Hai
Tahukah Anda bahwa platform iklan sering menyalin konten dari pesaing untuk meningkatkan jumlah iklan yang dihosting? Mereka melakukannya dengan cara ini: mereka memanggil penjual dan menawarkan mereka untuk menetap di platform mereka. Dan terkadang mereka sepenuhnya menyalin iklan tanpa izin pengguna. Avito adalah tempat yang populer, dan kami sering menghadapi persaingan yang tidak adil. Baca tentang bagaimana kami melawan fenomena ini, baca di bawah potongan.

Masalah
Menyalin konten dari Avito ke platform lain ada dalam beberapa kategori barang dan layanan. Artikel ini hanya akan fokus pada mobil. Dalam posting sebelumnya, saya berbicara tentang bagaimana kami menyembunyikan nomor otomatis pada mobil.

Tetapi ternyata (dilihat dari hasil pencarian platform lain) kami segera meluncurkan fitur ini di tiga situs pengumuman.

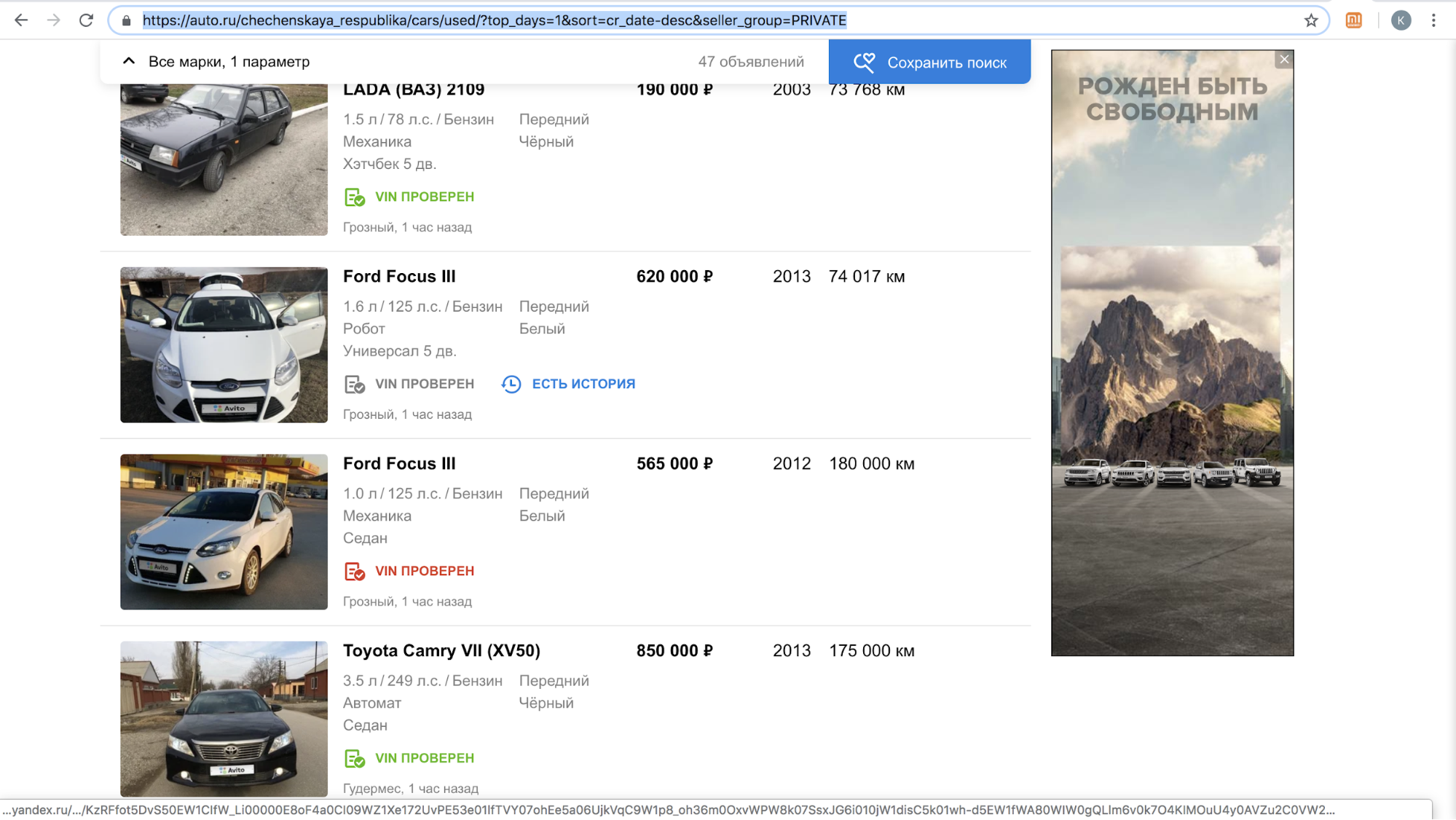
Setelah meluncurkan fitur, salah satu situs ini ditangguhkan sementara memanggil pengguna kami dengan penawaran untuk menyalin pengumuman di platform mereka: ada terlalu banyak konten dengan logo Avito di situs mereka, pada bulan November 2018 saja ada lebih dari 70.000 iklan. Misalnya, seperti inilah hasil pencarian mereka per hari di Republik Chechnya.
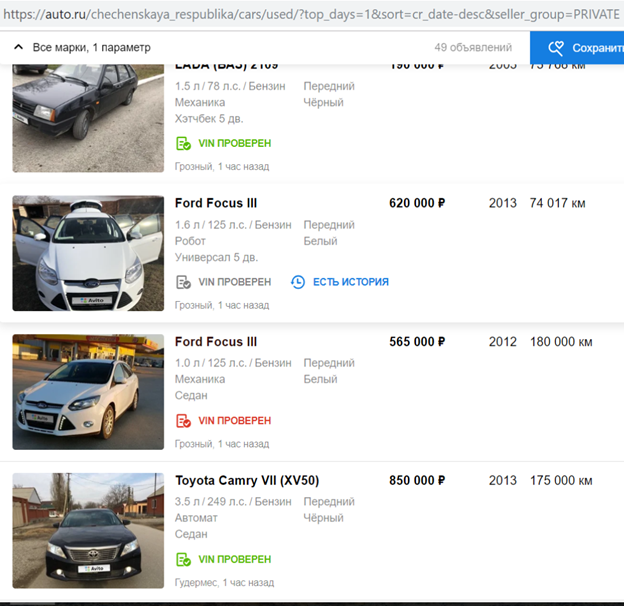
Setelah menyelesaikan algoritme mereka untuk menyembunyikan plat nomor sehingga secara otomatis mendeteksi dan menutup logo Avito, mereka melanjutkan proses.

