Kami telah membahas
mesin pengindeksan PostgreSQL, antarmuka metode akses, dan metode akses utama, seperti:
indeks hash ,
B-tree ,
GiST ,
SP-GiST , dan
GIN . Pada artikel ini, kita akan melihat bagaimana gin berubah menjadi rum.
RUM
Meskipun penulis mengklaim bahwa gin adalah jin yang kuat, tema minuman akhirnya menang: GIN generasi berikutnya telah disebut RUM.
Metode akses ini memperluas konsep yang mendasari GIN dan memungkinkan kami untuk melakukan pencarian teks lengkap lebih cepat. Dalam seri artikel ini, ini adalah satu-satunya metode yang tidak termasuk dalam pengiriman PostgreSQL standar dan merupakan ekstensi eksternal. Beberapa opsi instalasi tersedia untuknya:
- Ambil paket "yum" atau "apt" dari repositori PGDG . Sebagai contoh, jika Anda menginstal PostgreSQL dari paket "postgresql-10", instal juga "postgresql-10-rum".
- Bangun dari kode sumber di github dan instal sendiri (instruksi juga ada di sana).
- Gunakan sebagai bagian dari Postgres Pro Enterprise (atau setidaknya baca dokumentasi dari sana).
Keterbatasan gin
Keterbatasan GIN apa yang memungkinkan RUM untuk melampaui kita?
Pertama, tipe data "tsvector" tidak hanya berisi leksem, tetapi juga informasi tentang posisi mereka di dalam dokumen. Seperti yang kami amati
terakhir kali , indeks GIN tidak menyimpan informasi ini. Karena alasan ini, operasi untuk mencari frasa, yang muncul dalam versi 9.6, didukung oleh indeks GIN secara tidak efisien dan harus mengakses data asli untuk diperiksa ulang.
Kedua, sistem pencarian biasanya mengembalikan hasil yang diurutkan berdasarkan relevansi (apa pun artinya). Kita dapat menggunakan fungsi peringkat "ts_rank" dan "ts_rank_cd" untuk tujuan ini, tetapi mereka harus dihitung untuk setiap baris hasil, yang tentu saja lambat.
Untuk perkiraan pertama, metode akses RUM dapat dianggap sebagai GIN yang juga menyimpan informasi posisi dan dapat mengembalikan hasil dalam urutan yang diperlukan (seperti
GiST dapat mengembalikan tetangga terdekat). Mari kita bergerak selangkah demi selangkah.
Mencari frasa
