Setiap hari, puluhan ribu karyawan dari beberapa ribu organisasi di seluruh dunia bekerja di Pyrus. Kami menganggap responsif layanan (kecepatan permintaan pemrosesan) merupakan keunggulan kompetitif yang penting, karena secara langsung memengaruhi pengalaman pengguna. Metrik utama bagi kami adalah "persentase permintaan lambat". Mempelajari perilakunya, kami perhatikan bahwa sekali semenit pada server aplikasi ada jeda sekitar 1000 ms panjangnya. Pada interval ini, server tidak merespons dan muncul beberapa lusin permintaan. Pencarian untuk penyebab dan penghapusan hambatan yang disebabkan oleh pengumpulan sampah dalam aplikasi akan dibahas dalam artikel ini.

Bahasa pemrograman modern dapat dibagi menjadi dua kelompok. Dalam bahasa seperti C / C ++ atau Rust, manajemen memori manual digunakan, sehingga programmer menghabiskan lebih banyak waktu menulis kode, mengelola masa objek, dan kemudian debugging. Pada saat yang sama, bug karena penggunaan memori yang tidak tepat adalah beberapa yang paling sulit untuk di-debug, sehingga sebagian besar pengembangan modern dilakukan dalam bahasa dengan manajemen memori otomatis. Ini termasuk, misalnya, Java, C #, Python, Ruby, Go, PHP, JavaScript, dll. Programmer menghemat waktu pengembangan, tetapi Anda harus membayar waktu eksekusi tambahan yang dihabiskan program secara teratur pada pengumpulan sampah - membebaskan memori yang ditempati oleh objek yang tidak ada tautan yang tersisa dalam program. Dalam program kecil, waktu ini dapat diabaikan, tetapi karena jumlah objek meningkat dan intensitas pembuatannya, pengumpulan sampah mulai memberikan kontribusi nyata terhadap total waktu pelaksanaan program.
Server web Pyrus berjalan pada platform .NET, yang menggunakan manajemen memori otomatis. Sebagian besar pengumpulan sampah adalah 'hentikan dunia', mis. pada saat pekerjaan mereka, mereka menghentikan semua utas aplikasi. Rakitan non-pemblokiran (latar belakang) sebenarnya juga menghentikan semua utas, tetapi untuk periode yang sangat singkat. Selama pemblokiran utas, server tidak memproses permintaan, permintaan yang ada membeku, yang baru ditambahkan ke antrian. Akibatnya, permintaan yang diproses pada saat pengumpulan sampah langsung melambat, dan permintaan diproses lebih lambat segera setelah pengumpulan sampah selesai karena akumulasi antrian. Ini memperparah metrik "persentase kueri lambat."
Berbekal buku yang baru-baru ini diterbitkan
Konrad Kokosa: Pro .NET Memory Management (tentang bagaimana kami membawa salinan pertamanya ke Rusia dalam 2 hari, Anda dapat menulis posting terpisah), sepenuhnya dikhususkan untuk topik manajemen memori di .NET, kami mulai mempelajari masalahnya.
Pengukuran
Untuk profil server web Pyrus, kami menggunakan utilitas PerfView (
https://github.com/Microsoft/perfview ), dipertajam untuk profil aplikasi NET. Utilitas ini didasarkan pada mesin Event Tracing for Windows (ETW) dan memiliki dampak minimal pada kinerja aplikasi yang diprofilkan, yang memungkinkannya digunakan pada server tempur. Selain itu, dampak pada kinerja tergantung pada jenis acara apa dan informasi apa yang kami kumpulkan. Kami tidak mengumpulkan apa pun - aplikasi berfungsi seperti biasa. Selain itu, PerfView tidak memerlukan kompilasi ulang atau memulai ulang aplikasi.
Jalankan jejak PerfView dengan parameter / GCCollectOnly (lacak waktu 1,5 jam). Dalam mode ini, ia hanya mengumpulkan acara pengumpulan sampah dan memiliki dampak minimal pada kinerja. Mari kita lihat laporan jejak Memory Group / GCStats, dan di dalamnya ada ringkasan peristiwa pengumpul sampah:
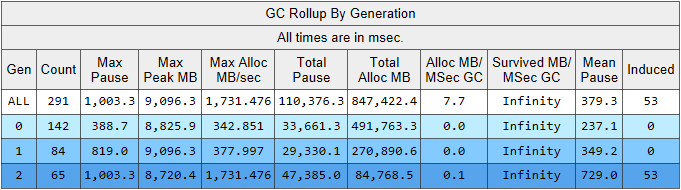
Di sini kita melihat beberapa indikator menarik sekaligus:
- Waktu jeda build rata-rata pada generasi ke-2 adalah 700 milidetik, dan jeda maksimum adalah sekitar satu detik. Gambar ini menunjukkan waktu di mana semua utas dalam aplikasi .NET berhenti, khususnya, jeda ini akan ditambahkan ke semua permintaan yang diproses.
