
Pendahuluan
Saya membuat laporan ini dalam bahasa Inggris di konferensi GopherCon Russia 2019 di Moskow dan di Rusia pada pertemuan di Nizhny Novgorod. Ini tentang indeks bitmap - kurang umum dari B-tree, tetapi tidak kalah menarik. Saya berbagi
rekaman pidato di konferensi dalam bahasa Inggris dan transkrip teks dalam bahasa Rusia.
Kami akan memeriksa bagaimana indeks bitmap bekerja, ketika lebih baik, ketika lebih buruk daripada indeks lain, dan dalam hal ini jauh lebih cepat daripada mereka; Kita akan melihat DBMS populer mana yang sudah memiliki indeks bitmap. coba tulis sendiri di Go. Dan untuk hidangan penutup, kami akan menggunakan perpustakaan siap pakai untuk membuat basis data khusus super cepat kami sendiri.
Saya sangat berharap bahwa pekerjaan saya akan bermanfaat dan menarik bagi Anda. Ayo pergi!
Pendahuluan
http://bit.ly/bitmapindexeshttps://github.com/mkevac/gopherconrussia2019Halo semuanya! Sekarang jam enam sore, kami semua sangat lelah. Saat yang tepat untuk berbicara tentang teori membosankan dari indeks basis data, bukan? Jangan khawatir, saya akan memiliki beberapa baris kode sumber di sana-sini. :-)
Jika tanpa lelucon, maka laporan itu penuh dengan informasi, dan kami tidak punya banyak waktu. Jadi mari kita mulai.

Hari ini saya akan membicarakan hal-hal berikut:
- apa itu indeks;
- apa itu indeks bitmap;
- di mana itu digunakan dan di mana itu TIDAK digunakan dan mengapa;
- implementasi sederhana di Go dan sedikit perjuangan dengan kompiler;
- sedikit kurang sederhana, tetapi jauh lebih produktif implementasi di Go-assembler;
- "Masalah" indeks bitmap;
- implementasi yang ada.
Jadi apa itu indeks?
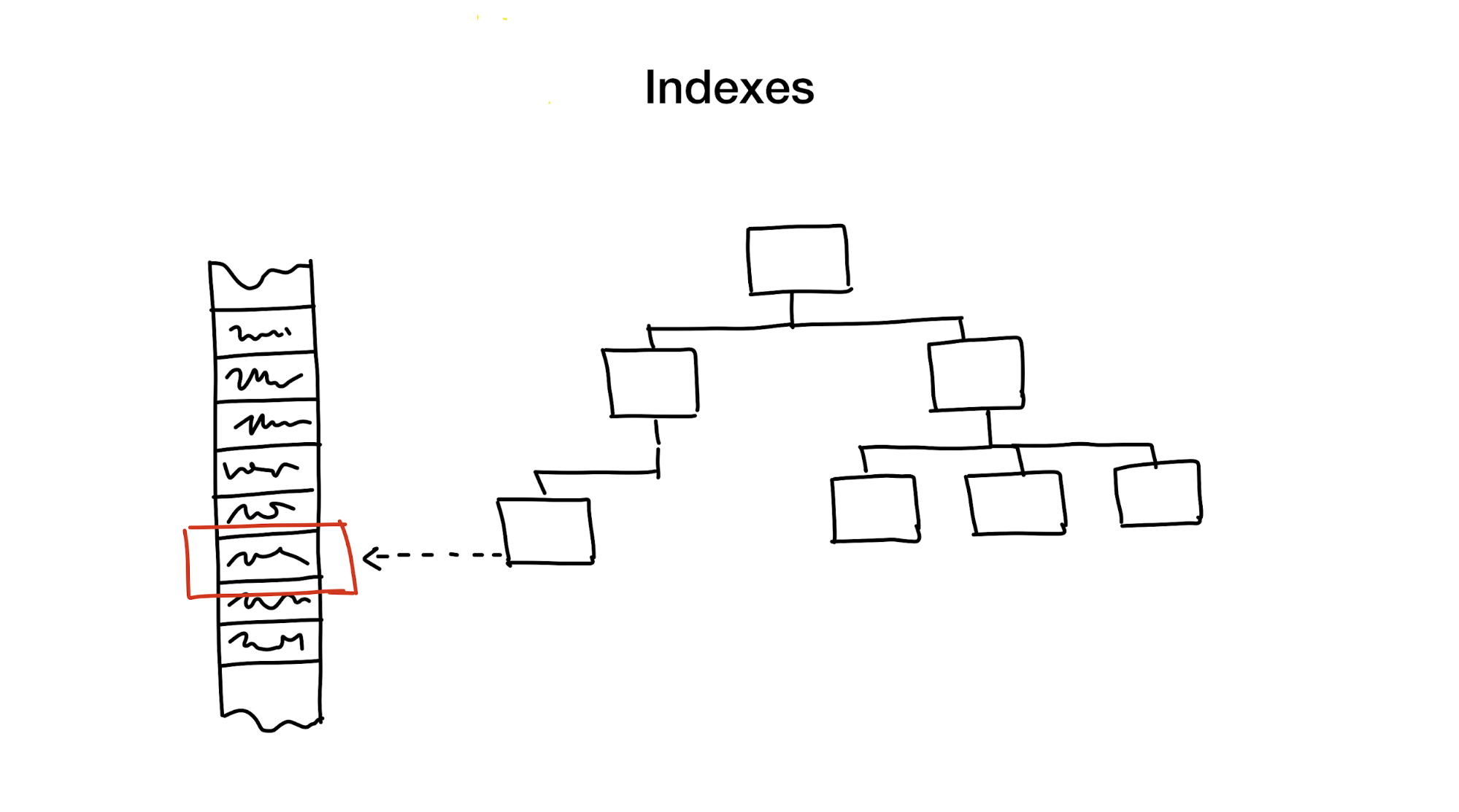
Indeks adalah struktur data terpisah yang kami pegang dan perbarui di samping data utama. Ini digunakan untuk mempercepat pencarian. Tanpa indeks, pencarian akan memerlukan data penuh (proses yang disebut pemindaian penuh), dan proses ini memiliki kompleksitas algoritme linear. Tetapi database biasanya mengandung sejumlah besar data dan kompleksitas linier terlalu lambat. Idealnya, kita akan mendapatkan logaritma atau konstanta.
Ini adalah topik yang sangat kompleks, penuh dengan kehalusan dan kompromi, tetapi setelah melihat dekade pengembangan dan penelitian berbagai database, saya siap untuk berdebat bahwa hanya ada beberapa pendekatan yang banyak digunakan untuk membuat indeks basis data.

Pendekatan pertama adalah mengurangi area pencarian secara hierarkis, membagi area pencarian menjadi bagian-bagian yang lebih kecil.
Biasanya kami melakukan ini menggunakan semua jenis pohon. Contohnya adalah kotak besar dengan bahan di lemari Anda, di mana ada kotak kecil dengan bahan dibagi dengan berbagai topik. Jika Anda membutuhkan bahan, maka Anda mungkin akan mencarinya dalam kotak dengan kata-kata "Bahan", dan bukan dalam kotak yang bertuliskan "Kue", kan?
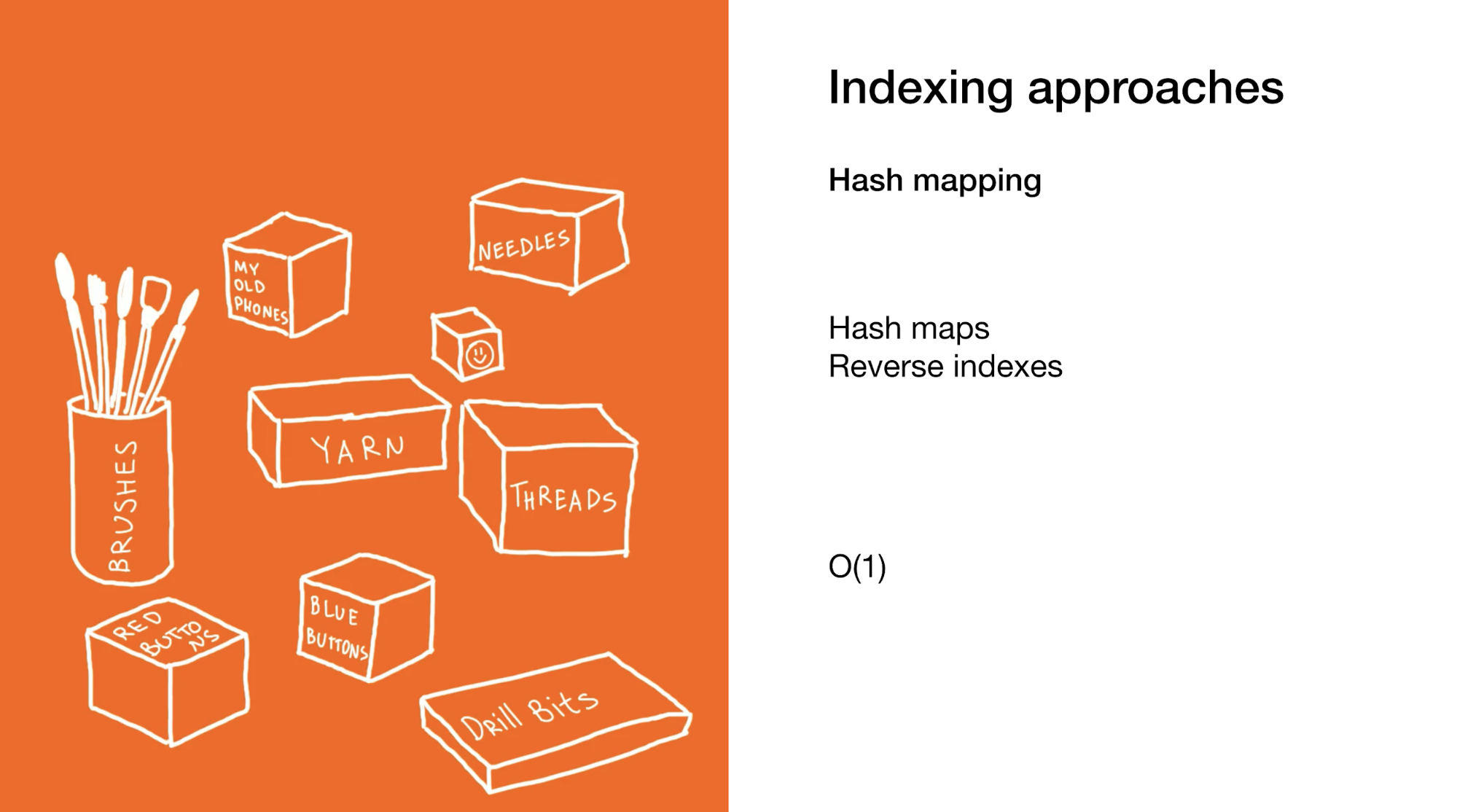
Pendekatan kedua adalah dengan segera memilih elemen atau kelompok elemen yang diinginkan. Kami melakukan ini di peta hash atau dalam indeks terbalik. Menggunakan peta hash sangat mirip dengan contoh sebelumnya, hanya sebagai ganti kotak dengan kotak di lemari Anda ada banyak kotak kecil dengan barang-barang akhir.

