AI hari ini secara teknis "lemah" - namun, itu kompleks dan secara signifikan dapat mempengaruhi masyarakat
 Anda tidak perlu menjadi Cyrus Dully untuk mengetahui seberapa menakutkan kecerdasan cerdas bisa menjadi [aktor Amerika yang berperan sebagai astronot Dave Bowman dalam film "Space Odyssey 2001" / approx. perev.]
Anda tidak perlu menjadi Cyrus Dully untuk mengetahui seberapa menakutkan kecerdasan cerdas bisa menjadi [aktor Amerika yang berperan sebagai astronot Dave Bowman dalam film "Space Odyssey 2001" / approx. perev.]AI, atau kecerdasan buatan, sekarang menjadi salah satu bidang pengetahuan terpenting. Masalah “tidak terpecahkan” sedang diselesaikan, miliaran dolar diinvestasikan, dan Microsoft bahkan
mempekerjakan Common untuk memberi tahu kami dalam ketenangan puitis, betapa indahnya ini - AI. Benar juga.
Dan, seperti halnya teknologi baru mana pun, mungkin sulit untuk melewati semua hype ini. Saya telah melakukan penelitian di bidang drone dan AI selama bertahun-tahun, tetapi bahkan mungkin sulit bagi saya untuk mengikuti semua ini. Dalam beberapa tahun terakhir, saya menghabiskan banyak waktu mencari jawaban untuk pertanyaan paling sederhana seperti:
- Apa yang orang maksud dengan mengatakan "AI"?
- Apa perbedaan antara AI, pembelajaran mesin, dan pembelajaran mendalam?
- Apa yang hebat dari pembelajaran mendalam?
- Mana tugas-tugas sulit sebelumnya yang sekarang mudah diselesaikan, dan apa yang masih sulit?
Saya tahu tidak ada yang tertarik pada hal-hal seperti itu. Karena itu, jika Anda tertarik pada apa yang semua antusiasme tentang AI ini terhubung pada level paling sederhana, inilah saatnya untuk melihat ke belakang layar. Jika Anda seorang ahli AI dan membaca laporan dari Conference on Neurological Information Processing (NIPS) untuk bersenang-senang, artikel itu tidak akan menjadi sesuatu yang baru bagi Anda - namun, kami mengharapkan klarifikasi dan koreksi dari Anda dalam komentar.
Apa itu AI?
Ada lelucon lama dalam ilmu komputer: apa perbedaan antara AI dan otomatisasi? Otomasi adalah sesuatu yang dapat dilakukan menggunakan komputer, dan AI adalah sesuatu yang kami ingin dapat lakukan. Segera setelah kita belajar bagaimana melakukan sesuatu, itu bergerak dari bidang AI ke kategori otomatisasi.
Lelucon ini berlaku hari ini, karena AI tidak didefinisikan dengan cukup jelas. Inteligensi buatan bukanlah istilah teknis. Jika Anda naik ke Wikipedia, dikatakan bahwa AI adalah "kecerdasan yang ditunjukkan oleh mesin, berbeda dengan kecerdasan alami yang ditunjukkan oleh manusia dan hewan lainnya." Anda tidak bisa mengatakan kurang jelas.
Secara umum, ada dua jenis AI: kuat dan lemah. Kebanyakan orang membayangkan AI yang kuat ketika mereka mendengar tentang AI - itu semacam kecerdasan mahatahu seperti Tuhan seperti Skynet atau Hal 9000, yang mampu menalar dan dapat dibandingkan dengan manusia, sambil melampaui kemampuannya.
AI yang lemah adalah algoritma yang sangat terspesialisasi yang dirancang untuk menjawab pertanyaan-pertanyaan berguna yang spesifik di area yang didefinisikan secara sempit. Misalnya, program catur yang sangat bagus termasuk dalam kategori ini. Hal yang sama dapat dikatakan tentang perangkat lunak yang secara akurat menyesuaikan pembayaran asuransi. Di bidangnya, AI semacam itu mencapai hasil yang mengesankan, tetapi secara umum mereka sangat terbatas.
Dengan pengecualian dari opium Hollywood, hari ini kita bahkan belum mendekati AI yang kuat. Sejauh ini, AI apa pun lemah, dan sebagian besar peneliti di bidang ini sepakat bahwa teknik yang kami ciptakan untuk membuat AI sangat lemah tidak mungkin membawa kami lebih dekat untuk menciptakan AI yang kuat.
Jadi AI hari ini lebih merupakan istilah pemasaran daripada istilah teknis. Alasan perusahaan mengiklankan AI mereka alih-alih otomatisasi adalah karena mereka ingin memperkenalkan Hollywood AI ke dalam pikiran publik. Namun, ini tidak terlalu buruk. Jika ini tidak diambil terlalu ketat, perusahaan hanya ingin mengatakan bahwa, meskipun kami masih sangat jauh dari AI yang kuat, AI yang lemah saat ini jauh lebih mampu daripada yang ada beberapa tahun yang lalu.
Dan jika Anda mengalihkan perhatian dari pemasaran, maka demikianlah adanya. Di bidang-bidang tertentu, kemampuan mesin telah meningkat secara dramatis, dan terutama berkat dua frase lagi yang sekarang modis: pembelajaran mesin dan pembelajaran yang mendalam.
 Dipotret dari video pendek dari para insinyur Facebook yang menunjukkan bagaimana AI waktu-nyata mengenali kucing (tugas yang juga dikenal sebagai cawan suci Internet)
Dipotret dari video pendek dari para insinyur Facebook yang menunjukkan bagaimana AI waktu-nyata mengenali kucing (tugas yang juga dikenal sebagai cawan suci Internet)Pembelajaran mesin
MO adalah cara khusus untuk menciptakan kecerdasan mesin. Misalkan Anda ingin meluncurkan roket, dan memprediksi ke mana ia akan pergi. Secara umum, ini tidak terlalu sulit: gravitasi dipelajari dengan cukup baik, Anda dapat menuliskan persamaan dan menghitung kemana ia akan pergi, berdasarkan beberapa variabel - seperti kecepatan dan posisi awal.
Namun, pendekatan ini menjadi canggung jika kita beralih ke area yang aturannya tidak begitu dikenal dan jelas. Misalkan Anda ingin komputer memberi tahu Anda jika ada kucing pada beberapa gambar. Bagaimana Anda akan menuliskan aturan yang menggambarkan tampilan di semua sudut pandang yang memungkinkan pada semua kemungkinan kombinasi kumis dan telinga?
Saat ini, pendekatan MO sudah dikenal: alih-alih mencoba menuliskan semua aturan, Anda membuat sistem yang dapat secara independen menurunkan seperangkat aturan internal setelah mempelajari sejumlah besar contoh. Alih-alih menggambarkan kucing, Anda cukup menunjukkan kepada AI Anda sekelompok foto kucing, dan biarkan dia mengerti sendiri apa itu kucing dan apa yang bukan.
Dan hari ini adalah pendekatan yang sempurna. Sistem belajar mandiri berdasarkan data dapat ditingkatkan hanya dengan menambahkan data. Dan jika spesies kita mampu melakukan sesuatu dengan sangat baik, itu adalah untuk menghasilkan, menyimpan, dan mengelola data. Ingin belajar cara mengenali kucing lebih baik? Internet menghasilkan jutaan contoh saat ini juga.