- Jumlah majelis dari generasi ke-2 sebanding dengan generasi ke-1 dan sedikit lebih sedikit dari jumlah majelis dari generasi ke-0.
- Kolom yang diinduksi mencantumkan 53 majelis di generasi ke-2. Perakitan terinduksi adalah hasil dari panggilan eksplisit ke GC.Collect (). Dalam kode kami, kami tidak menemukan satu panggilan pun ke metode ini, yang berarti bahwa beberapa perpustakaan yang digunakan oleh aplikasi kami yang harus disalahkan.
Mari kita jelaskan pengamatan tentang jumlah pengumpulan sampah. Gagasan untuk membagi objek berdasarkan umurnya didasarkan pada
hipotesis generasi : sebagian besar objek yang dibuat mati dengan cepat, dan sebagian besar sisanya berumur panjang (dengan kata lain, beberapa objek yang memiliki masa hidup "rata-rata"). Dalam mode ini pengumpul sampah .NET dipenjara, dan dalam mode ini majelis generasi kedua harus jauh lebih kecil daripada generasi ke-0. Yaitu, untuk operasi optimal pengumpul sampah, kita harus menyesuaikan pekerjaan aplikasi kita dengan hipotesis generasi. Mari kita merumuskan aturan sebagai berikut: objek harus mati dengan cepat, tanpa selamat ke generasi yang lebih tua, atau hidup untuk itu dan hidup di sana selamanya. Aturan ini juga berlaku untuk platform lain yang menggunakan manajemen memori otomatis dengan pemisahan generasi, seperti Java.
Data yang menarik bagi kami dapat diekstraksi dari tabel lain dalam laporan GCStats:

Berikut adalah beberapa kasus di mana aplikasi mencoba membuat objek besar (dalam .NET Framework objek dengan ukuran> 85.000 byte dibuat di LOH - Large Object Heap), dan harus menunggu penyelesaian perakitan generasi ke-2, yang terjadi secara paralel di latar belakang. Jeda pengalokasi ini tidak sepenting jeda pengumpul sampah, karena hanya memengaruhi satu utas. Sebelum itu, kami menggunakan .NET Framework versi 4.6.1, dan dalam versi 4.7.1 Microsoft menyelesaikan pengumpul sampah, sekarang ini memungkinkan Anda untuk mengalokasikan memori di Tumpukan Objek Besar selama generasi latar belakang generasi ke-2:
https://docs.microsoft.com / ru-ru / dotnet / framework / whats-new / # common-language-runtime-clrKarena itu, kami meningkatkan ke versi terbaru 4.7.2 pada saat itu.
Build Generasi ke-2