Pendekatan ketiga adalah menyingkirkan kebutuhan akan pencarian. Kami melakukan ini menggunakan filter Bloom atau filter kukuk. Yang pertama memberikan jawaban secara instan, menghilangkan kebutuhan untuk mencari.
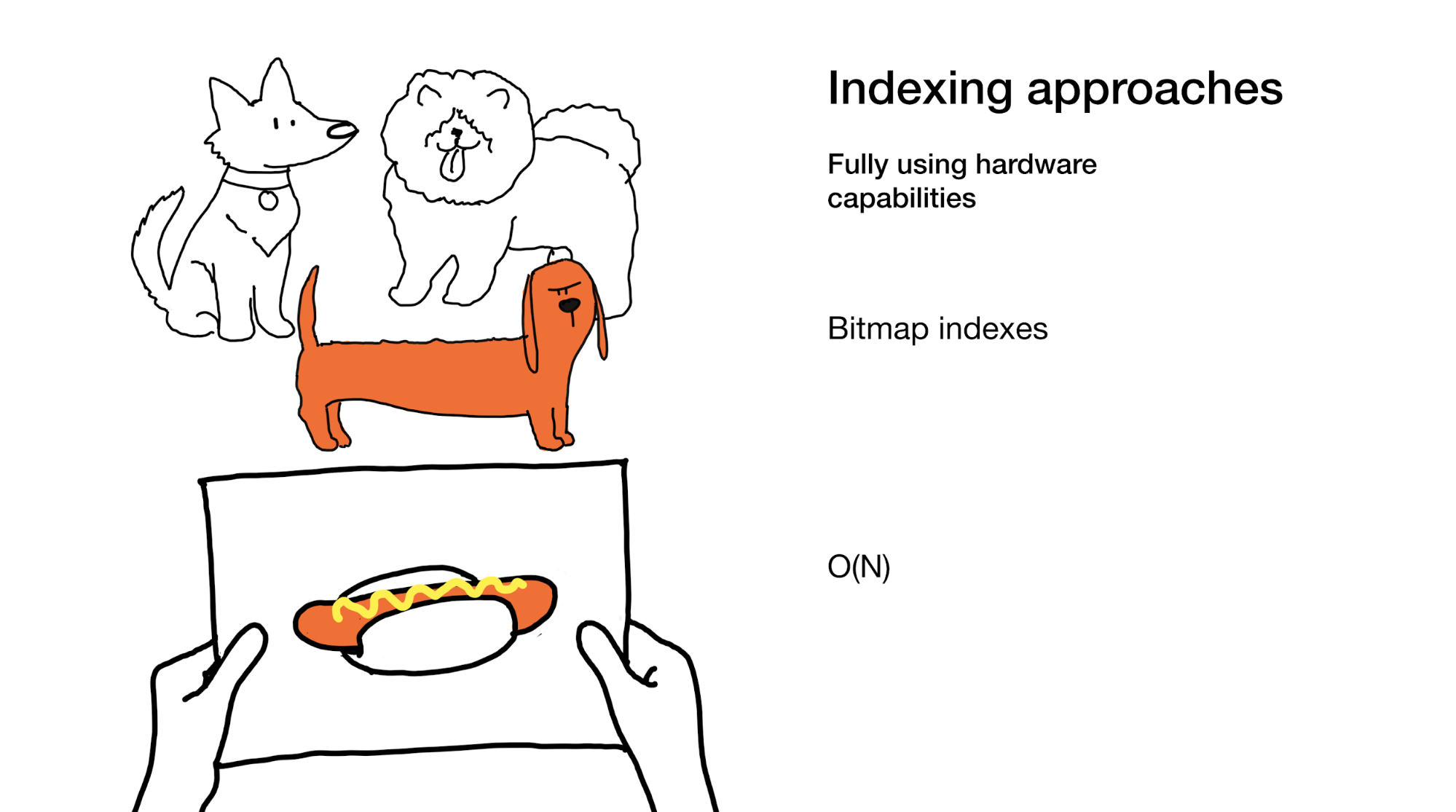
Pendekatan terakhir adalah memanfaatkan sepenuhnya semua kapasitas yang diberikan besi modern kepada kita. Inilah yang kami lakukan dalam indeks bitmap. Ya, ketika menggunakannya, kadang-kadang kita perlu memeriksa keseluruhan indeks, tetapi kita melakukannya dengan sangat efisien.
Seperti yang saya katakan, topik indeks basis data sangat luas dan penuh dengan kompromi. Ini berarti bahwa kadang-kadang kita dapat menggunakan beberapa pendekatan secara bersamaan: jika kita perlu mempercepat pencarian lebih lanjut atau jika perlu untuk mencakup semua jenis pencarian yang mungkin.
Hari ini saya akan berbicara tentang pendekatan yang paling tidak diketahui dari ini - tentang indeks bitmap.
Siapa yang harus saya bicarakan ini?
Saya bekerja sebagai pemimpin tim di Badoo (mungkin Anda lebih tahu produk kami yang lain, Bumble). Kami sudah memiliki lebih dari 400 juta pengguna di seluruh dunia dan banyak fitur yang terlibat dalam memilih pasangan terbaik untuk mereka. Kami melakukan ini menggunakan layanan kustom yang menggunakan indeks bitmap juga.
Jadi apa itu indeks bitmap?
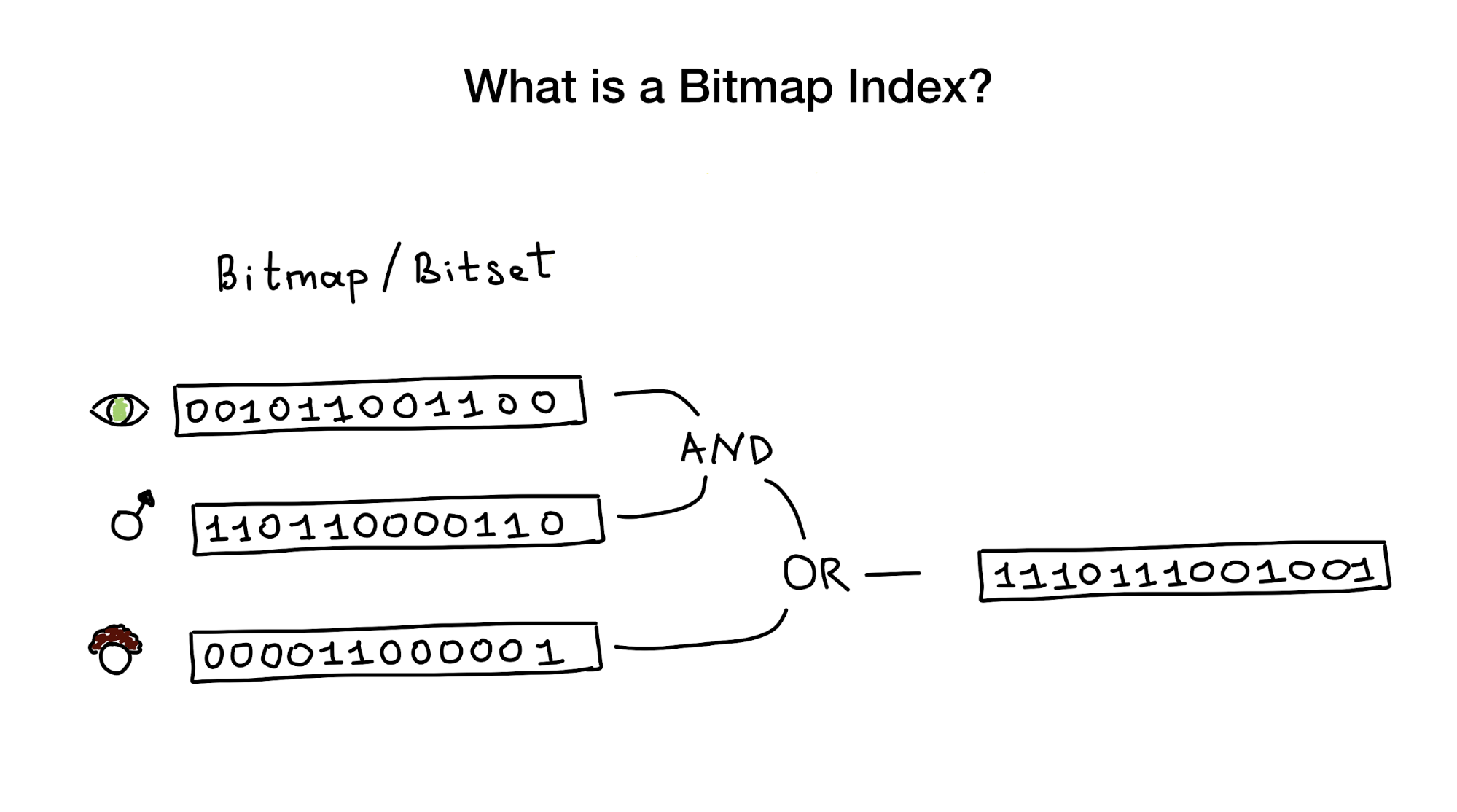
Indeks Bitmap, seperti namanya, menggunakan bitmap atau bitet untuk mengimplementasikan indeks pencarian. Dari pandangan mata burung, indeks ini terdiri dari satu atau lebih bitmap yang mewakili entitas (seperti orang) dan properti atau parameternya (usia, warna mata, dll.), Dan dari algoritme yang menggunakan operasi bit (DAN, ATAU, BUKAN) untuk menanggapi permintaan pencarian.

Kami diberitahu bahwa indeks bitmap paling cocok dan sangat produktif untuk kasus-kasus di mana ada pencarian yang menggabungkan pertanyaan di banyak kolom yang memiliki sedikit kardinalitas (bayangkan "warna mata" atau "status perkawinan" terhadap sesuatu seperti "jarak dari pusat kota" ) Tetapi nanti saya akan menunjukkan bahwa mereka bekerja dengan sempurna dalam kasus kolom dengan kardinalitas tinggi.
Pertimbangkan contoh paling sederhana dari indeks bitmap.

Bayangkan kita memiliki daftar restoran Moskow dengan properti biner seperti ini:
- dekat metro (dekat metro);
- ada parkir pribadi (memiliki parkir pribadi);
- ada beranda (memiliki teras);
- Anda dapat memesan meja (menerima reservasi);
- cocok untuk vegetarian (ramah vegan);
- mahal (mahal).
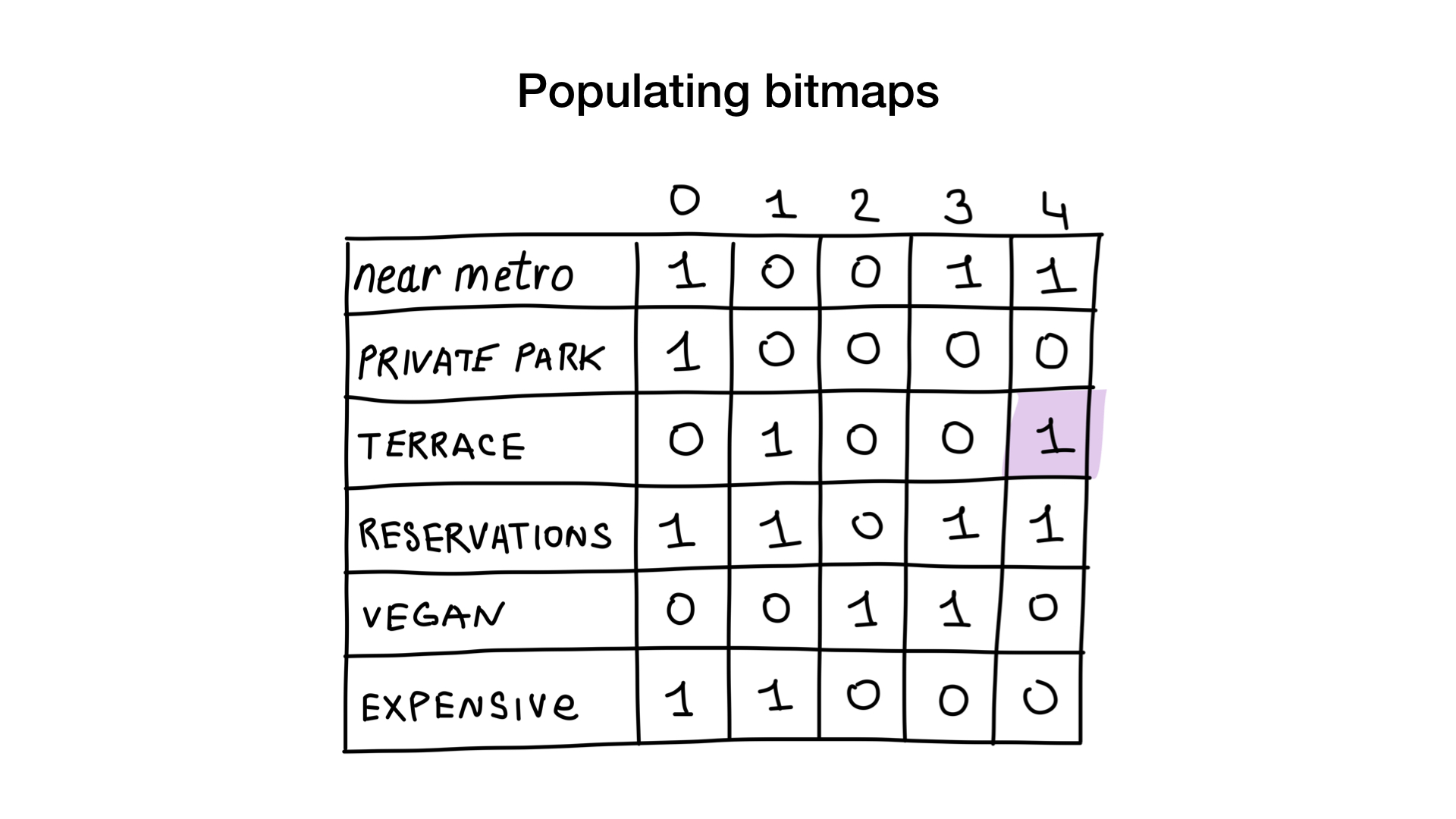
Mari kita beri setiap restoran nomor seri mulai dari 0 dan mengalokasikan memori untuk 6 bitmap (satu untuk setiap karakteristik). Kemudian kami mengisi bitmap ini, tergantung pada apakah restoran memiliki properti ini atau tidak. Jika restoran 4 memiliki beranda, maka bit No. 4 dalam bitmap "ada beranda" akan ditetapkan ke 1 (jika tidak ada beranda, maka ke 0).