Dari sudut pandang kami, menyalin konten pesaing, menggunakannya untuk tujuan komersial adalah tidak etis dan tidak dapat diterima. Kami menerima keluhan dari pengguna kami, yang tidak senang dengan ini, dalam dukungan kami. Dan ini adalah contoh reaksi di salah satu cerita.
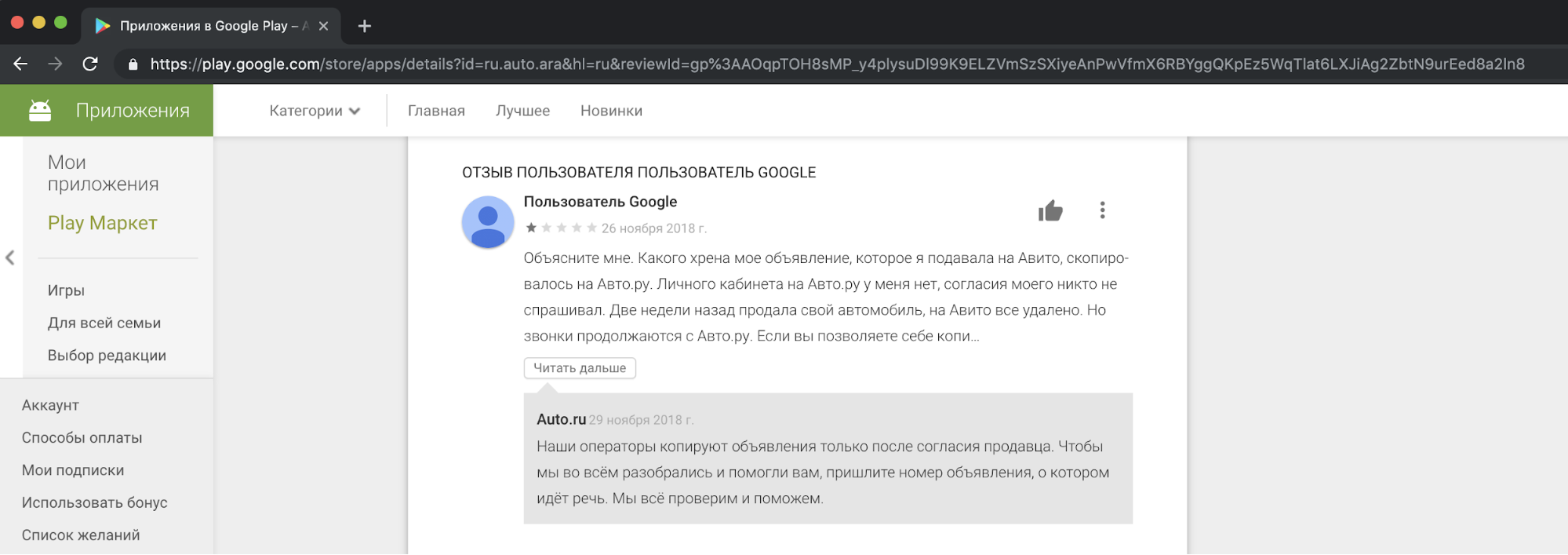
Saya harus mengatakan bahwa permintaan persetujuan orang untuk menyalin iklan tidak membenarkan tindakan tersebut. Ini merupakan pelanggaran terhadap undang-undang "Tentang Iklan" dan "Tentang Data Pribadi", peraturan Avito, hak merek dagang, dan basis data iklan.
Kami tidak bisa setuju secara damai dengan pesaing, tetapi kami tidak ingin meninggalkan situasi apa adanya.
Cara untuk memecahkan masalah
Metode pertama adalah legal. Preseden serupa sudah ada di negara lain. Sebagai contoh, Craigslist classifier Amerika terkenal telah menyita sejumlah besar uang dari situs menyalin konten dari itu.
Cara kedua untuk mengatasi masalah penyalinan adalah dengan menambahkan tanda air besar ke gambar sehingga tidak dapat dipotong.
Metode ketiga adalah teknologi. Kami dapat mempersulit proses menyalin konten kami. Adalah logis untuk berasumsi bahwa beberapa model terlibat dalam menyembunyikan logo Avito dari pesaing. Diketahui juga bahwa banyak model rentan terhadap "serangan" yang mencegahnya bekerja dengan benar. Artikel ini akan membahas tentang mereka saja.
Serangan permusuhan

