Pasar untuk komputasi terdistribusi dan data besar, menurut
statistik , tumbuh 18-19% per tahun. Jadi, pertanyaan memilih perangkat lunak untuk keperluan ini tetap relevan. Dalam posting ini, kita akan mulai dengan mengapa komputasi terdistribusi diperlukan, berkutat pada pilihan perangkat lunak, berbicara tentang penggunaan Hadoop dengan Cloudera, dan akhirnya, mari kita bicara tentang memilih perangkat keras dan bagaimana hal itu memengaruhi kinerja dalam berbagai cara.
Mengapa kita perlu komputasi terdistribusi dalam bisnis reguler? Semuanya sederhana dan rumit pada saat bersamaan. Sederhana - karena dalam kebanyakan kasus kami melakukan perhitungan yang relatif sederhana per unit informasi. Itu sulit karena ada banyak informasi seperti itu. Banyak. Akibatnya, Anda harus
memproses terabyte data dalam 1000 utas . Dengan demikian, skenario penggunaannya cukup universal: perhitungan dapat diterapkan di mana pun perlu untuk memperhitungkan sejumlah besar metrik pada susunan data yang lebih besar.
Satu contoh baru-baru ini: rantai restoran pizza Dodo
ditentukan berdasarkan analisis basis pesanan pelanggan bahwa ketika memilih pizza dengan isian yang sewenang-wenang, pengguna biasanya beroperasi hanya dengan enam set bahan dasar ditambah beberapa yang acak. Sesuai dengan ini, restoran pizza menyesuaikan pembelian. Selain itu, ia dapat merekomendasikan lebih baik kepada pengguna produk tambahan yang ditawarkan pada tahap pemesanan, yang membantu meningkatkan keuntungan.
Contoh lain:
analisis posisi komoditas memungkinkan toko H&M mengurangi kisaran di toko individu sebesar 40%, sambil mempertahankan tingkat penjualan. Ini dicapai dengan menghilangkan posisi penjualan yang buruk, dan musiman diperhitungkan dalam perhitungan.
Pemilihan alat
Standar industri untuk jenis komputasi ini adalah Hadoop. Mengapa Karena Hadoop adalah kerangka kerja yang sangat baik dan terdokumentasi dengan baik (Habr yang sama mengeluarkan banyak artikel terperinci tentang topik ini), yang disertai dengan serangkaian perangkat utilitas dan perpustakaan. Anda dapat memasukkan kumpulan besar data terstruktur dan tidak terstruktur, dan sistem itu sendiri akan mendistribusikannya di antara daya komputasi. Selain itu, kapasitas yang sama ini dapat ditingkatkan atau dinonaktifkan kapan saja - skalabilitas horizontal yang sama dalam aksi.
Pada 2017, perusahaan konsultan berpengaruh Gartner
menyimpulkan bahwa Hadoop akan segera menjadi usang. Alasannya cukup dangkal: analis percaya bahwa perusahaan akan secara besar-besaran bermigrasi ke cloud, karena di sana mereka dapat membayar fakta menggunakan daya komputasi. Faktor penting kedua, konon bisa "mengubur" Hadoop - adalah kecepatan kerja. Karena opsi seperti Apache Spark atau Google Cloud DataFlow lebih cepat daripada Hadoop yang mendasari MapReduce.
Hadoop bertumpu pada beberapa pilar, yang paling terkenal adalah teknologi MapReduce (sistem distribusi data untuk komputasi antar server) dan sistem file HDFS. Yang terakhir ini dirancang khusus untuk menyimpan informasi yang didistribusikan antara node dalam sebuah cluster: setiap blok dengan ukuran tetap dapat ditempatkan pada beberapa node, dan berkat replikasi, sistem ini kebal terhadap kegagalan node individu. Alih-alih tabel file, server khusus bernama NameNode digunakan.
Ilustrasi di bawah ini menunjukkan alur kerja MapReduce. Pada tahap pertama, data dibagi menurut karakteristik tertentu, pada tahap kedua - mereka didistribusikan sesuai dengan daya komputasi, pada tahap ketiga - perhitungan dilakukan.