Sekarang kami memiliki indeks bitmap sesederhana mungkin, dan kami dapat menggunakannya untuk menjawab pertanyaan seperti:
- “Tunjukkan pada saya restoran yang cocok untuk vegetarian”;
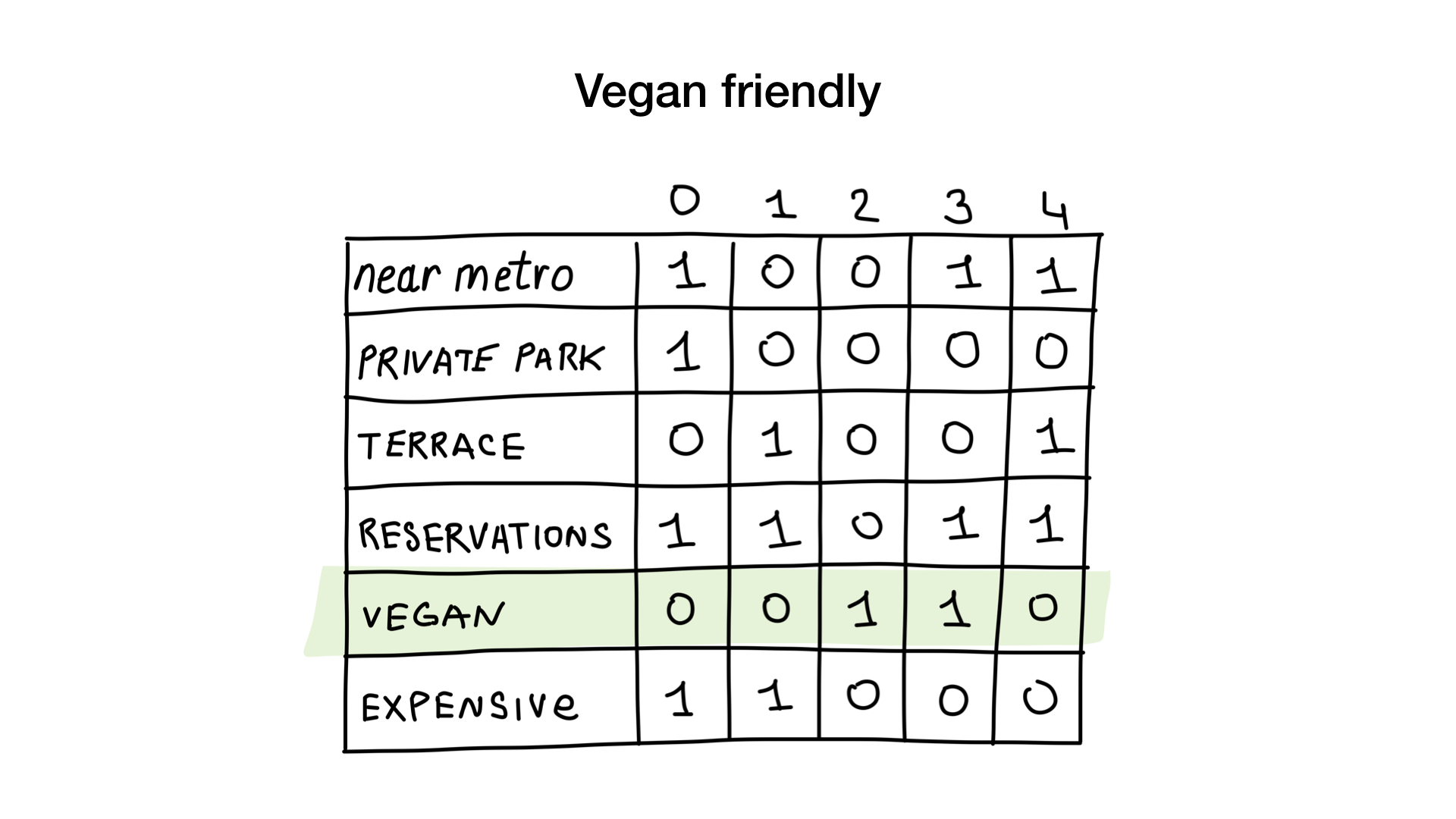
- "Tunjukkan padaku restoran murah dengan beranda di mana kamu dapat memesan meja."
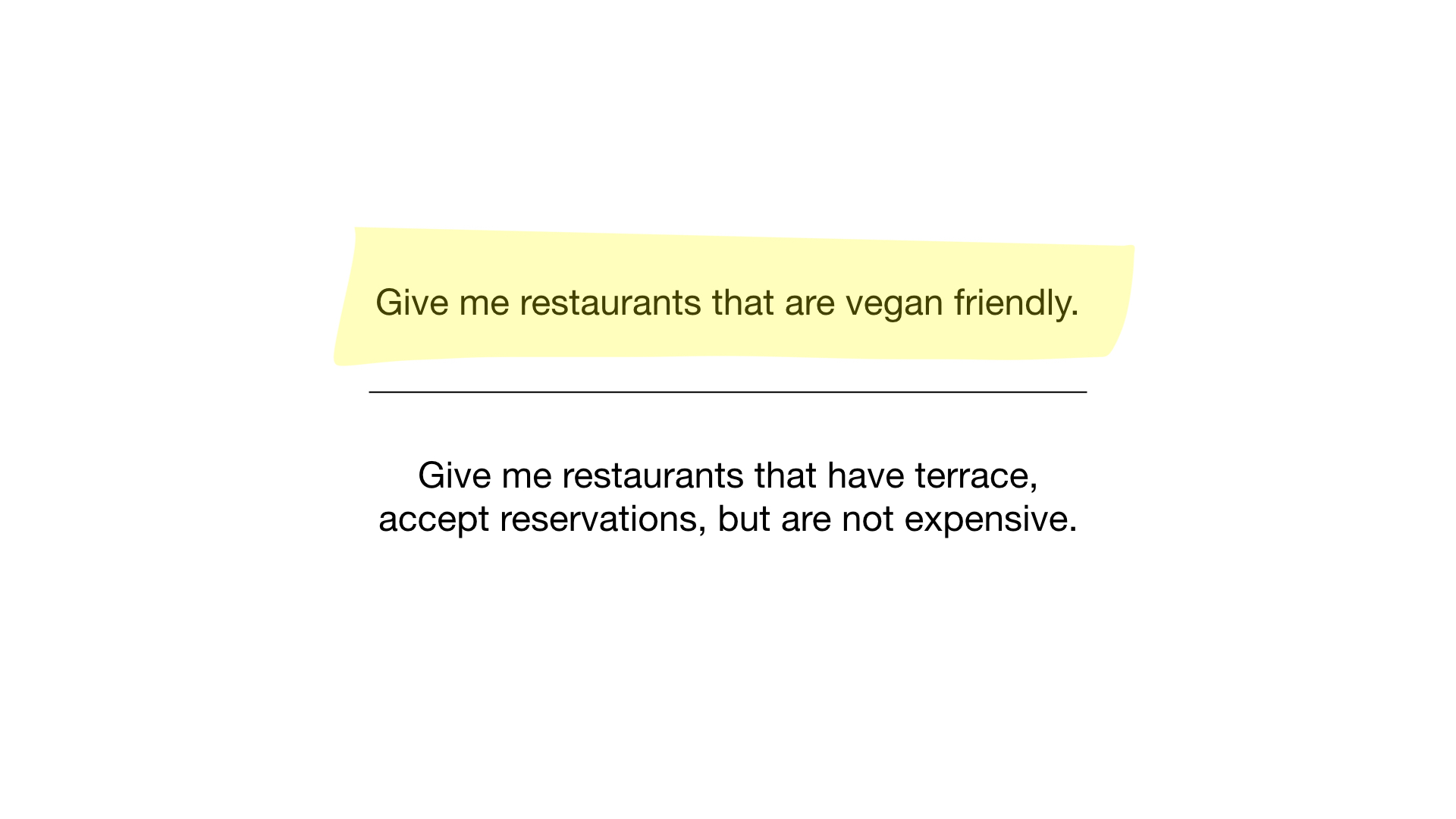
Bagaimana? Ayo lihat. Permintaan pertama sangat sederhana. Yang perlu kita lakukan hanyalah mengambil bitmap "cocok untuk vegetarian" dan mengubahnya menjadi daftar restoran yang bitnya dipajang.
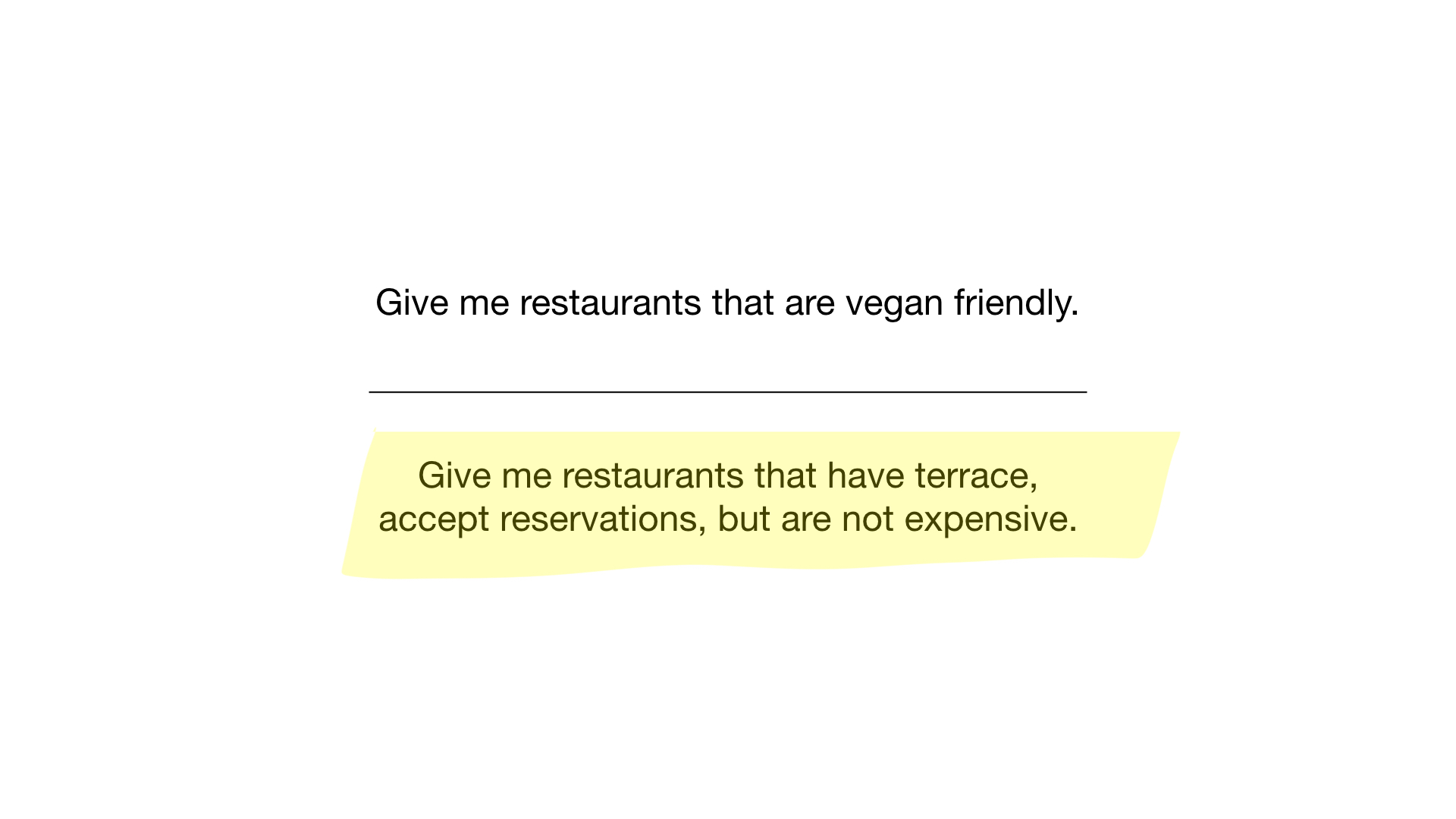

Kueri kedua sedikit lebih rumit. Kita perlu menggunakan operasi bit TIDAK pada bitmap "mahal" untuk mendapatkan daftar restoran murah, kemudian mengaturnya dengan bitmap "Anda dapat memesan meja" dan mengatur hasilnya dengan bitmap "ada beranda". Bitmap yang dihasilkan akan berisi daftar perusahaan yang memenuhi semua kriteria kami. Dalam contoh ini, ini hanya restoran Yunost.
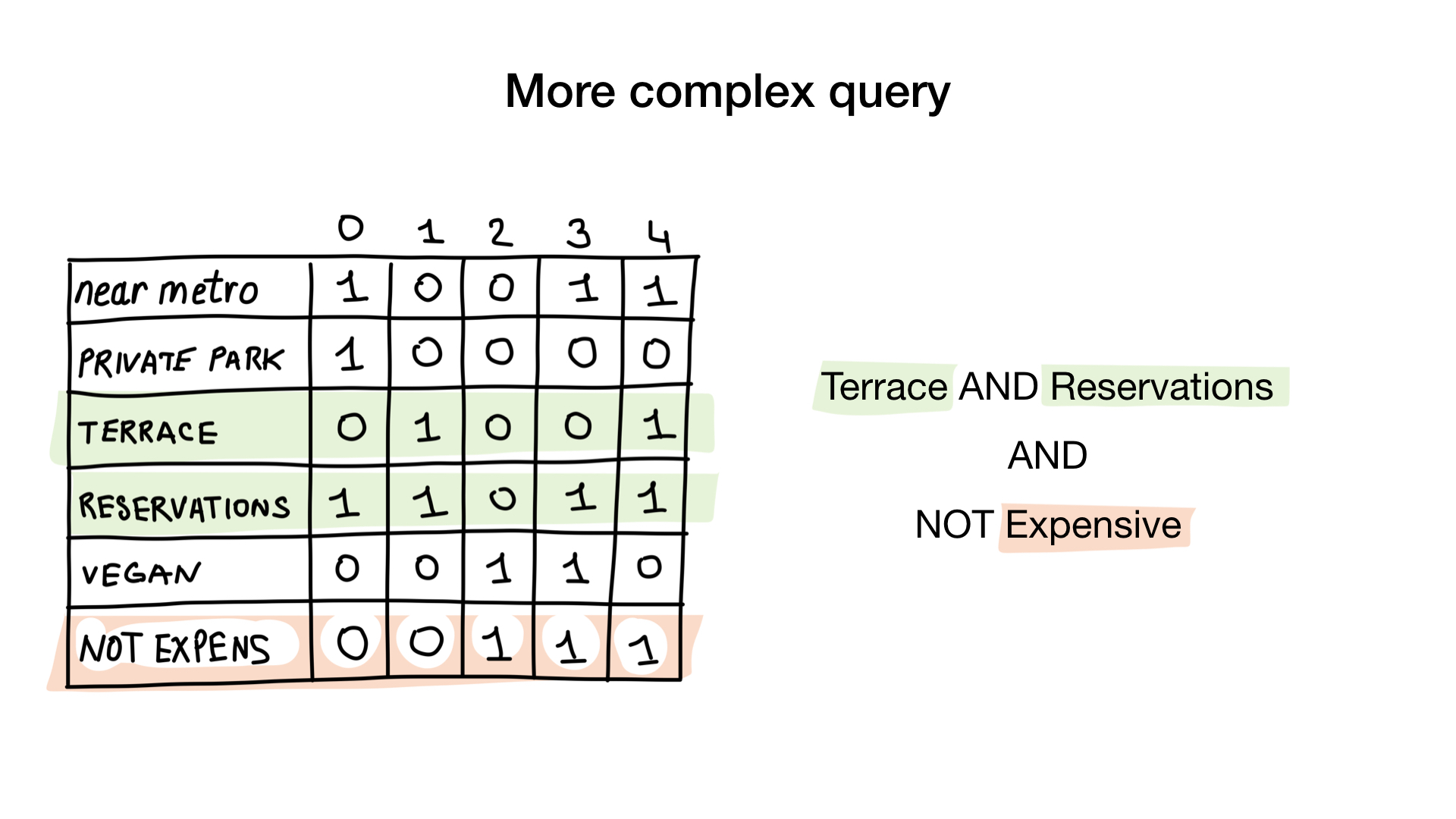
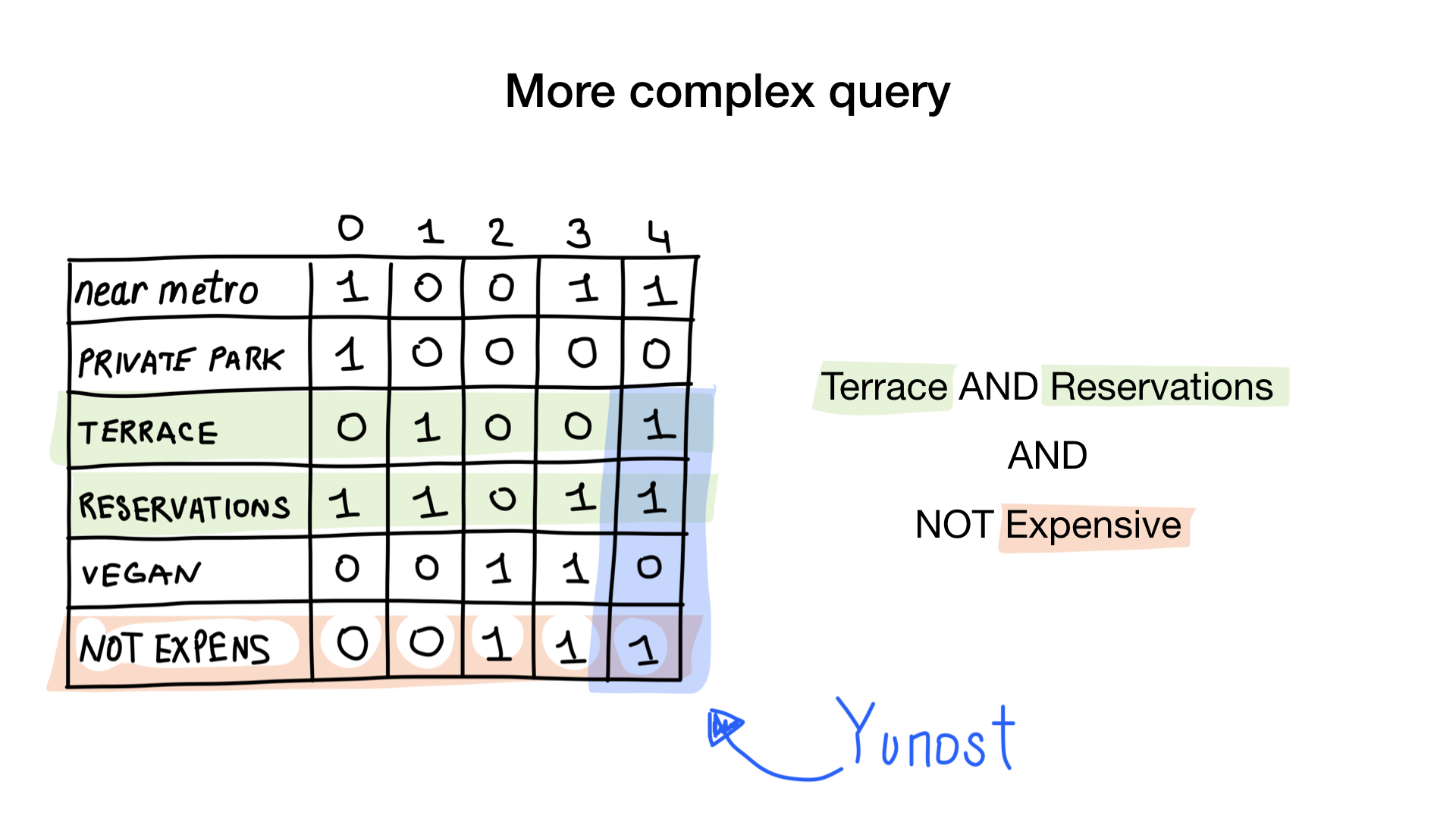
Ada banyak teori, tetapi jangan khawatir, kami akan segera melihat kode.
Di mana indeks bitmap digunakan?

Jika Anda "google" indeks bitmap, 90% dari jawaban entah bagaimana akan terkait dengan Oracle DB. Tetapi sisa DBMS juga mungkin mendukung hal yang keren, kan? Tidak juga.
Mari kita lihat daftar tersangka utama.