Idealnya, contoh permusuhan untuk jaringan terlihat seperti noise yang tidak dapat dibedakan oleh mata manusia, tetapi untuk pengklasifikasi itu menambahkan sinyal yang cukup ke kelas yang tidak ada dalam gambar. Akibatnya, gambar, misalnya, dengan panda, diklasifikasikan dengan kepercayaan tinggi sebagai owa. Membuat kebisingan permusuhan dimungkinkan tidak hanya untuk jaringan klasifikasi gambar, tetapi juga untuk segmentasi, deteksi. Contoh yang menarik adalah karya terbaru dari Keen Labs: mereka menipu Tesla autopilot dengan titik-titik di trotoar dan alat pendeteksi hujan dengan hanya menampilkan suara permusuhan . Ada juga serangan untuk domain lain, misalnya, suara: serangan terkenal di Amazon Alexa dan asisten suara lainnya terdiri dari bermain tim yang tidak dapat dibedakan oleh telinga manusia (cracker menawarkan untuk membeli sesuatu di Amazon).
Membuat kebisingan permusuhan untuk model yang menganalisis gambar dimungkinkan karena penggunaan gradien yang tidak standar yang diperlukan untuk melatih model. Biasanya, dalam metode back propagation of errors, menggunakan gradien terhitung dari fungsi tujuan, hanya bobot lapisan jaringan yang diubah sehingga kurang keliru pada dataset pelatihan. Sama seperti untuk lapisan jaringan, Anda dapat menghitung gradien fungsi objektif dari gambar input dan mengubahnya. Mengubah gambar input menggunakan gradien digunakan untuk berbagai algoritma terkenal. Ingat Deepdream ?

