Pada artikel sebelumnya kita membahas
mesin pengindeksan PostgreSQL, antarmuka metode akses, dan metode berikut:
indeks hash ,
B-tree ,
GiST ,
SP-GiST ,
GIN , dan
RUM . Topik artikel ini adalah indeks BRIN.
Brin
Konsep umum
Tidak seperti indeks yang telah kami kumpulkan, ide BRIN adalah untuk menghindari melihat-lihat baris yang tidak cocok daripada dengan cepat menemukan yang cocok. Ini selalu merupakan indeks yang tidak akurat: ini tidak mengandung TIDs baris tabel sama sekali.
Secara sederhana, BRIN berfungsi dengan baik untuk kolom yang nilainya berkorelasi dengan lokasi fisiknya dalam tabel. Dengan kata lain, jika kueri tanpa klausa ORDER BY mengembalikan nilai kolom secara virtual dalam urutan kenaikan atau penurunan (dan tidak ada indeks pada kolom itu).
Metode akses ini dibuat dalam lingkup
Axle , proyek Eropa untuk database analitik yang sangat besar, dengan memperhatikan tabel yang beberapa terabyte atau puluhan terabyte besar. Fitur penting dari BRIN yang memungkinkan kami membuat indeks pada tabel tersebut adalah ukuran kecil dan biaya pemeliharaan minimal.
Ini berfungsi sebagai berikut. Tabel ini dibagi menjadi
rentang yang beberapa halaman besar (atau beberapa blok besar, yang sama) - maka namanya: Block Range Index, BRIN. Indeks menyimpan
informasi ringkasan tentang data di setiap rentang. Sebagai aturan, ini adalah nilai minimal dan maksimal, tetapi kebetulan berbeda, seperti yang ditunjukkan lebih lanjut. Asumsikan bahwa kueri dilakukan yang berisi kondisi untuk kolom; jika nilai yang dicari tidak masuk ke dalam interval, seluruh rentang dapat dilewati; tetapi jika mereka mendapatkan, semua baris di semua blok harus diperiksa untuk memilih yang cocok di antara mereka.
Ini tidak akan menjadi kesalahan untuk memperlakukan BRIN bukan sebagai indeks, tetapi sebagai akselerator pemindaian sekuensial. Kita dapat menganggap BRIN sebagai alternatif untuk mempartisi jika kita menganggap setiap rentang sebagai partisi "virtual".
Sekarang mari kita bahas struktur indeks secara lebih rinci.
Struktur
Halaman pertama (lebih tepatnya, nol) berisi metadata.
Halaman dengan informasi ringkasan terletak pada offset tertentu dari metadata. Setiap baris indeks pada halaman tersebut berisi informasi ringkasan pada satu rentang.
Antara halaman meta dan data ringkasan, halaman dengan
peta rentang terbalik (disingkat "revmap") berada. Sebenarnya, ini adalah array pointer (TIDs) ke baris indeks yang sesuai.
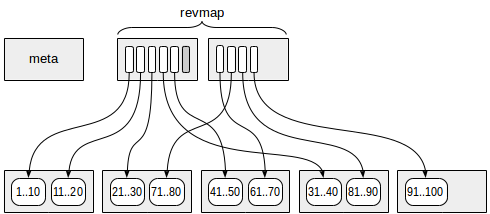
Untuk beberapa rentang, penunjuk di "revmap" dapat menyebabkan tidak ada baris indeks (satu ditandai dengan warna abu-abu pada gambar). Dalam kasus seperti itu, jangkauan dianggap belum memiliki informasi ringkasan.
Memindai indeks
Bagaimana indeks digunakan jika tidak mengandung referensi ke baris tabel? Metode akses ini tentu saja tidak dapat mengembalikan baris TID oleh TID, tetapi dapat membangun bitmap. Ada dua jenis halaman bitmap: akurat, ke baris, dan tidak akurat, ke halaman. Ini adalah bitmap yang tidak akurat yang digunakan.
