Kita semua tahu seperti apa hash itu, tetapi pernahkah Anda bertanya-tanya seberapa sering karakter tertentu muncul dalam hash? Saya bertanya-tanya. Dan saya memutuskan untuk memeriksanya. Membuat sketsa skrip Python untuk dihitung, dan inilah yang muncul darinya.
Pertama, saya membuat string karakter acak (panjang dari 0 hingga 1000).
def random_string(from_int, to_int): return str(''.join(random.SystemRandom().choice(string.ascii_letters + string.digits + string.punctuation) for _ in range(random.randint(from_int, to_int))))
Selanjutnya, saya mengambil hash MD5 dari string.
def md5_from_string(string): return hashlib.md5(string.encode('utf-8')).hexdigest()
Setelah - saya menghitung berapa digit dari 0 hingga 9 dalam hash. Pada sampel 1000 hash, saya menerima data berikut:
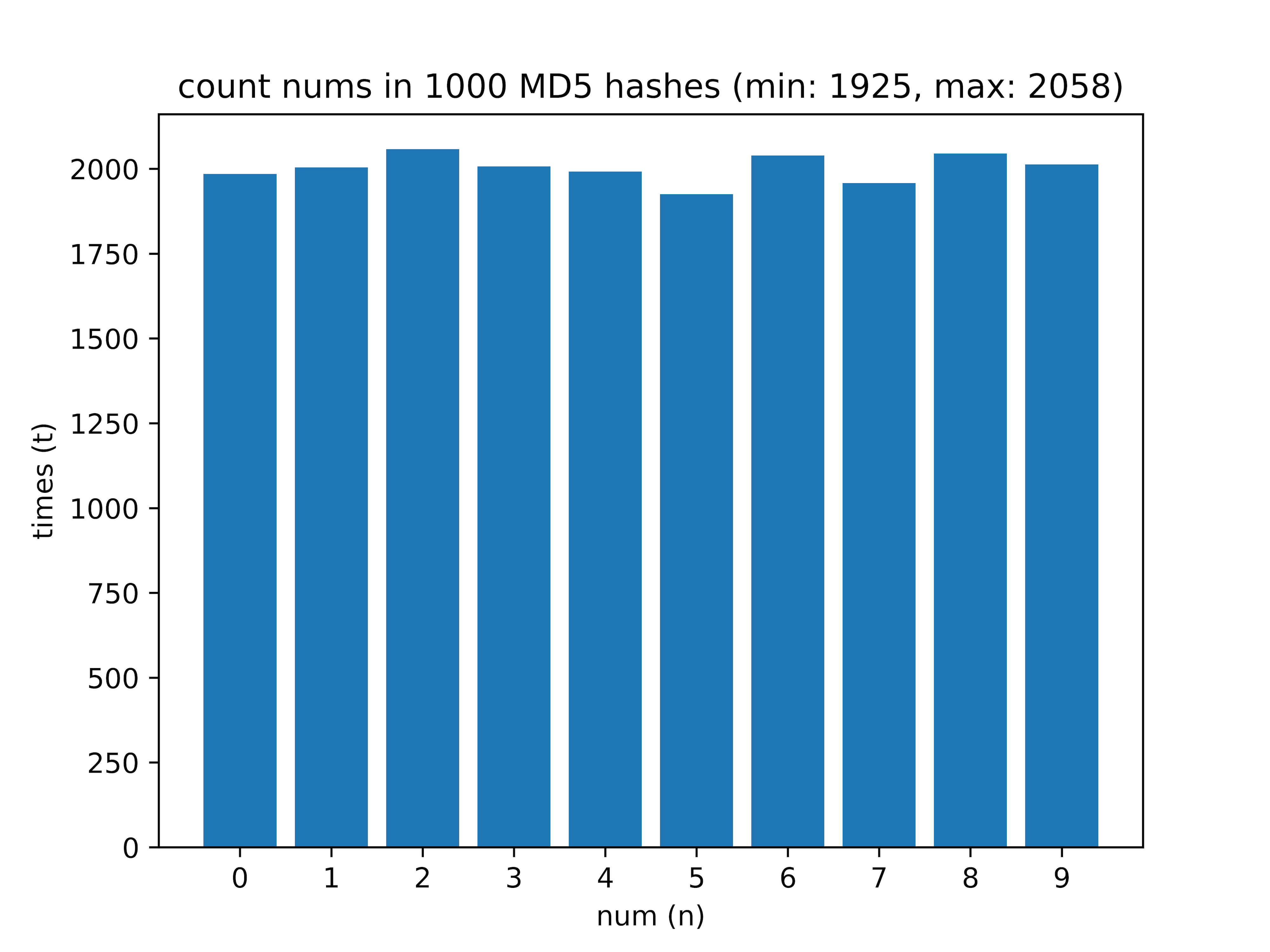
Di sini perbedaan antara digit yang paling sering dijumpai dan yang paling langka (nilai delta) menarik.

Selanjutnya, untuk melacak perubahan nilai delta, ia membuat sampel hash 10.000, 100.000, 1.000.000, 10.000.000.

Berikut ini adalah daftar dengan nilai angka minimum dan maksimum dan nilai delta pada sampel dengan nomor hash MD5 yang berbeda:
- 100 - mnt: 179, maks: 230, delta: 22,17%
- 1000 - mnt: 1925, maks: 2058, delta: 6.46%
- 10000 - mnt: 19769, maks: 20251, delta: 2,38%
- 100000 - min: 199297, maks: 200846, delta: 0,77%
- 1.000.000 - mnt: 1997650, maks: 2001690, delta: 0,20%
- 10000000 - min: 19991830, maks: 20004818, delta: 0,06%
Apa yang kita miliki: dengan peningkatan jumlah hash dalam array, nilai delta berkurang dan setiap digit dengan probabilitas yang hampir sama akan jatuh ke dalam array. Dengan demikian, semakin besar sampel, semakin kecil perbedaan antara angka yang sering ditemui dan jarang terlihat. Dengan demikian, probabilitas mendapatkan digit tertentu dalam hash cenderung seragam.
Informasi ini membentuk dasar dari algoritma yang kami terapkan pada
platform kompetisi
bepeam.com