MySQL belum mendukung indeks bitmap, tetapi ada Proposal dengan proposal untuk menambahkan opsi ini (
https://dev.mysql.com/worklog/task/?id=1524 ).
PostgreSQL tidak mendukung indeks bitmap, tetapi menggunakan bitmap sederhana dan operasi bit untuk menggabungkan hasil pencarian di beberapa indeks lainnya.
Tarantool memiliki indeks bitset, mendukung pencarian sederhana pada mereka.
Redis memiliki bidang bit sederhana
(https://redis.io/commands/bitfield ) tanpa kemampuan untuk mencari melalui mereka.
MongoDB belum mendukung indeks bitmap, tetapi ada juga Proposal dengan proposal untuk menambahkan opsi ini
https://jira.mongodb.org/browse/SERVER-1723Elasticsearch menggunakan bitmap di dalam
(https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps ).

- Tetapi tetangga baru muncul di rumah kami: Pilosa. Ini adalah basis data non-relasional baru yang ditulis dalam Go. Ini hanya berisi indeks bitmap dan mendasarkan semuanya pada mereka. Kami akan membicarakannya nanti.
Go implementasi
Tetapi mengapa indeks bitmap sangat jarang digunakan? Sebelum menjawab pertanyaan ini, saya ingin menunjukkan kepada Anda penerapan indeks bitmap yang sangat sederhana di Go.

Bitmap pada dasarnya hanya potongan data. Di Go, mari gunakan irisan byte untuk ini.
Kami memiliki satu bitmap per karakteristik restoran, dan setiap bit dalam bitmap menunjukkan apakah restoran tertentu memiliki properti ini atau tidak.

Kita akan membutuhkan dua fungsi bantu. Satu akan digunakan untuk mengisi bitmap kami dengan data acak. Acak, tetapi dengan probabilitas tertentu bahwa restoran memiliki setiap properti. Sebagai contoh, saya percaya bahwa ada sangat sedikit restoran di Moskow di mana Anda tidak dapat memesan meja, dan bagi saya tampaknya sekitar 20% dari perusahaan cocok untuk vegetarian.
Fungsi kedua akan mengkonversi bitmap ke daftar restoran.


Untuk menjawab permintaan "Tunjukkan restoran murah yang memiliki beranda dan tempat Anda dapat memesan meja", kami membutuhkan dua operasi bit: BUKAN dan DAN.
Kita dapat menyederhanakan kode kita sedikit dengan menggunakan operasi yang lebih kompleks DAN TIDAK.
Kami memiliki fungsi untuk masing-masing operasi ini. Keduanya melalui irisan, mengambil elemen yang sesuai dari masing-masing, menggabungkannya dengan operasi bit dan menempatkan hasilnya dalam irisan yang dihasilkan.
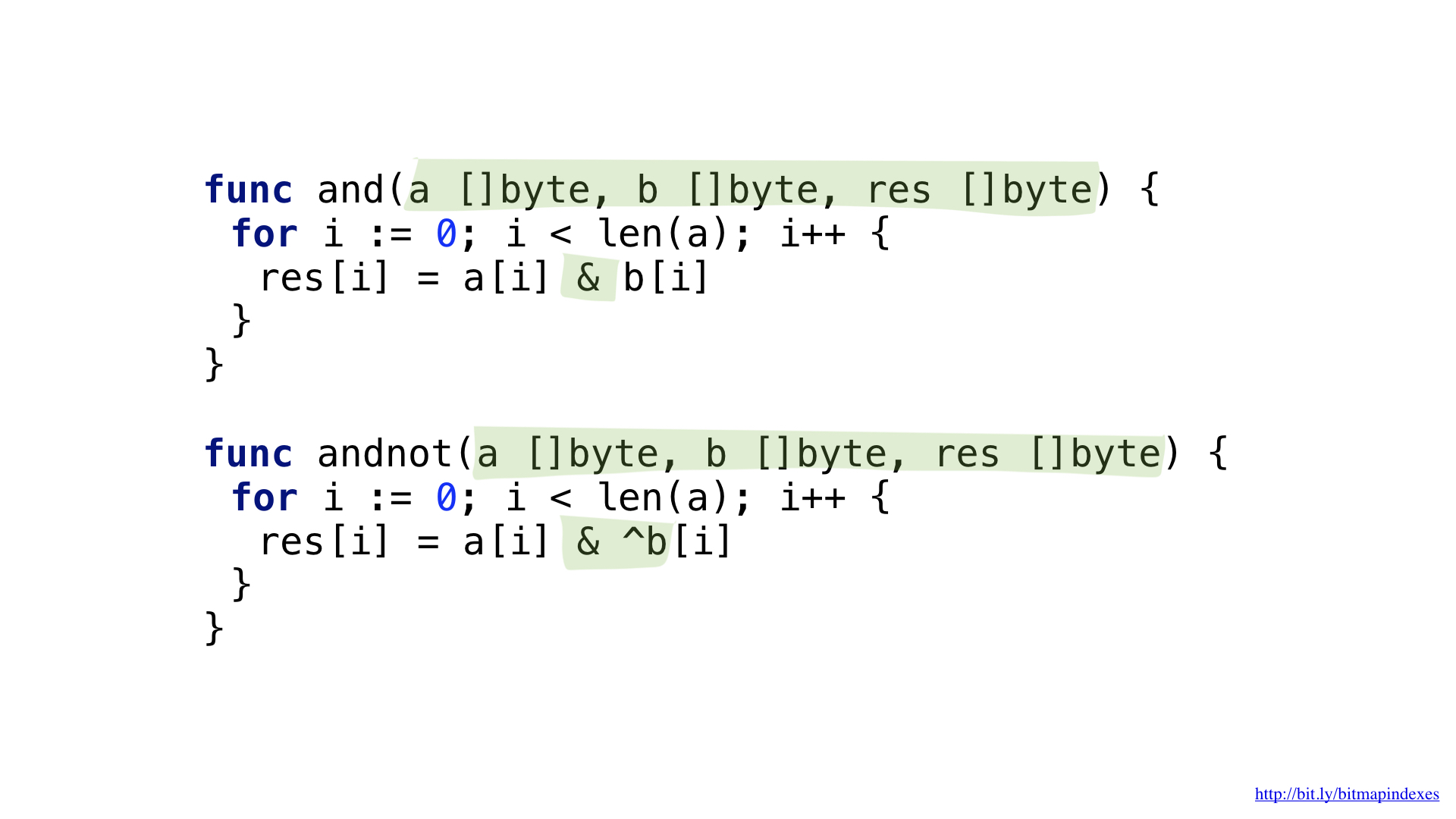
Dan sekarang kita dapat menggunakan bitmap dan fungsi kita untuk menanggapi permintaan pencarian.

Performanya tidak terlalu tinggi, walaupun faktanya fungsi-fungsinya sangat sederhana dan kami cukup menghemat fakta bahwa kami tidak mengembalikan irisan baru yang dihasilkan setiap kali fungsi dipanggil.
Setelah diprofilkan sedikit dengan pprof, saya perhatikan bahwa kompiler Go melewatkan satu optimasi yang sangat sederhana, tetapi sangat penting: fungsi inlining.
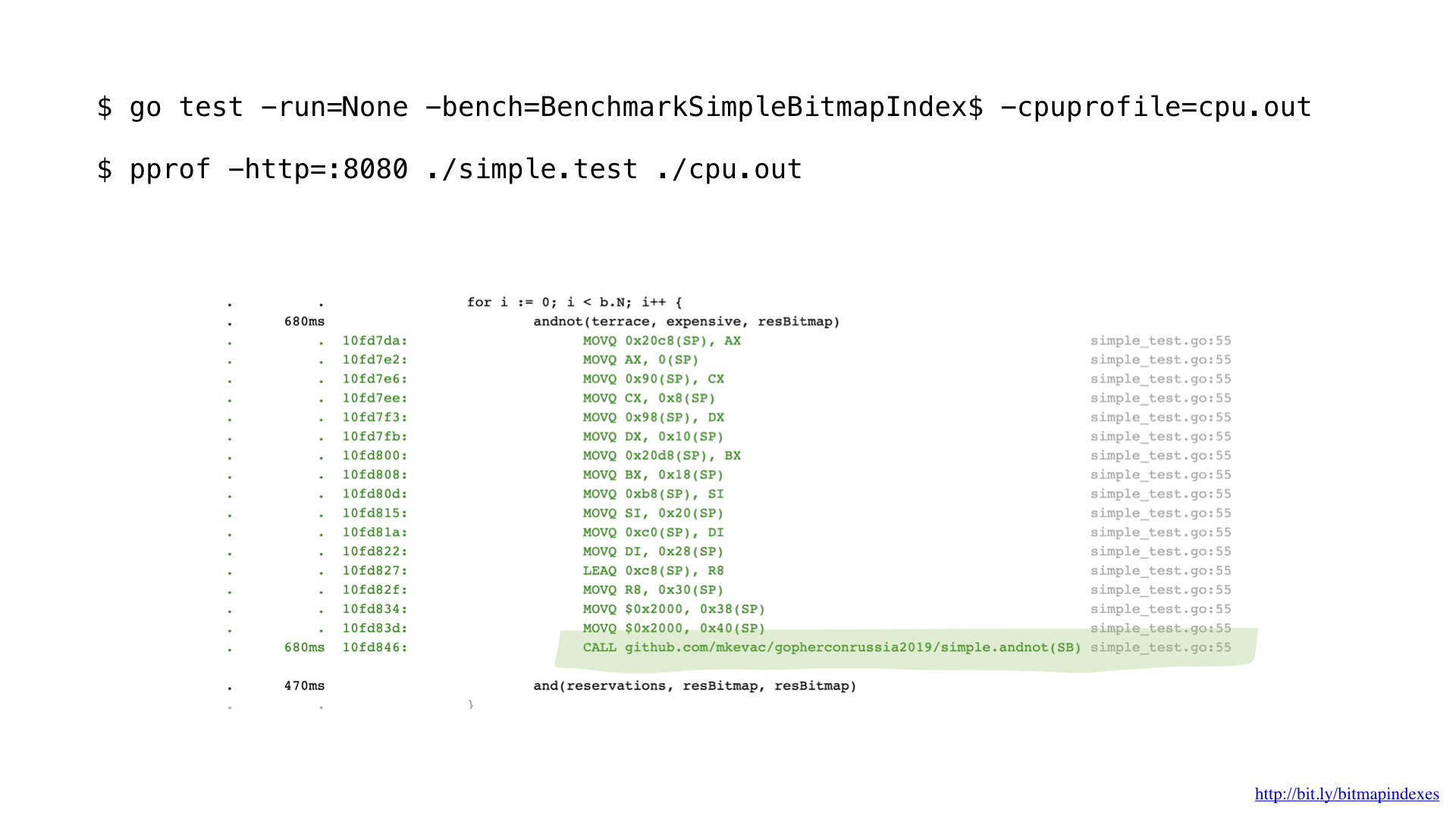
Faktanya adalah bahwa kompilator Go sangat takut pada loop yang melewati irisan, dan pasti menolak fungsi inline yang berisi loop.
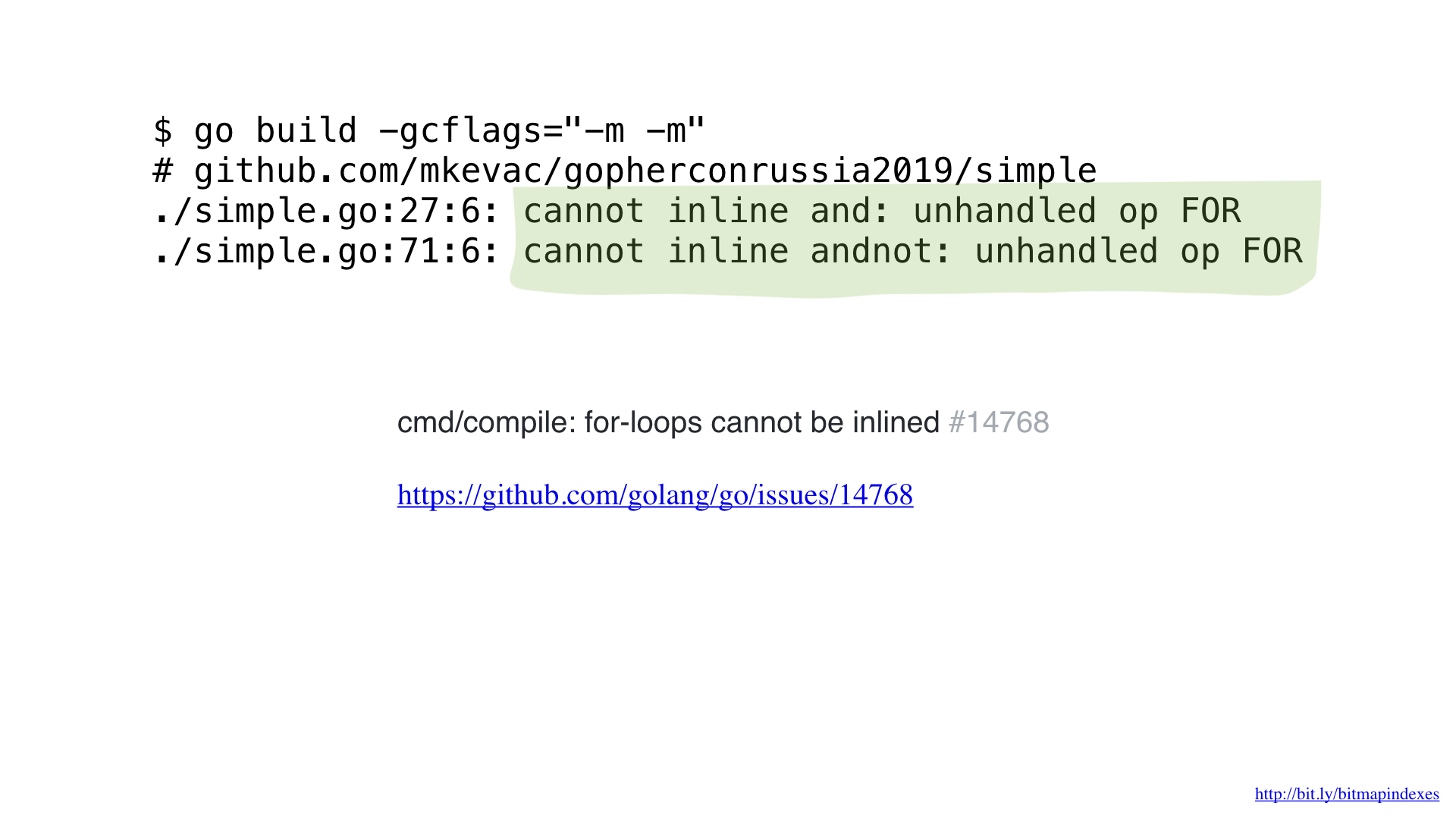
Tapi saya tidak takut, dan saya bisa membodohi kompiler dengan menggunakan goto bukannya loop, seperti di masa lalu yang baik.


Dan, seperti yang Anda lihat, sekarang kompiler dengan senang hati menguraikan fungsi kami! Akibatnya, kami berhasil menghemat sekitar 2 mikrodetik. Tidak buruk!