Jika kita secara iteratif menghitung gradien fungsi objektif dari gambar input dan menambahkan gradien ini ke dalamnya, informasi lebih lanjut tentang kelas yang berlaku dari ImageNet muncul di gambar: lebih banyak wajah anjing muncul, karena nilai penurunan fungsi berkurang dan model menjadi lebih percaya diri di kelas "anjing". Mengapa anjing dalam contoh ini? Hanya di ImageNet dari 1000 kelas - 120 kelas anjing . Pendekatan yang mirip dengan modifikasi gambar digunakan dalam algoritma Transfer Gaya, yang dikenal terutama karena aplikasi Prisma.
Untuk membuat contoh permusuhan, Anda juga dapat menggunakan metode berulang mengubah gambar input.
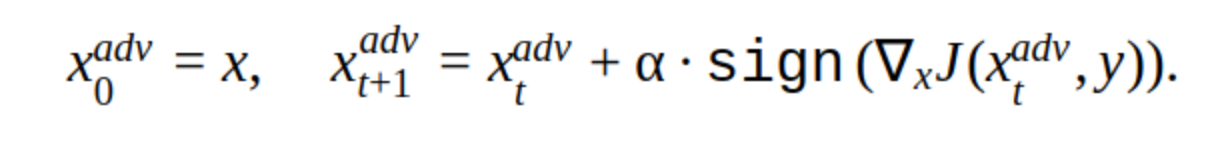
Ada beberapa modifikasi pada metode ini, tetapi ide dasarnya sederhana: gambar asli secara iteratif bergeser ke arah gradien dari hilangnya fungsi classifier J (karena hanya tanda yang digunakan) dengan langkah α. 'y' adalah kelas yang direpresentasikan dalam gambar untuk mengurangi kepercayaan jaringan pada jawaban yang benar. Serangan semacam itu disebut tidak ditargetkan. Anda dapat memilih langkah dan jumlah iterasi optimal sehingga perubahan pada gambar input tidak dapat dibedakan dari yang biasa dilakukan seseorang. Tetapi dari sudut pandang biaya waktu, serangan seperti itu tidak cocok untuk kita. Iterasi 5-10 untuk satu gambar di prod adalah waktu yang lama.
Alternatif untuk metode berulang adalah metode FGSM.

Ini adalah metode tembakan tunggal, mis. Untuk menggunakannya, Anda perlu menghitung gradien fungsi kerugian untuk gambar input sekali, dan kebisingan permusuhan siap ditambahkan ke gambar. Metode ini jelas lebih produktif. Dapat digunakan dalam produksi.
Membuat contoh permusuhan
Kami memutuskan untuk memulai dengan meretas model kami sendiri.
Ini adalah gambar yang mengurangi kemungkinan menemukan plat nomor untuk model kami.

