Kami memulai serangkaian artikel yang menggambarkan berbagai situasi di mana penggunaan alat Intel untuk pengembang telah secara signifikan meningkatkan kecepatan perangkat lunak dan meningkatkan kualitasnya.
Kisah pertama kami terjadi di Universitas Novosibirsk, di mana para peneliti mengembangkan alat perangkat lunak untuk simulasi numerik masalah magnetohidrodinamik selama ionisasi hidrogen. Pekerjaan ini dilakukan sebagai bagian dari proyek pemodelan astrofisika global,
AstroPhi ;
Prosesor Intel Xeon Phi digunakan sebagai platform perangkat keras. Sebagai hasil dari menggunakan
Penasihat Intel dan
Penganalisa dan Kolektor Intel Trace , kinerja komputasi meningkat 3 kali lipat, dan kecepatan penyelesaian satu masalah menurun dari satu minggu menjadi dua hari.
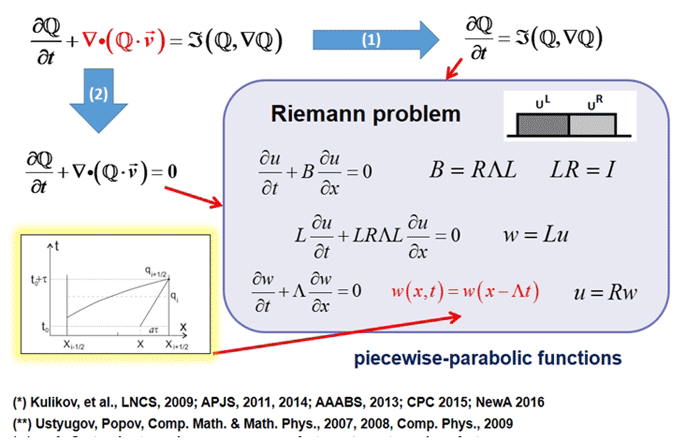
Deskripsi tugas
Pemodelan matematika memainkan peran penting dalam astrofisika modern, seperti dalam sains apa pun; Ini adalah alat universal untuk mempelajari proses evolusi nonlinear di alam semesta. Pemodelan resolusi tinggi dari proses astrofisika kompleks membutuhkan sumber daya komputasi yang besar. Proyek AstroPhi NSU sedang mengembangkan kode perangkat lunak astrofisika untuk superkomputer berbasis prosesor Intel Xeon Phi. Siswa belajar menulis program simulasi untuk runtime yang sangat paralel, mendapatkan pengetahuan penting yang akan mereka perlukan ketika bekerja dengan superkomputer lain.
Metode pemodelan numerik yang digunakan dalam proyek ini memiliki sejumlah keunggulan penting:
- kurangnya viskositas buatan,
- Invariansi Galilea,
- jaminan non-pengurangan entropi,
- paralelisasi sederhana
- berpotensi diperpanjang tanpa batas.
Tiga faktor pertama adalah kunci untuk pemodelan realistis efek fisik yang signifikan dalam masalah astrofisika.
Tim peneliti telah menciptakan alat pemodelan baru untuk arsitektur multi-paralel berbasis pada Intel Xeon Phi. Tugas utamanya adalah untuk menghindari kemacetan dalam pertukaran data antara node dan untuk menyederhanakan perbaikan kode sebanyak mungkin. Solusi paralelisasi menggunakan MPI, dan untuk vektorisasi, instruksi Intel Advanced Vector Extensions 512 (Intel AVX-512) menambahkan dukungan untuk SIMD 512-bit dan memungkinkan program untuk mengemas 8 angka floating-point presisi ganda atau 16 angka presisi tunggal (32-bit) ) untuk vektor panjang 512 bit. Dengan demikian, elemen data dua kali lebih banyak diproses per instruksi dibandingkan saat menggunakan AVX / AVX2 dan empat kali lebih banyak saat menggunakan SSE.
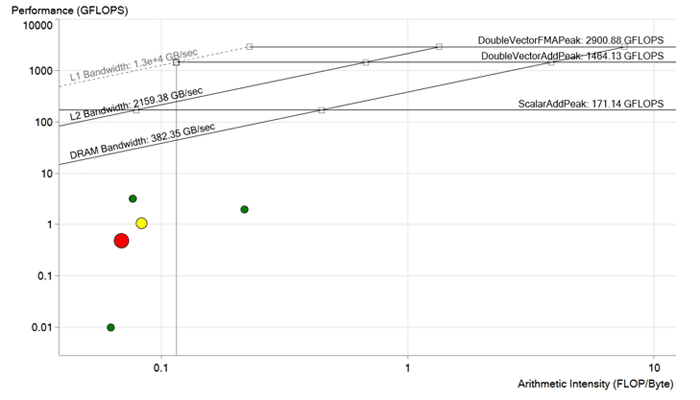 Gambar sebelum optimasi. Setiap titik adalah siklus pemrosesan. Semakin besar dan semakin buruk intinya, semakin lama siklus berlanjut dan semakin terlihat efek pengoptimalannya. Titik merah terletak jauh di bawah batas bandwidth DRAM dan dihitung dengan kinerja kurang dari 1 GFLOP. Ini memiliki potensi yang sangat besar untuk peningkatan.