Aliran data yang terus meningkat adalah salah satu alasan untuk pertumbuhan eksplosif dari algoritma MO dalam beberapa waktu terakhir. Alasan lain terkait dengan penggunaan data ini.
Selain data, ada dua masalah lagi yang terkait dengan ini untuk Wilayah Moskow:
- Bagaimana saya mengingat apa yang telah saya pelajari? Bagaimana cara menyimpan dan menyajikan di komputer komunikasi dan aturan yang saya simpulkan dari data?
- Bagaimana saya belajar? Bagaimana mengubah representasi yang disimpan dalam menanggapi contoh baru, dan meningkatkan?
Dengan kata lain, apa sebenarnya yang dilatih berdasarkan semua data ini?
Di MO, representasi komputasional dari pelatihan yang kami simpan adalah sebuah model. Jenis model yang digunakan sangat penting: ia menentukan bagaimana AI Anda belajar, data apa yang dapat dipelajari, dan pertanyaan apa yang dapat Anda tanyakan.
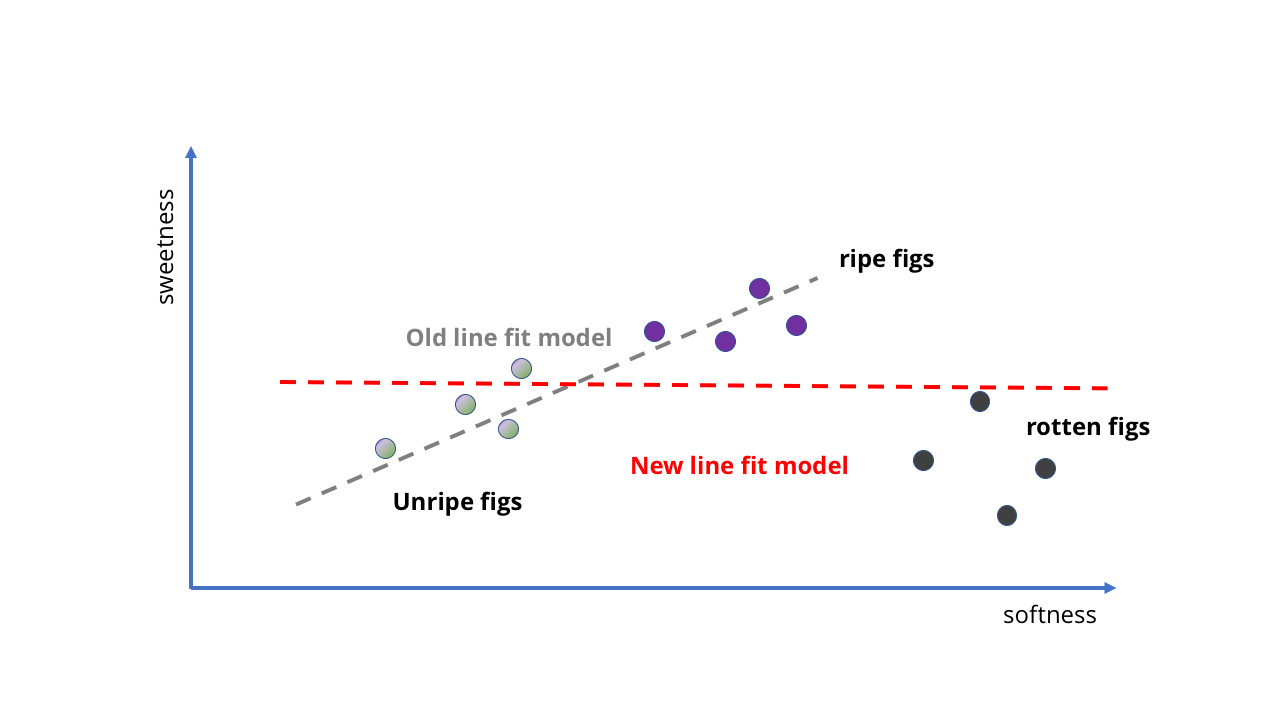
Mari kita lihat contoh yang sangat sederhana. Misalkan kita membeli buah ara di toko grosir dan ingin membuat AI dengan MO yang akan memberi tahu kita jika sudah matang. Ini harus mudah dilakukan, karena dalam kasus buah ara, semakin lembut semakin manis.
Kita dapat mengambil beberapa sampel buah ara yang sudah matang dan belum matang, lihat betapa manisnya mereka, dan kemudian letakkan di grafik dan sesuaikan garis lurus untuk itu. Baris ini akan menjadi model kami.
 Embrio AI dalam bentuk "yang lebih lembut yang lebih manis"
Embrio AI dalam bentuk "yang lebih lembut yang lebih manis" Dengan penambahan data baru, tugas menjadi lebih rumit.
Dengan penambahan data baru, tugas menjadi lebih rumit.Lihatlah! Garis lurus secara implisit mengikuti gagasan bahwa "semakin lembut mereka, semakin manis", dan kami bahkan tidak perlu menuliskan apa pun. Janin AI kami tidak tahu apa-apa tentang kandungan gula atau buah yang masak, tetapi bisa memperkirakan manisnya buah dengan meremasnya.
Bagaimana cara melatih model untuk membuatnya lebih baik? Kami dapat mengumpulkan lebih banyak sampel dan menggambar garis lurus lainnya untuk mendapatkan prediksi yang lebih akurat (seperti pada gambar kedua di atas). Namun, masalah segera menjadi jelas. Sejauh ini, kami telah melatih ara AI kami tentang buah berkualitas - bagaimana jika kami mengambil data dari kebun? Tiba-tiba, kita tidak hanya telah masak, tetapi juga buah-buah busuk. Mereka sangat lembut, tetapi jelas tidak cocok untuk dimakan.
Apa yang kita lakukan Nah, karena ini adalah model MO, kita bisa memberinya lebih banyak data, kan?
Seperti yang ditunjukkan gambar pertama di bawah ini, dalam hal ini kita akan mendapatkan hasil yang sama sekali tidak berarti. Garis ini sama sekali tidak cocok untuk menggambarkan apa yang terjadi ketika buah menjadi terlalu matang. Model kami tidak lagi cocok dengan struktur data.
Sebaliknya, kita harus mengubahnya, dan menggunakan model yang lebih baik dan lebih kompleks - mungkin parabola, atau yang serupa. Perubahan ini menyulitkan pembelajaran karena kurva menggambar membutuhkan matematika yang lebih canggih daripada menggambar garis lurus.
