Ada beberapa pendekatan untuk memahami mesin pidato sehari-hari: pendekatan tiga komponen klasik (termasuk komponen pengenalan ucapan, komponen pemahaman bahasa alami dan komponen yang bertanggung jawab untuk logika bisnis tertentu) dan pendekatan End2End yang melibatkan empat model implementasi: langsung, kolaboratif, multi-stage, dan multi-tasking . Mari kita pertimbangkan semua pro dan kontra dari pendekatan ini, termasuk yang didasarkan pada eksperimen Google, dan menganalisis secara rinci mengapa pendekatan End2End menyelesaikan masalah dari pendekatan klasik.

Kami memberikan dasar kepada pengembang terkemuka pusat AI MTS Nikita Semenov.
Hai Sebagai pengantar, saya ingin mengutip ilmuwan terkenal Jan Lekun, Joshua Benjio dan Jeffrey Hinton - ini adalah tiga perintis kecerdasan buatan yang baru-baru ini menerima salah satu penghargaan paling bergengsi di bidang teknologi informasi - Penghargaan Turing. Dalam salah satu edisi majalah Nature pada tahun 2015, mereka merilis artikel yang sangat menarik "Pembelajaran mendalam", di mana ada ungkapan yang menarik: "Pembelajaran mendalam datang dengan janji kemampuannya untuk menangani sinyal mentah tanpa perlu fitur kerajinan tangan". Sulit untuk menerjemahkannya dengan benar, tetapi maknanya kira-kira seperti ini: "Pembelajaran mendalam telah datang dengan janji kemampuan untuk mengatasi sinyal mentah tanpa perlu membuat tanda secara manual." Menurut pendapat saya, untuk pengembang ini adalah motivator utama dari semua yang ada.
Pendekatan klasik
Jadi, mari kita mulai dengan pendekatan klasik. Ketika kita berbicara tentang memahami berbicara dengan mesin, kita berarti bahwa kita memiliki orang tertentu yang ingin mengendalikan beberapa layanan dengan suaranya atau merasakan perlunya beberapa sistem untuk menanggapi perintah suaranya dengan beberapa logika.
Bagaimana mengatasi masalah ini? Dalam versi klasik, suatu sistem digunakan, yang, sebagaimana disebutkan di atas, terdiri dari tiga komponen besar: komponen pengenalan suara, komponen untuk memahami bahasa alami, dan komponen yang bertanggung jawab untuk logika bisnis tertentu. Jelas bahwa pada awalnya pengguna membuat sinyal suara tertentu, yang jatuh pada komponen pengenalan suara dan beralih dari suara ke teks. Kemudian teks jatuh ke dalam komponen pemahaman bahasa alami, dari mana struktur semantik tertentu dikeluarkan, yang diperlukan untuk komponen yang bertanggung jawab untuk logika bisnis.
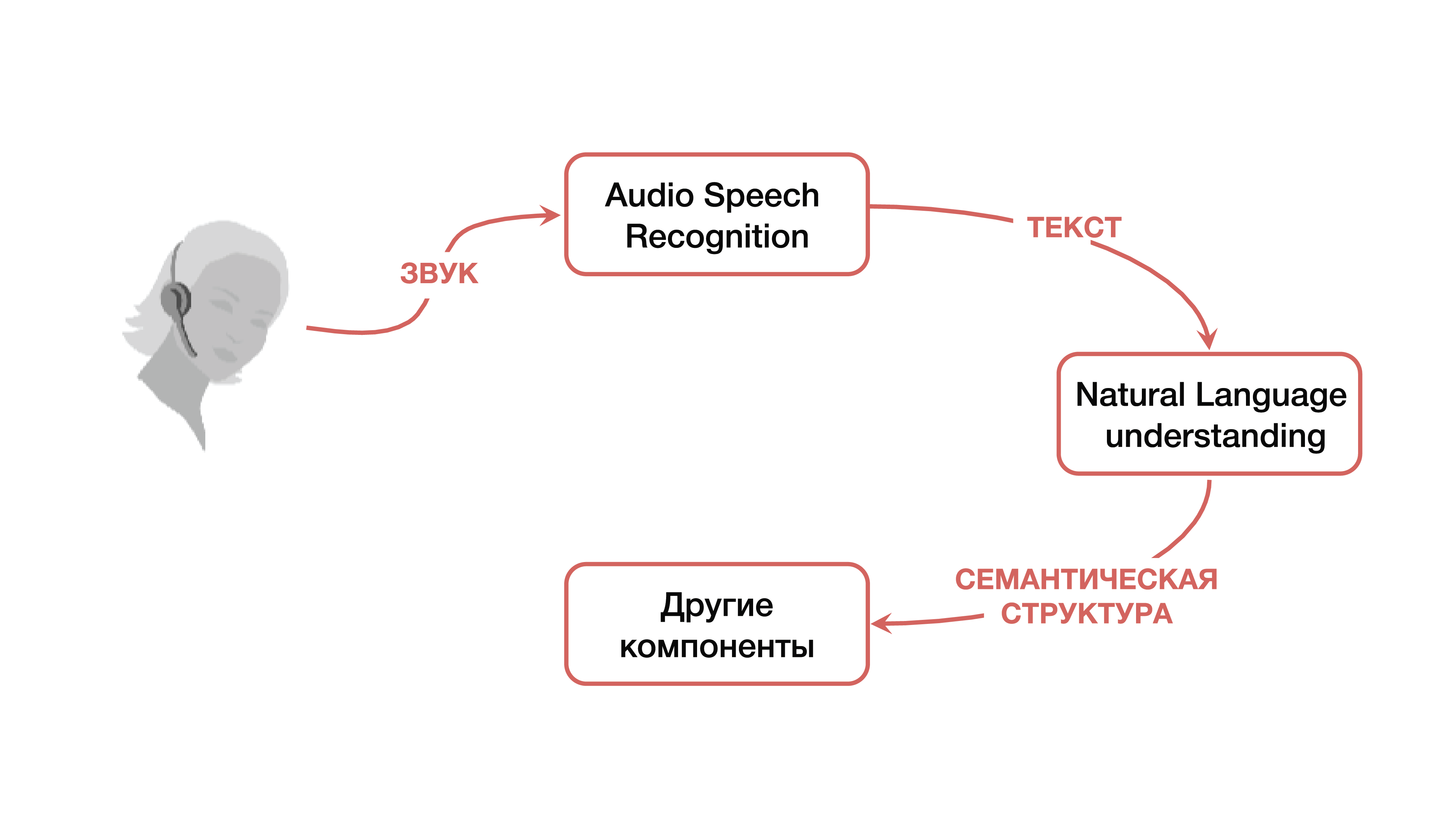