Algoritma itu sederhana. Peta rentang dipindai secara berurutan (yaitu, rentang tersebut dilalui sesuai urutan lokasi mereka dalam tabel). Pointer digunakan untuk menentukan baris indeks dengan informasi ringkasan pada setiap rentang. Jika rentang tidak mengandung nilai yang dicari, itu dilewati, dan jika itu dapat mengandung nilai (atau informasi ringkasan tidak tersedia), semua halaman rentang ditambahkan ke bitmap. Bitmap yang dihasilkan kemudian digunakan seperti biasa.
Memperbarui indeks
Lebih menarik bagaimana indeks diperbarui ketika tabel diubah.
Saat
menambahkan versi baru baris ke halaman tabel, kami menentukan rentang mana yang terkandung di dalamnya dan menggunakan peta rentang untuk menemukan baris indeks dengan informasi ringkasan. Semua ini adalah operasi aritmatika sederhana. Biarkan, misalnya, ukuran rentang menjadi empat dan pada halaman 13, versi baris dengan nilai 42 muncul. Jumlah rentang (dimulai dengan nol) adalah 13/4 = 3, oleh karena itu, dalam "revmap" kita mengambil pointer dengan offset 3 (nomor urutnya empat).
Nilai minimum untuk rentang ini adalah 31, dan yang maksimal adalah 40. Karena nilai baru 42 berada di luar interval, kami memperbarui nilai maksimal (lihat gambar). Tetapi jika nilai baru masih dalam batas yang disimpan, indeks tidak perlu diperbarui.

Semua ini berkaitan dengan situasi ketika versi halaman yang baru muncul dalam kisaran di mana informasi ringkasan tersedia. Ketika indeks dibuat, informasi ringkasan dihitung untuk semua rentang yang tersedia, tetapi sementara tabel diperluas, halaman baru dapat terjadi yang berada di luar batas. Dua opsi tersedia di sini:
- Biasanya indeks tidak segera diperbarui. Ini bukan masalah besar: seperti yang telah disebutkan, saat memindai indeks, seluruh rentang akan diperiksa. Pembaruan aktual dilakukan selama "vakum", atau dapat dilakukan secara manual dengan memanggil fungsi "brin_summarize_new_values".
- Jika kita membuat indeks dengan parameter "autosummarize", pembaruan akan segera dilakukan. Tetapi ketika halaman rentang diisi dengan nilai-nilai baru, pembaruan dapat terjadi terlalu sering, oleh karena itu, parameter ini dimatikan secara default.
Ketika rentang baru terjadi, ukuran "revmap" dapat meningkat. Setiap kali peta, yang terletak di antara halaman meta dan data ringkasan, perlu diperpanjang oleh halaman lain, versi baris yang ada dipindahkan ke beberapa halaman lain. Jadi, peta rentang selalu berada di antara halaman meta dan data ringkasan.
Ketika satu baris
dihapus , ... tidak ada yang terjadi. Kita dapat memperhatikan bahwa kadang-kadang nilai minimal atau maksimal akan dihapus, sehingga intervalnya dapat dikurangi. Tetapi untuk mendeteksi ini, kita harus membaca semua nilai dalam kisaran, dan ini mahal.
Keakuratan indeks tidak terpengaruh, tetapi pencarian mungkin memerlukan melihat lebih banyak rentang daripada yang sebenarnya dibutuhkan. Secara umum, informasi ringkasan dapat secara manual dihitung ulang untuk zona seperti itu (dengan memanggil "brin_desummarize_range" dan "brin_summarize_new_values" fungsi), tetapi bagaimana kita dapat mendeteksi kebutuhan seperti itu? Bagaimanapun, tidak ada prosedur konvensional yang tersedia untuk tujuan ini.
Akhirnya,
memperbarui baris hanyalah penghapusan dari versi yang sudah usang dan penambahan yang baru.
Contoh
Mari kita coba membangun gudang data mini kita sendiri untuk data dari tabel
database demo . Mari kita asumsikan bahwa untuk tujuan pelaporan BI, diperlukan tabel denormalized untuk mencerminkan penerbangan yang berangkat dari bandara atau mendarat di bandara dengan akurasi kursi di kabin. Data untuk setiap bandara akan ditambahkan ke tabel sekali sehari, saat tengah malam di zona waktu yang sesuai. Data tidak akan diperbarui atau dihapus.
