Bagian 1
Bagian 3
Pindah dari data ke hasil tanpa meninggalkan komputer Anda

Tumpukan gambar zona kecil di Slovenia, dan peta dengan tutupan lahan rahasia diperoleh dengan menggunakan metode yang dijelaskan dalam artikel.
Kata Pengantar
Bagian kedua dari serangkaian artikel tentang klasifikasi tutupan lahan menggunakan perpustakaan eo-learning. Kami mengingatkan Anda bahwa artikel pertama menunjukkan hal berikut:
- Membagi AOI (area of interest) menjadi fragmen yang disebut EOPatch
- Menerima gambar dan topeng cloud dari satelit Sentinel-2
- Perhitungan informasi tambahan seperti NDWI , NDVI
- Membuat topeng referensi dan menambahkannya ke data sumber
Selain itu, kami melakukan studi permukaan data, yang merupakan langkah yang sangat penting sebelum mulai terjun ke pembelajaran mesin. Tugas-tugas di atas dilengkapi dengan contoh dalam bentuk Notebook Jupyter , yang sekarang berisi bahan dari artikel ini.
Pada artikel ini, kami akan menyelesaikan persiapan data, dan juga membangun model pertama untuk membangun peta tutupan lahan untuk Slovenia pada tahun 2017.
Persiapan data
Jumlah kode yang berhubungan langsung dengan pembelajaran mesin cukup kecil dibandingkan dengan program lengkap. Bagian terbesar dari pekerjaan adalah untuk menghapus data, memanipulasi data sedemikian rupa untuk memastikan penggunaan yang mulus dengan classifier. Bagian dari pekerjaan ini akan dijelaskan di bawah ini.

Diagram pipa pembelajaran mesin yang menunjukkan bahwa kode itu sendiri menggunakan ML adalah sebagian kecil dari keseluruhan proses. Sumber
Penyaringan Gambar Awan
Awan adalah entitas yang biasanya muncul pada skala yang melebihi EOPatch rata-rata kami (1000x1000 piksel, resolusi 10m). Ini berarti bahwa situs mana pun dapat sepenuhnya ditutupi oleh awan pada tanggal acak. Gambar semacam itu tidak mengandung informasi yang berguna dan hanya menggunakan sumber daya, jadi kami mengabaikannya berdasarkan rasio piksel yang valid terhadap jumlah total dan menetapkan ambang batas. Kami dapat memanggil valid semua piksel yang tidak diklasifikasikan sebagai awan dan terletak di dalam citra satelit. Perhatikan juga bahwa kami tidak menggunakan topeng yang disertakan dengan gambar Sentinel-2, karena mereka dihitung pada tingkat gambar penuh (ukuran gambar S2 penuh adalah 10980 × 10980 piksel, sekitar 110 × 110 km), yang berarti bahwa sebagian besar tidak diperlukan untuk AOI kami. Untuk menentukan cloud, kita akan menggunakan algoritma dari paket s2cloudless untuk mendapatkan topeng piksel cloud.
Di buku catatan kami, ambang batas ditetapkan ke 0,8, jadi kami memilih hanya gambar yang diisi dengan data normal sebesar 80%. Ini mungkin terdengar seperti nilai yang cukup tinggi, tetapi karena awan tidak terlalu menjadi masalah bagi AOI kami, kami dapat membelinya. Patut dipertimbangkan bahwa pendekatan ini tidak dapat diterapkan tanpa berpikir ke titik mana pun di planet ini, karena daerah yang Anda pilih dapat ditutupi dengan awan untuk sebagian besar tahun ini.
Interpolasi temporal
Karena kenyataan bahwa gambar dapat dilewati pada beberapa tanggal, serta karena tanggal akuisisi AOI yang tidak konsisten, kurangnya data adalah kejadian yang sangat umum di bidang pengamatan Bumi. Salah satu cara untuk mengatasi masalah ini adalah dengan memaksakan topeng validitas piksel (dari langkah sebelumnya) dan menginterpolasi nilai untuk "mengisi lubang". Sebagai hasil dari proses interpolasi, nilai piksel yang hilang dapat dihitung untuk membuat EOPatch yang berisi snapshot pada hari-hari yang didistribusikan secara merata. Dalam contoh ini, kami menggunakan interpolasi linier, tetapi ada metode lain, beberapa di antaranya sudah diterapkan dalam eo-learning.

Di sebelah kiri adalah tumpukan gambar Sentinel-2 dari AOI yang dipilih secara acak. Pixel transparan berarti data yang hilang karena awan. Gambar di sebelah kanan menunjukkan tumpukan setelah interpolasi, dengan mempertimbangkan cloud mask akun.
