Pengguna lain ingin menulis data baru ke hard disk, tetapi ia tidak memiliki cukup ruang kosong untuk ini. Saya juga tidak ingin menghapus apa pun, karena "semuanya sangat penting dan perlu." Dan apa yang harus kita lakukan dengannya?
Dia tidak punya masalah seperti itu. Terabyte informasi bersandar pada hard drive kami, dan jumlah ini cenderung tidak berkurang. Tapi seberapa unikkah itu? Pada akhirnya, setelah semua, semua file hanya set bit dengan panjang tertentu dan, kemungkinan besar, yang baru tidak jauh berbeda dari yang sudah disimpan.
Jelas bahwa untuk mencari potongan informasi yang sudah tersimpan di hard disk adalah tugas, jika bukan kegagalan, maka setidaknya tidak efektif. Di sisi lain, karena jika perbedaannya kecil, maka Anda dapat memuat sedikit ...

TL; DR - upaya kedua untuk berbicara tentang metode aneh mengoptimalkan data menggunakan file JPEG, sekarang dalam bentuk yang lebih dimengerti.
Tentang bit dan perbedaan
Jika kita mengambil dua bagian data yang benar-benar acak, maka rata-rata setengah dari bit yang terkandung bertepatan di dalamnya. Memang, di antara kemungkinan tata letak untuk setiap pasangan ('00, 01, 10, 11 '), tepat setengahnya memiliki nilai yang sama, semuanya sederhana di sini.
Tapi tentu saja, jika kita hanya mengambil dua file dan memasukkan satu di bawah yang kedua, maka kita akan kehilangan salah satunya. Jika kita menyimpan perubahan, kita hanya akan menemukan kembali pengkodean delta , yang bahkan tanpa kita ada dengan sempurna, meskipun biasanya tidak digunakan untuk tujuan yang sama. Anda dapat mencoba menyematkan urutan yang lebih kecil ke yang lebih besar, tetapi meskipun demikian, kami berisiko kehilangan segmen data penting saat digunakan dengan gegabah dengan segalanya.
Antara apa dan lalu apa perbedaan itu bisa dihilangkan? Yaitu, file baru yang direkam oleh pengguna hanyalah urutan bit yang dengannya kita tidak bisa melakukan apa pun dengan sendirinya. Maka Anda hanya perlu menemukan bit-bit tersebut pada hard drive sehingga dapat diubah tanpa harus menyimpan perbedaannya, sehingga Anda dapat selamat dari kehilangannya tanpa konsekuensi serius. Ya, dan masuk akal untuk mengubah tidak hanya file itu sendiri di FS, tetapi beberapa informasi yang kurang sensitif di dalamnya. Tapi yang mana dan bagaimana?
Metode Fit
File terkompresi yang hilang datang untuk menyelamatkan. Semua jpeg, mp3, dan lainnya ini, walaupun kompresinya lossy, mengandung banyak bit yang tersedia untuk perubahan yang aman. Anda dapat menggunakan teknik-teknik canggih, secara diam-diam memodifikasi komponen mereka di berbagai bidang pengkodean. Tunggu sebentar. Teknik-teknik canggih ... modifikasi yang tidak mencolok ... beberapa bit untuk yang lain ... ya itu hampir steganografi !
Memang, menanamkan satu informasi di yang lain menyerupai metodenya tidak peduli apa. Itu juga mengesankan ketidaktampakan perubahan yang dilakukan pada indera manusia. Di situlah jalan menyimpang - itu rahasia: tugas kami adalah menambahkan informasi tambahan ke hard drive pengguna, itu hanya akan melukai dirinya. Lupakan lebih banyak.
Karena itu, walaupun kita dapat menggunakannya, kita perlu melakukan beberapa modifikasi. Dan kemudian saya akan memberi tahu dan menunjukkannya pada contoh salah satu metode yang ada dan format file umum.
Tentang serigala
Jika Anda kompres, maka yang paling kompresibel di dunia. Kami tentu saja berbicara tentang file JPEG. Tidak hanya ada satu ton alat dan metode yang ada untuk menanamkan data di dalamnya, itu adalah format grafik paling populer di planet ini.

