Seperti di
sebagian besar posting , ada masalah dengan layanan terdistribusi, sebut saja layanan ini Alvin. Kali ini saya tidak menemukan masalah sendiri, orang-orang dari bagian klien memberi tahu saya.
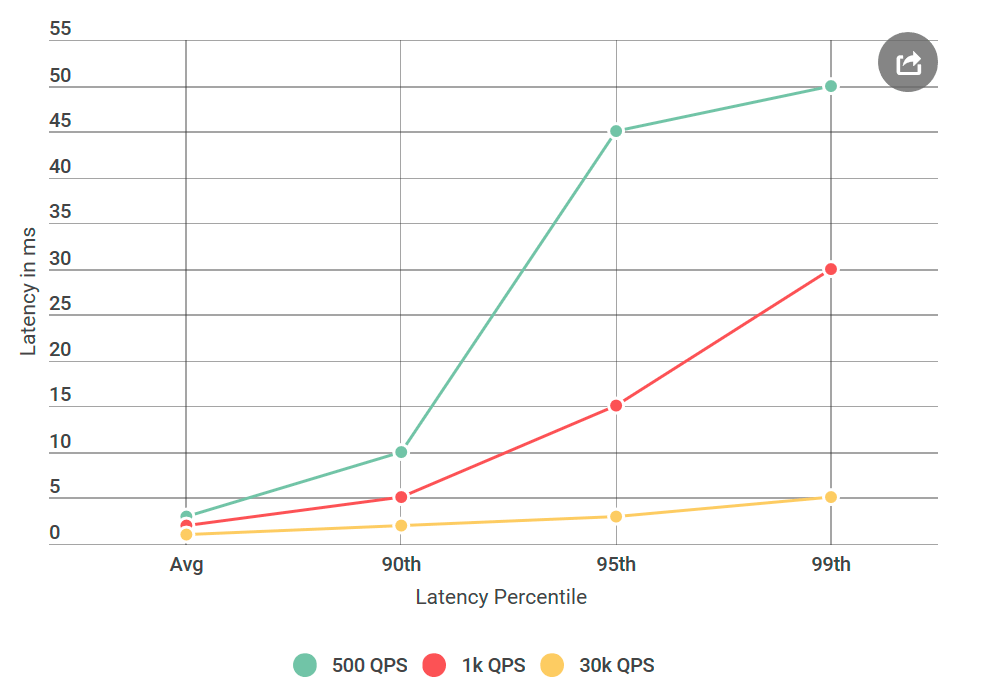
Suatu kali saya terbangun dari surat yang tidak puas karena keterlambatan besar Alvin, yang kami rencanakan untuk diluncurkan dalam waktu dekat. Secara khusus, klien mengalami keterlambatan persentil ke-99 di sekitar 50 ms, jauh di atas anggaran keterlambatan kami. Ini mengejutkan, karena saya benar-benar menguji layanan, terutama untuk keterlambatan, karena ini adalah masalah yang sering dikeluhkan.
Sebelum memberikan Alvin untuk pengujian, saya melakukan banyak percobaan dengan 40 ribu permintaan per detik (QPS), semua menunjukkan penundaan kurang dari 10 ms. Saya siap menyatakan bahwa saya tidak setuju dengan hasil mereka. Tetapi sekali lagi melihat surat itu, saya menarik perhatian pada sesuatu yang baru: Saya pasti tidak menguji kondisi yang mereka sebutkan, QPS mereka jauh lebih rendah daripada milik saya. Saya menguji pada 40k QPS, dan mereka hanya pada 1k. Saya menjalankan percobaan lain, kali ini dengan QPS lebih rendah, hanya untuk menyenangkan mereka.
Karena saya menulis tentang ini di blog saya, Anda mungkin sudah mengerti: jumlahnya ternyata benar. Saya menguji klien virtual saya lagi dan lagi, semua dengan hasil yang sama: sejumlah kecil permintaan tidak hanya meningkatkan penundaan, tetapi juga meningkatkan jumlah permintaan dengan penundaan lebih dari 10 ms. Dengan kata lain, jika pada 40k QPS sekitar 50 permintaan per detik melebihi 50 ms, maka pada 1k QPS setiap detik ada 100 permintaan di atas 50 ms. Paradoks!