Informasi temporal sangat penting dalam klasifikasi tutupan, dan bahkan lebih penting lagi dalam tugas mengidentifikasi budaya kecambah. Ini semua karena fakta bahwa sejumlah besar informasi tentang tutupan lahan tersembunyi dalam bagaimana plot berubah sepanjang tahun. Misalnya, saat melihat nilai NDVI yang diinterpolasi, Anda dapat melihat bahwa nilai di hutan dan ladang mencapai nilai maksimumnya di musim semi / musim panas dan jatuh dengan kuat di musim gugur / musim dingin, sementara air dan permukaan buatan menjaga nilai-nilai ini mendekati konstan sepanjang tahun. Permukaan buatan memiliki nilai NDVI sedikit lebih tinggi dibandingkan dengan air, dan sebagian mengulangi perkembangan hutan dan ladang, karena di kota sering Anda dapat menemukan taman dan vegetasi lainnya. Anda juga harus mempertimbangkan keterbatasan yang terkait dengan resolusi gambar - seringkali di area yang dicakup oleh satu piksel, Anda dapat mengamati beberapa jenis cakupan pada saat bersamaan.
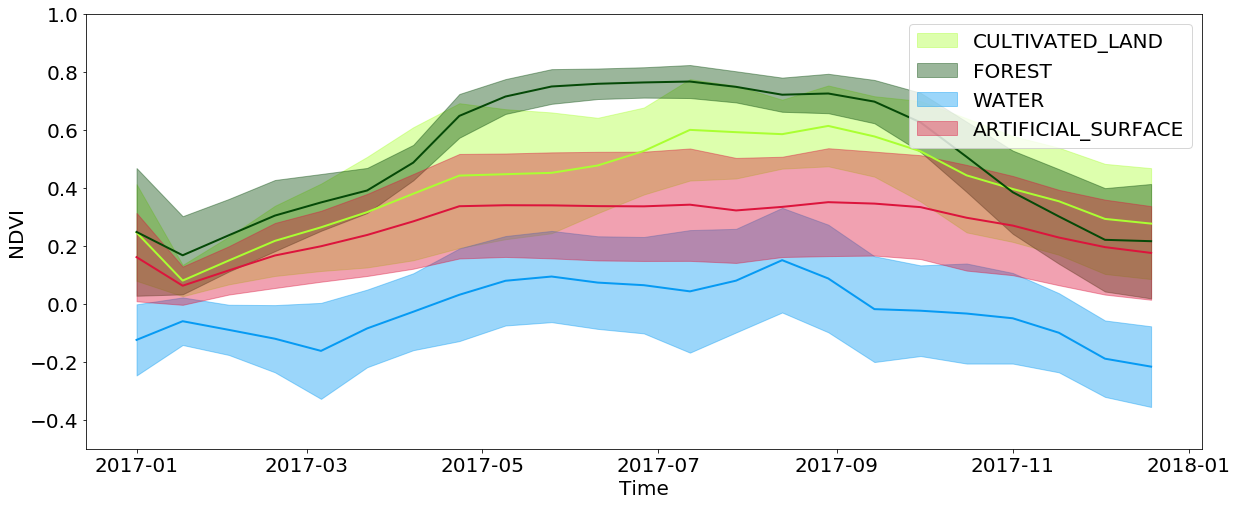
Pengembangan sementara nilai NDVI untuk piksel dari jenis tutupan lahan tertentu sepanjang tahun
Buffer negatif
Meskipun resolusi gambar 10m cukup untuk berbagai tugas yang sangat luas, efek samping dari objek kecil cukup signifikan. Objek-objek semacam itu terletak di perbatasan antara berbagai jenis sampul, dan piksel-piksel ini diberi nilai hanya dari satu jenis sampul. Karena itu, ketika melatih pengklasifikasi, kelebihan noise hadir dalam data input, yang memperburuk hasilnya. Selain itu, jalan dan objek lain dengan lebar 1 piksel hadir di peta asli, meskipun mereka sangat sulit diidentifikasi dari gambar. Kami menerapkan buffering negatif 1-pixel ke peta referensi, menghilangkan hampir semua area masalah dari input.
