
Halo, Habr! Deskripsi operasi bagian dalam platform pembayaran besar akan secara logis dilanjutkan dengan deskripsi tentang bagaimana sebenarnya semua komponen ini bekerja di dunia nyata pada perangkat keras fisik. Di pos ini, saya berbicara tentang bagaimana dan di mana aplikasi platform berada, bagaimana lalu lintas dari dunia luar menjangkau mereka, dan saya juga akan menjelaskan skema rak standar untuk kami dengan peralatan yang berlokasi di salah satu pusat data kami.
Pendekatan dan Keterbatasan

Salah satu persyaratan pertama yang kami formulasikan sebelum pengembangan platform terdengar seperti "kemampuan untuk skala sumber daya komputasi linear untuk memastikan pemrosesan sejumlah transaksi."
Pendekatan klasik sistem berbayar yang digunakan oleh pelaku pasar menyiratkan adanya plafon, meskipun agak tinggi menurut pernyataan tersebut. Biasanya terdengar seperti ini: "pemrosesan kami dapat menerima 1000 transaksi per detik."
Pendekatan ini tidak sesuai dengan tujuan dan arsitektur bisnis kami. Kami tidak ingin memiliki batasan apa pun. Bahkan, akan aneh mendengar dari Yandex atau Google pernyataan "kami dapat memproses 1 juta pencarian per detik." Platform harus memproses sebanyak mungkin permintaan yang dibutuhkan bisnis saat ini karena arsitekturnya, yang memungkinkan, secara sederhana, mengirim pekerja TI dengan troli server, yang akan dipasangnya di rak, terhubung ke sakelar dan pergi. Dan orkestra platform akan meluncurkan salinan instance aplikasi bisnis ke kapasitas baru, sebagai akibatnya kita akan mendapatkan peningkatan RPS yang kita butuhkan.
Persyaratan penting kedua adalah memastikan ketersediaan layanan yang tinggi. Akan lucu, tetapi tidak terlalu berguna, untuk membuat platform pembayaran yang dapat menerima jumlah pembayaran tanpa batas di / dev / null.
Mungkin cara paling efektif untuk mencapai ketersediaan tinggi adalah dengan menduplikasi entitas yang melayani layanan berkali-kali sehingga kegagalan sejumlah aplikasi, peralatan, atau pusat data yang masuk akal tidak memengaruhi ketersediaan platform secara keseluruhan.
Duplikasi beberapa aplikasi membutuhkan sejumlah besar server fisik dan peralatan jaringan terkait. Zat besi ini membutuhkan uang, jumlah yang kita miliki tentu saja, kita tidak mampu membeli banyak besi mahal. Jadi platform dirancang sedemikian rupa agar mudah mengakomodasi dan merasa nyaman dengan sejumlah besar besi yang murah dan tidak terlalu kuat, atau bahkan di cloud publik.
Penggunaan server yang bukan yang terkuat dalam hal daya komputasi memiliki kelebihan - kegagalannya tidak memiliki efek kritis pada kondisi umum sistem secara keseluruhan. Bayangkan apa yang lebih baik - jika server merek yang mahal, besar dan dapat diandalkan membakar, menjalankan DBMS sesuai dengan skema master-slave (dan menurut hukum Murphy, itu pasti akan terbakar, dan pada malam hari tanggal 31 Desember) atau beberapa server dalam gugus 30 node yang berjalan tanpa master diagram?
Berdasarkan logika ini, kami memutuskan untuk tidak membuat titik kegagalan besar lainnya dalam bentuk array disk terpusat. Perangkat blok umum diberikan kepada kami oleh cluster Ceph, yang digunakan hiper-konvergen pada server yang sama, tetapi dengan infrastruktur jaringan yang terpisah.
Jadi, kami secara logis sampai pada skema umum rak universal dengan sumber daya komputasi dalam bentuk server yang murah dan tidak terlalu kuat di pusat data. Jika kita membutuhkan lebih banyak sumber daya, kita bisa menyelesaikan setiap rak gratis dengan server, atau menempatkan yang lain, lebih disukai lebih dekat.

Yah, pada akhirnya, itu sangat indah. Ketika jumlah yang jelas dari besi yang sama dipasang di rak, ini memungkinkan Anda untuk memecahkan masalah dengan kualitas peletakan kawat, memungkinkan Anda untuk menyingkirkan sarang burung walet dan bahaya terjerat dalam kabel, menjatuhkan pemrosesan. Yang baik dari sudut pandang teknik, sistem harus indah di mana-mana - baik dari dalam dalam bentuk kode, dan luar dalam bentuk server dan perangkat keras jaringan. Sistem yang indah bekerja lebih baik dan lebih andal, saya punya cukup contoh untuk memverifikasi ini dari pengalaman saya sendiri.
