Halo, Habr! Saya hadir untuk Anda terjemahan artikel " Klasifikasi Tutupan Lahan dengan eo- learning : Bagian 1 " oleh Matic Lubej.
Bagian 2
Bagian 3
Kata Pengantar
Sekitar enam bulan yang lalu, komit pertama dibuat ke repositori e- learning di GitHub. Saat ini, eo-learn telah berkembang menjadi perpustakaan open source yang luar biasa, siap digunakan oleh siapa saja yang tertarik dengan data EO (Earth Observation - etc. trans.). Semua orang di tim Sinergise sedang menunggu saat transisi dari tahap membangun alat yang diperlukan ke tahap penggunaannya untuk pembelajaran mesin. Saatnya untuk memperkenalkan Anda serangkaian artikel tentang klasifikasi tutupan lahan menggunakan eo-learn
eo-learn adalah pustaka Python open source yang bertindak sebagai jembatan yang menghubungkan Earth Observation / Remote Sensing dengan ekosistem pustaka pembelajaran mesin Python. Kami sudah menulis posting terpisah di blog kami, yang kami sarankan agar Anda membiasakan diri. Perpustakaan menggunakan primitif dari perpustakaan numpy dan shapely untuk menyimpan dan memanipulasi data dari satelit. Saat ini, tersedia di repositori GitHub , dan dokumentasi tersedia di tautan yang sesuai ke ReadTheDocs .

Citra satelit Sentinel-2 dan topeng NDVI dari area kecil di Slovenia pada musim dingin
Untuk menunjukkan kemampuan eo-learn , kami memutuskan untuk menggunakan conveyor multi-temporal kami untuk mengklasifikasikan sampul wilayah Republik Slovenia (negara tempat kami tinggal), menggunakan data untuk 2017. Karena prosedur yang lengkap mungkin terlalu rumit untuk satu artikel, kami memutuskan untuk membaginya menjadi tiga bagian. Berkat ini, tidak perlu melewati langkah-langkah dan segera melanjutkan ke pembelajaran mesin - pertama kita harus benar-benar memahami data yang kita kerjakan. Setiap artikel akan disertai dengan contoh Notebook Jupyter. Juga, bagi yang berminat, kami telah menyiapkan contoh lengkap yang mencakup semua tahap.
- Pada artikel pertama, kami akan memandu Anda melalui prosedur untuk memilih / membagi area yang diminati (selanjutnya - AOI, area yang diminati), dan mendapatkan informasi yang diperlukan, seperti data dari sensor satelit dan cloud mask. Kami juga menunjukkan contoh cara membuat topeng raster data tentang cakupan nyata suatu wilayah dari data vektor. Semua ini adalah langkah yang diperlukan untuk mendapatkan hasil yang andal.
- Pada bagian kedua, kami terjun langsung ke persiapan data untuk prosedur pembelajaran mesin. Proses ini termasuk mengambil sampel acak untuk pelatihan \ validasi piksel, menghapus gambar cloud, menginterpolasi data sementara untuk mengisi "lubang", dll.
- Pada bagian ketiga kami akan mempertimbangkan pelatihan dan validasi classifier, serta, tentu saja, grafik yang indah!

Citra satelit Sentinel-2 dan topeng NDVI dari area kecil di Slovenia pada musim panas
Bidang minat? Pilih!
Perpustakaan eo-learn memungkinkan Anda untuk membagi AOI menjadi fragmen kecil yang dapat diproses dalam kondisi sumber daya komputasi yang terbatas. Dalam contoh ini, perbatasan Slovenia diambil dari Bumi Alami , namun, Anda dapat memilih zona dengan ukuran apa pun. Kami juga menambahkan buffer ke perbatasan, setelah itu dimensi AOI sekitar 250x170 km. Menggunakan keajaiban geopandas dan perpustakaan yang shapely , kami menciptakan alat untuk memecahkan AOI. Dalam hal ini, kami membagi wilayah menjadi 25x17 kotak dengan ukuran yang sama, sebagai hasilnya kami menerima ~ 300 fragmen 1000x1000 piksel, dalam resolusi 10m. Keputusan tentang pemisahan menjadi fragmen dibuat tergantung pada daya komputasi yang tersedia. Sebagai hasil dari langkah ini, kami mendapatkan daftar kotak yang mencakup AOI.

