
Dengan munculnya kamera berkualitas tinggi di telepon seluler, kami memotret semakin sering, merekam video dari momen-momen penting dan cerah dalam hidup kita. Banyak dari kita memiliki arsip foto sejak puluhan tahun dan ribuan foto, yang semakin sulit dinavigasi. Ingat berapa lama waktu yang dibutuhkan untuk menemukan foto yang tepat beberapa tahun yang lalu.
Salah satu tujuan Mail.ru Cloud adalah untuk menyediakan akses dan pencarian paling nyaman di arsip foto dan video Anda. Untuk melakukan ini, kami, tim visi mesin Mail.ru, telah menciptakan dan menerapkan sistem pemrosesan foto pintar: pencarian berdasarkan objek, adegan, wajah, dll. Teknologi mencolok lainnya adalah pengenalan pemandangan. Dan hari ini saya akan berbicara tentang bagaimana kami menyelesaikan masalah ini dengan bantuan Deep Learning.
Bayangkan situasinya: Anda pergi berlibur dan membawa banyak foto. Dan dalam percakapan dengan teman-teman, mereka meminta Anda untuk menunjukkan bagaimana Anda mengunjungi istana, kastil, piramida, kuil, danau, air terjun, gunung, dll. Anda mulai dengan gulir menelusuri folder dengan foto, mencoba menemukan yang tepat. Kemungkinan besar, Anda tidak menemukannya di antara ratusan gambar, dan mengatakan bahwa Anda akan ditampilkan nanti.
Kami mengatasi masalah ini dengan mengelompokkan foto khusus ke dalam album. Ini membuatnya mudah untuk menemukan gambar yang tepat hanya dalam beberapa klik. Sekarang kami memiliki album di wajah, pada objek dan adegan, serta pada atraksi.
Foto dengan tengara penting karena sering menampilkan momen penting dalam hidup kita (misalnya, perjalanan). Ini bisa berupa foto di latar belakang beberapa struktur arsitektur atau sudut alam yang tidak tersentuh manusia. Oleh karena itu, kita perlu menemukan foto-foto ini dan memberi pengguna akses yang mudah dan cepat ke foto-foto itu.
Pengenalan fitur
Tetapi ada nuansa: Anda tidak bisa hanya mengambil dan melatih beberapa model untuk mengenali pemandangan, ada banyak kesulitan.
- Pertama, kita tidak bisa dengan jelas menggambarkan apa itu "landmark". Kami tidak bisa mengatakan mengapa satu bangunan adalah landmark, dan berdiri di sebelahnya bukan. Ini bukan konsep formal, yang mempersulit perumusan masalah pengakuan.
- Kedua, pemandangannya sangat beragam. Ini bisa berupa bangunan bersejarah atau budaya - kuil, istana, istana. Ini bisa menjadi monumen yang paling beragam. Ini bisa menjadi benda alami - danau, ngarai, air terjun. Dan satu model harus dapat menemukan semua atraksi ini.
- Ketiga, ada sangat sedikit gambar dengan pemandangan, menurut perhitungan kami, mereka hanya ditemukan di 1-3% dari foto pengguna. Oleh karena itu, kami tidak dapat membiarkan diri kami kesalahan dalam pengakuan, karena jika kami menunjukkan foto kepada seseorang tanpa minat, itu akan segera terlihat dan akan menyebabkan kebingungan dan reaksi negatif. Atau, sebaliknya, kami menunjukkan orang itu foto dengan tengara di New York, dan dia belum pernah ke Amerika. Jadi model pengakuan harus memiliki FPR yang rendah (false positive rate).
- Keempat, sekitar 50% pengguna, atau bahkan lebih, mematikan penyimpanan informasi geografis saat memotret. Kita perlu mempertimbangkan ini dan menentukan tempat hanya dari gambar. Sebagian besar layanan yang saat ini entah bagaimana berhasil bekerja dengan tempat-tempat menarik melakukan ini berkat geodata. Persyaratan awal kami lebih ketat.
Saya akan tunjukkan sekarang dengan contoh.
Berikut adalah benda-benda serupa, tiga katedral Gothic Prancis. Di sebelah kiri adalah Katedral Amiens, di tengah-tengah Katedral Reims, di sebelah kanan adalah Notre Dame de Paris.

Bahkan seseorang perlu waktu untuk melihatnya dan memahami bahwa ini adalah katedral yang berbeda, dan mesin itu juga harus dapat mengatasinya, dan lebih cepat daripada seseorang.
Dan ini adalah contoh kesulitan lain: tiga foto pada slide adalah Notre Dame de Paris, diambil dari sudut yang berbeda. Foto-foto itu ternyata sangat berbeda, tetapi semuanya perlu dikenali dan ditemukan.