Apa itu struktur semantik? Ini adalah semacam generalisasi / agregasi dari beberapa tugas menjadi satu - untuk memudahkan pemahaman. Struktur ini mencakup tiga bagian penting: klasifikasi domain (definisi topik tertentu), klasifikasi maksud (memahami apa yang perlu dilakukan) dan alokasi entitas yang disebutkan untuk mengisi kartu yang diperlukan untuk tugas-tugas bisnis spesifik pada tahap berikutnya. Untuk memahami apa struktur semantik itu, Anda dapat mempertimbangkan contoh sederhana, yang paling sering dikutip Google. Kami memiliki permintaan sederhana: "Silakan mainkan beberapa lagu artis."

Domain dan subjek dalam permintaan ini adalah musik; niat - memainkan lagu; atribut kartu “main lagu” - lagu apa, artis seperti apa. Struktur seperti itu adalah hasil dari pemahaman bahasa alami.
Jika kita berbicara tentang memecahkan masalah yang kompleks dan multi-tahap dalam memahami percakapan sehari-hari, maka, seperti yang saya katakan, itu terdiri dari dua tahap: yang pertama adalah pengenalan suara, yang kedua adalah memahami bahasa alami. Pendekatan klasik melibatkan pemisahan lengkap dari tahapan-tahapan ini. Sebagai langkah pertama, kami memiliki model tertentu yang menerima sinyal akustik pada input, dan pada output, menggunakan model bahasa dan akustik dan leksikon, menentukan hipotesis verbal yang paling mungkin dari sinyal akustik ini. Ini adalah kisah yang sepenuhnya probabilistik - dapat diurai sesuai dengan formula Bayes yang terkenal dan dapatkan formula yang memungkinkan Anda menulis fungsi kemungkinan sampel dan menggunakan metode kemungkinan maksimum. Kami memiliki probabilitas bersyarat dari sinyal X asalkan urutan kata W dikalikan dengan probabilitas urutan kata ini.

Tahap pertama yang kami lalui - kami mendapat hipotesis verbal dari sinyal suara. Berikutnya adalah komponen kedua, yang mengambil hipotesis sangat verbal ini dan mencoba mengeluarkan struktur semantik yang dijelaskan di atas.
Kami memiliki kemungkinan struktur semantik S asalkan urutan verbal W adalah pada input.

Apa hal buruk tentang pendekatan klasik, yang terdiri dari dua elemen / langkah ini, yang diajarkan secara terpisah (mis. Pertama-tama kita melatih model elemen pertama, dan kemudian model elemen kedua)?
- Komponen pemahaman bahasa alami bekerja dengan hipotesis verbal tingkat tinggi yang dihasilkan ASR. Ini adalah masalah besar, karena komponen pertama (ASR sendiri) bekerja dengan data mentah tingkat rendah dan menghasilkan hipotesis verbal tingkat tinggi, dan komponen kedua menggunakan hipotesis sebagai input - bukan data mentah dari sumber utama, tetapi hipotesis yang diberikan oleh model pertama - dan membangun hipotesisnya atas hipotesis tahap pertama. Ini adalah kisah yang agak bermasalah, karena menjadi terlalu "kondisional."
