapat menggunakan spesifikasi yang diformulasikan sebagian, dan memperoleh spesifikasi lebih lanjut dari umpan balik.
DeepMind berkomitmen untuk memberikan dampak positif pada masyarakat melalui pengembangan dan penyebaran sistem MO yang bertanggung jawab. Untuk memastikan bahwa kontribusi pengembang dijamin positif, kita perlu menghadapi banyak kendala teknis. Kami bermaksud berkontribusi pada bidang ini dan senang bekerja dengan komunitas untuk menyelesaikan masalah ini.