AOI (wilayah Slovenia) dibagi menjadi kotak-kotak kecil dengan ukuran sekitar 1000x1000 piksel dalam resolusi 10m.
Menerima data dari satelit Sentinel
Setelah menentukan kotak, eo-learn memungkinkan Anda mengunduh data secara otomatis dari satelit Sentinel. Dalam contoh ini, kita mendapatkan semua gambar Sentinel-2 L1C yang diambil pada tahun 2017. Perlu dicatat bahwa produk Sentinel-2 L2A, serta sumber data tambahan (Landsat-8, Sentinel-1) dapat ditambahkan ke pipa dengan cara yang sama. Perlu juga dicatat bahwa penggunaan produk L2A dapat meningkatkan hasil klasifikasi, tetapi kami memutuskan untuk menggunakan L1C untuk universalitas solusi. Ini dilakukan dengan menggunakan sentinelhub-py , perpustakaan yang berfungsi seperti pembungkus pada layanan Sentinel-Hub. Menggunakan layanan ini gratis untuk lembaga penelitian dan pemula, tetapi dalam kasus lain perlu berlangganan.

Gambar warna satu fragmen pada hari yang berbeda. Beberapa gambar mendung, yang berarti diperlukan pendeteksi awan.
Selain data Sentinel, eo-learn s2cloudless memungkinkan Anda untuk mengakses data probabilitas cloud dan cloud secara transparan berkat pustaka s2cloudless . Pustaka ini menyediakan alat untuk mendeteksi awan secara otomatis piksel demi piksel . Detailnya bisa dibaca di sini .
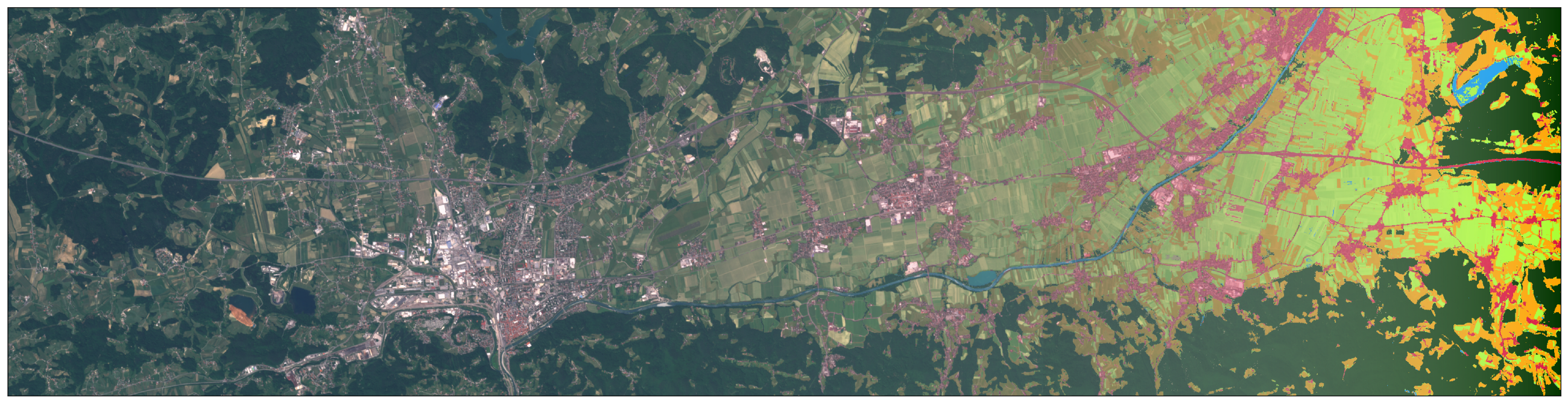
Masker Cloud untuk gambar di atas. Warna menunjukkan probabilitas kekeruhan pada piksel tertentu (probabilitas biru - rendah, kuning - tinggi).
Menambahkan Data Nyata
Mengajar dengan guru membutuhkan kartu dengan data nyata, atau kebenaran . Istilah terakhir tidak boleh diartikan secara harfiah, karena dalam kenyataannya, data hanyalah perkiraan dari apa yang ada di permukaan. Sayangnya, perilaku classifier sangat tergantung pada kualitas kartu ini ( namun, seperti untuk sebagian besar tugas lain dalam pembelajaran mesin ). Peta berlabel paling sering tersedia sebagai data vektor dalam format shapefile (misalnya, disediakan oleh negara atau komunitas ). eo-learn berisi alat untuk meraster data vektor dalam bentuk topeng raster.