Permintaan pencarian teks lengkap dapat berisi operator khusus yang memperhitungkan jarak antar leksem. Misalnya, kita dapat menemukan dokumen di mana "tangan" dipisahkan dari "paha" dengan dua kata lagi:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <3> thigh');
?column? ---------- t (1 row)
Atau kita dapat menunjukkan bahwa kata-kata harus ditempatkan satu demi satu:
postgres=# select to_tsvector('Clap your hands, slap your thigh') @@ to_tsquery('hand <-> slap');
?column? ---------- t (1 row)
Indeks GIN biasa dapat mengembalikan dokumen yang berisi kedua leksem tersebut, tetapi kami dapat memeriksa jarak di antara keduanya hanya dengan melihat ke dalam tsvector:
postgres=# select to_tsvector('Clap your hands, slap your thigh');
to_tsvector -------------------------------------- 'clap':1 'hand':3 'slap':4 'thigh':6 (1 row)
Dalam indeks RUM, setiap leksem tidak hanya mereferensikan baris tabel: setiap TID disediakan dengan daftar posisi di mana leksem terjadi dalam dokumen. Ini adalah bagaimana kita dapat membayangkan indeks yang dibuat pada tabel "slit-sheet", yang sudah cukup akrab bagi kita ("rum_tsvector_ops" kelas operator digunakan untuk tsvector secara default):
postgres=# create extension rum; postgres=# create index on ts using rum(doc_tsv);
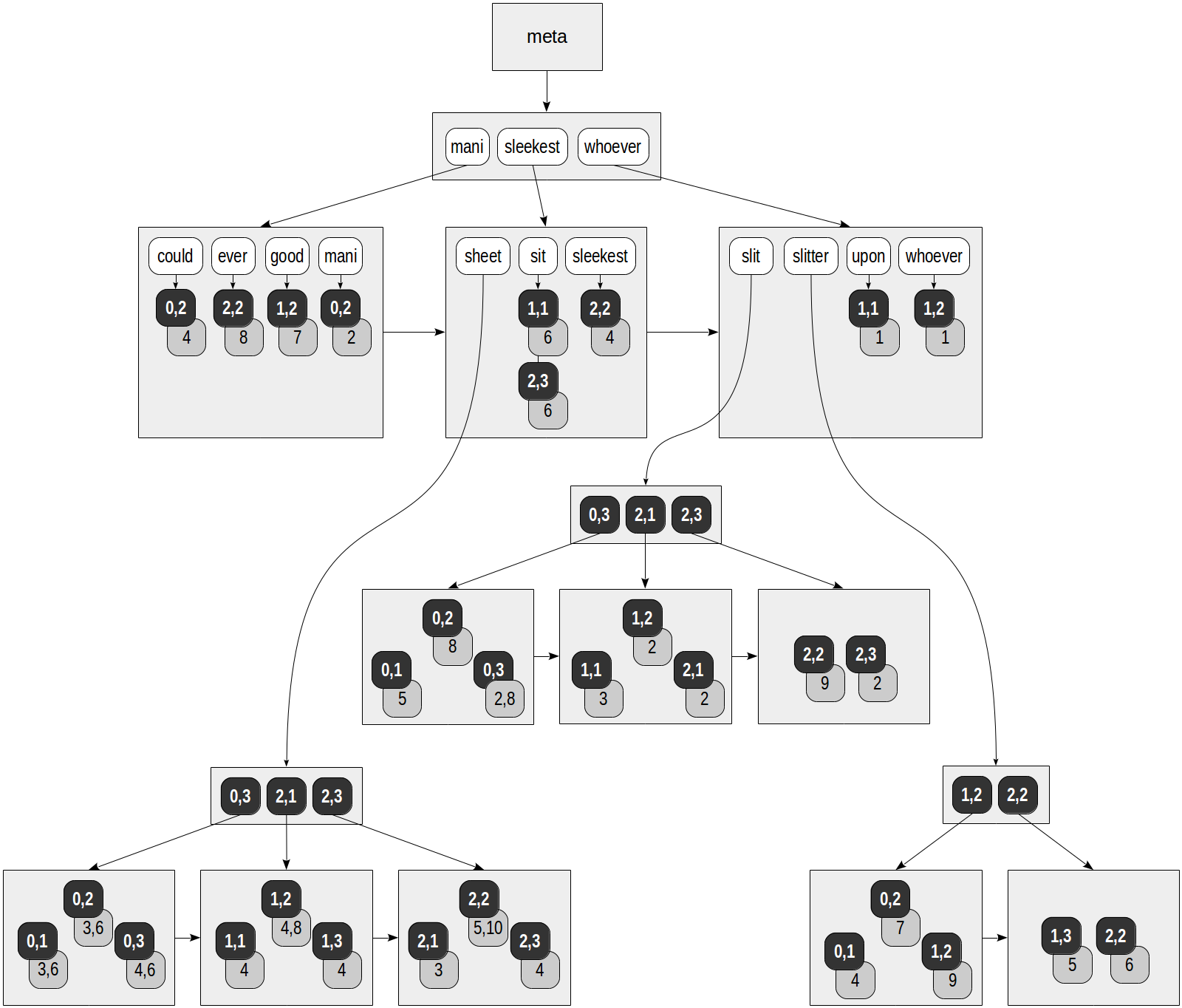
Kotak abu-abu pada gambar berisi informasi posisi yang ditambahkan:
postgres=# select ctid, left(doc,20), doc_tsv from ts;
ctid | left | doc_tsv -------+----------------------+--------------------------------------------------------- (0,1) | Can a sheet slitter | 'sheet':3,6 'slit':5 'slitter':4 (0,2) | How many sheets coul | 'could':4 'mani':2 'sheet':3,6 'slit':8 'slitter':7 (0,3) | I slit a sheet, a sh | 'sheet':4,6 'slit':2,8 (1,1) | Upon a slitted sheet | 'sheet':4 'sit':6 'slit':3 'upon':1 (1,2) | Whoever slit the she | 'good':7 'sheet':4,8 'slit':2 'slitter':9 'whoever':1 (1,3) | I am a sheet slitter | 'sheet':4 'slitter':5 (2,1) | I slit sheets. | 'sheet':3 'slit':2 (2,2) | I am the sleekest sh | 'ever':8 'sheet':5,10 'sleekest':4 'slit':9 'slitter':6 (2,3) | She slits the sheet | 'sheet':4 'sit':6 'slit':2 (9 rows)
GIN juga menyediakan penyisipan yang ditunda ketika parameter "pembaruan cepat" ditentukan; fungsi ini dihapus dari RUM.