Kemacetan kedua mudah dilihat jika Anda dengan cermat melihat output assembler. Kompilator telah menambahkan pengecekan slice bound tepat di dalam loop terpanas kami. Faktanya adalah bahwa Go adalah bahasa yang aman, kompiler takut bahwa tiga argumen saya (tiga irisan) memiliki ukuran yang berbeda. Setelah semua, maka akan ada kemungkinan teoritis tentang penampilan buffer overflow.
Mari meyakinkan kompiler dengan menunjukkan kepadanya bahwa semua irisan memiliki ukuran yang sama. Kita dapat melakukan ini dengan menambahkan cek sederhana di awal fungsi kita.
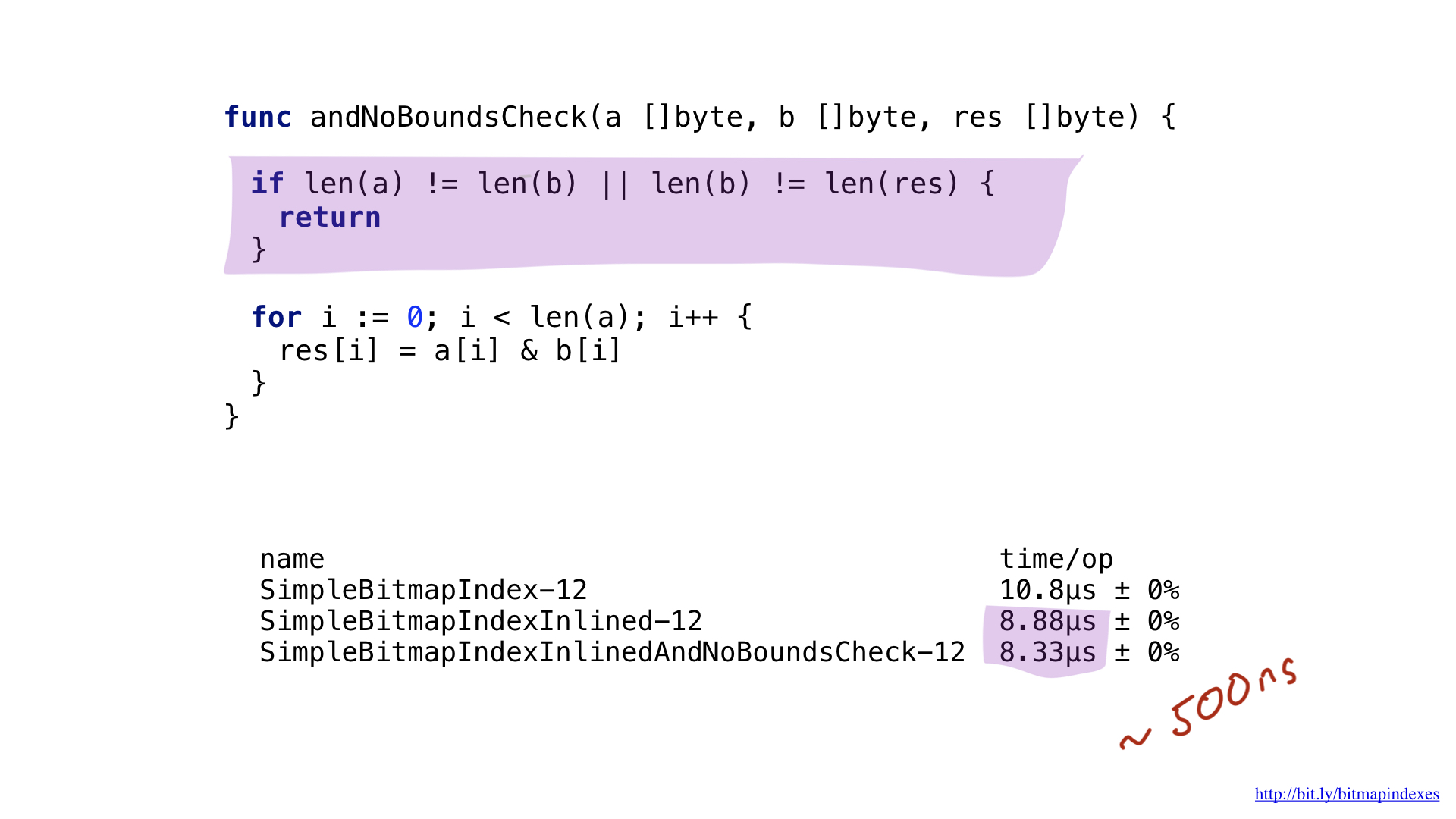
Melihat ini, kompiler dengan senang hati melewatkan tes, dan kami akhirnya menghemat 500 nanodetik lagi.
Batch besar
Oke, kami berhasil memeras beberapa kinerja dari implementasi sederhana kami, tetapi hasil ini, pada kenyataannya, jauh lebih buruk daripada yang mungkin dengan perangkat keras saat ini.
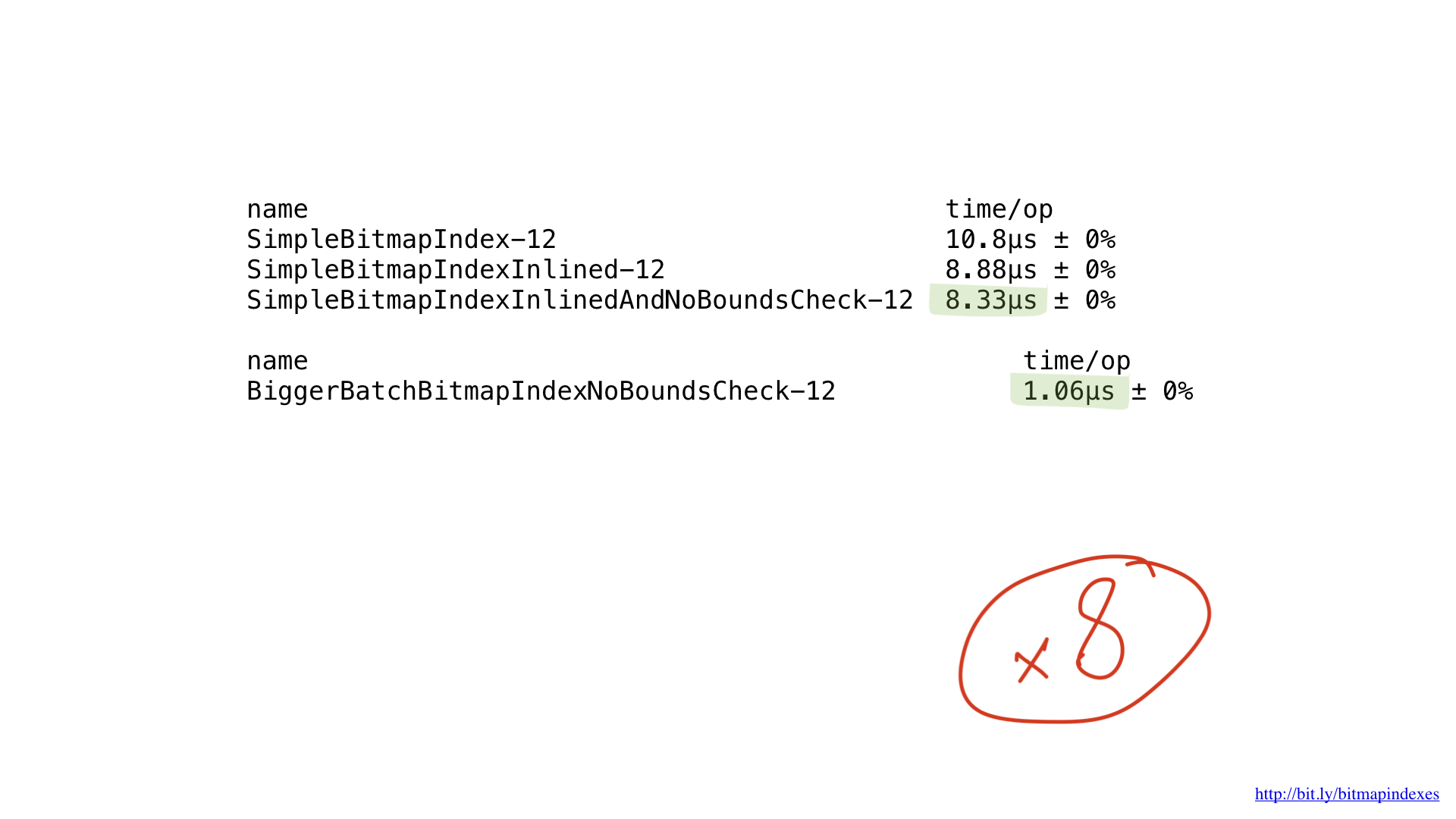
Yang kami lakukan hanyalah operasi bit dasar, dan prosesor kami melakukannya dengan sangat efisien. Namun, sayangnya, kami “memberi makan” prosesor kami dengan pekerjaan yang sangat kecil. Fungsi kami melakukan operasi byte demi byte. Kita dapat dengan mudah menyetel kode kita sehingga berfungsi dengan potongan 8-byte menggunakan irisan UInt64.

Seperti yang Anda lihat, perubahan kecil ini telah mempercepat program kami sebanyak delapan kali karena peningkatan batch sebanyak delapan kali. Keuntungannya bisa dikatakan linear.
Implementasi Assembler

Tapi ini bukan akhirnya. Prosesor kami dapat bekerja dengan potongan 16, 32 dan bahkan 64 byte. Operasi "lebar" seperti itu disebut instruksi tunggal banyak data (SIMD; satu instruksi, banyak data), dan proses transformasi kode sehingga menggunakan operasi tersebut disebut vektorisasi.
Sayangnya, kompiler Go jauh dari siswa yang sangat baik dalam vektorisasi. Saat ini, satu-satunya cara untuk membuat vektor kode di Go adalah dengan mengambil dan menempatkan operasi ini secara manual menggunakan assembler Go.

Assembler Go adalah binatang buas yang aneh. Anda mungkin tahu assembler adalah sesuatu yang sangat terkait dengan arsitektur komputer yang Anda tulis, tetapi ini tidak terjadi dengan Go. Assembler Go lebih mirip IRL (bahasa representasi perantara) atau bahasa perantara: praktis tidak tergantung platform. Rob Pike membuat
presentasi yang sangat baik tentang masalah ini beberapa tahun yang lalu di GopherCon di Denver.
Selain itu, Go menggunakan format Plan 9 yang tidak biasa, yang berbeda dari format AT&T dan Intel yang diakui secara umum.

Aman untuk mengatakan bahwa menulis Go assembler secara manual bukanlah kegiatan yang paling menyenangkan.
Tapi, untungnya, sudah ada dua alat tingkat tinggi yang membantu kita menulis Go assembler: PeachPy dan avo. Kedua utilitas menghasilkan assembler Go dari kode level yang lebih tinggi yang ditulis dengan Python dan Go, masing-masing.

Utilitas ini menyederhanakan hal-hal seperti alokasi register, siklus penulisan, dan umumnya menyederhanakan proses memasuki dunia pemrograman assembler di Go.
Kami akan menggunakan avo, sehingga program kami akan menjadi program Go yang hampir normal.

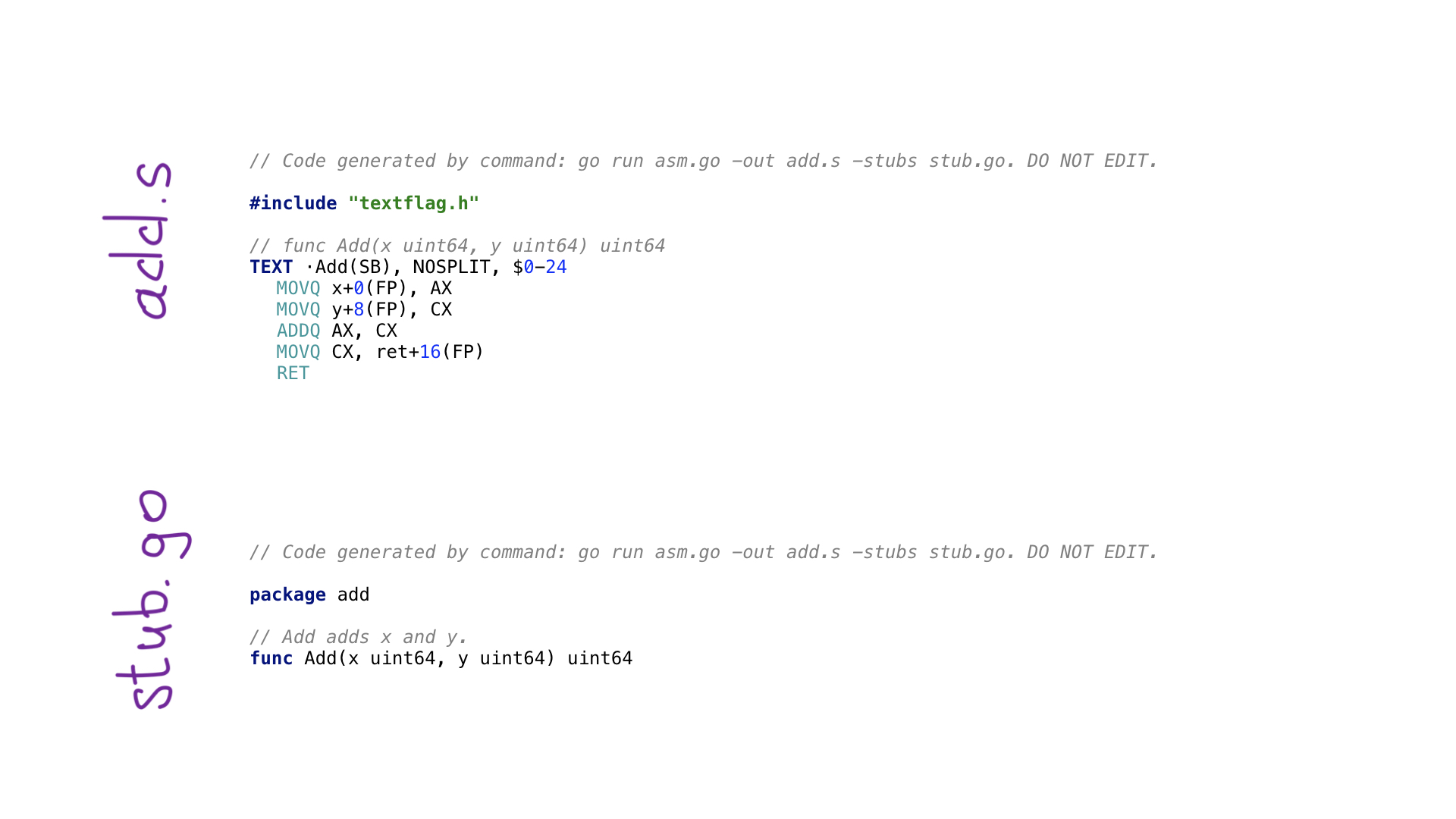
Inilah contoh paling sederhana dari program avo. Kami memiliki fungsi utama () yang mendefinisikan fungsi Tambah () di dalam dirinya, artinya menambahkan dua angka. Ada fungsi tambahan untuk mendapatkan parameter dengan nama dan mendapatkan salah satu register prosesor yang gratis dan cocok. Setiap operasi prosesor memiliki fungsi terkait pada avo, seperti terlihat pada ADDQ. Akhirnya, kita melihat fungsi pembantu untuk menyimpan nilai yang dihasilkan.

Dengan memanggil go menghasilkan, kami akan menjalankan program pada avo dan pada akhirnya dua file akan dihasilkan:
- add.s dengan kode assembler Go yang dihasilkan;
- stub.go dengan header fungsi untuk menghubungkan dua dunia: Pergi dan assembler.
Sekarang kita telah melihat apa dan bagaimana avo lakukan, mari kita lihat fungsi kita. Saya menerapkan versi fungsi skalar dan vektor (SIMD).
Pertama, lihat versi skalar.