Proses rasterisasi data menjadi topeng menggunakan contoh satu kotak. Poligon dalam file vektor ditunjukkan pada gambar kiri, topeng raster untuk setiap label ditunjukkan di tengah - warna hitam dan putih menunjukkan masing-masing ada dan tidak adanya atribut tertentu. Gambar kanan menunjukkan topeng raster gabungan di mana warna yang berbeda menunjukkan label yang berbeda.
Menyatukan semuanya
Semua tugas ini berperilaku seperti blok bangunan yang dapat digabungkan menjadi urutan tindakan yang nyaman dilakukan untuk setiap kotak. Karena jumlah fragmen yang berpotensi sangat besar, otomatisasi pipa sangat diperlukan
Mengenal data aktual adalah langkah pertama dalam bekerja dengan tugas semacam ini. Menggunakan masker cloud yang dipasangkan dengan data dari Sentinel-2, Anda dapat menentukan jumlah pengamatan kualitas semua piksel, serta probabilitas rata-rata awan di area tertentu. Berkat ini, Anda dapat lebih memahami data yang ada, dan menggunakannya saat men-debug masalah lebih lanjut.

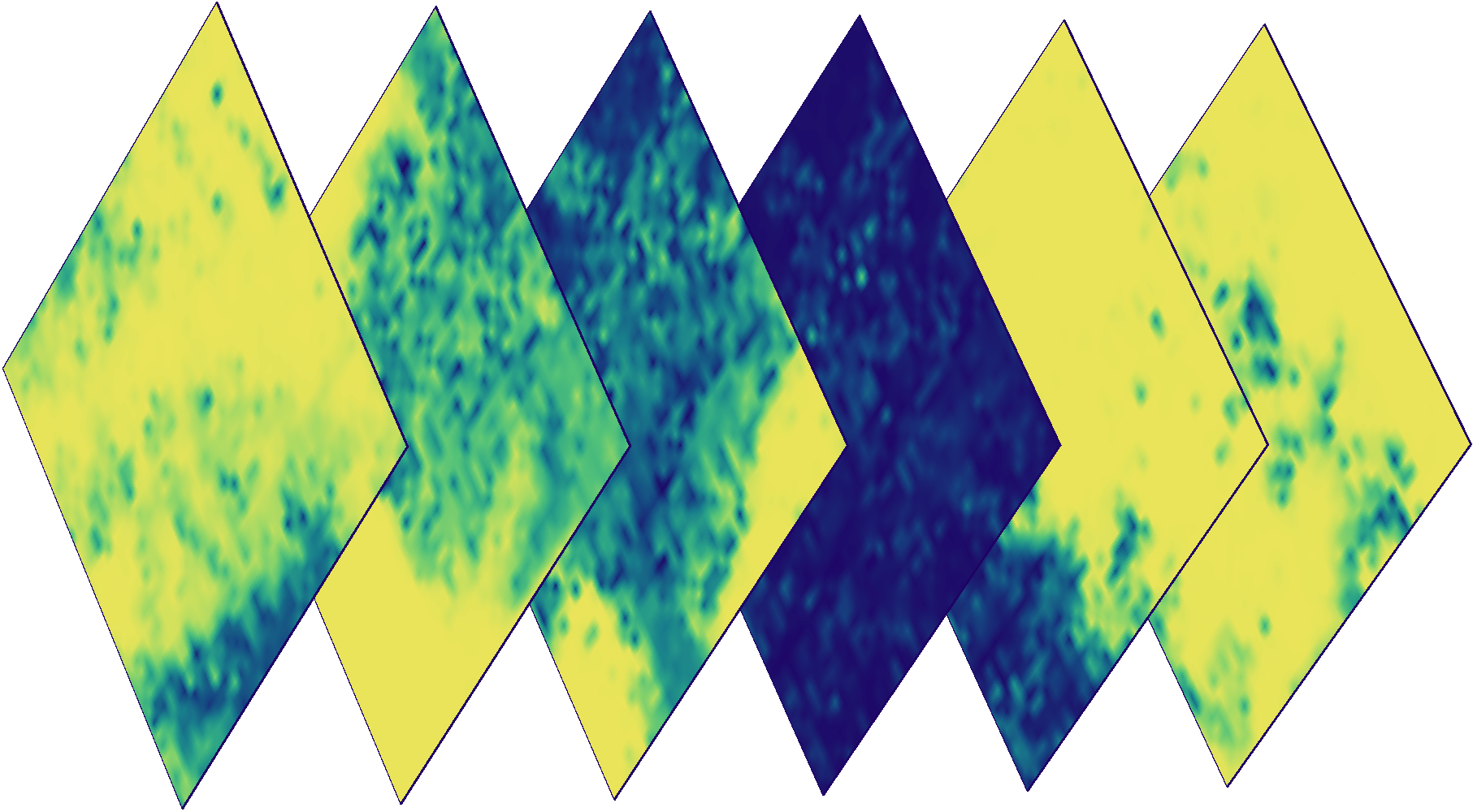
Gambar berwarna (kiri), topeng dari jumlah pengukuran kualitas untuk 2017 (tengah), dan probabilitas awan rata-rata untuk 2017 (kanan) untuk fragmen acak dari AOI.
