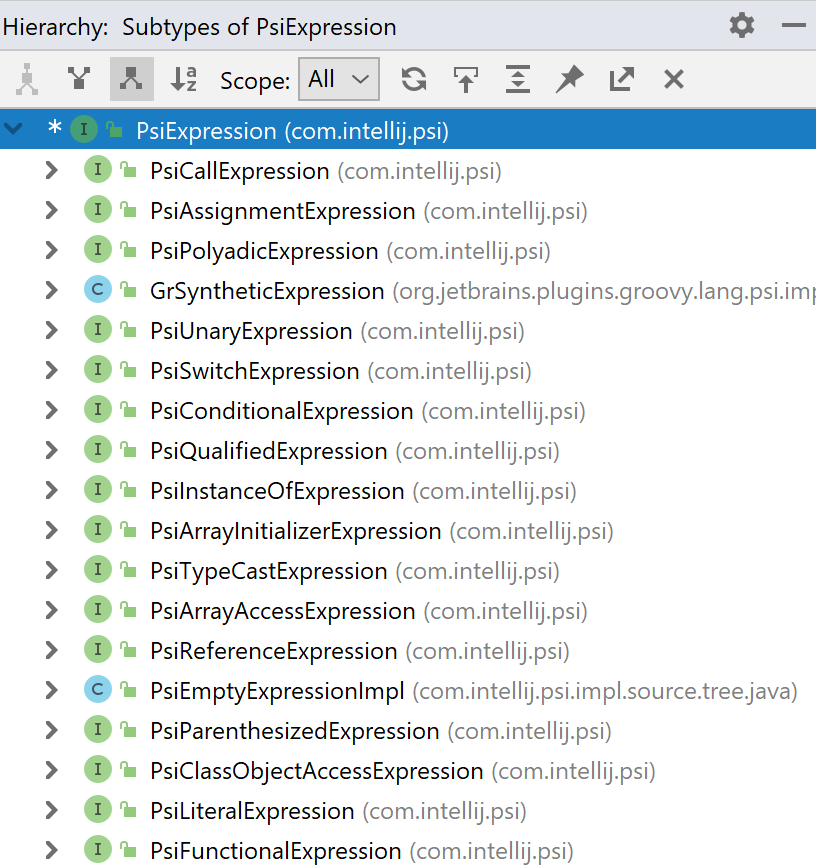
 Pencarian dan navigasi kode adalah fitur penting dari setiap IDE. Di Jawa, salah satu opsi pencarian yang umum digunakan adalah mencari semua implementasi antarmuka. Fitur ini sering disebut Type Hierarchy, dan tampilannya persis seperti gambar di sebelah kanan.
Pencarian dan navigasi kode adalah fitur penting dari setiap IDE. Di Jawa, salah satu opsi pencarian yang umum digunakan adalah mencari semua implementasi antarmuka. Fitur ini sering disebut Type Hierarchy, dan tampilannya persis seperti gambar di sebelah kanan.
Tidak efisien untuk mengulangi semua kelas proyek ketika fitur ini dipanggil. Salah satu opsi adalah untuk menyimpan hierarki kelas yang lengkap dalam indeks selama kompilasi karena kompiler tetap membuatnya. Kami melakukan ini ketika kompilasi dijalankan oleh IDE dan tidak didelegasikan, misalnya, ke Gradle. Tetapi ini hanya berfungsi jika tidak ada yang berubah dalam modul setelah kompilasi. Secara umum, kode sumber adalah penyedia informasi terbaru, dan indeks didasarkan pada kode sumber.