Jelas bahwa metode ini memiliki kelemahan: perubahan yang ditambahkannya pada gambar terlihat oleh mata. Metode ini juga tidak ditargetkan, tetapi dapat diubah untuk membuat serangan yang diarahkan. Kemudian model akan memprediksi tempat untuk plat di tempat lain. Ini adalah metode T-FGSM.
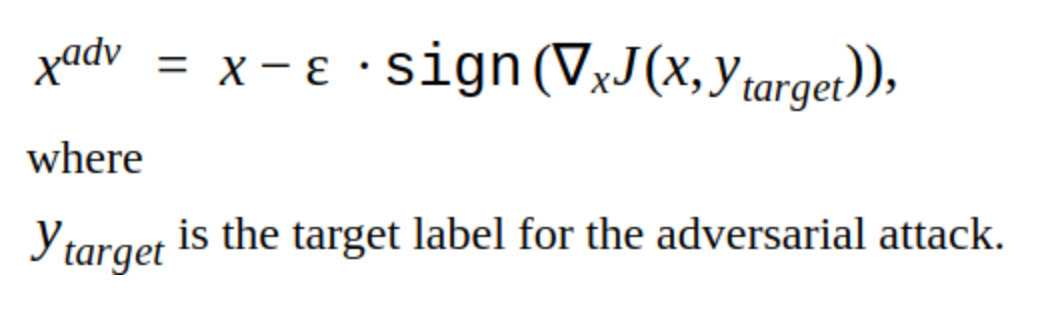
Untuk memecah model kami dengan metode ini, Anda perlu mengubah gambar input sedikit lebih mencolok.

Belum memungkinkan untuk mengatakan bahwa hasilnya ideal, tetapi setidaknya efisiensi metode telah diverifikasi. Kami juga mencoba perpustakaan yang sudah jadi untuk meretas jaringan Foolbox, CleverHans, dan ART-IBM, tetapi dengan bantuan mereka, tidak mungkin memutus jaringan kami untuk dideteksi. Metode yang diberikan lebih baik untuk jaringan klasifikasi. Ini adalah kecenderungan umum dalam peretasan jaringan: lebih sulit untuk membuat serangan lebih sulit untuk deteksi objek, terutama ketika datang ke model yang kompleks, misalnya, Mask RCNN.
Pengujian serangan
Segala sesuatu yang dijelaskan sejauh ini tidak melampaui eksperimen internal kami, tetapi perlu dipikirkan cara menguji serangan pada detektor platform iklan lain.
Ternyata saat melamar salah satu platform, plat nomor terdeteksi secara otomatis, sehingga Anda dapat mengunggah foto berkali-kali dan memeriksa bagaimana algoritme pendeteksian mengatasi contoh permusuhan baru.
Ini bagus! Tapi ...
Tidak ada serangan yang bekerja pada model kami yang berfungsi saat menguji pada platform lain. Mengapa ini terjadi? Ini adalah konsekuensi dari perbedaan dalam model dan seberapa buruk serangan permusuhan digeneralisasikan ke arsitektur jaringan yang berbeda. Karena kerumitan reproduksi serangan, mereka dibagi menjadi dua kelompok: kotak putih dan kotak hitam.

Serangan-serangan yang kami lakukan pada model kami - itu adalah kotak putih. Yang kami butuhkan adalah kotak hitam dengan batasan tambahan pada inferensi: tidak ada API, yang dapat Anda lakukan hanyalah mengunggah foto secara manual dan memeriksa serangan. Jika ada API, maka Anda bisa membuat model pengganti.

