Artikel yang dimaksud.
Pendahuluan
Sistem pengakuan modern terbatas untuk mengklasifikasikan ke dalam sejumlah kecil kelas yang tidak terkait secara semantik. Ketertarikan informasi tekstual, bahkan yang tidak terkait dengan gambar, memungkinkan untuk memperkaya model dan sampai batas tertentu memecahkan masalah berikut:
- jika model pengenalan membuat kesalahan, maka seringkali kesalahan ini secara semantik tidak dekat dengan kelas yang benar;
- tidak ada cara untuk memprediksi objek milik kelas baru yang tidak terwakili dalam dataset pelatihan.
Pendekatan yang diusulkan menunjukkan menampilkan gambar dalam ruang semantik yang kaya di mana label kelas yang lebih mirip lebih dekat satu sama lain daripada label kelas yang kurang serupa. Hasilnya, model ini memberikan jarak semantis yang jauh dari kelas prediksi yang sebenarnya. Selain itu, model, dengan mempertimbangkan kedekatan visual dan semantik, dapat dengan benar mengklasifikasikan gambar yang terkait dengan kelas yang tidak terwakili dalam kumpulan data pelatihan.
Algoritma Arsitektur
- Kami pra-melatih model bahasa, yang memberikan embeddings semantik bermakna baik. Dimensi ruang adalah n. Selanjutnya, n akan diambil sama dengan 500 atau 1000.
- Kami melatih model visual, yang mengklasifikasikan objek menjadi 1000 kelas.
- Kami memotong lapisan softmax terakhir dari model visual pra-terlatih dan menambahkan lapisan yang terhubung penuh dari 4096 ke n neuron. Kami melatih model yang dihasilkan untuk setiap gambar untuk memprediksi penyematan yang sesuai dengan label gambar.
Mari kita jelaskan dengan bantuan pemetaan. Biarkan LM menjadi model bahasa, VM menjadi model visual dengan memotong softmax dan lapisan yang terhubung penuh menambahkan, I - image, L - label gambar, LM (L) - label embedding di ruang semantik. Kemudian pada langkah ketiga kami melatih VM sehingga:
Arsitektur:
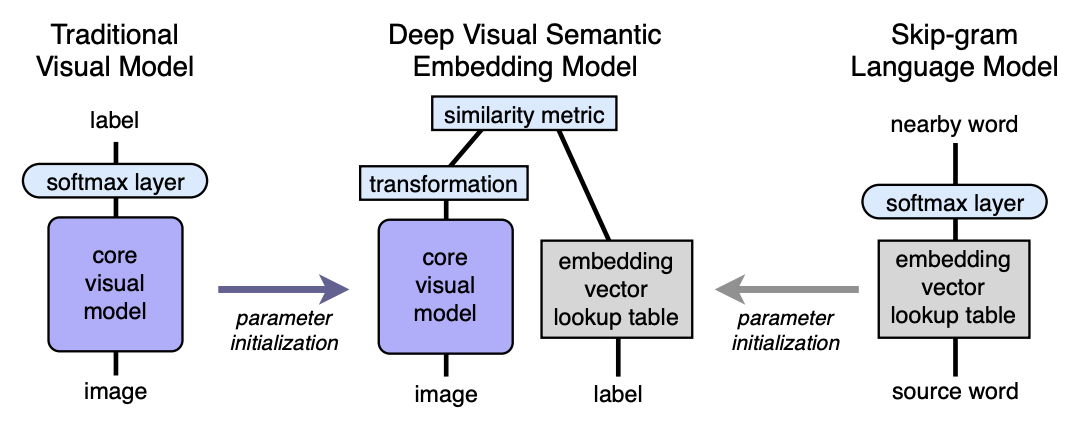
Model bahasa
Untuk mempelajari model bahasa, model skip-gram digunakan, kumpulan 5,4 miliar kata yang diambil dari wikipedia.org. Model ini menggunakan lapisan softmax hierarkis untuk memprediksi konsep terkait, jendela - 20 kata, jumlah lintasan melalui tubuh - 1. Secara eksperimental ditetapkan bahwa ukuran embedding lebih baik untuk mengambil 500-1000.
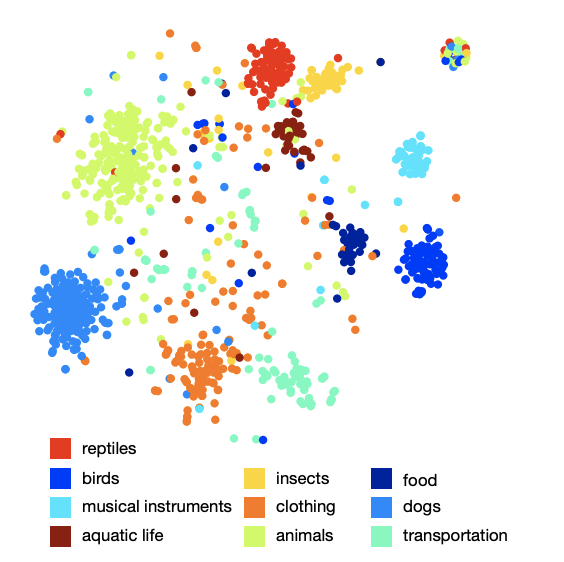
Gambar pengaturan kelas di ruang angkasa menunjukkan bahwa model tersebut telah mempelajari struktur semantik yang kualitatif dan kaya. Misalnya, untuk spesies hiu tertentu di ruang semantik yang dihasilkan, 9 tetangga terdekat adalah 9 jenis hiu lainnya.