Namun demikian, agar tidak terlibat dalam pengembangbiakan anjing, Anda perlu membatasi bidang aktivitas Anda dalam file format ini. Tidak ada yang suka kotak monokrom yang muncul karena kompresi yang berlebihan, jadi Anda perlu membatasi diri untuk bekerja dengan file yang sudah dikompresi, menghindari transcoding . Lebih khusus lagi, dengan koefisien bilangan bulat yang tersisa setelah operasi yang bertanggung jawab atas kehilangan data - DCT dan kuantisasi, yang ditampilkan dengan sempurna pada skema pengkodean (berkat wiki Perpustakaan Nasional Bauman):

Ada banyak metode optimasi yang mungkin untuk file jpeg. Ada optimasi lossless (jpegtran), ada optimasi lossless , yang sebenarnya masih berkontribusi, tetapi mereka tidak mengganggu kita. Memang, jika pengguna siap untuk menanamkan satu informasi ke yang lain demi meningkatkan ruang disk kosong, maka ia akan mengoptimalkan gambarnya untuk waktu yang lama atau tidak ingin melakukan ini sama sekali karena takut kehilangan kualitas.
F5
Dalam kondisi seperti itu, seluruh keluarga algoritma cocok, yang dapat ditemukan dalam presentasi yang baik ini . Yang paling canggih adalah algoritma F5 , yang ditulis oleh Andreas Westfeld, yang bekerja dengan koefisien komponen kecerahan, karena mata manusia adalah yang paling tidak sensitif terhadap perubahannya. Selain itu, ia menggunakan teknik penyematan berdasarkan pengkodean matriks, yang memungkinkan seseorang untuk membuat lebih sedikit dari perubahan mereka ketika menanamkan jumlah informasi yang sama, semakin besar ukuran wadah yang digunakan.
Perubahan itu sendiri turun ke penurunan nilai absolut dari koefisien per unit dalam kondisi tertentu (yaitu, tidak selalu), yang memungkinkan F5 digunakan untuk mengoptimalkan penyimpanan data pada hard disk. Faktanya adalah bahwa koefisien setelah perubahan tersebut cenderung menempati jumlah bit yang lebih kecil setelah pengkodean Huffman karena distribusi nilai statistik dalam JPEG, dan nol baru akan mendapat manfaat dari pengkodean mereka menggunakan RLE.
Modifikasi yang diperlukan dikurangi untuk menghilangkan bagian yang bertanggung jawab atas kerahasiaan (permutasi kata sandi), yang memungkinkan penghematan sumber daya dan waktu eksekusi, dan menambahkan mekanisme untuk bekerja dengan banyak file alih-alih satu per satu. Secara lebih rinci, proses mengubah pembaca sepertinya tidak menarik, jadi kita beralih ke deskripsi implementasinya.
Teknologi tinggi
Untuk menunjukkan kerja pendekatan ini, saya menerapkan metode ini dalam C murni dan melakukan sejumlah optimasi baik dalam hal kecepatan dan memori (Anda tidak dapat membayangkan berapa banyak gambar ini menimbang tanpa kompresi bahkan sebelum DCT). Kinerja lintas platform dicapai dengan menggunakan kombinasi perpustakaan libjpeg , pcre, dan tinydir , yang saya ucapkan terima kasih. Semua ini akan dilakukan oleh make, sehingga pengguna Windows ingin menginstal Cygwin untuk evaluasi, atau berurusan dengan Visual Studio dan perpustakaan sendiri.
Implementasinya tersedia dalam bentuk utilitas konsol dan perpustakaan. Informasi lebih lanjut tentang menggunakan yang terakhir dapat ditemukan di readme di repositori di github, tautan yang akan saya lampirkan di akhir posting.
Bagaimana cara menggunakan
Dengan hati-hati. Gambar yang digunakan untuk kemasan dipilih oleh pencarian ekspresi reguler di direktori root yang ditentukan. Di akhir file, Anda dapat memindahkan, mengganti nama, dan menyalin yang diinginkan di dalamnya, mengubah file dan sistem operasi, dll. Namun, Anda harus sangat berhati-hati dan tidak mengubah konten langsung. Hilangnya nilai bahkan satu bit dapat menyebabkan ketidakmampuan untuk memulihkan informasi.
Setelah menyelesaikan pekerjaan, utilitas meninggalkan file arsip khusus yang berisi semua informasi yang diperlukan untuk membongkar, termasuk data pada gambar yang digunakan. Dengan sendirinya, ini membebani urutan beberapa kilobyte dan tidak memiliki efek signifikan pada ruang disk yang ditempati.