Persempit pencarian Anda
Menghadapi masalah keterlambatan dalam sistem terdistribusi dengan banyak komponen, hal pertama yang perlu Anda lakukan adalah membuat daftar tersangka. Kami menggali sedikit lebih dalam tentang arsitektur Alvin:
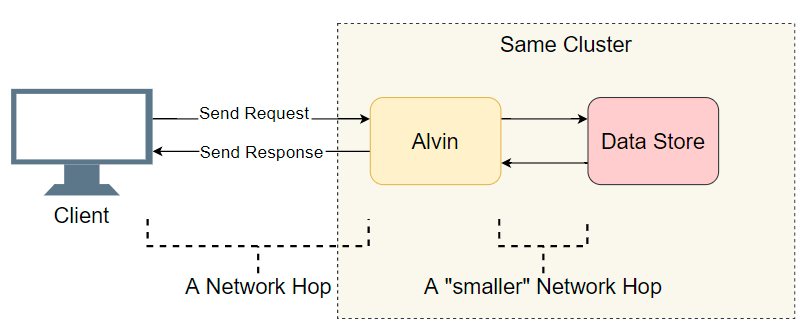
Titik awal yang baik adalah daftar transisi I / O yang telah selesai (panggilan jaringan / pencarian disk, dll.). Mari kita cari tahu di mana penundaannya. Selain I / O yang jelas dengan klien, Alvin mengambil langkah tambahan: dia mengakses data warehouse. Namun, penyimpanan ini berfungsi di kluster yang sama dengan Alvin, jadi seharusnya ada sedikit keterlambatan dibandingkan dengan klien. Jadi, daftar tersangka:
- Panggilan jaringan dari klien ke Alvin.
- Panggilan jaringan dari Alvin ke gudang data.
- Cari di disk di gudang data.
- Panggilan jaringan dari gudang data ke Alvin.
- Panggilan jaringan dari Alvin ke klien.
Mari kita coba mencoret beberapa poin.
Gudang Data
Hal pertama yang saya lakukan adalah mengonversi Alvin ke server ping-ping yang tidak menangani permintaan. Setelah menerima permintaan, itu mengembalikan respons kosong. Jika penundaan berkurang, maka kesalahan dalam implementasi Alvin atau data warehouse tidak pernah terdengar sebelumnya. Dalam percobaan pertama, kami mendapatkan grafik berikut:
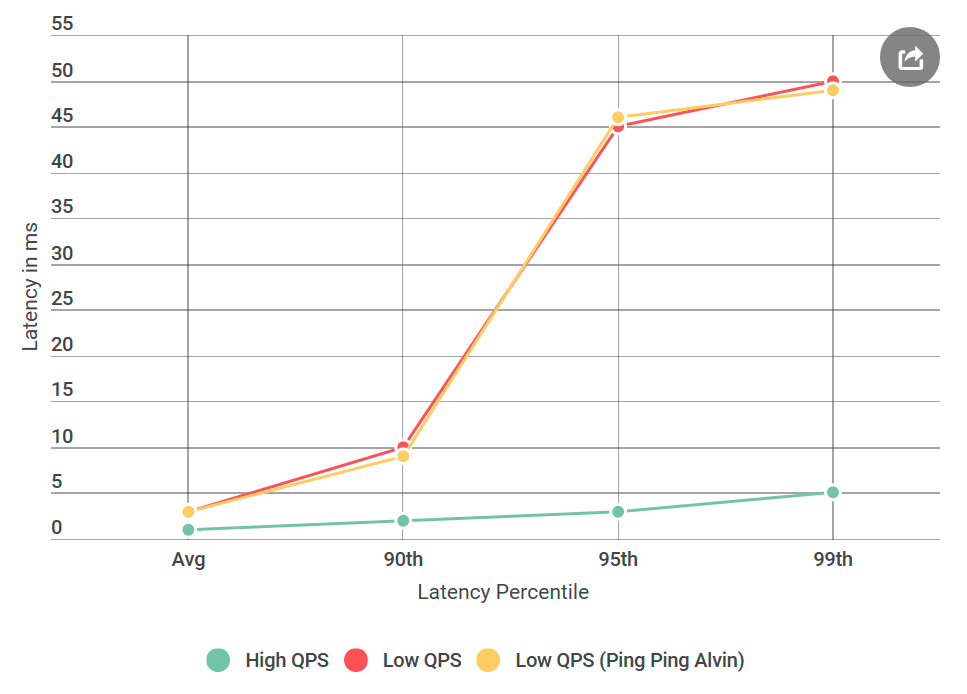
Seperti yang Anda lihat, saat menggunakan server ping-ping tidak ada peningkatan. Ini berarti bahwa gudang data tidak meningkatkan penundaan, dan daftar tersangka dibelah dua:
- Panggilan jaringan dari klien ke Alvin.