Menemukan anak langsung adalah tugas sederhana jika kita tidak berurusan dengan antarmuka fungsional. Saat mencari implementasi dari antarmuka Foo , kita perlu menemukan semua kelas yang implements Foo dan antarmuka yang telah extends Foo , serta kelas anonim new Foo(...) {...} . Untuk melakukan ini, cukup membangun pohon sintaksis dari setiap file proyek terlebih dahulu, menemukan konstruk yang sesuai, dan menambahkannya ke indeks. Namun, ada kerumitan di sini: Anda mungkin mencari antarmuka com.example.goodcompany.Foo , sedangkan org.example.evilcompany.Foo sebenarnya digunakan. Bisakah kita memasukkan nama lengkap antarmuka induk ke dalam indeks terlebih dahulu? Ini bisa rumit. Misalnya, file tempat antarmuka digunakan mungkin terlihat seperti ini:
Dengan melihat file itu sendiri, tidak mungkin untuk mengetahui apa nama Foo benar-benar memenuhi syarat. Kami harus melihat isi beberapa paket. Dan setiap paket dapat didefinisikan di beberapa tempat dalam proyek (misalnya, dalam beberapa file JAR). Jika kami melakukan resolusi simbol yang tepat saat menganalisis file ini, pengindeksan akan membutuhkan banyak waktu. Tetapi masalah utama adalah bahwa indeks yang dibangun di atas MyFoo.java akan tergantung pada file lain juga. Kita dapat memindahkan deklarasi antarmuka Foo , misalnya, dari paket org.example.foo ke paket org.example.bar , tanpa mengubah apa pun di file MyFoo.java , tetapi nama Foo sepenuhnya memenuhi syarat akan berubah.
Di IntelliJ IDEA, indeks hanya bergantung pada konten dari satu file. Di satu sisi, itu sangat nyaman: indeks yang terkait dengan file tertentu menjadi tidak valid ketika file diubah. Di sisi lain, itu memberlakukan batasan besar pada apa yang dapat dimasukkan ke dalam indeks. Misalnya, itu tidak memungkinkan nama kelas induk yang memenuhi syarat untuk disimpan secara andal dalam indeks. Tapi, secara umum, itu tidak terlalu buruk. Saat meminta hierarki jenis, kami dapat menemukan semua yang cocok dengan permintaan kami dengan nama pendek, dan kemudian melakukan resolusi simbol yang tepat untuk file-file ini dan menentukan apakah itu yang kami cari. Dalam kebanyakan kasus, tidak akan ada terlalu banyak simbol yang berlebihan dan pemeriksaan tidak akan lama.
 Namun, banyak hal berubah ketika kelas yang anak-anaknya kita cari adalah antarmuka fungsional. Kemudian, selain subclass eksplisit dan anonim, akan ada ekspresi lambda dan referensi metode. Apa yang kita masukkan ke dalam indeks sekarang, dan apa yang harus dievaluasi selama pencarian?
Namun, banyak hal berubah ketika kelas yang anak-anaknya kita cari adalah antarmuka fungsional. Kemudian, selain subclass eksplisit dan anonim, akan ada ekspresi lambda dan referensi metode. Apa yang kita masukkan ke dalam indeks sekarang, dan apa yang harus dievaluasi selama pencarian?
Mari kita asumsikan kita memiliki antarmuka fungsional:
@FunctionalInterface public interface StringConsumer { void consume(String s); }
Kode berisi berbagai ekspresi lambda. Misalnya:
() -> {}
Ini berarti kita dapat dengan cepat menyaring lambdas yang memiliki jumlah parameter yang tidak sesuai atau jenis pengembalian yang jelas tidak tepat, misalnya, batal bukannya tidak batal. Biasanya tidak mungkin untuk menentukan jenis pengembalian lebih tepat. Misalnya, dalam s -> list.add(s) Anda harus menyelesaikan list dan add , dan, mungkin, menjalankan prosedur inferensi tipe biasa. Butuh waktu dan tergantung pada konten file lain.
Kami beruntung jika antarmuka fungsional membutuhkan lima argumen. Tetapi jika hanya membutuhkan satu, filter akan menyimpan sejumlah besar lambda yang tidak perlu. Ini bahkan lebih buruk ketika sampai ke referensi metode. Ngomong-ngomong, orang tidak bisa memastikan apakah referensi metode cocok atau tidak.
Untuk memperbaikinya, mungkin ada baiknya melihat apa yang mengelilingi lambda. Terkadang berhasil. Misalnya:
Dalam semua kasus ini, nama pendek dari antarmuka fungsional yang sesuai dapat ditentukan dari file saat ini dan dapat dimasukkan ke dalam indeks di sebelah ekspresi fungsional, baik itu lambda atau referensi metode. Sayangnya, dalam proyek kehidupan nyata, kasus-kasus ini mencakup persentase yang sangat kecil dari semua lambda. Dalam kebanyakan kasus, lambdas digunakan sebagai argumen metode:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
Manakah dari tiga lambda yang dapat berisi StringConsumer ? Jelas, tidak ada. Di sini kami memiliki rantai Stream API yang hanya menampilkan antarmuka fungsional dari pustaka standar, itu tidak dapat memiliki jenis kustom.