Tabel akan terlihat sebagai berikut:
demo=# create table flights_bi( airport_code char(3), airport_coord point,
Kami dapat mensimulasikan prosedur pemuatan data menggunakan nested loop: eksternal satu - per hari (oleh karena itu kami akan mempertimbangkan
basis data besar , oleh karena itu 365 hari), dan zona loop - per waktu internal (dari UTC + 02 ke UTC + 12) . Permintaannya cukup panjang dan tidak menarik, jadi saya akan menyembunyikannya di bawah spoiler.
Simulasi memuat data ke penyimpanan DO $$ <<local>> DECLARE curdate date := (SELECT min(scheduled_departure) FROM flights); utc_offset interval; BEGIN WHILE (curdate <= bookings.now()::date) LOOP utc_offset := interval '12 hours'; WHILE (utc_offset >= interval '2 hours') LOOP INSERT INTO flights_bi WITH flight ( airport_code, airport_coord, flight_id, flight_no, scheduled_time, actual_time, aircraft_code, flight_type ) AS ( ;
demo=# select count(*) from flights_bi;
count ---------- 30517076 (1 row)
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi'));
pg_size_pretty ---------------- 4127 MB (1 row)
Kami mendapatkan 30 juta baris dan 4 GB. Ukurannya tidak terlalu besar, tapi cukup bagus untuk laptop: pemindaian sekuensial memakan waktu sekitar 10 detik.
Pada kolom apa kita harus membuat indeks?
Karena indeks BRIN memiliki ukuran kecil dan biaya overhead sedang dan pembaruan jarang terjadi, jika ada, peluang langka muncul untuk membangun banyak indeks "berjaga-jaga", misalnya, di semua bidang tempat pengguna analis dapat membuat kueri ad-hoc mereka . Tidak akan berguna - tidak masalah, tetapi bahkan indeks yang tidak terlalu efisien akan bekerja lebih baik daripada pemindaian berurutan pasti. Tentu saja, ada bidang yang tidak berguna untuk membangun indeks; akal sehat murni akan mendorong mereka.
Tetapi seharusnya aneh membatasi diri pada nasihat ini, oleh karena itu, mari kita coba untuk menyatakan kriteria yang lebih akurat.
Kami telah menyebutkan bahwa data harus berkorelasi dengan lokasi fisiknya. Di sini masuk akal untuk diingat bahwa PostgreSQL mengumpulkan statistik kolom tabel, yang mencakup nilai korelasi. Perencana menggunakan nilai ini untuk memilih antara pemindaian indeks reguler dan pemindaian bitmap, dan kita dapat menggunakannya untuk memperkirakan penerapan indeks BRIN.
Dalam contoh di atas, data jelas dipesan berdasarkan hari (oleh "dijadwalkan_waktu", serta oleh "aktual_waktu" - tidak ada banyak perbedaan). Ini karena ketika baris ditambahkan ke tabel (tanpa penghapusan dan pembaruan), mereka diletakkan dalam file satu demi satu. Dalam simulasi pemuatan data, kami bahkan tidak menggunakan klausa ORDER BY, oleh karena itu, tanggal dalam satu hari dapat, secara umum, tercampur secara sewenang-wenang, tetapi pemesanan harus dilakukan. Mari kita periksa ini:
demo=# analyze flights_bi; demo=# select attname, correlation from pg_stats where tablename='flights_bi' order by correlation desc nulls last;
attname | correlation --------------------+------------- scheduled_time | 0.999994 actual_time | 0.999994 fare_conditions | 0.796719 flight_type | 0.495937 airport_utc_offset | 0.438443 aircraft_code | 0.172262 airport_code | 0.0543143 flight_no | 0.0121366 seat_no | 0.00568042 passenger_name | 0.0046387 passenger_id | -0.00281272 airport_coord | (12 rows)
Nilai yang tidak terlalu dekat dengan nol (idealnya, mendekati plus-minus, seperti dalam kasus ini), memberi tahu kita bahwa indeks BRIN akan sesuai.
