
Saya tinggal di kota yang baik. Tetapi, seperti di banyak tempat lainnya, pencarian tempat parkir selalu berubah menjadi ujian. Ruang kosong dengan cepat ditempati, dan bahkan jika Anda memiliki sendiri, akan sulit bagi teman untuk memanggil Anda, karena mereka tidak punya tempat parkir.
Jadi saya memutuskan untuk mengarahkan kamera ke luar jendela dan menggunakan pembelajaran mendalam sehingga komputer saya memberi tahu saya ketika ruang tersedia:

Ini mungkin terdengar rumit, tetapi sebenarnya menulis prototipe yang berfungsi dengan pembelajaran mendalam adalah cepat dan mudah. Semua komponen yang diperlukan sudah ada di sana - Anda hanya perlu tahu di mana menemukannya dan bagaimana menyatukannya.
Jadi mari bersenang-senang dan menulis sistem pemberitahuan parkir gratis akurat menggunakan Python dan pembelajaran mendalam
Mengurai tugas
Ketika kita memiliki tugas yang sulit yang ingin kita selesaikan menggunakan pembelajaran mesin, langkah pertama adalah memecahnya menjadi urutan tugas sederhana. Kemudian kita dapat menggunakan berbagai alat untuk menyelesaikannya. Dengan menggabungkan beberapa solusi sederhana bersama, kami mendapatkan sistem yang mampu melakukan sesuatu yang kompleks.
Inilah cara saya melanggar tugas saya:

Aliran video dari webcam yang diarahkan ke jendela memasuki input konveyor:

Melalui pipa, kami akan mengirimkan setiap frame video, satu per satu.
Langkah pertama adalah mengenali semua ruang parkir yang mungkin ada dalam bingkai. Jelas, sebelum kita dapat mencari tempat yang tidak dihuni, kita perlu memahami di bagian mana dari gambar yang ada parkir.
Kemudian pada setiap bingkai Anda perlu menemukan semua mobil. Ini akan memungkinkan kami melacak pergerakan setiap mesin dari bingkai ke bingkai.
Langkah ketiga adalah menentukan tempat mana yang ditempati oleh mesin dan mana yang tidak. Untuk melakukan ini, gabungkan hasil dari dua langkah pertama.
Akhirnya, program harus mengirimkan peringatan ketika tempat parkir menjadi gratis. Ini akan ditentukan oleh perubahan lokasi mesin antara bingkai video.
Setiap langkah ini dapat diselesaikan dengan cara yang berbeda menggunakan teknologi yang berbeda. Tidak ada satu cara yang benar atau salah untuk menyusun konveyor ini, pendekatan yang berbeda akan memiliki kelebihan dan kekurangan. Mari kita bahas setiap langkah lebih terinci.
Kami mengenali ruang parkir
Inilah yang dilihat kamera kami:

Kita perlu memindai gambar ini dan mendapatkan daftar tempat parkir:

Solusi "di dahi" adalah dengan hanya meng-hardcode lokasi semua ruang parkir secara manual alih-alih mengenalinya secara otomatis. Tetapi dalam kasus ini, jika kita memindahkan kamera atau ingin mencari tempat parkir di jalan lain, kita harus melakukan seluruh prosedur lagi. Kedengarannya begitu-begitu, jadi mari kita mencari cara otomatis untuk mengenali ruang parkir.
Atau, Anda dapat mencari meteran parkir di gambar dan menganggap bahwa ada tempat parkir di sebelah masing-masing:

Namun, dengan pendekatan ini, tidak semuanya lancar. Pertama, tidak setiap tempat parkir memiliki meteran parkir, dan memang, kami lebih tertarik menemukan tempat parkir yang tidak perlu Anda bayar. Kedua, lokasi meteran parkir tidak memberi tahu kita apa pun tentang di mana tempat parkir, tetapi hanya memungkinkan kita untuk membuat asumsi.
Gagasan lain adalah membuat model pengenalan objek yang mencari tanda tempat parkir yang tergambar di jalan:

Tapi pendekatan ini biasa saja. Pertama, di kota saya semua tanda seperti itu sangat kecil dan sulit dilihat dari jauh, sehingga akan sulit untuk mendeteksi mereka menggunakan komputer. Kedua, jalanan penuh dengan segala macam garis dan tanda lainnya. Akan sulit untuk memisahkan tanda parkir dari pembatas jalur dan penyeberangan pejalan kaki.
Ketika Anda menghadapi masalah yang pada pandangan pertama tampaknya sulit, luangkan beberapa menit untuk menemukan pendekatan lain untuk memecahkan masalah, yang akan membantu untuk menghindari beberapa masalah teknis. Apa ada tempat parkir? Ini hanya tempat di mana mobil diparkir untuk waktu yang lama. Mungkin kita tidak perlu mengenali ruang parkir sama sekali. Mengapa kita tidak mengenali saja mobil yang berdiri diam untuk waktu yang lama dan tidak menganggap mereka berdiri di tempat parkir?
Dengan kata lain, tempat parkir terletak di mana mobil berdiri untuk waktu yang lama:

Jadi, jika kita bisa mengenali mobil-mobil dan mencari tahu mana yang tidak bergerak di antara frame, kita bisa menebak di mana tempat parkir. Sesederhana itu - buka pengenalan mesin!
Kenali mobil
Mengenali mobil pada bingkai video adalah tugas pengenalan objek klasik. Ada banyak pendekatan pembelajaran mesin yang bisa kita gunakan untuk pengakuan. Berikut adalah beberapa dari mereka dalam urutan dari "sekolah lama" ke "sekolah baru":
- Anda dapat melatih detektor berdasarkan HOG (Histogram of Oriented Gradients, histogram gradien arah) dan berjalan melalui seluruh gambar untuk menemukan semua mobil. Pendekatan lama ini, yang tidak menggunakan pembelajaran mendalam, bekerja relatif cepat, tetapi tidak mengatasi dengan baik mesin yang terletak dengan cara yang berbeda.
- Anda dapat melatih detektor berbasis CNN (Convolutional Neural Network, jaringan saraf convolutional) dan berjalan melalui seluruh gambar sampai Anda menemukan semua mobil. Pendekatan ini bekerja dengan tepat, tetapi tidak seefisien itu, karena kita perlu memindai gambar beberapa kali menggunakan CNN untuk menemukan semua mesin. Dan meskipun kami dapat menemukan mesin yang terletak dengan cara yang berbeda, kami membutuhkan lebih banyak data pelatihan daripada detektor HOG.
- Anda dapat menggunakan pendekatan baru dengan pembelajaran mendalam seperti Mask R-CNN, Faster R-CNN atau YOLO, yang menggabungkan akurasi CNN dan serangkaian trik teknis yang sangat meningkatkan kecepatan pengakuan. Model seperti itu akan bekerja relatif cepat (pada GPU) jika kita memiliki banyak data untuk melatih model.
Dalam kasus umum, kita membutuhkan solusi paling sederhana, yang akan berfungsi sebagaimana mestinya dan membutuhkan paling sedikit data pelatihan. Ini tidak diperlukan untuk menjadi algoritma terbaru dan tercepat. Namun, khusus dalam kasus kami, Mask R-CNN adalah pilihan yang masuk akal, meskipun faktanya cukup baru dan cepat.
Arsitektur Mask R-CNN dirancang sedemikian rupa sehingga mengenali objek di seluruh gambar, secara efektif menghabiskan sumber daya, dan tidak menggunakan pendekatan jendela geser. Dengan kata lain, ini bekerja sangat cepat. Dengan GPU modern, kita akan dapat mengenali objek dalam video dalam resolusi tinggi dengan kecepatan beberapa frame per detik. Untuk proyek kami ini sudah cukup.
Selain itu, Mask R-CNN menyediakan banyak informasi tentang setiap objek yang dikenali. Sebagian besar algoritma pengenalan hanya mengembalikan kotak pembatas untuk setiap objek. Namun, Mask R-CNN tidak hanya akan memberi kami lokasi setiap objek, tetapi juga garis besarnya (mask):

