Di "Black Mirror" ada seri (S2E1), di mana mereka menciptakan robot yang mirip dengan orang mati, menggunakan sejarah korespondensi di jejaring sosial untuk pelatihan. Saya ingin memberi tahu Anda bagaimana saya mencoba melakukan sesuatu yang serupa dan apa yang terjadi. Tidak akan ada teori, hanya latihan.

Idenya sederhana - untuk mengambil sejarah obrolan mereka dari Telegram dan, atas dasar mereka, untuk melatih jaringan seq2seq, yang mampu memprediksi penyelesaiannya di awal dialog. Jaringan seperti itu dapat beroperasi dalam tiga mode:
- Prediksi penyelesaian frasa pengguna berdasarkan riwayat percakapan
- Bekerja dalam mode chatbot
- Mensintesis seluruh log percakapan
Itu yang saya dapat
Bot menawarkan penyelesaian frase
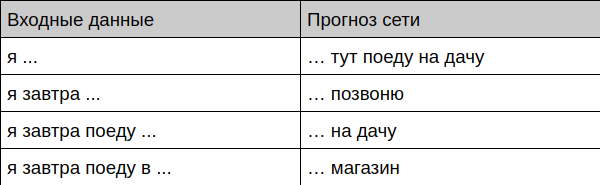
Bot menawarkan penyelesaian dialog
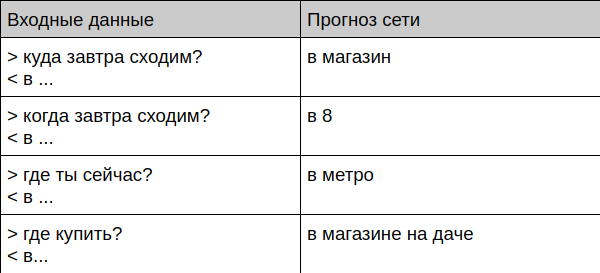
Bot berkomunikasi dengan orang yang hidup
User: Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot: User: ? Bot:
Selanjutnya saya akan memberi tahu Anda bagaimana mempersiapkan data dan melatih bot seperti itu sendiri.
Cara mengajar diri sendiri
Persiapan data
Pertama-tama, Anda perlu mendapatkan banyak obrolan di suatu tempat. Saya mengambil semua korespondensi saya di Telegram, karena klien untuk desktop memungkinkan mengunduh arsip lengkap dalam format JSON. Lalu saya membuang semua pesan yang berisi tanda kutip, tautan, dan file, dan mentransfer teks yang tersisa ke huruf kecil dan membuang semua karakter langka dari sana, hanya menyisakan satu set huruf, angka, dan tanda baca sederhana - lebih mudah untuk mempelajari jaringan.
Kemudian saya membawa obrolan ke formulir ini:
=== > < > < ! === > ? <
Di sini, pesan yang dimulai dengan simbol ">" adalah pertanyaan untuk saya, simbol "<" menandai jawaban saya, dan baris "===" berfungsi untuk memisahkan dialog di antara mereka sendiri. Fakta bahwa satu dialog berakhir dan yang lainnya dimulai, saya ditentukan oleh waktu (jika lebih dari 15 menit telah berlalu di antara pesan, maka kami pikir ini adalah percakapan baru. Anda dapat melihat skrip untuk mengonversi cerita di github .
Karena saya telah aktif menggunakan telegram untuk waktu yang lama, ada banyak pesan pada akhirnya - ada 443 ribu baris dalam file terakhir.
Pemilihan model
Saya berjanji tidak akan ada teori hari ini, jadi saya akan mencoba menjelaskan sesingkat mungkin di jari saya.
Saya memilih seq2seq klasik berdasarkan GRU. Model input seperti itu menerima surat teks dengan huruf dan juga mengeluarkan satu huruf pada suatu waktu. Proses pembelajaran didasarkan pada fakta bahwa kami mengajarkan jaringan untuk memprediksi huruf terakhir dari teks, misalnya, kami memberikan "timah" ke input dan menunggu "keling" untuk menjadi output.