Seperti dalam contoh sebelumnya, kami meminta Anda untuk memberikan kepada kami register tujuan umum yang bebas dan benar, kami tidak perlu menghitung offset dan ukuran untuk argumen. Semua ini berlaku untuk kita.

Sebelumnya kami menggunakan label dan goto (atau lompatan) untuk meningkatkan kinerja dan untuk mengelabui kompiler Go, tetapi sekarang kami melakukannya dari awal. Faktanya adalah bahwa loop adalah konsep level yang lebih tinggi. Di assembler, kami hanya memiliki label dan lompatan.

Kode yang tersisa harus sudah familier dan mudah dimengerti. Kami meniru loop dengan label dan lompatan, mengambil sebagian kecil data dari dua irisan kami, menggabungkannya dengan operasi bit (DAN TIDAK dalam kasus ini), dan kemudian memasukkan hasilnya dalam irisan yang dihasilkan. Itu saja.

Inilah yang terlihat seperti kode assembler akhir. Kami tidak perlu menghitung offset dan ukuran (disorot dengan warna hijau) atau melacak register yang digunakan (disorot dengan warna merah).
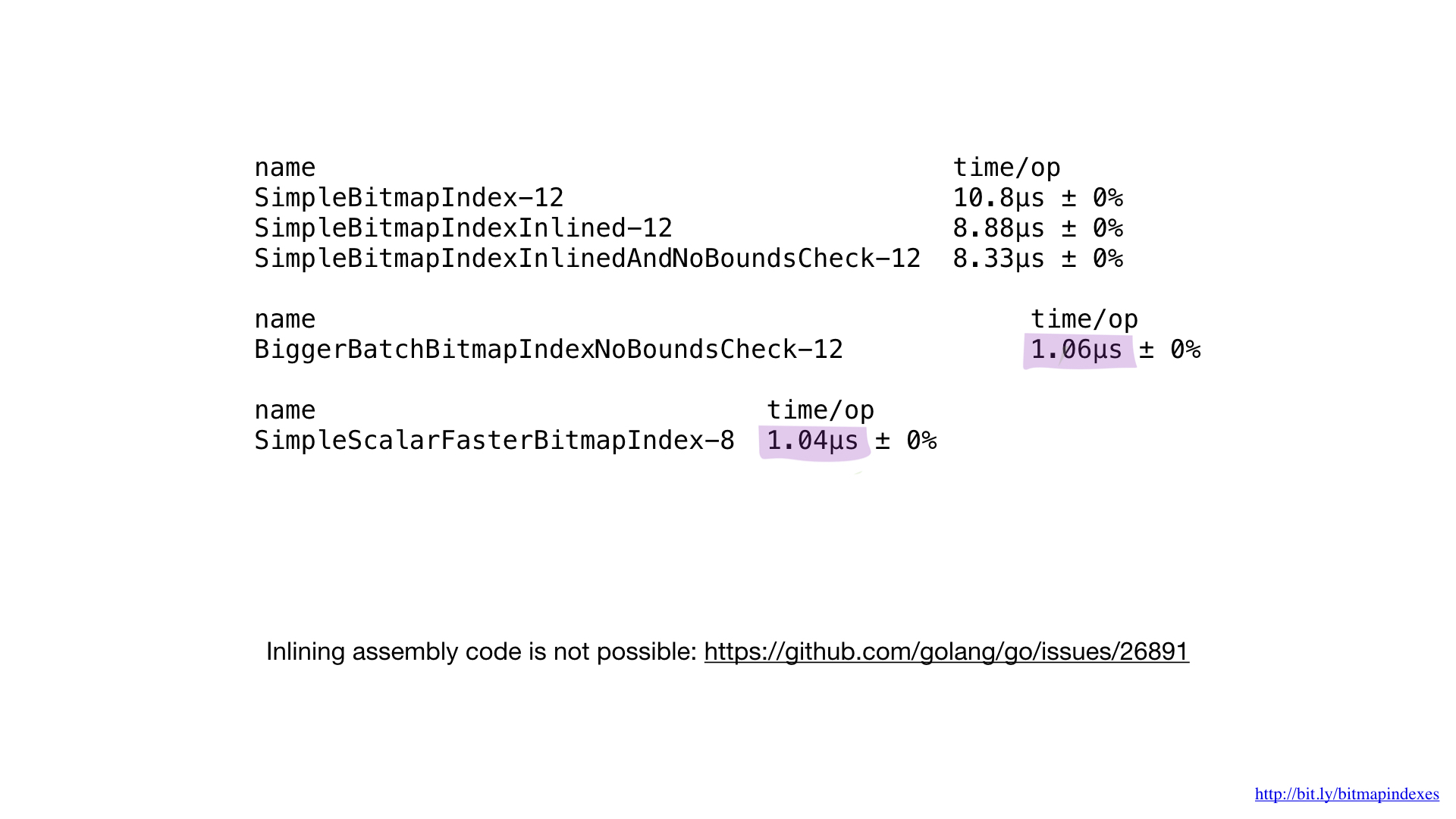
Jika kita membandingkan kinerja implementasi assembler dengan kinerja implementasi terbaik di Go, kita akan melihat bahwa itu sama. Dan itu diharapkan. Lagi pula, kami tidak melakukan sesuatu yang istimewa - kami hanya mereproduksi apa yang akan dilakukan oleh kompiler Go.
Sayangnya, kami tidak dapat memaksa kompiler untuk menampilkan fungsi kami yang ditulis dalam assembler. Kompiler Go tidak memiliki fitur ini hari ini, walaupun permintaan untuk menambahkannya sudah ada cukup lama.
Itu sebabnya tidak mungkin untuk mendapatkan manfaat dari fungsi kecil di assembler. Kita perlu menulis fungsi besar, atau menggunakan paket matematika / bit baru, atau memotong sisi assembler.
Sekarang mari kita lihat versi vektor dari fungsi kita.

Untuk contoh ini, saya memutuskan untuk menggunakan AVX2, jadi kami akan menggunakan operasi yang bekerja dengan potongan 32-byte. Struktur kode sangat mirip dengan opsi skalar: memuat parameter, berikan kami daftar umum gratis, dll.
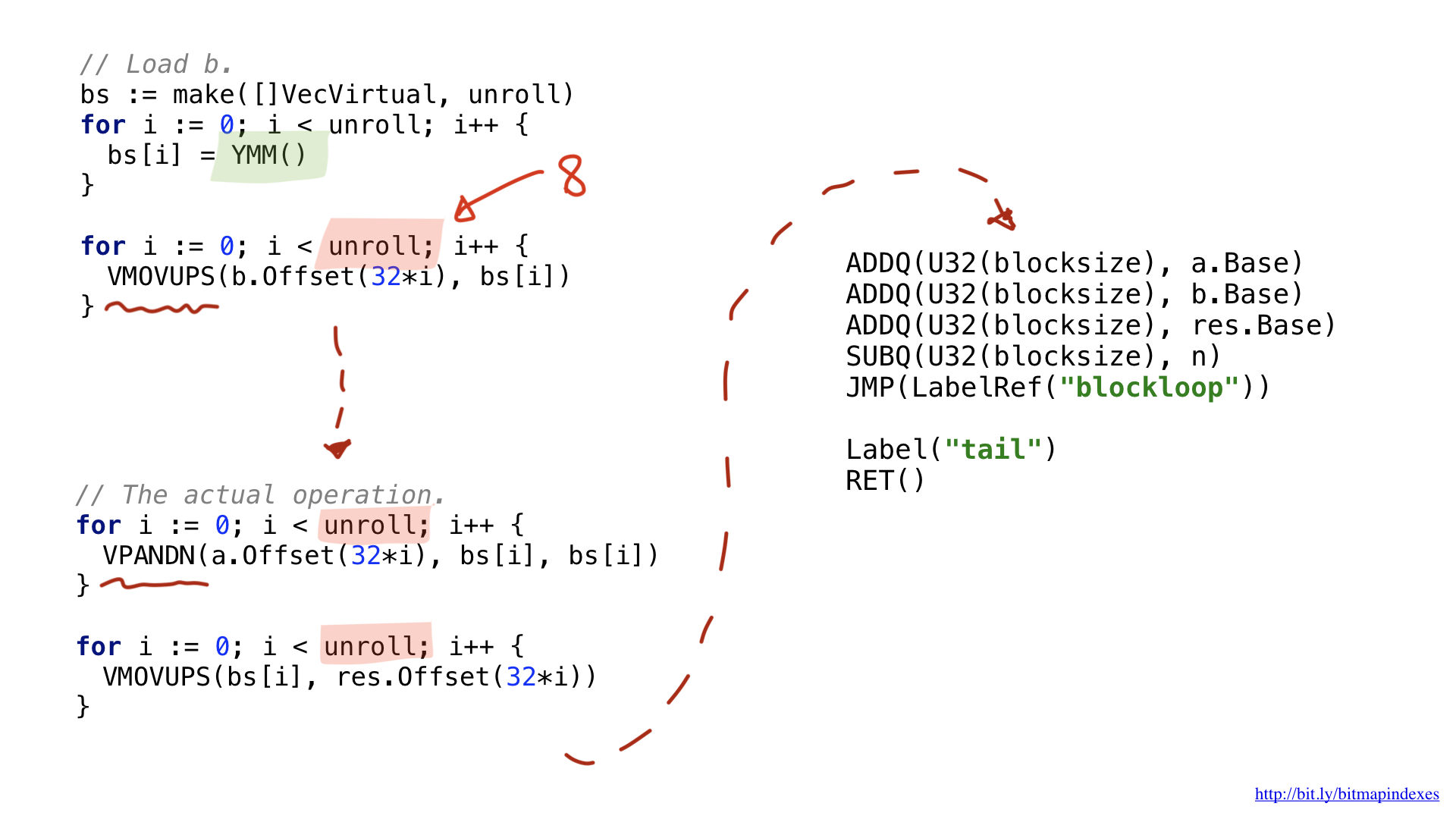
Salah satu inovasi adalah bahwa operasi vektor yang lebih luas menggunakan register lebar khusus. Dalam kasus potongan 32-byte, ini adalah register dengan awalan Y. Itulah sebabnya Anda melihat fungsi YMM () dalam kode. Jika saya menggunakan AVX-512 dengan potongan 64-bit, awalannya adalah Z.
Inovasi kedua adalah saya memutuskan untuk menggunakan optimasi yang disebut loop unrolling, yaitu, melakukan delapan operasi loop secara manual sebelum melompat ke awal loop. Pengoptimalan ini mengurangi jumlah brunch (cabang) dalam kode, dan dibatasi oleh jumlah register gratis yang tersedia.
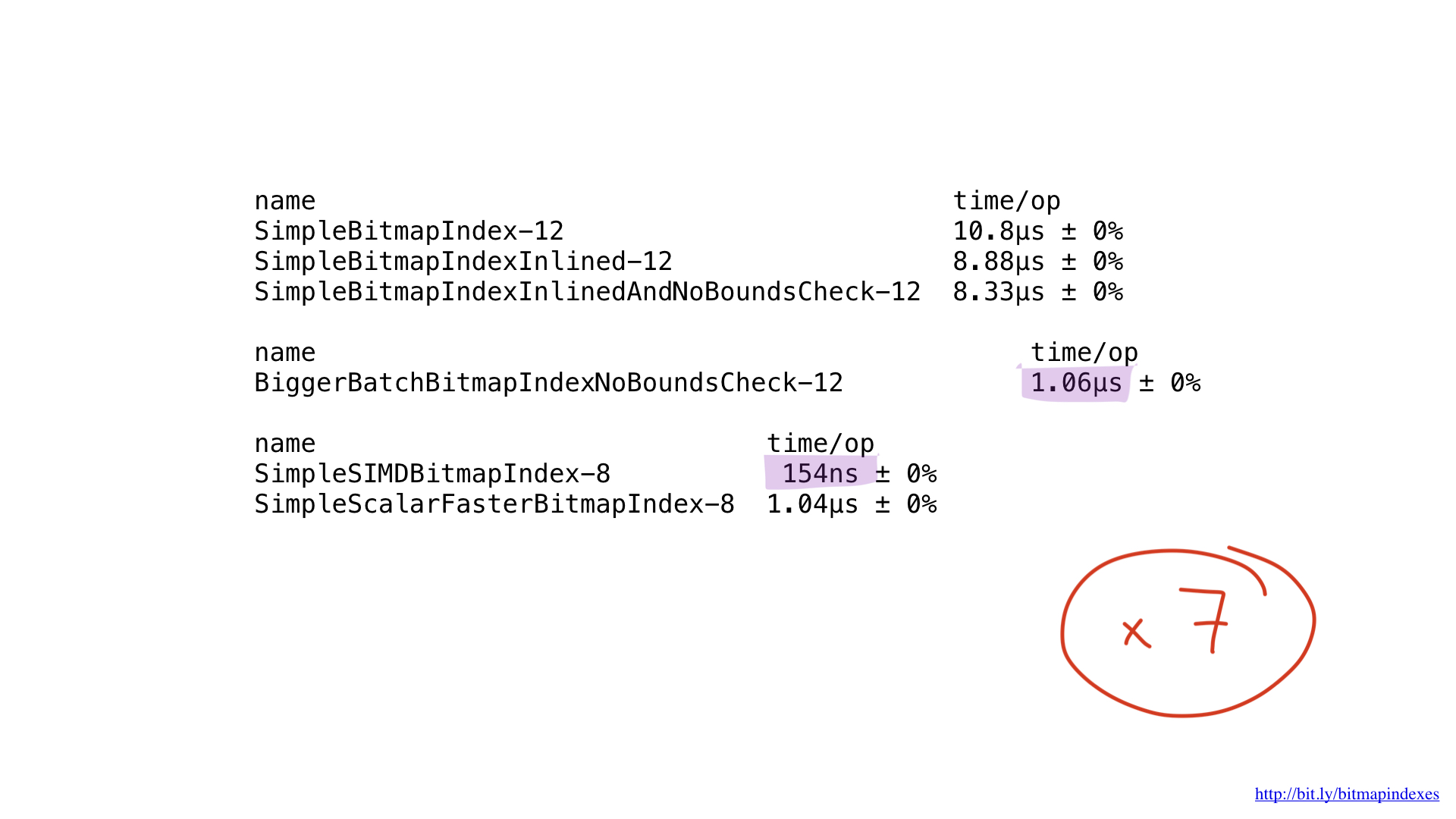
Nah, bagaimana dengan kinerja? Dia cantik! Kami mendapat akselerasi sekitar tujuh kali dibandingkan dengan solusi terbaik di Go. Mengesankan, ya?
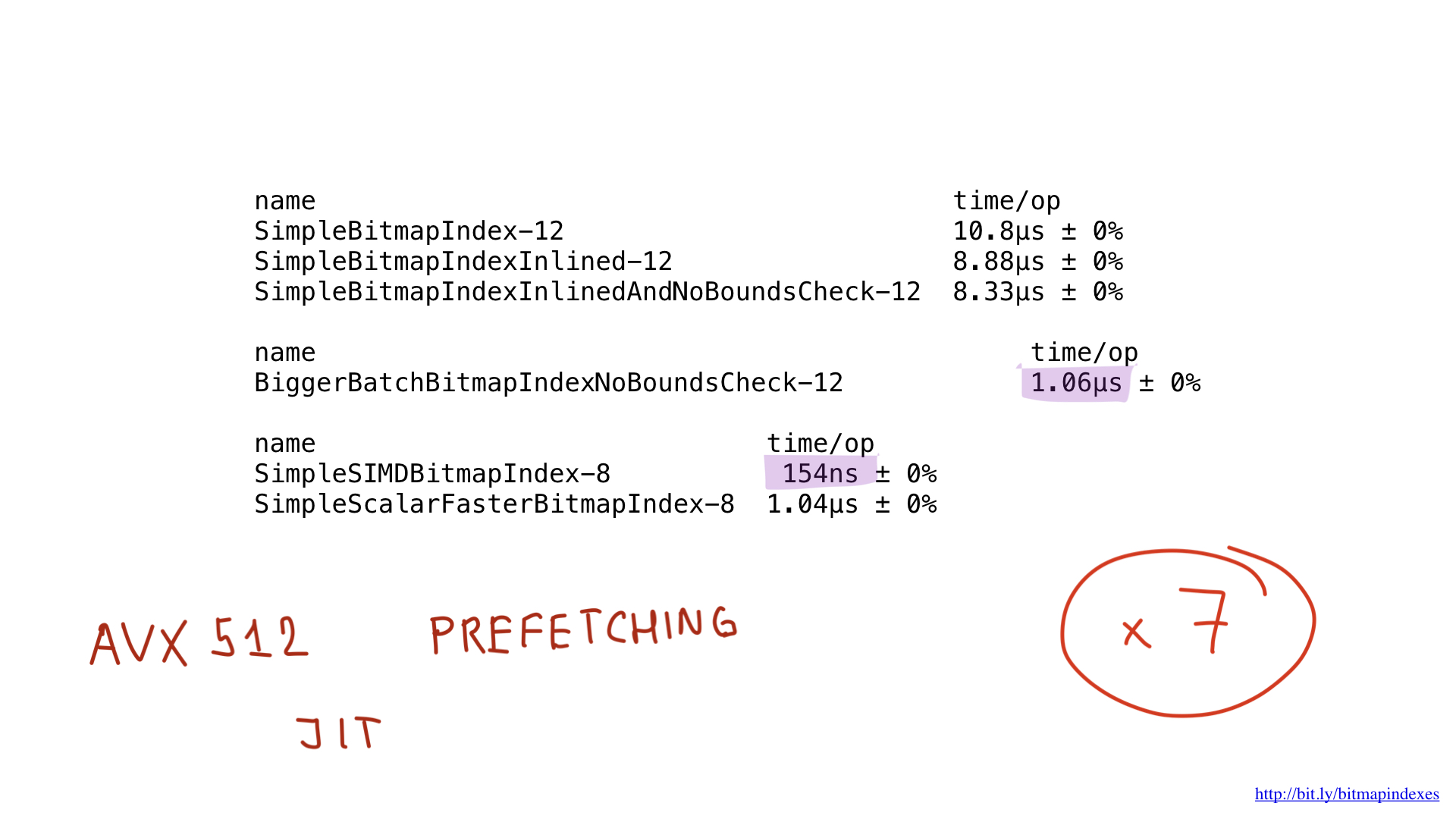
Tetapi bahkan implementasi ini berpotensi dipercepat dengan menggunakan AVX-512, prefetching atau JIT (just-in-time compiler) untuk perencana kueri. Tetapi ini tentu saja merupakan topik untuk laporan terpisah.
Masalah Indeks Bitmap
Sekarang kita telah melihat implementasi sederhana dari indeks bitmap Go dan bahasa assembly yang jauh lebih efisien, mari kita bicara tentang mengapa indeks bitmap sangat jarang digunakan.