Gambar sebelum optimasi. Setiap titik adalah siklus pemrosesan. Semakin besar dan semakin buruk intinya, semakin lama siklus berlanjut dan semakin terlihat efek pengoptimalannya. Titik merah terletak jauh di bawah batas bandwidth DRAM dan dihitung dengan kinerja kurang dari 1 GFLOP. Ini memiliki potensi yang sangat besar untuk peningkatan.Optimasi kode
Sebelum optimasi, kode memiliki masalah tertentu dengan dependensi dan ukuran vektor. Tujuan pengoptimalan adalah untuk menghapus dependensi vektor dan meningkatkan operasi pemuatan data ke dalam memori menggunakan ukuran vektor dan array yang optimal untuk Xeon Phi. Untuk optimasi, kami menggunakan
Intel Advisor dan
Intel Trace Analyzer and Collector , dua alat dari
Intel Parallel Studio XE .
Intel Advisor adalah, seperti namanya, penasihat - alat perangkat lunak yang mengevaluasi tingkat optimasi - vektorisasi (menggunakan instruksi AVX atau SIMD) dan paralelisasi untuk mencapai kinerja maksimum. Dengan menggunakan alat ini, tim dapat melakukan analisis ikhtisar siklus, menyoroti mereka yang memiliki produktivitas rendah, menunjukkan potensi untuk perbaikan dan menentukan apa yang dapat ditingkatkan dan apakah permainan itu layak untuk ditiru. Intel Advisor mengurutkan siklus berdasarkan potensi, menambahkan pesan ke sumber agar lebih mudah dibaca dari laporan penyusun. Dia juga memberikan informasi penting seperti waktu siklus, ketergantungan data, dan pola akses memori untuk vektorisasi yang aman dan efisien.
Intel Trace Analyzer and Collector adalah cara lain untuk mengoptimalkan kode Anda. Ini termasuk profiling komunikasi MPI dan fungsi analisis untuk meningkatkan skala lemah dan kuat. Alat grafis ini membantu tim memahami perilaku MPI aplikasi, dengan cepat menemukan kemacetan dan, yang paling penting, meningkatkan kinerja arsitektur Intel.
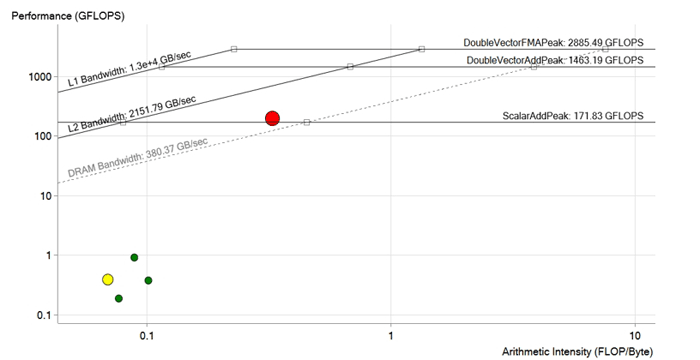 Gambar setelah optimasi. Selama optimasi loop merah, dependensi vektorisasi telah dihapus, operasi pemuatan ke dalam memori dioptimalkan, ukuran vektor dan array diadaptasi untuk instruksi Intel Xeon Phi dan AVX-512. Kinerja meningkat menjadi 190 GFLOPS, yaitu sekitar 200 kali. Sekarang berada di atas batas DRAM dan kemungkinan besar dibatasi oleh karakteristik cache L2
Gambar setelah optimasi. Selama optimasi loop merah, dependensi vektorisasi telah dihapus, operasi pemuatan ke dalam memori dioptimalkan, ukuran vektor dan array diadaptasi untuk instruksi Intel Xeon Phi dan AVX-512. Kinerja meningkat menjadi 190 GFLOPS, yaitu sekitar 200 kali. Sekarang berada di atas batas DRAM dan kemungkinan besar dibatasi oleh karakteristik cache L2Hasil
Jadi, setelah semua perbaikan dan optimalisasi, tim mencapai kinerja 190 GFLOPS dengan intensitas aritmatika 0,3 FLOP / b, pemanfaatan 100% dan bandwidth memori 573 GB / s.
 Cuplikan kode yang dioptimalkan
Cuplikan kode yang dioptimalkan