MapReduce pada awalnya dibuat oleh Google untuk kebutuhan pencariannya. Kemudian MapReduce masuk ke kode gratis, dan Apache mengambil proyek. Yah, Google secara bertahap telah bermigrasi ke solusi lain. Nuansa yang menarik: saat ini Google memiliki proyek bernama Google Cloud Dataflow, yang diposisikan sebagai langkah berikutnya setelah Hadoop, sebagai pengganti cepat.
Pandangan yang lebih dekat mengungkapkan bahwa Google Cloud Dataflow didasarkan pada berbagai Apache Beam, sementara Apache Beam menyertakan kerangka kerja Apache Spark yang terdokumentasi dengan baik, yang memungkinkan kita untuk berbicara tentang kecepatan eksekusi keputusan yang hampir sama. Nah, Apache Spark berfungsi dengan baik pada sistem file HDFS, yang memungkinkan Anda untuk menyebarkannya ke server Hadoop.
Kami menambahkan di sini volume dokumentasi dan solusi turnkey untuk Hadoop dan Spark terhadap Google Cloud Dataflow, dan pilihan alat menjadi jelas. Selain itu, insinyur dapat memutuskan sendiri kode mana - di bawah Hadoop atau Spark - yang akan dieksekusi untuk mereka, dengan fokus pada tugas, pengalaman, dan kualifikasi.
Cloud atau server lokal
Tren menuju transisi universal ke cloud bahkan telah menghasilkan istilah yang menarik seperti Hadoop-as-a-service. Dalam skenario ini, administrasi server yang terhubung menjadi sangat penting. Karena, sayangnya, terlepas dari popularitasnya, Hadoop murni adalah alat yang cukup sulit untuk dikonfigurasi, karena banyak hal harus dilakukan dengan tangan Anda. Sebagai contoh, secara individual mengkonfigurasi server, memantau kinerjanya, dengan hati-hati mengkonfigurasi banyak parameter. Secara umum, bekerja untuk seorang amatir adalah peluang besar untuk mengacaukan sesuatu atau melewatkan sesuatu.
Oleh karena itu, berbagai distribusi, yang pada awalnya dilengkapi dengan penyebaran yang mudah dan alat administrasi, memperoleh popularitas besar. Salah satu distribusi paling populer yang mendukung Spark dan mempermudah semuanya adalah Cloudera. Ini memiliki versi berbayar dan gratis - dan yang terakhir semua fungsi dasar tersedia, dan tanpa membatasi jumlah node.

Selama pengaturan, Cloudera Manager akan terhubung melalui SSH ke server Anda. Suatu hal yang menarik: selama instalasi lebih baik untuk menunjukkan bahwa itu harus dilakukan oleh
paket yang disebut: paket khusus, yang masing-masing berisi semua komponen yang diperlukan yang dikonfigurasi untuk saling bekerja sama. Sebenarnya, ini adalah versi yang lebih baik dari manajer paket.
Setelah instalasi, kami mendapatkan konsol manajemen cluster, di mana Anda dapat melihat telemetri demi cluster, layanan yang diinstal, plus Anda dapat menambah / menghapus sumber daya dan mengedit konfigurasi cluster.