Tolong jangan berpikir bahwa kita adalah penjahat atau bisnis itu terjepit oleh pembiayaan. Mengembangkan dan memelihara platform terdistribusi sebenarnya adalah kesenangan yang sangat mahal. Bahkan, ini bahkan lebih mahal daripada memiliki sistem klasik, dibangun, secara kondisional, pada perangkat keras bermerek yang kuat dengan Oracle / MSSQL, server aplikasi dan binding lainnya.
Pendekatan kami terbayar dengan keandalan tinggi, kemampuan penskalaan horizontal yang sangat fleksibel, tidak adanya plafon dalam jumlah pembayaran per detik, dan betapa pun aneh kedengarannya - sangat menyenangkan bagi tim TI. Bagi saya, tingkat kesenangan pengembang dan pengembang dari sistem yang mereka buat tidak kalah penting dari perkiraan waktu pengembangan, kuantitas dan kualitas fitur yang diluncurkan.
Infrastruktur server

Secara logis, kapasitas server kami dapat dibagi menjadi dua kelas utama: server untuk hypervisor, yang kepadatan CPU dan core RAM per unit adalah penting, dan server penyimpanan, di mana penekanan utama adalah pada jumlah ruang disk per unit, dan CPU dan RAM sudah dipilih untuk jumlah disk.
Saat ini, server klasik kami untuk daya komputasi terlihat seperti ini:
- 2xXeon E5-2630 CPU;
- RAM 128G;
- 3xSATA SSD (Ceph SSD pool);
- 1xNVMe SSD (dm-cache).
Server untuk menyimpan status:
- 1xXeon E5-2630 CPU;
- 12-16 HDD;
- 2 SSD untuk block.db;
- RAM 32G.
Infrastruktur jaringan
Dalam pilihan perangkat keras jaringan, pendekatan kami agak berbeda. Kami masih menggunakan sakelar bermerek untuk beralih dan merutekan antar vlan-s, sekarang Cisco SG500X-48 dan Cisco Nexus C5020 di SAN.
Secara fisik, setiap server terhubung ke jaringan dengan 4 port fisik:
- 2x1GbE - jaringan manajemen dan RPC antar aplikasi;
- 2x10GbE - jaringan untuk penyimpanan.
Antarmuka di dalam mesin dikombinasikan dengan ikatan, lalu lintas yang ditandai divergen sesuai dengan vlan yang diinginkan.
Mungkin ini adalah satu-satunya tempat di infrastruktur kami di mana Anda dapat melihat label vendor terkenal. Karena untuk perutean, penyaringan jaringan dan inspeksi lalu lintas kami menggunakan host Linux. Kami tidak membeli router khusus. Semua yang kita butuhkan, kita konfigurasikan pada server yang menjalankan Gentoo (iptables untuk penyaringan, BIRD untuk routing dinamis, Suricata sebagai IDS / IPS, Wallarm sebagai WAF).
Rak khas di DC
Saat meningkatkan, rak di DC praktis tidak berbeda satu sama lain kecuali untuk router uplink, yang dipasang di salah satunya.
Proporsi yang tepat dari server dari kelas yang berbeda dapat bervariasi, tetapi secara umum, logikanya dipertahankan - ada lebih banyak server untuk komputasi daripada server untuk menyimpan data.
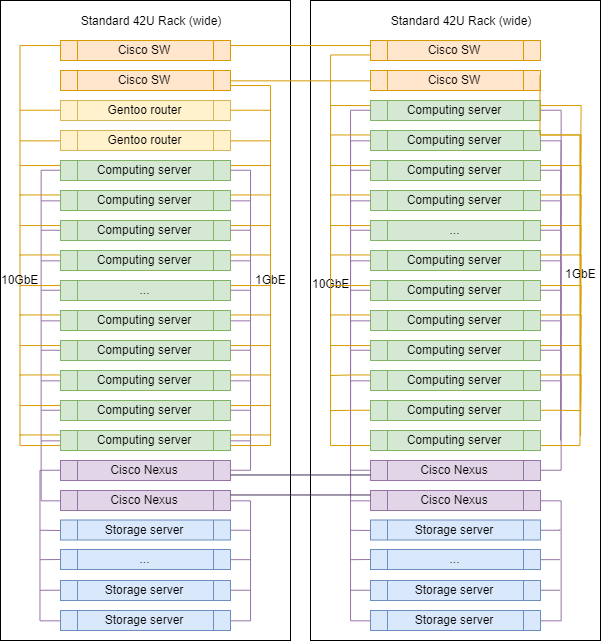
Blokir perangkat dan berbagi sumber daya
Mari kita coba menyatukan semuanya. Bayangkan bahwa kita perlu menempatkan beberapa layanan microser kami di dalam infrastruktur, untuk kejelasan yang lebih besar, ini akan berupa layanan microser yang perlu berkomunikasi satu sama lain melalui RPC dan salah satunya adalah Machinegun, yang menyimpan state dalam cluster Riak, serta beberapa layanan tambahan, seperti seperti ES dan node Consul.