Dalam makalah ilmiah lama, tiga masalah indeks bitmap disebutkan, tetapi makalah ilmiah baru dan saya berpendapat bahwa mereka tidak lagi relevan. Kami tidak akan mempelajari secara mendalam masing-masing masalah ini, tetapi kami akan mempertimbangkannya secara dangkal.
Masalah kardinalitas yang hebat
Jadi, kita diberitahu bahwa indeks bitmap hanya cocok untuk bidang dengan kardinalitas rendah, yaitu yang memiliki sedikit nilai (misalnya, jenis kelamin atau warna mata), dan alasannya adalah bahwa representasi biasa bidang tersebut (satu bit per nilai) dalam kasus kardinalitas besar, itu akan memakan terlalu banyak ruang dan, lebih lagi, indeks bitmap ini akan lemah (jarang) diisi.
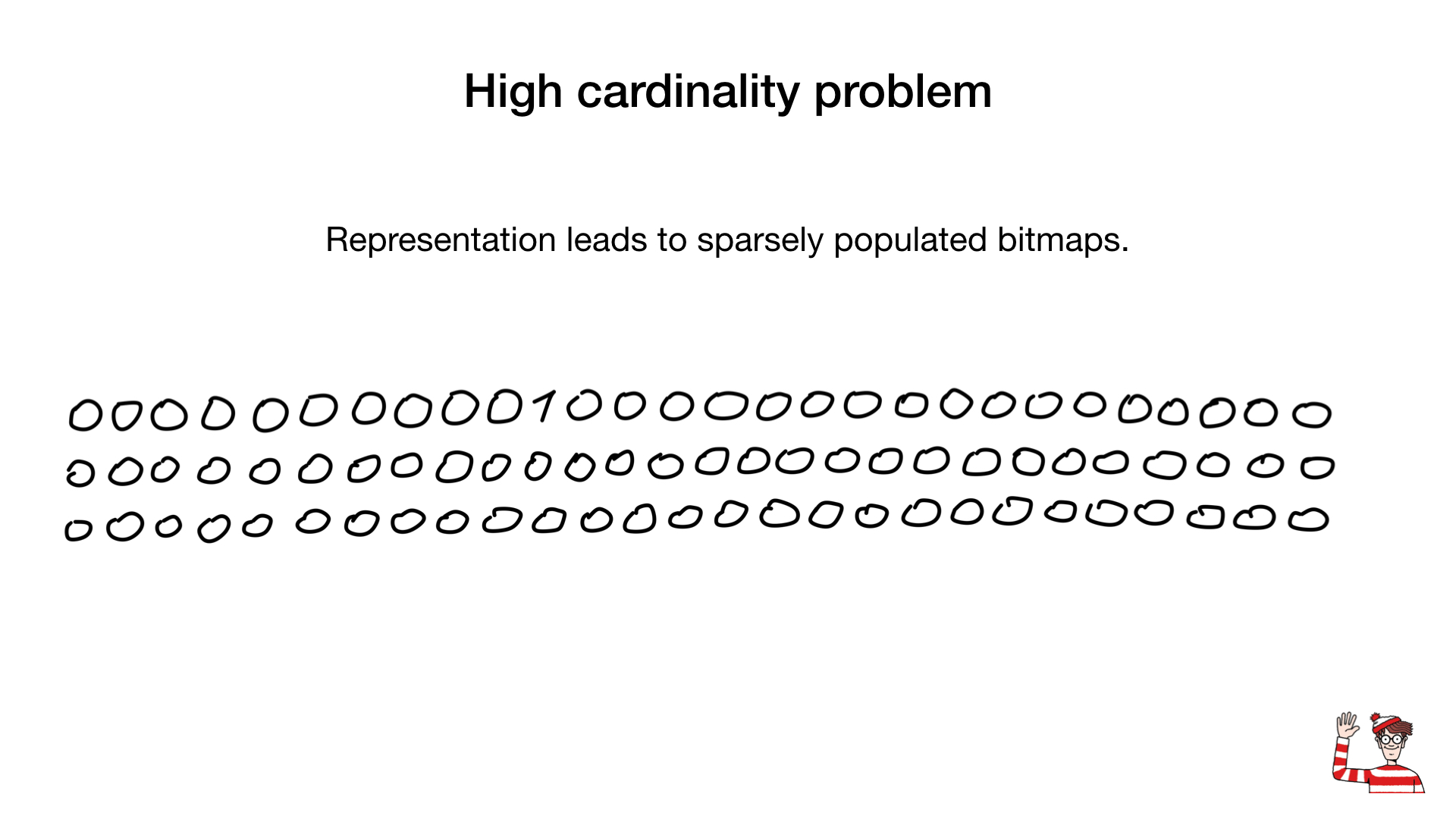
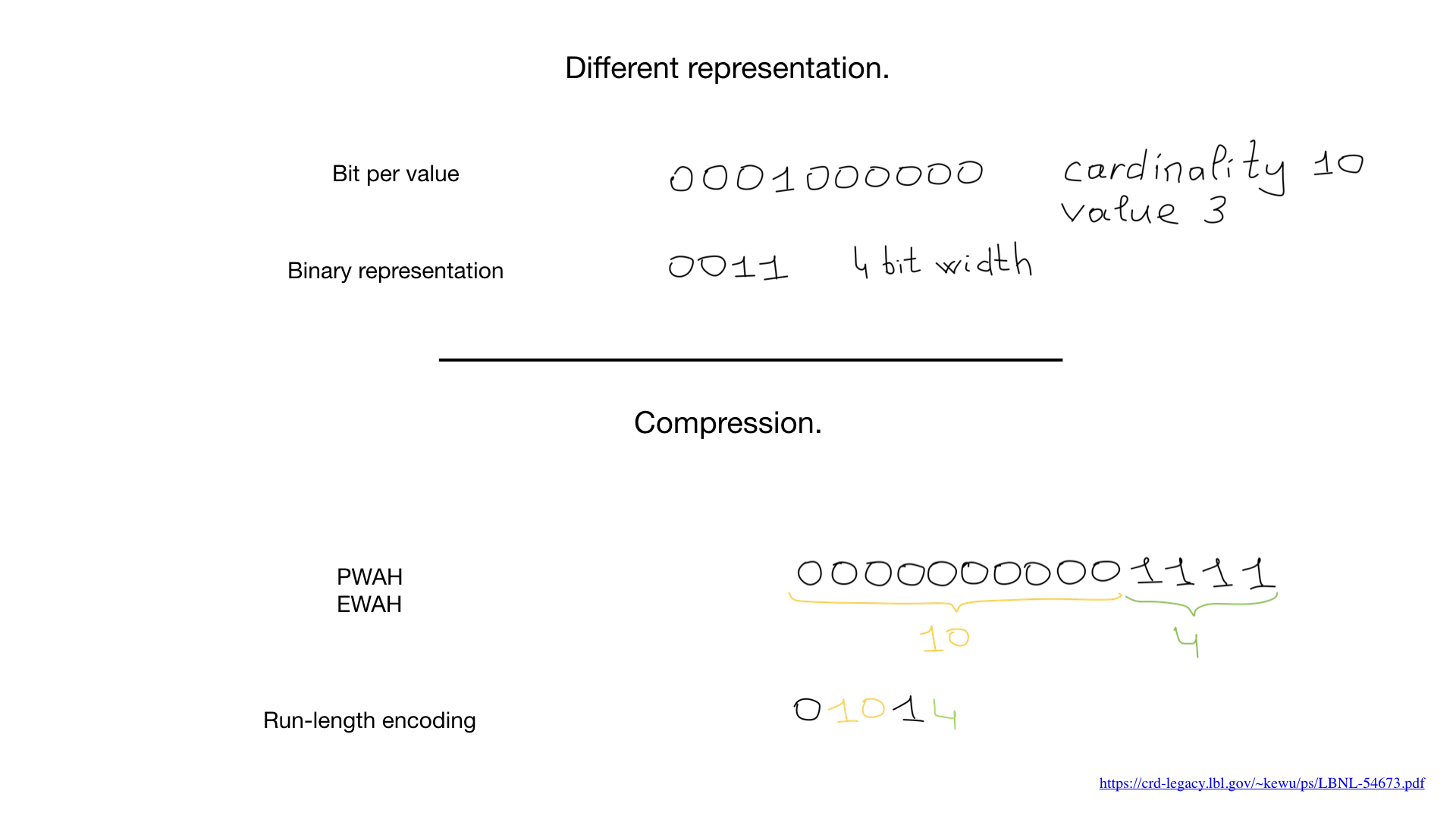 Terkadang kita dapat menggunakan representasi lain, misalnya yang standar, yang kita gunakan untuk mewakili angka. Tetapi munculnya algoritma kompresi yang mengubah segalanya. Selama beberapa dekade terakhir, para ilmuwan dan peneliti telah menghasilkan sejumlah besar algoritma kompresi untuk bitmap. Keuntungan utama mereka adalah Anda tidak perlu memperluas bitmap untuk operasi bit - kami dapat melakukan operasi bit secara langsung pada bitmap terkompresi.
Terkadang kita dapat menggunakan representasi lain, misalnya yang standar, yang kita gunakan untuk mewakili angka. Tetapi munculnya algoritma kompresi yang mengubah segalanya. Selama beberapa dekade terakhir, para ilmuwan dan peneliti telah menghasilkan sejumlah besar algoritma kompresi untuk bitmap. Keuntungan utama mereka adalah Anda tidak perlu memperluas bitmap untuk operasi bit - kami dapat melakukan operasi bit secara langsung pada bitmap terkompresi. Baru-baru ini, pendekatan hybrid sudah mulai muncul, seperti bitmap menderu. Mereka secara bersamaan menggunakan tiga representasi berbeda untuk bitmap - sebenarnya bitmap, array dan yang disebut bit run - dan menyeimbangkan di antara mereka untuk memaksimalkan kinerja dan meminimalkan konsumsi memori.
Baru-baru ini, pendekatan hybrid sudah mulai muncul, seperti bitmap menderu. Mereka secara bersamaan menggunakan tiga representasi berbeda untuk bitmap - sebenarnya bitmap, array dan yang disebut bit run - dan menyeimbangkan di antara mereka untuk memaksimalkan kinerja dan meminimalkan konsumsi memori.roaring . , Go.
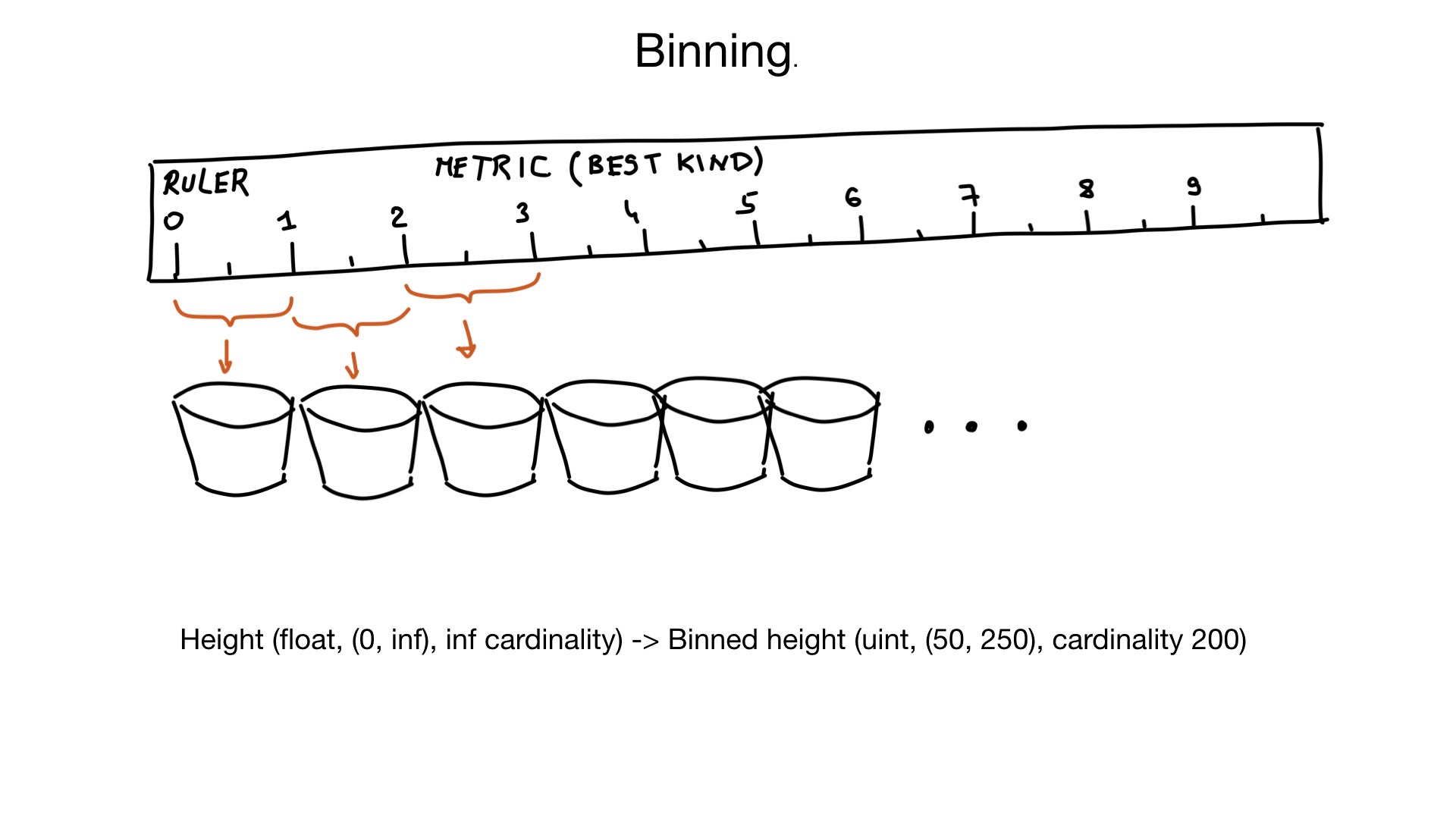
, , (binning). , , . — , , , . 185,2 185,3 .
, 1 .
, 50 250 , , , 200 .
, .
bitmap- , .
, . , . , , — lock contention, .
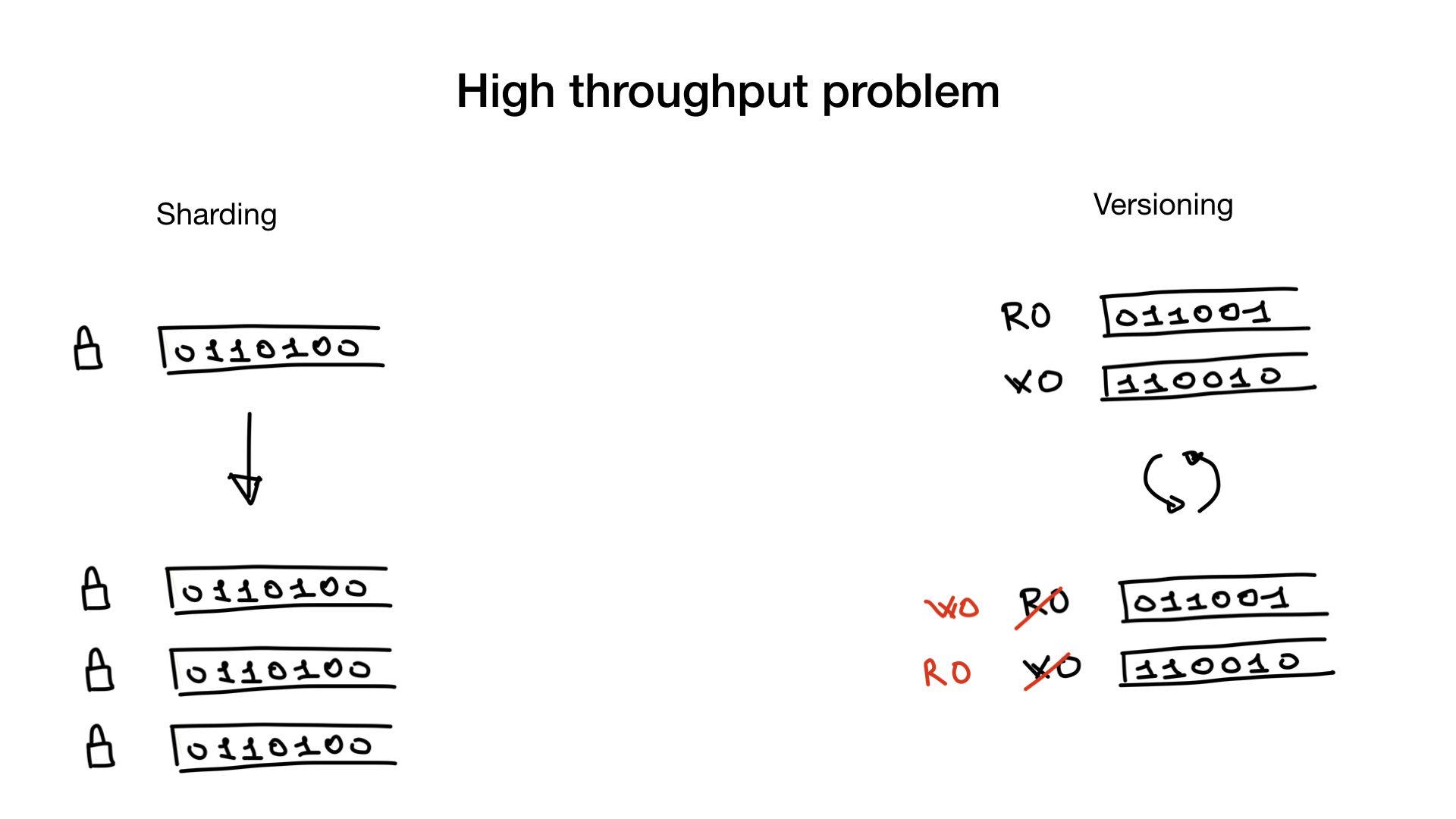
.
— . bitmap- , . lock contention.
— . , , — . - (, 100 500 ) . , , .
: .
bitmap- , , , , « ».
, , AND, OR . . - « 200 300 ».

