
Jika Anda mengelola infrastruktur virtual berdasarkan VMware vSphere (atau tumpukan teknologi lainnya), Anda mungkin sering mendengar keluhan dari pengguna: "Mesin virtual lambat!". Dalam seri artikel ini saya akan menganalisis metrik kinerja dan menjelaskan apa dan mengapa itu "melambat" dan bagaimana memastikan bahwa itu tidak "melambat".
Saya akan mempertimbangkan aspek kinerja berikut dari mesin virtual:
Saya akan mulai dengan CPU.
Untuk analisis kinerja kita perlu:
- Penghitung Kinerja vCenter adalah penghitung kinerja yang grafiknya dapat dilihat melalui vSphere Client. Informasi tentang penghitung ini tersedia dalam versi klien apa pun (klien "tebal" dalam C #, klien web pada Flex dan klien web pada HTML5). Dalam artikel ini, kami akan menggunakan tangkapan layar dari klien C #, hanya karena mereka terlihat lebih baik dalam miniatur :)
- ESXTOP adalah utilitas yang dijalankan dari baris perintah ESXi. Dengan bantuannya, Anda bisa mendapatkan nilai penghitung kinerja secara waktu nyata atau mengunggah nilai-nilai ini untuk periode tertentu ke file .csv untuk analisis lebih lanjut. Selanjutnya, saya akan memberi tahu Anda lebih banyak tentang alat ini dan memberikan beberapa tautan bermanfaat ke dokumentasi dan artikel terkait.
Sedikit teori
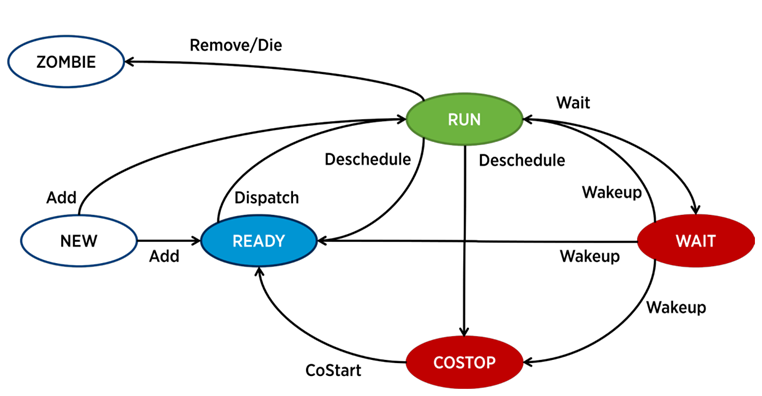
Dalam ESXi, proses terpisah bertanggung jawab untuk pengoperasian setiap vCPU (inti mesin virtual) - dunia dalam terminologi VMware. Ada juga proses layanan, tetapi dari sudut pandang analisis kinerja VM, mereka kurang menarik.
Suatu proses di ESXi dapat di salah satu dari empat negara:
- Jalankan - proses melakukan beberapa pekerjaan yang bermanfaat.
- Tunggu - proses tidak melakukan pekerjaan apa pun (idle) atau sedang menunggu input / output.
- Costop adalah suatu kondisi yang terjadi pada mesin virtual multi-core. Ini terjadi ketika penjadwal CPU hypervisor (ESXi CPU Scheduler) tidak dapat menjadwalkan semua core aktif dari mesin virtual untuk berjalan secara bersamaan pada core server fisik. Dalam dunia fisik, semua core prosesor bekerja secara paralel, OS tamu di dalam VM mengharapkan perilaku yang sama, sehingga hypervisor harus memperlambat core VM, yang memiliki kemampuan untuk menyelesaikan ketukan lebih cepat. Dalam versi modern ESXi, penjadwal CPU menggunakan mekanisme yang disebut santai penjadwalan bersama: hypervisor mempertimbangkan kesenjangan antara inti mesin virtual tercepat dan paling lambat (condong) .Jika kesenjangan melebihi ambang tertentu, inti cepat masuk ke keadaan costop Jika VM core menghabiskan banyak waktu dalam kondisi ini, ini dapat menyebabkan masalah kinerja.
- Siap - proses masuk ke keadaan ini ketika hypervisor tidak memiliki kemampuan untuk mengalokasikan sumber daya untuk pelaksanaannya. Nilai siap tinggi dapat menyebabkan masalah kinerja VM.
Penghitung kinerja CPU dasar dari mesin virtual
Penggunaan CPU,%. Memperlihatkan persentase penggunaan CPU untuk periode tertentu.
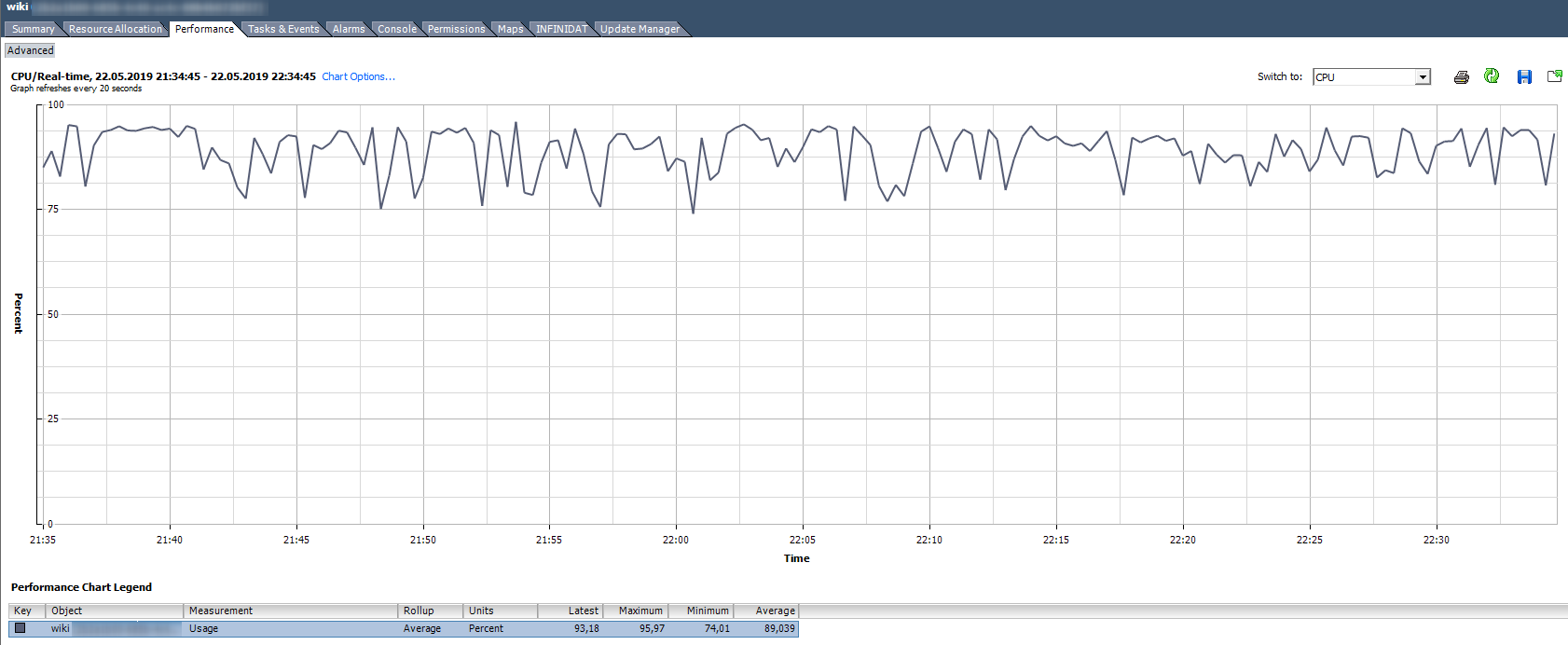 Bagaimana cara menganalisa?
Bagaimana cara menganalisa? Jika VM stabil menggunakan CPU untuk 90% atau ada puncak hingga 100%, maka kita memiliki masalah. Masalah dapat diekspresikan tidak hanya dalam operasi "lambat" aplikasi di dalam VM, tetapi juga dalam tidak dapat diaksesnya VM melalui jaringan. Jika sistem pemantauan menunjukkan bahwa VM jatuh secara berkala, perhatikan puncak pada grafik Penggunaan CPU.
Ada Alarm standar, yang menunjukkan beban CPU dari mesin virtual:
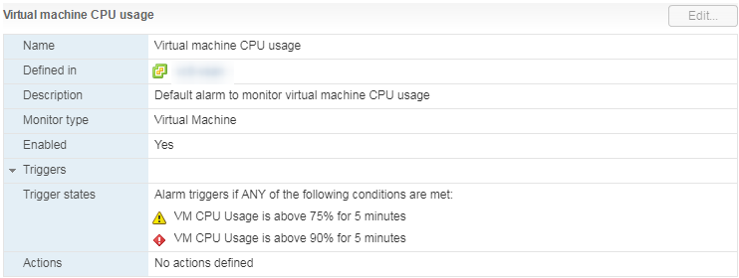 Apa yang harus dilakukan
Apa yang harus dilakukan Jika Penggunaan CPU terus-menerus membanjiri VM, maka Anda dapat berpikir tentang meningkatkan jumlah vCPU (sayangnya, ini tidak selalu membantu) atau mentransfer VM ke server dengan prosesor yang lebih efisien.
Penggunaan CPU dalam Mhz
Di grafik Penggunaan vCenter di% Anda hanya dapat melihat seluruh mesin virtual, tidak ada grafik untuk masing-masing inti (Esxtop memiliki nilai dalam% untuk inti). Untuk setiap inti, Anda dapat melihat Penggunaan dalam MHz.
Bagaimana cara menganalisa? Itu terjadi bahwa aplikasi tidak dioptimalkan untuk arsitektur multi-core: ia menggunakan 100% hanya satu inti, dan sisanya menganggur tanpa beban. Misalnya, dengan pengaturan cadangan default, MS SQL memulai proses hanya pada satu inti. Akibatnya, cadangan diperlambat bukan karena kecepatan disk yang lambat (ini yang awalnya dikeluhkan oleh pengguna), tetapi karena prosesor tidak dapat mengatasinya. Masalahnya dipecahkan dengan mengubah parameter: cadangan mulai berjalan secara paralel di beberapa file (masing-masing, dalam beberapa proses).
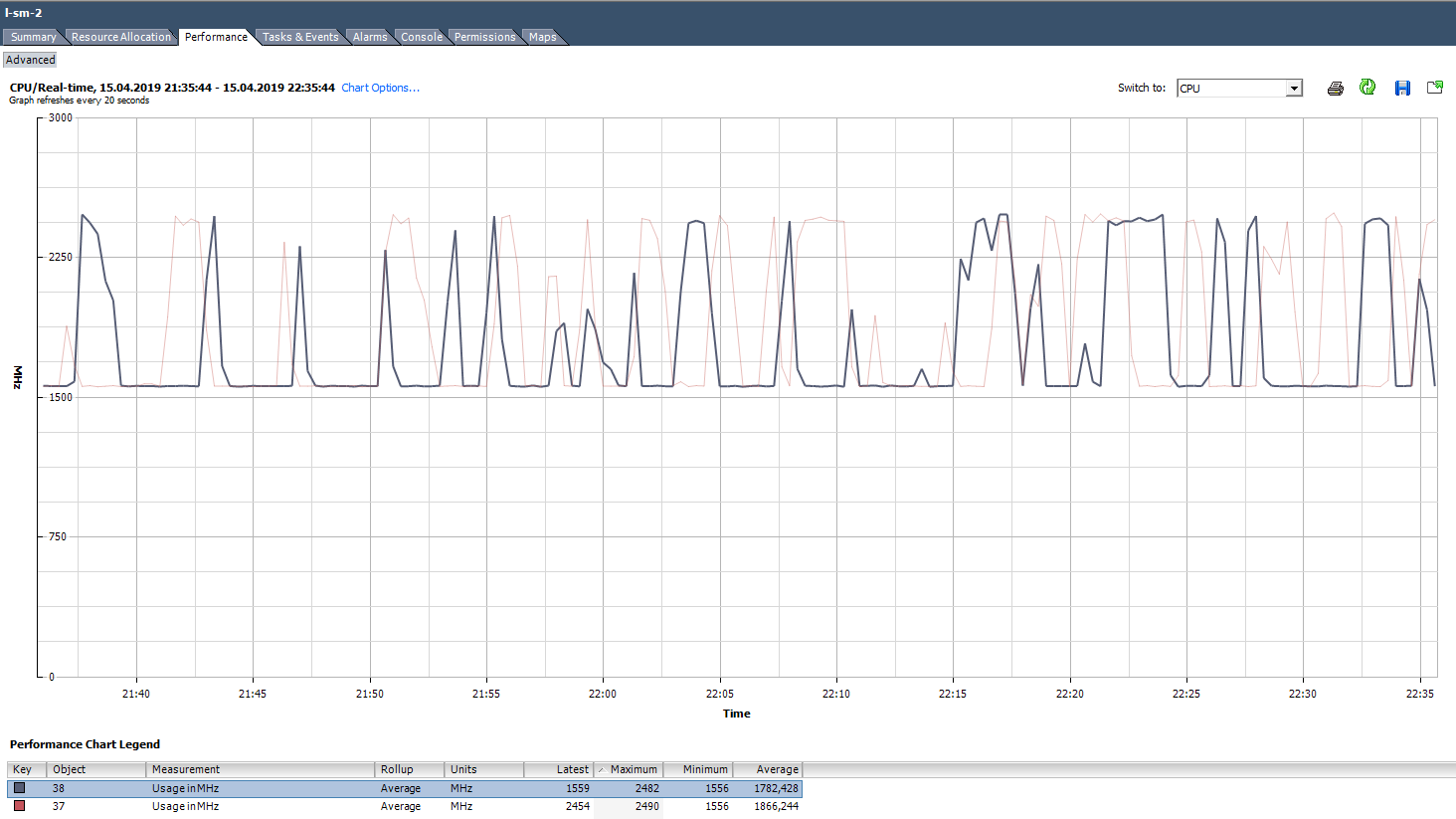 Contoh beban inti yang tidak merata.
Contoh beban inti yang tidak merata.Ada juga situasi (seperti pada grafik di atas) ketika core dimuat tidak merata dan beberapa dari mereka memiliki puncak 100%. Seperti halnya dengan memuat hanya satu inti, alarm pada Penggunaan CPU tidak akan berfungsi (ini ada di seluruh VM), tetapi akan ada masalah kinerja.
Apa yang harus dilakukan Jika perangkat lunak di mesin virtual memuat kernel tidak merata (hanya menggunakan satu inti atau bagian dari kernel), tidak ada gunanya meningkatkan jumlah mereka. Dalam hal ini, lebih baik untuk memindahkan VM ke server dengan prosesor yang lebih efisien.
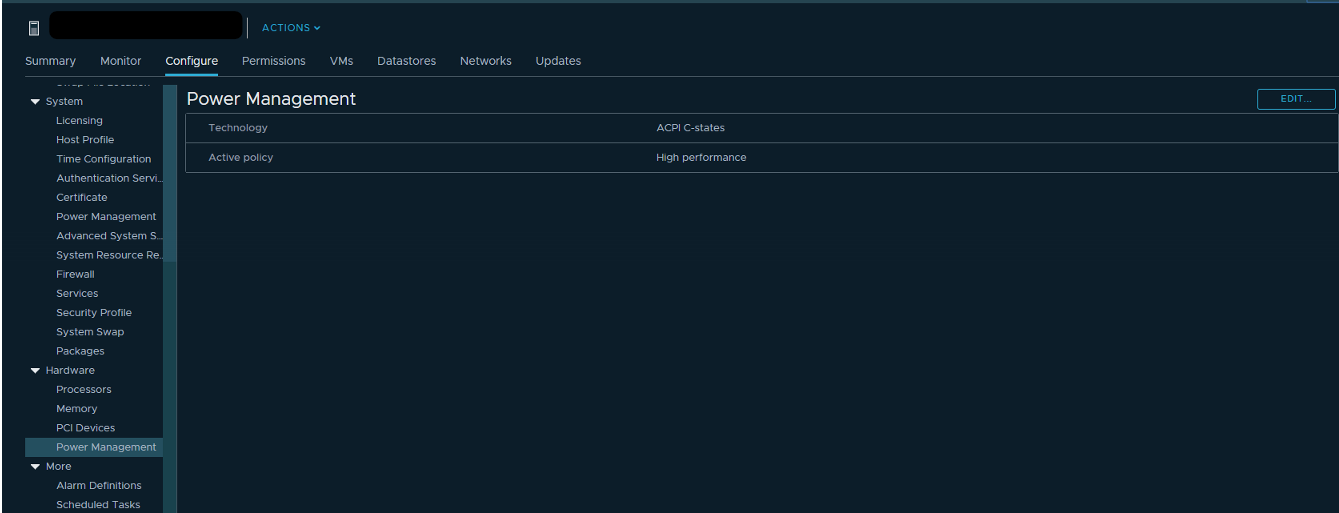
Anda juga dapat mencoba memeriksa pengaturan daya di BIOS server. Banyak administrator mengaktifkan mode Kinerja Tinggi di BIOS dan dengan demikian mematikan teknologi hemat daya dari C-state dan P-state. Prosesor Intel modern menggunakan teknologi Turbo Boost, yang meningkatkan frekuensi masing-masing inti prosesor karena inti lainnya. Tetapi hanya bekerja dengan teknologi hemat energi yang disertakan. Jika kita mematikannya, maka prosesor tidak dapat mengurangi konsumsi daya kernel yang tidak dimuat.
VMware merekomendasikan untuk tidak mematikan teknologi hemat energi di server, tetapi untuk memilih mode yang memaksimalkan manajemen energi untuk hypervisor. Pada saat yang sama, dalam pengaturan daya hypervisor Anda harus memilih High Performance.
Jika Anda memiliki VM terpisah (atau inti VM) di infrastruktur Anda yang memerlukan peningkatan frekuensi CPU, konfigurasi konsumsi daya yang benar dapat secara signifikan meningkatkan kinerjanya.
Siap CPU (Kesiapan)
Jika VM core (vCPU) dalam status Siap, itu tidak melakukan pekerjaan yang bermanfaat. Kondisi ini terjadi ketika hypervisor tidak menemukan inti fisik gratis yang dapat digunakan proses vCPU dari mesin virtual.
Bagaimana cara menganalisa? Biasanya, jika core mesin virtual dalam status Siap untuk lebih dari 10% dari waktu, maka Anda akan melihat masalah kinerja. Sederhananya, lebih dari 10% dari waktu VM menunggu ketersediaan sumber daya fisik.
Di vCenter, Anda dapat melihat 2 penghitung yang terkait dengan CPU Ready:
Nilai-nilai kedua penghitung dapat dilihat baik di seluruh VM dan untuk kernel individu.
Kesiapan menunjukkan nilai segera dalam persen, tetapi hanya dalam waktu-nyata (data untuk jam terakhir, interval pengukuran 20 detik). Penghitung ini paling baik digunakan hanya untuk mencari masalah "dalam pengejaran."
Nilai counter ready juga dapat dilihat dalam perspektif historis. Ini berguna untuk membangun pola dan untuk analisis masalah yang lebih dalam. Misalnya, jika mesin virtual mulai mengalami masalah kinerja pada waktu tertentu, Anda dapat membandingkan interval nilai Ready CPU yang digantung dengan total beban pada server tempat VM berjalan, dan mengambil langkah-langkah untuk mengurangi beban (jika DRS tidak dapat mengatasinya).
Siap, tidak seperti Kesiapan, ditampilkan bukan dalam persentase, tetapi dalam milidetik. Ini adalah penghitung tipe penjumlahan, yaitu, itu menunjukkan berapa lama inti VM berada dalam status siap selama periode pengukuran. Anda dapat menerjemahkan nilai ini menjadi persen dengan rumus sederhana:
(Nilai penjumitan siap CPU / (grafik interval pembaruan default dalam detik * 1000)) * 100 = CPU siap%
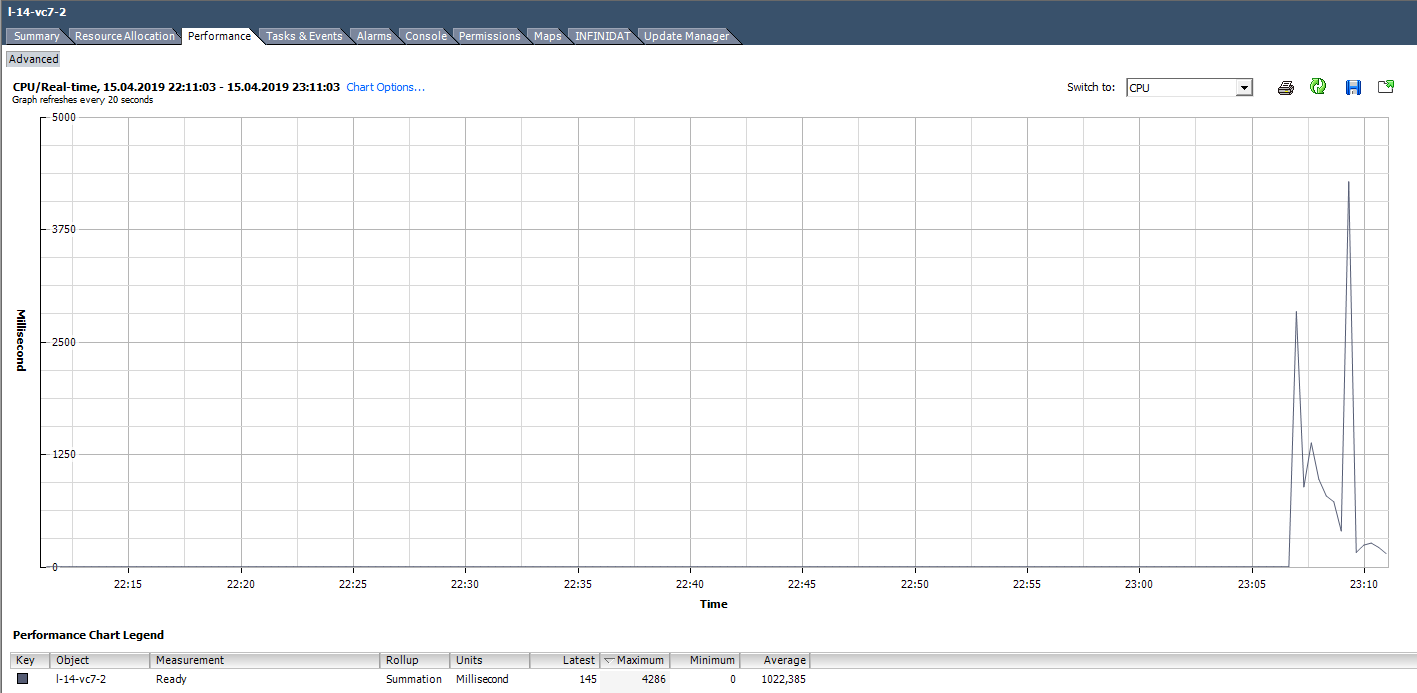
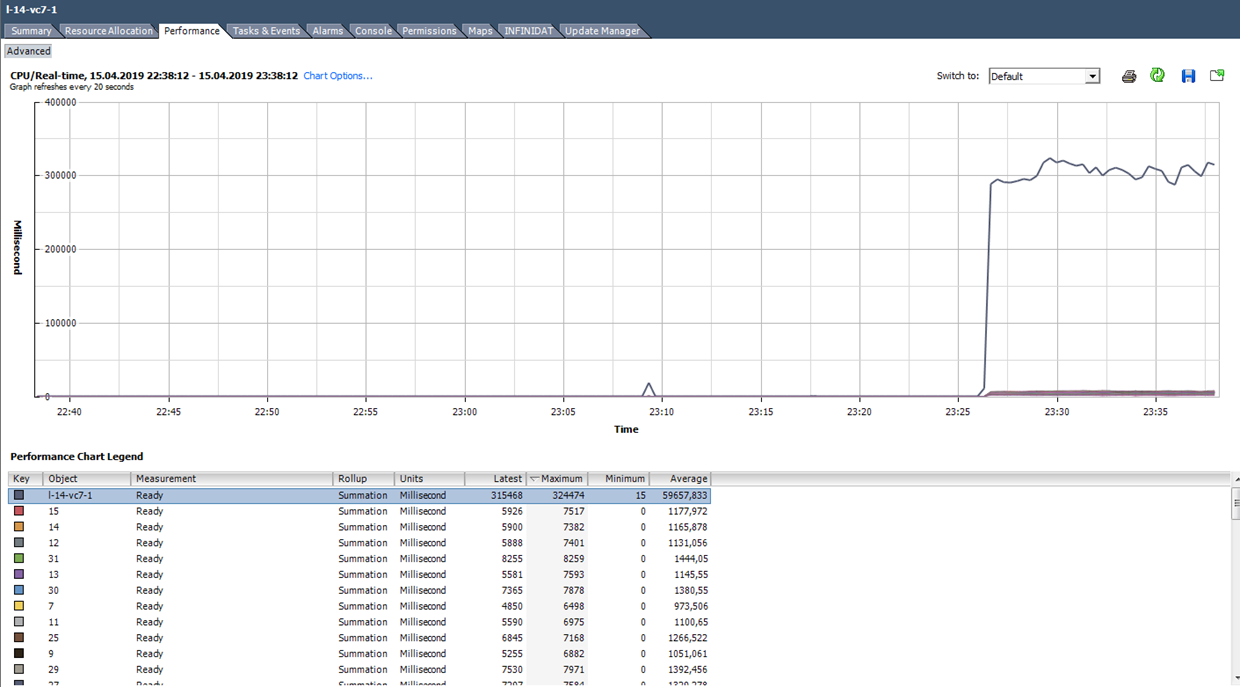
Misalnya, untuk VM di grafik di bawah ini, nilai puncak Ready untuk seluruh mesin virtual adalah sebagai berikut:
Saat menghitung nilai Ready sebagai persentase, Anda harus memperhatikan dua poin:
- Nilai Ready di seluruh VM adalah jumlah Ready di seluruh core.
- Interval pengukuran. Untuk Real-time, ini adalah 20 detik, dan, misalnya, pada grafik harian, ini adalah 300 detik.
Dengan pemecahan masalah aktif, poin-poin sederhana ini dapat dengan mudah dilewatkan dan waktu yang berharga dapat dihabiskan untuk menyelesaikan masalah yang tidak ada.
Kami menghitung Ready berdasarkan data dari grafik di bawah ini. (324474 / (20 * 1000)) * 100 = 1622% untuk seluruh VM. Jika Anda melihat inti, itu akan berubah tidak begitu menakutkan: 1622/64 = 25% per inti. Dalam hal ini, mendeteksi trik cukup sederhana: nilai Ready tidak realistis. Tetapi jika kita berbicara sekitar 10-20% untuk seluruh VM dengan beberapa core, maka untuk setiap inti nilainya dapat berada dalam kisaran normal.
 Apa yang harus dilakukan
Apa yang harus dilakukan Nilai Ready yang tinggi menunjukkan bahwa server tidak memiliki sumber daya prosesor yang cukup untuk operasi normal mesin virtual. Dalam situasi ini, tetap hanya untuk mengurangi kelebihan langganan pada prosesor (vCPU: pCPU). Jelas, ini dapat dicapai dengan mengurangi parameter VM yang ada atau dengan memigrasi sebagian VM ke server lain.
Berhenti bersama
Bagaimana cara menganalisa? Penghitung ini juga memiliki tipe penjumlahan dan diterjemahkan ke dalam persentase seperti Ready:
(Nilai penjumlah co-stop CPU / (grafik interval pembaruan default dalam detik * 1000)) * 100 = CPU co-stop%
Di sini Anda juga perlu memperhatikan jumlah core per VM dan interval pengukuran.
Dalam keadaan costop, kernel tidak melakukan pekerjaan yang bermanfaat. Dengan pemilihan ukuran VM yang benar dan beban normal pada server, penghitung co-stop harus mendekati nol.
 Dalam hal ini, bebannya jelas abnormal :)Apa yang harus dilakukan
Dalam hal ini, bebannya jelas abnormal :)Apa yang harus dilakukan Jika beberapa VM dengan sejumlah besar core berjalan pada hypervisor yang sama dan ada kelebihan langganan pada CPU, maka penghitung co-stop dapat tumbuh, yang akan menyebabkan masalah dengan kinerja VM ini.
Juga, co-stop akan meningkat jika utas digunakan untuk kernel aktif dari satu VM pada inti server fisik yang sama dengan hyper-treading diaktifkan. Situasi seperti itu dapat muncul, misalnya, jika VM memiliki lebih banyak core daripada yang ada secara fisik di server tempat kerjanya, atau jika pengaturan "preferHT" diaktifkan untuk VM. Anda dapat membaca tentang pengaturan ini di
sini .
Untuk menghindari masalah dengan kinerja VM karena co-stop yang tinggi, pilih ukuran VM sesuai dengan rekomendasi dari produsen perangkat lunak yang berjalan pada VM ini, dan dengan kemampuan server fisik di mana VM berjalan.
Jangan menambahkan kernel sebagai cadangan, ini dapat menyebabkan masalah kinerja tidak hanya dari VM itu sendiri, tetapi juga dari tetangga servernya.
Metrik CPU Berguna Lainnya
Jalankan - berapa banyak waktu (ms) untuk periode pengukuran vCPU dalam status RUN, yaitu, benar-benar melakukan pekerjaan yang bermanfaat.
Menganggur - berapa banyak waktu (ms) untuk periode pengukuran vCPU tidak aktif. Nilai Idle tinggi bukan masalah, hanya vCPU yang "tidak ada hubungannya."
Tunggu - berapa banyak waktu (ms) untuk periode pengukuran vCPU dalam status Tunggu. Karena IDLE termasuk dalam penghitung ini, nilai Tunggu yang tinggi juga tidak menunjukkan masalah. Tetapi jika pada IDLE tinggi Tunggu rendah, maka VM sedang menunggu untuk operasi I / O untuk menyelesaikan, dan ini, pada gilirannya, dapat menunjukkan masalah dengan kinerja hard disk atau beberapa perangkat VM virtual.
Terbatas terbatas - berapa banyak waktu (ms) untuk periode pengukuran vCPU dalam status Siap karena batas sumber daya yang ditetapkan. Jika kinerjanya sangat rendah, ada baiknya memeriksa nilai penghitung ini dan batas CPU dalam pengaturan VM. VM mungkin memang memiliki batasan yang tidak Anda sadari. Sebagai contoh, ini terjadi ketika VM miring dari template tempat batas CPU ditetapkan.
Swap wait - berapa lama vCPU menunggu operasi dengan VMkernel Swap selama periode pengukuran. Jika nilai-nilai penghitung ini di atas nol, maka VM pasti memiliki masalah kinerja. Kami akan berbicara lebih banyak tentang SWAP di artikel tentang penghitung RAM.
ESXTOP
Jika penghitung kinerja di vCenter baik untuk menganalisis data historis, maka analisis online masalah sebaiknya dilakukan di ESXTOP. Di sini, semua nilai disajikan dalam bentuk jadi (tidak perlu menerjemahkan apa pun), dan periode pengukuran minimum adalah 2 detik.
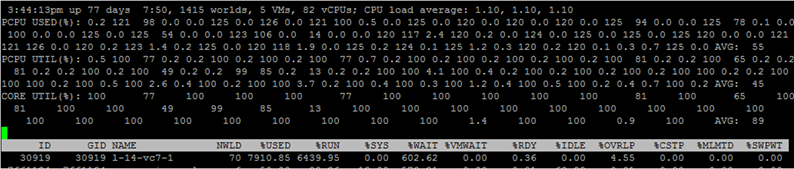
Layar ESXTOP pada CPU dipanggil oleh tombol "c" dan terlihat seperti ini:

Untuk kenyamanan, Anda hanya dapat meninggalkan proses mesin virtual dengan menekan Shift-V.
Untuk melihat metrik untuk masing-masing inti VM, tekan "e" dan ketikkan GID dari VM yang Anda minati (30919 pada tangkapan layar di bawah):

Secara singkat buka kolom yang disajikan secara default. Kolom tambahan dapat ditambahkan dengan menekan "f".
NWLD (Number of Worlds) - jumlah proses dalam grup. Untuk memperluas grup dan melihat metrik untuk setiap proses (misalnya, untuk setiap inti dari VM multi-inti), tekan "e". Jika grup memiliki lebih dari satu proses, maka nilai metrik untuk grup sama dengan jumlah metrik untuk masing-masing proses.
% DIGUNAKAN - berapa banyak siklus CPU server menggunakan suatu proses atau kelompok proses.
% RUN - berapa banyak waktu selama periode pengukuran proses berada dalam keadaan RUN, mis. melakukan pekerjaan yang bermanfaat. Ini berbeda dari% USED karena tidak memperhitungkan hyper-threading, penskalaan frekuensi, dan waktu yang dihabiskan untuk tugas sistem (% SYS).
% SYS - waktu yang dihabiskan untuk tugas-tugas sistem, misalnya: menangani interupsi, input / output, operasi jaringan, dll. Nilainya dapat tinggi jika ada banyak input / output pada VM.
% OVRLP - berapa banyak waktu inti fisik yang digunakan untuk menjalankan proses VM dihabiskan pada tugas-tugas dari proses lain.
Metrik ini terkait sebagai berikut:
% DIGUNAKAN =% RUN +% SYS -% OVRLP.
Biasanya metrik% USED lebih informatif.
% TUNGGU - berapa banyak waktu selama periode pengukuran proses dalam status Tunggu. Termasuk IDLE.
% IDLE - berapa lama proses dalam status IDLE selama periode pengukuran.
% SWPWT - berapa lama vCPU menunggu operasi dengan VMkernel Swap selama periode pengukuran.
% VMWAIT - berapa lama vCPU berada dalam keadaan menunggu suatu peristiwa (biasanya I / O) selama periode pengukuran. Tidak ada penghitung serupa di vCenter. Nilai tinggi menunjukkan masalah dengan input / output ke VM.
% WAIT =% VMWAIT +% IDLE +% SWPWT.
Jika VM tidak menggunakan VMkernel Swap, maka ketika menganalisis masalah kinerja, disarankan untuk melihat% VMWAIT, karena metrik ini tidak memperhitungkan waktu ketika VM tidak melakukan apa-apa (% IDLE).
% RDY - berapa lama proses dalam status Siap selama periode pengukuran.
% CSTP - berapa lama proses dalam status pos selama periode pengukuran.
% MLMTD - berapa banyak waktu selama periode pengukuran vCPU dalam status Siap karena batas sumber daya yang ditetapkan.
% WAIT +% RDY +% CSTP +% RUN = 100% - inti VM selalu di salah satu dari empat negara ini.
CPU pada hypervisor
Ada juga penghitung kinerja CPU untuk hypervisor di vCenter, tetapi mereka tidak mewakili sesuatu yang menarik - itu hanya jumlah penghitung untuk semua VM di server.
Cara paling mudah untuk melihat status CPU di server ada di tab Summary:

Untuk server, dan juga untuk mesin virtual, ada Alarm standar:
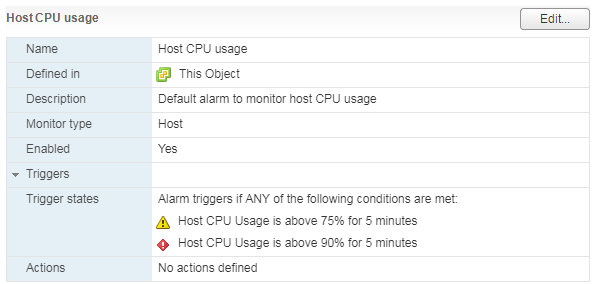
Dengan beban yang tinggi pada CPU server, VM yang menjalankannya mulai mengalami masalah kinerja.
Dalam ESXTOP, data pemanfaatan CPU server disajikan di bagian atas layar. Selain beban CPU standar, yang tidak informatif untuk hypervisor, ada tiga metrik lagi:
CORE UTIL (%) - memuat inti dari server fisik. Penghitung ini menunjukkan berapa banyak waktu kernel melakukan pekerjaan selama periode pengukuran.
PCPU UTIL (%) - jika hyper-threading diaktifkan, maka ada dua utas (PCPU) untuk setiap inti fisik. Metrik ini menunjukkan seberapa banyak waktu setiap utas bekerja.
PCPU USED (%) sama dengan PCPU UTIL (%), tetapi memperhitungkan penskalaan frekuensi akun (baik menurunkan frekuensi inti untuk menghemat energi atau meningkatkan frekuensi inti karena teknologi Turbo Boost) dan hyper-threading.
PCPU_USED% = PCPU_UTIL% * frekuensi inti efektif / frekuensi inti nominal.
 Dalam tangkapan layar ini, untuk beberapa inti, karena operasi Turbo Boost, nilai USED lebih dari 100%, karena frekuensi inti lebih tinggi dari nominal.
Dalam tangkapan layar ini, untuk beberapa inti, karena operasi Turbo Boost, nilai USED lebih dari 100%, karena frekuensi inti lebih tinggi dari nominal.Beberapa kata tentang bagaimana hyper-threading diperhitungkan. Jika proses berjalan 100% dari waktu pada kedua utas inti fisik server, sedangkan inti berjalan pada frekuensi nominal, maka:
- CORE UTIL untuk kernel akan menjadi 100%,
- PCPU UTIL untuk kedua utas akan menjadi 100%,
- PCED USED untuk kedua utas akan menjadi 50%.
Jika kedua utas tidak bekerja 100% dari waktu selama periode pengukuran, maka pada periode tersebut ketika utas bekerja secara paralel, PCPU DIGUNAKAN untuk inti dibagi menjadi setengah.
ESXTOP juga memiliki layar dengan parameter konsumsi daya dari server CPU. Di sini Anda dapat melihat apakah server menggunakan teknologi hemat energi: Status-C dan Status-P. Dipanggil oleh tombol p:

Masalah Kinerja CPU yang Umum
Akhirnya, saya akan membahas alasan khas masalah dengan kinerja VM CPU dan memberikan tips singkat untuk menyelesaikannya:
Kecepatan clock inti tidak cukup. Jika tidak ada cara untuk mentransfer VM ke kernel yang lebih efisien, Anda dapat mencoba mengubah pengaturan energi untuk membuat Turbo Boost bekerja lebih efisien.
Ukuran yang salah dari VM (terlalu banyak / sedikit inti). Jika Anda menaruh beberapa core, akan ada beban tinggi pada VM CPU. Jika banyak, tangkap pemberhentian bersama yang tinggi.
Berlebih-lebihan dari CPU pada server. Jika VM siap tinggi, kurangi langganan berlebih pada CPU.
Topologi NUMA salah pada VM besar. Topologi NUMA yang dilihat oleh VM (vNUMA) harus cocok dengan topologi server NUMA (pNUMA). Tentang diagnostik dan kemungkinan solusi untuk masalah ini ditulis, misalnya, dalam buku
"VMware vSphere 6.5 . Jika Anda tidak ingin masuk lebih dalam dan Anda tidak memiliki batasan lisensi pada OS yang diinstal pada VM, lakukan banyak soket virtual pada VM pada satu inti. Anda tidak akan kehilangan banyak :)
Itu saja untuk CPU. Ajukan pertanyaan. Pada bagian
selanjutnya saya akan berbicara tentang RAM.