Anda dapat menganalisis kapasitas yang mungkin menggunakan flag '-a': './f5ar -a [folder pencarian] [Ekspresi reguler yang kompatibel dengan Perl]]. Pengemasan dilakukan dengan perintah './f5ar -p [folder pencarian] [ekspresi reguler yang kompatibel dengan Perl] [file yang dikemas] [nama arsip]', dan membongkar dengan './f5ar -u [file arsip] [nama file yang dipulihkan]' .
Demonstrasi kerja
Untuk menunjukkan efektivitas metode ini, saya mengunduh koleksi 225 foto anjing yang benar-benar gratis dari layanan Unsplash dan menggali pdf besar sejauh 45 meter dalam dokumen volume kedua Seni Pemrograman Knut.
Urutannya cukup sederhana:
$ du -sh knuth.pdf dogs/ 44M knuth.pdf 633M dogs/ $ ./f5ar -p dogs/ .*jpg knuth.pdf dogs.f5ar Reading compressing file... ok Initializing the archive... ok Analysing library capacity... done in 17.0s Detected somewhat guaranteed capacity of 48439359 bytes Detected possible capacity of upto 102618787 bytes Compressing... done in 39.4s Saving the archive... ok $ ./f5ar -u dogs/dogs.f5ar knuth_unpacked.pdf Initializing the archive... ok Reading the archive file... ok Filling the archive with files... done in 1.4s Decompressing... done in 21.0s Writing extracted data... ok $ sha1sum knuth.pdf knuth_unpacked.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth.pdf 5bd1f496d2e45e382f33959eae5ab15da12cd666 knuth_unpacked.pdf $ du -sh dogs/ 551M dogs/
Tangkapan layar untuk penggemar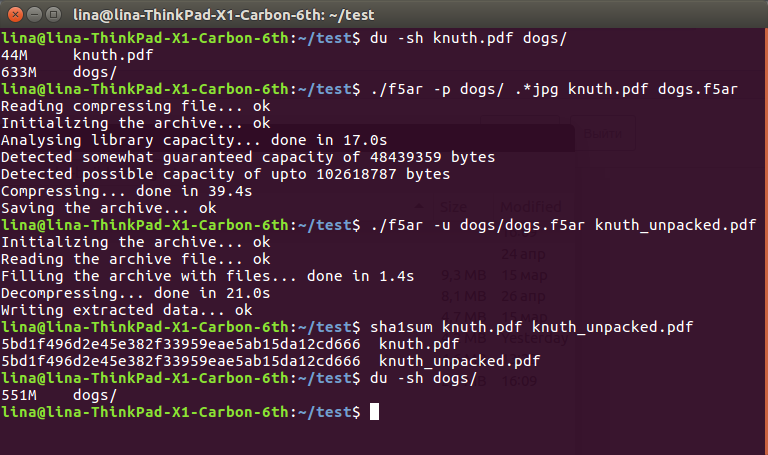
File yang belum dibongkar masih memungkinkan dan harus dibaca:

Seperti yang Anda lihat, dari data asli 633 + 36 == 669 megabita pada hard drive, kami sampai pada yang lebih menyenangkan 551. Perbedaan radikal ini dijelaskan oleh penurunan nilai koefisien, yang memengaruhi kompresi berikutnya tanpa kehilangan: penurunan hanya satu per satu dapat dengan tenang " potong "beberapa byte dari file yang dihasilkan. Namun, ini masih kehilangan data, meskipun sangat kecil, yang harus Anda tahan.
Untungnya, mereka tidak sepenuhnya terlihat oleh mata. Di bawah spoiler (karena habrastorage tidak dapat menangani file besar), pembaca dapat mengevaluasi perbedaan baik dengan mata maupun intensitasnya, diperoleh dengan mengurangi nilai komponen yang diubah dari yang asli: yang asli , dengan informasi di dalamnya , perbedaannya (semakin redup warnanya, semakin kecil perbedaan dalam blok tersebut). )
Alih-alih sebuah kesimpulan
Melihat semua kesulitan ini, membeli hard drive atau mengunggah semuanya ke cloud mungkin tampak seperti solusi yang lebih sederhana untuk masalah ini. Tetapi meskipun kita sekarang hidup dalam waktu yang begitu indah, tidak ada jaminan bahwa besok masih mungkin untuk online dan mengunggah semua data tambahan Anda ke suatu tempat. Atau datang ke toko dan beli sendiri seribu terabyte hard drive. Tapi Anda selalu bisa menggunakan rumah yang sudah tergeletak.
-> github