Benda-benda alami sama sekali berbeda dari benda-benda arsitektur. Di sebelah kiri adalah Kaisarea di Israel, di sebelah kanan adalah Taman Inggris di Munich.

Dalam foto-foto ini ada beberapa detail karakteristik yang modelnya dapat “tangkap”.
Metode kami
Metode kami sepenuhnya didasarkan pada jaringan saraf convolutional yang mendalam. Sebagai pendekatan untuk belajar, mereka memilih apa yang disebut belajar kurikulum - belajar dalam beberapa tahap. Agar dapat bekerja lebih efisien baik dengan keberadaan geodata maupun dengan tidak adanya geodata, kami membuat inferensi khusus (kesimpulan). Saya akan memberi tahu Anda tentang masing-masing tahap secara lebih rinci.
Datacet
Bahan bakar untuk pembelajaran mesin adalah data. Dan pertama-tama, kami perlu mengumpulkan dataset untuk pelatihan model.
Kami membagi dunia menjadi 4 wilayah, yang masing-masing digunakan pada berbagai tahap pelatihan. Kemudian, negara diambil di setiap daerah, untuk setiap negara disusun daftar kota dan database foto-foto atraksi mereka disusun. Contoh data disajikan di bawah ini.

Pertama, kami mencoba untuk melatih model kami di pangkalan yang dihasilkan. Hasilnya buruk. Mereka mulai menganalisis, dan ternyata datanya sangat "kotor." Setiap objek wisata memiliki sejumlah besar sampah. Apa yang harus dilakukan Secara manual meninjau seluruh jumlah data yang besar itu mahal, suram, dan tidak terlalu pintar. Oleh karena itu, kami melakukan pembersihan pangkalan secara otomatis, di mana pemrosesan manual hanya digunakan pada satu langkah: untuk setiap daya tarik, kami secara manual memilih 3-5 foto referensi yang secara akurat mengandung daya tarik yang diinginkan dalam perspektif yang kurang lebih benar. Ternyata cukup cepat, karena volume data referensi tersebut relatif kecil dibandingkan dengan keseluruhan database. Kemudian, pembersihan otomatis berdasarkan jaringan saraf convolutional yang dalam sudah dilakukan.
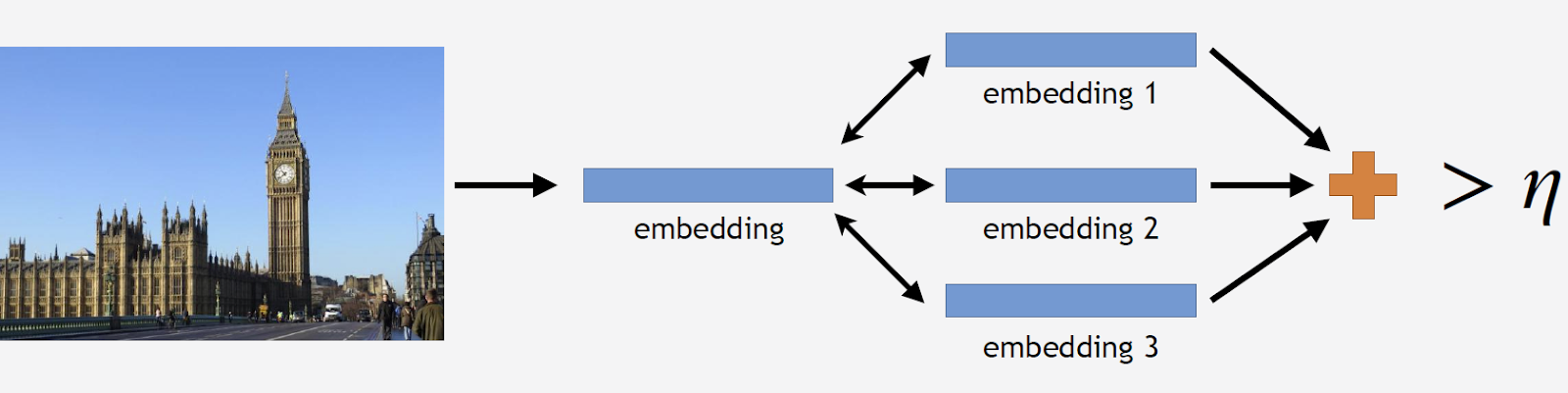
Selanjutnya saya akan menggunakan istilah "embedding", dimana saya akan mengerti yang berikut. Kami memiliki jaringan saraf convolutional, kami melatihnya untuk klasifikasi, memotong lapisan klasifikasi terakhir, mengambil beberapa gambar, melewati jaringan dan mendapat vektor numerik pada output. Saya akan menyebutnya embedding.