 Oke, mungkin gagasan menggunakan garis lurus untuk AI kompleks tidak terlalu berhasil
Oke, mungkin gagasan menggunakan garis lurus untuk AI kompleks tidak terlalu berhasil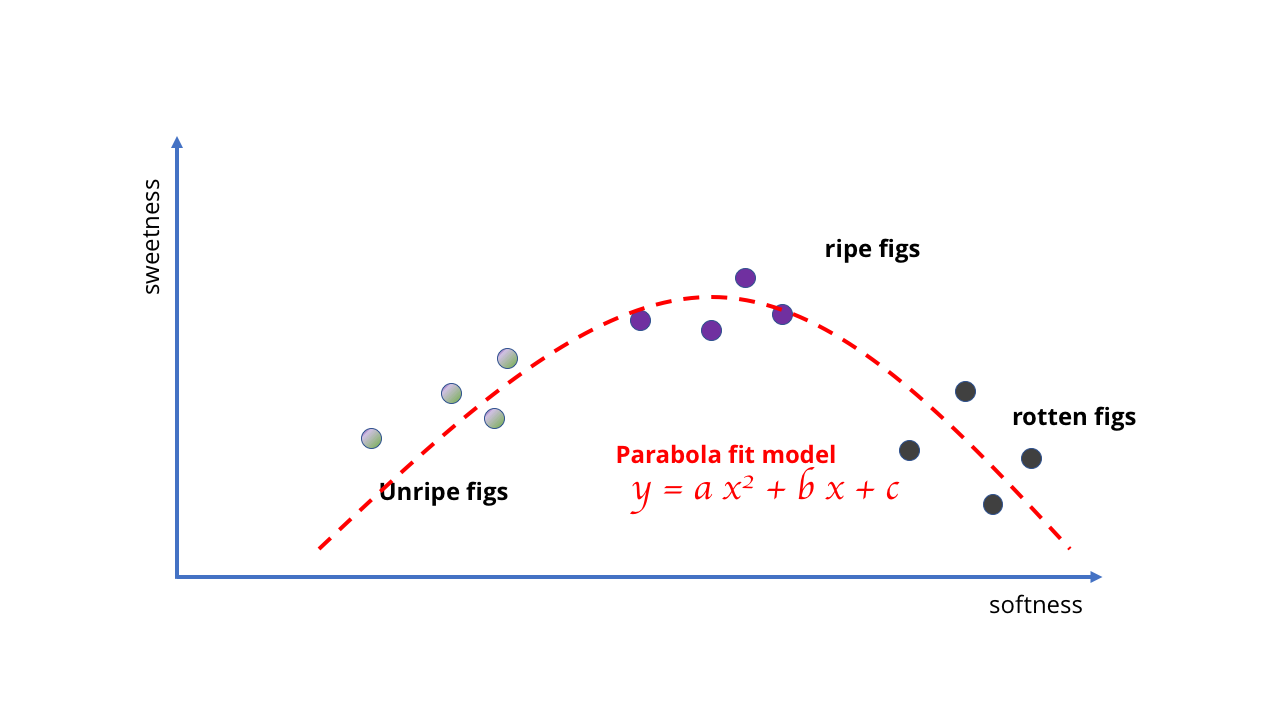 Diperlukan matematika yang lebih rumit
Diperlukan matematika yang lebih rumitContohnya agak bodoh, tetapi itu menunjukkan bahwa pilihan model menentukan kemungkinan belajar. Dalam kasus buah ara, datanya sederhana, dan modelnya bisa sederhana. Tetapi jika Anda mencoba mempelajari sesuatu yang lebih kompleks, diperlukan model yang lebih kompleks. Sama seperti tidak ada jumlah data yang membuat model linier mencerminkan perilaku buah busuk, tidak mungkin untuk memilih kurva sederhana yang sesuai dengan banyak gambar untuk membuat algoritma visi komputer.
Oleh karena itu, kesulitan untuk MO adalah membuat dan memilih model yang tepat untuk tugas yang sesuai. Kami membutuhkan model yang cukup rumit untuk menggambarkan hubungan dan struktur yang sangat kompleks, tetapi cukup sederhana sehingga Anda dapat bekerja dengannya dan melatihnya. Jadi, meskipun Internet, telepon pintar, dan sebagainya telah menciptakan banyak sekali data untuk dipelajari, kita masih membutuhkan model yang tepat untuk memanfaatkan data ini.
Di sinilah pembelajaran yang mendalam ikut bermain.

Pembelajaran yang mendalam
Deep learning adalah pembelajaran mesin yang menggunakan jenis model tertentu: deep neural networks.
Jaringan saraf adalah jenis model MO yang menggunakan struktur yang menyerupai neuron di otak untuk perhitungan dan prediksi. Neuron dalam jaringan saraf disusun dalam lapisan: setiap lapisan melakukan satu set perhitungan sederhana dan meneruskan jawaban ke yang berikutnya.
Model berlapis memungkinkan untuk perhitungan yang lebih kompleks. Jaringan sederhana dengan sejumlah kecil lapisan neuron sudah cukup untuk mereproduksi garis lurus atau parabola yang kami gunakan di atas. Deep neural networks adalah jaringan saraf dengan sejumlah besar lapisan, dengan puluhan, atau bahkan ratusan; karenanya nama mereka. Dengan begitu banyak lapisan, Anda dapat membuat model yang sangat kuat.
Peluang ini adalah salah satu alasan utama untuk popularitas besar jaringan syaraf yang dalam belakangan ini. Mereka dapat mempelajari berbagai hal rumit tanpa memaksa peneliti manusia untuk mendefinisikan aturan apa pun, dan ini memungkinkan kami untuk membuat algoritma yang dapat memecahkan berbagai masalah yang tidak dapat didekati oleh komputer sebelumnya.
Namun, aspek lain berkontribusi pada keberhasilan jaringan saraf: pelatihan.
"Memori" model adalah seperangkat parameter numerik yang menentukan bagaimana ia memberikan jawaban atas pertanyaan yang diajukan. Melatih model berarti menyempurnakan parameter ini sehingga model memberikan jawaban terbaik.
Dalam model kami dengan buah ara, kami mencari persamaan garis. Ini adalah tugas regresi sederhana, dan ada rumus yang akan memberi Anda jawaban dalam satu langkah.
 Jaringan saraf sederhana dan jaringan saraf dalam
Jaringan saraf sederhana dan jaringan saraf dalamDengan model yang lebih kompleks, segalanya tidak sesederhana itu. Garis lurus dan parabola dapat dengan mudah diwakili oleh beberapa angka, tetapi jaringan saraf yang dalam dapat memiliki jutaan parameter, dan kumpulan data untuk pelatihannya juga dapat terdiri dari jutaan contoh. Solusi analitis dalam satu langkah tidak ada.
Untungnya, ada satu trik aneh: Anda bisa mulai dengan jaringan saraf yang buruk, dan kemudian memperbaikinya dengan tweak bertahap.
Mempelajari model MO dengan cara ini mirip dengan menguji seorang siswa menggunakan tes. Setiap kali kami mendapatkan penilaian dengan membandingkan jawaban apa yang seharusnya ada dalam pendapat model dengan jawaban "benar" dalam data pelatihan. Kemudian kami melakukan peningkatan dan menjalankan tes lagi.
Bagaimana kita tahu parameter mana yang harus disesuaikan, dan berapa banyak? Jaringan saraf memiliki fitur yang sangat keren ketika untuk banyak jenis pelatihan Anda tidak hanya dapat memperoleh penilaian dalam ujian, tetapi juga menghitung berapa banyak itu akan berubah sebagai tanggapan terhadap perubahan pada setiap parameter. Dalam istilah matematika, estimasi adalah fungsi nilai, dan untuk sebagian besar fungsi ini kita dapat dengan mudah menghitung gradien fungsi ini sehubungan dengan ruang parameter.
Sekarang kita tahu persis ke arah mana kita perlu menyesuaikan parameter untuk meningkatkan skor, dan kita dapat menyesuaikan jaringan dengan langkah-langkah berturut-turut di semua "arah" yang terbaik dan terbaik, sampai Anda mencapai titik di mana tidak ada yang dapat ditingkatkan. Ini sering disebut sebagai memanjat bukit, karena itu benar-benar seperti naik bukit: jika Anda terus-menerus naik, Anda akan berakhir di atas.
 Pernahkah kamu melihat Atas!