Kelas perjalanan "fare_condition" (kolom berisi tiga nilai unik) dan jenis penerbangan "flight_type" (dua nilai unik) secara tak terduga tampaknya berada di tempat kedua dan ketiga. Ini adalah ilusi: secara formal korelasinya tinggi, sementara sebenarnya pada beberapa halaman berturut-turut semua nilai yang mungkin akan ditemui pasti, yang berarti bahwa BRIN tidak akan berbuat baik.
Zona waktu "airport_utc_offset" berlangsung berikutnya: dalam contoh yang dipertimbangkan, dalam siklus satu hari, bandara dipesan berdasarkan zona waktu "berdasarkan konstruksi".
Dua bidang ini, zona waktu dan waktu, inilah yang akan kami eksperimen lebih lanjut.
Kemungkinan melemahnya korelasi
Korelasi tempat "dengan konstruksi" dapat dengan mudah dilemahkan ketika data diubah. Dan masalahnya di sini bukanlah perubahan ke nilai tertentu, tetapi dalam struktur kontrol konkurensi multiversion: versi baris yang usang dihapus pada satu halaman, tetapi versi baru dapat dimasukkan di mana pun ruang kosong tersedia. Karena itu, seluruh baris digabungkan selama pembaruan.
Kami dapat mengontrol sebagian efek ini dengan mengurangi nilai parameter penyimpanan "fillfactor" dan dengan cara ini memberikan ruang kosong pada halaman untuk pembaruan di masa mendatang. Tapi apakah kita ingin menambah ukuran meja yang sudah besar? Selain itu, ini tidak menyelesaikan masalah penghapusan: mereka juga "mengatur jebakan" untuk baris baru dengan membebaskan ruang di suatu tempat di dalam halaman yang ada. Karena ini, baris yang sebaliknya akan sampai ke akhir file, akan disisipkan di beberapa tempat sewenang-wenang.
Ngomong-ngomong, ini adalah fakta yang aneh. Karena indeks BRIN tidak mengandung referensi ke baris tabel, ketersediaannya tidak boleh menghalangi pembaruan HOT sama sekali, tetapi itu.
Jadi, BRIN terutama dirancang untuk tabel ukuran besar dan bahkan sangat besar yang tidak diperbarui sama sekali atau diperbarui sangat sedikit. Namun, ini sangat cocok dengan penambahan baris baru (sampai akhir tabel). Ini tidak mengherankan karena metode akses ini dibuat dengan maksud untuk gudang data dan pelaporan analitis.
Ukuran rentang apa yang perlu kita pilih?
Jika kita berurusan dengan tabel terabyte, perhatian utama kita ketika memilih ukuran rentang mungkin tidak akan membuat indeks BRIN terlalu besar. Namun, dalam situasi kami, kami dapat menganalisis data dengan lebih akurat.
Untuk melakukan ini, kita dapat memilih nilai unik suatu kolom dan melihat pada berapa banyak halaman yang muncul. Pelokalan nilai meningkatkan peluang keberhasilan dalam menerapkan indeks BRIN. Selain itu, jumlah halaman yang ditemukan akan meminta ukuran rentang. Tetapi jika nilainya "tersebar" di semua halaman, BRIN tidak berguna.
Tentu saja, kita harus menggunakan teknik ini untuk mengawasi struktur internal data. Sebagai contoh, tidak masuk akal untuk mempertimbangkan setiap tanggal (lebih tepatnya, cap waktu, juga termasuk waktu) sebagai nilai unik - kita perlu membulatkannya menjadi beberapa hari.
Secara teknis, analisis ini dapat dilakukan dengan melihat nilai kolom "ctid" tersembunyi, yang menyediakan penunjuk ke versi baris (TID): jumlah halaman dan jumlah baris di dalam halaman. Sayangnya, tidak ada teknik konvensional untuk mengurai TID menjadi dua komponennya, oleh karena itu, kita harus membuang tipe melalui representasi teks:
demo=# select min(numblk), round(avg(numblk)) avg, max(numblk) from ( select count(distinct (ctid::text::point)[0]) numblk from flights_bi group by scheduled_time::date ) t;
min | avg | max ------+------+------ 1192 | 1500 | 1796 (1 row)
demo=# select relpages from pg_class where relname = 'flights_bi';
relpages ---------- 528172 (1 row)
Kita dapat melihat bahwa setiap hari didistribusikan secara merata di seluruh halaman, dan hari-hari sedikit tercampur satu sama lain (1500 & kali 365 = 547500, yang hanya sedikit lebih besar dari jumlah halaman pada tabel 528172). Ini sebenarnya jelas "dengan konstruksi".