Seperti yang saya katakan, pelatihan kami dilakukan dalam beberapa tahap, sesuai dengan bagian dari basis data kami. Oleh karena itu, pertama-tama kita mengambil jaringan saraf dari tahap sebelumnya, atau jaringan inisialisasi.
Kami akan menjalankan foto-foto pemandangan melalui jaringan dan mendapatkan beberapa embeddings. Sekarang Anda dapat membersihkan alasnya. Kami mengambil semua gambar dari dataset untuk objek wisata ini, dan kami juga mengarahkan setiap gambar melalui jaringan. Kami mendapatkan banyak embeddings dan untuk masing-masing kami mempertimbangkan jarak ke embedding standar. Lalu kami menghitung jarak rata-rata, dan jika lebih dari ambang tertentu, yang merupakan parameter algoritma, maka kami menganggap bahwa ini bukan objek wisata. Jika jarak rata-rata kurang dari ambang, maka kami meninggalkan foto ini.
Hasilnya, kami mendapat basis data yang berisi lebih dari 11 ribu objek wisata dari lebih dari 500 kota di 70 negara di dunia - lebih dari 2,3 juta foto. Sekarang saatnya untuk mengingat bahwa sebagian besar foto tidak mengandung atraksi sama sekali. Informasi ini perlu dibagikan dengan model kami. Karena itu, kami menambahkan 900 ribu foto tanpa pemandangan ke database kami, dan melatih model kami pada dataset yang dihasilkan.
Untuk mengukur kualitas pelatihan, kami memperkenalkan tes offline. Berdasarkan fakta bahwa pemandangan hanya ditemukan di sekitar 1-3% dari foto, kami secara manual menyusun satu set foto yang menunjukkan pemandangan. Ini adalah foto yang berbeda dan cukup kompleks dengan sejumlah besar objek yang diambil dari sudut yang berbeda, sehingga pengujiannya sesulit mungkin untuk model. Dengan prinsip yang sama, kami memilih 11 ribu foto tanpa pemandangan, yang juga cukup rumit, dan kami mencoba menemukan objek yang sangat mirip dengan pemandangan yang tersedia di database kami.
Untuk menilai kualitas pelatihan, kami mengukur akurasi model kami dari foto dengan dan tanpa pemandangan. Ini adalah dua metrik utama kami.
Pendekatan yang ada
Hanya ada sedikit informasi tentang pengenalan penglihatan dalam literatur ilmiah. Sebagian besar solusi didasarkan pada fitur-fitur lokal. Idenya adalah bahwa kita memiliki gambar permintaan tertentu dan gambar dari database. Dalam foto-foto ini kami menemukan tanda-tanda lokal - poin utama, dan membandingkannya. Jika jumlah pertandingan cukup besar, kami pikir kami telah menemukan tempat menarik.
Sampai saat ini, metode terbaik adalah metode yang diusulkan Google, DELF (fitur lokal mendalam), di mana perbandingan fitur lokal dikombinasikan dengan pembelajaran mendalam. Dengan menjalankan gambar input melalui jaringan konvolusi, kami mendapatkan beberapa tanda DELF.

Bagaimana pengakuan atraksi? Kami memiliki basis data foto dan gambar input, dan kami ingin memahami apakah ada objek wisata di sana atau tidak. Kami menjalankan semua gambar melalui DELF, kami mendapatkan tanda-tanda yang sesuai untuk basis dan untuk gambar input. Kemudian kami melakukan pencarian menggunakan metode tetangga terdekat dan pada output kami mendapatkan gambar kandidat dengan tanda. Kami membandingkan tanda-tanda ini dengan bantuan verifikasi geometrik: jika mereka berhasil lulus, maka kami percaya bahwa ada hal yang menarik dalam gambar.
Jaringan Saraf Konvolusional
Untuk Deep Learning, pra-pelatihan sangat penting. Oleh karena itu, kami mengambil basis adegan dan pra-terlatih di atasnya jaringan saraf kami. Kenapa begitu? Adegan adalah objek kompleks yang mencakup sejumlah besar objek lain. Dan daya tarik adalah kasus khusus dari pemandangan itu. Model pra-pelatihan atas dasar seperti itu, kami dapat memberikan model gagasan tentang beberapa fitur tingkat rendah yang kemudian dapat digeneralisasi untuk keberhasilan pengakuan objek wisata.
Sebagai model, kami menggunakan jaringan saraf dari keluarga jaringan Residual. Fitur utama mereka adalah bahwa mereka menggunakan blok residual, yang mencakup koneksi lewati, yang memungkinkan sinyal untuk melewati bebas tanpa masuk ke lapisan dengan bobot. Dengan arsitektur ini, Anda dapat secara kualitatif melatih jaringan yang dalam dan menangani efek gradient blur, yang sangat penting saat belajar.