Pernahkah kamu melihat Atas!Berkat ini, mudah untuk meningkatkan jaringan saraf. Jika jaringan Anda memiliki struktur yang baik, setelah menerima data baru, Anda tidak perlu memulai dari awal. Anda dapat mulai dengan parameter yang tersedia, dan belajar kembali dari data baru. Jaringan Anda secara bertahap akan membaik. AI yang paling menonjol saat ini - mulai dari pengenalan kucing di Facebook hingga teknologi yang Amazon (mungkin) gunakan di toko tanpa penjual - dibuat berdasarkan fakta sederhana ini.
Ini adalah kunci untuk satu alasan lagi mengapa pertahanan sipil menyebar begitu cepat dan luas: mendaki bukit memungkinkan Anda mengambil satu jaringan saraf yang terlatih untuk beberapa tugas dan melatihnya untuk melakukan yang lain, tetapi serupa. Jika Anda telah melatih AI untuk mengenali kucing dengan baik, jaringan ini dapat digunakan untuk melatih AI yang mengenali anjing atau jerapah tanpa harus memulai dari awal. Mulailah dengan AI untuk kucing, evaluasi dengan kualitas pengenalan anjing, dan kemudian mendaki bukit, meningkatkan jaringan!
Oleh karena itu, dalam 5-6 tahun terakhir, telah terjadi peningkatan tajam dalam kemampuan AI. Beberapa kepingan puzzle muncul bersamaan dengan cara sinergis: Internet menghasilkan sejumlah besar data untuk dipelajari. Komputasi, terutama komputasi paralel pada GPU, memungkinkan untuk memproses set besar ini. Akhirnya, jaringan saraf yang mendalam memungkinkan untuk mengambil keuntungan dari kit ini dan membuat model MO yang sangat kuat.
Dan semua ini berarti bahwa beberapa hal yang sebelumnya sangat sulit sekarang sangat mudah dilakukan.
Dan apa yang bisa kita lakukan sekarang? Pengenalan pola
Mungkin yang terdalam (maaf untuk permainan kata-kata) dan dampak paling awal dari pembelajaran mendalam di bidang visi komputer - khususnya, pada pengenalan objek dalam foto. Beberapa tahun yang lalu, komik xkcd ini menggambarkan dengan sempurna ujung tombak ilmu komputer:

Saat ini, pengenalan burung dan bahkan jenis burung tertentu adalah tugas sepele yang dapat diselesaikan oleh siswa sekolah menengah yang termotivasi dengan benar. Apa yang berubah?
Gagasan pengenalan visual objek mudah untuk dijelaskan, tetapi sulit untuk diterapkan: objek kompleks terdiri dari set yang lebih sederhana, yang pada gilirannya terdiri dari bentuk dan garis yang lebih sederhana. Wajah terdiri dari mata, hidung dan mulut, dan itu terdiri dari lingkaran dan garis, dan sebagainya.
Oleh karena itu, pengenalan wajah menjadi masalah pola pengenalan di mana mata dan mulut berada, yang mungkin memerlukan pengenalan bentuk mata dan mulut dari garis dan lingkaran.
Pola-pola ini disebut fitur, dan sebelum pembelajaran mendalam untuk pengakuan, perlu untuk menggambarkan semua fitur secara manual dan memprogram komputer untuk menemukannya. Sebagai contoh, ada algoritma pengenalan wajah
Viola-Jones yang terkenal, berdasarkan fakta bahwa alis dan hidung biasanya lebih ringan daripada rongga mata, sehingga mereka membentuk bentuk-T yang cerah dengan dua titik gelap. Algoritma, pada kenyataannya, sedang mencari bentuk-T yang serupa.
Metode Viola-Jones bekerja dengan baik dan sangat cepat, dan berfungsi sebagai dasar untuk pengenalan wajah di kamera murah, dll. Tetapi, tentu saja, tidak setiap objek yang perlu Anda kenali cocok untuk penyederhanaan seperti itu, dan orang-orang muncul dengan pola yang semakin kompleks dan tingkat rendah. Agar algoritma dapat bekerja dengan benar, diperlukan tim dokter sains, mereka sangat sensitif dan rentan terhadap kegagalan.
Terobosan besar terjadi berkat pertahanan sipil, dan khususnya untuk jenis jaringan saraf tertentu yang disebut jaringan saraf convolutional. Jaringan saraf convolutional, SNS adalah jaringan yang dalam dengan struktur tertentu, terinspirasi oleh struktur korteks visual otak mamalia. Struktur seperti itu memungkinkan SNA untuk secara mandiri mempelajari hierarki garis dan pola untuk mengenali objek alih-alih menunggu dokter sains menghabiskan waktu bertahun-tahun untuk meneliti fitur mana yang paling cocok untuk ini. Sebagai contoh, SNA, yang dilatih pada wajah, akan mempelajari representasi internal sendiri dari garis dan lingkaran yang terbentuk di mata, telinga dan hidung, dan sebagainya.
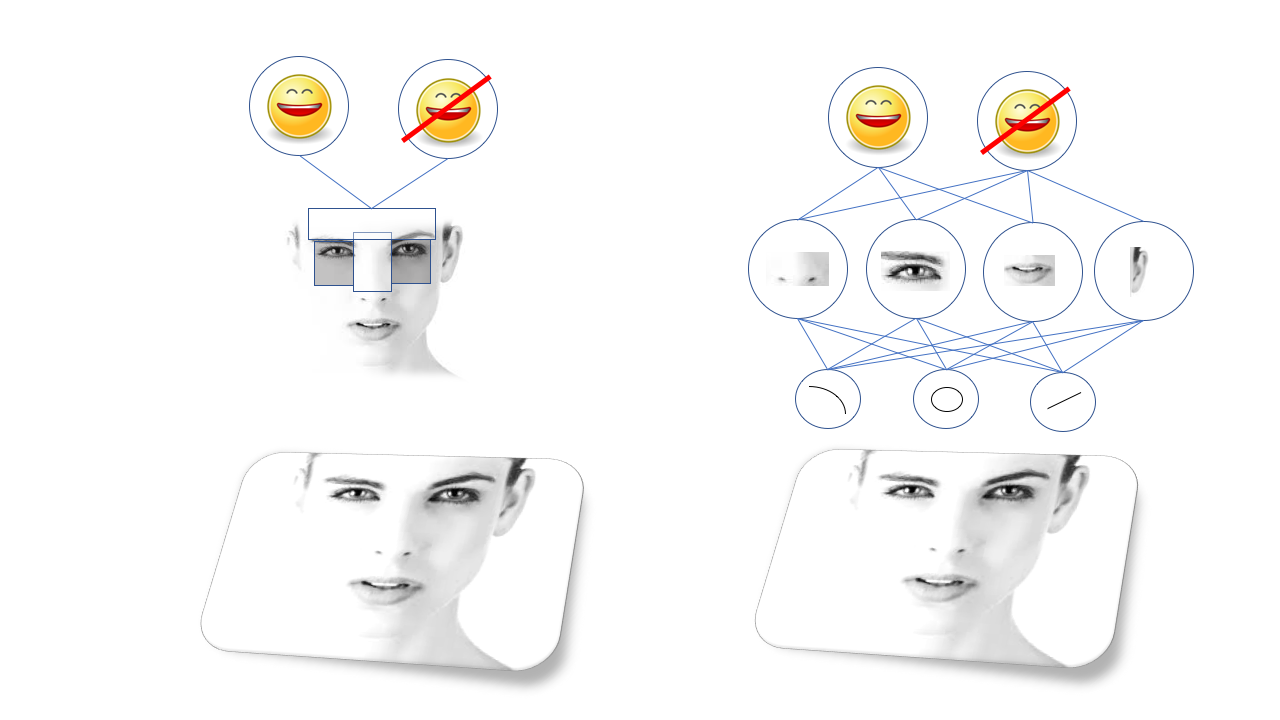 Algoritma visual lama (metode Viola-Jones, kiri) mengandalkan fitur yang dipilih secara manual, dan jaringan saraf yang dalam (kanan) pada hierarki mereka sendiri dari fitur yang lebih kompleks yang terdiri dari yang lebih sederhana
Algoritma visual lama (metode Viola-Jones, kiri) mengandalkan fitur yang dipilih secara manual, dan jaringan saraf yang dalam (kanan) pada hierarki mereka sendiri dari fitur yang lebih kompleks yang terdiri dari yang lebih sederhanaSNA luar biasa bagus untuk penglihatan komputer, dan tak lama kemudian para peneliti dapat melatih mereka untuk melakukan semua jenis tugas pengenalan visual, dari menemukan kucing di foto hingga mengidentifikasi pejalan kaki yang masuk ke kamera robomobile.