OR.

. , 50 . 50 .
, . range-encoded bitmaps.

- (, 200), , . 200 . 300: 300 . Dan sebagainya.
, , . , 300 , , 199 . Selesai

, bitmap-. , , . , S2 Google. , . « » ( ).
Solusi siap pakai
. - - , , .
, , bitmap- . , SIMD, .
, , .

Roaring
-, roaring bitmaps-, . , , bitmap-.
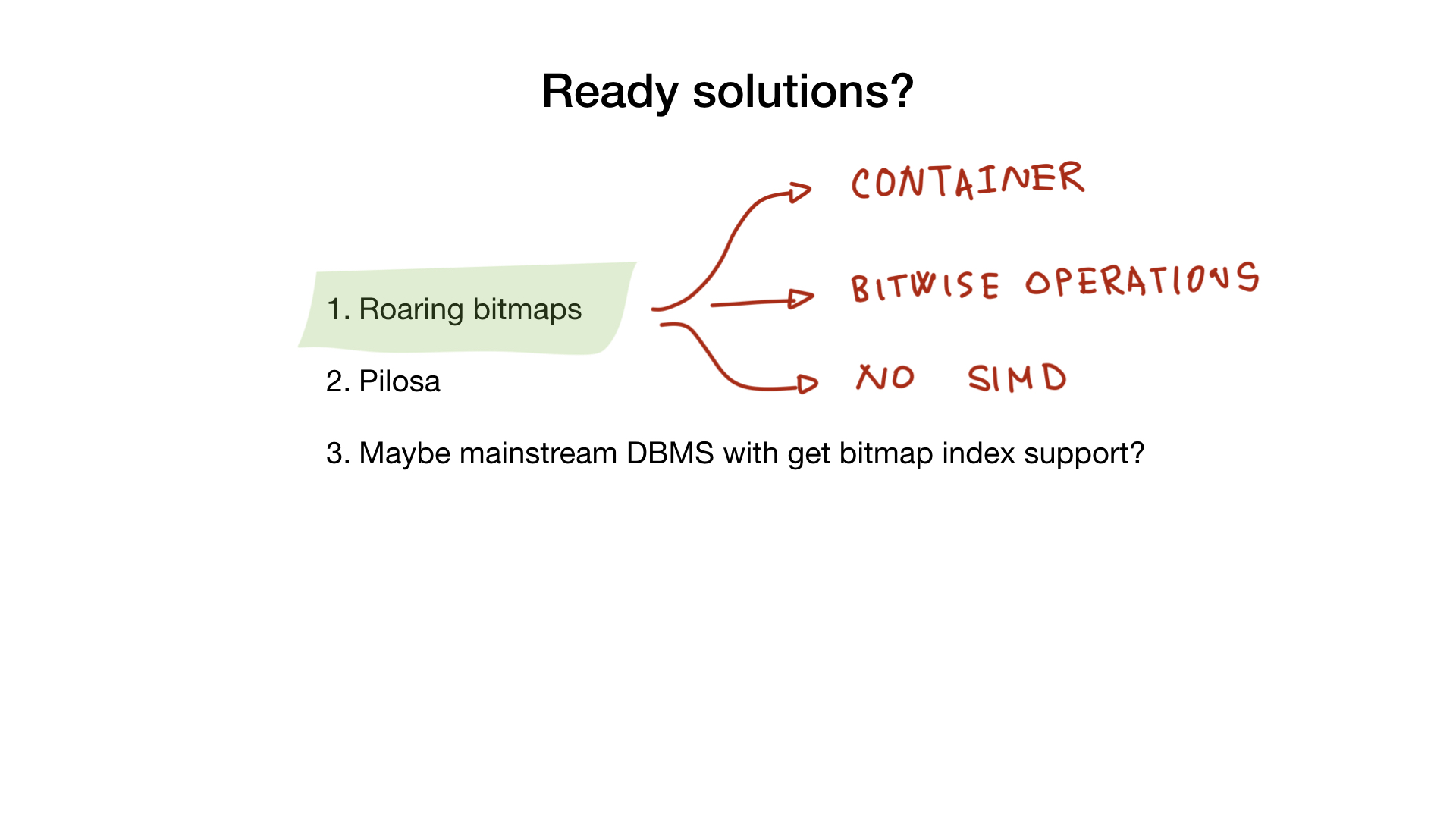
, Go- SIMD, , Go- , C, .
Pilosa
, , — Pilosa, , , bitmap- . , .
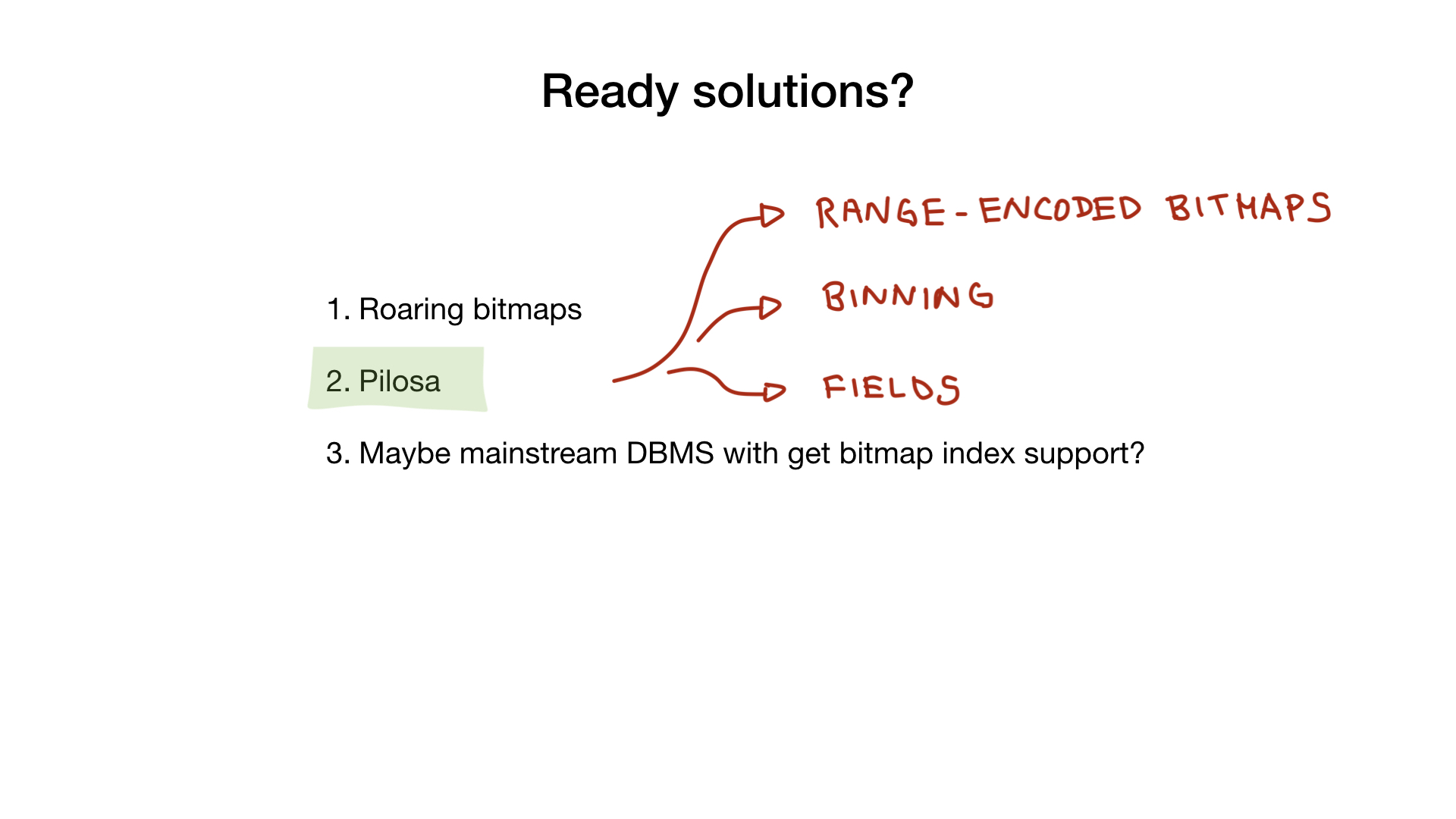
Pilosa roaring , , : , range-encoded bitmaps, . .
Pilosa .

, . Pilosa, , , , .
NOT «expensive», ( AND-) «terrace» «reservations». , .

, MySQL PostgreSQL — bitmap-.

Kesimpulan

Jika Anda belum tertidur, terima kasih. Saya harus menyinggung banyak topik secara sepintas karena keterbatasan waktu, tetapi saya berharap laporan ini bermanfaat dan, mungkin, bahkan memotivasi.
Adalah baik untuk mengetahui tentang indeks bitmap, bahkan jika Anda tidak membutuhkannya sekarang. Biarkan mereka menjadi alat lain di laci Anda.
Kami telah membahas berbagai trik kinerja untuk Go dan hal-hal yang tidak dilakukan dengan baik oleh kompiler Go. Tetapi ini sangat berguna untuk diketahui oleh setiap programmer Go.
Hanya itu yang ingin saya sampaikan. Terima kasih