Model kami adalah Wide ResNet 50-2, modifikasi dari ResNet 50, di mana jumlah konvolusi dalam blok bottleneck internal menjadi dua kali lipat.

Jaringannya sangat efisien. Kami melakukan tes pada database adegan kami dan inilah yang kami dapatkan:
Wide ResNet ternyata hampir dua kali lebih cepat dari jaringan ResNet 200 yang agak besar. Dan kecepatan operasi sangat penting untuk operasi. Berdasarkan totalitas dari keadaan ini, kami mengambil Wide ResNet 50-2 sebagai jaringan saraf utama kami.
Pelatihan
Untuk melatih jaringan, kita perlu kehilangan (loss function). Untuk memilihnya, kami memutuskan untuk menggunakan pendekatan pembelajaran metrik: jaringan saraf dilatih sehingga perwakilan dari kelas yang sama ditarik bersama dalam satu cluster. Pada saat yang sama, klaster untuk kelas yang berbeda harus terpisah sejauh mungkin. Untuk atraksi, kami menggunakan Center loss, yang mengumpulkan poin dari kelas yang sama ke pusat tertentu. Fitur penting dari pendekatan ini adalah tidak memerlukan pengambilan sampel negatif, yang pada tahap akhir pelatihan merupakan prosedur yang agak sulit.
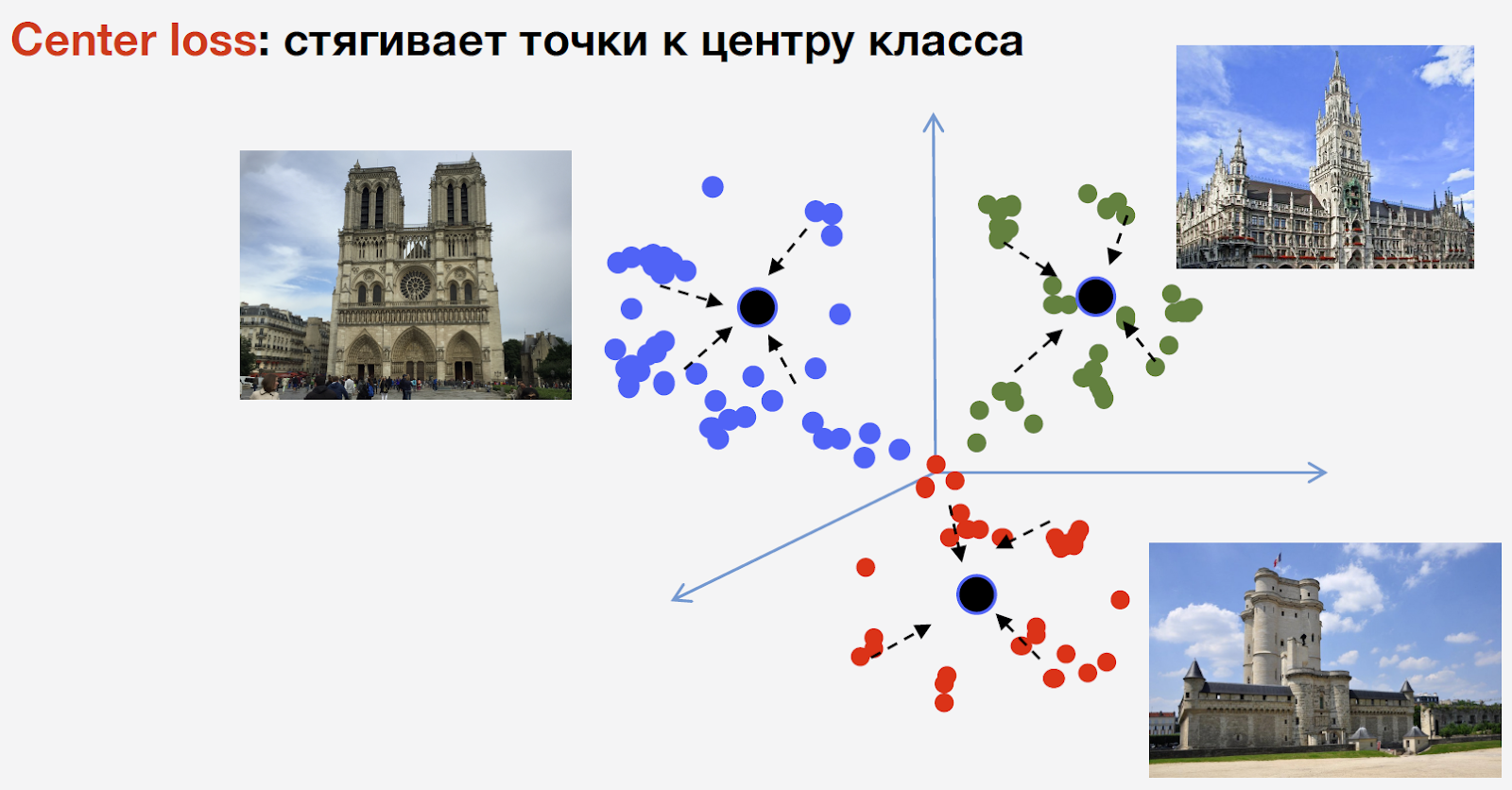
Biarkan saya mengingatkan Anda bahwa kami memiliki n kelas atraksi dan kelas "bukan atraksi" lainnya, Center loss tidak digunakan untuk itu. Maksud kami, tengara adalah satu dan objek yang sama, dan ada struktur di dalamnya, oleh karena itu disarankan untuk mempertimbangkan pusatnya. Tapi bukan daya tarik wisata yang bisa apa saja, dan menganggap pusat baginya tidak masuk akal.