Ini semua luar biasa, tetapi ada alasan lain untuk penyebaran SNA yang cepat dan luas - ini adalah cara mudah mereka beradaptasi. Ingat memanjat bukit?
Jika siswa sekolah menengah kita ingin mengenali burung tertentu, dia dapat mengambil salah satu dari banyak jaringan visual dengan kode terbuka, dan melatihnya pada kumpulan datanya sendiri, bahkan tanpa memahami bagaimana matematika yang mendasari kerjanya.Secara alami, ini dapat diperluas lebih jauh.Siapa disana? (pengenalan wajah)
Misalkan Anda ingin melatih jaringan yang mengenali tidak hanya wajah, tetapi satu wajah tertentu. Anda bisa melatih jaringan untuk mengenali orang tertentu, lalu orang lain, dan sebagainya. Namun, perlu waktu untuk melatih jaringan, dan itu berarti bahwa untuk setiap orang baru, perlu untuk melatih ulang jaringan. Tidak, sungguhSebaliknya, kita bisa mulai dengan jaringan yang terlatih untuk mengenali wajah secara umum. Neuronnya dikonfigurasikan untuk mengenali semua struktur wajah: mata, telinga, mulut, dan sebagainya. Kemudian Anda hanya mengubah hasilnya: alih-alih memaksanya mengenali wajah-wajah tertentu, Anda memerintahkannya untuk memberikan deskripsi wajah dalam bentuk ratusan angka yang menggambarkan lengkungan hidung atau bentuk mata, dan sebagainya. Jaringan dapat melakukan ini karena sudah "tahu" komponen apa yang terdiri dari wajah.Tentu saja, Anda tidak mendefinisikan semua ini secara langsung. Alih-alih, Anda melatih jaringan dengan menunjukkan serangkaian wajah, lalu membandingkan hasilnya. Anda juga mengajarinya sehingga dia memberikan deskripsi yang mirip satu sama lain dari orang yang sama, dan sangat berbeda dari masing-masing deskripsi orang yang berbeda. Secara matematis, Anda melatih jaringan untuk membangun korespondensi dengan gambar wajah suatu titik dalam ruang fitur, di mana jarak Cartesian antara titik dapat digunakan untuk menentukan kesamaan mereka. Mengubah jaringan saraf dari pengenalan wajah (di sebelah kiri) ke deskripsi wajah (di sebelah kanan) hanya memerlukan mengubah format data keluaran, tanpa mengubah basisnya.
Mengubah jaringan saraf dari pengenalan wajah (di sebelah kiri) ke deskripsi wajah (di sebelah kanan) hanya memerlukan mengubah format data keluaran, tanpa mengubah basisnya. Sekarang Anda dapat mengenali wajah dengan membandingkan deskripsi dari masing-masing wajah yang dibuat oleh jaringan saraf.Setelah melatih jaringan, Anda dapat dengan mudah mengenali wajah. Anda mengambil orang asli dan mendapatkan deskripsinya. Kemudian ambil wajah baru dan bandingkan deskripsi yang disediakan oleh jaringan dengan asli Anda. Jika mereka cukup dekat, Anda mengatakan bahwa itu adalah satu dan orang yang sama. Dan sekarang Anda telah pindah dari jaringan yang mampu mengenali satu wajah ke apa yang dapat digunakan untuk mengenali wajah apa pun!Fleksibilitas struktural ini adalah alasan lain untuk kegunaan jaringan saraf yang dalam. Sejumlah besar berbagai model MO untuk visi komputer telah dikembangkan, dan meskipun mereka berkembang ke arah yang sangat berbeda, struktur dasar banyak dari mereka didasarkan pada SNA awal seperti Alexnet dan Resnet.Saya bahkan mendengar cerita tentang orang yang menggunakan jaringan saraf visual untuk bekerja dengan data deret waktu atau pengukuran sensor. Alih-alih membuat jaringan khusus untuk menganalisis aliran data, mereka melatih jaringan saraf open-source yang dirancang untuk visi komputer untuk benar-benar melihat bentuk grafik garis.Fleksibilitas semacam itu adalah hal yang baik, tetapi tidak terbatas. Untuk mengatasi beberapa masalah lain, Anda perlu menggunakan jenis jaringan lain.