Namun, IDE harus dapat melihat triknya dan memberi kami jawaban yang tepat. Bagaimana jika list tidak sepenuhnya java.util.List , dan list.stream() mengembalikan sesuatu yang berbeda dari java.util.stream.Stream ? Maka kita harus menyelesaikan list , yang, seperti yang kita ketahui, tidak dapat dilakukan hanya berdasarkan pada konten file saat ini. Dan bahkan jika kita melakukannya, pencarian tidak harus bergantung pada implementasi perpustakaan standar. Bagaimana jika dalam proyek khusus ini kita telah mengganti java.util.List dengan kelas kita sendiri? Pencarian harus memperhitungkan ini. Dan, tentu saja, lambda digunakan tidak hanya dalam aliran standar: ada banyak metode lain yang dilewati.
Akibatnya, kami dapat meminta indeks untuk daftar semua file Java yang menggunakan lambdas dengan jumlah parameter yang diperlukan dan jenis pengembalian yang valid (pada kenyataannya, kami hanya mencari empat opsi: void, non-void, boolean, dan ada). Dan selanjutnya apa? Apakah kita perlu membangun pohon PSI lengkap (semacam pohon parse dengan resolusi simbol, tipe inferensi, dan fitur pintar lainnya) untuk masing-masing file ini dan melakukan inferensi tipe yang tepat untuk lambda? Untuk proyek besar, perlu waktu lama untuk mendapatkan daftar semua implementasi antarmuka, meskipun hanya ada dua.
Jadi, kita perlu mengambil langkah-langkah berikut:
- Tanyakan indeks (tidak mahal)
- Bangun PSI (mahal)
- Jenis Infer lambda (sangat mahal)
Untuk Java 8 dan yang lebih baru, ketik inferensi adalah operasi yang sangat mahal. Dalam rantai panggilan yang kompleks, mungkin ada banyak parameter generik pengganti, nilai-nilai yang harus ditentukan menggunakan prosedur memukul keras yang dijelaskan dalam Bab 18 dari spesifikasi. Untuk file saat ini, ini dapat dilakukan di latar belakang, tetapi memproses ribuan file yang belum dibuka dengan cara ini akan menjadi tugas yang mahal.
Namun, di sini dimungkinkan untuk sedikit memotong sudut: dalam banyak kasus, kita tidak memerlukan jenis beton. Kecuali suatu metode menerima parameter generik di mana lambda diteruskan ke sana, langkah substitusi parameter akhir dapat dihindari. Jika kami telah menyimpulkan fungsi java.util.function.Function<T, R> lambda, kami tidak perlu mengevaluasi nilai-nilai parameter substitusi T dan R : sudah jelas apakah akan menyertakan lambda ke dalam hasil pencarian atau tidak. Namun, itu tidak akan berfungsi untuk metode seperti ini:
static <T> void doSmth(Class<T> aClass, T value) {}
Metode ini dapat dipanggil dengan doSmth(Runnable.class, () -> {}) . Maka jenis lambda akan disimpulkan sebagai T , masih diperlukan penggantian. Namun, ini adalah kasus yang jarang terjadi. Kita sebenarnya dapat menghemat waktu CPU di sini, tetapi hanya sekitar 10%, jadi ini tidak menyelesaikan masalah pada intinya.
Atau, ketika inferensi tipe yang tepat terlalu rumit, dapat dibuat perkiraan. Berbeda dengan spesifikasi yang disarankan, biarkan itu bekerja hanya pada tipe kelas yang terhapus dan tidak mengurangi set kendala, tetapi cukup ikuti rantai panggilan. Selama tipe yang dihapus tidak menyertakan parameter generik, semuanya baik-baik saja. Mari pertimbangkan aliran dari contoh di atas dan tentukan apakah lambda terakhir mengimplementasikan StringConsumer :
list variabel -> tipe java.util.ListList.stream() → tipe java.util.stream.StreamStream.filter(...) -> tipe java.util.stream.Stream , kita tidak perlu mempertimbangkan argumen filter- demikian pula,
Stream.map(...) → tipe java.util.stream.Stream Stream.forEach(...) → metode seperti itu ada, parameternya memiliki tipe Consumer , yang jelas bukan StringConsumer .