Lalu kami menggabungkan semuanya dan mendapatkan model untuk pelatihan. Ini terdiri dari tiga bagian utama:
- Jaringan saraf convolutional Wide ResNet 50-2, pra-dilatih berdasarkan adegan;
- Bagian penyisipan yang terdiri dari lapisan yang terhubung penuh dan lapisan norma Batch;
- Klasifikasi, yang merupakan lapisan yang sepenuhnya terhubung, diikuti oleh sepasang kerugian Softmax dan kerugian Tengah.

Seperti yang Anda ingat, basis kami dibagi menjadi 4 bagian berdasarkan wilayah dunia. Kami menggunakan 4 bagian ini sebagai bagian dari paradigma pembelajaran kurikulum. Pada setiap tahap, kami memiliki dataset saat ini, kami menambahkan bagian lain dunia ke dalamnya dan kami mendapatkan dataset pelatihan baru.
Model ini terdiri dari tiga bagian, dan untuk masing-masing kami menggunakan tingkat pembelajaran kami sendiri dalam pelatihan. Ini diperlukan agar jaringan tidak hanya dapat mempelajari pemandangan dari bagian baru dari dataset yang kami tambahkan, tetapi juga agar tidak melupakan data yang telah dipelajari. Setelah banyak percobaan, pendekatan ini ternyata menjadi yang paling efektif.
Jadi, kami melatih modelnya. Anda perlu memahami cara kerjanya. Mari kita gunakan peta aktivasi kelas untuk melihat bagian mana dari gambar yang paling responsif terhadap jaringan saraf kita. Pada gambar di bawah ini, di baris pertama, gambar input, dan di baris kedua mereka ditumpangkan peta aktivasi kelas dari grid, yang kami latih pada langkah sebelumnya.

Peta panas menunjukkan bagian gambar yang lebih diperhatikan jaringan. Dari peta aktivasi kelas dapat dilihat bahwa jaringan saraf kita telah berhasil mempelajari konsep tarik-menarik.
Kesimpulan
Sekarang Anda perlu entah bagaimana menggunakan pengetahuan ini untuk mendapatkan hasilnya. Karena kami menggunakan Center loss untuk pelatihan, tampaknya cukup logis untuk menyimpulkan juga menghitung tserotoid untuk atraksi.
Untuk ini, kami mengambil bagian dari gambar dari set pelatihan untuk beberapa jenis atraksi, misalnya, untuk Penunggang Kuda Perunggu. Kami menjalankannya melalui jaringan, mendapatkan embeddings, rata-rata dan mendapatkan centroid.