Untuk melihat bagaimana indeks bekerja pada data langsung, mari kita gunakan
arsip dari mailing list pgsql-hacker.
fts=# alter table mail_messages add column tsv tsvector; fts=# set default_text_search_config = default; fts=# update mail_messages set tsv = to_tsvector(body_plain);
... UPDATE 356125
Ini adalah bagaimana kueri yang menggunakan pencarian frasa dilakukan dengan indeks GIN:
fts=# create index tsv_gin on mail_messages using gin(tsv); fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.490..18.088 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Rows Removed by Index Recheck: 1517 Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual time=2.204..2.204 rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.266 ms Execution time: 18.151 ms (8 rows)
Seperti yang dapat kita lihat dari rencana, indeks GIN digunakan, tetapi mengembalikan 1776 pertandingan potensial, yang tersisa 259 dan 1517 dijatuhkan pada tahap periksa ulang.
Mari kita hapus indeks GIN dan bangun RUM.
fts=# drop index tsv_gin; fts=# create index tsv_rum on mail_messages using rum(tsv);
Indeks sekarang berisi semua informasi yang diperlukan, dan pencarian dilakukan dengan akurat:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello <-> hackers');
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on mail_messages (actual time=2.798..3.015 rows=259 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Heap Blocks: exact=250 -> Bitmap Index Scan on tsv_rum (actual time=2.768..2.768 rows=259 loops=1) Index Cond: (tsv @@ to_tsquery('hello <-> hackers'::text)) Planning time: 0.245 ms Execution time: 3.053 ms (7 rows)
Menyortir berdasarkan relevansi
Untuk mengembalikan dokumen dengan mudah dalam urutan yang diperlukan, indeks RUM mendukung operator pemesanan, yang kami bahas dalam artikel terkait
GiST . Ekstensi RUM mendefinisikan operator seperti itu,
<=> , yang mengembalikan jarak antara dokumen ("tsvector") dan permintaan ("tsquery"). Sebagai contoh:
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=>l to_tsquery('slit');
?column? ---------- 16.4493 (1 row)
fts=# select to_tsvector('Can a sheet slitter slit sheets?') <=> to_tsquery('sheet');
?column? ---------- 13.1595 (1 row)
Dokumen itu tampaknya lebih relevan dengan permintaan pertama daripada yang kedua: semakin sering kata itu muncul, semakin sedikit "berharganya" itu.
Mari kita coba lagi membandingkan GIN dan RUM pada ukuran data yang relatif besar: kita akan memilih sepuluh dokumen paling relevan yang berisi "halo" dan "peretas".
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by ts_rank(tsv,to_tsquery('hello & hackers')) limit 10;
QUERY PLAN --------------------------------------------------------------------------------------------- Limit (actual time=27.076..27.078 rows=10 loops=1) -> Sort (actual time=27.075..27.076 rows=10 loops=1) Sort Key: (ts_rank(tsv, to_tsquery('hello & hackers'::text))) Sort Method: top-N heapsort Memory: 29kB -> Bitmap Heap Scan on mail_messages (actual ... rows=1776 loops=1) Recheck Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Heap Blocks: exact=1503 -> Bitmap Index Scan on tsv_gin (actual ... rows=1776 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Planning time: 0.276 ms Execution time: 27.121 ms (11 rows)
Indeks GIN menghasilkan 1776 pertandingan, yang kemudian diurutkan sebagai langkah terpisah untuk memilih sepuluh klik terbaik.