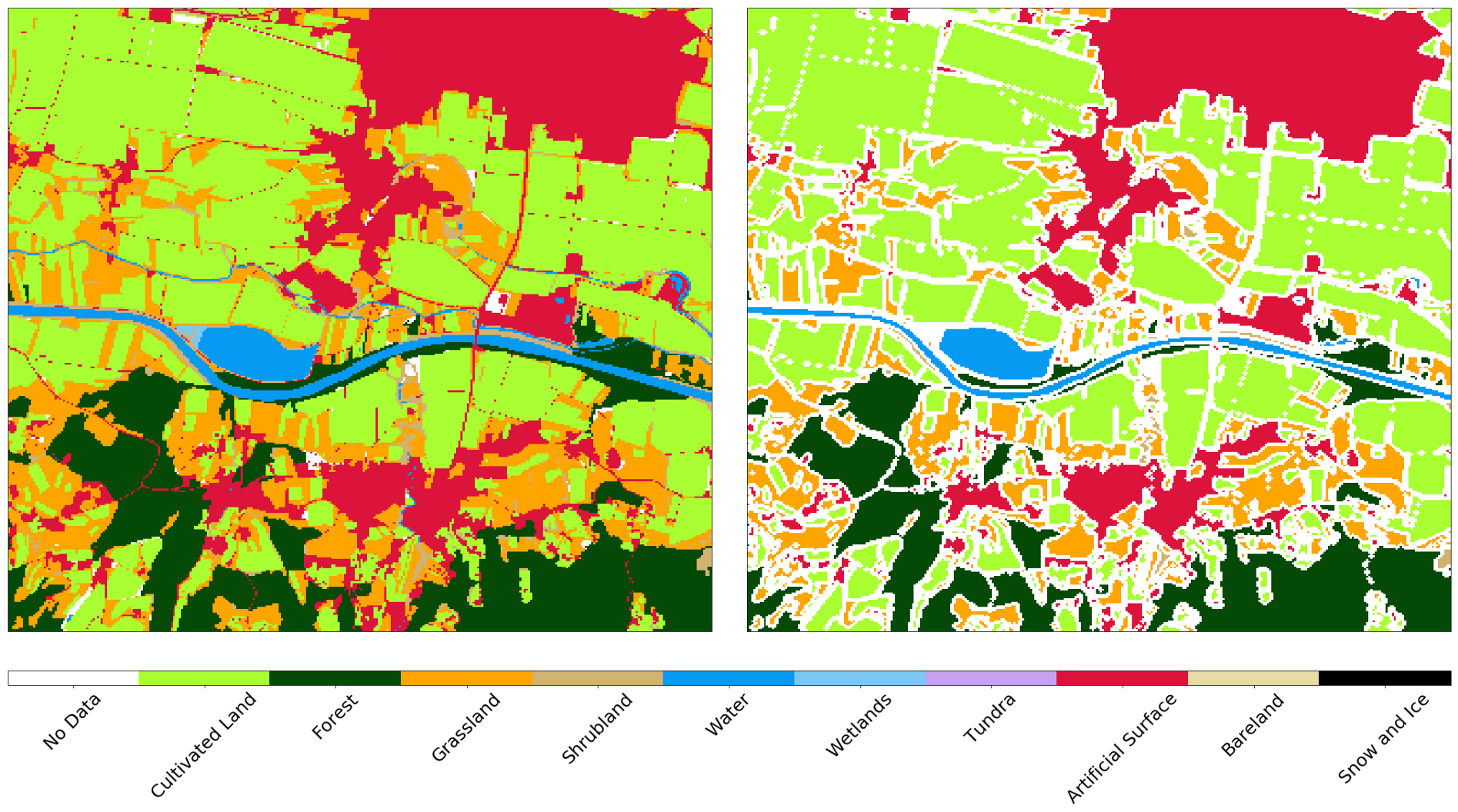
Peta referensi AOI sebelum (kiri) dan setelah (kanan) buffering negatif
Pemilihan data acak
Seperti disebutkan dalam artikel sebelumnya, AOI lengkap dibagi menjadi sekitar 300 fragmen, yang masing-masing terdiri dari ~ 1 juta piksel. Ini adalah jumlah yang cukup mengesankan dari piksel yang sama ini, jadi kami mengambil sekitar 40.000 piksel untuk setiap EOPatch secara merata untuk mendapatkan kumpulan data 12 juta salinan. Karena piksel diambil secara merata, sejumlah besar tidak masalah pada peta referensi, karena data ini tidak diketahui (atau hilang setelah langkah sebelumnya). Masuk akal untuk menyaring data tersebut untuk menyederhanakan pelatihan pengklasifikasi, karena kita tidak perlu mengajarkannya untuk mendefinisikan label “tidak ada data”. Prosedur yang sama diulangi untuk set uji, karena data tersebut secara artifisial menurunkan indikator kualitas prediksi classifier.
Kami membagi data input ke dalam set pelatihan / pengujian masing-masing dengan rasio 80/20%, bahkan pada tingkat EOPatch, yang menjamin kami bahwa set ini tidak berpotongan. Kami juga membagi piksel dari set untuk pelatihan ke dalam set untuk pengujian dan validasi silang dengan cara yang sama. Setelah pemisahan, kita mendapatkan array dimensi numpy.ndarray Array (p,t,w,h,d) , di mana:
p adalah jumlah EOPatch dalam kumpulan data
t - jumlah gambar yang diinterpolasi untuk setiap EOPatch
* w, h, d - lebar, tinggi, dan jumlah lapisan dalam gambar, masing-masing.
Setelah memilih himpunan bagian, lebar w sesuai dengan jumlah piksel yang dipilih (misalnya, 40.000), sedangkan dimensi h adalah 1. Perbedaan dalam bentuk array tidak mengubah apa pun, prosedur ini hanya diperlukan untuk menyederhanakan bekerja dengan gambar.
Data dari sensor dan topeng d dalam gambar apa pun t menentukan data input untuk pelatihan, di mana instance seperti total p*w*h . Untuk mengkonversi data menjadi bentuk yang dapat dicerna untuk pengklasifikasi, kita harus mengurangi dimensi array dari 5 ke matriks bentuk (p*w*h, d*t) . Ini mudah dilakukan dengan menggunakan kode berikut:
import numpy as np p, t, w, h, d = features_array.shape
Prosedur seperti itu akan memungkinkan untuk membuat prediksi pada data baru dari bentuk yang sama, dan kemudian mengubahnya kembali dan memvisualisasikannya dengan cara standar.