- Masalah berikutnya: kita tidak dapat membuat hubungan antara pentingnya kata-kata yang diperlukan untuk membangun struktur yang sangat semantik dan apa yang lebih disukai komponen pertama ketika membangun hipotesis verbal kita. Artinya, jika Anda ulangi, kami mendapatkan bahwa hipotesis telah dibangun. Itu dibangun atas dasar tiga komponen, seperti yang saya katakan: bagian akustik (apa yang masuk ke input dan entah bagaimana dimodelkan), bagian bahasa (sepenuhnya memodelkan bahasa apa pun engrams - kemungkinan berbicara) dan leksikon (pengucapan kata-kata). Ini adalah tiga bagian besar yang perlu digabungkan dan beberapa hipotesis ditemukan di dalamnya. Tetapi tidak ada cara untuk mempengaruhi pilihan hipotesis yang sama sehingga hipotesis ini penting untuk tahap berikutnya (yang, pada prinsipnya, terletak pada titik bahwa mereka belajar sepenuhnya secara terpisah dan tidak saling mempengaruhi dengan cara apa pun).
Pendekatan End2End
Kami memahami apa pendekatan klasik, masalah apa yang dimilikinya. Mari kita coba selesaikan masalah ini menggunakan pendekatan End2End.
By End2End yang kami maksud adalah model yang akan menggabungkan berbagai komponen menjadi satu komponen. Kami akan memodelkan menggunakan model yang terdiri dari arsitektur encoder-decoder yang berisi modul perhatian (attention). Arsitektur semacam itu sering digunakan dalam masalah pengenalan ucapan dan dalam tugas yang berkaitan dengan pemrosesan bahasa alami, khususnya, terjemahan mesin.
Ada empat opsi untuk penerapan pendekatan seperti itu yang dapat memecahkan masalah yang diajukan kepada kita melalui pendekatan klasik: ini adalah model langsung, kolaboratif, multi-tahap dan multi-tugas.
Model langsung
Model langsung mengambil input atribut mentah level rendah, yaitu sinyal audio tingkat rendah, dan pada output kita segera mendapatkan struktur semantik. Yaitu, kita mendapatkan satu modul - input dari modul pertama dari pendekatan klasik dan output dari modul kedua dari pendekatan klasik yang sama. Seperti "kotak hitam". Dari sini ada beberapa kelebihan dan kekurangan. Model tidak belajar sepenuhnya menyalin sinyal input - ini merupakan nilai tambah yang jelas, karena kita tidak perlu mengumpulkan markup besar, besar, kita tidak perlu mengumpulkan banyak sinyal audio, dan kemudian memberikannya kepada para pengakses untuk markup. Kami hanya perlu sinyal audio ini dan struktur semantik yang sesuai. Dan itu saja. Ini berkali-kali mengurangi tenaga kerja yang terlibat dalam menandai data. Mungkin minus terbesar dari pendekatan ini adalah bahwa tugasnya terlalu rumit untuk "kotak hitam" seperti itu, yang mencoba untuk menyelesaikan segera, dengan syarat, dua masalah. Pertama, di dalam dirinya, ia mencoba membangun semacam transkripsi, dan kemudian dari transkripsi ini mengungkapkan struktur yang sangat semantik. Ini menimbulkan tugas yang agak sulit - belajar mengabaikan bagian-bagian transkripsi. Dan itu sangat sulit. Faktor ini adalah minus yang agak besar dan kolosal dari pendekatan ini.
Jika kita berbicara tentang probabilitas, maka model ini memecahkan masalah menemukan struktur semantik yang paling mungkin dari sinyal akustik X dengan parameter model θ.
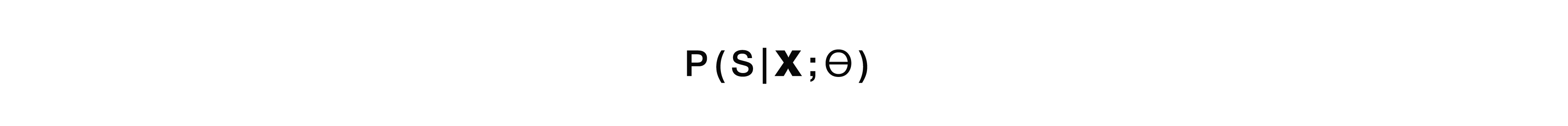
Model bersama
Apa alternatifnya? Ini adalah model kolaboratif. Yaitu, beberapa model sangat mirip dengan garis lurus, tetapi dengan satu pengecualian: output bagi kita sudah terdiri dari urutan verbal dan struktur semantik hanya disatukan dengan mereka. Yaitu, pada input kita memiliki sinyal suara dan model jaringan saraf, yang pada output sudah memberikan transkripsi verbal dan struktur semantik.