Dengan indeks RUM, kueri dilakukan menggunakan pemindaian indeks sederhana: tidak ada dokumen tambahan yang dilihat, dan tidak diperlukan penyortiran terpisah:
fts=# explain (costs off, analyze) select * from mail_messages where tsv @@ to_tsquery('hello & hackers') order by tsv <=> to_tsquery('hello & hackers') limit 10;
QUERY PLAN -------------------------------------------------------------------------------------------- Limit (actual time=5.083..5.171 rows=10 loops=1) -> Index Scan using tsv_rum on mail_messages (actual ... rows=10 loops=1) Index Cond: (tsv @@ to_tsquery('hello & hackers'::text)) Order By: (tsv <=> to_tsquery('hello & hackers'::text)) Planning time: 0.244 ms Execution time: 5.207 ms (6 rows)
Informasi tambahan
Indeks RUM, serta GIN, dapat dibangun di beberapa bidang. Tetapi sementara GIN menyimpan leksem dari setiap kolom secara terpisah dari yang dari kolom lain, RUM memungkinkan kita untuk "mengasosiasikan" bidang utama ("tsvector" dalam kasus ini) dengan yang tambahan. Untuk melakukan ini, kita perlu menggunakan kelas operator khusus "rum_tsvector_addon_ops":
fts=# create index on mail_messages using rum(tsv RUM_TSVECTOR_ADDON_OPS, sent) WITH (ATTACH='sent', TO='tsv');
Kami dapat menggunakan indeks ini untuk mengembalikan hasil yang diurutkan pada bidang tambahan:
fts=# select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
id | sent | ?column? ---------+---------------------+---------- 2298548 | 2017-01-01 15:03:22 | 202 2298547 | 2017-01-01 14:53:13 | 407 2298545 | 2017-01-01 13:28:12 | 5508 2298554 | 2017-01-01 18:30:45 | 12645 2298530 | 2016-12-31 20:28:48 | 66672 2298587 | 2017-01-02 12:39:26 | 77966 2298588 | 2017-01-02 12:43:22 | 78202 2298597 | 2017-01-02 13:48:02 | 82082 2298606 | 2017-01-02 15:50:50 | 89450 2298628 | 2017-01-02 18:55:49 | 100549 (10 rows)
Di sini kami mencari baris yang cocok sedekat mungkin dengan tanggal yang ditentukan, tidak peduli sebelumnya atau nanti. Untuk mendapatkan hasil yang secara ketat mendahului (atau mengikuti) tanggal yang ditentukan, kita perlu menggunakan
<=| (atau
|=> ) operator.
Seperti yang kami harapkan, kueri dilakukan hanya dengan pemindaian indeks sederhana:
ts=# explain (costs off) select id, sent, sent <=> '2017-01-01 15:00:00' from mail_messages where tsv @@ to_tsquery('hello') order by sent <=> '2017-01-01 15:00:00' limit 10;
QUERY PLAN --------------------------------------------------------------------------------- Limit -> Index Scan using mail_messages_tsv_sent_idx on mail_messages Index Cond: (tsv @@ to_tsquery('hello'::text)) Order By: (sent <=> '2017-01-01 15:00:00'::timestamp without time zone) (4 rows)
Jika kami membuat indeks tanpa informasi tambahan tentang asosiasi lapangan, untuk permintaan yang sama, kami harus mengurutkan semua hasil pemindaian indeks.
Selain tanggal, kami tentu saja dapat menambahkan bidang tipe data lain ke indeks RUM. Hampir semua tipe dasar didukung. Misalnya, toko online dapat dengan cepat menampilkan barang berdasarkan kebaruan (tanggal), harga (numerik), dan nilai popularitas atau diskon (integer atau floating-point).
Kelas operator lainnya
Untuk melengkapi gambar, kita harus menyebutkan kelas operator lain yang tersedia.