Sekarang Anda dapat mengenali wajah dengan membandingkan deskripsi dari masing-masing wajah yang dibuat oleh jaringan saraf.Setelah melatih jaringan, Anda dapat dengan mudah mengenali wajah. Anda mengambil orang asli dan mendapatkan deskripsinya. Kemudian ambil wajah baru dan bandingkan deskripsi yang disediakan oleh jaringan dengan asli Anda. Jika mereka cukup dekat, Anda mengatakan bahwa itu adalah satu dan orang yang sama. Dan sekarang Anda telah pindah dari jaringan yang mampu mengenali satu wajah ke apa yang dapat digunakan untuk mengenali wajah apa pun!Fleksibilitas struktural ini adalah alasan lain untuk kegunaan jaringan saraf yang dalam. Sejumlah besar berbagai model MO untuk visi komputer telah dikembangkan, dan meskipun mereka berkembang ke arah yang sangat berbeda, struktur dasar banyak dari mereka didasarkan pada SNA awal seperti Alexnet dan Resnet.Saya bahkan mendengar cerita tentang orang yang menggunakan jaringan saraf visual untuk bekerja dengan data deret waktu atau pengukuran sensor. Alih-alih membuat jaringan khusus untuk menganalisis aliran data, mereka melatih jaringan saraf open-source yang dirancang untuk visi komputer untuk benar-benar melihat bentuk grafik garis.Fleksibilitas semacam itu adalah hal yang baik, tetapi tidak terbatas. Untuk mengatasi beberapa masalah lain, Anda perlu menggunakan jenis jaringan lain. Dan bahkan sampai pada titik ini, asisten virtual membutuhkan waktu yang sangat lama
Dan bahkan sampai pada titik ini, asisten virtual membutuhkan waktu yang sangat lamaApa yang kamu katakan (Pengenalan Bicara)
Katalog gambar dan visi komputer bukan satu-satunya bidang kebangkitan AI. Bidang lain di mana komputer telah berkembang sangat jauh adalah pengenalan ucapan, terutama dalam menerjemahkan ucapan ke tulisan.Ide dasar dalam pengenalan suara sangat mirip dengan prinsip visi komputer: untuk mengenali hal-hal kompleks dalam bentuk set yang lebih sederhana. Dalam hal berbicara, pengenalan kalimat dan frasa didasarkan pada pengenalan kata-kata, yang didasarkan pada pengakuan suku kata, atau, lebih tepatnya, fonem. Jadi ketika seseorang berkata "Bond, James Bond," kita sebenarnya mendengar BON + DUH + JAY + MMS + BON + DUH.Dalam visi, fitur diatur secara spasial, dan SNA memproses struktur ini. Dalam rumor, fitur-fitur ini diatur dalam waktu. Orang dapat berbicara dengan cepat atau lambat, tanpa awal dan akhir pembicaraan yang jelas. Kami membutuhkan model yang dapat memahami suara saat tiba, sebagai pribadi, alih-alih menunggu dan mencari kalimat lengkap di dalamnya. Kita tidak bisa, seperti dalam fisika, mengatakan bahwa ruang dan waktu adalah satu dan sama.Mengenali suku kata individual cukup mudah, tetapi sulit untuk diisolasi. Misalnya, "Halo," mungkin terdengar seperti "tidak, mereka" ... Jadi, untuk setiap urutan suara biasanya ada beberapa kombinasi suku kata yang diucapkan.Untuk memahami semua ini, kita perlu kesempatan untuk mempelajari urutan dalam konteks tertentu. Jika saya mendengar suara, apa yang lebih mungkin adalah orang itu berkata "halo sayang" atau "tidak, mereka rusa?" Di sini sekali lagi, pembelajaran mesin datang untuk menyelamatkan. Dengan seperangkat pola kata-kata yang diucapkan cukup besar, Anda dapat mempelajari frasa yang paling mungkin. Dan semakin banyak contoh yang Anda miliki, semakin baik hasilnya.Untuk ini, orang menggunakan jaringan saraf berulang, RNS. Dalam sebagian besar jenis jaringan saraf, seperti SNA yang terlibat dalam visi komputer, koneksi antara neuron bekerja dalam satu arah, dari input ke output (secara matematis, ini adalah grafik asiklik langsung). Dalam RNS, output neuron dapat diarahkan kembali ke neuron pada level yang sama, untuk diri mereka sendiri atau bahkan lebih jauh. Ini memungkinkan RNS untuk memiliki memori sendiri (jika Anda terbiasa dengan logika biner, maka situasi ini mirip dengan operasi pemicu).SNA bekerja untuk satu pendekatan: kami memberinya gambar, dan dia memberikan beberapa deskripsi. RNS mempertahankan ingatan internal tentang apa yang diberikan kepadanya sebelumnya, dan memberikan jawaban berdasarkan apa yang telah dilihatnya, ditambah apa yang dilihatnya sekarang.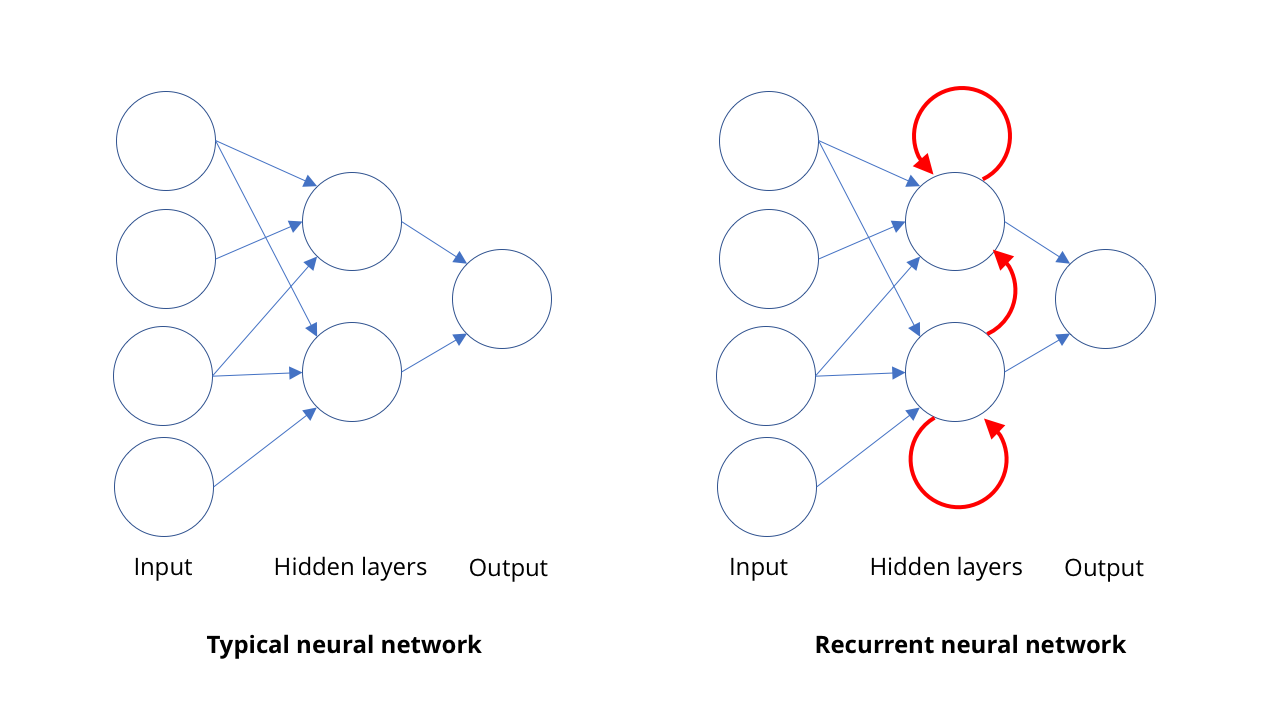 Properti memori ini dalam RNS memungkinkan mereka tidak hanya untuk "mendengarkan" suku kata yang datang satu per satu. Ini memungkinkan jaringan untuk mempelajari suku kata mana yang secara bersamaan membentuk kata, dan seberapa besar kemungkinan urutannya.Dengan menggunakan RNS, dimungkinkan untuk memperoleh transkripsi bicara manusia yang sangat baik - sedemikian rupa sehingga komputer sekarang dapat mengungguli manusia dalam beberapa pengukuran akurasi transkripsi. Tentu saja, suara bukan satu-satunya area di mana urutan muncul. Saat ini, RNS juga digunakan untuk menentukan urutan gerakan untuk mengenali tindakan pada video.