Dan itulah yang bisa kami lakukan tanpa inferensi tipe biasa. Namun, dengan pendekatan sederhana ini, mudah untuk mengalami metode kelebihan beban. Jika kami tidak melakukan inferensi jenis yang tepat, kami tidak dapat memilih metode kelebihan beban yang benar. Namun terkadang itu mungkin: jika metode memiliki jumlah parameter yang berbeda. Sebagai contoh:
CompletableFuture.supplyAsync(Foo::bar, myExecutor).thenRunAsync(s -> list.add(s));
Di sini kita dapat melihat bahwa:
- Ada dua metode
CompletableFuture.supplyAsync ; yang pertama mengambil satu argumen dan yang kedua mengambil dua, jadi kami memilih yang kedua. Ini mengembalikan CompletableFuture . - Ada dua metode
thenRunAsync juga, dan kita juga bisa memilih salah satu yang mengambil satu argumen. Parameter yang sesuai memiliki tipe Runnable , yang berarti bukan StringConsumer .
Jika beberapa metode mengambil jumlah parameter yang sama atau memiliki jumlah parameter yang bervariasi tetapi terlihat sesuai, kita harus mencari semua opsi. Seringkali itu tidak menakutkan:
new StringBuilder().append(foo).append(bar).chars().forEach(s -> list.add(s));
new StringBuilder() jelas menciptakan java.lang.StringBuilder . Untuk konstruktor, kami masih menyelesaikan referensi, tetapi inferensi tipe kompleks tidak diperlukan di sini. Bahkan jika ada new Foo<>(x, y, z) , kami tidak akan menyimpulkan nilai-nilai parameter tipe karena hanya Foo yang menarik bagi kami.- Ada banyak metode
StringBuilder.append yang mengambil satu argumen, tetapi mereka semua mengembalikan tipe java.lang.StringBuilder , jadi kami tidak peduli tentang jenis foo dan bar . - Ada satu metode
StringBuilder.chars , dan ia mengembalikan java.util.stream.IntStream . - Ada metode
IntStream.forEach tunggal, dan dibutuhkan tipe IntConsumer .
Bahkan jika beberapa opsi tetap ada, Anda masih dapat melacak semuanya. Misalnya, tipe lambda yang diteruskan ke ForkJoinPool.getInstance().submit(...) mungkin Runnable atau Callable , dan jika kami mencari opsi lain, kami masih dapat membuang lambda ini.
Hal-hal menjadi lebih buruk ketika metode mengembalikan parameter generik. Maka prosedur gagal dan Anda harus melakukan inferensi jenis yang tepat. Namun, kami mendukung satu kasus. Itu ditampilkan dengan baik di perpustakaan StreamEx saya, yang memiliki AbstractStreamEx<T, S extends AbstractStreamEx<T, S>> kelas abstrak yang berisi metode seperti S filter(Predicate<? super T> predicate) . Biasanya orang bekerja dengan kelas StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> konkret StreamEx<T> extends AbstractStreamEx<T, StreamEx<T>> . Dalam hal ini, Anda dapat mengganti parameter tipe dan mengetahui bahwa S = StreamEx .
Begitulah cara kami menghilangkan inferensi tipe mahal untuk banyak kasus. Tapi kami belum melakukan apa pun dengan pembangunan PSI. Mengecewakan karena mengurai file dengan 500 baris kode hanya untuk mengetahui bahwa lambda on line 480 tidak cocok dengan kueri kami. Mari kita kembali ke aliran kita:
list.stream() .filter(s -> StringUtil.isNonEmpty(s)) .map(s -> s.trim()) .forEach(s -> list.add(s));
Jika list adalah variabel lokal, parameter metode, atau bidang dalam kelas saat ini, sudah pada tahap pengindeksan, kita dapat menemukan deklarasi dan menetapkan bahwa nama tipe pendek adalah List . Dengan demikian, kita dapat memasukkan informasi berikut ke dalam indeks untuk lambda terakhir:
Tipe lambda ini adalah tipe parameter dari metode forEach yang mengambil satu argumen, dipanggil pada hasil metode map yang mengambil satu argumen, dipanggil pada hasil metode filter yang mengambil satu argumen, dipanggil pada hasil dari metode stream yang mengambil nol argumen, dipanggil pada objek List .