Seseorang mungkin tertarik pada NDVI rata-rata untuk zona arbitrer, mengabaikan awan. Dengan menggunakan topeng cloud, Anda dapat menghitung nilai rata-rata fitur apa pun, mengabaikan piksel tanpa data. Dengan demikian, berkat masker, kami dapat menghapus gambar dari noise untuk hampir semua fitur dalam data kami.
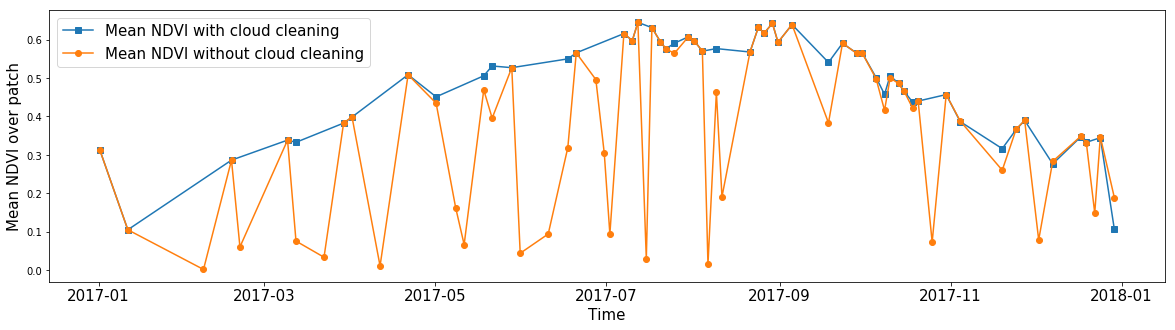
Rata-rata NDVI semua piksel dalam fragmen AOI acak sepanjang tahun. Garis biru menunjukkan hasil perhitungan yang diperoleh jika mengabaikan nilai di dalam awan. Garis oranye menunjukkan nilai rata-rata ketika semua piksel diperhitungkan.
"Tapi bagaimana dengan penskalaan?"
Setelah kami menyiapkan conveyor kami menggunakan contoh satu fragmen, yang masih harus dilakukan adalah memulai prosedur serupa untuk semua fragmen secara otomatis (secara paralel, jika sumber daya memungkinkan), sementara Anda bersantai dengan secangkir kopi dan memikirkan seberapa besar bos akan terkejut dengan senang hati hasil pekerjaan Anda. Setelah akhir pipa, Anda dapat mengekspor data yang Anda minati menjadi satu gambar dalam format GeoTIFF. Script gdal_merge.py menerima gambar dan menggabungkannya, menghasilkan gambar yang mencakup seluruh negara.