Membuat Model Pembelajaran Mesin
Pilihan optimal dari classifier sangat tergantung pada tugas spesifik, dan bahkan dengan pilihan yang tepat kita tidak boleh lupa tentang parameter model tertentu, yang harus diubah dari tugas ke tugas. Biasanya diperlukan untuk melakukan banyak percobaan dengan set parameter yang berbeda untuk secara akurat mengatakan apa yang diperlukan dalam situasi tertentu.
Dalam seri artikel ini, kami menggunakan paket LightGBM , karena ini adalah kerangka kerja yang intuitif, cepat, didistribusikan, dan produktif untuk membangun model berdasarkan pohon keputusan. Untuk memilih hyperparameters classifier, seseorang dapat menggunakan pendekatan yang berbeda, seperti pencarian grid , yang harus diuji pada set tes. Untuk kesederhanaan, kami akan melewati langkah ini dan menggunakan parameter default.
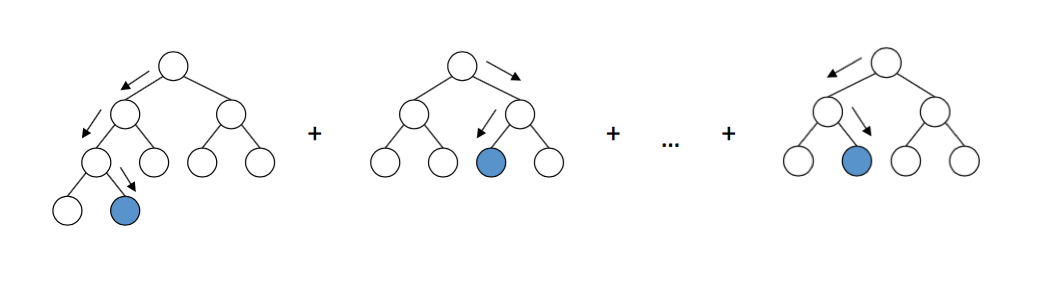
Skema kerja pohon keputusan di LightGBM. Sumber
Implementasi model cukup sederhana, dan karena data sudah datang dalam bentuk matriks, kami cukup memberi makan data ini ke input model dan menunggu. Selamat! Sekarang Anda dapat memberi tahu semua orang bahwa Anda terlibat dalam pembelajaran mesin dan akan menjadi orang yang paling modis di sebuah pesta, sementara ibumu akan gelisah tentang pemberontakan robot dan kematian umat manusia.
Validasi model
Model pelatihan dalam pembelajaran mesin itu mudah. Kesulitannya adalah melatih mereka dengan baik . Untuk ini, kita memerlukan algoritma yang sesuai, kartu referensi yang andal, dan sumber daya komputasi yang cukup. Tetapi bahkan dalam kasus ini, hasilnya mungkin bukan yang Anda inginkan, jadi memeriksa classifier dengan matriks kesalahan dan metrik lainnya mutlak diperlukan untuk setidaknya beberapa kepercayaan pada hasil pekerjaan Anda.
Matriks kesalahan
Matriks kesalahan adalah hal pertama yang harus dilihat ketika mengevaluasi kualitas pengklasifikasi. Mereka menunjukkan jumlah tag yang diprediksi dengan benar dan salah untuk setiap tag dari kartu referensi dan sebaliknya. Biasanya, matriks dinormalisasi digunakan, di mana semua nilai dalam garis dibagi dengan jumlah total. Ini menunjukkan apakah classifier tidak memiliki bias terhadap jenis penutup tertentu relatif terhadap yang lain
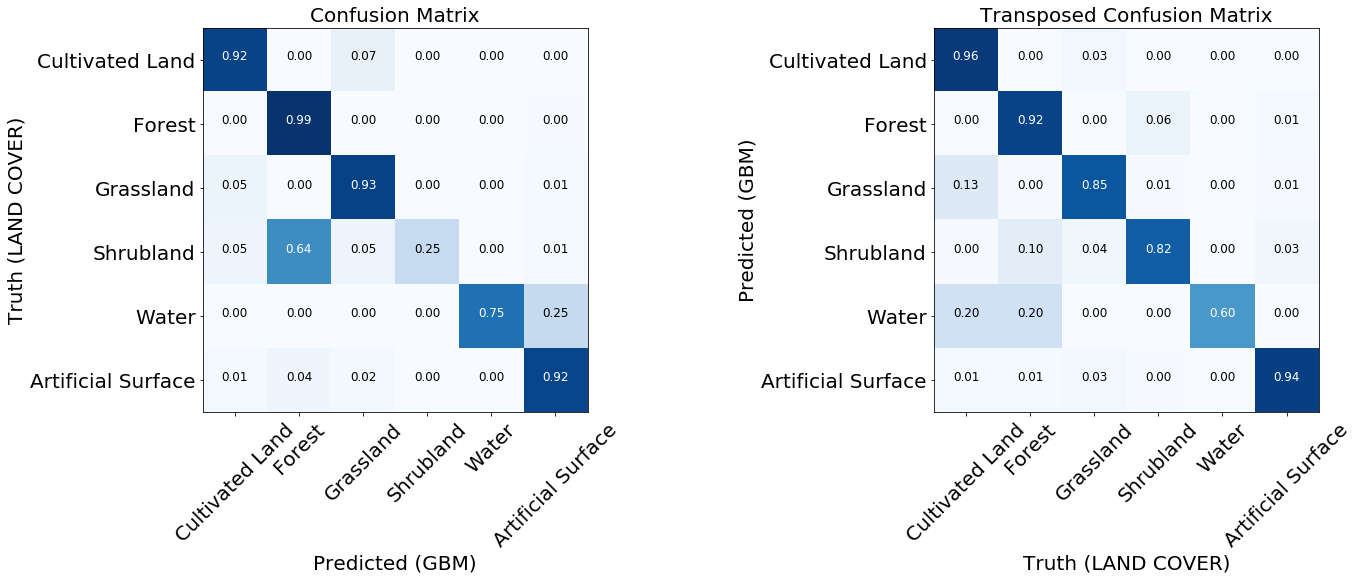
Dua matriks kesalahan yang dinormalisasi dari model yang dilatih.