Semua informasi ini tersedia dari file saat ini dan, oleh karena itu, dapat ditempatkan dalam indeks. Saat mencari, kami meminta informasi tersebut tentang semua lambda dari indeks dan mencoba untuk mengembalikan jenis lambda tanpa membangun PSI. Pertama, kita harus melakukan pencarian global untuk kelas dengan nama List pendek. Jelas, kita akan menemukan tidak hanya java.util.List tetapi juga java.awt.List atau sesuatu dari kode proyek. Selanjutnya, semua kelas ini akan melalui prosedur inferensi tipe perkiraan yang sama yang kami gunakan sebelumnya. Kelas redundan seringkali dengan cepat disaring. Sebagai contoh, java.awt.List tidak memiliki metode stream , oleh karena itu akan dikecualikan. Tetapi bahkan jika sesuatu yang berlebihan tetap ada dan kami menemukan beberapa kandidat untuk jenis lambda, kemungkinan tidak satupun dari mereka akan cocok dengan permintaan pencarian, dan kami masih akan menghindari membangun PSI lengkap.
Pencarian global bisa menjadi terlalu mahal (ketika sebuah proyek mengandung terlalu banyak kelas List ), atau awal rantai tidak dapat diselesaikan dalam konteks satu file (katakanlah, itu adalah bidang kelas induk), atau rantai bisa pecah ketika metode mengembalikan parameter generik. Kami tidak akan menyerah dan akan mencoba memulai kembali dengan pencarian global pada metode rantai berikutnya. Misalnya, untuk map.get(key).updateAndGet(a -> a * 2) , instruksi berikut masuk ke indeks:
Tipe lambda ini adalah tipe parameter tunggal dari metode updateAndGet , dipanggil pada hasil metode get dengan satu parameter, dipanggil pada objek Map .
Bayangkan kita beruntung, dan proyek ini hanya memiliki satu tipe Map java.util.Map . Itu memang memiliki metode get(Object) , tetapi, sayangnya, ia mengembalikan parameter generik V Kemudian kita akan membuang rantai dan mencari metode updateAndGet dengan satu parameter secara global (tentu saja menggunakan indeks). Dan kami senang mengetahui bahwa hanya ada tiga metode dalam proyek ini: di kelas AtomicInteger , AtomicLong , dan AtomicReference dengan tipe parameter IntUnaryOperator , LongUnaryOperator , dan UnaryOperator . Jika kami mencari jenis lain, kami telah menemukan bahwa lambda ini tidak cocok dengan permintaan, dan kami tidak harus membuat PSI.
Anehnya, ini adalah contoh yang bagus dari fitur yang bekerja lebih lambat dengan waktu. Misalnya, ketika Anda mencari implementasi antarmuka fungsional dan hanya memiliki tiga di antaranya dalam proyek Anda, dibutuhkan sepuluh detik bagi IntelliJ IDEA untuk menemukannya. Anda ingat bahwa tiga tahun lalu jumlah mereka sama, tetapi IDE memberi Anda hasil pencarian hanya dalam dua detik pada mesin yang sama. Dan meskipun proyek Anda sangat besar, hanya tumbuh lima persen selama bertahun-tahun ini. Masuk akal untuk mulai menggerutu tentang kesalahan yang dilakukan pengembang IDE untuk membuatnya sangat lambat.
Meskipun kita mungkin tidak mengubah apa pun. Pencarian berfungsi seperti dulu tiga tahun lalu. Masalahnya adalah bahwa tiga tahun yang lalu, Anda baru saja beralih ke Java 8 dan hanya memiliki seratus lambda di proyek Anda. Sekarang, kolega Anda telah mengubah kelas anonim menjadi lambdas, sudah mulai menggunakan stream atau perpustakaan reaktif. Hasilnya, alih-alih seratus lambda, ada sepuluh ribu. Dan sekarang, untuk menemukan tiga yang diperlukan, IDE harus mencari opsi seratus kali lebih banyak.
Saya berkata "kami mungkin" karena, tentu saja, kami kembali ke pencarian ini dari waktu ke waktu dan mencoba mempercepatnya. Tapi itu seperti mendayung di sungai, atau lebih tepatnya di air terjun. Kami berusaha keras, tetapi jumlah lambda dalam proyek terus tumbuh sangat cepat.