Mengapa kita memiliki banyak bangunan generasi yang lebih tua? Asumsi pertama adalah bahwa kita memiliki kebocoran memori. Untuk menguji hipotesis ini, mari kita lihat ukuran generasi kedua (kami menyiapkan pemantauan penghitung kinerja yang sesuai di Zabbix). Dari grafik ukuran generasi ke-2 untuk 2 server Pyrus, dapat dilihat bahwa ukurannya pertama kali tumbuh (terutama karena pengisian cache), tetapi kemudian stabil (kegagalan besar pada grafik - restart rutin layanan web untuk memperbarui versi):
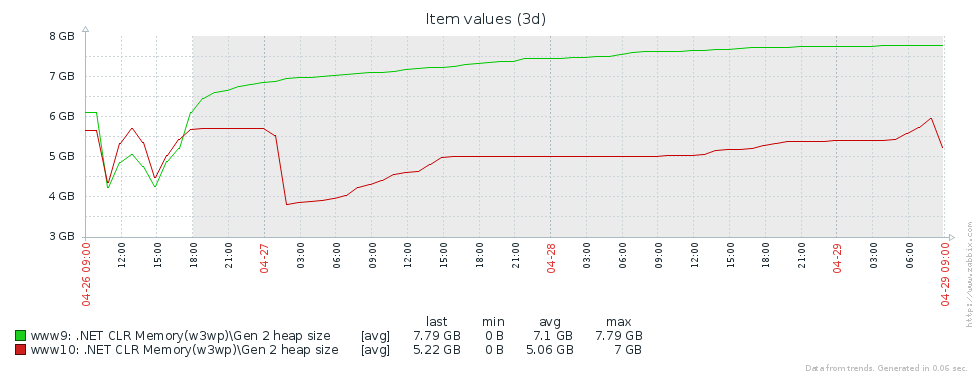
Ini berarti bahwa tidak ada kebocoran memori yang nyata, yaitu, sejumlah besar rakitan generasi ke-2 terjadi karena alasan lain. Hipotesis berikutnya adalah bahwa ada banyak lalu lintas memori, yaitu, banyak objek jatuh ke generasi ke-2, dan banyak objek mati di sana. PerfView memiliki mode / GCOnly untuk menemukan objek tersebut. Dari laporan jejak, mari kita perhatikan 'Gen 2 Object Deaths (Coarse Sampling) Stacks', yang berisi pilihan objek yang mati pada generasi ke-2, bersama dengan tumpukan panggilan dari tempat-tempat di mana objek-objek ini dibuat. Di sini kita melihat hasil berikut:
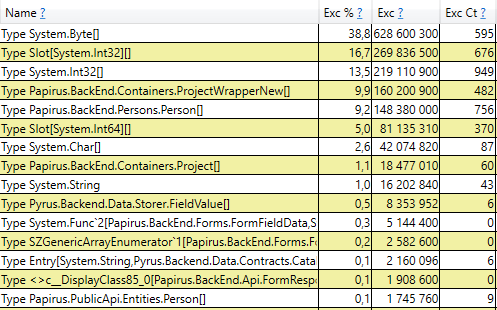
Setelah membuka baris, di dalam kita melihat tumpukan panggilan tempat-tempat dalam kode yang membuat objek yang hidup hingga generasi ke-2. Diantaranya adalah:
- System.Byte [] Jika Anda melihat ke dalam, kita akan melihat bahwa lebih dari setengahnya adalah buffer untuk serialisasi di JSON:
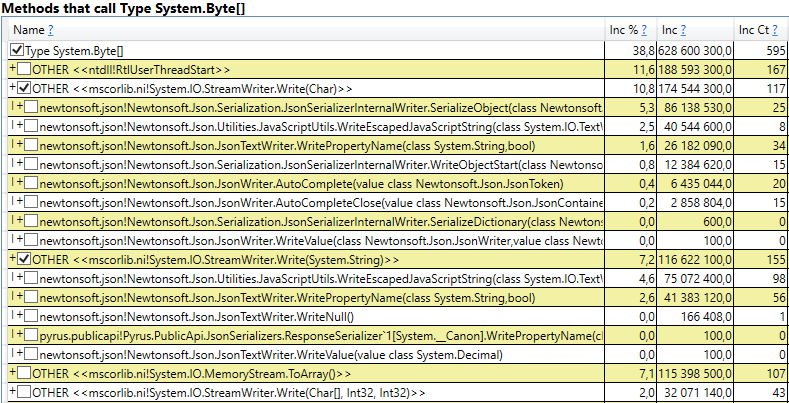
- Slot [System.Int32] [] (ini adalah bagian dari implementasi HashSet), System.Int32 [], dll. Ini adalah kode kami yang menghitung cache klien - direktori, formulir, daftar, teman, dll yang dilihat pengguna ini dan yang di-cache di browser atau aplikasi selulernya:

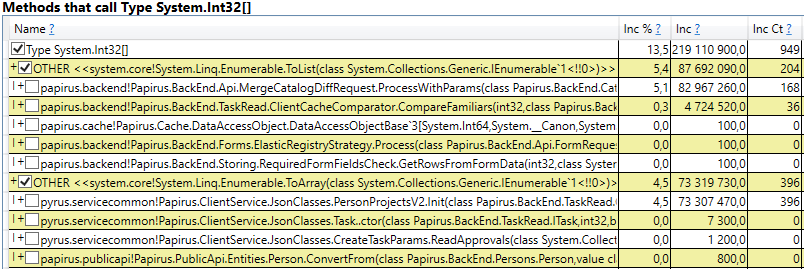
Menariknya, buffer untuk JSON dan untuk menghitung cache klien adalah semua objek sementara yang hidup berdasarkan permintaan yang sama. Mengapa mereka hidup sampai generasi ke-2? Perhatikan bahwa semua objek ini adalah array dengan ukuran yang agak besar. Dan pada ukuran> 85000 byte, memori untuk mereka dialokasikan di Large Object Heap, yang hanya dikumpulkan bersama dengan generasi ke-2.
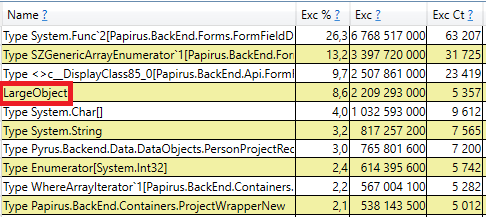
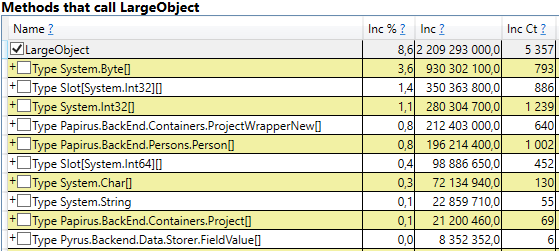
Untuk memeriksa, buka bagian 'GC Heap Alloc Ignore Free (Coarse Sampling) tumpukan' di perfview / hasil GCOnly. Di sana kita melihat garis LargeObject, di mana PerfView mengelompokkan pembuatan objek besar, dan di dalamnya kita melihat semua array yang sama yang kita lihat dalam analisis sebelumnya. Kami mengakui penyebab utama masalah dengan pengumpul sampah: kami membuat banyak objek besar sementara.
Perubahan dalam sistem Pyrus
Berdasarkan hasil pengukuran, kami mengidentifikasi bidang utama pekerjaan lebih lanjut: perjuangan melawan objek besar saat menghitung cache klien dan serialisasi di JSON. Ada beberapa solusi untuk masalah ini:
- Hal paling sederhana adalah tidak membuat objek besar. Misalnya, jika buffer B besar digunakan dalam transformasi data sekuensial A-> B-> C, maka kadang-kadang transformasi ini dapat digabungkan dengan mengubahnya menjadi A-> C, dan menyingkirkan membuat objek B. Opsi ini tidak selalu berlaku, tetapi yang paling sederhana dan paling efektif.
- Kolam objek. Daripada terus-menerus membuat objek baru dan membuangnya, memuat pengumpul sampah, kita dapat menyimpan koleksi objek gratis. Dalam kasus paling sederhana, ketika kita membutuhkan objek baru, kita mengambilnya dari kolam, atau membuat yang baru jika kolam itu kosong. Ketika kita tidak lagi membutuhkan objek, kita mengembalikannya ke kolam. Contoh yang baik adalah ArrayPool dalam .NET Core, yang juga tersedia dalam .NET Framework sebagai bagian dari paket System.Buffers Nuget.
- Gunakan benda kecil, bukan yang besar.
Mari kita pertimbangkan secara terpisah kedua kasus objek besar - komputasi cache klien dan serialisasi di JSON.
Perhitungan Cache Klien
Klien web dan aplikasi seluler Pyrus melakukan cache data yang tersedia bagi pengguna (proyek, formulir, pengguna, dll.) Caching digunakan untuk mempercepat pekerjaan, juga diperlukan untuk bekerja dalam mode offline. Tembolok dihitung pada server dan ditransfer ke klien. Mereka bersifat individual untuk setiap pengguna, karena mereka bergantung pada hak akses mereka, dan sering diperbarui, misalnya, ketika mengubah direktori yang ia akses.
Dengan demikian, banyak perhitungan cache klien secara teratur dilakukan di server, dan banyak objek sementara berumur pendek dibuat. Jika pengguna adalah organisasi besar, maka ia bisa mendapatkan akses ke banyak objek, masing-masing, cache klien untuknya akan besar. Itulah sebabnya kami melihat alokasi memori untuk array sementara besar di Tumpukan Objek Besar.
Mari kita menganalisis opsi yang diusulkan untuk menghilangkan penciptaan objek besar:
- Pembuangan lengkap benda besar. Pendekatan ini tidak berlaku, karena algoritma persiapan data menggunakan, antara lain, penyortiran dan penyatuan set, dan mereka membutuhkan buffer sementara.
- Menggunakan kumpulan benda. Pendekatan ini mengalami kesulitan:
- Variasi koleksi yang digunakan dan jenis elemen di dalamnya: HashSet, List dan Array digunakan (2 yang terakhir dapat dikombinasikan). Int32, Int64, serta semua jenis kelas data disimpan dalam koleksi. Untuk setiap jenis yang digunakan, Anda akan membutuhkan kolam Anda sendiri, yang juga akan menyimpan koleksi ukuran yang berbeda.
- Koleksi waktu hidup yang sulit. Untuk mendapatkan manfaat dari kolam, benda di dalamnya harus dikembalikan setelah digunakan. Ini dapat dilakukan jika objek digunakan dalam satu metode. Tetapi dalam kasus kami situasinya lebih rumit, karena banyak objek besar bergerak di antara metode, dimasukkan ke dalam struktur data, dipindahkan ke struktur lain, dll.
- Implementasi. Ada ArrayPool dari Microsoft, tetapi kami masih membutuhkan List dan HashSet. Kami tidak menemukan perpustakaan yang cocok, jadi kami harus mengimplementasikan kelas sendiri.
- Gunakan benda kecil. Array besar dapat dibagi menjadi beberapa bagian kecil, yang saya tidak akan memuat Heap Obyek Besar, tetapi akan dibuat pada generasi 0, dan kemudian pergi di sepanjang jalur standar di 1 dan 2. Kami berharap bahwa mereka tidak akan hidup sampai ke-2, tetapi akan dikumpulkan oleh pemulung di tanggal 0, atau dalam kasus-kasus ekstrem di generasi 1. Keuntungan dari pendekatan ini adalah bahwa perubahan kode yang ada minimal. Kesulitan:
- Implementasi. Kami tidak menemukan perpustakaan yang cocok, jadi kami harus menulis sendiri kelasnya. Kurangnya perpustakaan dapat dipahami, karena skenario "koleksi yang tidak memuat Tumpukan Objek Besar" adalah ruang lingkup yang sangat sempit.
Kami memutuskan untuk pergi di jalan ke-3 dan
menciptakan sepeda kami untuk menulis Daftar dan HashSet, tidak memuat Heap Objek Besar.
Daftar bagian
ChunkedList <T> kami mengimplementasikan antarmuka standar, termasuk IList <T>, yang memerlukan perubahan minimal pada kode yang ada. Ya, dan pustaka Newtonsoft.Json yang kami gunakan secara otomatis dapat membuat cerita bersambung, karena mengimplementasikan IEnumerable <T>:
public sealed class ChunkedList<T> : IList<T>, ICollection<T>, IEnumerable<T>, IEnumerable, IList, ICollection, IReadOnlyList<T>, IReadOnlyCollection<T> {
Daftar standar <T> memiliki bidang-bidang berikut: array untuk elemen dan jumlah elemen yang diisi. Di ChunkedList <T> ada array array elemen, jumlah array yang terisi penuh, jumlah elemen dalam array terakhir. Masing-masing array elemen dengan kurang dari 85.000 byte:

private T[][] chunks; private int currentChunk; private int currentChunkSize;
Karena ChunkedList <T> agak rumit, kami menulis tes terperinci. Setiap operasi harus diuji dalam setidaknya 2 mode: dalam "kecil" ketika seluruh daftar cocok dalam satu potong hingga 85.000 byte dalam ukuran, dan "besar" ketika terdiri dari lebih dari satu bagian. Selain itu, untuk metode yang mengubah ukuran (misalnya, Tambah), skenarionya bahkan lebih besar: "kecil" -> "kecil", "kecil" -> "besar", "besar" -> "besar", "besar" -> " kecil. " Di sini ada beberapa kasus batas yang membingungkan yang dilakukan dengan baik oleh unit test.
Situasi ini disederhanakan oleh fakta bahwa beberapa metode dari antarmuka IList tidak digunakan, dan mereka dapat dihilangkan (seperti Sisipkan, Hapus). Implementasi dan pengujian mereka akan sangat mahal. Selain itu, tes unit penulisan disederhanakan oleh fakta bahwa kita tidak perlu membuat fungsionalitas baru, ChunkedList <T> harus berperilaku sama dengan List <T>. Artinya, semua tes disusun sebagai berikut: buat Daftar <T> dan ChunkedList <T>, jalankan operasi yang sama dengannya dan bandingkan hasilnya.
Kami mengukur kinerja menggunakan perpustakaan BenchmarkDotNet untuk memastikan bahwa kami tidak memperlambat banyak kode kami ketika beralih dari Daftar <T> ke ChunkedList <T>. Mari kita coba, misalnya, menambahkan item ke daftar:
[Benchmark] public ChunkedList<int> ChunkedList() { var list = new ChunkedList<int>(); for (int i = 0; i < N; i++) list.Add(i); return list; }
Dan tes yang sama menggunakan Daftar <T> untuk perbandingan. Hasil saat menambahkan 500 elemen (semuanya cocok dalam satu array):
Hasil saat menambahkan 50.000 elemen (dibagi menjadi beberapa array):
Penjelasan rinci tentang kolom dalam hasil BenchmarkDotNet=v0.11.4, OS=Windows 10.0.17763.379 (1809/October2018Update/Redstone5) Intel Core i7-8700K CPU 3.70GHz (Coffee Lake), 1 CPU, 12 logical and 6 physical cores [Host] : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0 DefaultJob : .NET Framework 4.7.2 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.3324.0
Jika Anda melihat kolom 'Mean', yang menampilkan waktu pelaksanaan pengujian rata-rata, Anda dapat melihat bahwa implementasi kami hanya 2-2,5 kali lebih lambat dari standar. Mempertimbangkan bahwa dalam kode sebenarnya, operasi dengan daftar hanya sebagian kecil dari semua tindakan yang dilakukan, perbedaan ini menjadi tidak signifikan. Tetapi kolom 'Gen 2 / 1k op' (jumlah rakitan generasi ke-2 per 1000 uji coba) menunjukkan bahwa kami telah mencapai tujuannya: dengan sejumlah besar elemen, ChunkedList tidak membuat sampah di generasi ke-2, yang merupakan tugas kami.
Sepotong set
Demikian pula, ChunkedHashSet <T> mengimplementasikan antarmuka ISet <T>. Saat menulis ChunkedHashSet <T>, kami menggunakan kembali logika chunked kecil yang sudah diterapkan di ChunkedList. Untuk melakukan ini, kami mengambil implementasi yang sudah jadi dari HashSet <T> dari .NET Reference Source, tersedia di bawah lisensi MIT, dan mengganti array dengan ChunkedLists di dalamnya.
Dalam pengujian unit, kami juga menggunakan trik yang sama dengan daftar: kami akan membandingkan perilaku ChunkedHashSet <T> dengan referensi HashSet <T>.
Akhirnya, tes kinerja. Operasi utama yang kami gunakan adalah gabungan set, itulah sebabnya kami mengujinya:
public ChunkedHashSet<int> ChunkedHashSet(int[][] source) { var set = new ChunkedHashSet<int>(); foreach (var arr in source) set.UnionWith(arr); return set; }
Dan tes yang sama persis untuk HashSet standar. Tes pertama untuk set kecil:
var source = new int[][] { Enumerable.Range(0, 300).ToArray(), Enumerable.Range(100, 600).ToArray(), Enumerable.Range(300, 1000).ToArray(), }
Tes kedua untuk set besar yang menyebabkan masalah dengan banyak objek besar:
var source = new int[][] { Enumerable.Range(0, 30000).ToArray(), Enumerable.Range(10000, 60000).ToArray(), Enumerable.Range(30000, 100000).ToArray(), }
Hasilnya mirip dengan daftar. ChunkedHashSet lebih lambat 2-2,5 kali, tetapi pada saat yang sama pada set besar itu memuat 2 generasi ke 2 pesanan kurang besar.
Serialisasi di JSON
Server web Pyrus menyediakan beberapa API yang menggunakan serialisasi berbeda. Kami menemukan pembuatan objek besar di API yang digunakan oleh bot dan utilitas sinkronisasi (selanjutnya disebut sebagai API Publik). Perhatikan bahwa pada dasarnya API menggunakan serialisasi sendiri, yang tidak terpengaruh oleh masalah ini. Kami menulis tentang ini di artikel
https://habr.com/en/post/227595/ , di bagian "2. Anda tidak tahu di mana hambatan aplikasi Anda. " Artinya, API utama sudah berfungsi dengan baik, dan masalah muncul di API Publik saat jumlah permintaan dan jumlah data dalam tanggapan bertambah.
Mari mengoptimalkan API Publik. Menggunakan contoh API utama, kami tahu bahwa Anda dapat mengembalikan respons kepada pengguna dalam mode streaming. Artinya, Anda tidak perlu membuat buffer perantara yang berisi seluruh respons, tetapi tulis respons segera ke stream.
Setelah diperiksa lebih dekat, kami menemukan bahwa dalam proses serialisasi respons, kami membuat buffer sementara untuk hasil antara ('konten' adalah array byte yang berisi JSON dalam pengkodean UTF-8):
var serializer = Newtonsoft.Json.JsonSerializer.Create(...); byte[] content; var sw = new StreamWriter(new MemoryStream(), new UTF8Encoding(false)); using (var writer = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(writer, result); writer.Flush(); content = ms.ToArray(); }
Mari kita lihat di mana konten digunakan. Untuk alasan historis, API Publik didasarkan pada WCF, yang XML adalah format permintaan dan respons standar. Dalam kasus kami, respons XML memiliki elemen 'Biner' tunggal, yang di dalamnya JSON dikodekan dalam Base64 ditulis:
public class RawBodyWriter : BodyWriter { private readonly byte[] _content; public RawBodyWriter(byte[] content) : base(true) { _content = content; } protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { writer.WriteStartElement("Binary"); writer.WriteBase64(_content, 0, _content.Length); writer.WriteEndElement(); } }
Perhatikan bahwa penyangga sementara tidak diperlukan di sini. JSON dapat ditulis langsung ke buffer XmlWriter yang disediakan WCF kepada kami, dengan menyandikannya di Base64 dengan cepat. Jadi, kita akan pergi dengan cara pertama, menyingkirkan alokasi memori:
protected override void OnWriteBodyContents(XmlDictionaryWriter writer) { var serializer = Newtonsoft.Json.JsonSerializer.Create(...); writer.WriteStartElement("Binary"); Stream stream = new Base64Writer(writer); Var sw = new StreamWriter(stream, new UTF8Encoding(false)); using (var jsonWriter = new Newtonsoft.Json.JsonTextWriter(sw)) { serializer.Serialize(jsonWriter, _result); jsonWriter.Flush(); } writer.WriteEndElement(); }
Di sini Base64Writer adalah pembungkus sederhana di atas XmlWriter yang mengimplementasikan antarmuka Stream, yang menulis ke XmlWriter sebagai Base64. Pada saat yang sama, dari seluruh antarmuka, cukup untuk mengimplementasikan hanya satu metode Write, yang disebut dalam StreamWriter:
public class Base64Writer : Stream { private readonly XmlWriter _writer; public Base64Writer(XmlWriter writer) { _writer = writer; } public override void Write(byte[] buffer, int offset, int count) { _writer.WriteBase64(buffer, offset, count); } <...> }
Diinduksi gc
Mari kita coba berurusan dengan pengumpulan sampah misterius yang diinduksi. Kami memeriksa ulang kode kami 10 kali untuk panggilan GC.Collect, tetapi ini gagal. Saya berhasil menangkap peristiwa ini di PerfView, tetapi tumpukan panggilan tidak terlalu indikatif (acara DotNETRuntime / GC / Triggered):
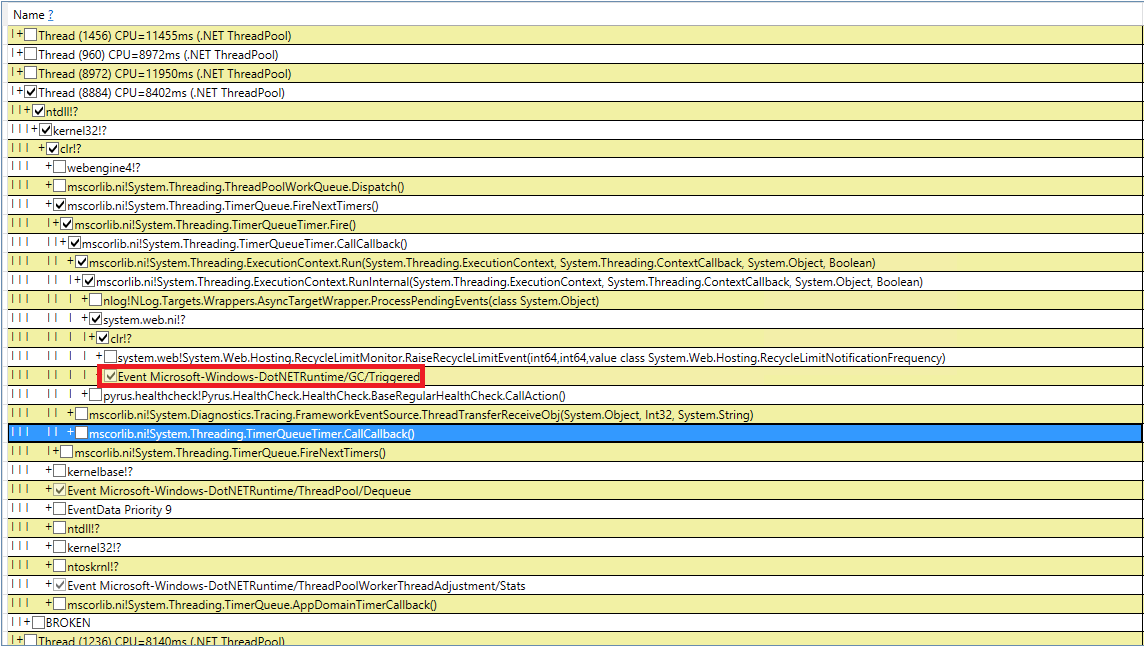
Ada petunjuk kecil - memanggil RecycleLimitMonitor.RaiseRecycleLimitEvent sebelum pengumpulan sampah yang diinduksi. Mari kita telusuri tumpukan panggilan ke metode RaiseRecycleLimitEvent:
RecycleLimitMonitor.RaiseRecycleLimitEvent(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.AlertProxyMonitors(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.CollectInfrequently(...) RecycleLimitMonitor.RecycleLimitMonitorSingleton.PBytesMonitorThread(...)
Nama-nama metode ini konsisten dengan fungsinya:
- Dalam konstruktor dari RecycleLimitMonitor.RecycleLimitMonitorSingleton, timer dibuat yang memanggil PBytesMonitorThread pada interval tertentu.
- PBytesMonitorThread mengumpulkan statistik tentang penggunaan memori dan, dalam beberapa kondisi, panggilan CollectInfrequently.
- CollectInfrequently memanggil AlertProxyMonitors, mendapat bool sebagai hasilnya, dan panggilan GC.Collect () jika itu benar. Dia juga memantau waktu yang berlalu sejak panggilan terakhir ke pemulung, dan tidak terlalu sering memanggilnya.
- AlertProxyMonitors menelusuri daftar menjalankan aplikasi web IIS, untuk masing-masing memunculkan objek RecycleLimitMonitor yang sesuai, dan memanggil RaiseRecycleLimitEvent.
- RaiseRecycleLimitEvent memunculkan daftar IObserver <RecycleLimitInfo>. Penangan menerima sebagai parameter RecycleLimitInfo, di mana mereka dapat mengatur flag RequestGC, yang kembali ke CollectInfrequently, menyebabkan pengumpulan sampah yang diinduksi.
Investigasi lebih lanjut mengungkapkan bahwa penangan IObserver <RecycleLimitInfo> ditambahkan dalam metode RecycleLimitMonitor.Subscribe (), yang disebut dalam metode AspNetMemoryMonitor.Subscribe (). Juga, penangan IObserver <RecycleLimitInfo> default (kelas RecycleLimitObserver) digantung di kelas AspNetMemoryMonitor, yang membersihkan cache ASP.NET dan kadang-kadang meminta pengumpulan sampah.