Idenya adalah untuk membuat dataset gambar input dan jawaban dari model kotak hitam, di mana Anda dapat melatih beberapa model arsitektur yang berbeda, sehingga dapat mendekati model kotak hitam. Kemudian Anda dapat melakukan serangan kotak putih pada model-model ini dan mereka lebih cenderung bekerja pada kotak hitam. Dalam kasus kami, ini menyiratkan banyak pekerjaan manual, jadi opsi ini tidak cocok untuk kami.
Memecah kebuntuan
Dalam mencari karya yang menarik tentang topik serangan kotak hitam, sebuah artikel ditemukan ShapeShifter: Robust Physical Adversarial Attack on F-R-CNN Object Detector Lebih Cepat
Para penulis artikel melakukan serangan pada deteksi objek dari jaringan mesin self-driving dengan menambahkan gambar-gambar selain kelas sebenarnya ke latar belakang tanda berhenti.


Serangan seperti itu jelas terlihat oleh mata manusia, namun, ia berhasil memutus kerja jaringan pendeteksi objek, yang kami butuhkan. Oleh karena itu, kami memutuskan untuk mengabaikan serangan tembus pandang yang diinginkan demi kapasitas kerja.
Kami ingin memeriksa berapa banyak model pendeteksian yang dilatih ulang, apakah ia menggunakan informasi tentang mobil, atau hanya pelat Avito yang diperlukan?
Untuk melakukan ini, buat gambar berikut:

Kami mengunggahnya sebagai mesin ke platform iklan dengan model kotak hitam. Diterima:

Ini berarti bahwa Anda hanya dapat mengubah pelat Avito, informasi lainnya dalam gambar input tidak diperlukan untuk mendeteksi model kotak hitam.
Setelah beberapa upaya, muncul ide untuk menambah kebisingan permusuhan pelat Avito yang diperoleh dengan metode FGSM, yang merusak model kita sendiri, tetapi dengan koefisien ε yang agak besar. Ternyata seperti ini:

Dengan mobil, tampilannya seperti ini:

Kami mengunggah foto ke platform dengan model kotak hitam. Hasilnya berhasil.

Menerapkan metode ini ke beberapa foto lain, kami menemukan bahwa itu tidak berfungsi sering. Kemudian, setelah beberapa upaya, kami memutuskan untuk fokus pada bagian lain yang paling mencolok dari masalah ini - perbatasan. Diketahui bahwa lapisan konvolusional awal jaringan memiliki aktivasi pada objek sederhana seperti garis, sudut. Dengan "memutus" garis perbatasan, kita dapat mencegah jaringan mendeteksi dengan benar area nomor tersebut. Ini dapat dilakukan, misalnya, dengan menambahkan noise dalam bentuk kotak putih dengan ukuran acak di seluruh batas ruangan.

Dengan mengunggah gambar seperti itu ke platform dengan model kotak hitam, kami mendapat contoh permusuhan yang sukses.