Untuk sebagian besar kelas, model ini menunjukkan hasil yang baik. Untuk beberapa kelas, kesalahan terjadi karena ketidakseimbangan dalam data input. Kami melihat bahwa masalahnya adalah, misalnya, semak dan air, yang modelnya sering membingungkan label piksel dan mengidentifikasinya dengan tidak benar. Di sisi lain, apa yang ditandai sebagai semak atau air berkorelasi cukup baik dengan peta referensi. Dari gambar berikut, kita dapat melihat bahwa masalah muncul untuk kelas yang memiliki sedikit contoh pelatihan - ini terutama disebabkan oleh sejumlah kecil data dalam contoh kita, tetapi masalah ini dapat terjadi dalam tugas nyata apa pun.
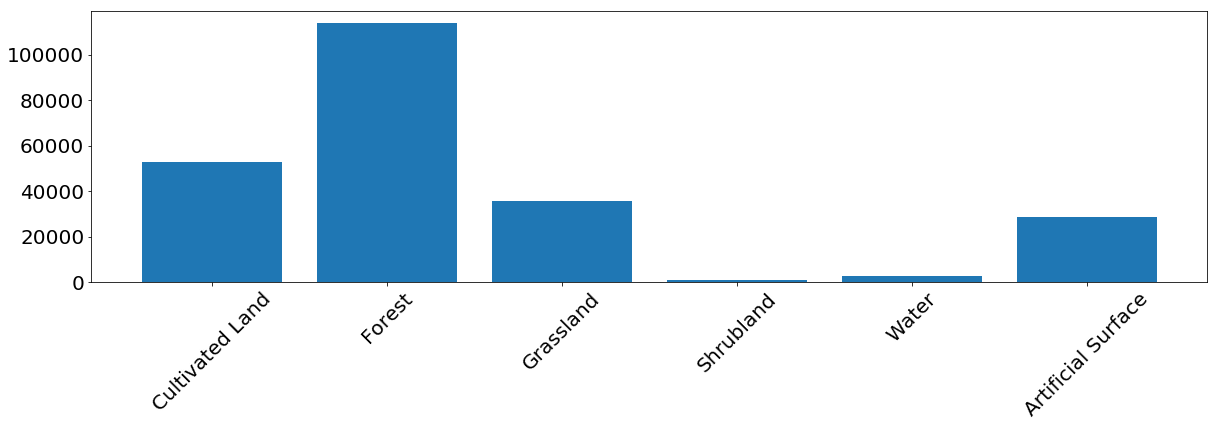
Frekuensi kemunculan piksel dari setiap kelas dalam set pelatihan.
Karakteristik Pengoperasian Penerima - Kurva ROC
Pengklasifikasi memprediksi label dengan kepastian tertentu, tetapi ambang ini untuk label tertentu dapat diubah. Kurva ROC menunjukkan kemampuan classifier untuk membuat prediksi yang benar ketika mengubah ambang sensitivitas. Biasanya grafik ini digunakan untuk sistem biner , tetapi dapat digunakan dalam kasus kami jika kami menghitung karakteristik "label terhadap yang lainnya" untuk setiap kelas. Sumbu x menunjukkan hasil positif palsu (kita perlu meminimalkan jumlahnya), dan sumbu y menunjukkan hasil positif sejati (kita perlu menambah jumlahnya) pada ambang yang berbeda. Klasifikasi yang baik dapat digambarkan dengan kurva di mana area kurva maksimal. Indikator ini juga dikenal sebagai area di bawah kurva, AUC. Dari grafik kurva ROC orang dapat menarik kesimpulan yang sama tentang jumlah contoh kelas “semak” yang tidak mencukupi, meskipun kurva untuk air terlihat jauh lebih baik - ini disebabkan oleh kenyataan bahwa secara visual air sangat berbeda dari kelas lainnya, bahkan dengan jumlah contoh yang tidak mencukupi dalam data.