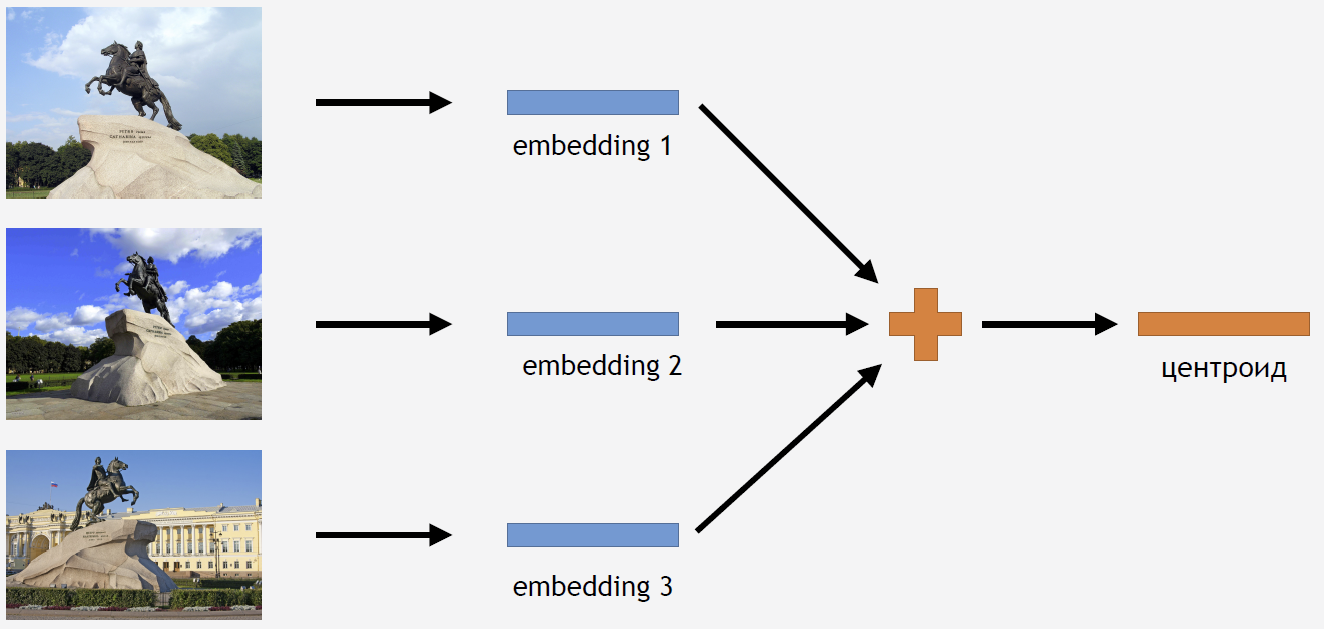
Tetapi muncul pertanyaan: berapa banyak centroid untuk satu daya tarik yang masuk akal untuk dihitung? Pada awalnya, jawabannya tampak jelas dan logis: satu centroid. Tapi ini ternyata tidak begitu. Pada awalnya, kami juga memutuskan untuk membuat satu centroid dan mendapatkan hasil yang cukup bagus. Jadi mengapa Anda perlu mengambil beberapa centroid?
Pertama, data kami tidak sepenuhnya bersih. Meskipun kami membersihkan dataset, kami hanya membuang sampah saja. Dan kita dapat memiliki gambar yang tidak dapat dianggap sampah, tetapi yang memperburuk hasilnya.
Sebagai contoh, saya memiliki kelas landmark Istana Musim Dingin. Saya ingin menghitung centroid untuknya. Tetapi set termasuk sejumlah foto dengan Palace Square dan lengkungan Gedung Staf Umum. Jika kita mempertimbangkan centroid di semua gambar, hasilnya tidak terlalu stabil. Penting untuk mengelompokkan embeddings mereka, yang diperoleh dari grid biasa, hanya mengambil centroid yang bertanggung jawab untuk Winter Palace, dan menghitung rata-rata berdasarkan data ini.

Kedua, foto dapat diambil dari berbagai sudut.
Saya akan mengutip menara lonceng Belfort di Bruges sebagai ilustrasi perilaku ini. Dua centroid dihitung untuknya. Di baris atas gambar adalah foto-foto yang lebih dekat ke centroid pertama, dan di baris kedua - yang lebih dekat ke centroid kedua:

Centroid pertama bertanggung jawab atas foto-foto close-up yang lebih "pintar" yang diambil dari Bruges Market Square. Dan centroid kedua bertanggung jawab atas foto yang diambil dari jauh, dari jalan-jalan yang berdekatan.
Ternyata dengan menghitung beberapa centroid per kelas dari suatu tempat menarik, kita dapat menampilkan sudut berbeda dari tempat menarik ini dalam inferensi.
Jadi, bagaimana kita menemukan set ini untuk menghitung centroid? Kami menerapkan pengelompokan hierarkis ke kumpulan data untuk setiap tempat menarik - tautan lengkap. Dengan bantuannya, kami menemukan kluster yang valid untuk menghitung centroid. Yang kami maksudkan adalah cluster yang, sebagai hasil pengelompokan, mengandung setidaknya 50 foto. Cluster yang tersisa dibuang. Hasilnya, ternyata sekitar 20% pemandangan memiliki lebih dari satu centroid.