Mari kita mulai dengan
"rum_tsvector_hash_ops" dan
"rum_tsvector_hash_addon_ops" . Mereka mirip dengan yang sudah dibahas "rum_tsvector_ops" dan "rum_tsvector_addon_ops", tetapi indeks menyimpan kode hash dari lexeme daripada lexeme itu sendiri. Ini dapat mengurangi ukuran indeks, tetapi tentu saja, pencarian menjadi kurang akurat dan memerlukan pengecekan ulang. Selain itu, indeks tidak lagi mendukung pencarian kecocokan parsial.
Sangat menarik untuk melihat kelas operator
"rum_tsquery_ops" . Ini memungkinkan kami untuk memecahkan masalah "terbalik": temukan pertanyaan yang cocok dengan dokumen. Mengapa ini diperlukan? Misalnya, untuk berlangganan pengguna ke barang baru sesuai dengan filternya atau untuk secara otomatis mengkategorikan dokumen baru. Lihatlah contoh sederhana ini:
fts=# create table categories(query tsquery, category text); fts=# insert into categories values (to_tsquery('vacuum | autovacuum | freeze'), 'vacuum'), (to_tsquery('xmin | xmax | snapshot | isolation'), 'mvcc'), (to_tsquery('wal | (write & ahead & log) | durability'), 'wal'); fts=# create index on categories using rum(query); fts=# select array_agg(category) from categories where to_tsvector( 'Hello hackers, the attached patch greatly improves performance of tuple freezing and also reduces size of generated write-ahead logs.' ) @@ query;
array_agg -------------- {vacuum,wal} (1 row)
Kelas operator yang tersisa
"rum_anyarray_ops" dan
"rum_anyarray_addon_ops" dirancang untuk memanipulasi array daripada "tsvector". Ini sudah dibahas untuk GIN
terakhir kali dan tidak perlu diulang.
Ukuran indeks dan log write-ahead (WAL)
Jelas bahwa karena RUM menyimpan lebih banyak informasi daripada GIN, RUM harus berukuran lebih besar. Kami membandingkan ukuran indeks yang berbeda terakhir kali; mari tambahkan RUM ke tabel ini:
rum | gin | gist | btree --------+--------+--------+-------- 457 MB | 179 MB | 125 MB | 546 MB
Seperti yang dapat kita lihat, ukurannya tumbuh cukup signifikan, yang merupakan biaya pencarian cepat.
Perlu memperhatikan satu hal lagi yang tidak jelas: RUM adalah ekstensi, yaitu, dapat diinstal tanpa modifikasi pada inti sistem. Ini diaktifkan di versi 9.6 berkat tambalan oleh
Alexander Korotkov . Salah satu masalah yang harus dipecahkan untuk tujuan ini adalah pembuatan catatan log. Teknik untuk pencatatan operasi harus benar-benar andal, oleh karena itu, ekstensi tidak dapat dibiarkan masuk ke dapur ini. Alih-alih mengizinkan ekstensi untuk membuat jenis catatan log sendiri, berikut ini ada di tempat: kode ekstensi mengomunikasikan niatnya untuk memodifikasi halaman, membuat perubahan apa pun padanya, dan memberi sinyal penyelesaian, dan itu adalah inti sistem, yang membandingkan versi lama dan baru dari halaman dan menghasilkan catatan log yang disatukan diperlukan.
Algoritma pembuatan log saat ini membandingkan halaman byte demi byte, mendeteksi fragmen yang diperbarui, dan mencatat masing-masing fragmen ini, beserta offsetnya dari mulai halaman. Ini berfungsi dengan baik ketika memperbarui hanya beberapa byte atau seluruh halaman. Tetapi jika kita menambahkan fragmen di dalam halaman, memindahkan sisa konten ke bawah (atau sebaliknya, menghapus fragmen, memindahkan konten ke atas), secara signifikan lebih banyak byte akan berubah daripada yang sebenarnya ditambahkan atau dihapus.