Informasi berharga di sini adalah jumlah halaman tertentu. Dengan ukuran rentang konvensional 128 halaman, setiap hari akan mengisi rentang 9-14. Ini tampaknya realistis: dengan permintaan untuk hari tertentu, kami dapat mengharapkan kesalahan sekitar 10%.
Mari kita coba:
demo=# create index on flights_bi using brin(scheduled_time);
Ukuran indeks sekecil 184 KB:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_idx'));
pg_size_pretty ---------------- 184 kB (1 row)
Dalam hal ini, hampir tidak masuk akal untuk meningkatkan ukuran kisaran dengan mengorbankan kehilangan keakuratan. Tetapi kita dapat mengurangi ukuran jika diperlukan, dan keakuratannya akan, sebaliknya, meningkat (bersama dengan ukuran indeks).
Sekarang mari kita lihat zona waktu. Di sini kita juga tidak bisa menggunakan pendekatan brute-force. Semua nilai harus dibagi dengan jumlah siklus hari sebagai gantinya karena distribusi diulang dalam setiap hari. Selain itu, karena hanya ada beberapa zona waktu saja, kita dapat melihat seluruh distribusi:
demo=# select airport_utc_offset, count(distinct (ctid::text::point)[0])/365 numblk from flights_bi group by airport_utc_offset order by 2;
airport_utc_offset | numblk --------------------+-------- 12:00:00 | 6 06:00:00 | 8 02:00:00 | 10 11:00:00 | 13 08:00:00 | 28 09:00:00 | 29 10:00:00 | 40 04:00:00 | 47 07:00:00 | 110 05:00:00 | 231 03:00:00 | 932 (11 rows)
Rata-rata, data untuk setiap zona waktu mengisi 133 halaman sehari, tetapi distribusinya sangat tidak seragam: Petropavlovsk-Kamchatskiy dan Anadyr cocok hanya dengan enam halaman, sedangkan Moskow dan lingkungannya membutuhkan ratusan halaman. Ukuran default rentang tidak baik di sini; mari, misalnya, atur menjadi empat halaman.
demo=# create index on flights_bi using brin(airport_utc_offset) with (pages_per_range=4); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_airport_utc_offset_idx'));
pg_size_pretty ---------------- 6528 kB (1 row)
Rencana eksekusi
Mari kita lihat bagaimana indeks kita bekerja. Mari kita pilih suatu hari, katakanlah, seminggu yang lalu (dalam database demo, "hari ini" ditentukan oleh fungsi "booking.now"):
demo=# \set d 'bookings.now()::date - interval \'7 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=10.282..94.328 rows=83954 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 12045 Heap Blocks: lossy=1664 -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=3.013..3.013 rows=16640 loops=1) Index Cond: ... Planning time: 0.375 ms Execution time: 97.805 ms
Seperti yang bisa kita lihat, perencana menggunakan indeks yang dibuat. Seberapa akurat? Rasio jumlah baris yang memenuhi persyaratan kueri ("baris" dari Bitmap Heap Scan node) dengan total jumlah baris yang dikembalikan menggunakan indeks (nilai yang sama ditambah Baris Dihapus oleh Index Recheck) memberi tahu kita tentang hal ini. Dalam hal ini 83954 / (83954 + 12045), yaitu sekitar 90%, seperti yang diharapkan (nilai ini akan berubah dari satu hari ke hari lain).
Dari mana asal 16640 dalam "baris aktual" dari Bitmap Index Scan node berasal? Masalahnya adalah bahwa simpul rencana ini membangun bitmap (halaman demi halaman) yang tidak akurat dan sama sekali tidak mengetahui berapa banyak baris bitmap yang akan disentuh, sementara sesuatu perlu ditunjukkan. Karena itu, dalam keputusasaan satu halaman diasumsikan mengandung 10 baris. Bitmap berisi total 1664 halaman (nilai ini ditunjukkan dalam "Heap Blocks: lossy = 1664"); jadi, kita baru mendapatkan 16640. Secara keseluruhan, ini adalah angka yang tidak masuk akal, yang seharusnya tidak kita perhatikan.
