
Teknologi dari Harry Potter telah bertahan hingga hari ini. Sekarang, untuk membuat video lengkap seseorang, hanya satu dari gambar atau fotonya yang cukup. Peneliti pembelajaran mesin dari Skolkovo dan Samsung AI Center di Moskow menerbitkan karya mereka tentang menciptakan sistem seperti itu, bersama dengan sejumlah video selebriti dan benda seni yang telah menerima kehidupan baru.

Teks karya ilmiah dapat dibaca di sini . Semuanya cukup menarik di sana, dengan banyak formula, tetapi artinya sederhana: sistem mereka dipandu oleh "landmark", pemandangan wajah, seperti hidung, dua mata, dua alis, dan garis dagu. Jadi dia langsung menangkap siapa orang itu. Dan kemudian dapat mentransfer segala sesuatu yang lain (warna, tekstur wajah, kumis, tunggul, dll.) Ke video orang lain. Menyesuaikan wajah lama dengan situasi baru.
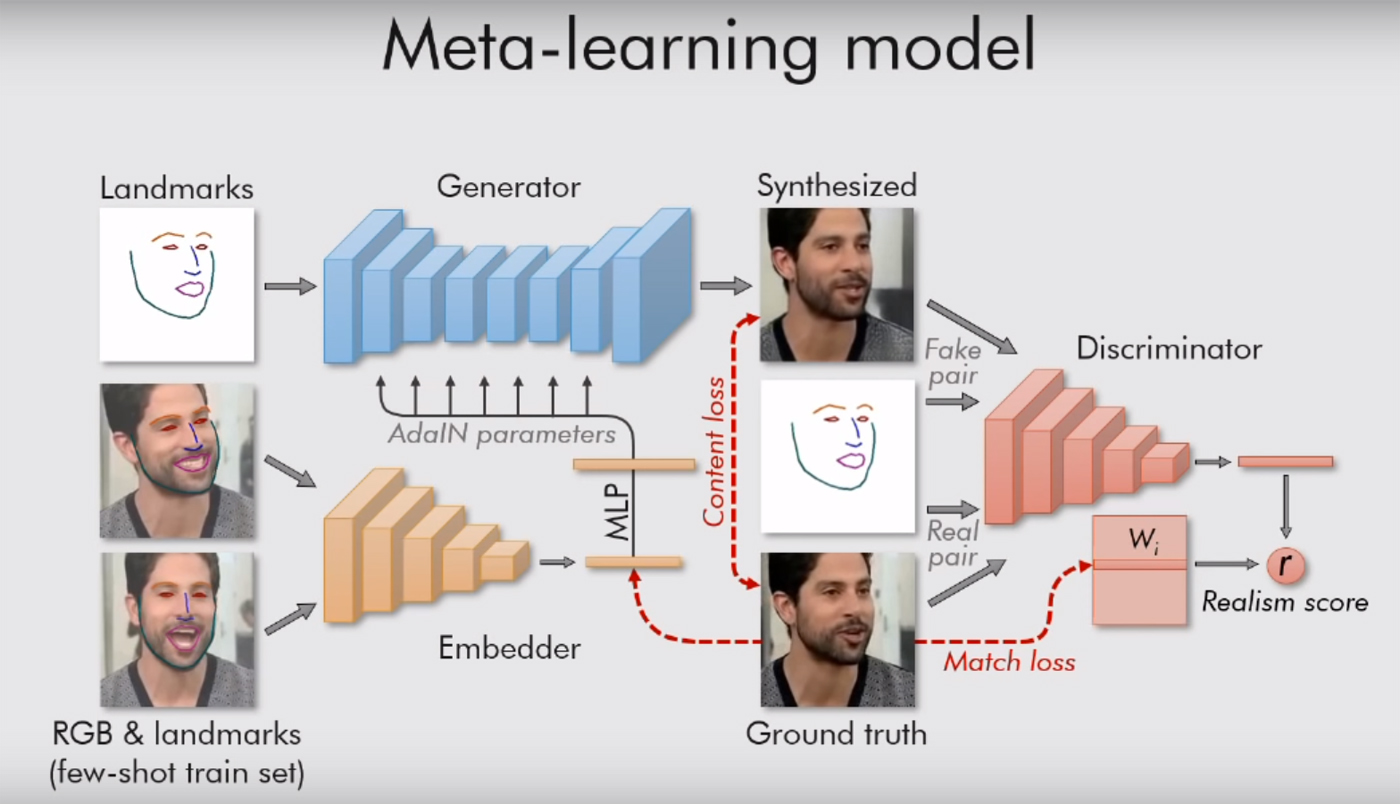
Tentu saja, ini hanya berfungsi pada potret. Model hanya membutuhkan satu orang, dengan wajah menoleh ke arah kami, sehingga ia setidaknya bisa melihat kedua mata. Kemudian sistem dapat melakukan apa saja dengannya, mengirimkan ekspresi wajah apa pun padanya. Cukup memberinya video yang cocok (dengan orang lain dengan posisi kepala hampir sama).
Sebelumnya, AI sudah belajar cara membuat diphake, dan pengguna internet dengan anggun mengejek selebriti dengan memasukkan wajah mereka ke dalam porno dan membuat meme dengan Nicholas Cage. Tetapi untuk ini, mereka harus melatih algoritme dalam megabita (atau lebih baik - gigabita) data, untuk menemukan sebanyak mungkin gambar dan video dengan wajah selebritis untuk menghasilkan hasil yang kurang lebih layak. Pencipta Deepfakes sendiri mengatakan bahwa dibutuhkan 8-12 jam untuk menyusun satu video pendek. Sistem baru menghasilkan hasilnya secara instan, dan pada input hanya membutuhkan satu gambar.
Dengan sistem sebelumnya, kita tidak akan pernah bisa melihat Mona Lisa yang hidup, kita hanya memiliki satu sudut. Sekarang, dengan algoritma pembandingan, ini menjadi mungkin. Yang ideal tidak tercapai, tetapi sesuatu sudah dekat.

Peneliti Moskow juga menggunakan jaringan generatif-permusuhan. Dua model algoritma saling bertarung. Masing-masing mencoba untuk menipu lawan, dan membuktikan kepadanya bahwa video yang dia buat adalah nyata. Dengan cara ini, tingkat realisme tertentu tercapai: gambar wajah manusia tidak dilepaskan "ke cahaya" jika kritik tidak lebih dari 90% yakin akan keasliannya. Seperti yang dikatakan penulis dalam karya mereka, puluhan juta parameter diatur dalam gambar, tetapi karena sistem seperti itu, pekerjaan mendidih dengan sangat cepat.

Jika ada beberapa gambar, hasilnya membaik. Sekali lagi, cara termudah adalah bekerja dengan selebriti yang sudah diambil dari semua sudut pandang. Untuk mencapai "realisme ideal" diperlukan 32 tembakan. Dalam hal ini, foto AI yang dihasilkan dalam resolusi rendah tidak dapat dibedakan dari foto manusia asli. Orang-orang yang tidak terlatih pada tahap ini tidak lagi dapat mengidentifikasi palsu - mungkin peluang tetap dengan para ahli atau dengan kerabat dekat "eksperimental" dari semua gambar ini.
Jika hanya ada satu foto atau gambar, hasilnya tidak selalu yang terbaik. Anda dapat melihat artefak di video saat kepala bergerak tanpa masalah. Para peneliti sendiri mengatakan bahwa titik terlemah mereka adalah pandangan. Model berdasarkan landmark wajah belum selalu mengerti bagaimana dan di mana seseorang harus melihat.