Properti memori ini dalam RNS memungkinkan mereka tidak hanya untuk "mendengarkan" suku kata yang datang satu per satu. Ini memungkinkan jaringan untuk mempelajari suku kata mana yang secara bersamaan membentuk kata, dan seberapa besar kemungkinan urutannya.Dengan menggunakan RNS, dimungkinkan untuk memperoleh transkripsi bicara manusia yang sangat baik - sedemikian rupa sehingga komputer sekarang dapat mengungguli manusia dalam beberapa pengukuran akurasi transkripsi. Tentu saja, suara bukan satu-satunya area di mana urutan muncul. Saat ini, RNS juga digunakan untuk menentukan urutan gerakan untuk mengenali tindakan pada video.Tunjukkan pada saya bagaimana Anda bisa bergerak (deep fakes dan generative networks)
Sejauh ini, kita telah berbicara tentang model MO yang dirancang untuk pengakuan: katakan padaku apa yang ditunjukkan dalam gambar, katakan padaku apa yang dikatakan orang itu. Tetapi model ini lebih mampu - model GO saat ini juga dapat digunakan untuk membuat konten.Inilah saat orang berbicara tentang deepfake - video dan gambar palsu yang sangat realistis dibuat menggunakan GO. Beberapa waktu lalu, seorang pejabat televisi Jerman memprovokasi diskusi politik yang luas dengan membuat video palsudi mana menteri keuangan Yunani menunjukkan jari tengah Jerman. Untuk membuat video ini, kami membutuhkan tim editor yang bekerja untuk membuat acara TV, tetapi di dunia modern, ini dapat dilakukan dalam beberapa menit oleh siapa saja yang memiliki akses ke komputer game berukuran sedang.Semua ini agak menyedihkan, tetapi tidak begitu suram di area ini - video favorit saya tentang topik teknologi ini ditampilkan di bagian atas.Tim ini menciptakan model yang mampu memproses video dengan gerakan menari dari satu orang dan membuat video dengan orang lain mengulangi gerakan ini, secara ajaib menampilkannya di tingkat ahli. Menarik juga untuk membaca karya ilmiah yang menyertainya .Orang bisa membayangkan bahwa, dengan menggunakan semua teknik yang kita bahas, adalah mungkin untuk melatih jaringan yang menerima gambar penari dan memberi tahu di mana lengan dan kakinya. Dan dalam kasus ini, jelas, pada tingkat tertentu, jaringan belajar bagaimana menghubungkan piksel dalam gambar dengan lokasi anggota tubuh manusia. Mengingat bahwa jaringan saraf hanya data yang disimpan di komputer, bukan otak biologis, harus dimungkinkan untuk mengambil data ini dan pergi ke arah yang berlawanan - untuk mendapatkan piksel yang sesuai dengan lokasi anggota badan.Mulailah dengan jaringan yang mengekstrak pose dari gambar orang.
Model MO yang dapat melakukan ini disebut model generatif. menghasilkan - menghasilkan, menghasilkan, membuat / kira-kira. diterjemahkan.]. Semua model sebelumnya yang kami pertimbangkan disebut diskriminatif [ind. diskriminasikan - untuk membedakan / perkiraan. diterjemahkan.]. Perbedaan di antara mereka dapat dibayangkan sebagai berikut: model diskriminatif untuk kucing melihat foto dan membedakan antara foto yang mengandung kucing dan foto di mana mereka tidak. Model generatif menciptakan gambar kucing berdasarkan, katakanlah, deskripsi seperti apa kucing seharusnya. Model generatif yang "menggambar" gambar objek dibuat menggunakan struktur SNA yang sama dengan model yang digunakan untuk mengenali objek ini. Dan model ini dapat dilatih dengan cara yang sama seperti model MO lainnya.Namun, triknya adalah dengan membuat "penilaian" untuk pelatihan mereka. Saat melatih model diskriminatif, ada cara sederhana untuk mengevaluasi kebenaran dan kesalahan jawaban - seperti apakah jaringan dengan benar membedakan anjing dari kucing. Namun, bagaimana cara mengevaluasi kualitas gambar kucing yang dihasilkan, atau akurasinya?Dan di sini untuk orang yang menyukai teori konspirasi dan percaya bahwa kita semua dikutuk, situasinya menjadi sedikit menakutkan. Anda tahu, cara terbaik yang kami temukan untuk mempelajari jaringan generatif adalah tidak melakukannya sendiri. Untuk ini, kami cukup menggunakan jaringan saraf yang berbeda.Teknologi ini disebut jaringan permusuhan generatif, atau GSS. Anda memaksa dua jaringan saraf untuk bersaing satu sama lain: satu jaringan mencoba untuk membuat palsu, misalnya, dengan menggambar penari baru berdasarkan postur lama. Jaringan lain dilatih untuk menemukan perbedaan antara contoh nyata dan palsu menggunakan banyak contoh penari nyata.Dan dua jaringan ini memainkan permainan kompetitif. Karenanya kata "permusuhan" dalam judul. Jaringan generatif mencoba untuk membuat kepalsuan yang meyakinkan, dan jaringan yang diskriminatif mencoba untuk memahami di mana yang palsu dan di mana yang asli berada.Dalam kasus video dengan penari, jaringan diskriminatif terpisah dibuat selama proses pelatihan, memberikan jawaban ya / tidak sederhana. Dia melihat gambar orang itu dan deskripsi posisi anggota tubuhnya, dan memutuskan apakah gambar itu adalah foto asli atau gambar yang diambil oleh model generatif.