- Panggilan jaringan dari Alvin ke klien.
Wow! Daftar ini menyusut dengan cepat. Saya pikir saya hampir menemukan alasannya.
gRPC
Sekarang saatnya memperkenalkan Anda kepada pemain baru:
gRPC . Ini adalah pustaka sumber terbuka dari Google untuk komunikasi
RPC dalam proses. Meskipun
gRPC dioptimalkan dengan baik dan banyak digunakan, pertama kali saya menggunakannya pada sistem skala ini, dan saya berharap bahwa implementasi saya akan kurang optimal - untuk sedikitnya.
Kehadiran
gRPC di stack memunculkan pertanyaan baru: mungkin ini implementasi saya atau apakah
gRPC sendiri menyebabkan masalah keterlambatan? Tambahkan ke daftar tersangka baru:
- Klien memanggil pustaka
gRPC
- Pustaka
gRPC pada klien membuat panggilan jaringan ke pustaka gRPC di server
- Pustaka
gRPC mengakses Alvin (tidak ada operasi dalam kasus server ping-pong)
Untuk membuat Anda memahami seperti apa kode itu, implementasi klien / Alvin saya tidak jauh berbeda dengan
contoh -
contoh server klien
async .
Catatan: daftar di atas sedikit disederhanakan, karena gRPC memungkinkan Anda untuk menggunakan model aliran (templat?) Anda sendiri, di mana gRPC eksekusi gRPC dan implementasi pengguna saling terkait. Demi kesederhanaan, kami akan tetap berpegang pada model ini.
Profiling akan memperbaiki semuanya
Mencoret gudang data, saya pikir saya hampir selesai: “Sekarang mudah! Kami akan menerapkan profil dan mencari tahu di mana penundaan terjadi. " Saya
penggemar berat profil yang akurat karena CPU sangat cepat dan paling sering mereka tidak mengalami hambatan. Kebanyakan penundaan terjadi ketika prosesor harus berhenti memproses untuk melakukan sesuatu yang lain. Penentuan profil CPU yang tepat dilakukan hanya untuk ini: ia secara akurat mencatat semua
sakelar konteks dan memperjelas di mana terjadi keterlambatan.
Saya mengambil empat profil: di bawah QPS tinggi (latensi rendah) dan dengan server ping-pong pada QPS rendah (latensi tinggi), baik di sisi klien maupun di sisi server. Dan untuk berjaga-jaga, saya juga mengambil profil prosesor sampel. Saat membandingkan profil, saya biasanya mencari tumpukan panggilan yang tidak normal. Misalnya, di sisi buruk dengan penundaan tinggi, ada lebih banyak saklar konteks (10 kali atau lebih). Tetapi dalam kasus saya, jumlah konteks beralih hampir bersamaan. Yang membuatku ngeri, tidak ada yang signifikan di sana.
Debugging tambahan
Saya putus asa. Saya tidak tahu alat apa yang bisa digunakan, dan rencana saya selanjutnya adalah mengulang percobaan dengan variasi yang berbeda, dan tidak mendiagnosis masalah dengan jelas.
Bagaimana jika
Sejak awal, saya khawatir tentang waktu tunda spesifik 50 ms. Ini waktu yang sangat besar. Saya memutuskan bahwa saya akan memotong bagian-bagian dari kode sampai saya bisa mengetahui bagian mana yang menyebabkan kesalahan ini. Kemudian diikuti percobaan yang berhasil.
Seperti biasa, dengan pikiran belakang sepertinya semuanya sudah jelas. Saya menempatkan klien pada mesin yang sama dengan Alvin - dan mengirim permintaan ke
localhost . Dan peningkatan penundaan telah menghilang!