Bagaimana dengan bandara? Sebagai contoh, mari kita ambil zona waktu Vladivostok, yang memuat 28 halaman sehari:
demo=# explain (costs off,analyze) select * from flights_bi where airport_utc_offset = interval '8 hours';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=75.151..192.210 rows=587353 loops=1) Recheck Cond: (airport_utc_offset = '08:00:00'::interval) Rows Removed by Index Recheck: 191318 Heap Blocks: lossy=13380 -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=74.999..74.999 rows=133800 loops=1) Index Cond: (airport_utc_offset = '08:00:00'::interval) Planning time: 0.168 ms Execution time: 212.278 ms
Perencana lagi menggunakan indeks BRIN yang dibuat. Akurasinya lebih buruk (sekitar 75% dalam kasus ini), tetapi ini diharapkan karena korelasinya lebih rendah.
Beberapa indeks BRIN (sama seperti yang lain) tentu saja dapat digabungkan di tingkat bitmap. Misalnya, berikut ini adalah data pada zona waktu yang dipilih selama sebulan (perhatikan simpul "BitmapAnd"):
demo=# \set d 'bookings.now()::date - interval \'60 days\'' demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '30 days' and airport_utc_offset = interval '8 hours';
QUERY PLAN --------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=62.046..113.849 rows=48154 loops=1) Recheck Cond: ... Rows Removed by Index Recheck: 18856 Heap Blocks: lossy=1152 -> BitmapAnd (actual time=61.777..61.777 rows=0 loops=1) -> Bitmap Index Scan on flights_bi_scheduled_time_idx (actual time=5.490..5.490 rows=435200 loops=1) Index Cond: ... -> Bitmap Index Scan on flights_bi_airport_utc_offset_idx (actual time=55.068..55.068 rows=133800 loops=1) Index Cond: ... Planning time: 0.408 ms Execution time: 115.475 ms
Perbandingan dengan b-tree
Bagaimana jika kita membuat indeks B-tree reguler pada bidang yang sama dengan BRIN?
demo=# create index flights_bi_scheduled_time_btree on flights_bi(scheduled_time); demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_scheduled_time_btree'));
pg_size_pretty ---------------- 654 MB (1 row)
Tampaknya
beberapa ribu kali lebih besar dari BRIN kami! Namun, kueri dilakukan sedikit lebih cepat: perencana menggunakan statistik untuk mengetahui bahwa data dipesan secara fisik dan tidak diperlukan untuk membangun bitmap dan, terutama, kondisi indeks tidak perlu diperiksa ulang:
demo=# explain (costs off,analyze) select * from flights_bi where scheduled_time >= :d and scheduled_time < :d + interval '1 day';
QUERY PLAN ---------------------------------------------------------------- Index Scan using flights_bi_scheduled_time_btree on flights_bi (actual time=0.099..79.416 rows=83954 loops=1) Index Cond: ... Planning time: 0.500 ms Execution time: 85.044 ms
Itulah yang sangat luar biasa dari BRIN: kami mengorbankan efisiensinya, tetapi mendapatkan banyak ruang.
Kelas operator
minmax
Untuk tipe data yang nilainya dapat dibandingkan satu sama lain, informasi ringkasan terdiri dari
nilai minimal dan maksimal . Nama-nama kelas operator yang sesuai berisi "minmax", misalnya, "date_minmax_ops". Sebenarnya, ini adalah tipe data yang kami pertimbangkan sejauh ini, dan sebagian besar tipe dari jenis ini.
inklusif
Operator perbandingan tidak ditentukan untuk semua tipe data. Misalnya, mereka tidak didefinisikan untuk titik (tipe "titik"), yang mewakili koordinat geografis bandara. Omong-omong, karena alasan inilah statistik tidak menunjukkan korelasi untuk kolom ini.
demo=# select attname, correlation from pg_stats where tablename='flights_bi' and attname = 'airport_coord';
attname | correlation ---------------+------------- airport_coord | (1 row)
Tetapi banyak dari jenis-jenis tersebut memungkinkan kita untuk memperkenalkan konsep "daerah pembatas", misalnya, persegi panjang pembatas untuk bentuk geometris. Kami membahas secara rinci bagaimana indeks
GiST menggunakan fitur ini. Demikian pula, BRIN juga memungkinkan pengumpulan informasi ringkasan pada kolom yang memiliki tipe data seperti ini:
area pembatas untuk semua nilai di dalam rentang hanyalah nilai ringkasan.