Tata letak yang khas akan terlihat seperti ini:
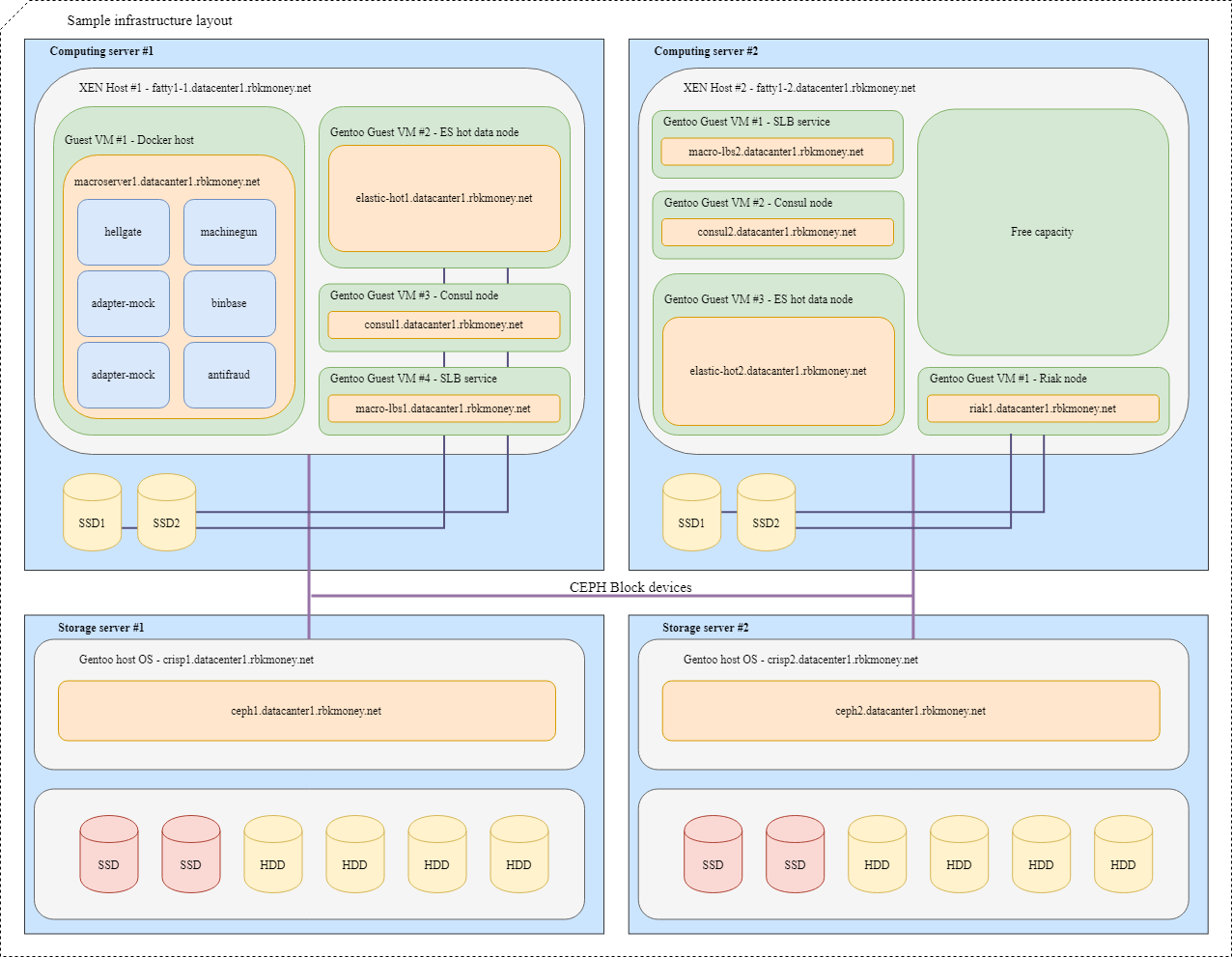
Untuk VM dengan aplikasi yang membutuhkan kecepatan blok perangkat maksimum, seperti hot node Riak dan Elasticsearch, partisi pada disk NVMe lokal digunakan. VM seperti itu melekat erat pada hypervisor mereka, dan aplikasi itu sendiri bertanggung jawab atas ketersediaan dan integritas data mereka.