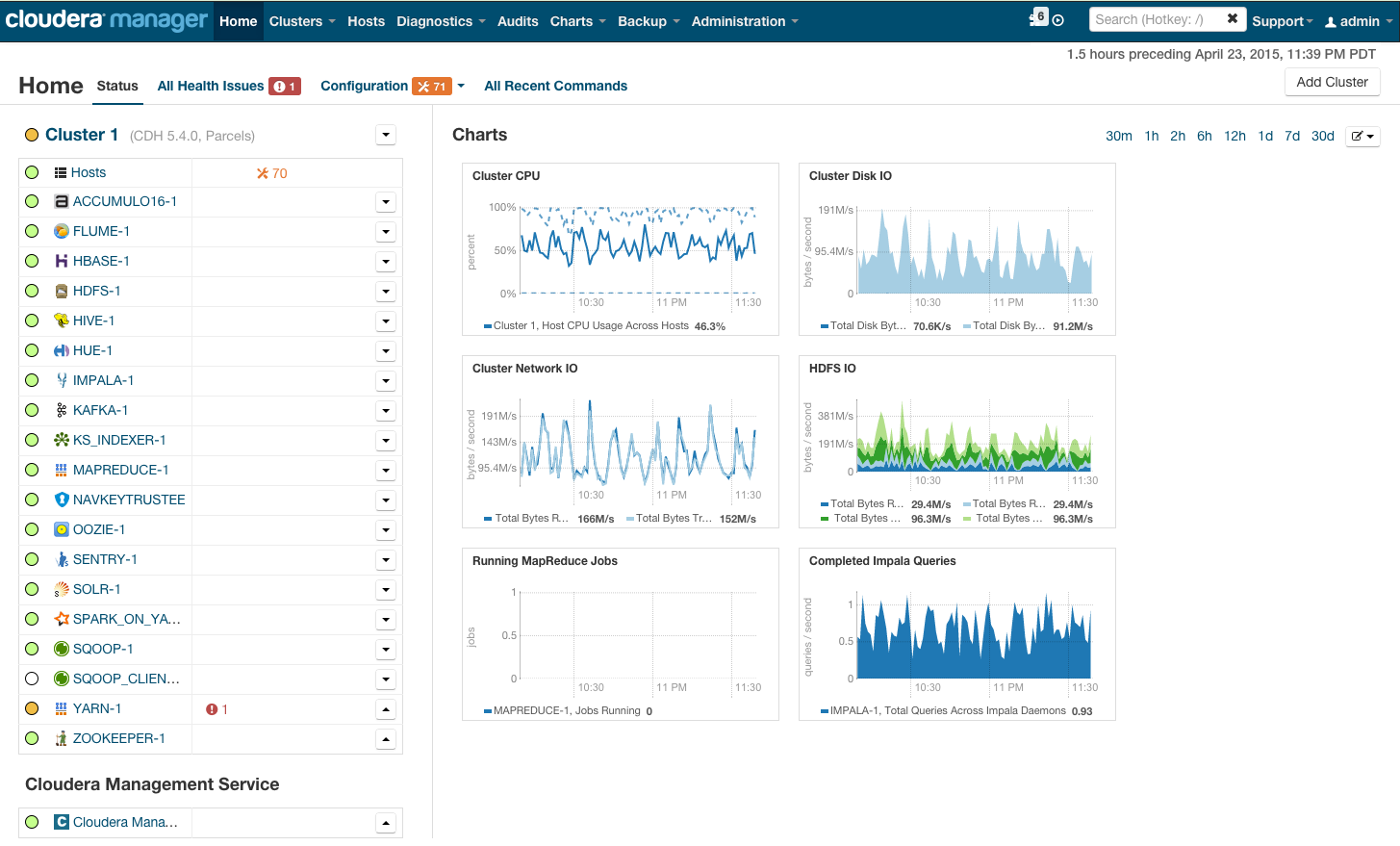
Hasilnya, Anda melihat kabin roket yang akan membawa Anda ke masa depan BigData yang cerah. Tetapi sebelum Anda mengatakan "ayo pergi," mari masuk ke bawah tenda.