Karena hal ini, indeks RUM yang diubah secara intensif dapat menghasilkan catatan log dengan ukuran yang jauh lebih besar daripada GIN (yang, karena bukan merupakan ekstensi, tetapi bagian dari inti, mengelola log itu sendiri). Tingkat efek menjengkelkan ini sangat tergantung pada beban kerja yang sebenarnya, tetapi untuk mendapatkan wawasan tentang masalah ini, mari kita coba untuk menghapus dan menambahkan sejumlah baris beberapa kali, menghubungkan operasi-operasi ini dengan "vakum". Kita dapat mengevaluasi ukuran catatan log sebagai berikut: di awal dan di akhir, ingat posisi dalam log menggunakan fungsi "pg_current_wal_location" ("pg_current_xlog_location" dalam versi lebih awal dari sepuluh) dan kemudian lihat perbedaannya.
Tetapi tentu saja, kita harus mempertimbangkan banyak aspek di sini. Kami perlu memastikan bahwa hanya satu pengguna yang bekerja dengan sistem (jika tidak, catatan "ekstra" akan diperhitungkan). Bahkan jika ini masalahnya, kami memperhitungkan tidak hanya RUM, tetapi juga pembaruan tabel itu sendiri dan indeks yang mendukung kunci utama. Nilai parameter konfigurasi juga memengaruhi ukuran (level log "replika", tanpa kompresi, digunakan di sini). Tapi mari kita coba.
fts=# select pg_current_wal_location() as start_lsn \gset
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 0;
INSERT 0 3576
fts=# delete from mail_messages where id % 100 = 99;
DELETE 3590
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 1;
INSERT 0 3605
fts=# delete from mail_messages where id % 100 = 98;
DELETE 3637
fts=# vacuum mail_messages;
fts=# insert into mail_messages(parent_id, sent, subject, author, body_plain, tsv) select parent_id, sent, subject, author, body_plain, tsv from mail_messages where id % 100 = 2;
INSERT 0 3625
fts=# delete from mail_messages where id % 100 = 97;
DELETE 3668
fts=# vacuum mail_messages;
fts=# select pg_current_wal_location() as end_lsn \gset fts=# select pg_size_pretty(:'end_lsn'::pg_lsn - :'start_lsn'::pg_lsn);
pg_size_pretty ---------------- 3114 MB (1 row)
Jadi, kami mendapatkan sekitar 3 GB. Tetapi jika kami mengulangi percobaan yang sama dengan indeks GIN, ini hanya akan menghasilkan sekitar 700 MB.
Oleh karena itu, diinginkan untuk memiliki algoritma yang berbeda, yang akan menemukan jumlah minimal operasi insert dan delete yang dapat mengubah satu keadaan halaman menjadi yang lain. Utilitas "Diff" bekerja dengan cara yang sama.
Oleg Ivanov telah menerapkan algoritma semacam itu, dan
tambalannya sedang dibahas. Dalam contoh di atas, tambalan ini memungkinkan kita untuk mengurangi ukuran catatan log sebanyak 1,5 kali, menjadi 1900 MB, dengan biaya perlambatan kecil.
Sayangnya, tambalan macet dan tidak ada aktivitas di sekitarnya.
Properti
Seperti biasa, mari kita lihat properti dari metode akses RUM, memperhatikan perbedaan dari GIN (pertanyaan
telah disediakan ).
Berikut ini adalah properti dari metode akses:
amname | name | pg_indexam_has_property --------+---------------+------------------------- rum | can_order | f rum | can_unique | f rum | can_multi_col | t rum | can_exclude | t -- f for gin
Properti lapisan indeks berikut tersedia:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | t -- f for gin bitmap_scan | t backward_scan | f
Perhatikan bahwa, tidak seperti GIN, RUM mendukung pemindaian indeks - jika tidak, RUM tidak akan mungkin mengembalikan jumlah hasil yang diinginkan secara tepat dalam kueri dengan klausa "batas". Tidak perlu untuk counterpart dari parameter "gin_fuzzy_search_limit" sesuai. Dan sebagai konsekuensinya, indeks dapat digunakan untuk mendukung batasan pengecualian.
Berikut ini adalah properti lapisan-kolom:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | t -- f for gin returnable | f search_array | f search_nulls | f
Perbedaannya di sini adalah bahwa RUM mendukung operator pemesanan. Namun, ini benar bukan untuk semua kelas operator: misalnya, ini salah untuk "tsquery_ops".
Baca terus .