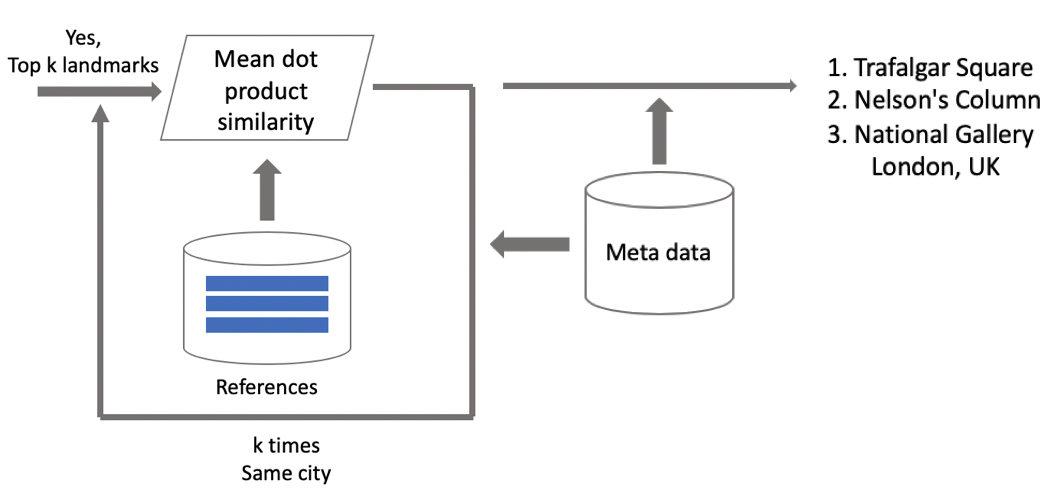
Sekarang inferensi. Kami menghitungnya dalam dua tahap: pertama, kami menjalankan gambar input melalui jaringan saraf convolutional kami dan mendapatkan embedding, dan kemudian menggunakan produk skalar yang kami bandingkan dengan embedding dengan centroid. Jika gambar berisi geodata, maka kami membatasi pencarian untuk centroid, yang terkait dengan objek wisata yang terletak di kotak 1 per 1 km dari lokasi pemotretan. Ini memungkinkan Anda untuk mencari lebih tepat, memilih ambang yang lebih rendah untuk perbandingan selanjutnya. Jika jarak yang diperoleh lebih besar dari ambang, yang merupakan parameter algoritma, maka kita mengatakan bahwa di foto ada titik menarik dengan nilai maksimum dari produk skalar. Jika kurang, maka ini bukan objek wisata.
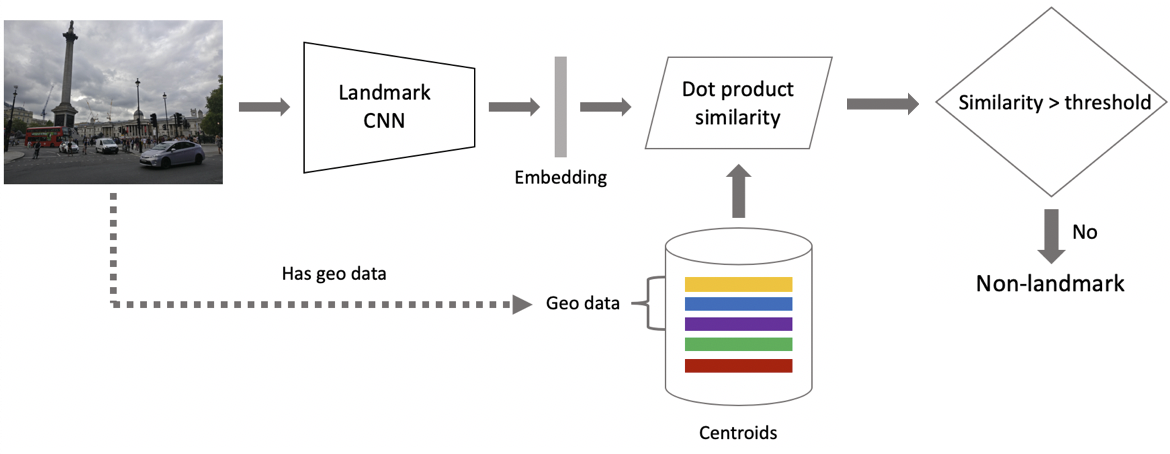
Misalkan foto tersebut mengandung tengara. Jika kami memiliki geodata, maka kami menggunakannya dan menampilkan jawabannya. Jika tidak ada geodata, maka kami melakukan pemeriksaan tambahan. Ketika kami membersihkan dataset, kami membuat satu set gambar referensi untuk setiap kelas atraksi. Bagi mereka, kita bisa menghitung embeddings, dan kemudian kita menghitung jarak rata-rata dari mereka ke embedding gambar permintaan. Jika lebih dari ambang tertentu, maka verifikasi dilewati, kami menyertakan metadata dan menampilkan hasilnya. Penting untuk dicatat bahwa kita dapat melakukan prosedur semacam itu untuk beberapa objek wisata yang ditemukan dalam gambar.
Hasil tes
Kami membandingkan model kami dengan DELF, di mana kami mengambil parameter yang menunjukkan hasil terbaik pada pengujian kami. Hasilnya hampir sama.
: ( 100 ), 87 % , . : 85,3 %. 46 %, — .
/B- . 10 %, 3 %, 13 %.