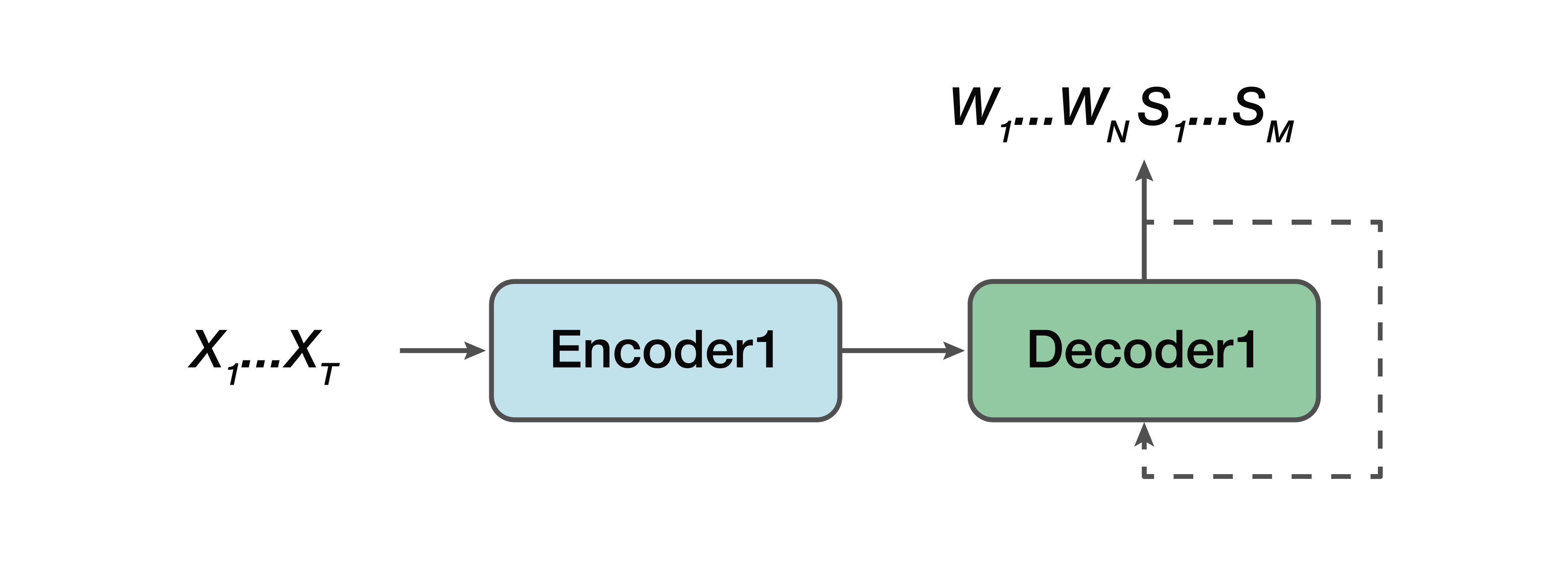
Dari pro: kami masih memiliki encoder sederhana, decoder sederhana. Pembelajaran difasilitasi karena model tidak mencoba menyelesaikan dua masalah sekaligus, seperti dalam kasus model langsung. Satu keuntungan lagi adalah bahwa ketergantungan struktur semantik pada atribut-atribut suara tingkat rendah masih ada. Karena, sekali lagi, satu encoder, satu decoder. Dan, dengan demikian, salah satu nilai tambah dapat dicatat bahwa ada ketergantungan dalam memprediksi struktur yang sangat semantik ini dan pengaruhnya langsung pada transkripsi itu sendiri - yang tidak sesuai dengan kita dalam pendekatan klasik.
Sekali lagi, kita perlu menemukan urutan kata yang paling memungkinkan dari W dan struktur semantik yang sesuai S dari sinyal akustik X dengan parameter θ.
Model multitasking
Pendekatan selanjutnya adalah model multi-tasking. Sekali lagi, pendekatan encoder-decoder, tetapi dengan satu pengecualian.
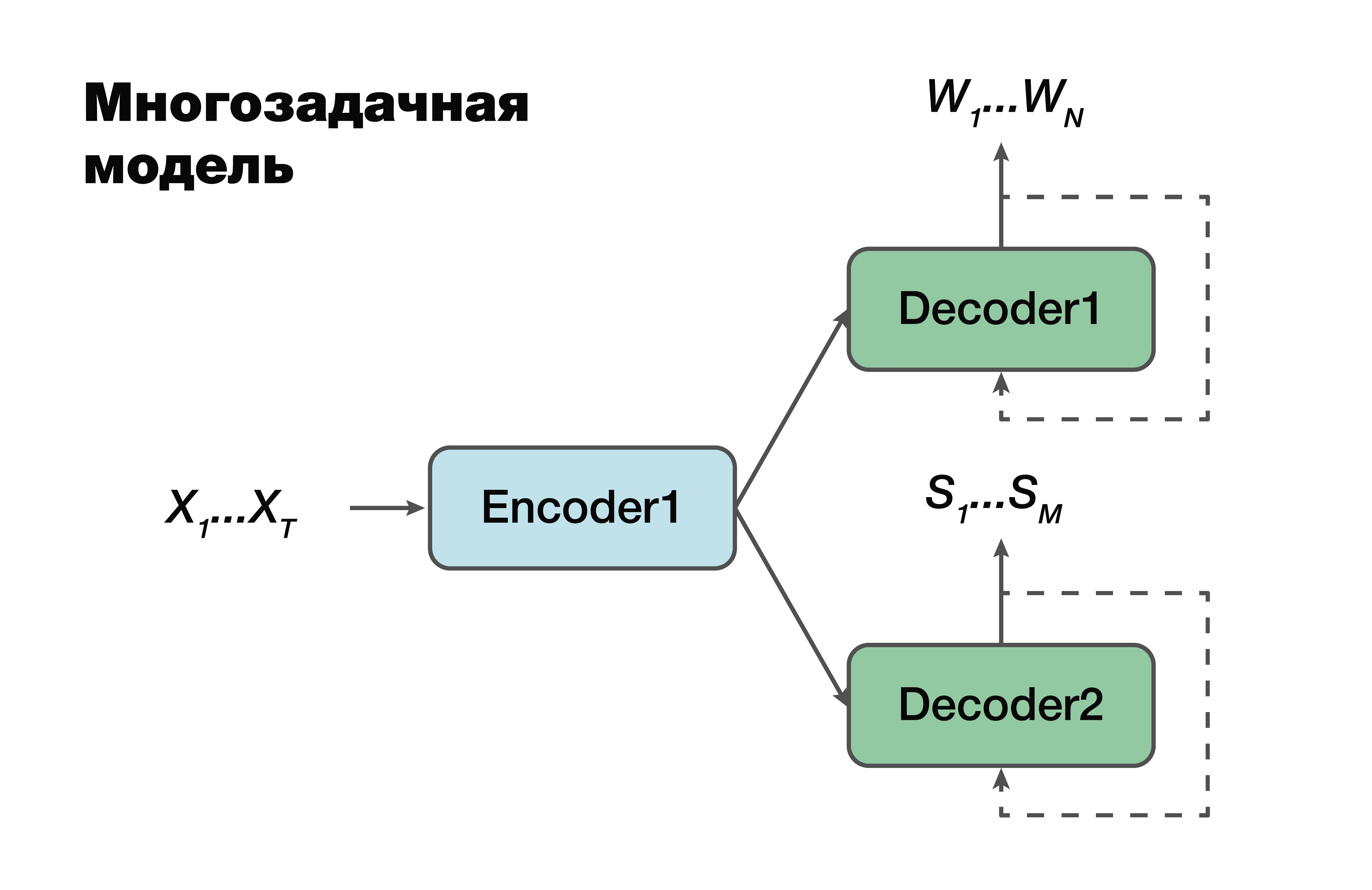
Untuk setiap tugas, yaitu, untuk membuat urutan verbal, untuk membuat struktur semantik, kami memiliki dekoder kami sendiri yang menggunakan satu representasi tersembunyi umum yang menghasilkan satu encoder. Trik yang sangat terkenal dalam pembelajaran mesin, sangat sering digunakan dalam pekerjaan. Memecahkan dua masalah yang berbeda sekaligus membantu untuk mencari dependensi dalam sumber data yang jauh lebih baik. Dan sebagai konsekuensi dari ini - kemampuan generalisasi terbaik, karena parameter optimal dipilih untuk beberapa tugas sekaligus. Pendekatan ini paling cocok untuk tugas-tugas dengan lebih sedikit data. Dan decoder menggunakan satu ruang vektor tersembunyi tempat pembuat enkode mereka menciptakan.

Penting untuk dicatat bahwa sudah dalam probabilitas ada ketergantungan pada parameter model encoder dan decoder. Dan parameter ini penting.
Model multi-tahap
Menurut saya, kita beralih ke pendekatan yang paling menarik: model multi-tahap. Jika Anda melihat dengan sangat hati-hati, Anda dapat melihat bahwa sebenarnya ini adalah pendekatan klasik dua komponen yang sama dengan satu pengecualian.
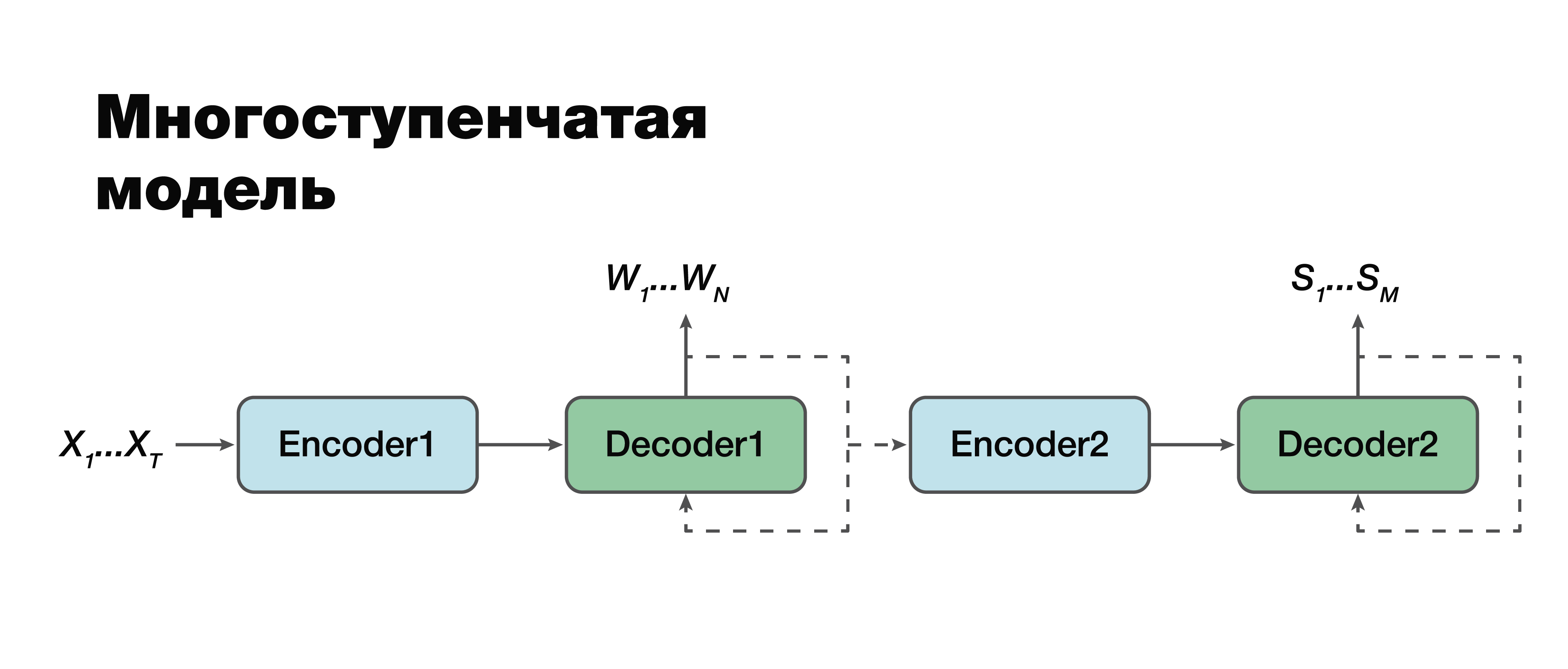
Di sini dimungkinkan untuk membuat koneksi antar modul dan menjadikannya satu modul. Oleh karena itu, struktur semantik dianggap tergantung secara kondisional pada transkripsi. Ada dua opsi untuk bekerja dengan model ini. Kita dapat melatih dua blok mini ini secara terpisah: dekoder-dekoder pertama dan kedua. Atau gabungkan keduanya dan latih kedua tugas sekaligus.
Dalam kasus pertama, parameter untuk dua tugas tidak terkait (kita bisa berlatih menggunakan data yang berbeda). Misalkan kita memiliki tubuh suara yang besar dan urutan dan transkripsi verbal yang sesuai. Kami "menyetir" mereka, kami hanya melatih bagian pertama. Kami mendapatkan simulasi transkripsi yang baik. Lalu kita ambil bagian kedua, kita latih kasus lain. Kami terhubung dan mendapatkan solusi yang dalam pendekatan ini 100% konsisten dengan pendekatan klasik, karena kami secara terpisah mengambil dan melatih bagian pertama dan secara terpisah bagian kedua. Dan kemudian kita melatih model yang terhubung pada case, yang sudah berisi triad data: sinyal audio, transkripsi yang sesuai dan struktur semantik yang sesuai. Jika kita memiliki bangunan seperti itu, kita dapat melatih ulang model, dilatih secara individual pada bangunan besar, untuk tugas kecil spesifik kita dan mendapatkan keakuratan maksimum dalam cara yang rumit. Pendekatan ini memungkinkan kita untuk memperhitungkan pentingnya berbagai bagian transkripsi dan pengaruhnya terhadap prediksi struktur semantik dengan
memperhitungkan kesalahan tahap kedua pada tahap pertama.
Penting untuk dicatat bahwa tugas akhir sangat mirip dengan pendekatan klasik dengan hanya satu perbedaan besar: istilah kedua dari fungsi kami - logaritma probabilitas struktur semantik - asalkan sinyal akustik input X juga tergantung pada parameter
model model tahap pertama .

Penting juga untuk dicatat di sini bahwa komponen kedua tergantung pada parameter model pertama dan kedua.
Metodologi untuk menilai keakuratan pendekatan
Sekarang ada baiknya memutuskan teknik penilaian akurasi. Bagaimana, sebenarnya, untuk mengukur akurasi ini untuk memperhitungkan fitur-fitur akun yang tidak sesuai dengan kita dalam pendekatan klasik? Ada label klasik untuk tugas-tugas terpisah ini. Untuk mengevaluasi komponen pengenalan suara, kita dapat menggunakan metrik WER klasik. Ini adalah Tingkat Kesalahan Kata. Kami mempertimbangkan, menurut formula yang tidak terlalu rumit, jumlah sisipan, substitusi, permutasi kata dan membaginya dengan jumlah semua kata. Dan kami mendapatkan perkiraan karakteristik tertentu dari kualitas pengakuan kami. Untuk struktur semantik, secara komponen, kita dapat mempertimbangkan skor F1. Ini juga beberapa metrik klasik untuk masalah klasifikasi. Di sini semuanya plus atau minus jelas. Ada kepenuhan, ada akurasi. Dan ini hanya rata-rata harmonis di antara mereka.
Tetapi muncul pertanyaan bagaimana mengukur akurasi ketika transkripsi input dan argumen output tidak cocok atau ketika output adalah data audio. Google telah mengusulkan metrik yang akan mempertimbangkan pentingnya memprediksi komponen pertama dari pengenalan suara dengan menilai efek dari pengakuan ini pada komponen kedua itu sendiri. Mereka menyebutnya Arg WER, yaitu, itu menimbang WER atas entitas struktur semantik.
Terima permintaan: "Setel alarm selama 5 jam." Struktur semantik ini berisi argumen seperti "lima jam", argumen tipe "tanggal". Penting untuk dipahami bahwa jika komponen pengenalan ucapan menghasilkan argumen ini, maka metrik kesalahan argumen ini, yaitu, WER, adalah 0%. Jika nilai ini tidak sesuai dengan lima jam, maka metriknya 100% WER. Dengan demikian, kami hanya mempertimbangkan nilai rata-rata tertimbang untuk semua argumen dan, secara umum, mendapatkan metrik agregat tertentu yang memperkirakan pentingnya kesalahan transkripsi yang membuat komponen pengenalan suara.
Biarkan saya memberi Anda contoh percobaan Google yang dilakukan dalam salah satu studi tentang topik ini. Mereka menggunakan data dari lima domain, lima mata pelajaran: Media, Media_Control, Produktivitas, Delight, Tidak ada - dengan distribusi data yang sesuai pada set data uji pelatihan. Penting untuk dicatat bahwa semua model dilatih dari awal. Cross_entropy digunakan, parameter pencarian balok adalah 8, pengoptimal yang mereka gunakan, tentu saja, Adam. Dianggap, tentu saja, di atas awan besar TPU mereka. Apa hasilnya? Ini adalah angka yang menarik:
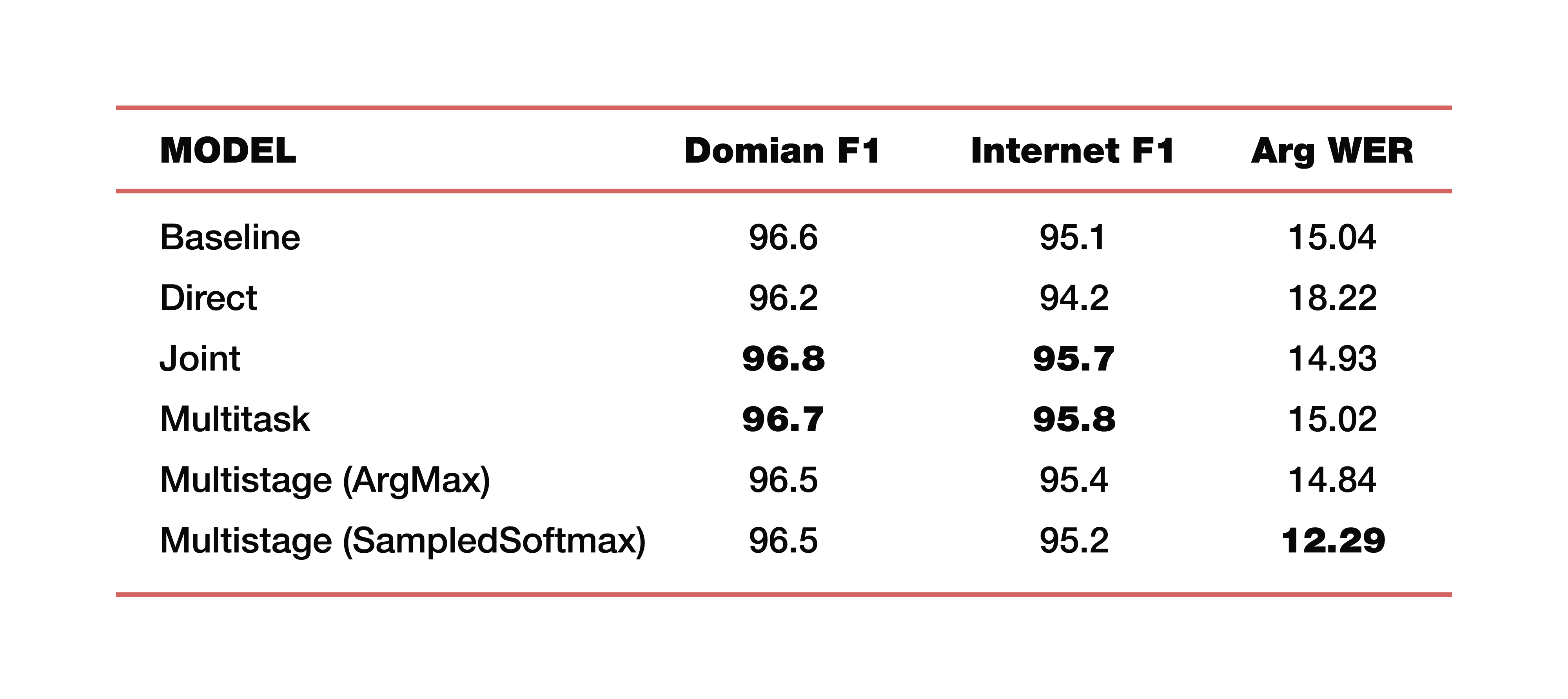
Untuk pemahaman, Baseline adalah pendekatan klasik yang terdiri dari dua komponen, seperti yang kami katakan di awal. Berikut ini adalah contoh model langsung, terhubung, multitask, dan multi-tahap.
Berapa dua model multi-tahap? Tepat di persimpangan bagian pertama dan kedua, lapisan yang berbeda digunakan. Dalam kasus pertama, ini adalah ArgMax, dalam kasus kedua, SampedSoftmax.
Apa yang layak diperhatikan? Pendekatan klasik hilang dalam ketiga metrik, yang merupakan perkiraan kolaborasi langsung kedua komponen ini. Ya, kami tidak tertarik pada seberapa baik transkripsi dilakukan di sana, kami hanya tertarik pada seberapa baik elemen yang memprediksi struktur semantik bekerja. Ini dievaluasi oleh tiga metrik: F1 - menurut topik, F1 - dengan niat dan metrik ArgWer, yang dipertimbangkan oleh argumen entitas. F1 dianggap sebagai rata-rata tertimbang antara akurasi dan kelengkapan. Artinya, standarnya adalah 100. ArgWer, sebaliknya, tidak berhasil, itu adalah kesalahan, yaitu, di sini standarnya adalah 0.
Perlu dicatat bahwa model gabungan dan multi-tugas kami benar-benar mengungguli semua model klasifikasi untuk topik dan niat. Dan modelnya, yang multi-stage, memiliki peningkatan total ArgWer yang sangat besar. Mengapa ini penting? Karena dalam tugas yang terkait dengan memahami percakapan sehari-hari, tindakan terakhir yang akan dilakukan dalam komponen yang bertanggung jawab untuk logika bisnis adalah penting. Ini tidak secara langsung bergantung pada transkripsi yang dibuat oleh ASR, tetapi pada kualitas komponen ASR dan NLU yang bekerja bersama. Oleh karena itu, perbedaan hampir tiga poin dalam metrik argWER adalah indikator yang sangat keren, yang menunjukkan keberhasilan pendekatan ini. Perlu juga dicatat bahwa semua pendekatan memiliki nilai yang sebanding dengan definisi topik dan niat.
Saya akan memberikan beberapa contoh penggunaan algoritma seperti itu untuk memahami percakapan percakapan. Google, ketika berbicara tentang tugas-tugas memahami percakapan percakapan, terutama mencatat antarmuka manusia-komputer, yaitu, ini semua jenis asisten virtual seperti Asisten Google, Apple Siri, Amazon Alexa, dan sebagainya. Sebagai contoh kedua, perlu disebutkan kumpulan tugas seperti Respon Suara Interaktif. Artinya, ini adalah kisah tertentu yang bergerak dalam otomatisasi pusat panggilan.
Jadi, kami memeriksa pendekatan dengan kemungkinan menggunakan optimasi bersama, yang membantu model fokus pada kesalahan yang lebih penting untuk SLU. Pendekatan terhadap tugas memahami bahasa lisan ini sangat menyederhanakan kerumitan keseluruhan.
Kami memiliki kesempatan untuk membuat kesimpulan logis, yaitu, untuk memperoleh semacam hasil, tanpa perlu sumber daya tambahan seperti leksikon, model bahasa, analisis, dan sebagainya (mis. Ini semua adalah faktor yang melekat dalam pendekatan klasik). Tugas ini diselesaikan "langsung".
Padahal, Anda tidak bisa berhenti di situ. Dan jika sekarang kita telah menggabungkan dua pendekatan, dua komponen dari struktur yang sama, maka kita dapat membidik lebih banyak. Gabungkan ketiga komponen dan empat - teruslah menggabungkan rantai logis ini dan "mendorong" pentingnya kesalahan ke tingkat yang lebih rendah, mengingat kekritisan yang sudah ada. Ini akan memungkinkan kami untuk meningkatkan akurasi penyelesaian masalah.