Tidak seperti untuk GiST, nilai ringkasan untuk BRIN harus dari jenis yang sama dengan nilai yang diindeks. Oleh karena itu, kami tidak dapat membuat indeks untuk poin, walaupun jelas bahwa koordinat tersebut dapat berfungsi di BRIN: garis bujur terkait erat dengan zona waktu. Untungnya, tidak ada yang menghalangi pembuatan indeks pada ekspresi setelah mengubah poin menjadi persegi panjang yang merosot. Pada saat yang sama, kami akan mengatur ukuran rentang menjadi satu halaman, hanya untuk menunjukkan batas kasus:
demo=# create index on flights_bi using brin (box(airport_coord)) with (pages_per_range=1);
Ukuran indeks sekecil 30 MB bahkan dalam situasi ekstrem seperti ini:
demo=# select pg_size_pretty(pg_total_relation_size('flights_bi_box_idx'));
pg_size_pretty ---------------- 30 MB (1 row)
Sekarang kita dapat membuat kueri yang membatasi bandara dengan koordinat. Sebagai contoh:
demo=# select airport_code, airport_name from airports where box(coordinates) <@ box '120,40,140,50';
airport_code | airport_name --------------+----------------- KHV | Khabarovsk-Novyi VVO | Vladivostok (2 rows)
Perencana akan, bagaimanapun, menolak untuk menggunakan indeks kami.
demo=# analyze flights_bi; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN --------------------------------------------------------------------- Seq Scan on flights_bi (cost=0.00..985928.14 rows=30517 width=111) Filter: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Mengapa Mari kita nonaktifkan pemindaian berurutan dan lihat apa yang terjadi:
demo=# set enable_seqscan = off; demo=# explain select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN -------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (cost=14079.67..1000007.81 rows=30517 width=111) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) -> Bitmap Index Scan on flights_bi_box_idx (cost=0.00..14072.04 rows=30517076 width=0) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box)
Tampaknya indeks
dapat digunakan, tetapi perencana menduga bahwa bitmap harus dibangun di atas seluruh tabel (lihat "baris" dari simpul Pemindaian Bitmap Index), dan tidak heran bahwa perencana memilih pemindaian berurutan dalam kasus ini. Masalahnya di sini adalah untuk tipe geometris, PostgreSQL tidak mengumpulkan statistik apa pun, dan perencana harus membabi buta:
demo=# select * from pg_stats where tablename = 'flights_bi_box_idx' \gx
-[ RECORD 1 ]----------+------------------- schemaname | bookings tablename | flights_bi_box_idx attname | box inherited | f null_frac | 0 avg_width | 32 n_distinct | 0 most_common_vals | most_common_freqs | histogram_bounds | correlation | most_common_elems | most_common_elem_freqs | elem_count_histogram |
Sayang Tetapi tidak ada keluhan tentang indeks - itu berfungsi dan berfungsi dengan baik:
demo=# explain (costs off,analyze) select * from flights_bi where box(airport_coord) <@ box '120,40,140,50';
QUERY PLAN ---------------------------------------------------------------------------------- Bitmap Heap Scan on flights_bi (actual time=158.142..315.445 rows=781790 loops=1) Recheck Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Rows Removed by Index Recheck: 70726 Heap Blocks: lossy=14772 -> Bitmap Index Scan on flights_bi_box_idx (actual time=158.083..158.083 rows=147720 loops=1) Index Cond: (box(airport_coord) <@ '(140,50),(120,40)'::box) Planning time: 0.137 ms Execution time: 340.593 ms
Kesimpulannya harus seperti ini: PostGIS diperlukan jika ada sesuatu yang nontrivial diperlukan dari geometri. Itu bisa mengumpulkan statistik.