DELF. GPU DELF 7 , 7 , 1 . CPU DELF . CPU 15 . , .
:
. .
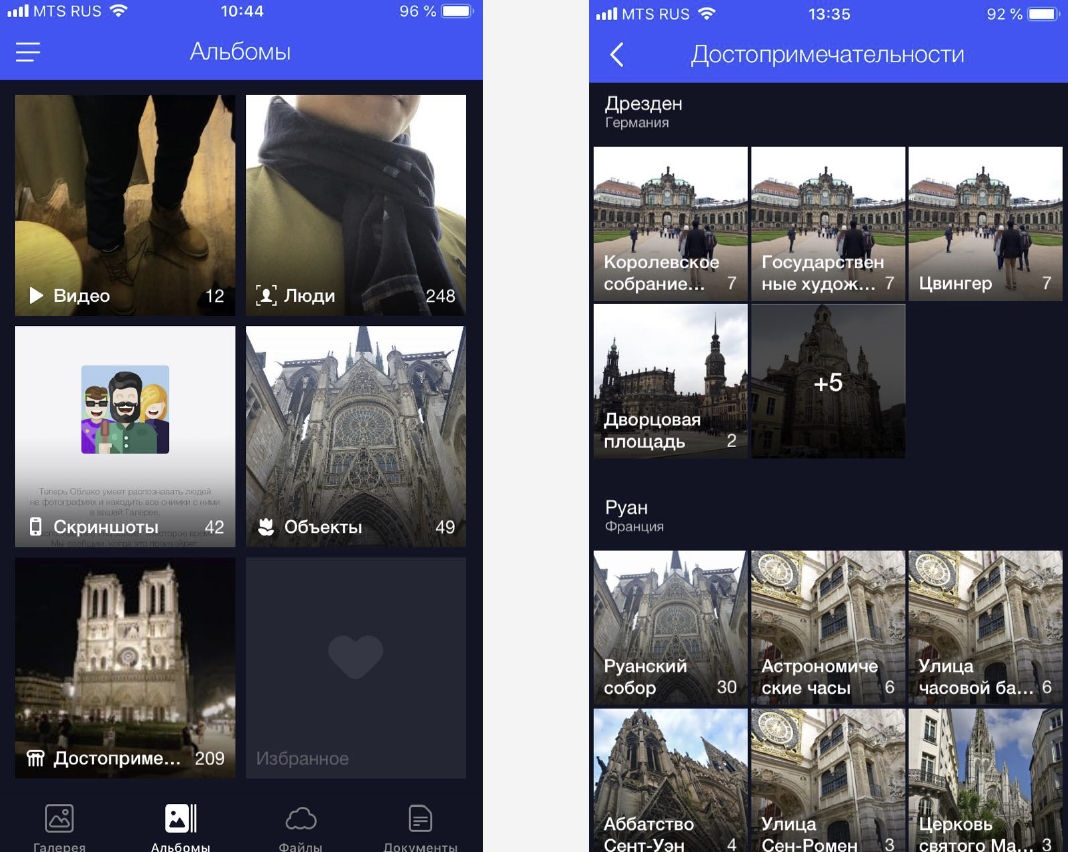
, . «», «», «». , . , .
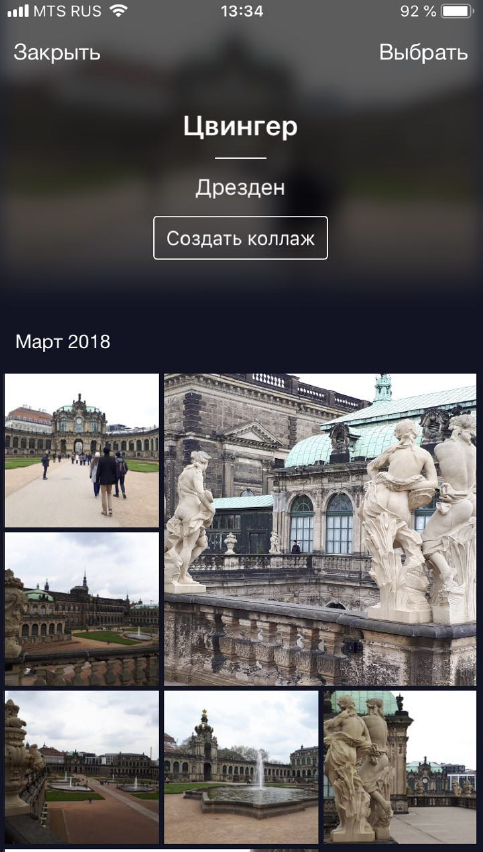
: , , . Instagram , , — .
.
- . , . .
- deep metric learning, .
- curriculum learning — . . inference , .
, — . , , . - . !