Kurva ROC dari classifier, dalam bentuk "satu terhadap semua" untuk setiap kelas. Angka dalam tanda kurung adalah nilai AUC.
Pentingnya gejala
Jika Anda ingin mempelajari lebih dalam seluk-beluk classifier, Anda dapat melihat grafik pentingnya fitur, yang memberitahu kami tanda mana yang lebih memengaruhi hasil akhir. Beberapa algoritma pembelajaran mesin, seperti yang kami gunakan dalam artikel ini, mengembalikan nilai-nilai ini. Untuk model lain, metrik ini harus dipertimbangkan sendiri.

Matriks pentingnya karakteristik untuk pengklasifikasi dari contoh
Meskipun tanda-tanda lain di musim semi (NDVI) umumnya lebih penting, kita melihat bahwa ada tanggal yang tepat ketika salah satu tanda (B2 - biru) adalah yang paling penting. Jika Anda melihat gambar-gambarnya, ternyata AOI selama periode ini tertutup salju. Dapat disimpulkan bahwa salju mengungkapkan informasi tentang penutup yang mendasarinya, yang sangat membantu pengklasifikasi untuk menentukan jenis permukaan. Perlu diingat bahwa fenomena semacam itu khusus untuk AOI yang diamati dan secara umum tidak dapat diandalkan.

Bagian AOI tertutup salju 3x3 EOPatch
Hasil prediksi
Setelah validasi, kami lebih memahami kekuatan dan kelemahan model kami. Jika kami tidak puas dengan keadaan saat ini, Anda dapat membuat perubahan pada pipeline dan coba lagi. Setelah mengoptimalkan model, kami mendefinisikan EOTask sederhana yang menerima EOPatch dan model classifier, membuat prediksi, dan menerapkannya pada fragmen.
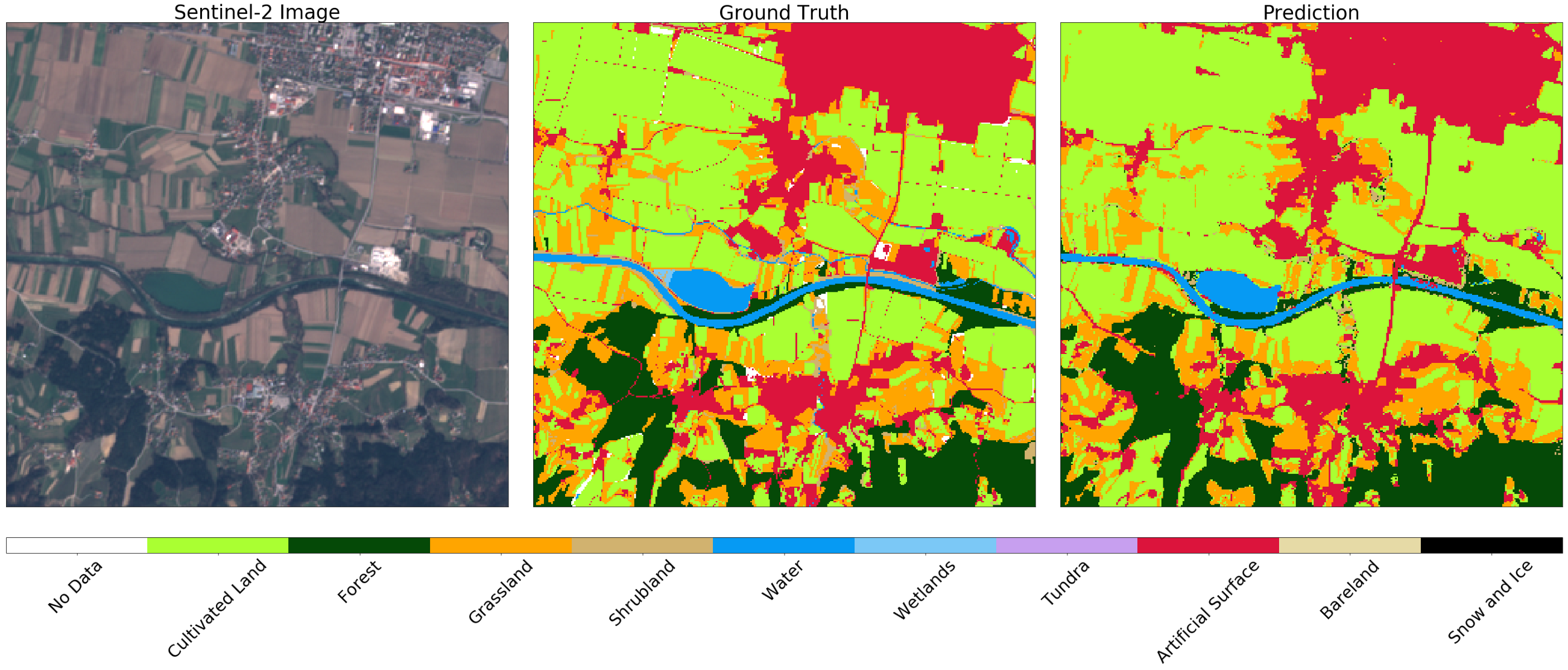
Gambar Sentinel-2 (kiri), kebenaran (tengah) dan prediksi (kanan) untuk fragmen acak dari AOI. Anda mungkin melihat beberapa perbedaan dalam gambar, yang dapat dijelaskan dengan menggunakan buffering negatif pada peta asli. Secara umum, hasil untuk contoh ini memuaskan.