Untuk melatih Mask R-CNN, kita membutuhkan banyak gambar objek yang ingin kita kenali. Kita bisa pergi keluar, mengambil gambar mobil dan menandainya dalam foto, yang akan membutuhkan beberapa hari kerja. Untungnya, mobil adalah salah satu objek yang sering ingin dikenali, sehingga beberapa set data publik dengan gambar mobil sudah ada.
Salah satunya adalah
dataset SOCO yang populer (kependekan dari Common Objects In Context), yang memiliki gambar beranotasi dengan topeng objek. Dataset ini berisi lebih dari 12.000 gambar dengan mesin yang telah dilabeli. Berikut adalah contoh gambar dari dataset:

Data tersebut sangat baik untuk melatih model berdasarkan Mask R-CNN.
Tapi pegang kudanya, ada berita yang lebih baik lagi! Kami bukan yang pertama yang ingin melatih model mereka menggunakan dataset COCO - banyak orang telah melakukan ini sebelum kami dan membagikan hasilnya. Karena itu, alih-alih melatih model kita, kita dapat mengambil yang sudah jadi yang sudah bisa mengenali mobil. Untuk proyek kami, kami akan menggunakan model
open-source dari Matterport.Jika kita memberikan gambar dari kamera ke input model ini, inilah yang sudah kita dapatkan “out of the box”:

Model ini tidak hanya mengenali mobil, tetapi juga benda-benda seperti lampu lalu lintas dan manusia. Lucu dia mengenali pohon itu sebagai tanaman hias.
Untuk setiap objek yang dikenali, model Mask R-CNN mengembalikan 4 hal:
- Jenis objek yang terdeteksi (integer). Model COCO yang sudah dilatih sebelumnya dapat mengenali 80 objek umum yang berbeda seperti mobil dan truk. Daftar lengkapnya dapat ditemukan di sini.
- Tingkat kepercayaan pada hasil pengakuan. Semakin tinggi angkanya, semakin kuat model percaya diri dalam pengenalan objek.
- Kotak pembatas untuk objek dalam bentuk koordinat XY piksel dalam gambar.
- "Mask" yang menunjukkan piksel mana dalam kotak pembatas adalah bagian dari objek. Menggunakan data mask, Anda dapat menemukan garis besar objek.
Di bawah ini adalah kode Python untuk mendeteksi kotak pembatas untuk mesin yang menggunakan model Mask R-CNN dan OpenCV yang sudah dilatih sebelumnya:
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path
Setelah menjalankan skrip ini, gambar dengan bingkai di sekitar setiap mesin yang terdeteksi akan muncul di layar:

Juga, koordinat masing-masing mesin akan ditampilkan di konsol:
Cars found in frame of video: Car: [492 871 551 961] Car: [450 819 509 913] Car: [411 774 470 856]
Jadi kami belajar mengenali mobil dalam gambar.
Kami mengenali ruang parkir kosong
Kami tahu koordinat piksel dari setiap mesin. Melihat melalui beberapa frame berturut-turut, kita dapat dengan mudah menentukan mobil mana yang tidak bergerak, dan berasumsi bahwa ada ruang parkir. Tetapi bagaimana memahami bahwa mobil meninggalkan tempat parkir?
Masalahnya adalah bahwa kerangka mesin sebagian tumpang tindih satu sama lain:

Oleh karena itu, jika Anda membayangkan bahwa setiap frame mewakili ruang parkir, mungkin ternyata sebagian ditempati oleh mesin, padahal sebenarnya kosong. Kita perlu menemukan cara untuk mengukur tingkat persimpangan dua objek untuk mencari hanya frame "paling kosong".
Kami akan menggunakan ukuran yang disebut Intersection Over Union (rasio area persimpangan dengan total area) atau IoU. IoU dapat ditemukan dengan menghitung jumlah piksel di mana dua objek berpotongan, dan dibagi dengan jumlah piksel yang ditempati oleh objek-objek ini:
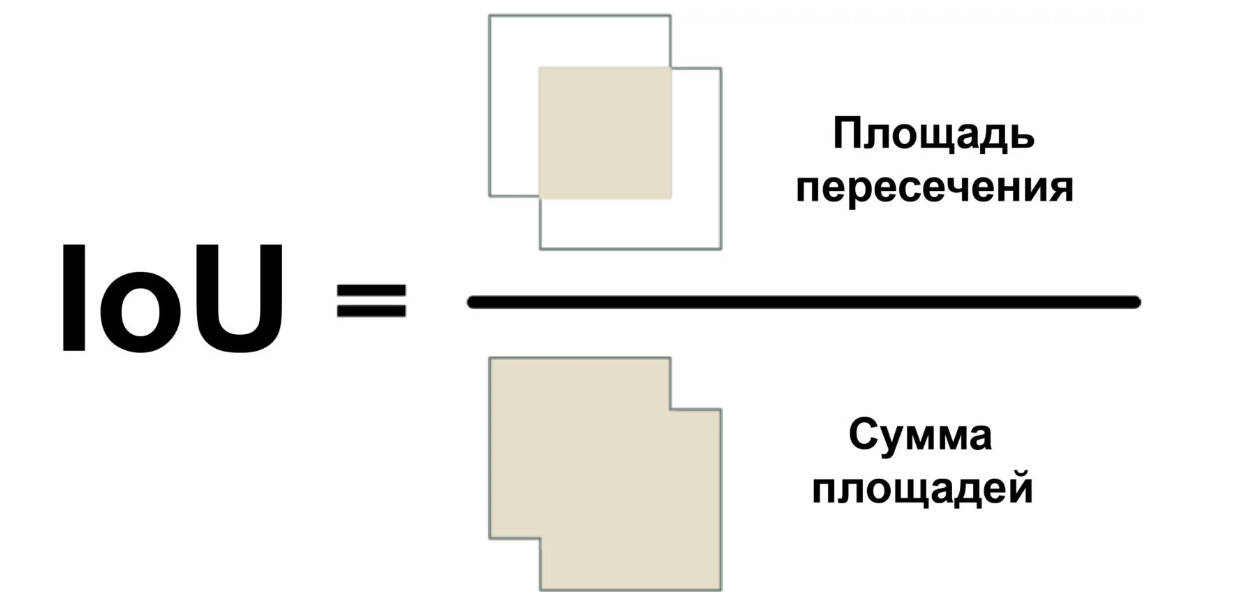
Jadi kita bisa mengerti bagaimana rangka mobil yang sangat melintang bersilangan dengan bingkai tempat parkir. Ini akan memudahkan untuk menentukan apakah parkir gratis. Jika nilai IoU rendah, seperti 0,15, maka mobil menempati sebagian kecil dari tempat parkir. Dan jika tinggi, seperti 0,6, maka ini berarti mobil mengambil sebagian besar ruang dan Anda tidak dapat parkir di sana.
Karena IoU cukup sering digunakan dalam visi komputer, sangat mungkin bahwa perpustakaan yang sesuai menerapkan ukuran ini. Di pustaka kami Mask R-CNN, ini diimplementasikan sebagai fungsi mrcnn.utils.compute_overlaps ().
Jika kami memiliki daftar kotak pembatas untuk tempat parkir, Anda dapat menambahkan tanda centang untuk keberadaan mobil dalam kerangka ini dengan menambahkan satu atau dua baris kode:
Hasilnya akan terlihat seperti ini:
[ [1. 0.07040032 0. 0.] [0.07040032 1. 0.07673165 0.] [0. 0. 0.02332112 0.] ]
Dalam array dua dimensi ini, setiap baris mencerminkan satu bingkai ruang parkir. Dan setiap kolom menunjukkan seberapa kuat masing-masing tempat bersinggungan dengan salah satu mesin yang terdeteksi. Hasil 1,0 berarti bahwa seluruh tempat benar-benar ditempati oleh mobil, dan nilai rendah seperti 0,02 menunjukkan bahwa mobil telah naik sedikit ke tempat, tetapi Anda masih dapat parkir di atasnya.
Untuk menemukan tempat kosong, Anda hanya perlu memeriksa setiap baris dalam larik ini. Jika semua angka mendekati nol, maka kemungkinan besar tempat itu gratis!
Namun, perlu diingat bahwa pengenalan objek tidak selalu bekerja dengan sempurna dengan video waktu-nyata. Meskipun model berdasarkan Mask R-CNN cukup akurat, dari waktu ke waktu mungkin kehilangan satu atau dua mobil dalam satu frame video. Oleh karena itu, sebelum menyatakan bahwa tempat itu gratis, Anda harus memastikan bahwa tempat itu tetap demikian untuk 5-10 frame video berikutnya. Dengan cara ini kita dapat menghindari situasi ketika sistem secara keliru menandai tempat kosong karena kesalahan dalam satu bingkai video. Segera setelah kami memastikan bahwa tempat itu tetap gratis untuk beberapa bingkai, Anda dapat mengirim pesan!