Internal
Ekstensi konvensional "pageinspect" memungkinkan kita untuk melihat ke dalam indeks BRIN.
Pertama, metainformation akan meminta kita ukuran rentang dan berapa banyak halaman yang dialokasikan untuk "revmap":
demo=# select * from brin_metapage_info(get_raw_page('flights_bi_scheduled_time_idx',0));
magic | version | pagesperrange | lastrevmappage ------------+---------+---------------+---------------- 0xA8109CFA | 1 | 128 | 3 (1 row)
Halaman 1-3 di sini dialokasikan untuk "revmap", sementara sisanya berisi data ringkasan. Dari "revmap" kita bisa mendapatkan referensi ke data ringkasan untuk setiap rentang. Katakanlah, informasi pada rentang pertama, menggabungkan 128 halaman pertama, terletak di sini:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) limit 1;
pages --------- (6,197) (1 row)
Dan ini adalah data ringkasan itu sendiri:
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 197;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 02:45:00+03 .. 2016-08-15 17:15:00+03} (1 row)
Rentang selanjutnya:
demo=# select * from brin_revmap_data(get_raw_page('flights_bi_scheduled_time_idx',1)) offset 1 limit 1;
pages --------- (6,198) (1 row)
demo=# select allnulls, hasnulls, value from brin_page_items( get_raw_page('flights_bi_scheduled_time_idx',6), 'flights_bi_scheduled_time_idx' ) where itemoffset = 198;
allnulls | hasnulls | value ----------+----------+---------------------------------------------------- f | f | {2016-08-15 06:00:00+03 .. 2016-08-15 18:55:00+03} (1 row)
Dan sebagainya.
Untuk kelas "inklusi", bidang "nilai" akan menampilkan sesuatu seperti
{(94.4005966186523,69.3110961914062),(77.6600036621,51.6693992614746) .. f .. f}
Nilai pertama adalah persegi panjang penyematan, dan huruf "f" pada akhirnya menunjukkan kekurangan elemen kosong (yang pertama) dan tidak memiliki nilai yang tidak dapat digabungkan (yang kedua). Sebenarnya, satu-satunya nilai yang tidak dapat digabungkan adalah alamat "IPv4" dan "IPv6" (tipe data "inet").
Properti
Mengingatkan Anda pada pertanyaan yang
telah disediakan .
Berikut ini adalah properti dari metode akses:
amname | name | pg_indexam_has_property --------+---------------+------------------------- brin | can_order | f brin | can_unique | f brin | can_multi_col | t brin | can_exclude | f
Indeks dapat dibuat di beberapa kolom. Dalam hal ini, statistik ringkasannya dikumpulkan untuk setiap kolom, tetapi statistik tersebut disimpan bersama untuk setiap rentang. Tentu saja, indeks ini masuk akal jika satu dan ukuran rentang yang sama cocok untuk semua kolom.
Properti lapisan indeks berikut tersedia:
name | pg_index_has_property ---------------+----------------------- clusterable | f index_scan | f bitmap_scan | t backward_scan | f
Terbukti, hanya pemindaian bitmap yang didukung.
Namun, kurangnya pengelompokan mungkin tampak membingungkan. Tampaknya, karena indeks BRIN sensitif terhadap urutan fisik baris, akan logis untuk dapat mengelompokkan data sesuai dengan indeks. Tapi ini tidak benar. Kami hanya dapat membuat indeks "biasa" (B-tree atau GiST, tergantung pada tipe data) dan mengelompokkannya. Omong-omong, apakah Anda ingin mengelompokkan tabel yang seharusnya besar dengan mempertimbangkan kunci eksklusif, waktu eksekusi, dan konsumsi ruang disk selama pembangunan kembali?
Berikut ini adalah properti layer-kolom:
name | pg_index_column_has_property --------------------+------------------------------ asc | f desc | f nulls_first | f nulls_last | f orderable | f distance_orderable | f returnable | f search_array | f search_nulls | t
Satu-satunya properti yang tersedia adalah kemampuan untuk memanipulasi NULL.
Baca terus .