Untuk perangkat blok umum, kami menggunakan Ceph RBD, biasanya dengan write-through dm-cache pada disk NVMe lokal. OSD untuk perangkat dapat berupa flash penuh atau HDD dengan log SSD, tergantung pada waktu respons yang diinginkan.
Pengiriman lalu lintas ke aplikasi
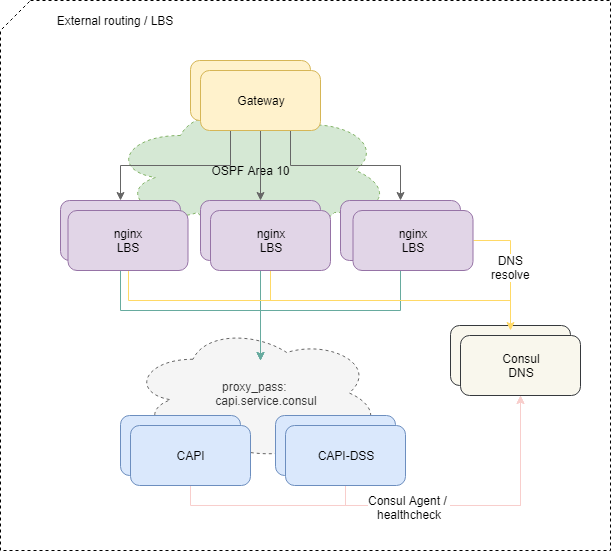
Untuk menyeimbangkan permintaan yang datang dari luar, kami menggunakan skema standar OSPFv3 ECMP. Mesin virtual kecil dengan nginx, bird, consul mengumumkan di OSPF cloud alamat anycast umum dari antarmuka lo. Pada router, untuk alamat-alamat ini, bird menciptakan rute multi-hop yang menyediakan penyeimbangan per-aliran, di mana alirannya adalah "src-ip src-port dst-ip dst-port". Untuk dengan cepat menonaktifkan penyeimbang yang hilang, protokol BFD digunakan.
Ketika menambah atau gagal salah satu penyeimbang, router hulu memiliki rute yang sesuai muncul atau dihapus, dan lalu lintas jaringan dikirimkan kepada mereka sesuai dengan pendekatan multi-jalur Equal-biaya. Dan jika kita tidak secara khusus melakukan intervensi, maka semua lalu lintas jaringan didistribusikan secara merata ke semua penyeimbang yang tersedia di setiap aliran IP.
Omong-omong, pendekatan dengan ECMP-balancing memiliki perangkap yang tidak jelas yang dapat menyebabkan hilangnya lalu lintas yang tidak jelas, terutama jika router lain atau firewall yang dikonfigurasi secara aneh berada di rute antara sistem.
Untuk mengatasi masalah tersebut, kami menggunakan daemon PMTUD di bagian infrastruktur ini.
Lebih lanjut, lalu lintas masuk ke dalam platform ke layanan microser tertentu sesuai dengan konfigurasi nginx pada balancers.
Dan jika menyeimbangkan lalu lintas eksternal lebih atau kurang sederhana dan dapat dimengerti, maka akan sulit untuk memperluas skema semacam itu lebih jauh ke dalam - kita perlu lebih dari sekadar memeriksa ketersediaan wadah dengan layanan mikro di tingkat jaringan.
Agar layanan mikro dapat mulai menerima dan memproses permintaan, ia harus mendaftar ke Service Discovery (kami menggunakan Konsul ), menjalani pemeriksaan kesehatan setiap detik dan memiliki RTT yang wajar.
Jika microservice merasa dan berperilaku baik, Konsul mulai menyelesaikan alamat wadahnya ketika mengakses DNS-nya dengan nama layanan. Kami menggunakan zona internal service.consul , dan, misalnya, microservice Common API versi 2 akan dinamai capi-v2.service.consul .