Model generatif yang "menggambar" gambar objek dibuat menggunakan struktur SNA yang sama dengan model yang digunakan untuk mengenali objek ini. Dan model ini dapat dilatih dengan cara yang sama seperti model MO lainnya.Namun, triknya adalah dengan membuat "penilaian" untuk pelatihan mereka. Saat melatih model diskriminatif, ada cara sederhana untuk mengevaluasi kebenaran dan kesalahan jawaban - seperti apakah jaringan dengan benar membedakan anjing dari kucing. Namun, bagaimana cara mengevaluasi kualitas gambar kucing yang dihasilkan, atau akurasinya?Dan di sini untuk orang yang menyukai teori konspirasi dan percaya bahwa kita semua dikutuk, situasinya menjadi sedikit menakutkan. Anda tahu, cara terbaik yang kami temukan untuk mempelajari jaringan generatif adalah tidak melakukannya sendiri. Untuk ini, kami cukup menggunakan jaringan saraf yang berbeda.Teknologi ini disebut jaringan permusuhan generatif, atau GSS. Anda memaksa dua jaringan saraf untuk bersaing satu sama lain: satu jaringan mencoba untuk membuat palsu, misalnya, dengan menggambar penari baru berdasarkan postur lama. Jaringan lain dilatih untuk menemukan perbedaan antara contoh nyata dan palsu menggunakan banyak contoh penari nyata.Dan dua jaringan ini memainkan permainan kompetitif. Karenanya kata "permusuhan" dalam judul. Jaringan generatif mencoba untuk membuat kepalsuan yang meyakinkan, dan jaringan yang diskriminatif mencoba untuk memahami di mana yang palsu dan di mana yang asli berada.Dalam kasus video dengan penari, jaringan diskriminatif terpisah dibuat selama proses pelatihan, memberikan jawaban ya / tidak sederhana. Dia melihat gambar orang itu dan deskripsi posisi anggota tubuhnya, dan memutuskan apakah gambar itu adalah foto asli atau gambar yang diambil oleh model generatif. GSS memaksa dua jaringan untuk saling bersaing: satu menghasilkan palsu, dan yang lainnya mencoba untuk membedakan yang palsu dari yang asli
GSS memaksa dua jaringan untuk saling bersaing: satu menghasilkan palsu, dan yang lainnya mencoba untuk membedakan yang palsu dari yang asli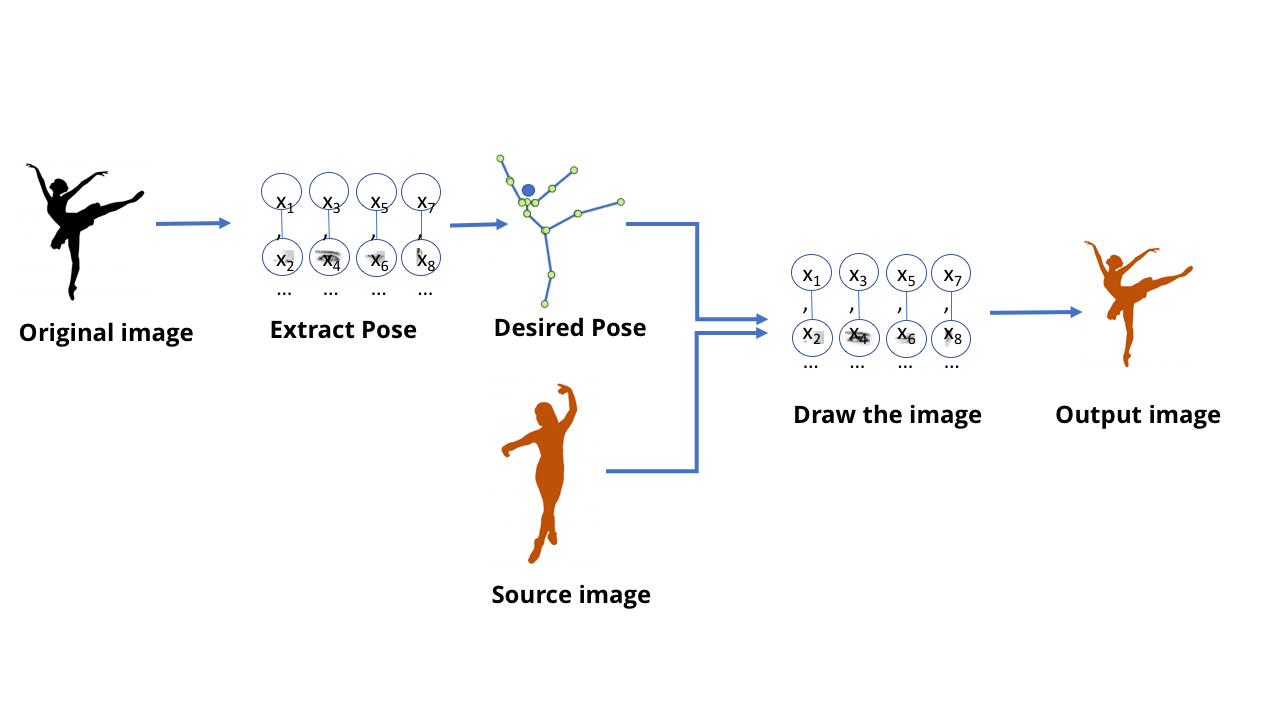 .Dalam alur kerja akhir, hanya model generatif yang digunakan yang menciptakan gambar yang diperlukanSelama putaran pelatihan berulang, model menjadi lebih baik dan lebih baik. Ini mirip dengan persaingan antara pakar perhiasan dan pakar penilaian - bersaing dengan lawan yang kuat, masing-masing menjadi lebih kuat dan lebih pintar. Akhirnya, ketika model bekerja cukup baik, Anda dapat mengambil model generatif dan menggunakannya secara terpisah.Model generatif pasca pelatihan dapat sangat berguna untuk membuat konten. Misalnya, mereka dapat menghasilkan gambar wajah (yang dapat digunakan untuk melatih program pengenalan wajah), atau latar belakang untuk video game.Agar semua ini bekerja dengan benar, banyak pekerjaan pada penyesuaian dan koreksi diperlukan, tetapi pada dasarnya orang di sini bertindak sebagai wasit. AIlah yang bekerja melawan satu sama lain, membuat peningkatan besar.
.Dalam alur kerja akhir, hanya model generatif yang digunakan yang menciptakan gambar yang diperlukanSelama putaran pelatihan berulang, model menjadi lebih baik dan lebih baik. Ini mirip dengan persaingan antara pakar perhiasan dan pakar penilaian - bersaing dengan lawan yang kuat, masing-masing menjadi lebih kuat dan lebih pintar. Akhirnya, ketika model bekerja cukup baik, Anda dapat mengambil model generatif dan menggunakannya secara terpisah.Model generatif pasca pelatihan dapat sangat berguna untuk membuat konten. Misalnya, mereka dapat menghasilkan gambar wajah (yang dapat digunakan untuk melatih program pengenalan wajah), atau latar belakang untuk video game.Agar semua ini bekerja dengan benar, banyak pekerjaan pada penyesuaian dan koreksi diperlukan, tetapi pada dasarnya orang di sini bertindak sebagai wasit. AIlah yang bekerja melawan satu sama lain, membuat peningkatan besar., Skynet Hal 9000?
Di setiap film dokumenter tentang alam di akhir ada sebuah episode di mana penulis berbicara tentang bagaimana semua keindahan muluk ini akan segera menghilang karena betapa mengerikannya manusia. Saya pikir dengan semangat yang sama, setiap diskusi yang bertanggung jawab mengenai AI harus mencakup bagian tentang batasan dan konsekuensi sosialnya.
Pertama, mari kita tekankan sekali lagi keterbatasan AI saat ini: ide utama yang saya harap Anda pelajari dari membaca artikel ini adalah bahwa keberhasilan MO atau AI sangat tergantung pada model pelatihan yang telah kita pilih. Jika orang tidak mengatur jaringan dengan baik atau menggunakan materi yang tidak cocok untuk pelatihan, maka distorsi ini bisa sangat jelas bagi semua orang.
Jaringan saraf dalam sangat fleksibel dan kuat, tetapi tidak memiliki sifat magis. Terlepas dari kenyataan bahwa Anda menggunakan jaringan saraf yang dalam untuk RNS dan SNA, strukturnya sangat berbeda, dan karena itu, orang tetap harus menentukannya. Jadi, bahkan jika Anda dapat mengambil SNA untuk mobil dan melatihnya untuk pengenalan burung, Anda tidak dapat mengambil model ini dan melatihnya untuk pengenalan suara.
Jika kita menggambarkannya dalam istilah manusia, maka kita seolah-olah memahami bagaimana korteks visual dan korteks pendengaran bekerja, tetapi kita tidak tahu bagaimana cara kerja korteks serebral, dan di mana kita dapat mulai mendekatinya.
Ini berarti bahwa dalam waktu dekat, kita mungkin tidak akan melihat AI seperti Hollywood. Tetapi ini tidak berarti bahwa dalam bentuknya saat ini, AI tidak dapat memiliki dampak serius pada masyarakat.
Kita sering membayangkan bagaimana AI "menggantikan" kita, yaitu, bagaimana robot benar-benar melakukan pekerjaan kita, tetapi dalam kenyataannya ini tidak akan terjadi. Lihatlah radiologi, misalnya: kadang-kadang orang, melihat keberhasilan penglihatan komputer, mengatakan bahwa AI akan menggantikan ahli radiologi. Mungkin kita tidak akan mencapai titik di mana kita tidak akan memiliki seorang ahli radiologi manusia sama sekali. Tetapi masa depan sangat mungkin di mana, bagi seratus ahli radiologi hari ini, AI akan memungkinkan lima hingga sepuluh dari mereka untuk melakukan pekerjaan semua orang. Jika skenario seperti itu direalisasikan, ke mana 90 dokter yang tersisa akan pergi?
Sekalipun generasi modern AI tidak memenuhi harapan pendukungnya yang paling optimis, itu masih akan membawa konsekuensi yang sangat luas. Dan kita harus menyelesaikan masalah ini, jadi awal yang baik mungkin akan menguasai dasar-dasar area ini.