Jalur selanjutnya jelas. Penting untuk mengulangi prosedur untuk semua fragmen. Anda bahkan dapat mengekspornya dalam format GeoTIFF, dan merekatkannya menggunakan gdal_merge.py .
Kami mengunggah GeoTIFF yang direkatkan ke portal GeoPedia kami, Anda dapat melihat hasilnya secara terperinci di sini
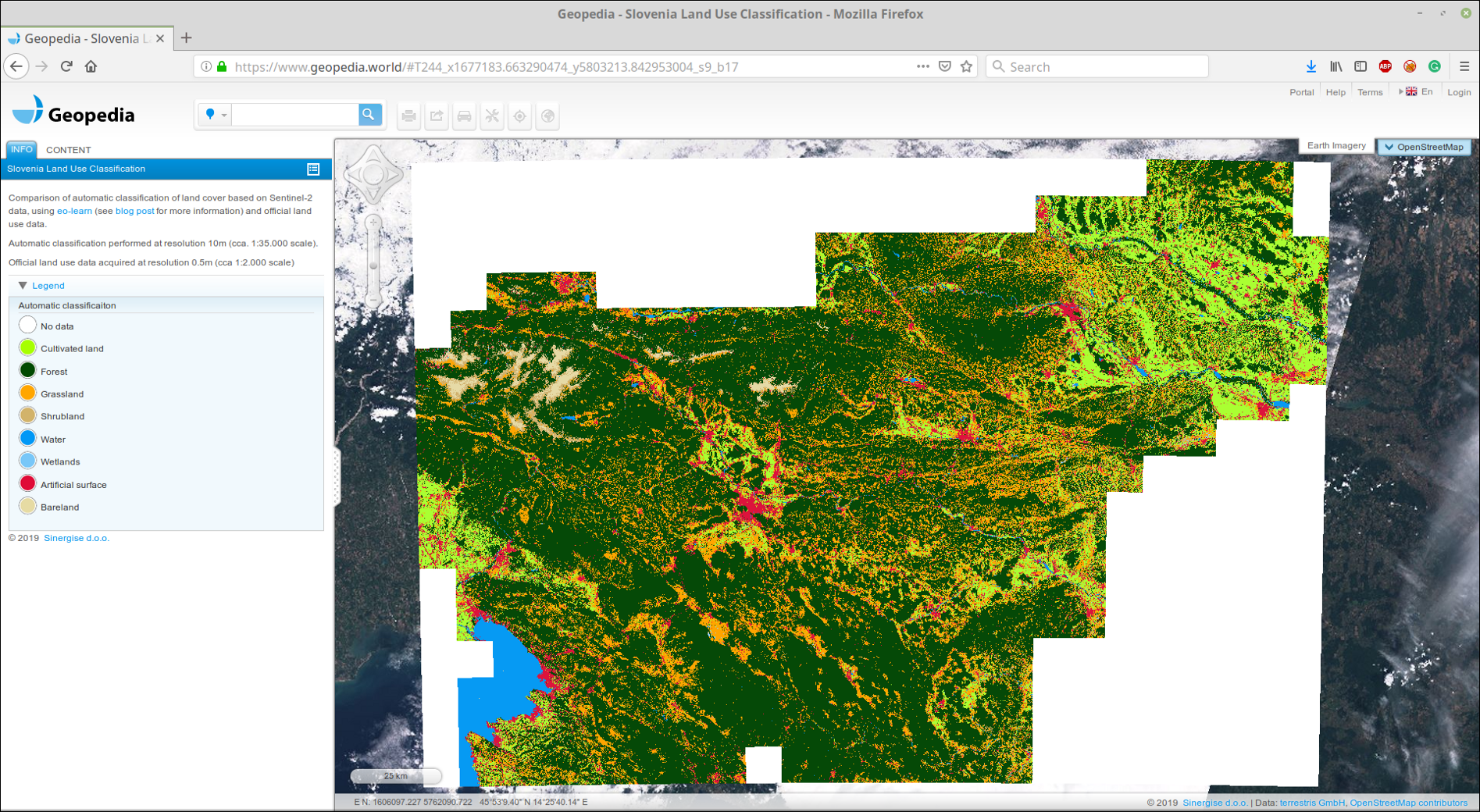
Cuplikan layar prediksi tutupan lahan Slovenia 2017 menggunakan pendekatan dari pos ini. Tersedia dalam format interaktif di tautan di atas
Anda juga dapat membandingkan data resmi dengan hasil pengklasifikasi. Perhatikan perbedaan antara konsep penggunaan lahan dan tutupan lahan , yang sering ditemukan dalam tugas pembelajaran mesin - tidak selalu mudah untuk memetakan data dari register resmi ke kelas di alam. Sebagai contoh, kami menunjukkan dua bandara di Slovenia. Yang pertama adalah Levets, dekat kota Celje . Bandara ini kecil, terutama digunakan untuk jet pribadi, dan tertutup rumput. Secara resmi, wilayah tersebut ditandai sebagai permukaan buatan, meskipun pengklasifikasi dapat mengidentifikasi wilayah tersebut dengan benar sebagai rumput, lihat di bawah.

Gambar Sentinel-2 (kiri), true (tengah), dan prediksi (kanan) untuk area di sekitar bandara olahraga kecil. Pengklasifikasi mendefinisikan landasan sebagai rumput, meskipun ditandai sebagai permukaan buatan dalam data ini.
Di sisi lain, di bandara terbesar di Slovenia, Ljubljana , zona yang ditandai sebagai permukaan buatan pada peta adalah jalan. Dalam hal ini, pengklasifikasi membedakan antara struktur, sementara membedakan rumput dan ladang dengan benar di wilayah tetangga.
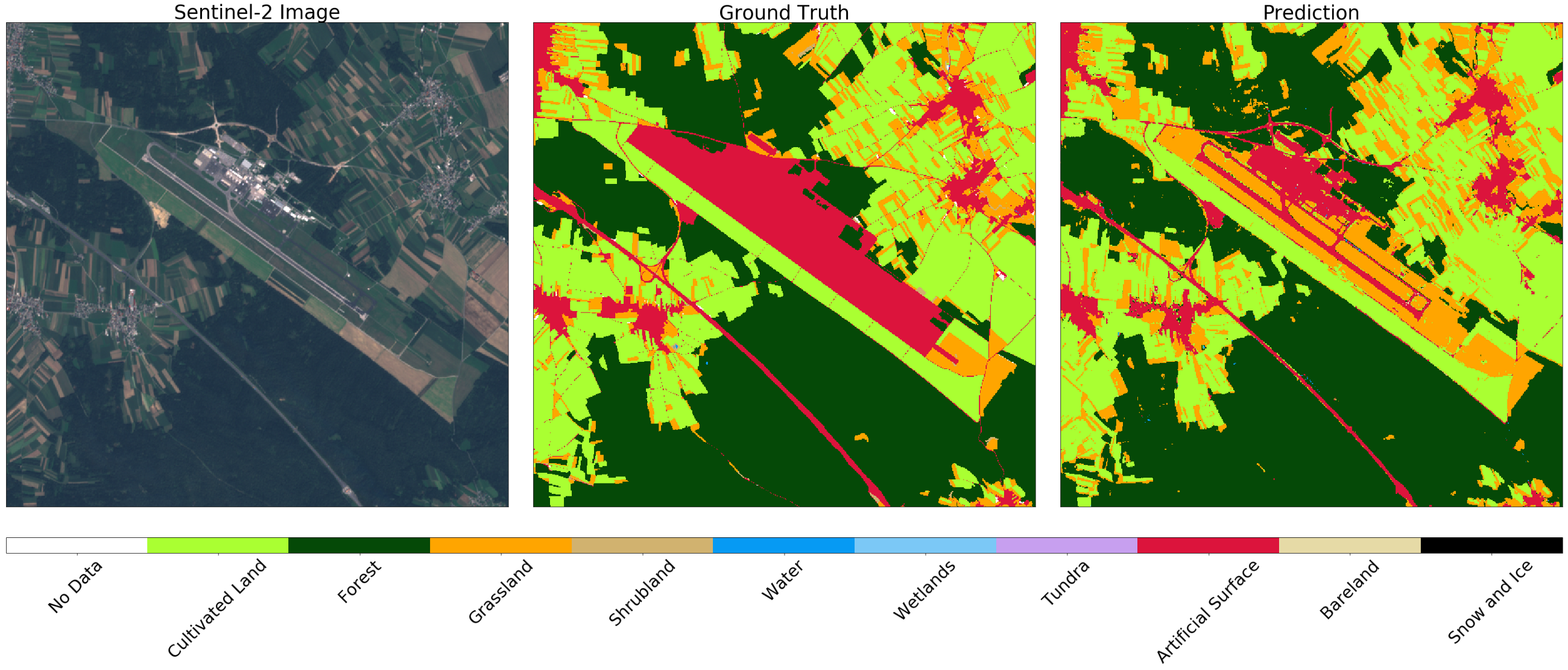
Gambar Sentinel-2 (kiri), kebenaran (tengah), dan prediksi (kanan) untuk area di sekitar Ljubljana. Pengklasifikasi menentukan runway dan jalan, sementara membedakan rumput dan ladang di lingkungan dengan benar
Voila!
Sekarang Anda tahu cara membuat model yang andal dalam skala nasional! Ingatlah untuk menambahkan ini ke resume Anda.