Konfigurasi nginx mengenai keseimbangan pada akhirnya terlihat seperti ini:
location = /v2/ { set $service_hostname "${staging_pass}capi-v2.service.consul"; proxy_pass http://$service_hostname:8022; }
Jadi, jika kita sekali lagi tidak melakukan intervensi dengan sengaja, lalu lintas dari penyeimbang didistribusikan secara merata di antara semua layanan microsoft yang terdaftar di Service Discovery, menambah atau menghapus instance baru dari layanan micro yang diperlukan sepenuhnya otomatis.
Jika permintaan dari penyeimbang naik, dan dia mati di jalan, kami mengembalikan 502 - penyeimbang di tingkatnya tidak dapat menentukan apakah permintaan itu idempoten atau tidak, jadi kami memberikan pemrosesan kesalahan tersebut ke tingkat logika yang lebih tinggi.
Idempotensi dan Tenggat Waktu
Secara umum, kami tidak takut dan tidak ragu untuk memberikan kesalahan 5xx dengan API, ini adalah bagian normal dari sistem jika Anda melakukan pemrosesan kesalahan tersebut dengan benar di tingkat logika bisnis RPC. Prinsip-prinsip pemrosesan ini dijelaskan dalam formulir kami sebagai manual kecil yang disebut Kebijakan Retry Errors, kami mendistribusikannya ke klien pedagang kami dan menerapkannya dalam layanan kami.
Untuk menyederhanakan proses ini, kami telah menerapkan beberapa pendekatan.
Pertama, untuk setiap permintaan yang diubah oleh negara untuk API kami, Anda dapat menentukan kunci idempotensi unik dalam akun, yang hidup selamanya dan memungkinkan Anda untuk memastikan bahwa panggilan berulang dengan set data yang sama akan mengembalikan jawaban yang sama.
Kedua, kami menerapkan mekanisme tambahan dalam bentuk pengidentifikasi unik untuk sesi pembayaran, yang menjamin idempotensi permintaan untuk mendebit dana, memberikan perlindungan terhadap debit berulang yang keliru, bahkan jika Anda tidak menghasilkan dan mengirimkan kunci idempotensi terpisah.
Ketiga, kami memutuskan untuk mengaktifkan waktu respons yang dapat diprediksi dan dikendalikan secara eksternal untuk setiap panggilan eksternal ke API kami dalam bentuk parameter cut-off time yang menentukan waktu tunggu maksimum untuk sebuah operasi untuk menyelesaikan atas permintaan. Cukup untuk mentransfer, misalnya, tajuk HTTP X-Request-Deadline: 10s untuk memastikan bahwa permintaan Anda akan dieksekusi dalam 10 detik atau akan dibunuh oleh platform di suatu tempat di dalam, setelah itu kami dapat dihubungi lagi, dipandu oleh meminta kebijakan penerusan.
Kami menggunakan SaltStack sebagai alat manajemen untuk konfigurasi dan infrastruktur secara keseluruhan. Alat terpisah untuk kontrol otomatis daya komputasi platform belum lepas landas, meskipun kami sudah memahami bahwa kami akan menuju ke arah ini. Dengan kecintaan kami pada produk Hashicorp, ini sepertinya Nomad.