Persyaratan perangkat keras
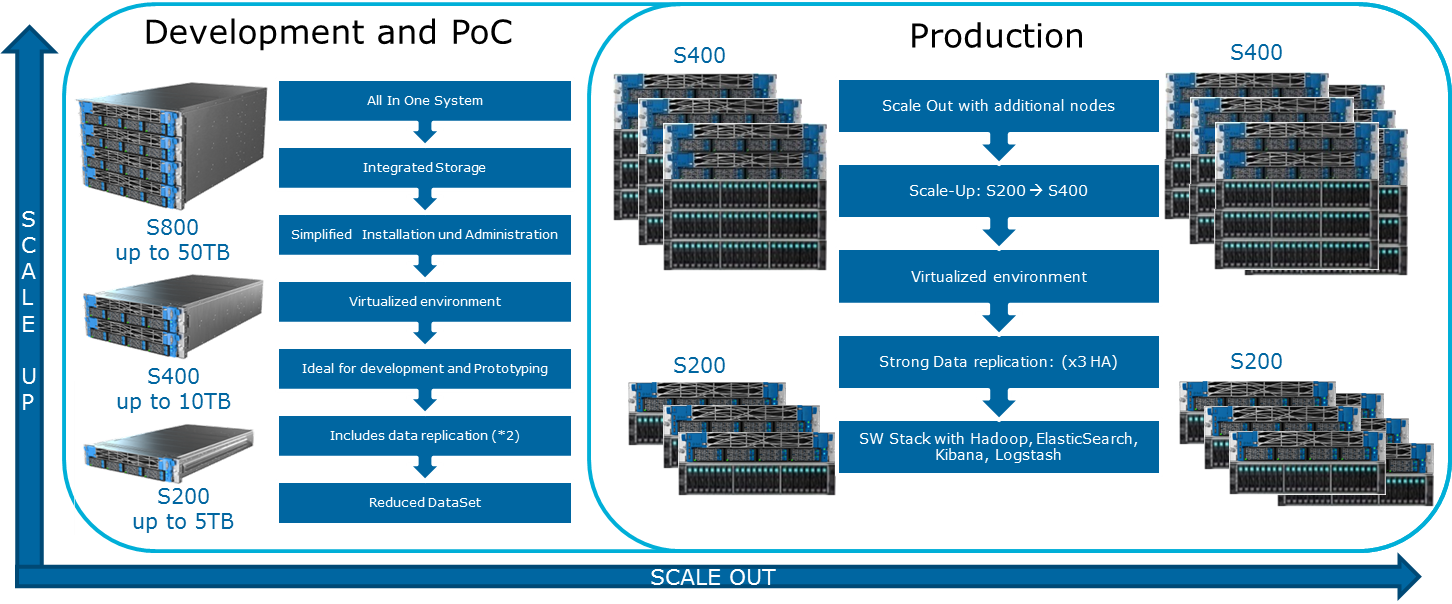
Cloudera menyebutkan berbagai kemungkinan konfigurasi di situs webnya. Prinsip-prinsip umum di mana mereka dibangun ditunjukkan dalam ilustrasi:
Untuk melumasi gambar optimis ini dapat MapReduce. Jika Anda melihat kembali pada diagram dari bagian sebelumnya, menjadi jelas bahwa dalam hampir semua kasus pekerjaan MapReduce dapat mengalami hambatan ketika membaca data dari disk atau dari jaringan. Ini juga ditampilkan di blog Cloudera. Akibatnya, untuk perhitungan cepat apa pun, termasuk melalui Spark, yang sering digunakan untuk perhitungan waktu nyata, kecepatan I / O sangat penting. Oleh karena itu, ketika menggunakan Hadoop, sangat penting bahwa mesin yang seimbang dan cepat masuk ke cluster, yang, jika dikatakan ringan, tidak selalu disediakan dalam infrastruktur cloud.
Balancing load balancing dicapai melalui penggunaan virtualisasi Openstack pada server dengan CPU multi-core yang kuat. Node data dialokasikan sumber daya prosesor dan disk spesifiknya. Dalam solusi
Atos Codex Data Lake Engine kami , virtualisasi luas tercapai, itulah sebabnya kami memenangkan keduanya dalam kinerja (pengaruh infrastruktur jaringan diminimalkan) dan di TCO (server fisik yang tidak perlu dihilangkan).
Dalam hal menggunakan server BullSequana S200, kami mendapatkan beban yang sangat seragam, tanpa hambatan. Konfigurasi minimum mencakup 3 server BullSequana S200, masing-masing dengan dua JBOD, ditambah S200 tambahan opsional yang berisi empat node data yang secara opsional terhubung. Berikut ini contoh beban dalam tes TeraGen:
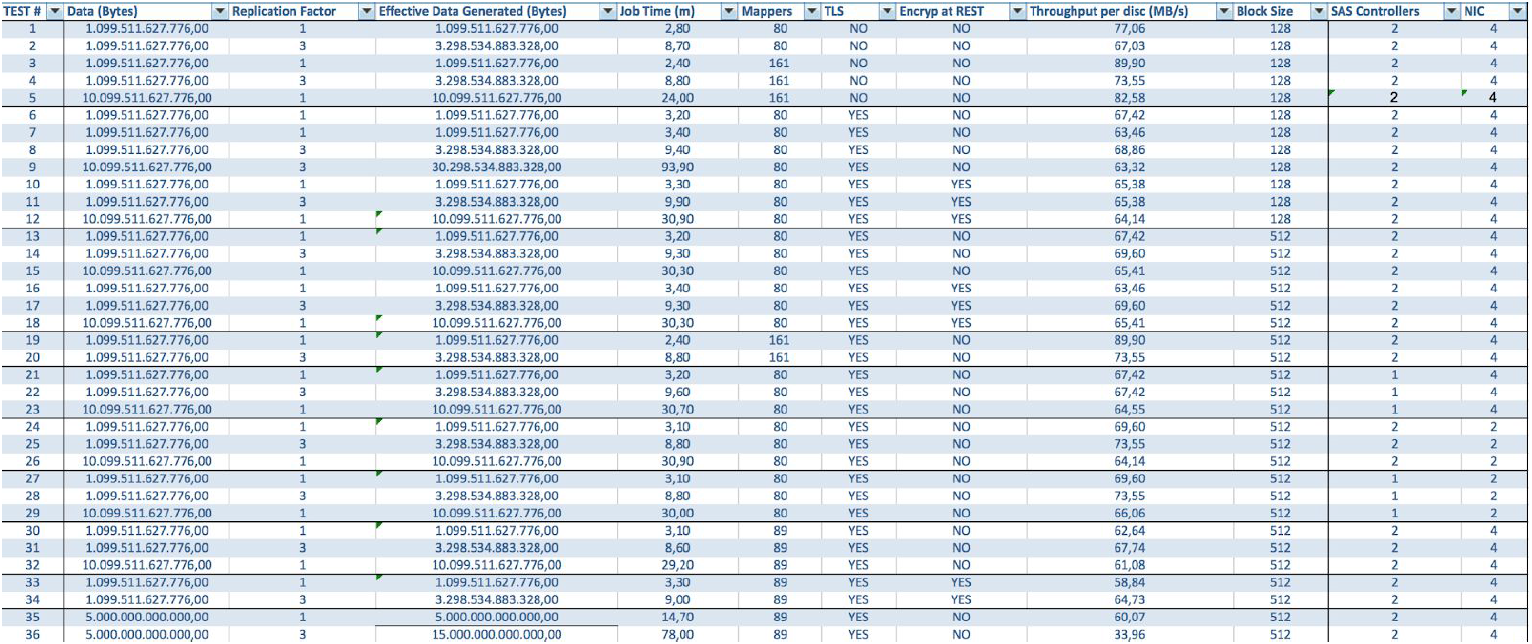
Pengujian dengan volume data dan nilai replikasi yang berbeda menunjukkan hasil yang sama dalam hal penyeimbangan beban antara node cluster. Di bawah ini adalah grafik distribusi akses disk dengan tes kinerja.
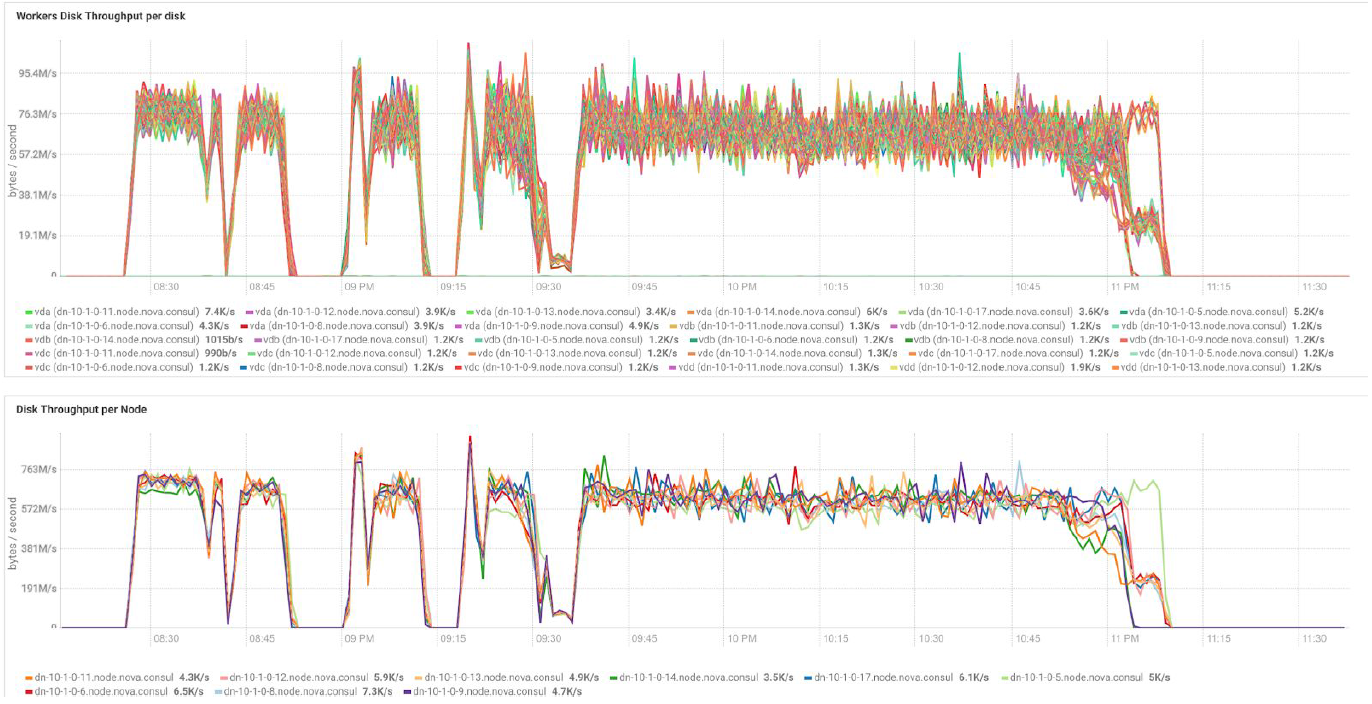
Perhitungan didasarkan pada konfigurasi minimum 3 server BullSequana S200. Ini mencakup 9 node data dan 3 node utama, serta mesin virtual yang disediakan dalam kasus penyebaran perlindungan berdasarkan OpenStack Virtualization. Hasil tes TeraSort: ukuran blok 512 MB dari koefisien replikasi tiga dengan enkripsi adalah 23,1 menit.
Bagaimana saya bisa memperluas sistem? Berbagai jenis ekstensi tersedia untuk Mesin Danau Data:
- Node Data: Untuk setiap 40 TB ruang yang dapat digunakan
- Node analitik dengan kemampuan untuk menginstal GPU
- Pilihan lain tergantung pada kebutuhan bisnis (misalnya, jika Anda memerlukan Kafka dan sejenisnya)
Atos Codex Data Lake Engine mencakup server itu sendiri dan perangkat lunak yang sudah diinstal sebelumnya, termasuk suite Cloudera berlisensi; Hadoop sendiri, OpenStack dengan mesin virtual berbasis pada kernel RedHat Enterprise Linux, sistem replikasi data dan cadangan (termasuk menggunakan node cadangan dan Cloudera BDR - Backup and Disaster Recovery). Atos Codex Data Lake Engine adalah solusi virtualisasi pertama yang disertifikasi oleh
Cloudera .
Jika Anda tertarik dengan detailnya, kami akan dengan senang hati menjawab pertanyaan kami di komentar.