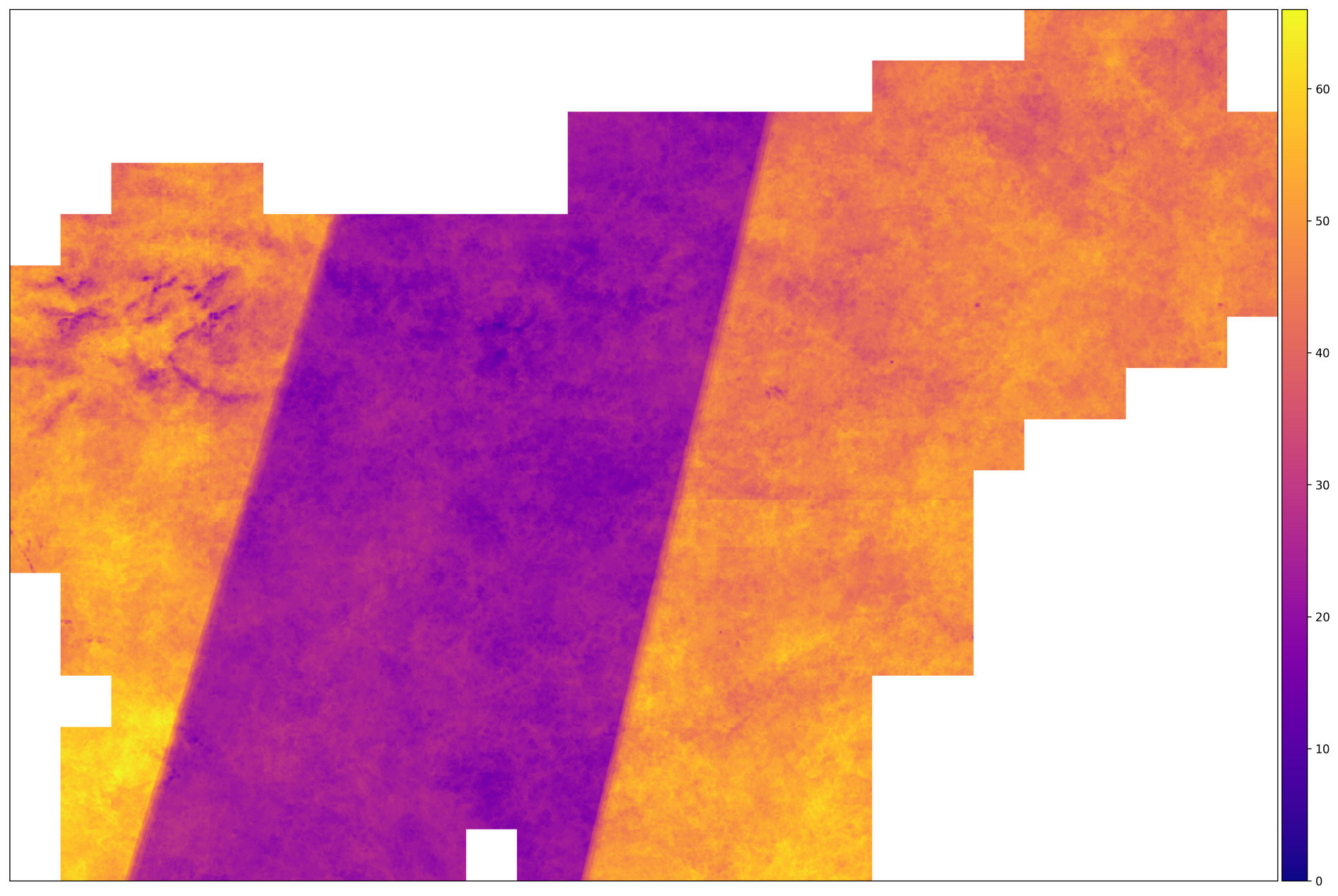
Jumlah pemotretan yang benar untuk AOI pada 2017. Wilayah dengan sejumlah besar gambar terletak di wilayah tempat lintasan satelit Sentinel-2A dan Sentinel-2B berpotongan. Di tengah ini tidak terjadi.
Dari gambar di atas, kita dapat menyimpulkan bahwa data input heterogen - untuk beberapa fragmen, jumlah gambar dua kali lebih tinggi daripada yang lain. Ini berarti bahwa kita perlu mengambil langkah-langkah untuk menormalkan data - seperti interpolasi sepanjang sumbu waktu.
Eksekusi pipa yang ditentukan membutuhkan waktu sekitar 140 detik untuk satu fragmen, yang totalnya memberi ~ 12 jam ketika memulai proses di seluruh AOI. Sebagian besar waktu ini mengunduh data satelit. Fragmen rata-rata terkompresi dengan konfigurasi yang dijelaskan membutuhkan sekitar 3 GB, yang secara total memberikan ~ 1 TB ruang untuk seluruh AOI.
Contoh dalam Notebook Jupyter
Untuk pengantar yang lebih sederhana untuk kode eo-learn , kami telah menyiapkan contoh yang mencakup topik yang dibahas dalam posting ini. Contoh ini dirancang sebagai notepad Jupyter, dan Anda dapat menemukannya di direktori contoh paket eo-learn learning.