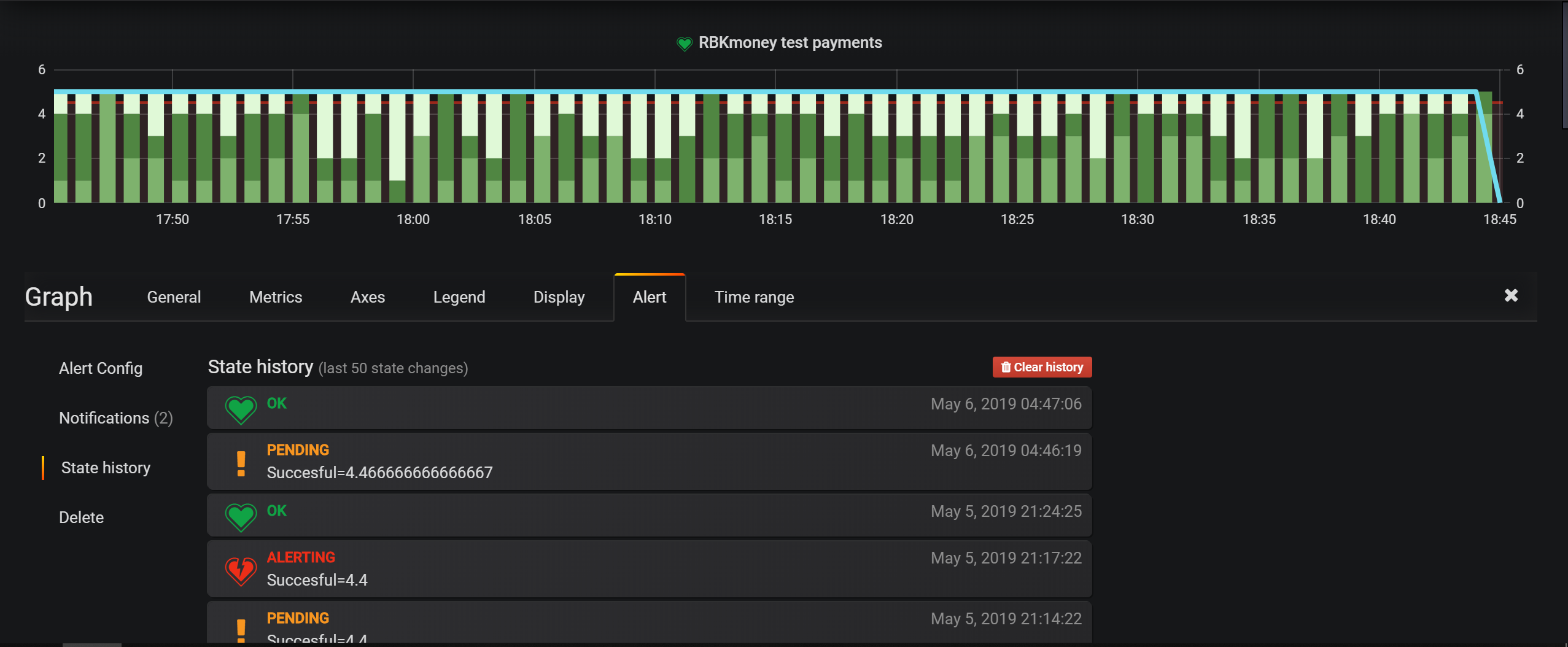
Alat pemantauan infrastruktur utama adalah pemeriksaan di Nagios, tetapi untuk entitas bisnis, kami terutama mengonfigurasi lansiran di Grafana. Ini memiliki alat yang sangat mudah untuk menetapkan kondisi, dan model platform berbasis peristiwa memungkinkan Anda untuk menulis semuanya untuk Elasticsearch dan mengonfigurasi kondisi pemilihan.
Pusat data terletak di Moskow, di dalamnya kami menyewa ruang rak, menginstal dan mengelola semua peralatan secara independen. Kami tidak menggunakan optik gelap di mana pun, kami hanya memiliki internet di luar dari penyedia lokal.
Kalau tidak, pendekatan kami untuk pemantauan, manajemen dan layanan terkait agak standar untuk industri, saya tidak yakin bahwa deskripsi selanjutnya dari integrasi layanan ini layak disebutkan dalam posting.
Pada artikel ini, saya mungkin akan mengakhiri serangkaian posting ulasan tentang bagaimana platform pembayaran kami diatur.
Saya pikir siklus itu ternyata cukup jujur, saya telah bertemu beberapa artikel yang akan mengungkapkan secara rinci dapur dalam sistem pembayaran besar.
Secara umum, menurut saya, tingkat keterbukaan dan keterbukaan yang tinggi adalah hal yang sangat penting untuk sistem pembayaran. Pendekatan ini tidak hanya meningkatkan tingkat kepercayaan mitra dan pembayar, tetapi juga mendisiplinkan tim, pencipta dan operator layanan.
Jadi, dipandu oleh prinsip ini, kami baru-baru ini membuat status platform dan riwayat uptime dari layanan kami tersedia untuk umum. Seluruh riwayat uptime, pembaruan, dan kerusakan kami selanjutnya bersifat publik dan tersedia di https://status.rbk.money/ .
Saya harap Anda tertarik, dan mungkin seseorang akan menemukan pendekatan kami dan kesalahan yang dijelaskan bermanfaat. Jika Anda tertarik pada salah satu bidang yang dijelaskan dalam pos, dan Anda ingin saya mengungkapkannya secara lebih rinci, jangan ragu untuk menulis di komentar atau di PM.
Terima kasih telah bersama kami!

NB Untuk kenyamanan Anda, arahkan ke artikel sebelumnya dalam seri: