Judul artikel mungkin tampak aneh dan karena alasan yang baik - itu indah karena itu bukan ditulis oleh saya, tetapi oleh jaringan saraf LSTM (atau lebih tepatnya, bagian sebelum "atau").
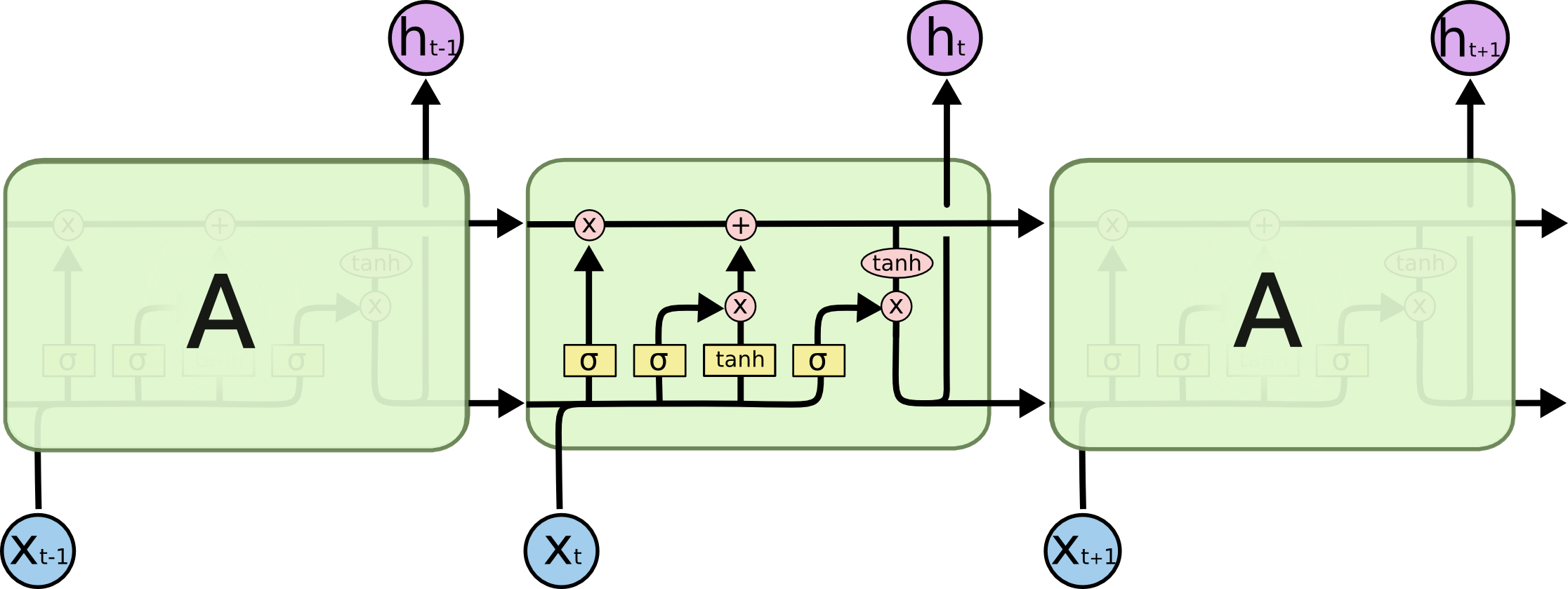
(Skema LSTM diambil dari Memahami Jaringan LSTM )
Dan hari ini kita akan mencari tahu bagaimana Anda dapat menghasilkan judul artikel Habr (dan, pada prinsipnya, teks itu sendiri dapat dihasilkan oleh neuro-arsitektur yang sama). Semua kode tersedia untuk dijalankan secara online di buku catatan dari Google. Data, seperti biasa, terbuka di github .
Dan di sini Anda dapat menjalankan model yang sudah terlatih pada GPU dari Google (gratis dan tanpa SMS) dan benar-benar menghasilkan header.
Tautan kunci
Teori dan deskripsi jaringan saraf (khususnya LSTM) dalam artikel ini didasarkan pada
Deskripsi Data
Secara total, sekitar 40k judul artikel dikumpulkan: setiap judul dilengkapi dengan dua karakter khusus <START_CHAR> dan <END_CHAR> di awal dan akhir, serta <PADDING_CHAR> setelah <END_CHAR> hingga ukuran maksimum judul.
Contoh data yang dikumpulkan:
Google IT . Now it's official
Teori LSTM
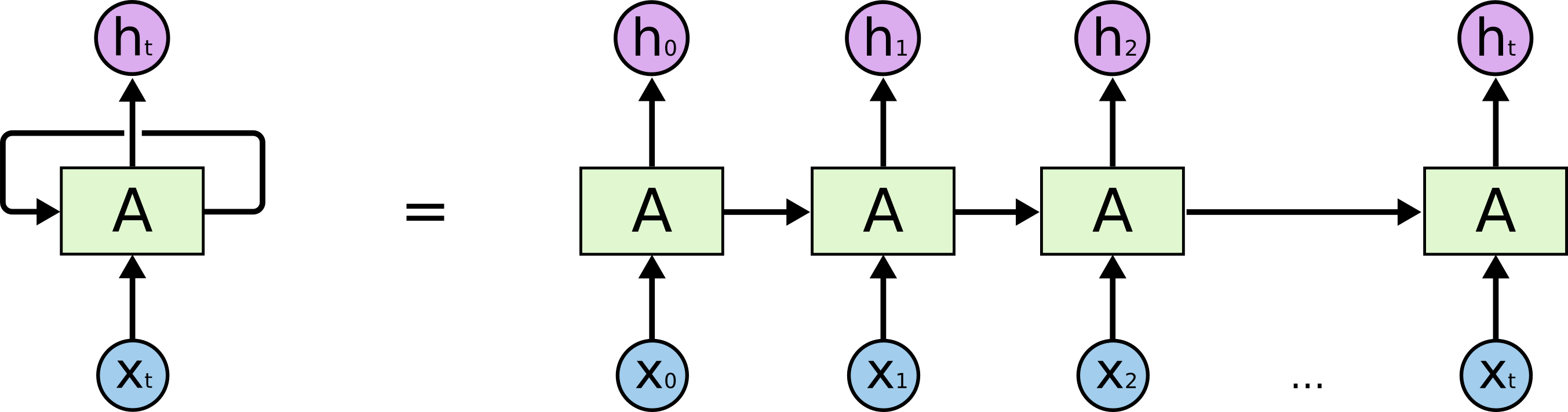
Mari kita mulai dengan tugas aktual yang kita selesaikan: kita ingin memprediksi garis (N + 1) dalam karakter N, secara ilustratif dari sudut pandang model LSTM, terlihat seperti pada gambar di bawah ini: X di bawah - input data; h i di atas adalah akhir pekan; di antara mereka adalah keadaan internal jaringan. Dalam sedikit lebih detail - gambar di sebelah kiri dengan loop umpan balik, setara dengan rantai detail di sebelah kanan.
Apa garamnya? Dalam memprediksi karakter yang disorot di akhir, karakter yang disorot di awal dapat memainkan peran kunci - maka istilah Ketergantungan Jangka Panjang. Jelas bahwa seringkali karakter yang berdiri di sampingnya memainkan peran penting - ketergantungan seperti itu disebut Dependensi Jangka Pendek.
Internal sel LSTM:
Seluruh sel mengandung empat elemen dasar.
- Gates lupa - elemen memutuskan bahwa itu akan keluar dari memori
- Gerbang masuk - ini menciptakan satu set "nilai kandidat" yang dapat kita gunakan untuk menulis dan memperbarui memori
- Memori - elemen menentukan apa yang sebenarnya dan bagaimana kita menyimpan
- Elemen Keluaran - menentukan output dari model
Penunjukan:

Gerbang lupa
Jika kita mencoba untuk memprediksi akhir kata - penting untuk mengetahui jenis kelamin dari kata benda saat ini, jika kita melihat kata benda baru - ada baiknya melupakan arti sebelumnya:

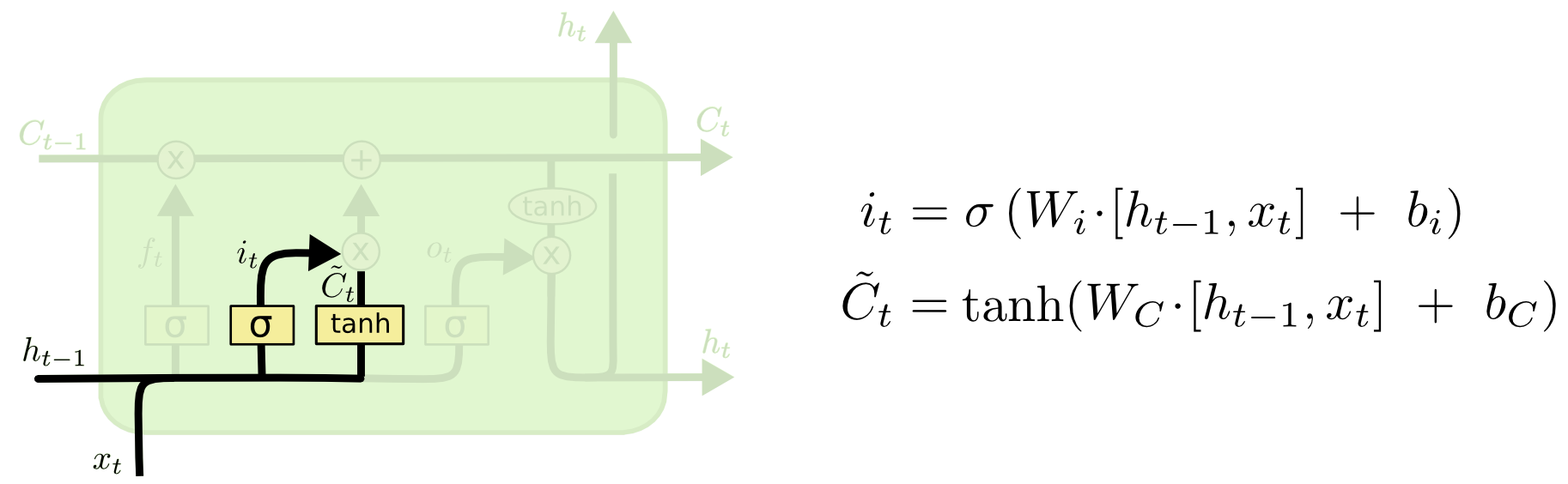
Gerbang Masuk
Selanjutnya, kita menghitung it , yang akan menentukan nilai sel memori apa yang ingin kita perbarui, dan
menghitung nilai kandidat untuk pembaruan.
Sel memori
Selanjutnya, nilai memori adalah superposisi dari apa yang kita lupakan dalam kondisi saat ini dan apa yang kita tambahkan

Output model
Apa yang dimaksud dengan inferensi model - kombinasi dari tiga hal: simbol input saat ini, prediksi sebelumnya, dan memori model

Kode
Logika dasar model disajikan di bawah ini, sebagai aturan - ini adalah sekitar 5-10% dari seluruh kode, sisa kode adalah pembersihan, persiapan dan pemrosesan data, serta output dalam bentuk yang dapat dibaca manusia.
Di sini Anda dapat menjalankan kode dengan model yang sudah terlatih.
model = Sequential()
Contoh header yang dibuat
Pengambilan sampel pribadi:
python powershell
(referensi model acak untuk Dr. Strangelove sangat menyenangkan)
Apa itu suhu (dalam konteks DL)
Pada output, model menghasilkan bobot x w dari kata w - kami memiliki opsi tentang cara mengubah bobot ini menjadi probabilitas p (w), misalnya, menggunakan rumus:
Di mana T adalah parameter bebas (dalam fisika ini adalah bagaimana suhu ditentukan secara statistik - maka namanya), semakin rendah suhu - semakin besar eksponen dan bobot yang lebih tinggi akan "menghilangkan" semua kemungkinan, yaitu, model akan memprediksi hanya beberapa kata dengan maksimum Bobot, jika suhunya tinggi, maka distribusinya akan bergerak ke seragam dan lebih "kreatif". Ini memberi kita kesempatan untuk mengontrol keseimbangan antara secara akurat mengikuti data yang tersedia dan kreativitas bersyarat dari model.
Contoh keluaran model using temperature 0.03 python sql azure federations 2 temperature 0.04 devcon 2013 temperature 0.05 python temperature 0.06 jbreak 2 10 19 temperature 0.07 temperature 0.08 php 10 temperature 0.09 unix oracle temperature 0.1 php temperature 0.11 android android studio github vue js php ruby temperature 0.12 asp net temperature 0.13 google glass using temperature 0.14 android temperature 0.15 python android sql azure federations 2 temperature 0.16 windows python using temperature 0.17 scala apache solr 1 c, 2 3 temperature 0.18 python cpatext content security policy temperature 0.190 52 28 27 nes c 1 3 scanner temperature 0.2 google chrome ms ie
Kesimpulan
- Model arsitektur LSTM berurutan dengan baik dan jelas
- Tata bahasa dan logika sering mengalami - kemungkinan besar masalah di dua tempat: pertama, perangkat memori cukup sederhana dan tidak dapat menangkap semua aturan dan konteks; kedua, kekuatan case - dataset cukup kecil dan tidak terlalu beragam
- Akan menarik untuk melihat versi Better Language Model dan Implikasinya dalam kasus besar bahasa Rusia - untuk memahami apakah arsitektur dan kasus yang lebih kuat menyelesaikan masalah ini
- Beberapa tajuk berita keluar sangat konyol dan ironis, misalnya, "... dan mengapa disalahkan untuk ini"
- Kami melihat pola-pola tertentu dalam pos Habr, misalnya, "kami \ dibuat \ dibangun", indikator yang jelas bahwa orang suka berbagi cerita pribadi tentang Habr