Model visual
Arsitektur yang memenangkan kompetisi ILSVRC 2012 diambil sebagai model visual. Softmax dihapus di dalamnya dan lapisan yang terhubung penuh ditambahkan untuk mendapatkan ukuran embedding yang diinginkan pada output.
Fungsi kerugian
Ternyata pilihan fungsi kerugian itu penting. Kombinasi kesamaan cosinus dan kehilangan peringkat engsel digunakan. Fungsi kerugian mendorong produk skalar yang lebih besar antara vektor hasil jaringan visual dan embedding label yang sesuai, dan didenda untuk produk skalar besar antara hasil jaringan visual dan embedding dari label gambar acak yang mungkin. Jumlah label acak acak tidak tetap, tetapi dibatasi oleh kondisi di mana, jumlah produk skalar dengan label palsu menjadi lebih dari produk skalar dengan label yang valid dikurangi margin tetap (konstan sama dengan 0,1). Tentu saja, semua vektor sudah dinormalisasi.
Proses pelatihan
Pada awalnya, hanya lapisan yang terhubung sepenuhnya ditambahkan terakhir dilatih, sisa jaringan tidak memperbarui berat. Dalam hal ini, metode optimasi SGD digunakan. Kemudian seluruh jaringan visual dicairkan dan dilatih menggunakan pengoptimal Adagrad sehingga selama propagasi balik pada lapisan jaringan yang berbeda skala gradien dengan benar.
Prediksi
Selama prediksi, dari gambar menggunakan jaringan visual, kami mendapatkan beberapa vektor di ruang semantik kami. Selanjutnya, kami menemukan tetangga terdekat, yaitu, beberapa label yang mungkin dan dengan cara khusus menampilkannya kembali di sinkronisasi ImageNet untuk penilaian. Prosedur untuk tampilan terakhir tidak begitu sederhana, karena label di ImageNet adalah serangkaian sinonim, bukan hanya satu label. Jika pembaca tertarik untuk mengetahui perinciannya, saya merekomendasikan artikel aslinya (lampiran 2).
Hasil
Hasil dari model DEVISE dibandingkan dengan dua model:
- Model dasar Softmax - model visi canggih (SOTA - pada saat publikasi)
- Model embedding acak adalah versi dari model DEVISE yang dijelaskan, di mana embedding tidak dipelajari oleh model bahasa, tetapi diinisialisasi secara sewenang-wenang.
Untuk menilai kualitas, metrik hit "k" datar dan metrik presisi @ k hirarki digunakan. Metrik “flat” hit @ k adalah persentase gambar uji yang labelnya benar ada di antara opsi k yang diprediksi pertama. Metrik presisi @ k hirarki digunakan untuk mengevaluasi kualitas korespondensi semantik. Metrik ini didasarkan pada hierarki label di ImageNet. Untuk setiap label sejati dan k tetap, himpunan
label yang benar secara semantik - daftar kebenaran tanah. Mendapatkan prediksi (tetangga terdekat) adalah persentase persimpangan dengan daftar kebenaran dasar.

Para penulis berharap bahwa model softmax harus menunjukkan hasil terbaik pada metrik datar karena fakta bahwa meminimalkan kerugian lintas-entropi, yang sangat cocok untuk metrik hit "k" datar. Para penulis terkejut seberapa dekat model DEVISE dengan model softmax, mencapai paritas pada k besar dan bahkan menyalip pada k = 20.
Pada metrik hierarkis, model DEVISE menunjukkan dirinya dengan segala kemuliaan dan menyalip baseball softmax sebesar 3% untuk k = 5 dan sebesar 7% untuk k = 20.
Belajar tanpa tembakan
Keuntungan khusus dari model DEVISE adalah kemampuan untuk memberikan prediksi yang memadai untuk gambar yang label jaringannya tidak pernah lihat selama pelatihan. Misalnya, selama pelatihan, jaringan melihat gambar menandai hiu harimau, hiu banteng, dan hiu biru dan tidak pernah bertemu tanda hiu. Karena model bahasa memiliki representasi untuk hiu di ruang semantik dan dekat dengan embedding dari berbagai jenis hiu, model ini sangat mungkin memberikan prediksi yang memadai. Ini disebut kemampuan untuk menggeneralisasi - generalisasi.
Mari kita tunjukkan beberapa contoh prediksi Zero-Shot:

Perhatikan bahwa model DEVISE, bahkan dalam asumsi yang keliru, lebih dekat ke jawaban yang benar daripada asumsi yang salah dari model softmax.
Jadi, model yang disajikan kehilangan sedikit ke softmax ke garis dasar pada metrik datar, tetapi secara signifikan menang pada metrik presisi @ k metrik. Model ini memiliki kemampuan untuk menggeneralisasi, menghasilkan prediksi yang memadai untuk gambar yang label jaringannya belum terpenuhi (pembelajaran zero-shot).
Pendekatan yang dideskripsikan dapat dengan mudah diimplementasikan, karena didasarkan pada dua model pra-terlatih - bahasa dan visual.