Teka-teki dari GC yang Diinduksi hampir terpecahkan. Masih mencari tahu mengapa pengumpulan sampah ini disebut. RecycleLimitMonitor memonitor penggunaan memori IIS (lebih tepatnya, jumlah byte pribadi), dan ketika penggunaannya mendekati batas tertentu, itu dimulai dengan algoritma yang agak membingungkan untuk meningkatkan event RaiseRecycleLimitEvent. Nilai AspNetMemoryMonitor.ProcessPrivateBytesLimit digunakan sebagai batas memori, dan pada gilirannya itu berisi logika berikut:
- Jika Application Pool di IIS diatur ke 'Private Memory Limit (KB)', maka nilai dalam kilobyte diambil dari sana
- Kalau tidak, untuk sistem 64-bit, 60% dari memori fisik diambil (untuk sistem 32-bit, logika lebih rumit).
Kesimpulan dari investigasi adalah ini: ASP.NET mendekati batas ingatannya dan mulai secara teratur memanggil pengumpulan sampah. 'Private Memory Limit (KB)' tidak disetel, sehingga ASP.NET dibatasi hingga 60% dari memori fisik. Masalahnya ditutupi oleh fakta bahwa pada server Task Manager itu menunjukkan banyak memori bebas dan sepertinya itu hilang. Kami telah meningkatkan nilai 'Batas Memori Pribadi (KB)' di pengaturan Application Pool di IIS hingga 80% dari memori fisik. Ini mendorong ASP.NET untuk menggunakan lebih banyak memori yang tersedia. Kami juga menambahkan pemantauan penghitung kinerja '.NET CLR Memory / # Induced GC' agar tidak ketinggalan saat berikutnya ASP.NET memutuskan bahwa ia mendekati batas penggunaan memori.
Pengukuran berulang
Mari kita lihat apa yang terjadi dengan pengumpulan sampah setelah semua perubahan ini. Mari kita mulai dengan perfview / GCCollectOnly (lacak waktu - 1 jam), laporan GCStats:
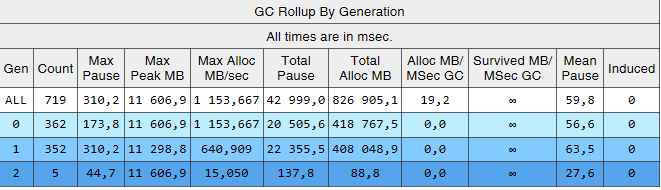
Dapat dilihat bahwa majelis dari generasi ke-2 sekarang 2 urutan besarnya lebih kecil dari ke-0 dan ke-1. Juga, waktu majelis ini menurun. Majelis yang diinduksi tidak lagi diamati. Mari kita lihat daftar majelis dari generasi ke-2:
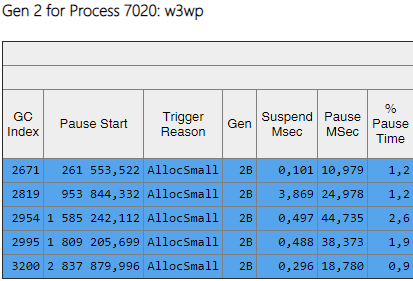
Kolom Gen menunjukkan bahwa semua majelis dari generasi ke-2 telah menjadi latar belakang ('2B' berarti generasi ke-2, Latar Belakang). Artinya, sebagian besar pekerjaan dilakukan secara paralel dengan eksekusi aplikasi, dan semua utas diblokir untuk waktu yang singkat (kolom 'Jeda MSec'). Mari kita lihat jeda saat membuat objek besar:

Dapat dilihat bahwa jumlah jeda tersebut saat membuat objek besar turun secara signifikan.
Ringkasan
Berkat perubahan yang dijelaskan dalam artikel, itu mungkin untuk secara signifikan mengurangi jumlah dan durasi majelis dari generasi ke-2. Saya berhasil menemukan penyebab majelis yang diinduksi dan menyingkirkan mereka. Jumlah majelis dari generasi 0 dan 1 meningkat, tetapi durasi rata-rata mereka menurun (dari ~ 200 ms hingga ~ 60 ms). Durasi perakitan maksimum generasi 0 dan 1 telah menurun, tetapi tidak begitu terasa. Majelis generasi ke-2 menjadi lebih cepat, jeda yang panjang hingga 1000 ms benar-benar hilang.
Adapun metrik kunci - "persentase permintaan lambat", itu menurun sebesar 40% setelah semua perubahan.
Berkat kerja kami, kami menyadari penghitung kinerja apa yang diperlukan untuk menilai situasi dengan memori dan pengumpulan sampah, menambahkannya ke Zabbix untuk pemantauan berkelanjutan. Berikut adalah daftar yang paling penting yang kami perhatikan dan cari tahu alasannya (misalnya, peningkatan aliran permintaan, sejumlah besar data yang dikirimkan, bug dalam aplikasi):