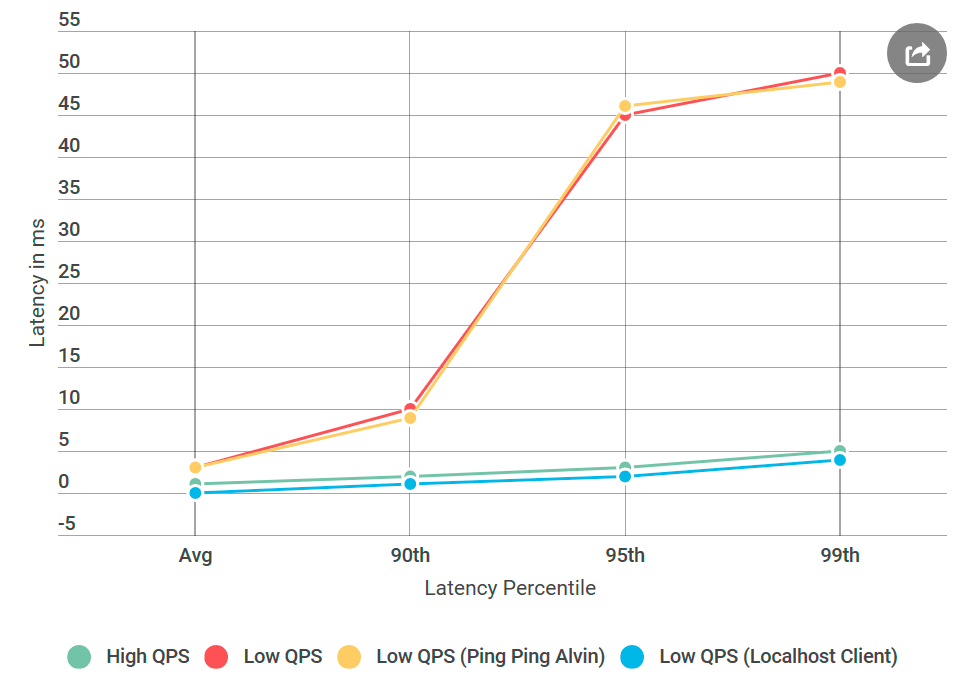
Ada yang salah dengan jaringan.
Mempelajari keterampilan seorang insinyur jaringan
Saya harus mengakui: pengetahuan saya tentang teknologi jaringan sangat buruk, terutama mengingat fakta bahwa saya bekerja dengan mereka setiap hari. Tetapi jaringan itu adalah tersangka utama, dan saya perlu belajar cara men-debug-nya.
Untungnya, Internet menyukai mereka yang ingin belajar. Kombinasi ping dan tracert tampaknya merupakan awal yang cukup baik untuk men-debug masalah transportasi jaringan.
Pertama, saya menjalankan
PsPing pada port TCP
Alvin . Saya menggunakan opsi default - tidak ada yang istimewa. Dari lebih dari seribu ping, tidak ada yang melebihi 10 ms, dengan pengecualian yang pertama untuk pemanasan. Ini bertentangan dengan peningkatan yang diamati dalam keterlambatan 50 ms dalam persentil ke-99: di sana, untuk setiap 100 permintaan, kita harus melihat tentang satu permintaan dengan penundaan 50 ms.
Lalu saya mencoba
tracert : mungkin masalahnya ada di salah satu node di sepanjang rute antara Alvin dan klien. Tapi pelacak itu kembali dengan tangan kosong.
Jadi, alasan penundaan itu bukan karena kode saya, bukan implementasi gRPC, dan bukan jaringan. Saya sudah mulai khawatir bahwa saya tidak akan pernah mengerti ini.
Sekarang apa OS kita
gRPC banyak digunakan di Linux, tetapi eksotis untuk Windows. Saya memutuskan untuk melakukan percobaan yang berhasil: Saya menciptakan mesin virtual Linux, mengkompilasi Alvin untuk Linux, dan menggunakannya.