Kirim SMS
Bagian terakhir dari conveyor kami adalah mengirimkan notifikasi SMS ketika tempat parkir gratis muncul.
Mengirim pesan dari Python sangat mudah jika Anda menggunakan Twilio. Twilio adalah API populer yang memungkinkan Anda mengirim SMS dari hampir semua bahasa pemrograman hanya dengan beberapa baris kode. Tentu saja, jika Anda lebih suka layanan yang berbeda, maka Anda dapat menggunakannya. Saya tidak ada hubungannya dengan Twilio, itu hanya hal pertama yang terlintas dalam pikiran.
Untuk menggunakan Twilio, daftar
akun percobaan , buat nomor telepon Twilio, dan dapatkan informasi otentikasi akun Anda. Kemudian instal pustaka klien:
$ pip3 install twilio
Setelah itu, gunakan kode berikut untuk mengirim pesan:
from twilio.rest import Client
Untuk menambahkan kemampuan mengirim pesan ke skrip kami, cukup salin kode ini di sana. Namun, Anda perlu memastikan bahwa pesan tidak dikirim pada setiap frame, di mana Anda dapat melihat ruang kosong. Oleh karena itu, kami akan memiliki bendera yang dalam keadaan terpasang tidak akan mengizinkan pengiriman pesan untuk beberapa waktu atau hingga tempat lain dikosongkan.
Menyatukan semuanya
import numpy as np import cv2 import mrcnn.config import mrcnn.utils from mrcnn.model import MaskRCNN from pathlib import Path from twilio.rest import Client
Untuk menjalankan kode itu, Anda harus menginstal Python 3.6+,
Matterport Mask R-CNN, dan
OpenCV terlebih dahulu .
Saya secara khusus menulis kode sesederhana mungkin. Misalnya, jika dia melihat mobil di bingkai pertama, dia menyimpulkan bahwa mereka semua diparkir. Cobalah bereksperimen dengannya dan lihat apakah Anda dapat meningkatkan keandalannya.
Hanya dengan mengubah pengidentifikasi objek yang model cari, Anda dapat mengubah kode menjadi sesuatu yang sama sekali berbeda. Misalnya, bayangkan Anda bekerja di resor ski. Setelah melakukan beberapa perubahan, Anda dapat mengubah skrip ini menjadi sistem yang secara otomatis mengenali papan luncur salju dari lintasan dan merekam video dengan lompatan keren. Atau, jika Anda bekerja di cagar alam, Anda dapat membuat sistem yang menghitung zebra. Anda hanya dibatasi oleh imajinasi Anda.
Lebih banyak artikel seperti itu dapat dibaca di saluran telegram
Neuron (@neurondata)
Tautan terjemahan alternatif:
tproger.ru/translations/parking-searching/Semua pengetahuan Eksperimen!