Setelah mencoba pendekatan ini pada satu set gambar lain, kami menemukan bahwa model kotak hitam tidak lagi dapat mendeteksi pelat Avito (set itu dirakit secara manual, ada kurang dari seratus gambar, dan itu, tentu saja, tidak representatif, tetapi butuh banyak waktu untuk membuat lebih banyak). Pengamatan yang menarik: serangan hanya berhasil ketika menggabungkan suara dalam huruf Avito dan kotak putih acak dalam bingkai, menggunakan metode ini secara terpisah tidak memberikan hasil yang sukses.
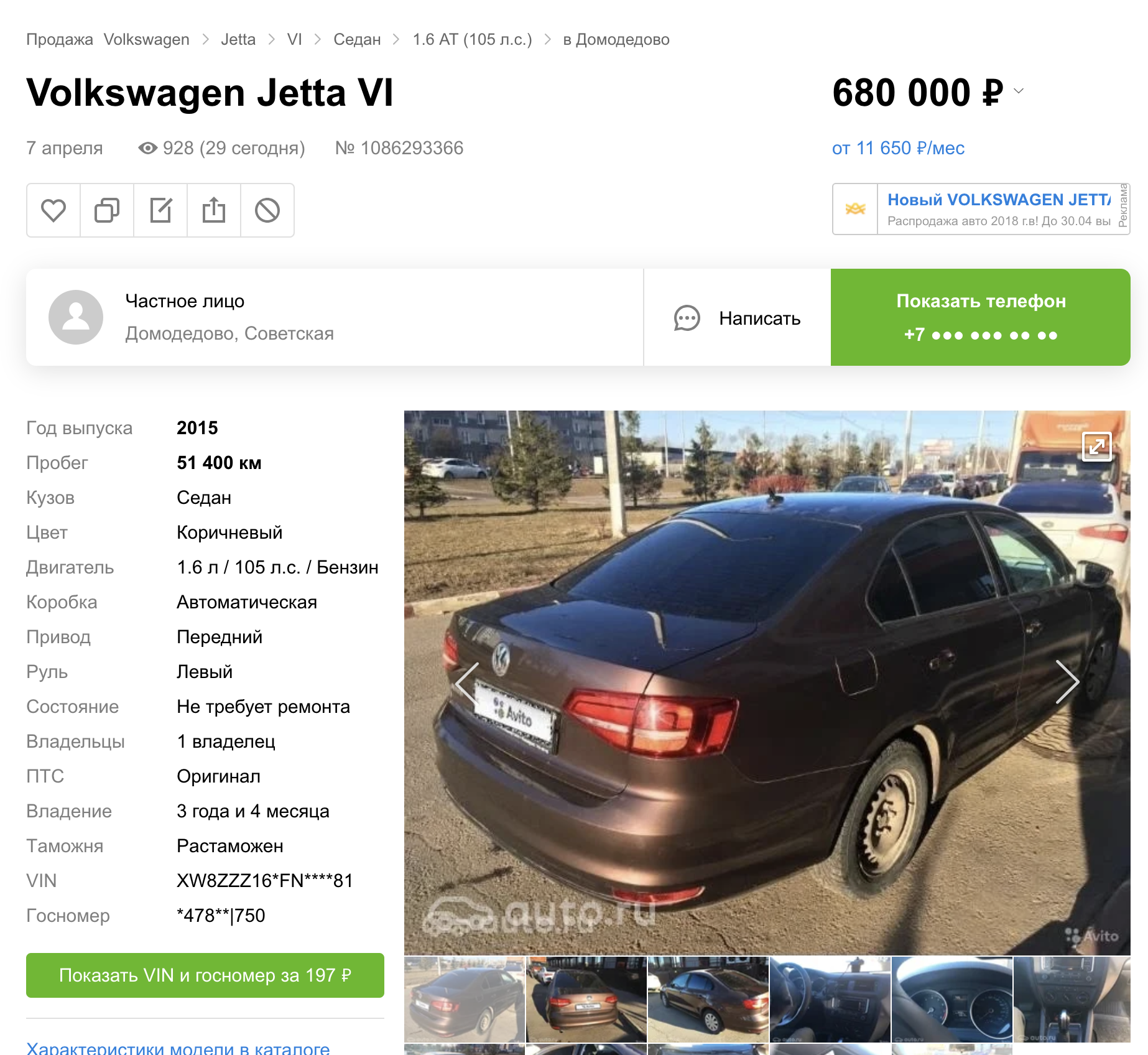
Akibatnya, kami meluncurkan algoritme ini di prod, dan inilah yang keluar darinya :)
Beberapa Iklan Ditemukan


Sesuatu yang lebih segar:
Kami bahkan masuk ke platform iklan:
Total
Akibatnya, kami berhasil melakukan serangan permusuhan, yang dalam penerapannya tidak menambah waktu pemrosesan gambar. Waktu yang kami habiskan untuk menciptakan serangan adalah dua minggu sebelum Tahun Baru. Jika tidak mungkin melakukannya selama waktu ini, maka mereka akan menempatkan tanda air. Sekarang plat nomor permusuhan dinonaktifkan, karena sekarang pesaing memanggil pengguna, menawarkan mereka untuk mengunggah foto ke iklan sendiri atau mengganti foto mobil dengan yang stok dari Internet.