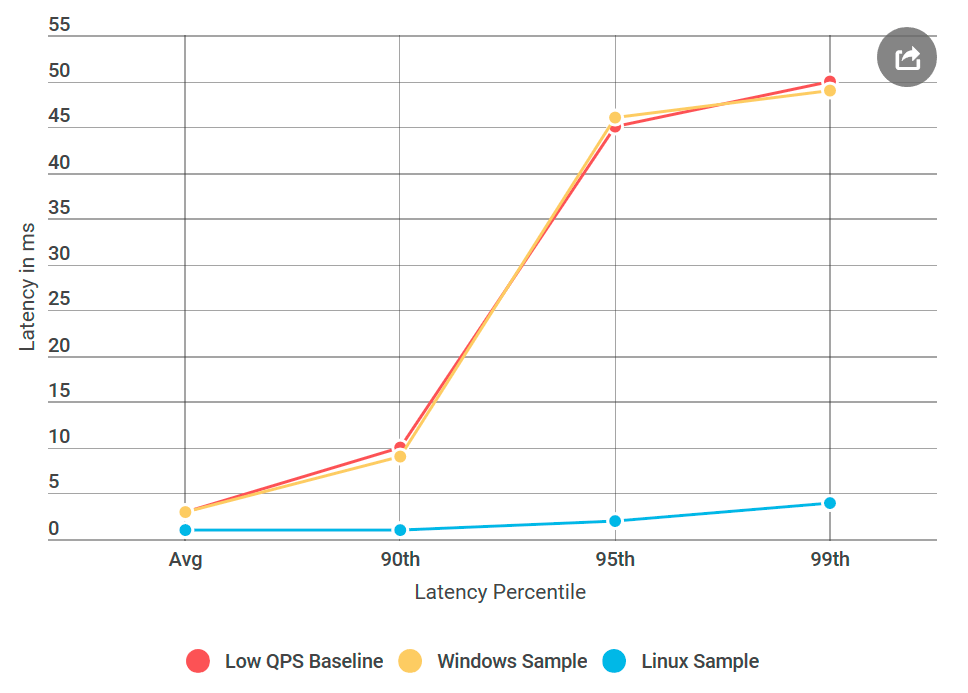
Dan inilah yang terjadi: server Linux ping-pong tidak memiliki penundaan seperti simpul Windows yang serupa, meskipun sumber data tidak berbeda. Ternyata masalahnya adalah dalam mengimplementasikan gRPC untuk Windows.
Algoritma Nagle
Selama ini, saya pikir saya kehilangan bendera
gRPC . Sekarang saya menyadari bahwa ini
gRPC tidak memiliki bendera Windows di
gRPC . Saya menemukan perpustakaan RPC internal, di mana saya yakin itu berfungsi dengan baik untuk semua flag
Winsock yang diinstal. Kemudian dia menambahkan semua flag ini ke gRPC dan menyebarkan Alvin ke Windows, di server ping-pong tetap untuk Windows!
 Hampir
Hampir selesai: Saya mulai menghapus bendera yang ditambahkan satu per satu sampai regresi kembali, sehingga saya dapat menentukan penyebabnya. Itu adalah
TCP_NODELAY yang terkenal, sebuah saklar dari algoritma Nagle.
Algoritme Neigl mencoba untuk mengurangi jumlah paket yang dikirim melalui jaringan dengan menunda pengiriman pesan hingga ukuran paket melebihi jumlah byte tertentu. Meskipun ini mungkin menyenangkan bagi pengguna rata-rata, ini merusak untuk server waktu-nyata, karena OS akan menunda beberapa pesan, menyebabkan keterlambatan pada QPS rendah.
gRPC menetapkan flag ini dalam implementasi Linux untuk soket TCP, tetapi tidak untuk Windows. Saya
memperbaikinya .
Kesimpulan
Penundaan besar dalam QPS rendah disebabkan oleh optimasi OS. Melihat ke belakang, pembuatan profil tidak mendeteksi penundaan karena dilakukan dalam mode kernel dan tidak dalam
mode pengguna . Saya tidak tahu apakah mungkin untuk mengamati algoritma Nagle melalui tangkapan ETW, tapi itu akan menarik.
Adapun percobaan localhost, itu mungkin tidak menyentuh kode jaringan yang sebenarnya, dan algoritma Neigl tidak memulai, sehingga masalah penundaan menghilang ketika klien menghubungi Alvin melalui localhost.
Lain kali Anda melihat peningkatan latensi sambil mengurangi jumlah permintaan per detik, algoritma Neigl harus ada dalam daftar tersangka Anda!