Untuk menghasilkan teks yang panjang, trik sederhana digunakan - hasil prediksi sebelumnya dikirim kembali ke jaringan dan seterusnya sampai panjang teks yang diperlukan dihasilkan.
Modul GRU dapat sangat, sangat disederhanakan sebagai "perceptron licik dengan memori dan perhatian", rincian lebih lanjut tentang mereka dapat ditemukan, misalnya, di sini .
Contoh yang terkenal dari tugas menghasilkan teks Shakespeare dipilih sebagai dasar dari model.
Pelatihan
Siapa pun yang pernah menemukan jaringan saraf mungkin tahu bahwa mempelajarinya di CPU sangat membosankan. Untungnya, Google datang untuk menyelamatkan dengan layanan Colab mereka - di dalamnya Anda dapat menjalankan kode Anda di jupyter notebook secara gratis menggunakan CPU, GPU dan bahkan TPU . Dalam kasus saya, pelatihan pada kartu video cocok dalam 30 menit, meskipun hasil yang waras tersedia setelah 10. Hal utama yang harus diingat untuk mengganti jenis perangkat keras (dalam menu Runtime -> Ubah jenis runtime).
Pengujian
Setelah pelatihan, Anda dapat melanjutkan ke verifikasi model - saya menulis beberapa contoh yang memungkinkan Anda untuk mengakses model dalam mode yang berbeda - dari pembuatan teks hingga live chat. Semuanya ada di github .
Metode untuk menghasilkan teks memiliki parameter suhu - semakin tinggi, semakin beragam teks (dan tidak berarti) akan menghasilkan bot. Parameter ini masuk akal untuk mengonfigurasi tangan untuk tugas tertentu.
Penggunaan lebih lanjut
Mengapa jaringan seperti itu dapat digunakan? Yang paling jelas adalah mengembangkan bot (atau keyboard pintar) yang dapat menawarkan jawaban yang siap pakai kepada pengguna bahkan sebelum ia menulisnya. Fitur serupa sudah lama ada di Gmail dan sebagian besar keyboard, tetapi tidak memperhitungkan konteks percakapan dan cara pengguna tertentu melakukan korespondensi. Katakanlah, G-Keyboard secara stabil menawarkan saya pilihan yang sama sekali tidak berarti, misalnya, "Saya akan dengan ... hormat" di tempat di mana saya ingin mendapatkan opsi "Saya akan pergi dari dacha", yang pasti saya gunakan berkali-kali.
Apakah bot obrolan memiliki masa depan? Dalam bentuknya yang murni, pasti tidak ada di sana, ia memiliki terlalu banyak data pribadi, tidak ada yang tahu pada titik apa itu akan memberikan kepada lawan bicara jumlah kartu kredit Anda yang pernah Anda lemparkan ke teman. Selain itu, bot seperti itu tidak disetel sama sekali, sangat sulit untuk membuatnya melakukan tugas tertentu atau dengan benar menjawab pertanyaan tertentu. Sebaliknya, obrolan seperti itu bisa bekerja bersama dengan jenis bot lain, memberikan dialog yang lebih terhubung "tentang tidak ada" - itu mengatasi dengan baik dengan ini. (Namun, seorang ahli eksternal dalam pribadi istrinya mengatakan bahwa gaya komunikasi bot sangat mirip dengan saya. Dan topik yang dia pedulikan jelas sama - bug, perbaikan, komitmen, dan kegembiraan dan kesedihan pengembang lainnya terus muncul dalam teks).
Apa lagi yang menyarankan Anda untuk mencoba jika topik ini menarik bagi Anda?
- Transfer pembelajaran (untuk melatih dialog orang lain, dan kemudian selesaikan sendiri)
- Ubah model - tambah, ubah jenis (misalnya, pada LSTM).
- Cobalah bekerja dengan TPU. Dalam bentuknya yang murni, model ini tidak akan berfungsi, tetapi dapat disesuaikan. Akselerasi pembelajaran teoretis harus sepuluh kali.
- Port ke platform seluler, misalnya menggunakan ponsel Tensorflow.
PS Tautan ke github